HCIA-Cloud-01
HCIA-Cloud
01-上午
云计算简介



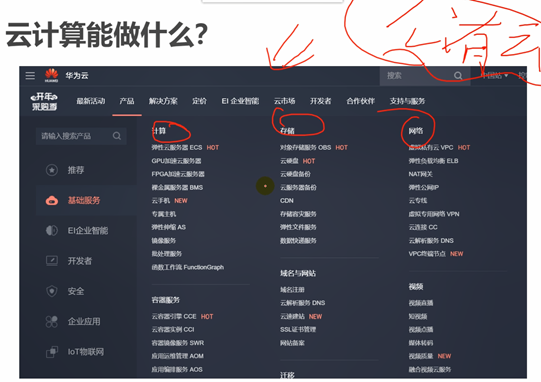
华为的官网,这些是公有云能够提供的服务。
基于华为自主研发的芯片的。华为自主研发的AI智能芯片。
如图这里有面向各种业务类型提供的智能服务。
这里都是偏向云存储的内容。

相比传统IT行业而言的。

计算资源池。
存储资源池。
网络资源池。
我们使用vm和存储和网络,那么就从相应池中来拿对应的大小。
除此之外,还可以提供数据库资源池,就是按需,可以创建自己对应的数据库。

可计量服务,就是可以按照你的使用量去收费。例如,你使用了8核心64g的机器,那么收费多少。
可计量服务,正常来讲是按使用时间或者使用量来收费,但是并没有到达这么细粒度的层面的。而只是按照你使用的单位去收费的,例如,购买了8核64g的机器,那么一年收费多少。也就是计算的是资源的使用单位,并不是说按照你使用时间之类的进行计费的。


云计算不是一门单一的技术,它是一种架构模型,内部使用了非常多的技术的。


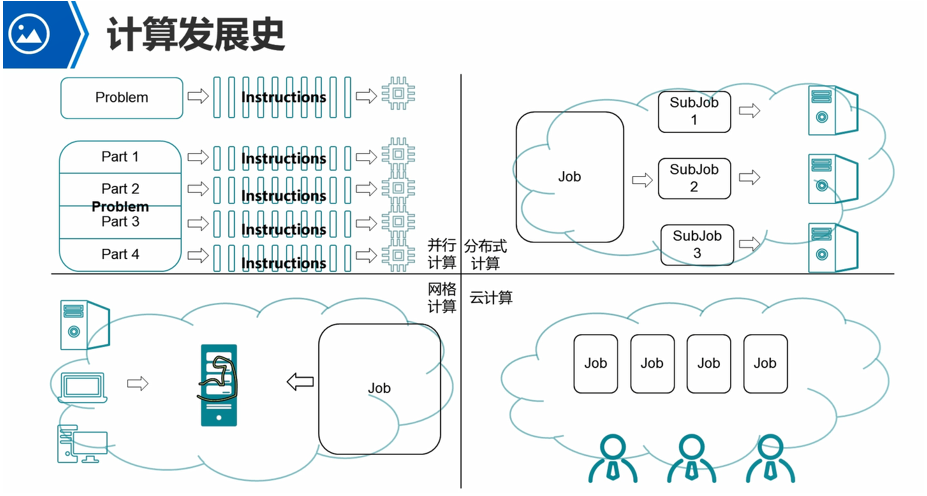
最早出现的是串行计算,效率很低,淘汰了。
并行计算,就是指一台服务器上,多个处理器并行处理任务。如图就是将一个problem拆分成多个part,然后交给不同的处理器去并行的处理。就是将一个复杂任务拆分成多个部分,交个不同的cpu处理器进行并行处理。
并行计算是只能在一台服务器上运行的,分配到多个处理器上去并行处理的。不能够将其分配到两个或者多个服务器上的cpu去处理的。
分布式计算,也是将一个大任务拆分成多个小任务,然后是将其放到多个不同的主机的cpu上去进行处理了。相对于并行计算而言,就是可以跨主机了,多个主机上的多个cpu来进行并行处理了。多个服务器处理各个任务之后,将结果交给一个中心系统,由中心系统去将结果整合。大数据计算就是这类。
网格计算,就是将多种计算设备,整合成一个非常强大的计算能力的服务器了,然后直接将一个非常复杂的任务交由这个非常强大的计算能力的服务器去处理了。网格计算的典型例子,就是超级计算机。例如,可以计算行星的运行轨迹,原子弹爆炸的效果。都是去处理非常复杂的任务的。
云计算,用户将任务提交到云端,那么不管这个云端用的是并行计算,还是分布式计算,还是网格计算,都行,只要在云端将任务处理完毕,然后将结果返回给我就行了。也就是云计算,不管这个任务是在哪处理的,如何处理的,我只是关注处理之后得到的结果的。
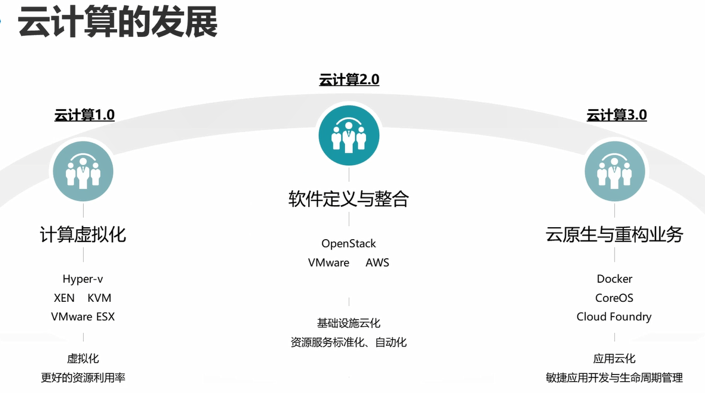
现在大部分的企业都处于在云计算2.0时代。
云计算1.0,主要就是虚拟化技术。
最开始各个硬件厂商,都是关注提高单台设备的处理性能,例如,提升cpu的处理性能。那么企业买到服务器之后,可能仅仅用到了cpu的5%的性能,剩下的都浪费了。因此,虚拟化技术出现,将一台物理设备,分割成多个虚拟机,然后在每个虚拟机上就可以分别去处理不同的任务,这样任务之间不会产生冲突。
Xen,kvm,开源的。
Hyper-v,esxi,闭源的。
云计算2.0,就是将各种底层的基础设置资源,如何进行整合,然后进行调度使用。也就是统一进行管理。这就是云管理平台了。
Openstack是开源的。华为基于其进行了二次研发,叫做fusionsul openstack。
现在大部分企业都处于云计算2.0时代。
云计算2.0,主要就是进行资源的整合。
云计算3.0,主要是面向应用开发人员使用的。更关注应用层面的东西,如何让应用开发的周期更短,最短的时间内完成应用的开发,以及应用的管理,发布,部署,上线,测试。
应用云化,应用上到云端。
Docker容器技术,早期的lxc,rocket也都是容器技术。


还有一种叫做行业云,它是一种比较特殊的私有云,也就是针对某一个行业的私有云。
云服务提供商。
云服务使用者。
如果云服务器提供商和云服务使用者,是同一个人,那么就是私有云。自己建,自己用。
如果云服务器提供商和云服务使用者,不是同一个人,那么就是公有云。例如,华为云,提供的东西,都是面向大众,只要花钱购买,就可以进行使用的。这种就是公有云。
混合云,例如,一个公司,既有自建的私有云,又有一部分是从公有云租用的服务器。这混合云。
行业云,例如,浙江省,所有医疗行业,建立的一个私有云,所有医疗行业来使用,而公安或者政府的就用不了这里的云提供的资源。这就是行业云,也是私有云。
因此,针对某一个行业来部署的云,有地域限制的,例如,浙江省的医疗行业,或者杭州市的医疗行业构建的私有云,那么其它的省市,就用不了。当然也可以全国的医疗行业构建行业云。
如果使用的是私有云+行业云,那么它也是混合云的。
公有云,私有云,行业云,任意两个混合使用,那么就是混合云。
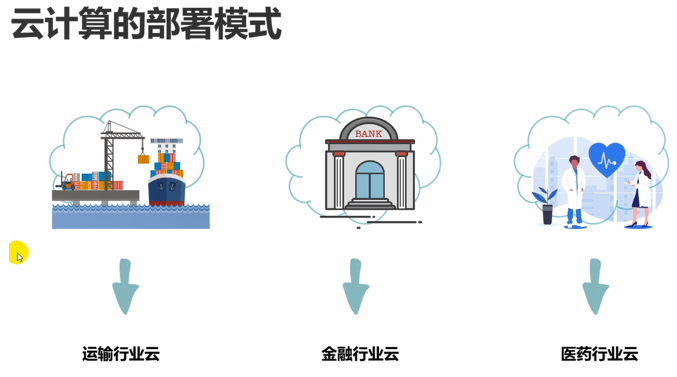
行业云的好处,例如,一个人一家医院看病,然后可能需要转院,那么到达另外一家医院的时候,那么就可以通过行业云调取到我这这家医院看病的病例情况,开的药之类的。
又或者医院内部,拍片可能需要计算之类的,那么就可以到行业云中申请服务器来使用。
对外公众提供服务的,只有公有云。
私有云,行业云,都是对内提供服务的。
现在发展趋势,就是向混合云来发展的。例如,企业,将自己的核心数据,业务,放置在自己的私有云上的。将非核心的内容,例如,测试,展销类的东西,那么就可以部署到公有云上去。
然后将两者整合一起管理,那么就是混合云了。
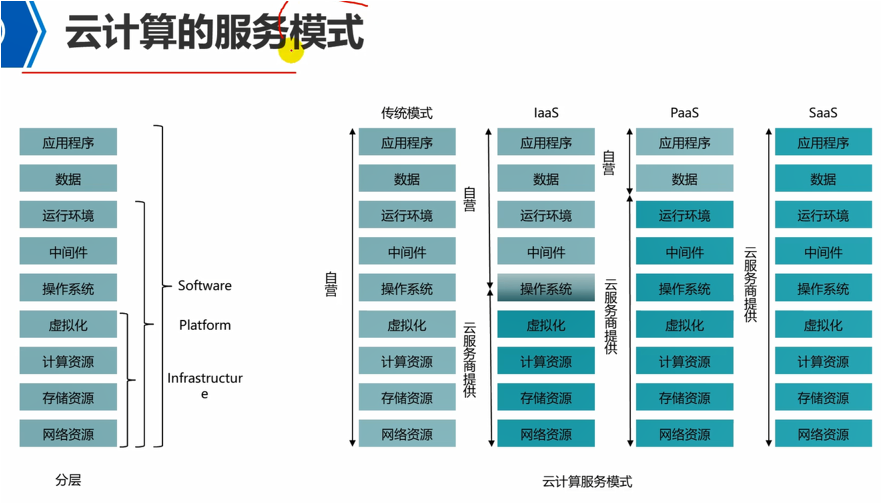
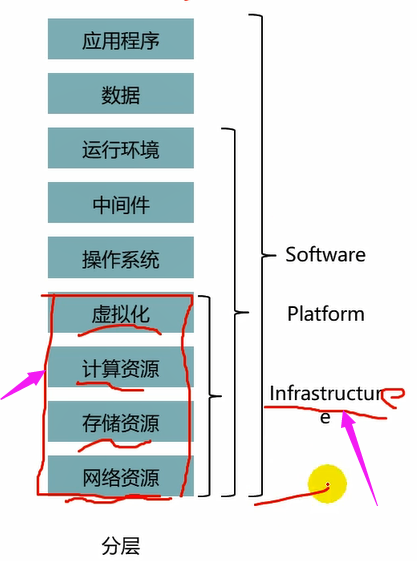
这4个就是基础设施资源。那么就是iaas。
Paas,例如,做java开发,等,都需要部署开发平台的,也就是运行java程序的jvm环境,以及tomcat容器的,或者写c的话,需要安装vs这个IDE,java的话,需要ecplise这样的IDE,还有代码运行可能需要各种库。
那么如果平台将这些都给你提供了,也就是直接给你提供好了一个开发环境了,你开箱即用,直接就可以写代码了,那么这就是paas环境。也就是直接开通一个账号,然后登录上去,直接各种开发工具,环境都有了,无需自己再去部署各种开发工具以及环境了,这就是paas环境。
Saas,就是软件级服务,就是直接将你使用的各种软件都准备好,例如,办公软件之类的应用程序,都给你安装好了,提供好了,那么账号登录进去之后,直接就可以写文字了,这就是saas服务。
因此,saas就是在云端放了这样一个应用程序了,可以在线写文档,Excel之类的,还可以多人同时在线协同编辑一个文档,这就是saas服务。

计算的是资源单位的使用量或者使用时间,例如,8c/12g,使用一年多少钱。
收费使用的是第三方系统的,并不是在云计算系统中的了。
行业云也有叫做社区云。
计算虚拟化简介

云计算不等于虚拟化。实际上没有虚拟化,云计算也可以进行,只是没那么方便了而已。
华为的fc或者openstack底层虚拟化,都是使用的kvm技术。
这里面说的就是服务器虚拟化解决方案。

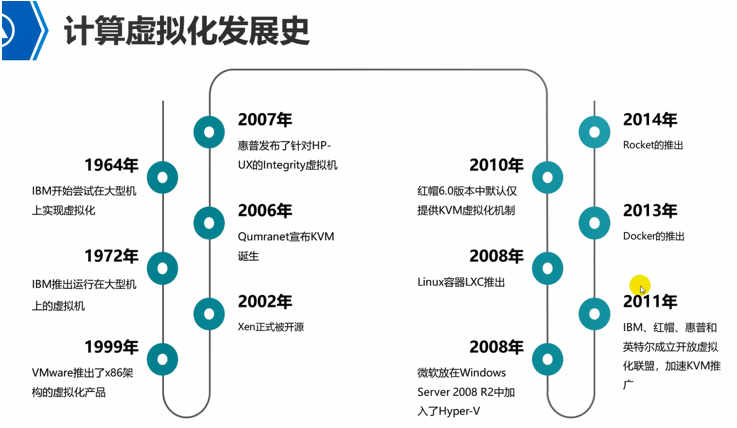
公有云老大aws
私有云老大vmware
国内私有云老大华为私有云。华为的公有云业务出现的比较晚。
国内公有云老大阿里巴巴。09年就开始做公有云了。
Xen最早是剑桥大学搞出来的。后来被思杰Citrix收购了。
Kvm是犹太人一家公司开发出来的。
红帽6.0之前使用的是xen的虚拟化。但是xen后来被Citrix收购了。因此,红帽后来收购了kvm了,因此,6.0之后,虚拟化使用kvm了。
Docker是容器平台。而rocket也是容器的一种,但是它针对的是应用中的那些库组件的容器,不能算是一种容器平台。
01-下午
左边是传统模式。
右边是虚拟化模式。
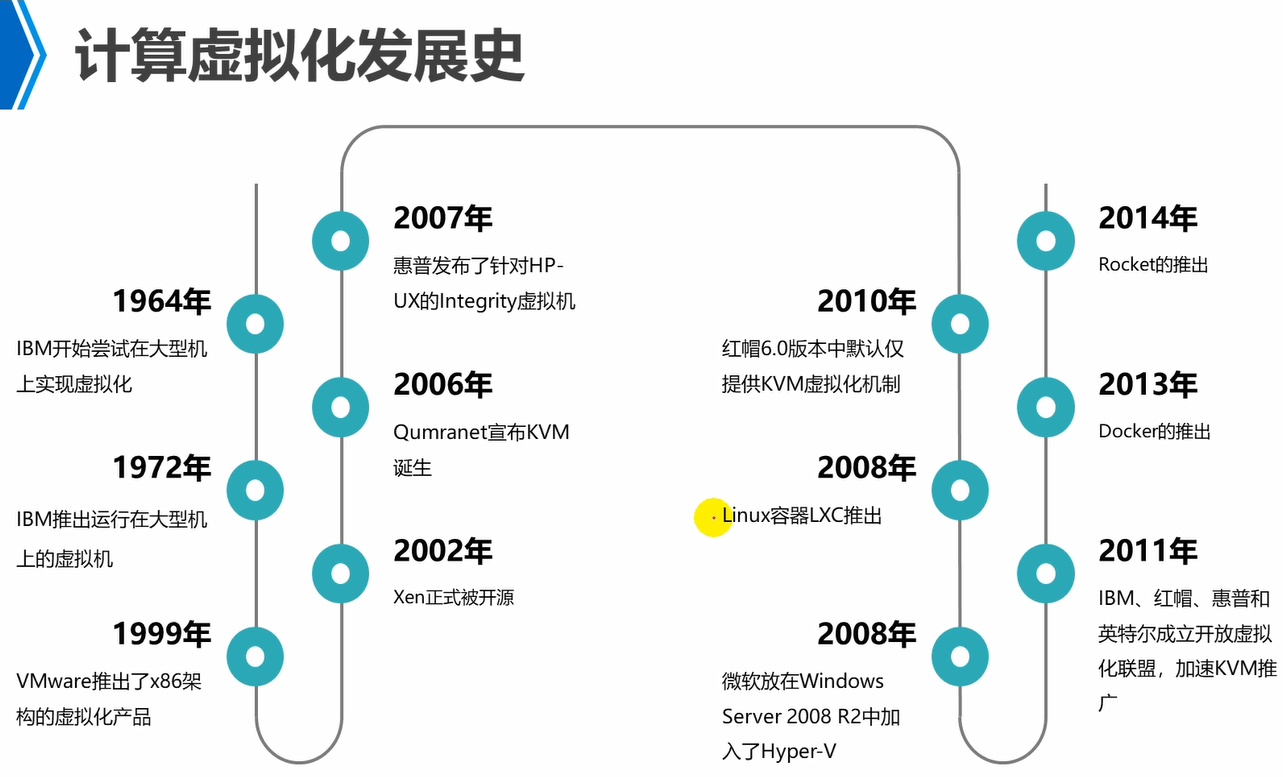
VMM,例如,kvm,xen这些都是VMM。
注意,hypervisor和vmm是一个意思。
hypervisor叫做虚拟化软件层,原因就是将底层硬件部分的cpu,内存,存储,网络等进行了资源池化,分别形成计算资源池,网络资源池,存储资源池,然后对于上层的vm就通过hypervisor来到底层资源池中来拿资源。
因此,虚拟化软件层,就是将底层的物理资源逻辑化形成各种资源池,供上层的vm来使用。
vmm叫做虚拟机监控器,原因是,它是用来监控上面跑的这些vm的资源使用信息的。
因此,对于中间这个层面有两个名称叫做虚拟化软件层(对下)和虚拟机监控器(对上)。而两者是同一个层面提供的功能,例如,kvm或者xen。
目前来看,hypervisor/vmm,例如,kvm或者xen。是基于Linux操作系统的,不能跑在Windows上的。
另外,要注意,一台物理机上,只能运行一种或者一个hypervisor的。例如,一台物理机上已经跑了xen了,那么就不能再跑kvm了。
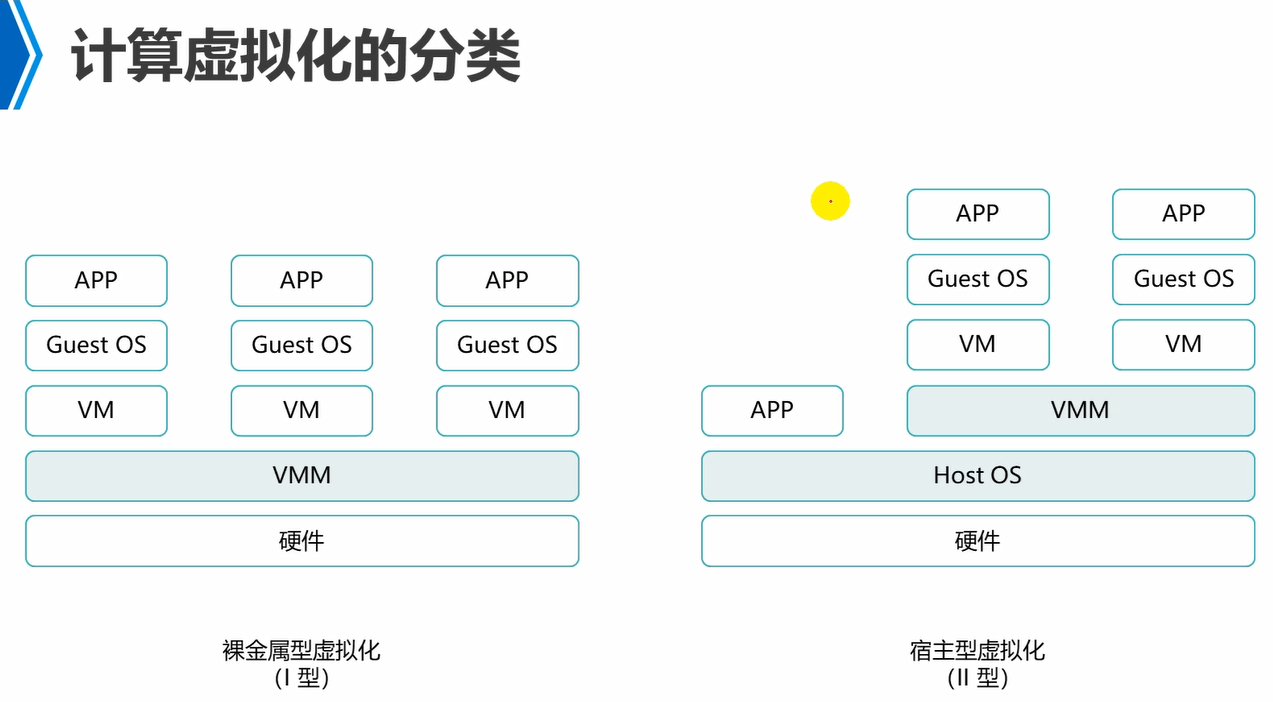
I型虚拟化,就是直接在硬件上面跑hypervisor/vmm,然后再通过hypervisor去部署相应的vm。例如,xen,esxi,都是I型虚拟化。就是将hypervisor/vmm整合到精简的Linux中去了,因此,直接跑在硬件上的hypervisor/vmm,实际上也是Linux,然后Linux中跑的hypervisor/vmm的。
II型虚拟化,例如,VMware workstation,kvm。
III型虚拟化,也就是容器,叫做操作系统级虚拟化。容器是共享同一个操作系统资源的。属于轻量级虚拟化。
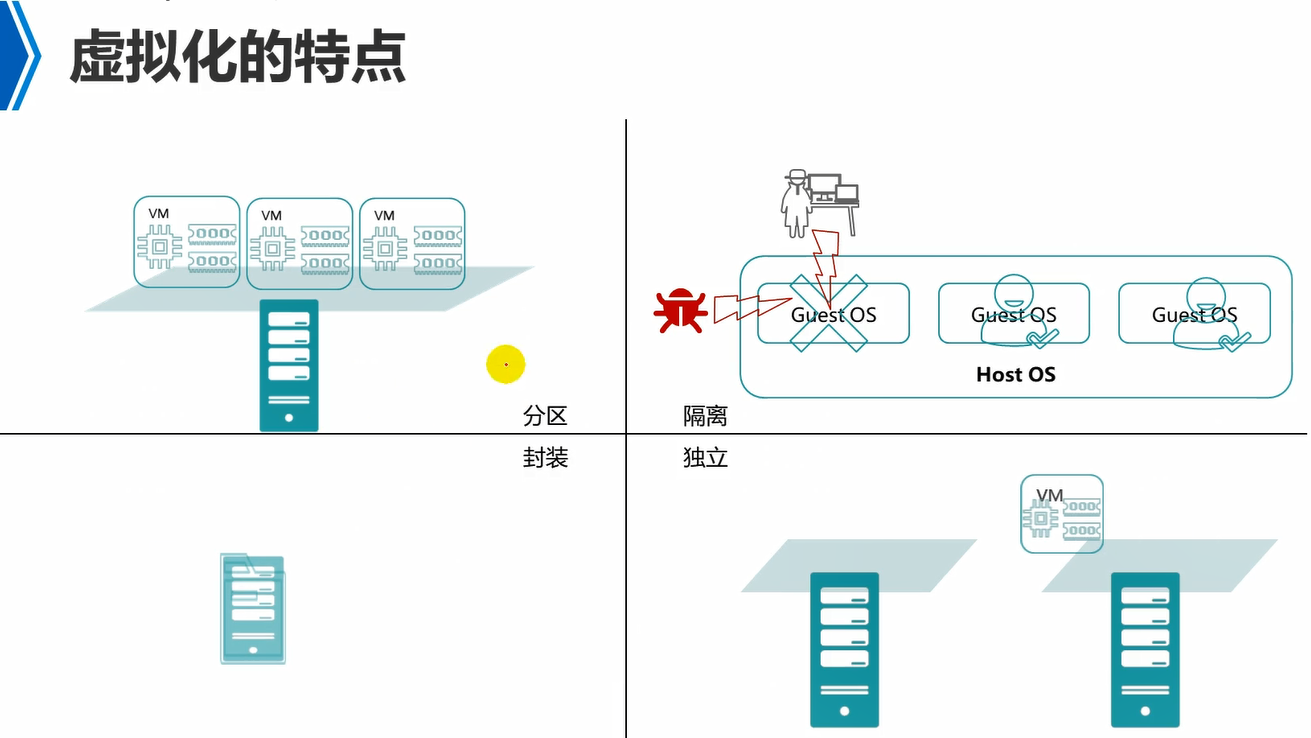
分区,就是将一台物理机的资源逻辑上分成独立的区域,然后,每个区域运行一个vm。例如,cpu,内存,磁盘,都逻辑上分成多份,然后运行的vm可以独占一部分的cpu,内存,磁盘。各个vm彼此隔离。
隔离,就是各个vm彼此独立,互不干扰,例如,一个vm中毒(蠕虫),不会影响到其他的vm。另外就是资源使用隔离,例如,给一个vm分配了指定的资源,那么它就能使用这些资源,不能够占用其他vm的资源。
封装,意思就是说vm在宿主机来看就是一个单独的文件夹。例如,vm的配置信息放在宿主机的一个文件夹中,然后vm使用的磁盘放在另外的宿主机的一个文件夹中。因此,vm实际上在宿主机来看,是封装在一个文件中的。
独立,意思是说相对于硬件独立,例如,传统的应用部署方式,是应用直接部署在宿主机物理操作系统上的,那么该应用和os的版本有对应绑定关系,那么该应用如果迁移到另外一个宿主机上,那么该宿主机需要os系统版本和之前的一样才行。而如果应用部署在vm中,那么vm从一个宿主机上迁移到另外一个宿主机上,那么对于宿主机的os就没有要求了,因为它和应用没有关系,同时和宿主机的硬件也没有关系,不管是Dell的还是hp的机器,都没有关系,只要运行的虚拟化环境是一致即可,例如都是kvm。应用只和vm中的os版本有对应绑定关系。这也叫做软硬件解耦。
vm迁移,例如,两台机器,os版本可能不一致,但是只要都部署了kvm虚拟化环境,那么就可以将一台物理机上vm的配置信息文件夹以及磁盘文件夹等,拷贝到另外一个机器上去即可。
cpu虚拟化
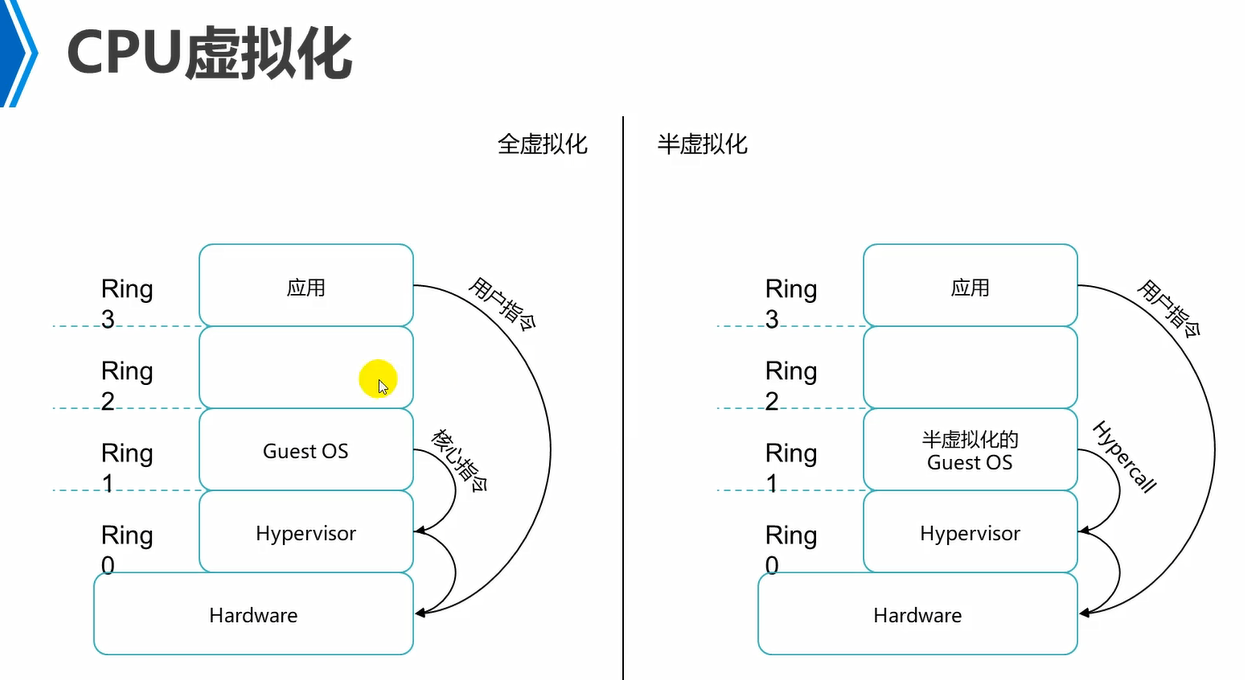
ring,就是对物理硬件的调用权限。
传统模式,hostOS跑在硬件上的,应用跑在hostOS上,hostOS是有ring0权限的,也就是具有最高权限的,能够操作底层硬件的。而应用程序在用户空间,是ring3级别的,ring3权限最低的,不能够直接操纵硬件的,需要借助os来完成的。中间的ring1,ring2就是各种驱动程序所处的级别了。那么应用想要播放是一个视频,那么不能直接去操纵硬件的,需要通过中间的驱动程序去操纵硬件的显卡的。
这种分层的好处就是,各个层之间不影响,例如,应用程序出问题了,可以直接kill掉,而不会影响到os。
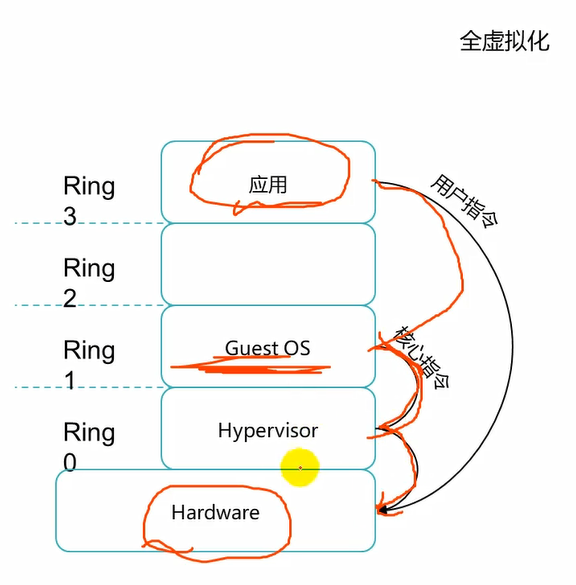
对于全虚拟化来说,guestOS中的应用想要操纵硬件,那么需要将指令发送到guestOS,然后guestOS将其发送给hypervisor,hypervisor处于ring0级别,再去操纵硬件的。
对于全虚拟化来说,vm它自己不知道自己是vm,它会认为自己就是一台真实的物理机,因此,全虚拟化下vm中的应用程序发送的操纵硬件的指令,就是发送到它的内核级,也就是guestOS,然后会发送给hypervisor,因为guestOS中的内核指令集和操纵硬件的指令集有所不同,需要hypervisor进行翻译的操作。
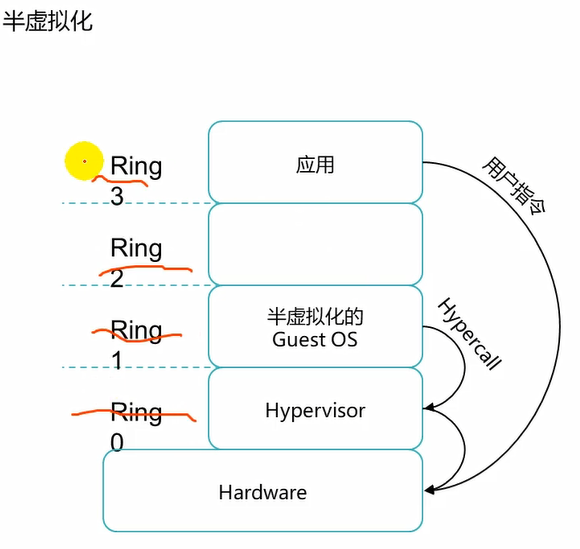
对于半虚拟化来说,半虚拟化中的vm它是知道自己是一台vm的,因此,应用操纵硬件的时候,调用systemCall,而此时的系统调用中的指令集已经是可以直接操纵硬件的指令集了,因此,不需要hypervisor再去翻译了。此时的hypervisor只是负责一个指令的转发,转发去操纵硬件了。
因此,半虚拟化效率更高,因为hypervisor不需要再进行指令的编译转换的操作了。
从这也能够看出半虚拟化的guestOS应该是内核经过改装的了。而全虚拟化的guestOS的内核是不需要做任何改动的。
常规来说,半虚拟化性能高于全虚拟化。但是现在更多使用的是硬件辅助虚拟化了,如下。
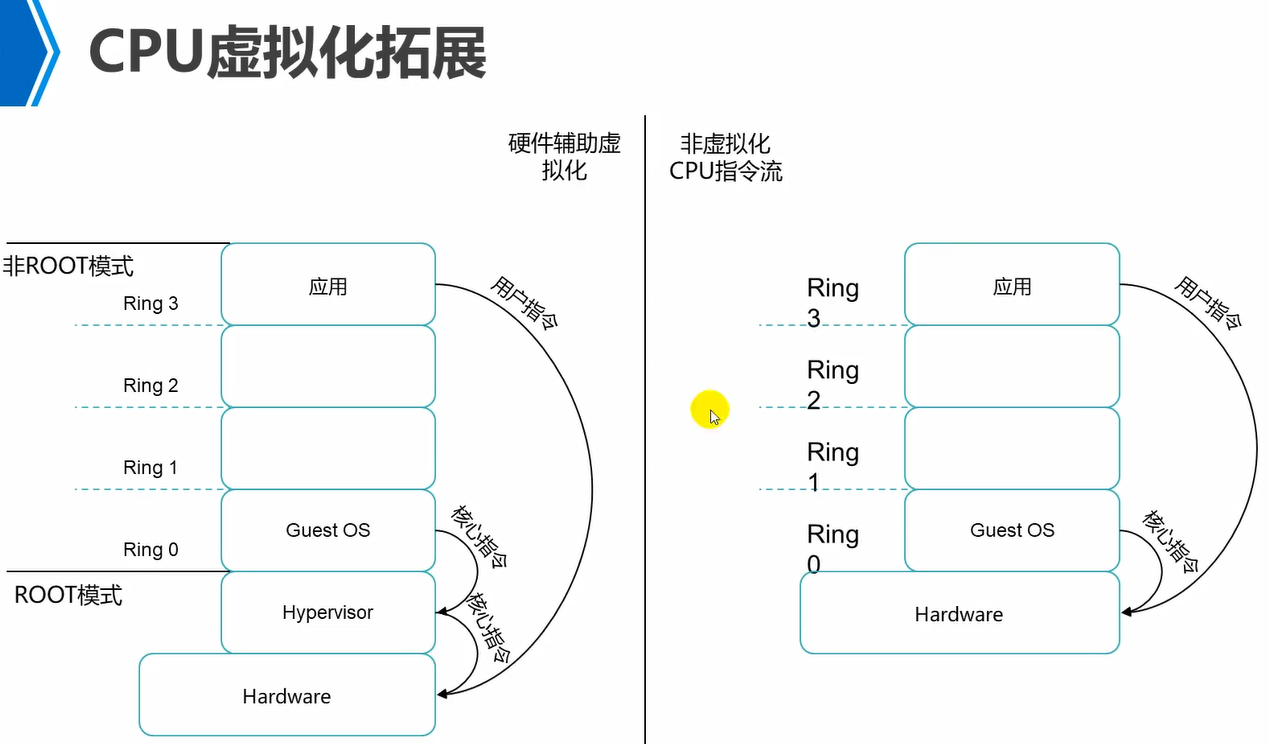
全虚拟化是需要hypervisor去做指令的编译转换工作。而硬件辅助虚拟化,hypervisor不需要再去做指令的编译转换工作了,而是由底层硬件cpu内部指令集直接去转换了,也就是说开启了虚拟化功能之后的硬件cpu,能够直接认识到虚拟化指令了。
因此,现在使用的虚拟化基本都是全虚拟化+硬件辅助虚拟化,这样来使用的。提升性能。
cpu虚拟化和内存虚拟化,都会用到硬件辅助虚拟化,也就是硬件层级就具备解析虚拟化指令的功能了。
图中的应用将指令发送到guestOS,然后guestOS将指令发送到hypervisor,然后hypervisor不做编译转换,直接发送给硬件cpu,通过硬件去解析。
因此,目前现实中使用的就是全虚拟化配合硬件辅助虚拟化来使用。性能和半虚拟化性能一致。同时全虚拟化还支持虚拟化的更高级的功能,因此,相比半虚拟化更广泛的使用。
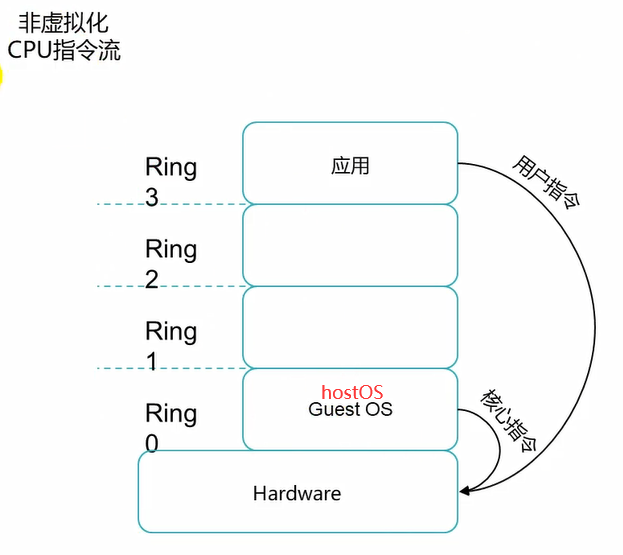
这里是没有虚拟化的情况,应该是hostOS,不是guestOS。
内存虚拟化
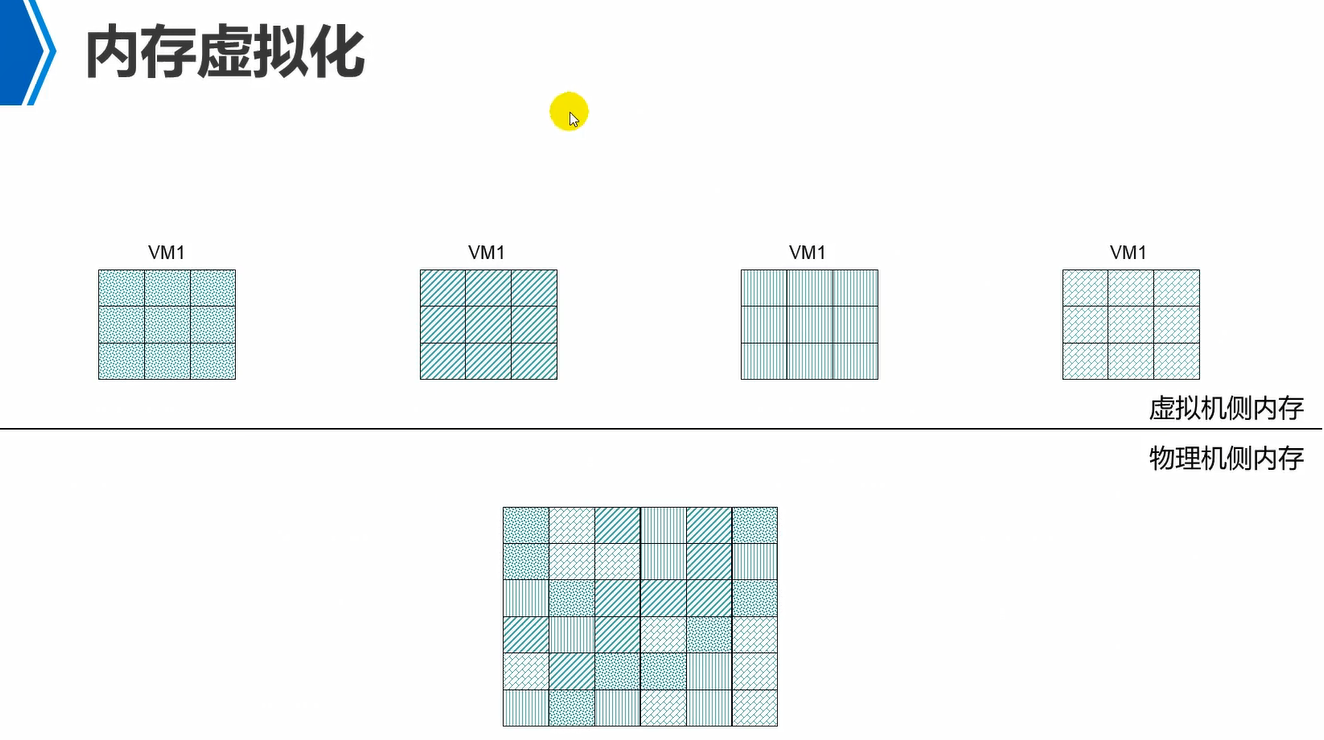
物理内存,需要满足两个条件,1、连续的地址空间,2、知道内存的起始点,例如从地址0000开始读。这就是物理内存能够使用的条件。
如图,虚拟机层面来看,vm的内存都是满足这两个条件的,但是在物理内存上来看,分出去的内存不一定连续的。因此,中间是有vm内存到物理内存的地址映射关系。
因此,vm角度来看,内存都是连续的并且有起始地址的,但是映射到物理内存上来看,内存不一定连续,同时起始地址也不一定是从0000开始的。
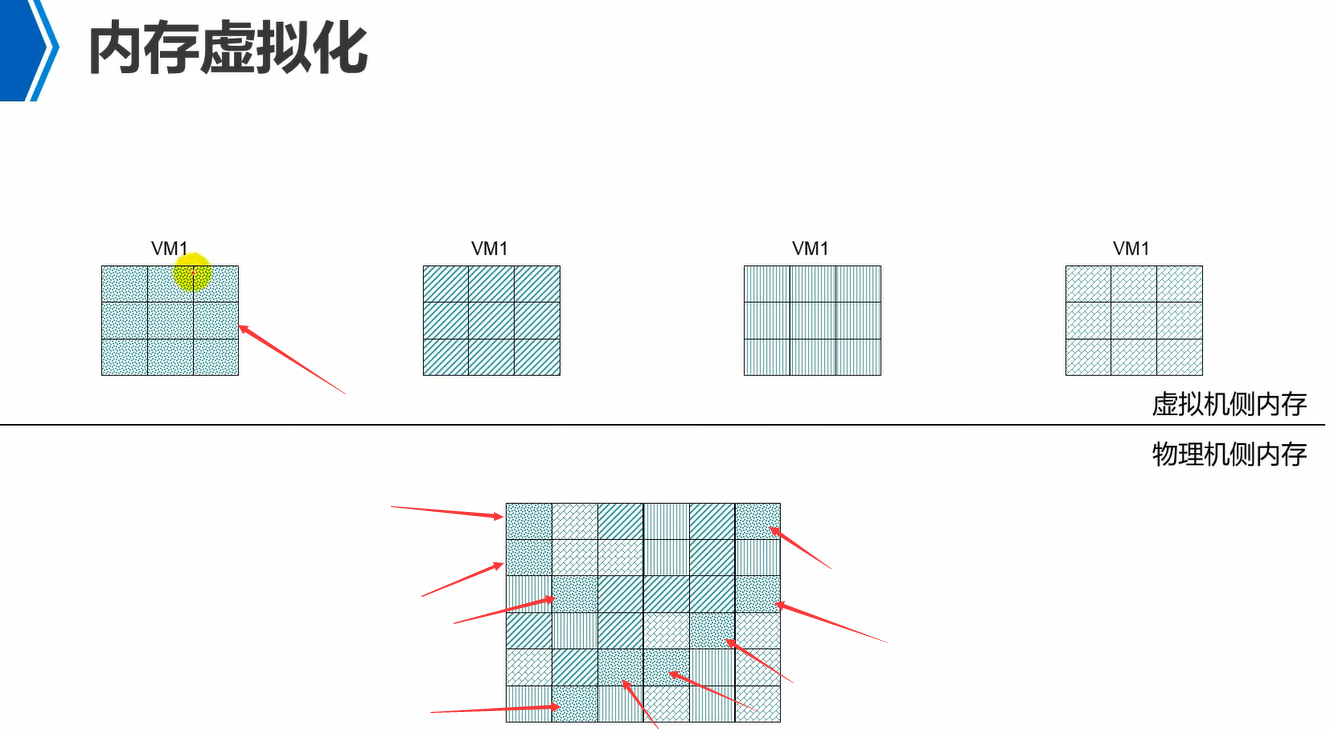
因此,内存虚拟化,就是通过逻辑映射,将物理上地址不连续的空间,映射到虚拟机上地址连续的空间。
io虚拟化

io虚拟化分为如上3种。
模拟,就是io设备完全由程序去模拟了。例如,有3个vm,那么不可能有3套键盘鼠标的,因此,通过软件模拟,然后点击到了哪个vm,哪个vm内部的这个软件程序就捕捉到了这个信号,然后信号传入到vm,通过程序去模拟这个键盘鼠标的功能。完全通过软件程序去模拟硬件,性能很差。
半虚拟化,就是vm中有前端驱动程序,然后要操作某个硬件,就将信号发送给宿主机上的hypervisor中的后端驱动程序,然后通过后端驱动去直接调用底层硬件。通常只适用于硬盘和网卡。
IO透传,性能最好,直接将物理设备分配给vm了。需要硬件具备IO透传功能才行。例如,直接将网卡分配给vm,那么这个vm的流量就直接透传给物理网卡了,而不会再发送给vm中的虚拟网卡了。又例如GPU,将物理的GPU直接分配给vm,这样vm进行图形渲染功能操作就流畅了。
透传也叫做直通技术。例如,有cpu直通,网卡直通,硬盘直通等。
硬件需要具备IO透传功能,能够直接被vm去调度的。
模拟性能最差。
半虚拟化性能居中。
IO透传性能最好。
以上就是计算虚拟化的3部分,cpu虚拟化,内存虚拟化,IO虚拟化。
云计算和虚拟化
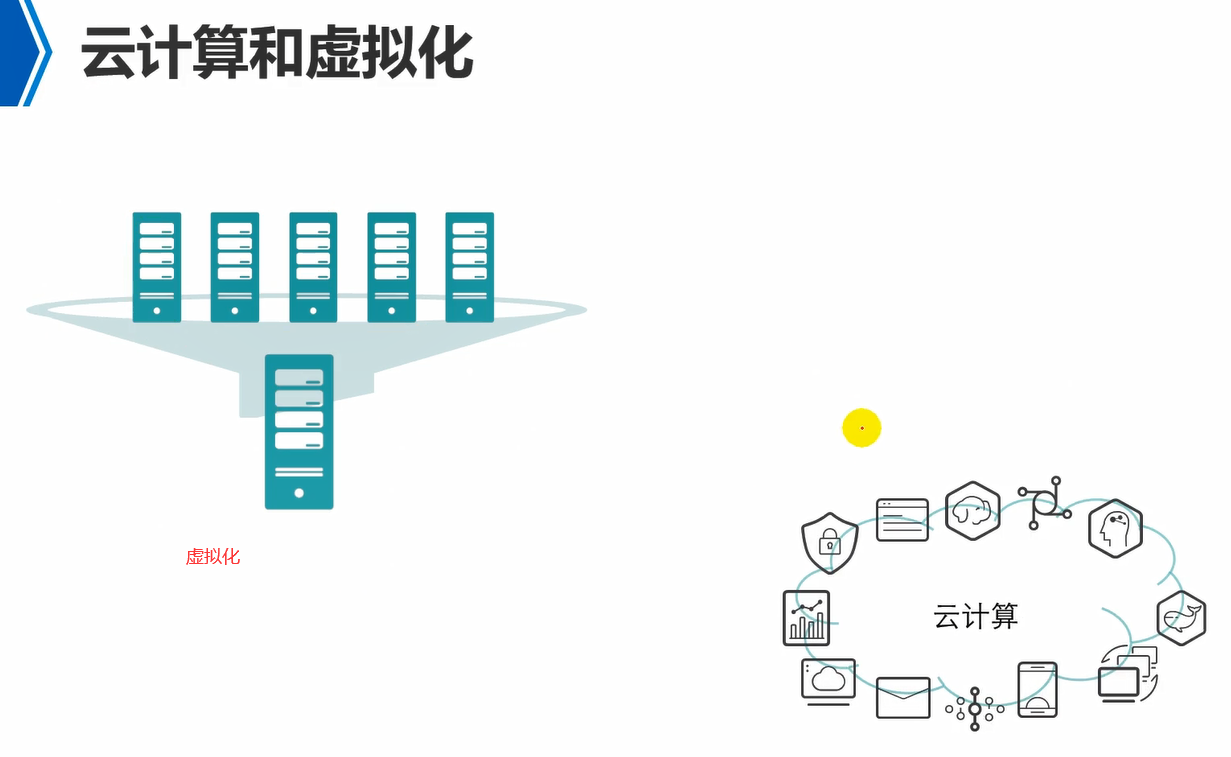
虚拟化提升了单台计算机的资源使用率。
云计算,虚拟化只是云计算中的一个核心技术。云计算还涉及到分布式计算,分布式存储等。
注意,云计算是一种架构,而不是一种技术。
云计算,是整合了资源(计算,存储,网络),对所有资源进行统一管理和调度,并向外提供各种服务,例如,可以提供平台级服务,资源级服务,应用级服务,等。
Daas,桌面云服务。
SaaS
PaaS
Iaas
主流计算虚拟化技术
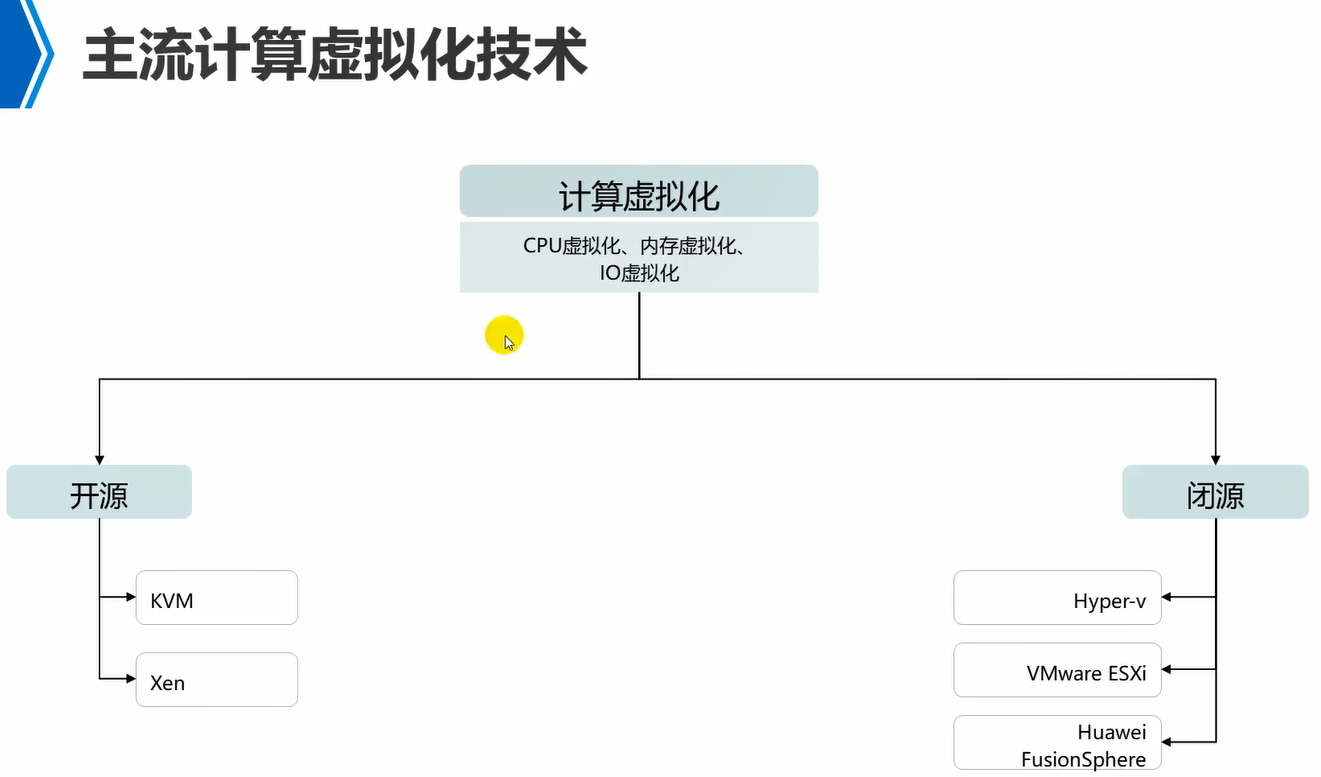
kvm,xen,都认为是I型虚拟化。
VMware workstation,是II型虚拟化。
注意,华为的fusionsphere是基于kvm的,做了二次开发的,然后闭源的。
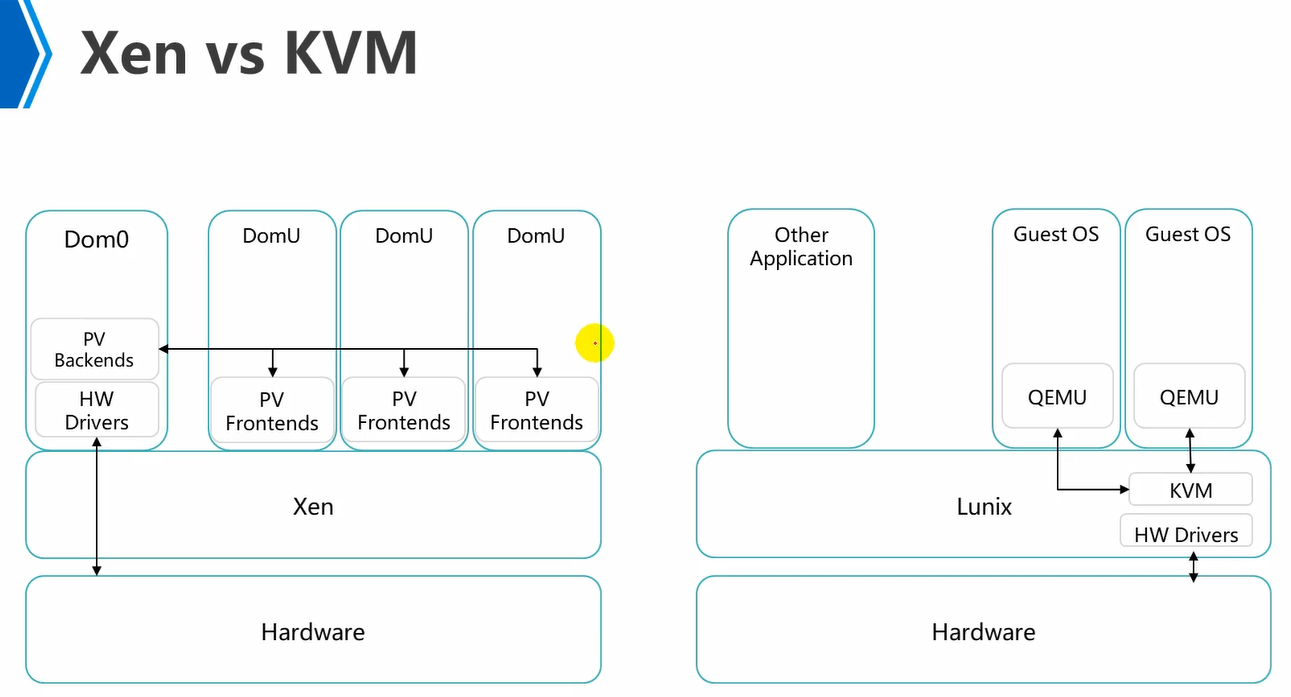
xen是直接跑在硬件上面的,它是将Linux内核进行了修改精简,整合了xen这个hypervisor软件了。即xen是xen公司自行开发的系统。
xen属于半虚拟化。
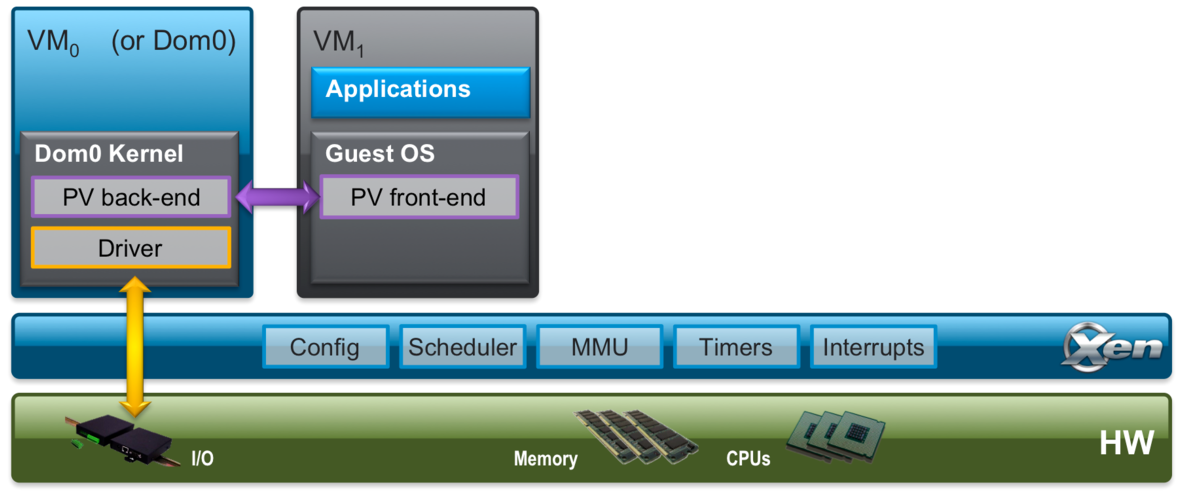
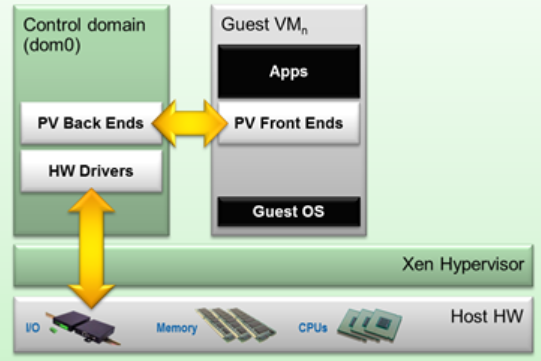
PV(Paravirtualization)就是驱动程序。
domU是普通虚拟机vm,普通vm中存在着前端驱动。
dom0是特权虚拟机vm。
domU如果对物理硬件有访问需求,那么就将指令发送到前端驱动,然后将其发送到特权虚拟机中的后端驱动,然后再将其发送到特权虚拟机dom0中的硬件驱动,通过硬件驱动去调度底层硬件,进行操作。
dom0特权vm,1、可以调用底层硬件,直接去操作硬件。2、可以对普通vm,即domU的生命周期管理,即普通vm的创建到删除,都是dom0来管的。
因此,在xen架构上,一定是dom0先启动,之后domU才能启动,因为domU的启动是需要通过dom0来控制的。
华为之前底层用的就是左边的xen架构,2018年之后,就使用kvm架构了。
kvm就是在标准Linux系统中注入一个kvm内核模块,这个kvm内核模块会替换Linux内核中本身的一些内容,然后该Linux系统就可以提供相应的hypervisor功能。
kvm调度底层硬件是通过全虚拟化+硬件辅助虚拟化实现的。注意,它不是半虚拟化的。对于关键资源,例如,cpu,内存,如果使用全虚拟化,性能太差,因此,都是使用硬件辅助虚拟化的。cpu硬件辅助虚拟化,Intel叫做vt-x,amd叫做amd-v。对于键盘鼠标,这些,可以使用全虚拟化去模拟,即通过程序软件qemu去模拟的,例如,模拟网卡,模拟键盘,模拟鼠标,等设备。
另外kvm中对于硬件的操作就是在Linux内核中的硬件驱动了。
Paravirtualization (PV) is an efficient and lightweight virtualization technique introduced by the Xen Project team, later adopted by other virtualization solutions. PV does not require virtualization extensions from the host CPU and thus enables virtualization on hardware architectures that do not support Hardware-assisted virtualization. However, PV guests and control domains require kernel support and drivers that in the past required special kernel builds, but are now part of the Linux kernel as well as other operating systems.
半虚拟化(PV)是由 Xen 项目团队引入的一种高效且轻量级的虚拟化技术,后来被其他虚拟化解决方案所采用。PV 不需要来自主机 CPU 的虚拟化扩展,因此可以在不支持硬件辅助虚拟化的硬件架构上进行虚拟化。然而,PV 来宾和控制域需要内核支持和驱动程序,过去这些需要特殊的内核构建,但现在已经成为 Linux 内核和其他操作系统的一部分。
Paravirtualization implements the following functionality
半虚拟化实现以下功能
Disk and Network drivers 磁盘和网络驱动程序
Interrupts and timers 中断和计时器
Emulated Motherboard and Legacy Boot 仿真主板和遗留引导
Privileged Instructions and 特权指示及Page Tables 页表
Xen虚拟化技术中PV和HVM的区别
Xen是一个开源的type-1或者裸机管理程序,它使得一个物理主机能够同时并行运行多个相同的或者不同的操作系统实例。Xen是目前唯一的开源可得的type-1管理程序。Xen被应用于许多商业和开源的应用程序中,比如:服务器虚拟化(server virtualization)、基础设施即服务(Infrastructure as a Service)、桌面虚拟化(desktop virtualization)、安全应用程序(security applications)、嵌入式和硬件设备(embedded and hardware appliances)。毫无疑问,Xen驱动着当今大部分的云计算市场。
Xen支持运行两种不同类型的虚拟机:半虚拟化(PV)和全虚拟化(HVM)。在一个单一的Xen系统中可以同时运行这两种不同类型的虚拟机。另外,在全虚拟化(HVM)虚拟机中也能够使用半虚拟化(PV)技术:实质上是创建一个半虚拟化(PV)和全虚拟化(HVM)的连续体。这种方式被称为PV on HVM。想要获取更多关于虚拟化的知识可以看这里
那么Xen虚拟化技术中的半虚拟化(PV)和全虚拟化(HVM)有什么区别呢?
Xen Paravirtualization (PV)
半虚拟化是由Xen引入的高效和轻量的虚拟化技术,随后被其他虚拟化平台采用。半虚拟化技术不需要物理机CPU含有虚拟化扩展。但是,要使虚拟机能够高效的运行在没有仿真或者虚拟仿真的硬件上,半虚拟化技术需要一个Xen-PV-enabled内核和PV驱动。可喜的是,Linux、NetBSD、FreeBSD和OpenSolaris都提供了Xen-PV-enabled内核。Linux内核从2.6.24版本起就使用了Linux pvops框架来支持Xen。这意味着半虚拟化技术可以在绝大多数的Liunx发行版上工作(除了那么内核很古老的发行版)。关于半虚拟化技术的更多信息可以看这里)
Xen Full Virtualization (HVM)
全虚拟化或者叫硬件协助的虚拟化技术使用物理机CPU的虚拟化扩展来虚拟出虚拟机。全虚拟化技术需要Intel VT或者AMD-V硬件扩展。Xen使用Qemu来仿真PC硬件,包括BIOS、IDE硬盘控制器、VGA图形适配器(显卡)、USB控制器、网络适配器(网卡)等。虚拟机硬件扩展被用来提高仿真的性能。全虚拟化虚拟机不需要任何的内核支持。这意味着,Windows操作系统可以作为Xen的全虚拟化虚拟机使用(众所周知,除了微软没有谁可以修改Windows内核)。由于使用了仿真技术,通常来说全虚拟化虚拟机运行效果要逊于半虚拟化虚拟机。
PV on HVM
为了提高性能,全虚拟化虚拟机也可以使用一些特殊的半虚拟化设备驱动(PVHVM 或者 PV-on-HVM驱动)。这些半虚拟化驱动针对全虚拟化环境进行了优化并对磁盘和网络IO仿真进行分流,从而得到一个类似于或优于半虚拟化虚拟机性能的全虚拟化虚拟机。这意味着,你可以对只支持全虚拟化技术的操作系统进行优化,比如Windows。
Xen半虚拟化虚拟机自动使用PV驱动-因此不需要提供这些驱动,你已经在使用这些优化过的驱动了。另外,只有Xen全虚拟化虚拟机才需要PVHVM驱动。关于PV on HVM的更多信息可以看这里
PV in an HVM Container (PVH) - New in Xen 4.4
Xen 4.4会带来一个被称作PVH的新的虚拟化模式。实质上,它是一个使用了针对启动和I/O的半虚拟化驱动的半虚拟化模式。与全虚拟化不同的是,它使用了硬件虚拟化扩展,但是不需要进行仿真。在Xen 4.3发布后,xen-unstable会加入对此模式的补丁,Xen 4.4中将可以预览到这个功能。PVH拥有结合和权衡所以虚拟化模式优点的潜力,与此同时简化Xen的架构。
Xen虚拟化技术中PV和HVM的区别 - cgj - 博客园 (cnblogs.com)

kvm简介
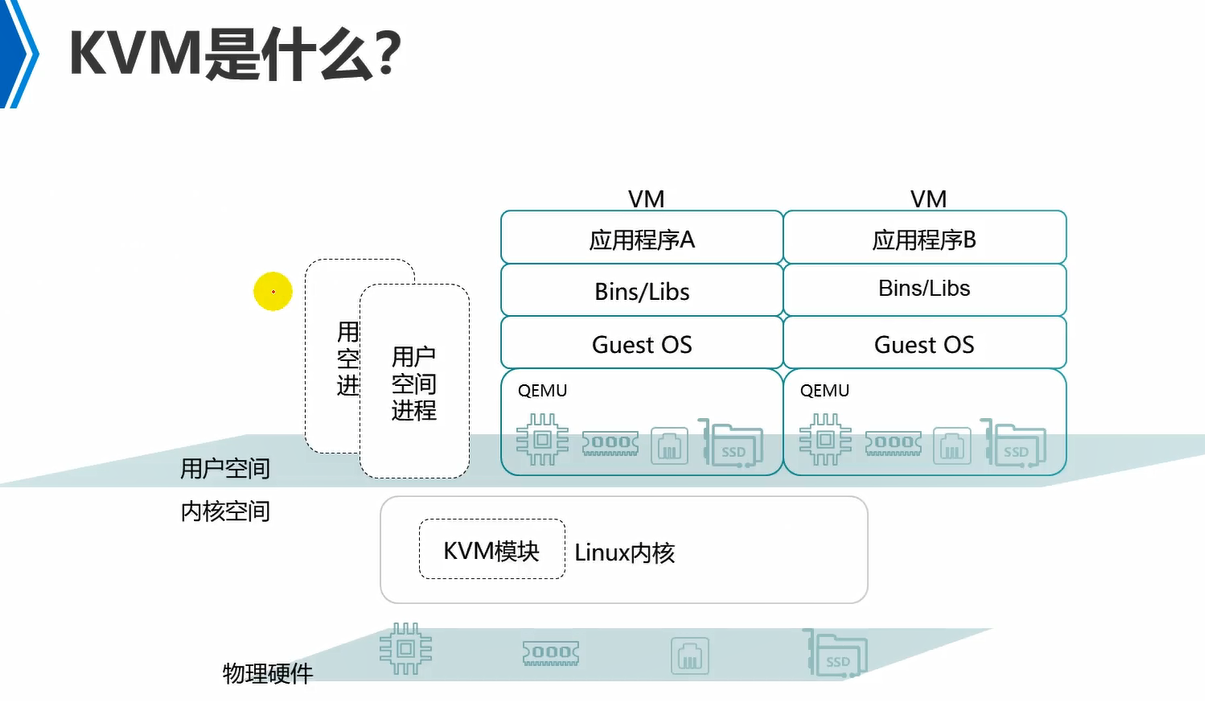
kvm就是在Linux内核中添加了一个kvm内核模块。这个kvm内核模块功能就是将普通的Linux操作系统内核给你替换成或者说更改成可以支持虚拟化功能,具备hypervisor能力的Linux内核系统。
内核模式,内核模式下对底层硬件有绝对的控制权,有操作硬件的所有指令集。
用户模式,要操作底层硬件,需要通过内核模式进行。
guest模式,即vm中。
kvm(kernel virtualization mode)
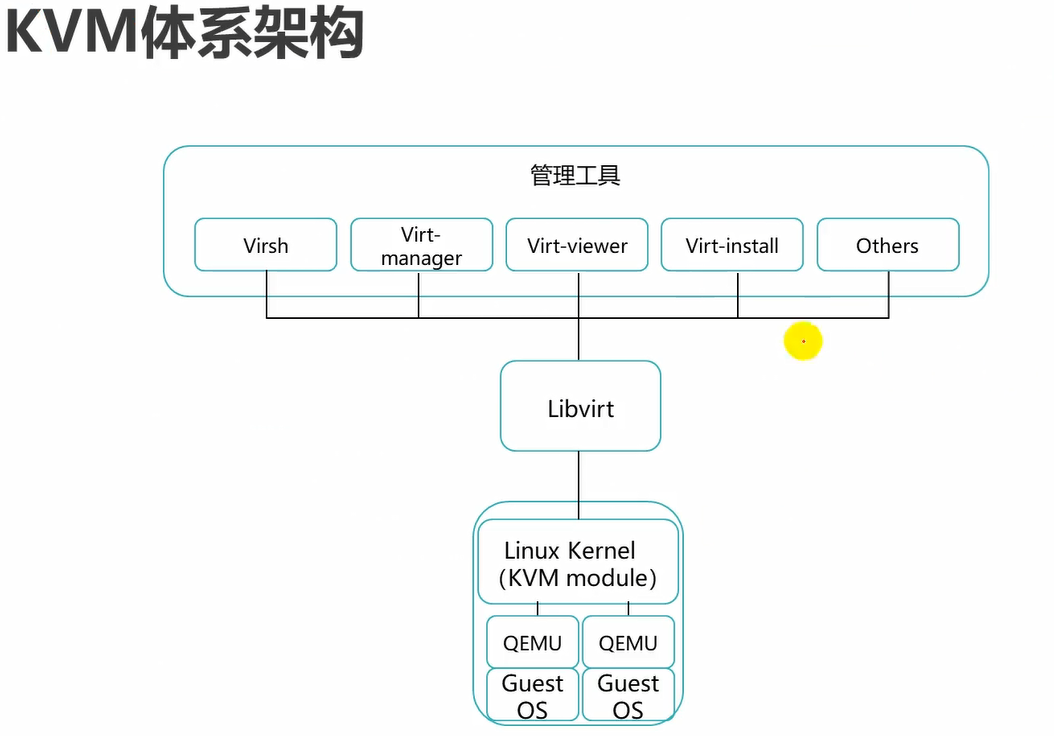
qemu,io,键盘,鼠标,这些通过它来模拟。而cpu和内存不会通过它模拟,性能差。
cpu和内存,通过硬件辅助虚拟化来实现。
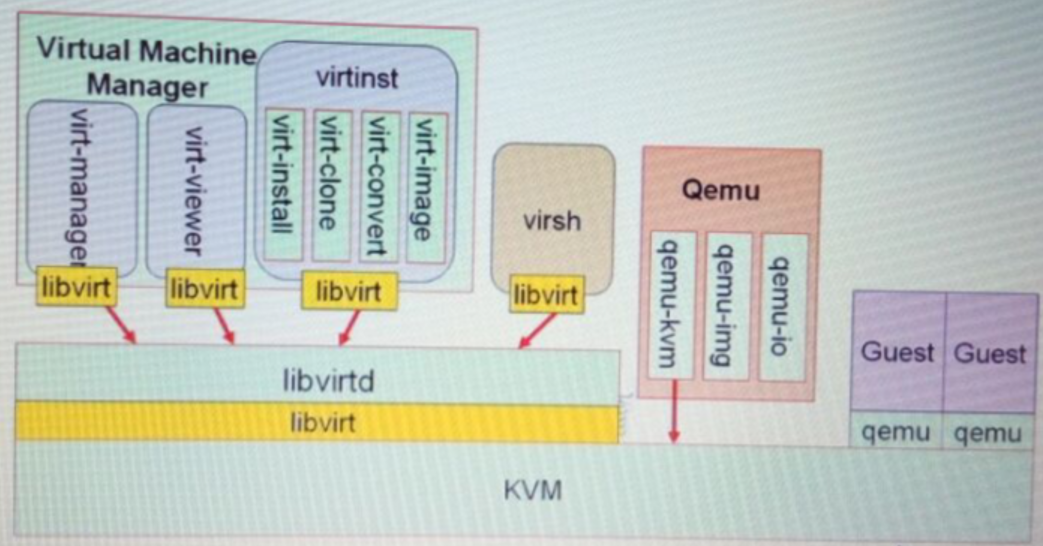
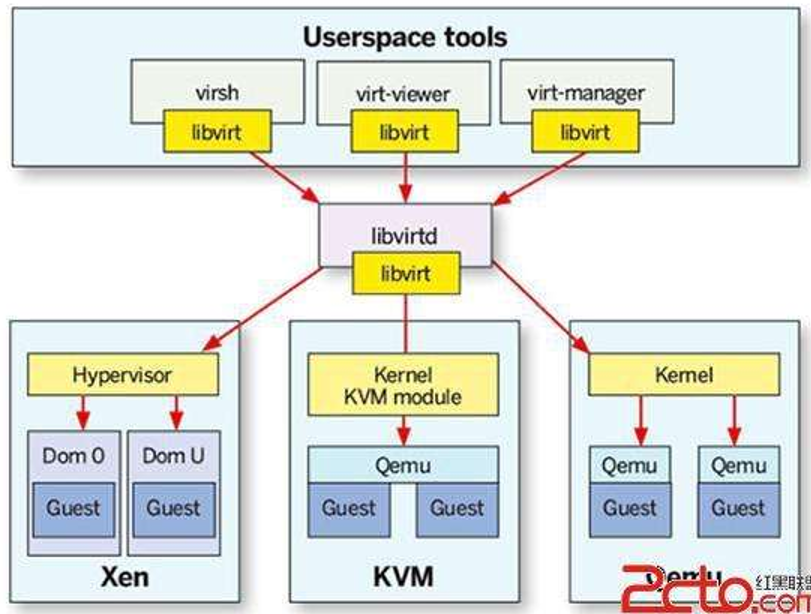
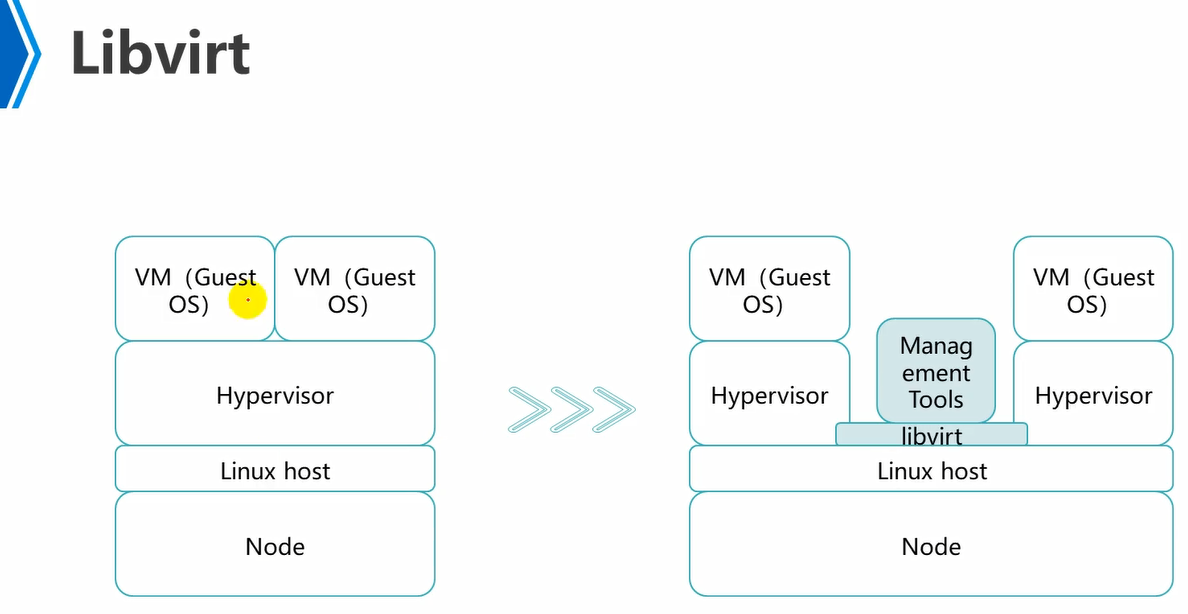
可以看到libvirt链接了hostOS,hypervisor,management tools。
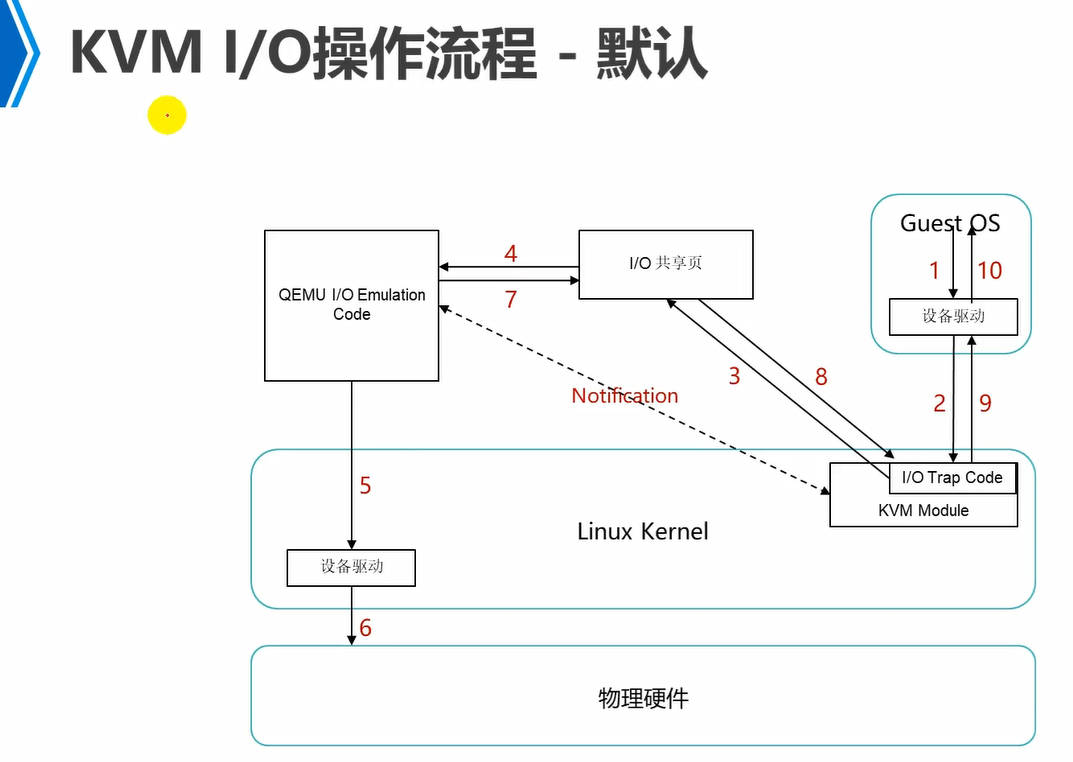
1下面的设备驱动是vm中模拟出来的虚拟设备驱动。
trap是陷阱,捕获的意思。
因此,1的虚拟设备驱动将信息发送给kvm模块,kvm模块中的IO trap code代码就能够捕获到这个信息。
qemu IO emulation code会从IO共享页拿到信息,qemu IO emulation code主要用来模拟各种硬件的。然后将信息发送给OS内核中的真实物理硬件驱动上来操作各种硬件,即5。
注意,例如,3,IO trap code将信息放到IO共享页之后,就会notification通知qemu IO emulation code,告诉它让它去IO共享页上来拿信息。消息通知模型。
同理qemu IO emulation code根据guestOS访问的内容,例如是鼠标,那么它就会根据OS物理设备驱动,然后去模拟出鼠标硬件,然后将信息放回到IO共享页,然后它也会通知notification kvm内核模块,告诉IO trap code过来IO共享页上来取。
因此,如图,qemu IO emulation code就是用来模拟各种物理硬件的。而真实去操作各种物理硬件还是需要去调用底层OS上的硬件设备驱动来完成的。
1,guestOS要访问硬件,因此,将信息发送给自己的虚拟设备驱动上。
2,虚拟设备驱动将这个访问消息发送给kvm中,kvm中的IO trap code捕获这个消息。
3,IO trap code将这个访问消息发送到IO共享页上。然后notification通知qemu IO emulation code到IO共享页上来取。
4,qemu IO emulation code已经模拟了各种硬件,然后它会到IO共享页上取到要访问哪个硬件的消息。然后根据自己模拟的硬件,将这个消息发送给底层OS的真实硬件设备驱动。
5,真实物理设备硬件驱动接收到这个消息,调用操作底层物理硬件。
然后信息依次返回。
上述是默认流程,性能比较差。
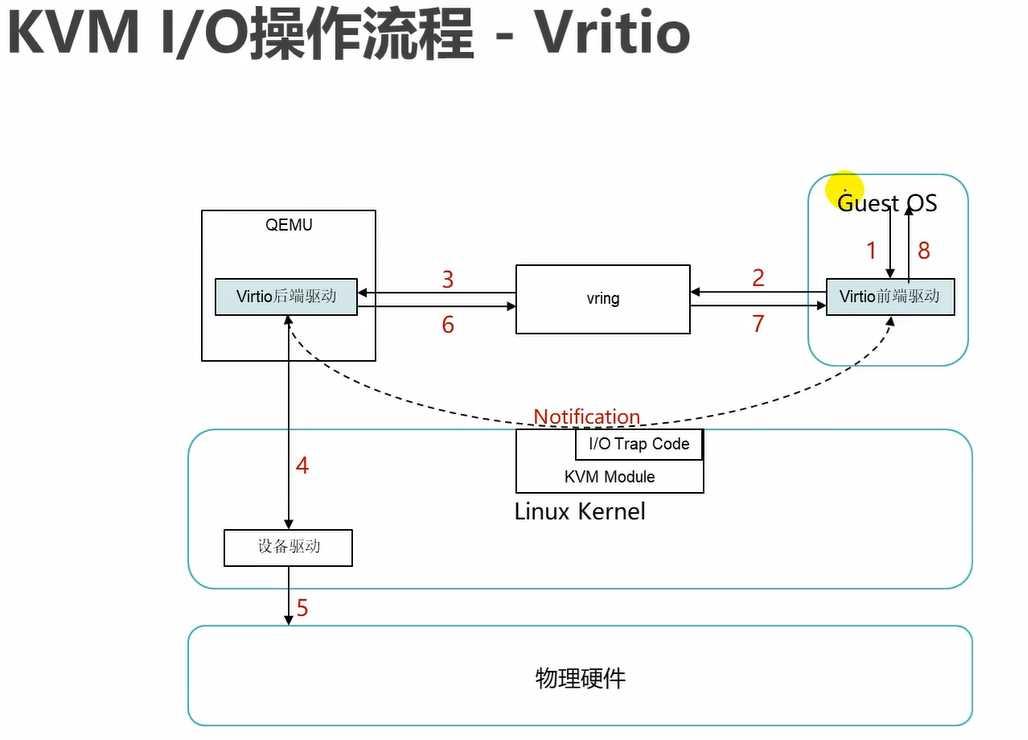
这种就是优化之后的性能比较高的流程。即通过半虚拟化驱动来完成。
可以看到virtIO,不需要通过kvm模块中的IO trap code来传递信息了,而是通过自己的前端驱动和后端驱动进行沟通了。
这里virtIO前端驱动将信息发送到vring,但是此时qemu上的virtIO后端驱动还不知道,因此,需要通过kvm模块来传递通知notification,告诉virtIO后端驱动,信息已经放到Vring上了,过来到vring上取。
反之也是同理,virtIO后端驱动将返回的信息放到vring队列上之后,virtIO前端启动也不知道,因此,需要通过kvm模块来传递通知notification。
vring,队列。
这种模式,可以看到,此时guestOS发送的指令是通过virtIO的前端驱动和virtIO的后端驱动进行交流了,而kvm模块仅做消息通知功能,不进行传递指令信息功能。因此,性能显著提升,很强了。
virtIO方式可以看到步骤较之前默认方式少了2步,性能提升。
前面使用默认模式去模拟网卡,那么网卡只能达到百兆的性能。
而这里使用virtIO模式,那么网卡可以模拟出万兆的性能。
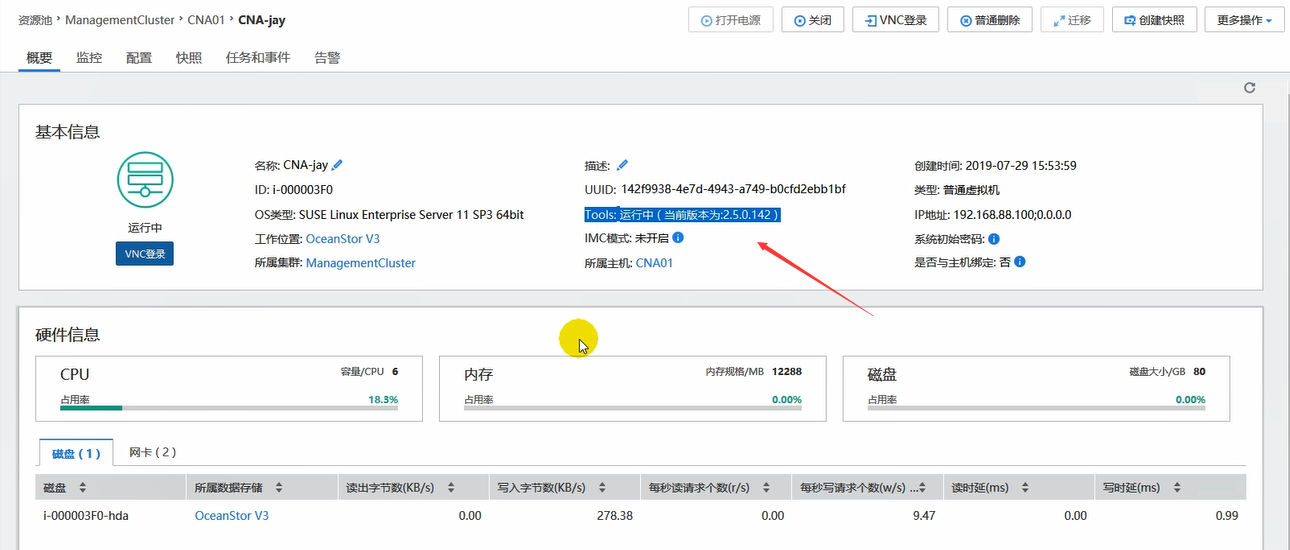
FusionCompute简介

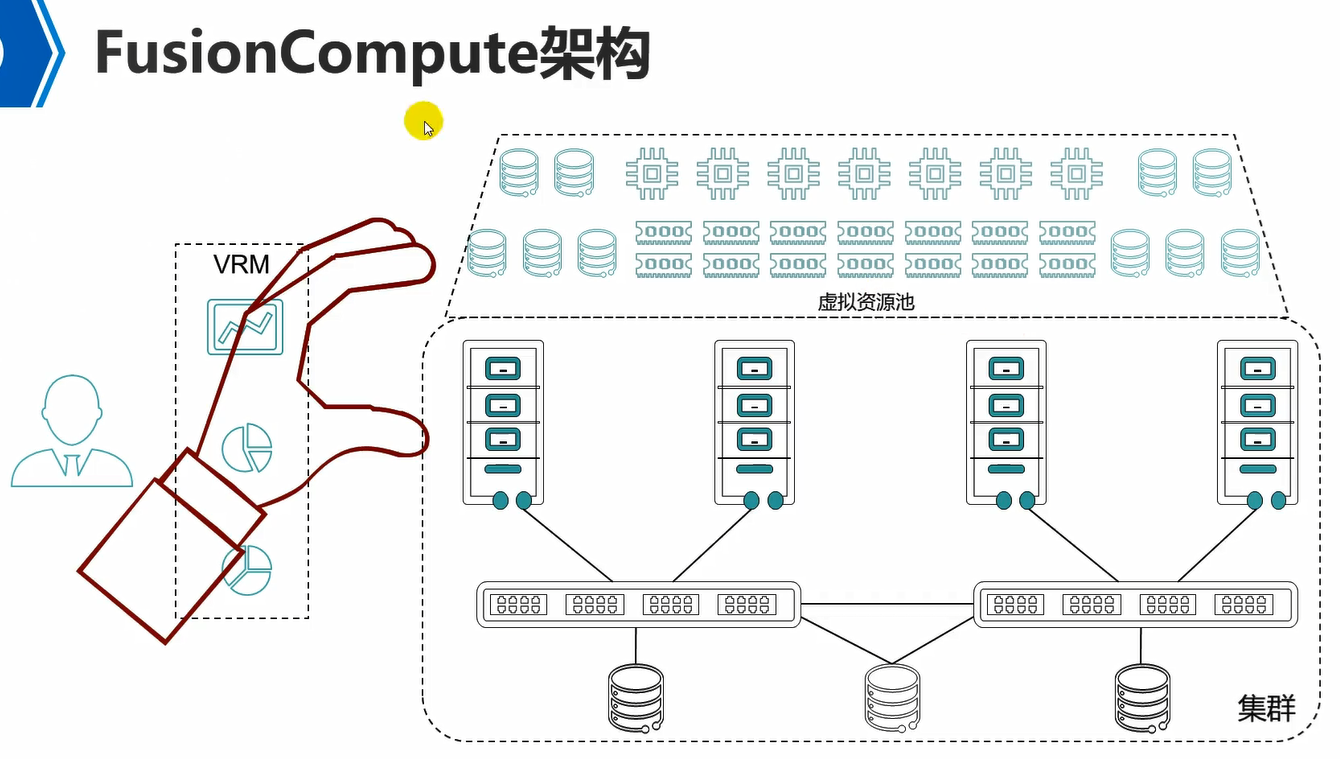
FusionCompute是华为下的服务器虚拟化架构。
图中集群中的是一台台的物理服务器,然后下面接交换机,交换机下面接的就是存储了。
然后每个物理服务器上安装OS和kvm,让单台物理机服务器具备虚拟化功能。
然后所有物理服务器上的所有资源,会形成一个虚拟资源池,里面有计算资源池,存储资源池,网络资源池。
此时创建vm就是从虚拟资源池中来拿,例如,创建4c/8g/500g的vm,那么就从计算资源池中拿4c,8g,然后从存储资源池中拿500g。
然后这些vm如何去管理呢?通过华为专用的管理工具VRM。它可以统一管理所有物理服务器,同时也可以管理各个服务器上运行的各个vm。可以通过VRM进行创建,删除,迁移虚拟机。
因此,本质就是在物理服务器上安装kvm虚拟化操作系统,让它变成一个CNA(计算节点代理)。
VRM(virtualization resource manager),虚拟资源管理。
CNA(compute node agent),计算节点代理。
因此,部署FusionCompute,实际上就是部署CNA和VRM。一台物理服务器就是一个CNA。
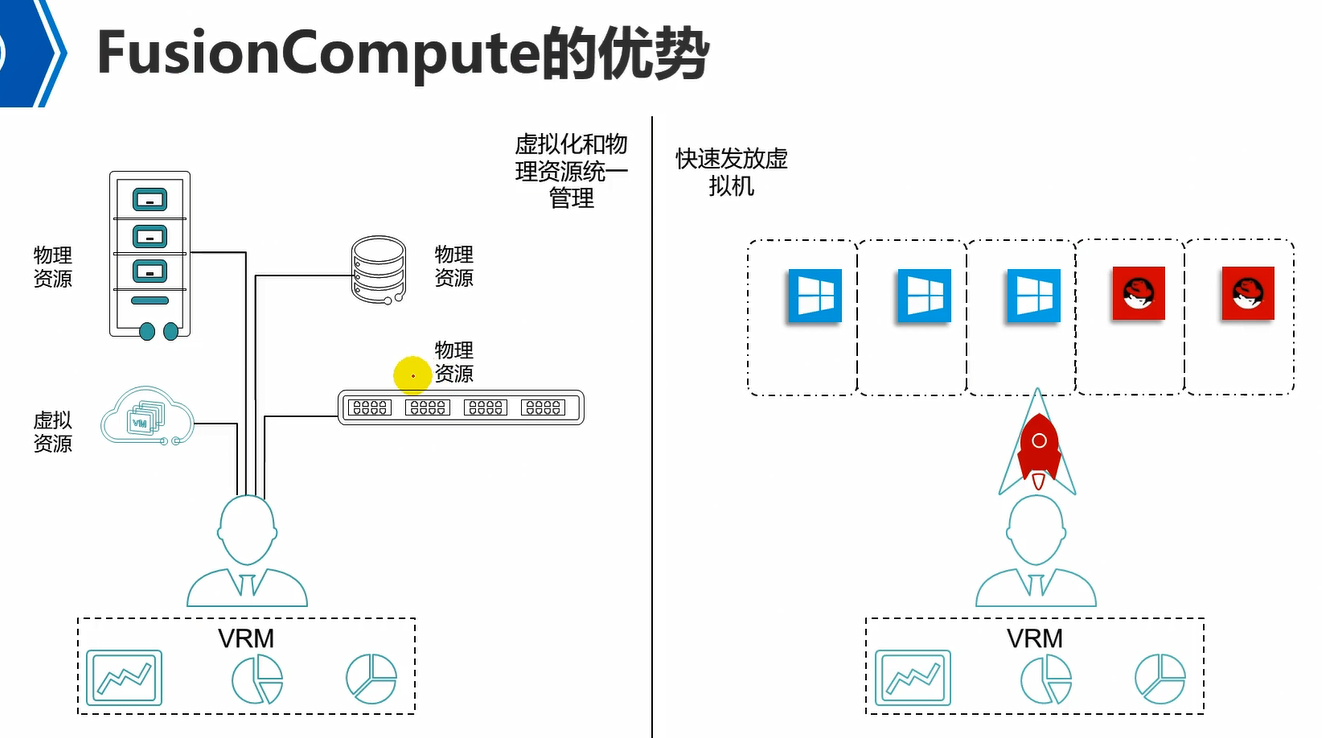
可以看到,FusionCompute的优势,通过VRM可以管理所有的物理资源和虚拟资源,统一管理。
例如,VRM可以管理物理服务器的开关机,通过VRM去对接服务器的BMC口,去管理物理服务器的硬件内容,远程控制物理服务器的开关机。
VRM还可以管理物理交换机路由器,物理的存储设备,等。
VRM直观感受就是一个web页面,在这个页面上有不同入口,可以管理物理资源,虚拟资源。
上述是第一个优势。
第二个优势,就是可以快速发放虚拟机,可以批量部署虚拟机,例如可以一次性部署10台虚拟机。FusionCompute最多可以一次性部署50台vm。例如,通过模板一次性部署50台vm。也可以通过虚拟机克隆,一次性克隆出50台,但是使用克隆方式,需要vm关机状态,否则只能克隆一台。

CNA是部署在每个node物理服务器节点上的。
VRM是对所有node以及其它硬件资源进行统一管理的。
CNA做虚拟机,VRM去管理CNA。
实际上VRM只是下发一些操作指令,而具体去管理执行动作,仍然是CNA来做的。

hypervisor,虚拟化软件层,用来管理下面的物理资源。
vmm,虚拟机监控器,用来管理上面的vm的。

FusionCompute也是基于kvm的。
esxi也是I型的。


FusionCompute搭建过程
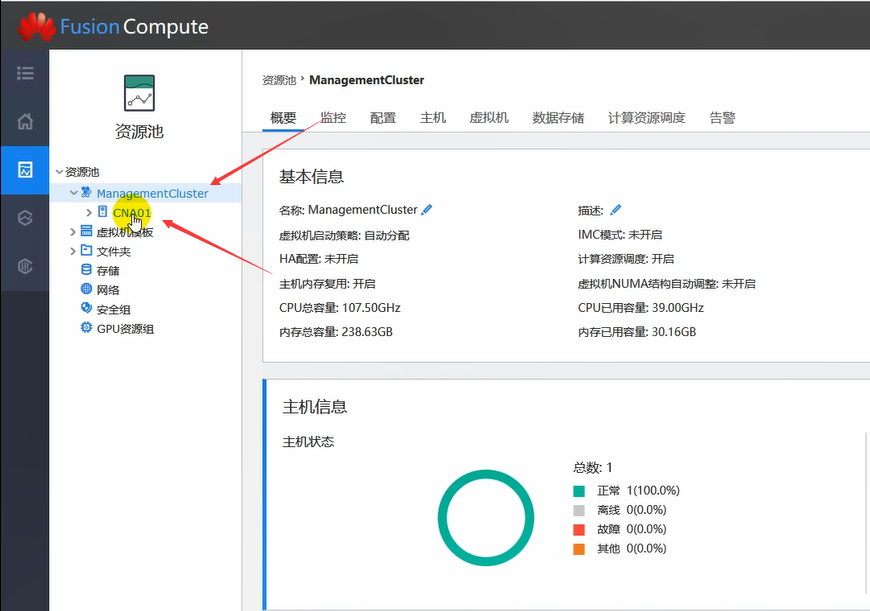
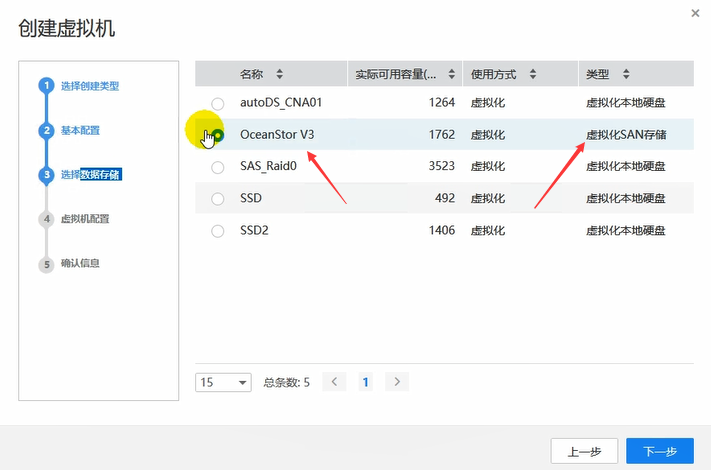
集群下可以有多个CNA。目前只有一个CNA。
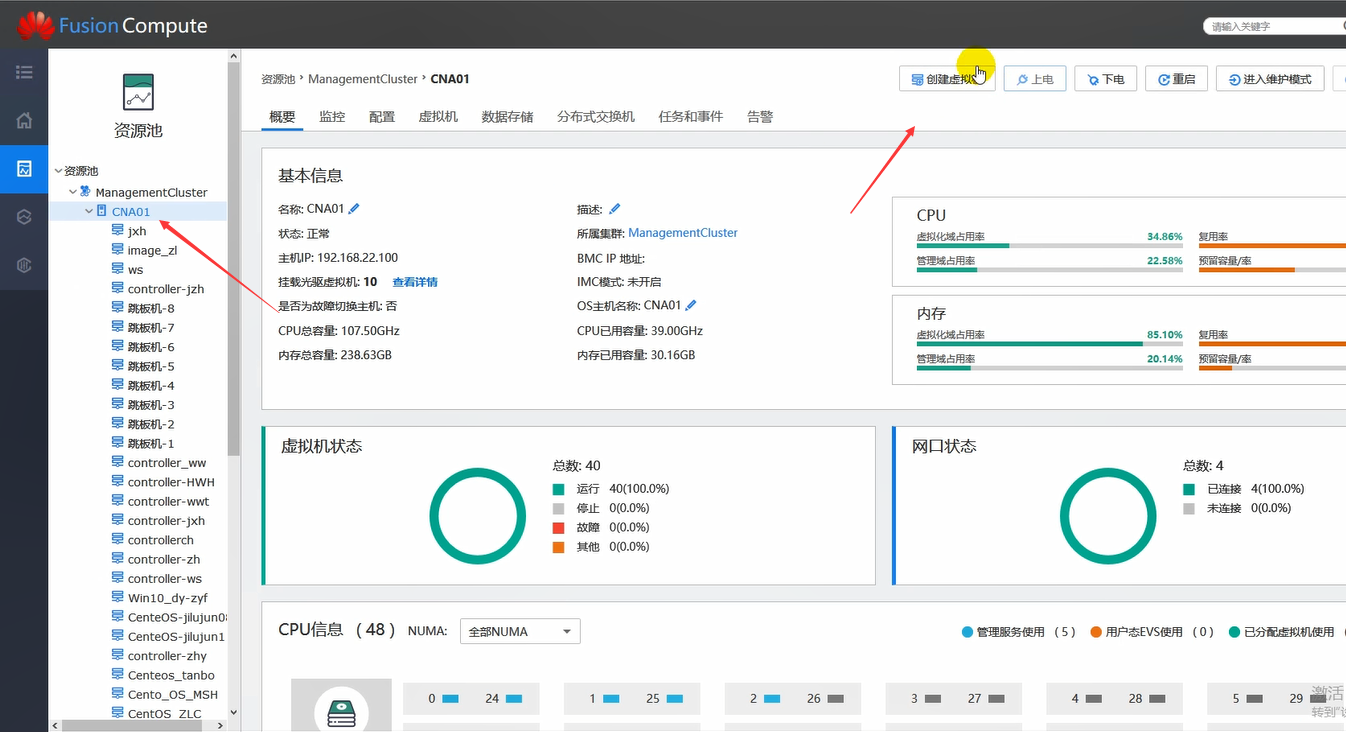
然后可以在指定的CNA上来创建vm。
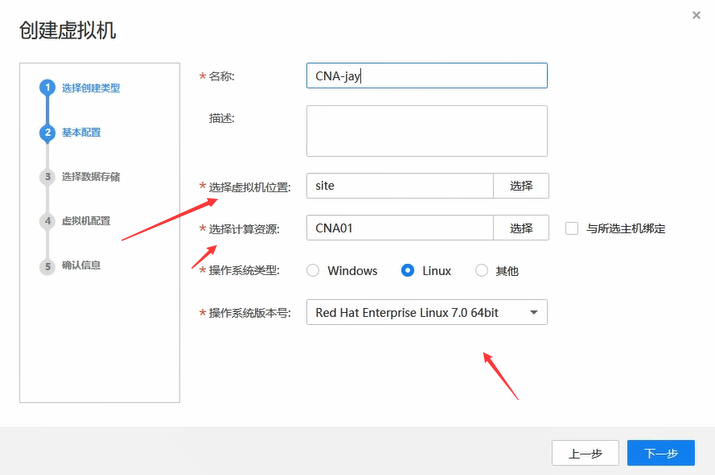
这里的目的就是创建两个vm,然后两个vm上去安装CNA和VRM来实验。
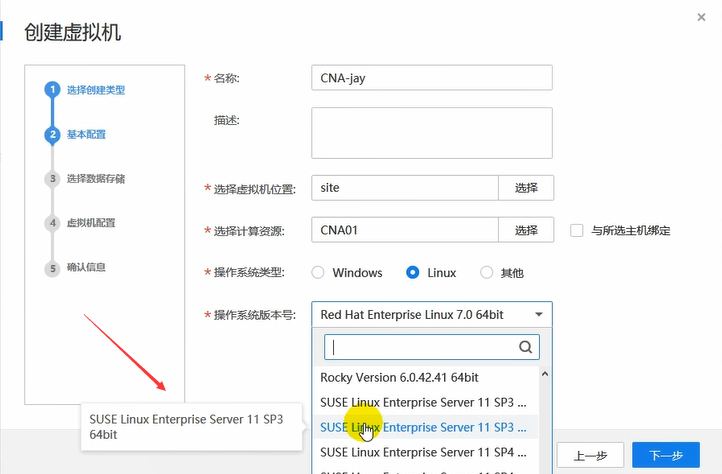
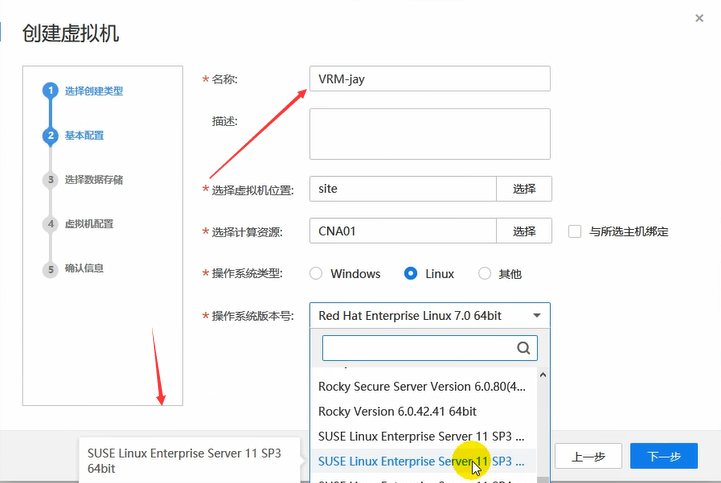
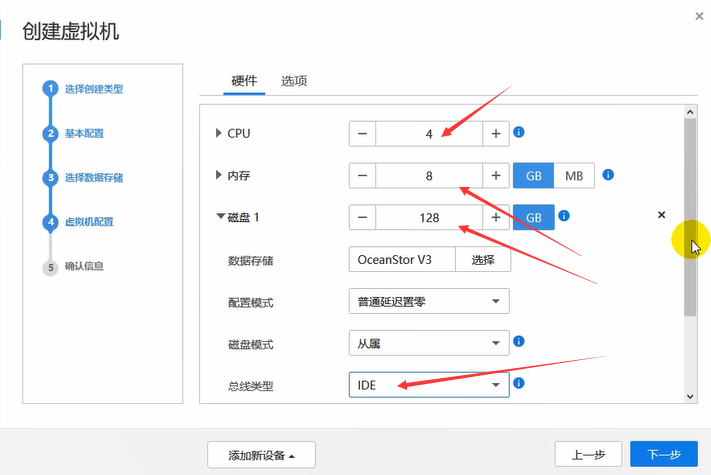
操作系统这里使用的是suse。
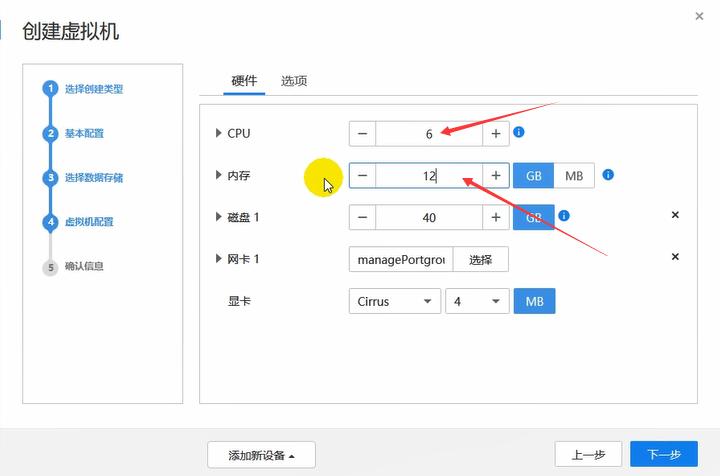
这台vm作为CNA,内存大一些。
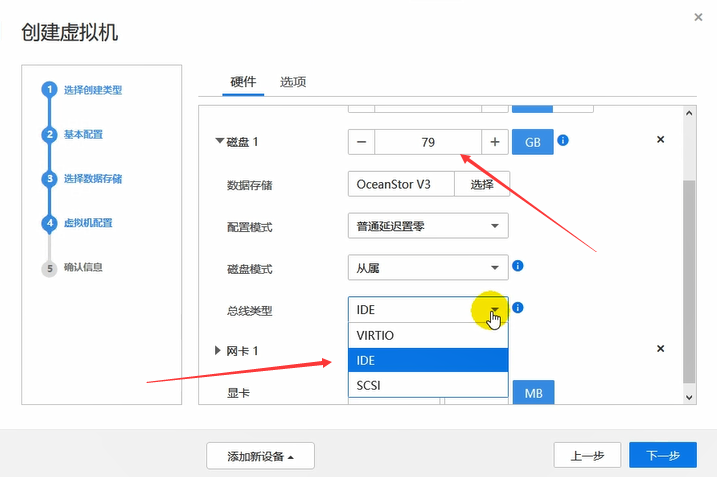
硬盘80g。由于这里是在vm中部署CNA,因此,总线类型选择IDE即可。
网卡,CNA和VRM在一个网络里即可。
还可以添加其他的设备。
由于这里是在vm中做实验,因此,使用IDE磁盘。
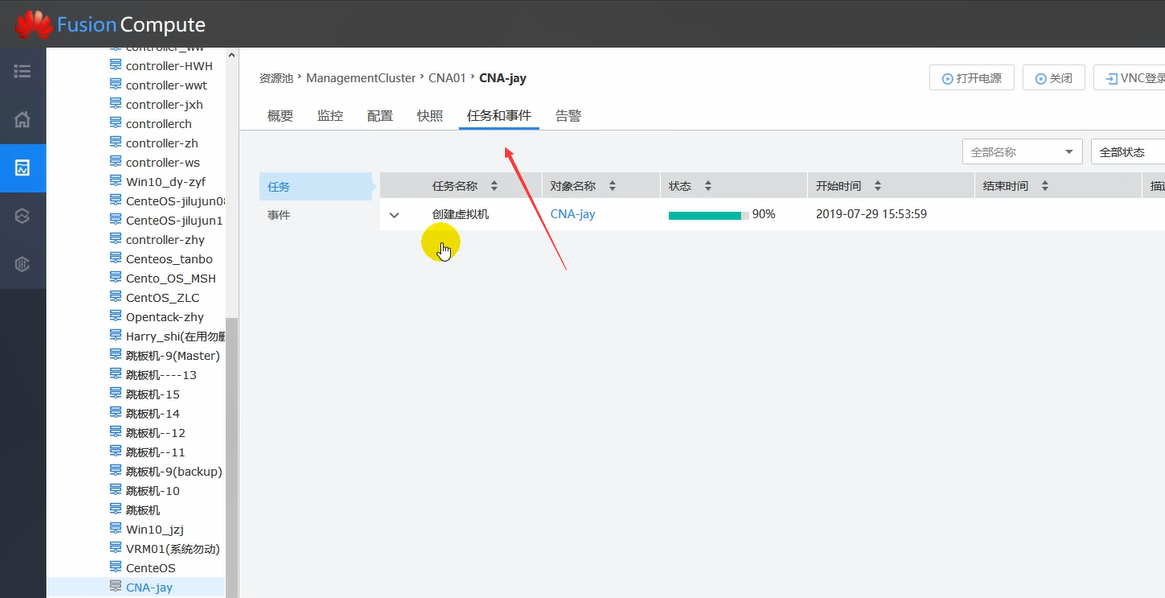
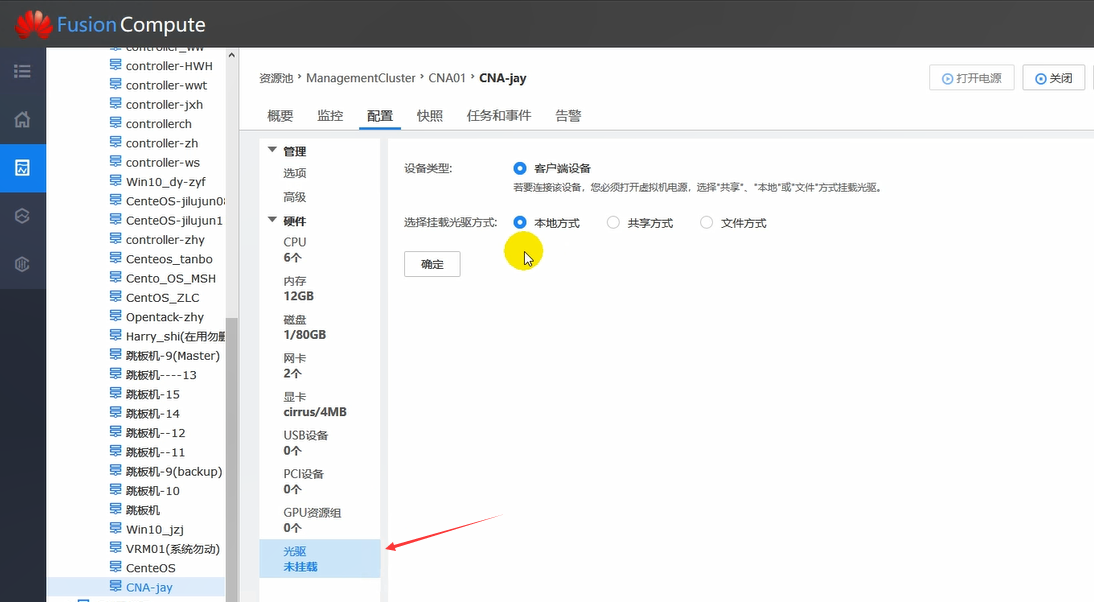
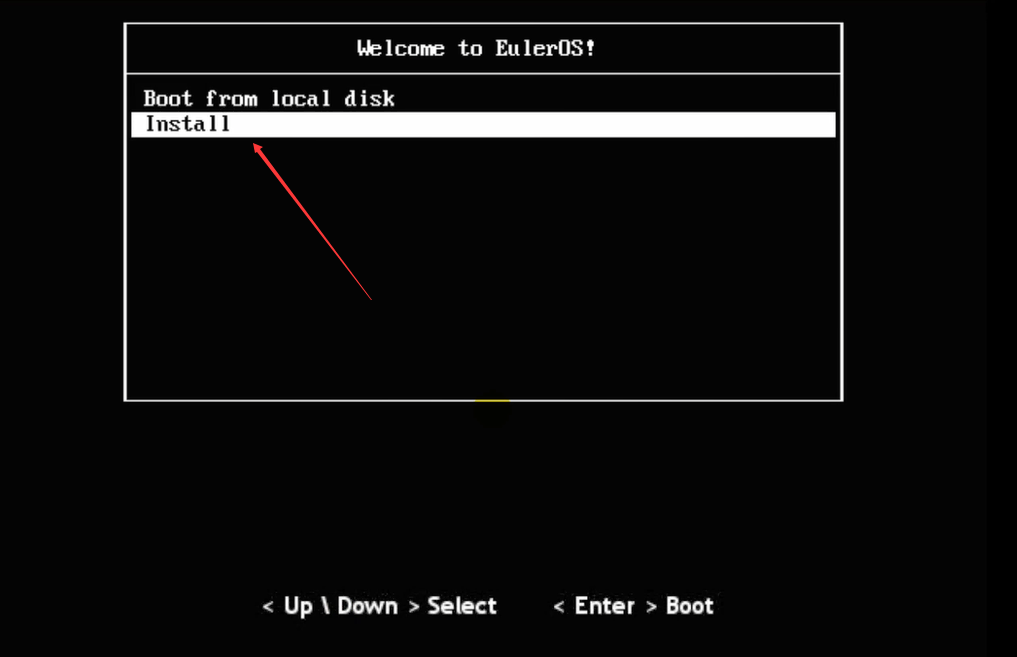
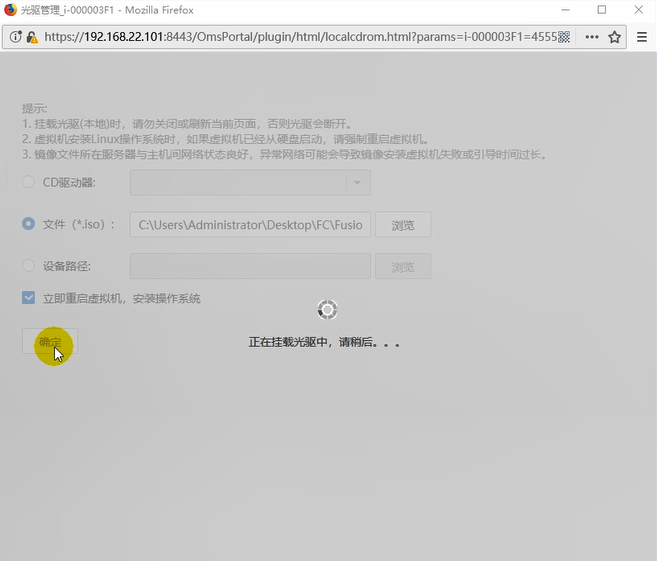
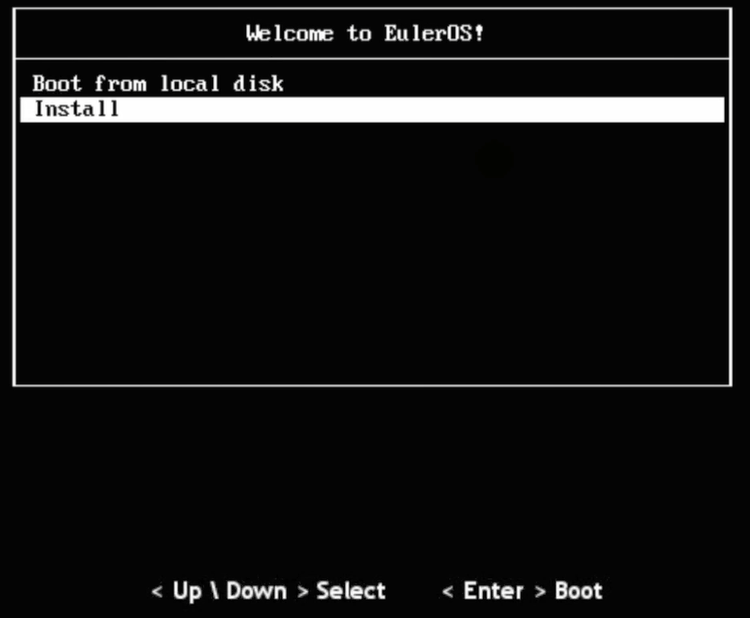
注意,之前只是选择要安装什么类型的OS,但是OS还没有呢。因此,需要安装。
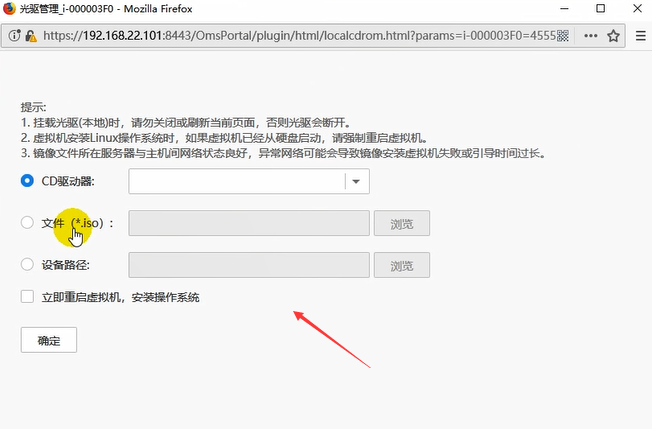
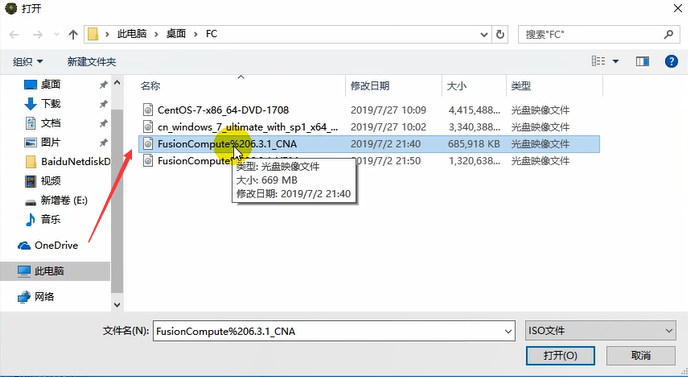
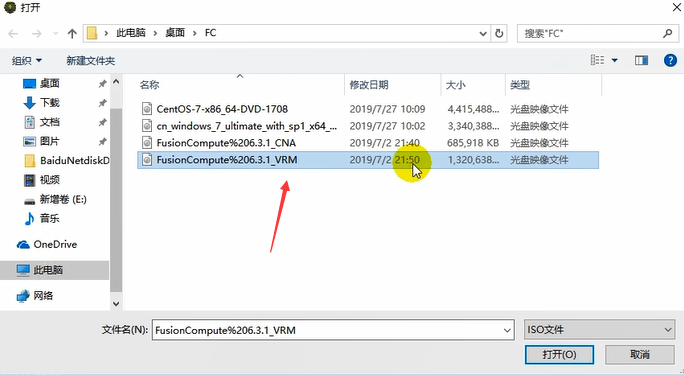
找到CNA的操作系统镜像。
此时确定。
此时挂载了光驱,不要×掉,否则光驱会卸载掉。直接最小化即可。
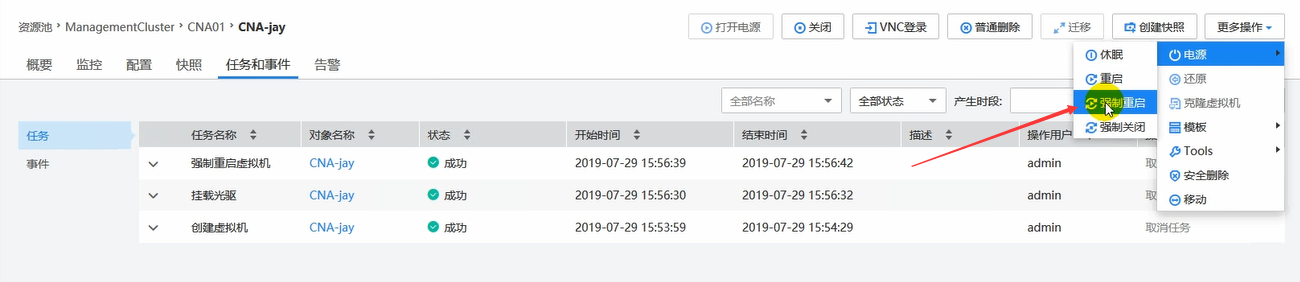
这里可以强制重启,普通重启可能不好使。

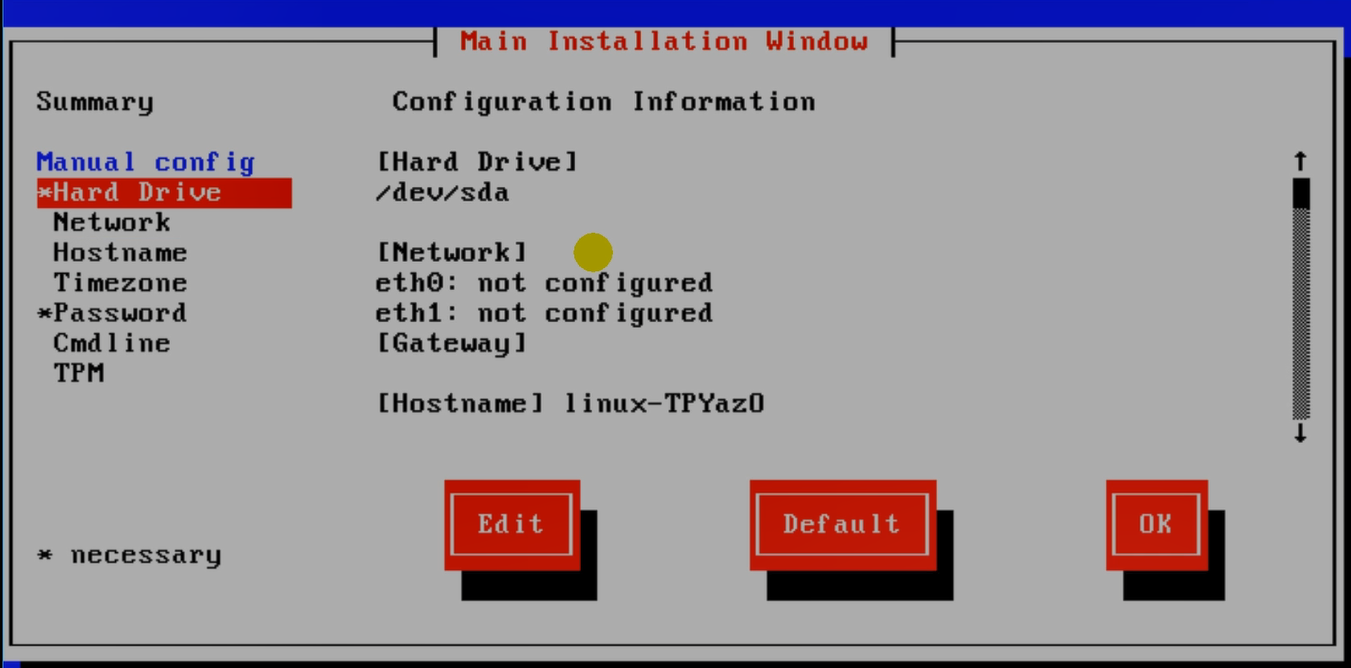
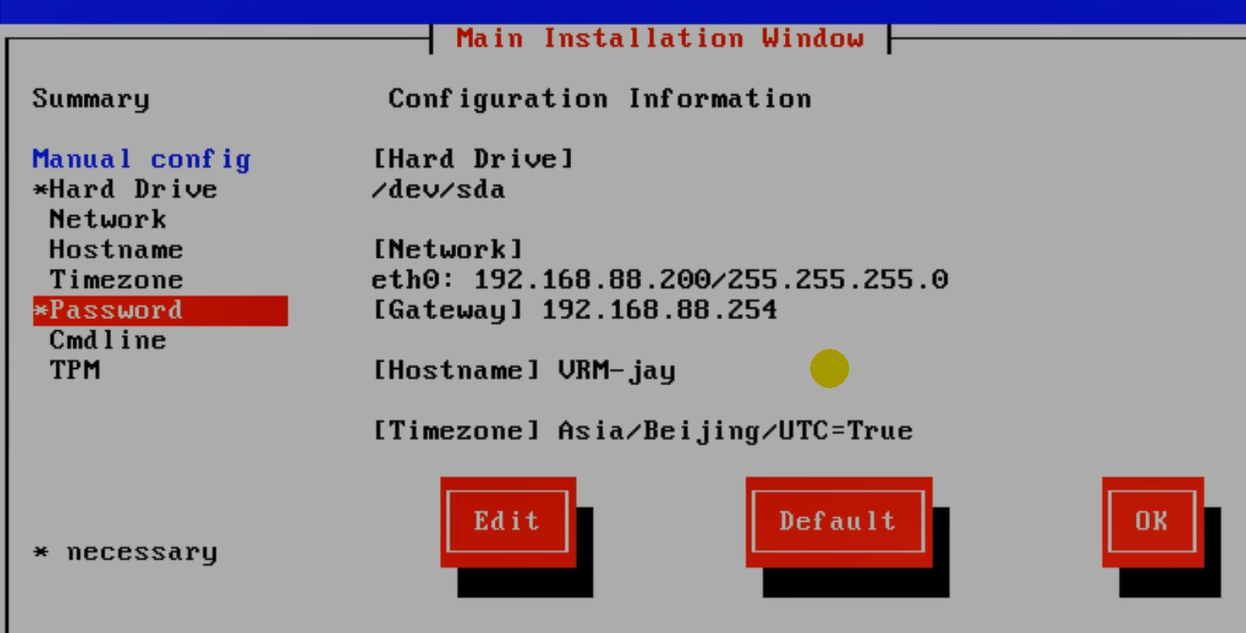
安装配置页面。
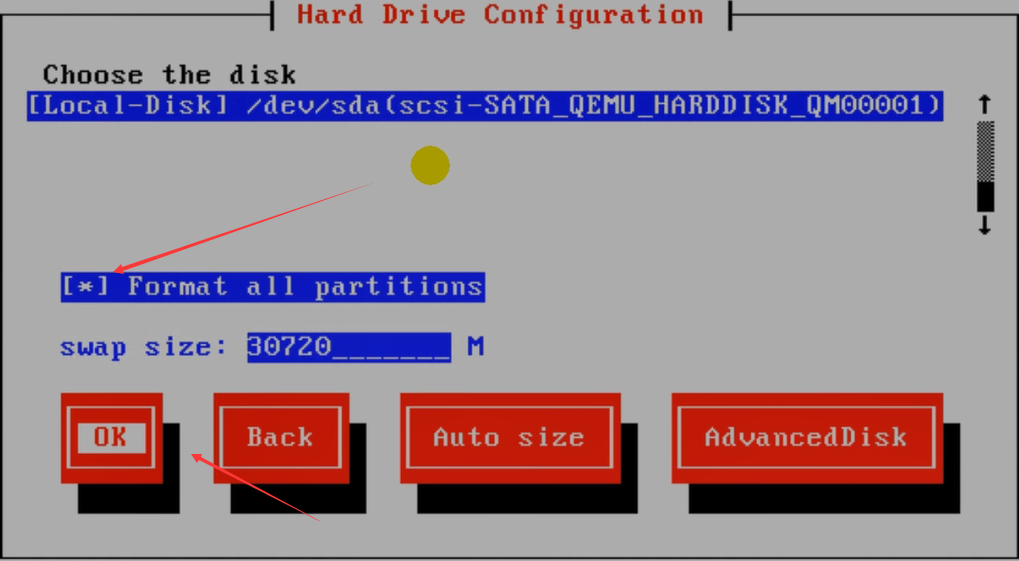
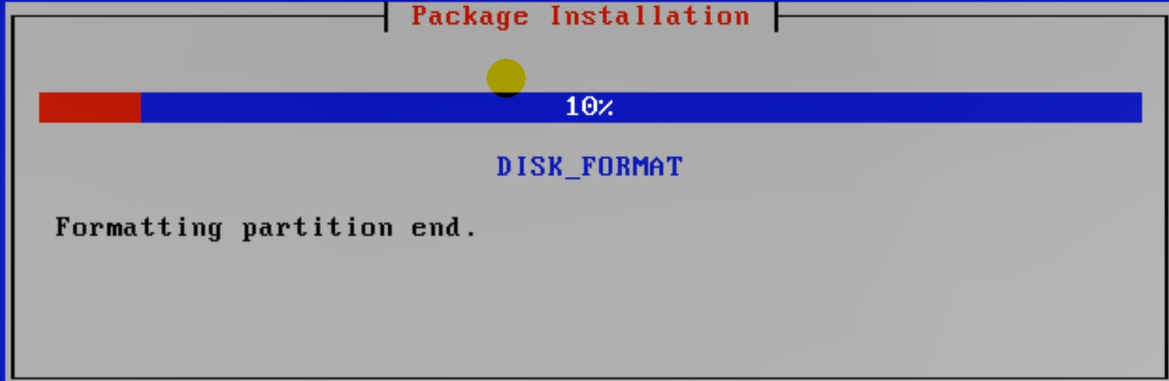
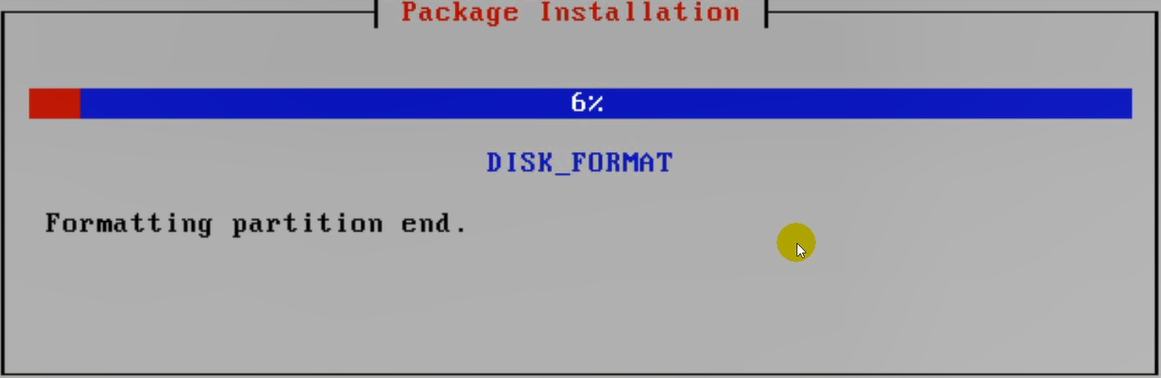
将硬盘格式化一下。
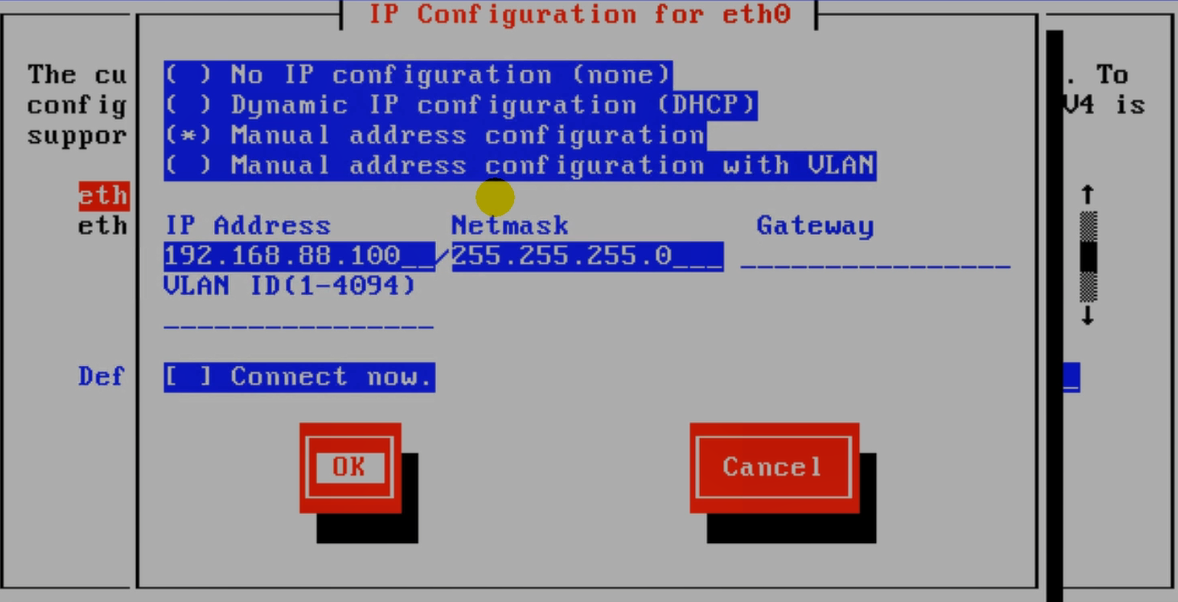
CNA和VRM处于同一个网段即可。
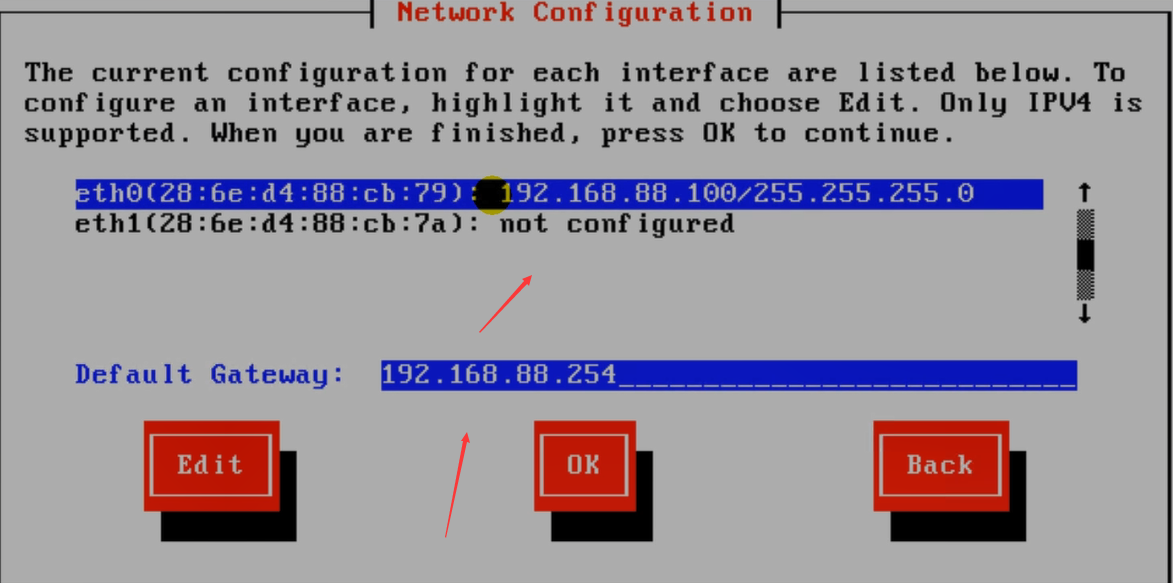
第二块网卡是之前额外添加的,没用。
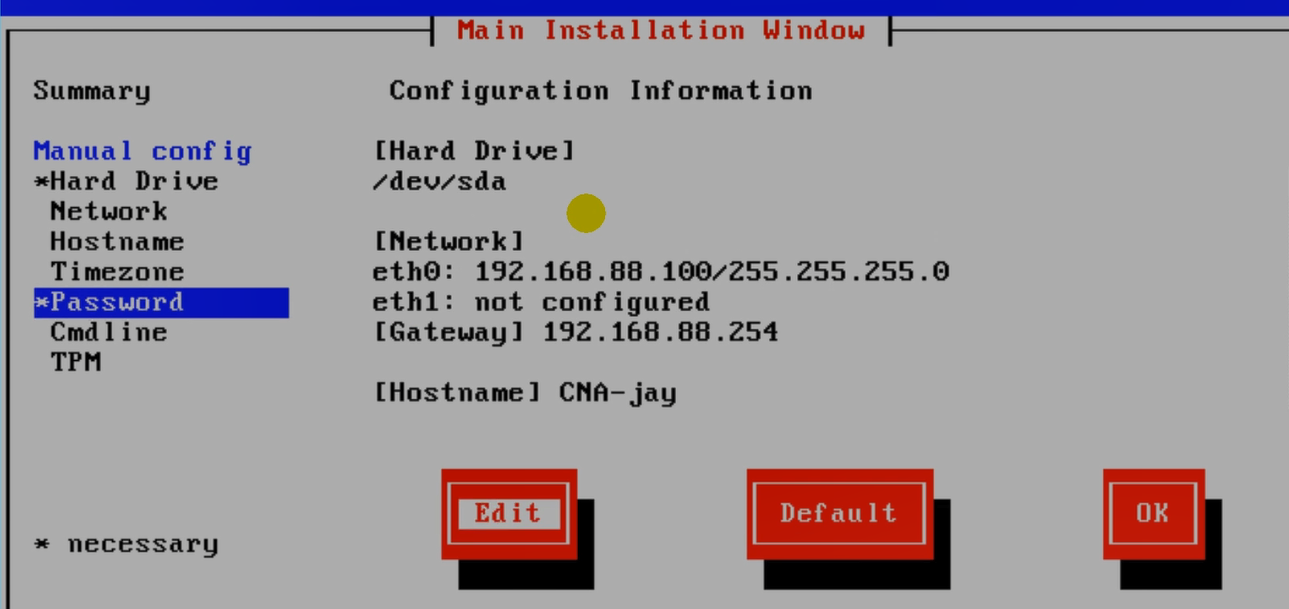
上述是创建并安装了一台CNA。
下述是创建并安装一台VRM。
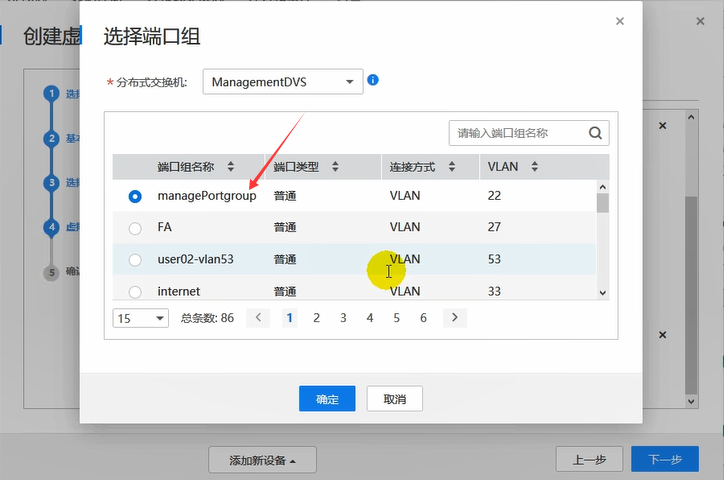
网卡这里,CNA和VRM的端口组要保持一致。

此时这里创建的仍然是一个空的没有OS的vm,因此,vm中的OS仍然需要自己去安装的。
配置界面操作同CNA。
VRM安装好之后,可以浏览器输入VRM地址,即可访问到web界面。
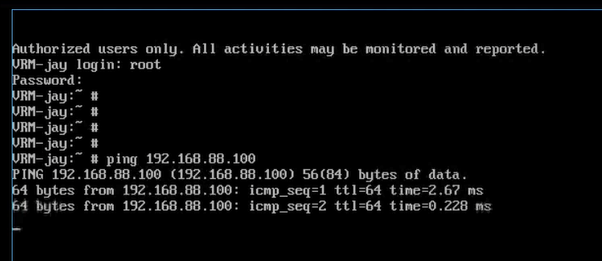
VRM和CNA是通的。
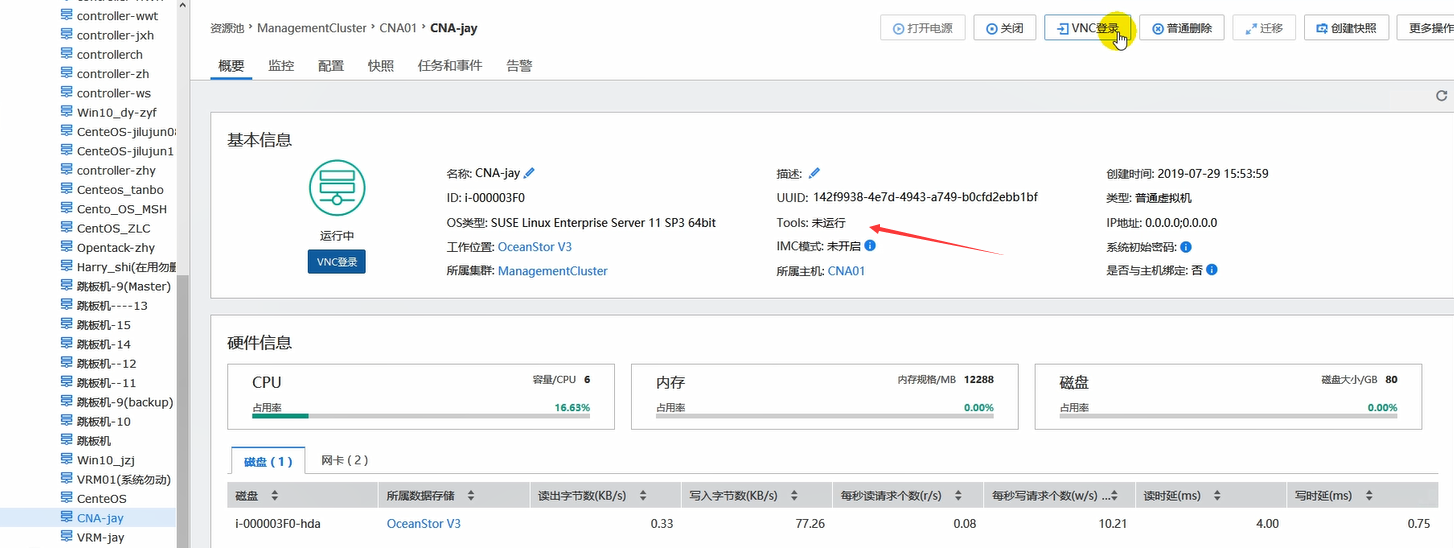
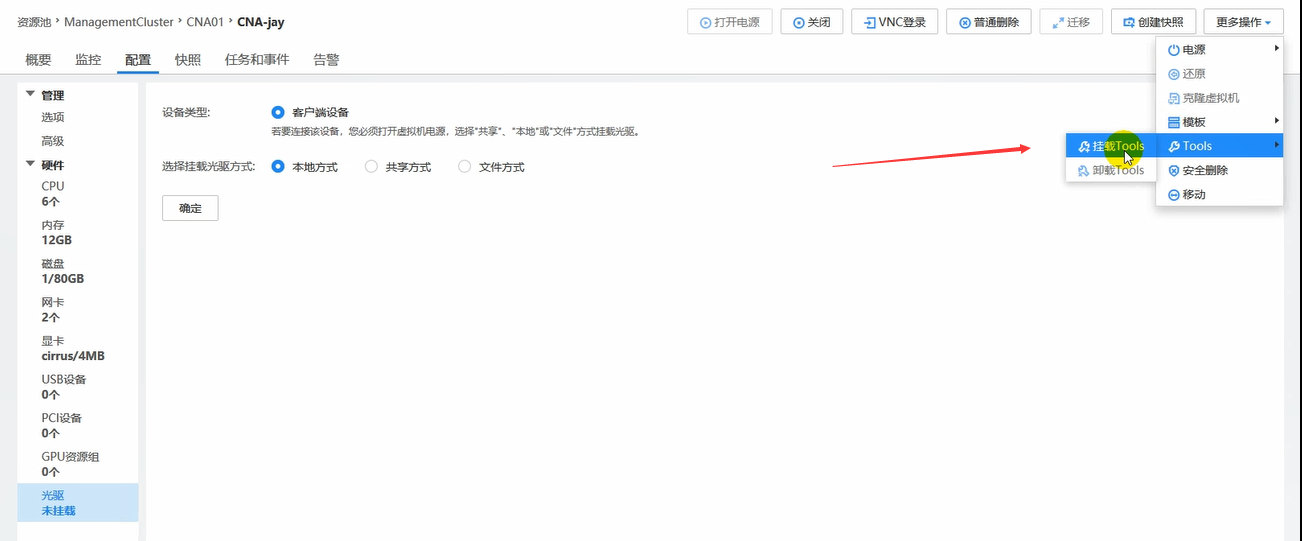
然后可以挂载安装tools,目的是提升性能,注意,这个在Windows和Linux上挂载安装方式不同。
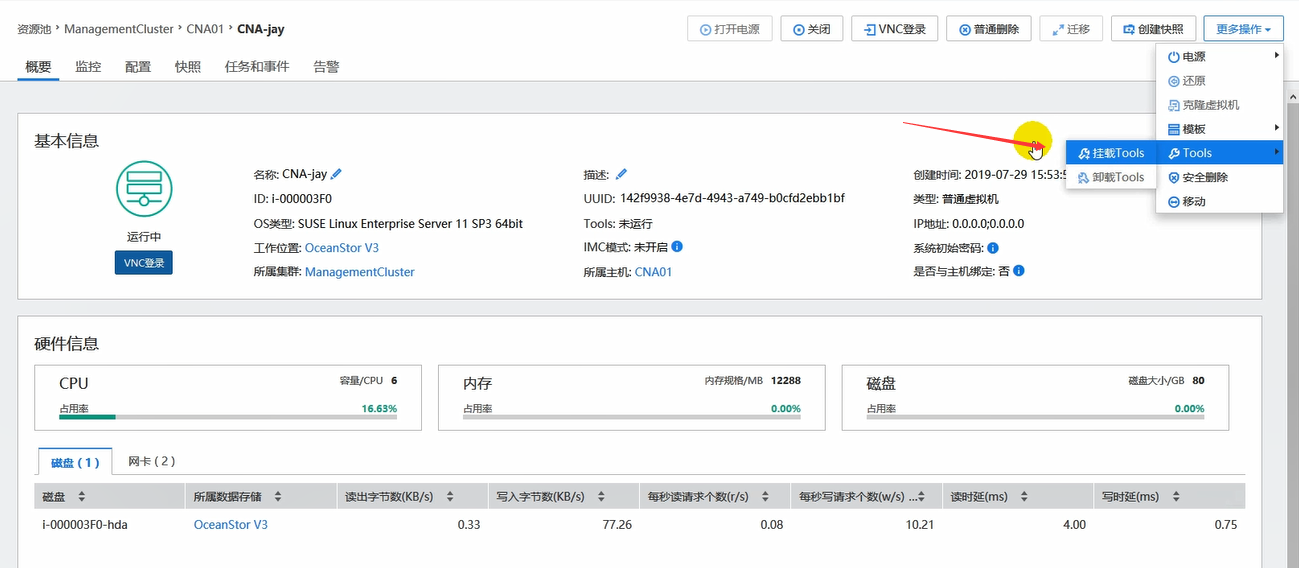
注意,挂载tools也是挂载到光驱上的,因此,需要将之前安装时挂载的光驱卸载。
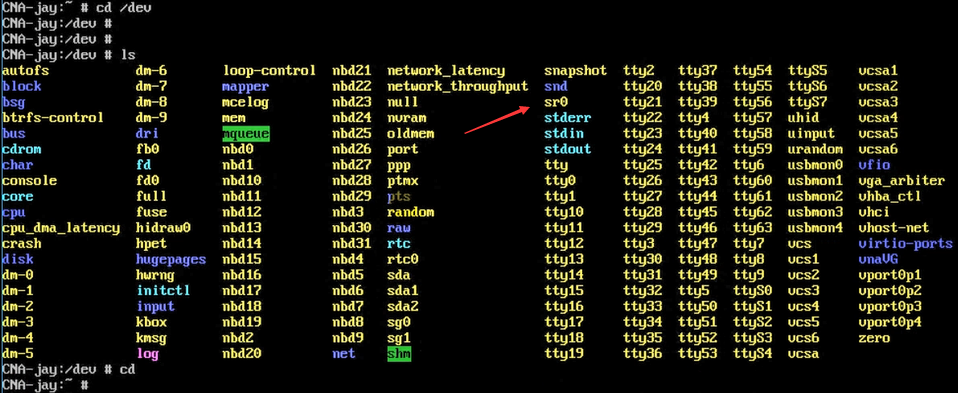
光驱sr0设备。




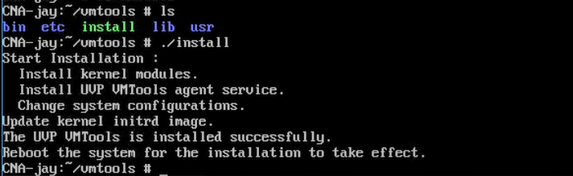
安装好之后,reboot重启系统即可。

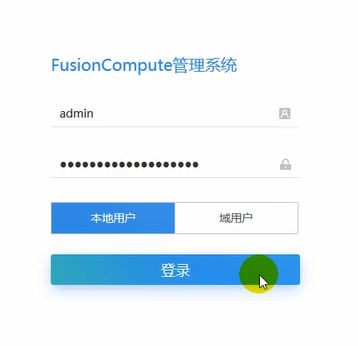
默认的admin密码。
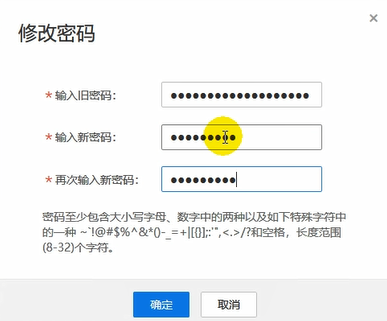
首次登录修改口令。
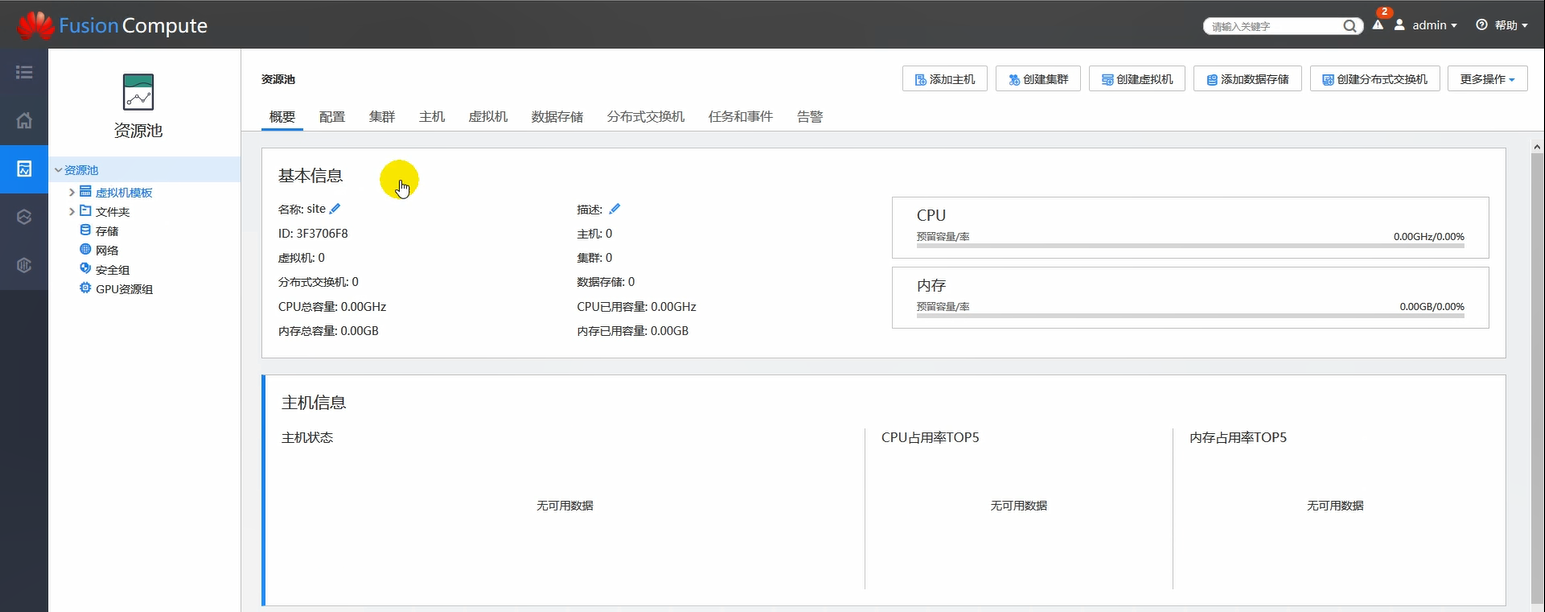
这就是自己搭建的fusionCompute了。
这就是fc的搭建过程。
网络参考
Virtualization Spectrum
虚拟化光谱
Icon Info.png A new article, 一篇新文章,Understanding the Virtualization Spectrum 理解虚拟化领域, summarizes this article and incorporates a great ,总结了本文,并结合了一个伟大的article 文章 by Brendan Gregg which cleans up the terminology. The article on this page has more detail, but the new one is more focused on explaining the general concepts behind the different modes. 作者 Brendan Gregg 清理了术语。本页上的文章有更多细节,但是新的文章更侧重于解释不同模式背后的一般概念
Contents内容
1 Full virtualization 完全虚拟化
2 Xen and paravirtualization Xen 和半虚拟化
3 Xen and full virtualization Xen 和完全虚拟化
4 From Poles to a Spectrum 从极点到光谱
5 Problems with paravirtualization: AMD and x86-64 半虚拟化的问题: AMD 和 x86-64
6 Paravirtualizing little by little: PVHVM mode 一点一点半虚拟化: PVHVM 模式
7 Problems with paravirtualization: Linux and the PV MMU 半虚拟化的问题: Linux 和 PV MMU
8 Almost fully PV: PVH mode 几乎完全 PV: PVH 模式
9 What about KVM? KVM 呢?
10 The paravirtualization spectrum 半虚拟化光谱
At XenSummit 2012 in San Diego, Mukesh Rathor from Oracle presented his work on a new virtualization mode, called “PVH”. Adding this mode, there are now a rather dizzying array of different terms thrown about — “HVM”, “PV”, “PVHVM”, “PVH” — what do they all mean? And why do we have so many?
在圣地亚哥举行的 XenSummit 2012上,甲骨文公司的 Mukesh Rathor 展示了他在一种名为“ PVH”的新型虚拟化模式上的工作。加上这个模式,现在有一大堆令人眼花缭乱的不同术语ーー“ HVM”、“ PV”、“ PVHVM”、“ PVH”ーー它们都是什么意思?为什么我们有这么多?
The reason we have all these terms is that virtualization is no longer binary; there is a spectrum of virtualization, and the different terms are different points along the spectrum. Part of the reason the terminology is a little unclear is the history; any language and terminology evolves over time in response to the changing situation. However, changing the terminology after-the-fact, once certain usages become common, is difficult.
我们之所以有这些术语,是因为虚拟化不再是二进制的; 存在一个虚拟化的范围,不同的术语在范围内是不同的点。术语有点不清楚的部分原因是历史; 任何语言和术语都随着时间的推移而演变,以应对不断变化的情况。然而,一旦某些用法变得普遍,在事后更改术语是困难的。
So in this article I will introduce just enough history to understand how the current situation came about, and (hopefully) introduce a consistent set of terminology which may help clear things up, while balancing this against the fact that people will still continue to use existing terminology.
因此,在本文中,我将介绍足够多的历史,以了解当前情况是如何发生的,并(希望)介绍一套一致的术语,这可能有助于澄清事实,同时平衡这一点,人们仍将继续使用现有的术语。
This article will give a general introduction to virtualization, and to paravirtualization, Xen’s unique contribution to the field, as well as the advent of hardware virtualization extensions (HVM). It will also introduce the idea of adding paravirtualized drivers for disk and network, and cover the motivation and technical descriptions of two more modes which further mix elements of full virtualization and paravirtualization.
这篇文章将对虚拟化和半虚拟化做一个简单的介绍,Xen 对这个领域的独特贡献,以及硬件虚拟化扩展(hVM)的出现。它还将介绍为磁盘和网络添加半虚拟化驱动程序的想法,并涵盖另外两种模式的动机和技术说明,这两种模式进一步混合了完全虚拟化和半虚拟化的元素。
Full virtualization 完全虚拟化
In the early days of virtualization (at least in the x86 world), the assumption was that you needed your hypervisor to provide a virtual machine that was functionally nearly identical to a real machine. This included the following aspects:
在虚拟化的早期阶段(至少在 x86领域) ,假设您需要虚拟机监控程序来提供与真实机器功能几乎相同的虚拟机。这包括以下方面:
Disk and network devices 磁盘和网络设备
Interrupts and timers 中断和计时器
Emulated platform: motherboard, device buses, BIOS 仿真平台: 主板,设备总线,BIOS
“Legacy” boot: i.e., starting in 16-bit mode and bootstrapping up to 64-bit mode “ Legacy”启动: 也就是说,从16位模式启动,到64位模式启动
Privileged instructions 特权指示
Pagetables (memory access) 分页表(内存访问)
In the early days of x86 virtualization, all of this needed to be virtualized: disk and network devices needed to be emulated, as did interrupts and timers, the motherboard and PCI buses, and so on. Guests needed to start in 16-bit mode and run a BIOS which loaded the guest kernel, which (again) ran in 16-bit mode, then bootstrapped its way up to 32-bit mode, and possibly then to 64-bit mode. All privileged instructions executed by the guest kernel needed to be emulated somehow; and the pagetables needed to be emulated in software.
在 X86虚拟化的早期,所有这些都需要虚拟化: 磁盘和网络设备需要仿真,中断和定时器、主板和 PCI 总线等等也需要仿真。客户机需要在16位模式下启动并运行一个 BIOS,该 BIOS 加载了客户机内核,该内核(同样)在16位模式下运行,然后启动到32位模式,然后可能进入64位模式。所有由客户内核执行的特权指令都需要以某种方式进行仿真; 分页表需要在软件中进行仿真。
This mode - where all of the aspects the virtual machine must be functionally identical to real hardware - is what I will call fully virtualized mode.
这种模式——虚拟机的所有方面在功能上必须与实际硬件完全相同——就是我所说的完全虚拟化模式。
Xen and paravirtualization Xen 和半虚拟化
Unfortunately, particularly for x86, virtualizing privileged instructions is very complicated. Many instructions for x86 behave differently in kernel and user mode without generating a trap, meaning that your options for running kernel code were to do full software emulation (incredibly slow) or binary translation (incredibly complicated, and still very slow).
不幸的是,特别是对于 x86,虚拟化特权指令是非常复杂的。X86的许多指令在内核和用户模式下表现不同,没有产生陷阱,这意味着运行内核代码的选项是完全的软件仿真(非常慢)或二进制翻译(非常复杂,仍然非常慢)。
The key question of the original Xen research project at Cambridge University was, “What if instead of trying to fool the guest kernel into thinking it’s running on real hardware, you just let the guest know that it was running in a virtual machine, and changed the interface you provide to make it easier to implement?” To answer that question, they started from the ground up designing a new interface designed for virtualization. Working together with researchers at both the Intel and Microsoft labs, they took both Linux and Windows XP, and ripped out anything that was slow or difficult to virtualize, replacing it with calls into the hypervisor (hypercalls) or other virtualization-friendly techniques. (The Windows XP port to Xen 1.0, as you might imagine, never left Microsoft Research; but it was benchmarked in the original paper.)
剑桥大学最初的 Xen 研究项目的关键问题是,“如果不是试图让客户内核认为它运行在真正的硬件上,而是让客户知道它运行在虚拟机中,并改变你提供的接口,使其更容易实现,会怎么样?”为了回答这个问题,他们从头开始为虚拟化设计一个新的界面。他们与英特尔和微软实验室的研究人员一起工作,同时使用 Linux 和 Windows XP,删除任何缓慢或难以虚拟化的东西,代之以对 hypervisor (超级调用)或其他虚拟化友好技术的调用。(你可能会想,Windows XP 到 Xen 1.0的移植从未离开过微软研究院,但它在原始论文中有过基准测试。)
The result was impressive — by getting rid of all the difficult legacy interfaces, they were able to make a fast, very lightweight hypervisor in under 70,000 lines of code.
结果令人印象深刻ーー通过摆脱所有困难的遗留接口,他们能够在不到7万行代码的情况下构建一个快速、非常轻量级的虚拟机监控程序。
This technique of changing the interface to make it easy to virtualize they called paravirtualization. In a paravirtualized VM, guests run with fully paravirtualized disk and network interfaces; interrupts and timers are paravirtualized; there is no emulated motherboard or device bus; guests boot directly into the kernel in the mode the kernel wishes to run in (32-bit or 64-bit), without needing to start in 16-bit mode or go through a BIOS; all privileged instructions are replaced with paravirtualized equivalents (hypercalls), and access to the page tables was paravirtualized as well.
这种改变界面的技术使得虚拟化变得更加容易,他们称之为半虚拟化。在半虚拟化虚拟机中,客户机使用完全半虚拟化的磁盘和网络接口运行; 中断和计时器是半虚拟化的; 没有模拟的主板或设备总线; 客户机以内核希望运行的模式(32位或64位)直接引导到内核,而不需要以16位模式启动或通过 BIOS; 所有特权指令被半虚拟化的等价物(超级调用)取代,对页表的访问也是半虚拟化的。
Xen and full virtualization Xen 和完全虚拟化
In early versions of Xen, paravirtualization was the only mode available. Although Windows XP had been ported to the Xen platform, it was pretty clear that such a port was never going to see the light of day outside Microsoft Research. This meant, essentially, that only open-source operating systems were going to be able to run on Xen.
在 Xen 的早期版本中,半虚拟化是唯一可用的模式。尽管 Windows XP 已经被移植到 Xen 平台上,但是很明显这样的移植在微软研究院之外永远不会出现。从本质上说,这意味着只有开源操作系统才能在 Xen 上运行。
At the same time the Xen team was coming up with paravirtualization, the engineers at Intel and AMD were working to try to make full virtualization easier. The result was something we now call HVM — which stands for “hardware virtual machine”. Rather than needing to do software emulation or binary translation, the HVM extensions do what might be called “hardware emulation”.
在 Xen 团队提出半虚拟化的同时,英特尔和 AMD 的工程师们正在努力使完全虚拟化变得更加容易。其结果就是我们现在称之为 HVM 的东西ーー它代表着“硬件虚拟机”。HVM 扩展不需要进行软件仿真或二进制翻译,而是进行所谓的“硬件模拟”。
Technically speaking, HVM refers to a set of extensions that make it much simpler to virtualize one component: the processor. To run a fully virtualized guest, many other components still need to be virtualized. To accomplish this, the Xen project integrated qemu to emulate disk, network, motherboard, and PCI devices; wrote the shadow code, to virtualize the pagetables; wrote emulated interrupt controllers in Xen; and integrated ROMBIOS to provide a virtual BIOS to the guest.
从技术上讲,HVM 指的是一组扩展,它们使虚拟化一个组件变得更加简单: 处理器。要运行一个完全虚拟化的客户端,许多其他组件仍然需要虚拟化。为了实现这一点,Xen 项目集成了 qemu 来模拟磁盘、网络、主板和 PCI 设备; 编写了影子代码来虚拟化页面; 在 Xen 中编写了模拟中断控制器; 集成了 ROMBIOS 来为客户端提供虚拟 BIOS。
Even though the HVM extensions are only one component of making a fully virtualized VM, the “fully virtualized” mode in the hypervisor was called HVM mode, distinguishing it from PV mode. This usage spread throughout the toolstack and into the user interface; to this day, users generally speak of running a VM in “PV mode” or in “HVM mode”.
尽管 HVM 扩展只是构建完全虚拟化 VM 的一个组件,但管理程序中的“完全虚拟化”模式被称为 HVM 模式,与 PV 模式不同。这种使用遍及整个工具堆栈和用户界面; 直到今天,用户通常还在谈论以“ PV 模式”或“ HVM 模式”运行 VM。
Once you have a fully-virtualized system, the first thing you notice is that the interface you provide for network and disks — that is, emulating a full PCI card with MMIO registers and so on — is really unnecessarily complicated. Because nearly all modern kernels have ways to load third-party device drivers, it’s a fairly obvious step to create disk and network drivers that can use the paravirtualized interfaces. Running in this mode can be called fully virtualized with PV drivers.
一旦您拥有了一个完全虚拟化的系统,您首先会注意到,您为网络和磁盘提供的接口ーー即,使用 MMIO 寄存器等仿真完整的 PCI 卡ーー实际上是不必要的复杂。因为几乎所有的现代内核都有加载第三方设备驱动程序的方法,所以创建可以使用半虚拟化接口的磁盘和网络驱动程序是一个相当明显的步骤。在这种模式下运行可以用 PV 驱动程序调用完全虚拟化。
From Poles to a Spectrum 从极点到光谱
I have introduced the concepts of full virtualization and paravirtualization (PV), as well as the hardware virtualization (HVM) feature used by Xen (among other things) to implement full virtualization. I have also introduced the concept of installing paravirtualized drivers on a fully virtualized system.
我已经介绍了完全虚拟化和半虚拟化(PV)的概念,以及 Xen 用来实现完全虚拟化的硬件虚拟化(HVM)特性。我还介绍了在完全虚拟化的系统上安装半虚拟化驱动程序的概念。
This small step, from full virtualization towards paravirtualization, begins to hint at the idea of a spectrum of paravirtualization. I will continue with the historical reasons for the development of PVHVM, and finally of the newest mode, PVH.
这一小步,从完全虚拟化到半虚拟化,开始暗示了一系列半虚拟化的想法。我将继续探讨 PVHVM 发展的历史原因,最后探讨最新的模式 PVH。
Problems with paravirtualization: AMD and x86-64 半虚拟化的问题: AMD 和 x86-64
It comes as a surprise to many people that while 32-bit paravirtualized guests in Xen are faster than 32-bit fully virtualized guests, when running in 64-bit mode, paravirtualized guests can sometimes be slower than fully virtualized guests. This is due to some changes AMD made when designing the architecture which simplified things for them, but made things more difficult for Xen.
在 Xen,32位的半虚拟客户比32位的全虚拟客户运行速度更快,这让很多人感到惊讶,但在64位模式下,半虚拟客户有时会比全虚拟客户运行速度更慢。这是由于 AMD 在设计体系结构时做了一些改变,这些改变简化了他们的工作,但使 Xen 的工作更加困难。
Most modern operating systems need just two levels of protection: user mode and kernel mode. Kernel mode memory is protected from user mode memory via the pagetable “supervisor mode” bit.
大多数现代操作系统只需要两个级别的保护: 用户模式和内核模式。内核模式存储器通过分页“管理模式”位保护不受用户模式存储器的影响。
When running a virtual machine, you need at least three levels of protection: user mode, guest kernel, and hypervisor. The hypervisor memory needs to be protected from the guest kernel, and the guest kernel memory needs to be protected from the user. The pagetable protections only provide two levels of protection, so Xen uses another processor feature, called a segmentation limit, to provide the third level of protection. Segmentation limits are a processor feature that was in common use before paging was available. But since paging has been available, segmentation limits have basically not been used; so Xen was able to commandeer them to provide the extra level of necessary protection. The pagetable protections protect both the guest kernel and Xen from userspace; the segmentation limits protect Xen from the guest kernel.
在运行虚拟机时,您至少需要三个级别的保护: 用户模式、客户内核和系统管理程序。系统管理程序内存需要受到来宾内核的保护,而来宾内核内存需要受到用户的保护。分页保护只提供两级保护,因此 Xen 使用另一个处理器特性,称为分段限制,来提供第三级保护。分段限制是在分页可用之前通常使用的处理器特性。但是由于分页已经可用,所以基本上没有使用分段限制; 因此 Xen 能够强制使用它们来提供额外的必要保护级别。分页表保护同时保护来宾内核和 Xen 不受用户空间的影响; 分段限制保护 Xen 不受来宾内核的影响。
Unfortunately, at the time that Xen team was developing clever new uses for this little-used feature, AMD was designing their 64-bit extensions to the x86 architecture. Any unused processor feature makes hardware much more complicated to design, reason about, and verify. Since basically no operating systems use segmentation limits, AMD decided to get rid of them.
不幸的是,当 Xen 团队正在为这个很少使用的特性开发聪明的新用途时,AMD 正在设计他们对 x86架构的64位扩展。任何未使用的处理器特性都会使硬件的设计、推理和验证变得更加复杂。由于基本上没有操作系统使用细分限制,AMD 决定去掉它们。
This may have greatly simplified the architecture for AMD, but it made it impossible for Xen to squeeze in 3 levels of protection into the same address space. Instead, for 64-bit PV guests, both guest kernel and guest user-space need to run in ring 3, each with their own address space. Every time a guest process needs to make a system call, it has to bounce up into Xen, which will context-switch to the guest kernel. This not only takes more time for each system call, but requires flushing one of the key CPU caches, called a TLB. Frequent flushing of the TLB causes all execution to run more slowly for some time afterwards, as the TLB is filled up again.
这可能极大地简化了 AMD 的体系结构,但是它使得 Xen 不可能在同一个地址空间中加入3个级别的保护。相反,对于64位 PV 客户机,客户内核和客户用户空间都需要在环3中运行,每个用户都有自己的地址空间。每次客户进程需要进行系统调用时,它都必须弹出到 Xen,Xen 将上下文切换到客户内核。这不仅需要为每个系统调用花费更多的时间,而且还需要刷新一个称为 TLB 的关键 CPU 缓存。TLB 的频繁刷新会导致所有执行在随后的一段时间内运行得更慢,因为 TLB 被再次填满。
In 64-bit HVM mode, the problem doesn’t occur. The HVM extensions make it easy to have three different protection levels without needing to play clever tricks with little-used processor features. So making system calls in 64-bit HVM mode is just as fast as on real hardware. For this reason, a lot of people began running 64-bit Linux in fully virtualized mode.
在64位 HVM 模式下,这个问题不会发生。HVM 扩展可以很容易地拥有三种不同的保护级别,而不需要使用很少使用的处理器特性。因此,在64位 HVM 模式下进行系统调用的速度与在实际硬件上一样快。出于这个原因,很多人开始在完全虚拟化模式下运行64位 Linux。
Paravirtualizing little by little: PVHVM mode 一点一点半虚拟化: PVHVM 模式
But fully virtualized mode, even with PV drivers, has a number of things that are unnecessarily inefficient. One example is the interrupt controllers: fully virtualized mode provides the guest kernel with emulated interrupt controllers (APICs and IOAPICs). Each instruction that interacts with the APIC requires a trip up into Xen and a software instruction decode; and each interrupt delivered requires several of these emulations.
但是,即使使用 PV 驱动程序,完全虚拟化模式也存在许多不必要的低效问题。一个例子是中断控制器: 完全虚拟化模式为客户内核提供了模拟中断控制器(APIC 和 IOAPIC)。与 APIC 交互的每条指令都需要进入 Xen 和一个软件指令解码; 并且每个中断都需要进行几次这样的模拟。
As it turns out, many of the the paravirtualized interfaces for interrupts, timers, and so on are actually available for guests running in HVM mode; they just need to be turned on and used. The paravirtualized interfaces use memory pages shared with Xen, and are streamlined to minimize traps into the hypervisor.
事实证明,许多用于中断、计时器等的半虚拟化接口实际上可用于在 HVM 模式下运行的客户机; 它们只需要打开并使用。半虚拟化接口使用与 Xen 共享的内存页面,并进行了流线型处理,以尽量减少管理程序中的陷阱。
So Stefano Stabellini wrote some patches for the Linux kernel that allowed Linux, when it detects that it’s running in HVM mode under Xen, to switch from using the emulated interrupt controllers and timers to the paravirtualized interrupts and timers. This mode he called PVHVM mode, because although it runs in HVM mode, it uses the PV interfaces extensively.
所以 Stefano Stabellini 为 Linux 内核编写了一些补丁,当 Linux 检测到它在 Xen 下以 HVM 模式运行时,它可以从使用模拟的中断控制器和定时器切换到半虚拟化的中断和定时器。这种模式他称之为 PVHVM 模式,因为尽管它在 HVM 模式下运行,但它广泛地使用了 PV 接口。
(“PVHVM” mode should not be confused with “PV-on-HVM” mode, which is a term sometimes used in the past for “fully virtualized with PV drivers”.)
(“ PVHVM”模式不应与“ PV-on-HVM”模式混淆,后者过去有时用于表示“使用 PV 驱动程序进行完全虚拟化”。)
With the introduction of PVHVM mode, we can start to see paravirtualization not as binary on or off, but as a spectrum. In PVHVM mode, the disk and network are paravirtualized, as are interrupts and timers. But the guest still boots with an emulated motherboard, PCI bus, and so on. It also goes through a legacy boot, starting with a BIOS and then booting into 16-bit mode. Privileged instructions are virtualized using the HVM extensions, and pagetables are fully virtualized, using either shadow pagetables, or the hardware assisted paging (HAP) available on more recent AMD and Intel processors.
随着 PVhVM 模式的引入,我们可以开始看到半虚拟化不再是二进制的开关,而是一个频谱。在 PVHVM 模式下,磁盘和网络是半虚拟化的,中断和计时器也是如此。但是客户端仍然使用模拟主板、 PCI 总线等进行引导。它还要经历一次遗留引导,从 BIOS 开始,然后进入16位模式。特权指令使用 HVM 扩展进行虚拟化,分页表则完全虚拟化,可以使用影子分页表,也可以使用最新的 AMD 和 Intel 处理器上提供的硬件辅助分页(HAP)。
Problems with paravirtualization: Linux and the PV MMU 半虚拟化的问题: Linux 和 PV MMU
PVHVM mode allows 64-bit guests to run at near native speed, taking advantage of both the hardware virtualization extensions and the paravirtualized interfaces of Xen. But it still leaves something to be desired. For one, it still requires the overhead of an emulated BIOS and legacy boot. Secondly, it requires the extra memory overhead of a qemu instance to emulate the motherboard and PCI devices. For this reason, memory-conscious or security-conscious users may opt to use 64-bit PV anyway, even if it is somewhat slower.
PVHVM 模式允许64位客户机以接近本地速度运行,同时利用了 Xen 的硬件虚拟化扩展和半虚拟化接口。但它仍然留下了一些需要改进的地方。首先,它仍然需要仿真 BIOS 和遗留引导的开销。其次,它需要 qemu 实例的额外内存开销来模拟主板和 PCI 设备。出于这个原因,有内存意识或安全意识的用户可能会选择使用64位 PV,即使它有点慢。
But there is one PV guest that can never be run in PVHVM mode, and that is domain 0. Because having a domain 0 with the current Linux drivers will always be necessary, it will always be necessary to have a PV mode in the Linux kernel.
但是有一个 PV 客户端永远不能在 PVHVM 模式下运行,那就是域0。因为使用当前 Linux 驱动程序的域0总是必要的,所以在 Linux 内核中使用 PV 模式总是必要的。
But what’s the problem, you ask? Weren’t all of the features necessary to run Linux as a dom0 upstreamed in Linux 3.0?
你会问,有什么问题吗?在 Linux 3.0中,将 Linux 作为 dom0上游运行不是所有的特性都是必需的吗?
Yes, they were; but they are still occasionally the source of some irritation. The core changes required to paravirtualize the page tables (also known as the “PV MMU”) are straightforward and work well once the system is up and running. However, while the kernel is booting, before the normal MMU is up and running, the story is a bit different. The changes required for the early MMU are fragile, and are often inadvertently broken when making seemingly innocent changes. This makes both the x86 maintainers and the pvops maintainers unhappy, consuming time and emotional energy that could be used for other purposes.
是的,他们是; 但是他们仍然偶尔是一些烦恼的来源。将页面表(也称为“ PV MMU”)半虚拟化所需的核心更改非常简单,并且在系统启动和运行后能够很好地工作。但是,当内核启动时,在正常的 MMU 启动并运行之前,情况有所不同。早期 MMU 所需的更改是脆弱的,并且在进行看似无关紧要的更改时经常在不经意间被破坏。这使得 x86维护人员和 pvops 维护人员都不高兴,消耗了可以用于其他目的的时间和情感能量。
Almost fully PV: PVH mode 几乎完全 PV: PVH 模式
A lot of the choices Xen made when designing a PV interface were made before HVM extensions were available. Nearly all hardware now has HVM extensions available, and nearly all also include hardware-assisted pagetable virtualization. What if we could run a fully PV guest — one that had no emulated motherboard, BIOS, or anything like that — but used the HVM extensions to make the PV MMU unnecessary, as well as to speed up system calls in 64-bit mode?
Xen 在设计 PV 接口时做出的许多选择都是在 HVM 扩展可用之前做出的。现在几乎所有的硬件都有可用的 HVM 扩展,而且几乎所有的硬件都包含了硬件辅助的分页虚拟化。如果我们可以运行一个完整的 PV 客户端(没有模拟主板、 BIOS 或者类似的东西) ,但是使用 HVM 扩展来使 PV MMU 变得不必要,并且在64位模式下加速系统调用,那会怎么样?
This is exactly what Mukesh’s PVH mode is. It’s a fully PV kernel mode, running with paravirtualized disk and network, paravirtualized interrupts and timers, no emulated devices of any kind (and thus no qemu), no BIOS or legacy boot — but instead of requiring PV MMU, it uses the HVM hardware extensions to virtualize the pagetables, as well as system calls and other privileged operations.
这就是 Mukesh 的 PVH 模式。它是一个完全 PV 内核模式,运行半虚拟化的磁盘和网络,半虚拟化的中断和定时器,没有任何类型的仿真设备(因此没有 qemu) ,没有 BIOS 或遗留启动ーー但它不需要 PV MMU,而是使用 HVM 硬件扩展来虚拟化分页表,以及系统调用和其他特权操作。
We fully expect PVH to have the best characteristics of all the modes — a simple, fast, secure interface, low memory overhead, while taking full advantage of the hardware. If HVM had been available at the time the Xen hypervisor was designed, PVH is probably the mode we would have chosen to use. In fact, in the new ARM Xen port, it is the primary mode that guests will operate in.
我们完全期望 PVH 具有所有模式中最好的特性ーー一个简单、快速、安全的接口,低内存开销,同时充分利用硬件的优势。如果在设计 Xen hypervisor 时 HVM 已经可用,那么 PVH 可能是我们选择使用的模式。事实上,在新的 ARM Xen 端口中,它是客户操作的主要模式。
Once PVH is well-established (perhaps five years or so after it’s introduced), we will probably consider removing non-PVH support from the Linux kernel, making maintenance of Xen support for Linux much simpler. The Xen kernel will probably support older kernels for some time after that. However, rest assured that none of this will be done without consideration of the community.
一旦 PVH 得到了很好的建立(可能是在它引入之后的五年左右) ,我们可能会考虑从 Linux 内核中删除非 PVH 支持,从而使得对 Linux 的 Xen 支持的维护更加简单。在此之后的一段时间内,Xen 内核可能会支持较老的内核。然而,请放心,如果没有社会的考虑,这些工作都不会完成。
Given the number of other things in the fully virtualized – paravirtualized spectrum, finding a descriptive name has been difficult. The developers have more or less settled on “PVH” (mainly PV, but with a little bit of HVM), but it has in the past been called other things, including “PV in an HVM container” (or just “HVM containers”), and “Hybrid mode”.
考虑到完全虚拟化-半虚拟化范围内的其他事物的数量,要找到一个描述性的名称是很困难的。开发人员或多或少已经确定了“ PVH”(主要是 PV,但也有一点 HVM) ,但在过去它被称为其他东西,包括“ HVM 容器中的 PV”(或仅仅是“ HVM 容器”)和“混合模式”。
What about KVM? KVM 呢?
At this point, some people may be wondering, how would KVM’s virtualization fit into this spectrum?
在这一点上,有些人可能想知道,KVM 的虚拟化如何适应这个范围?
Strictly speaking, KVM is just a set of kernel extensions designed to help processes implement virtualization. When most people speak of using KVM, they mean “qemu-kvm”, which means qemu running configured to use the KVM extensions. (There are other projects, such as the Native Linux KVM tool, which also use the KVM extensions.) When I say “KVM” here, I mean qemu-kvm.
严格地说,KVM 只是一组旨在帮助进程实现虚拟化的内核扩展。当大多数人谈到使用 KVM 时,他们指的是“ qemu-KVM”,即配置为使用 KVM 扩展的 qemu 运行。(还有其他项目,比如 NativeLinuxKVM 工具,也使用 KVM 扩展。)我说的“ KVM”是指 qemu-KVM。
KVM supports both “legacy boot”, starting in 16-bit mode with a BIOS (or EFI) to load the kernel bootloader, and booting directly into a kernel passed on the qemu command-line. It also provides an emulated motherboard, PCI bus, and so on. It can provide both emulated disk and network cards; and thus it is capable of supporting guests running in fully virtualized mode.
KVM 既支持“遗留引导”,以16位模式启动,使用 BIOS (或 EFI)加载内核引导加载程序,也直接引导到通过 qemu 命令行传递的内核。它还提供了一个仿真主板、 PCI 总线等。它可以提供模拟磁盘和网卡,因此它能够支持在完全虚拟化模式下运行的客户机。
KVM also provides virtio devices, which can be considered paravirtualized, as well as a PV clock, for operating systems that can be modified to support them. KVM’s typical method of paravirtualization is somewhat different than Xen’s. Virtio devices expose a normal device interface, with MMIO control paths and so on, and could in theory be implemented by real hardware. Xen’s PV interfaces are based on shared memory and lockless synchronization. The kinds of actions that need an MMIO context switch for virtio devices probably correspond pretty closely to actions that need hypercalls for Xen PV devices; but in Xen no instruction emulation needs to be done.
KVM 还为可以修改以支持它们的操作系统提供半虚拟化的 virtio 设备和 PV 时钟。KVM 的典型半虚拟化方法与 Xen 的有些不同。Virtio 设备公开了一个常规的设备接口,包括 MMIO 控制路径等,理论上可以由实际的硬件实现。Xen 的 PV 接口基于共享内存和无锁同步。对于 virtio 设备而言,需要 MMIO 上下文切换的操作可能与需要对 Xen PV 设备进行超级呼叫的操作非常相似,但在 Xen,不需要进行指令模拟。
KVM does not have a paravirtualized interface for timers or interrupts; instead (if I understand correctly) it uses an emulated local APIC. Handling a full interrupt cycle for an emulated local APIC typically requires several MMIO accesses, each of which requires a context switch and an instruction emulation. The Xen PV interrupt interface is based on memory shared with the hypervisor, supplemented by hypercalls when necessary; so most operations can be done without context switches, and those that do require only a single context switch (and no instruction emulation). This was one of the major reasons for introducing PVHVM mode for Xen guests.
KVM 没有用于计时器或中断的半虚拟化接口; 相反(如果我理解正确的话) ,它使用一个模拟的本地 APIC。处理模拟本地 APIC 的完整中断周期通常需要多个 MMIO 访问,每个访问都需要上下文切换和指令模拟。Xen PV 中断接口基于与虚拟机监控程序共享的内存,并在必要时辅以超级调用; 因此大多数操作可以在没有上下文切换的情况下完成,而那些确实只需要一个上下文切换的操作(并且不需要指令模拟)。这是为 Xen 客户机引入 PVHVM 模式的主要原因之一。
So KVM has paravirtualized devices and a paravirtualized clock, but not paravirtualized interrupts; placing KVM on the spectrum, it would be one step more paravirtualized than “FV with PV drivers”, but not as paravirtualized as PVHVM.
所以 KVM 有半虚拟化的设备和半虚拟化的时钟,但是没有半虚拟化的中断; 把 KVM 放到频谱上,它会比“带 PV 驱动的 FV”更加半虚拟化一步,但是不会像 PVHVM 那样半虚拟化。
The paravirtualization spectrum 半虚拟化光谱
So to summarize: There are a number of things that can be either virtualized or paravirtualized when creating a VM; these include:
因此,总结一下: 在创建 VM 时,有许多东西可以虚拟化或半虚拟化; 这些东西包括:
Disk and network devices
Interrupts and timers
Emulated platform: motherboard, device buses, BIOS, legacy boot
Privileged instructions and pagetables (memory access)
Each of these can be fully virtualized or paravirtualized independently. This leads to a spectrum of virtualization modes, summarized in the table below:
其中的每一个都可以完全虚拟化或半虚拟化。这就产生了一系列虚拟化模式,概述如下:
The first three of these will all be classified as “HVM mode”, and the last two as “PV mode” for historical reasons. PVH is the new mode, which we expect to be a sweet spot between full virtualization and paravirtualization: it combines the best advantages of Xen’s PV mode with full utilization of hardware support.
由于历史原因,前三种模式都将被归类为“ HVM 模式”,后两种模式将被归类为“ PV 模式”。PVH 是一种新模式,我们希望它能成为完全虚拟化和半虚拟化之间的一个甜蜜点,它结合了 Xen 的 PV 模式的最佳优势和对硬件支持的充分利用。
Hopefully this has given you an insight into what the various modes are, how they came about, and what are the advantages and disadvantages of each.
希望本文能够让您了解各种模式是什么,它们是如何产生的,以及每种模式的优缺点。
Virtualization Spectrum - Xen (xenproject.org)
FusionSphere和FusionCompute到底是什么关系
FusionSphere是解决方案了,FusionCompute是解决方案里面的,FusionSphere里面包涵虚拟化、云计算中心场景
首先理解openstack:openstack不是云,也不是虚拟化,而是构建云的关键组件,而且只是系统的控制面(不包括系统的数据面组件【如hypervisor、存储和网络设备等】)。可以把openstack理解为一种分布式操作系统,只是这种系统部署在多台主机上,以服务的方式对外提供;
那么FusionSphere是什么呢??这是华为基于openstack架构开发,整个系统专门为云设计和优化的云操作系统产品;
FusionSphere是产品的合集,其中包含但不限于:FusionSphere Openstack、FusionComputer、FusionStorage等,根据应用场景不同搭配不同的套件
FusionSphere的概念:
FusionSphere是业界领先的服务器虚拟化解决方案,FusionSphere解决方案通过在服务器上部署虚拟化软件,使一台物理服务器可以承担多台服务器的工作。通过整合现有的工作负载并利用剩余的服务器以部署新的应用程序和解决方案,实现较高的整合率。
FusionCompute的概念:
FusionCompute是云操作系统软件,主要负责硬件资源的虚拟化,以及对虚拟资源、业务资源、用户资源的集中管理。
FusionSphere是解决方案,只是一个概念,看不见摸不着,FusionCompute是操作系统,是一个软件,像windows操作系统镜像一样
FusionShpere是解决方案的名称,那么这个方案中需要用到产品组合。这些产品就包括了:FusionComputer(服务器虚拟化)、FusionStorage(存储虚拟化)、FusionNetwork(网络虚拟化)、FusionAccess(桌面虚拟化)、FusionInsight(大数据)。
fusionsphere我理解可以是office(类似vmware的vsphere),而fusioncompter可以理解成是Office其中的一个word(类似vmware的esxi),vrm是管理fusioncomputer的,类似vmware的vcenter
FusionSphere只是一个方案,不是具体的系统,也不是具体的软件,它只是一种云解决方案,你可以理解为一套云解决方案的名称,而在这个解决方案里面,包括了具体的用来实现方案的各种软件系统,比如,用来进行云平台管理的FusionManager管理软件,用来进行资源虚拟化的FusionCompute软件,还有用于分布式块存储的FusionStorage软件,还有进行容灾的UltraVR软件,云数据备份的软件eBackup等。
FusionSphere 云操作系统产品,集虚拟化平台和云管理等软件于一身,提供强大的虚拟化,资源池管理,云基础服务等功能。
fusioncompute是华为公司虚拟化软件,用于将物理资源虚拟化为云资源池,以达到更合理的分配和利用IT资源的目的。
FusionCompute
VRM+主机
VRM对云资源池进行管理和协调,使云资源池中的资源能够被合理的使用。
主机:安装了虚拟化操作系统的服务器,将主机的CPU和内存进行虚拟化;同时关联存储设备和交换机,将存储资源和网络资源进行虚拟化。
FusionSphere是华为公司面向多行业客户的云操作系统产品,整个系统专为云设计和优化提供强大的虚拟化功能、资源池管理、丰富的云基础服务组件和工具、开发的API接口等。极大帮助客户水平整合数据中心物理和虚拟资源,垂直优化业务平台,让企业的云计算建设和使用更加简捷。
它包含两种场景应用:场景一是服务器虚拟化,其虚拟化层是FusionSphere的虚拟化套件FusionCompute和云数据中心管理平台FusionManager;场景二是云数据中心和NFV,其虚拟化层是FusionSphere OpenStack和FusionSphere OpenStack OM。
FusionSphere OpenStack是开源社区OpenStack的一个华为商用加强产品,包含Controller节点(包含Nova、Neutron、Clider、Swift、Glance、Keystone等计算、网络、存储、鉴权的服务,还有一些非必选的或不那么通用的服务,比如裸金属、大数据等)和计算节点(可以直接是KVM,也可以是FusionCompute集群等)等。一般配合ManageOne(提供SC、OC服务界面和运维界面)来使用。FusionCompute是VRM+Hypervisor的服务器虚拟化产品,架构组网比OpenStack要简单很多。对于最终使用者,二者相同点是都能创建虚拟机等资源,区别在于OpenStack更偏向于服务化,不像服务器虚拟化那样,管理员清楚地知道哪台计算节点跑了哪些虚拟机,比较偏Operation层面。
注意,服务虚拟化和服务器虚拟化有区别。

