shell-正则表达式
正则表达式元字符
正则表达式功能和通配符功能差不多,但是比通配符功能更加强大。
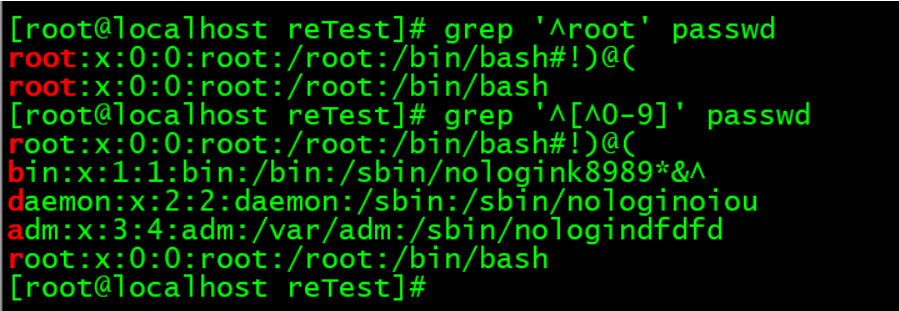
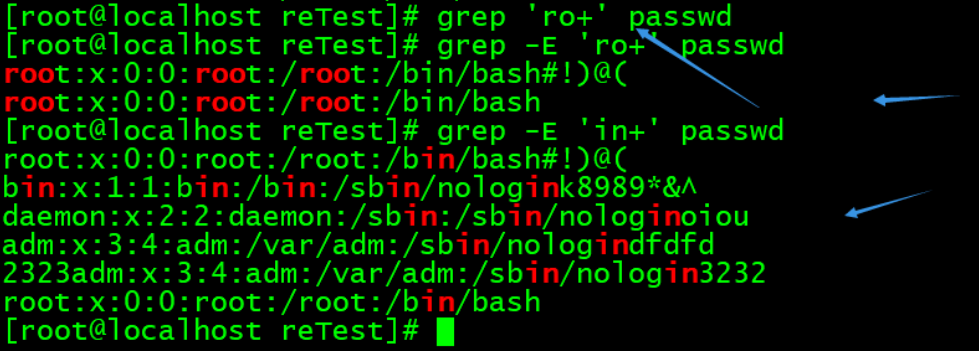
^:匹配行首。表示以某个字符开头。
[^0-9]:^出现在[]中,表示否定的意思。这里表示非数字。
$:匹配行尾。表示以某个字符结尾。
^$:表示空行的意思。
.:匹配任意单个字符。表示任意一个字符。注意,不是2个,也不是0个,只能是1个字符。
*:表示前面的字符,出现0次或者多次。
.*:表示任意多个字符。
+:表示前面的字符,出现1次或者多次。
?:表示前面的字符,出现0次或者1次。
[]:表示中括号中的任意一个字符。注意,只能是1个字符。
\<:表示单词的开头。
\>:表示单词的结尾。
\b单词\b:用来匹配单词。
\(\):分组,反向引用。
\{n\}:表示前面的字符出现n次。
\{n,\}:表示前面的字符最少出现n次,最多不限。
\{n,m\}:表示前面的字符最少出现n次,最多出现m次。
结合grep命令详细说明元字符含义
^:匹配行首。表示以某个字符开头。
[^0-9]:^出现在[]中,表示否定的意思。这里表示非数字。
样例文件:
[root@localhost reTest]# cat passwd
root:x:0:0:root:/root:/bin/bash#!)@(
bin:x:1:1:bin:/bin:/sbin/nologink8989*&^
daemon:x:2:2:daemon:/sbin:/sbin/nologinoiou
adm:x:3:4:adm:/var/adm:/sbin/nologindfdfd
2323adm:x:3:4:adm:/var/adm:/sbin/nologin3232
root:x:0:0:root:/root:/bin/bash
[root@localhost reTest]#
$:匹配行尾。表示以某个字符结尾。

^$:表示空行的意思。
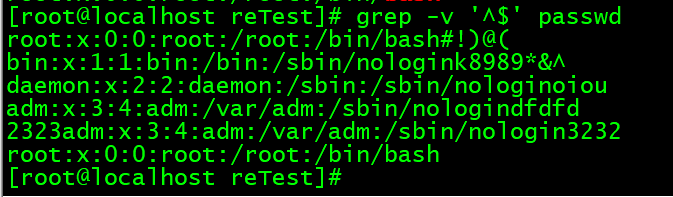
注意,使用正则的时候,要加上单引号或者双引号,防止bash将里面的元字符当成通配符了。

这里面的r没有加引号,是因为,正则表达式中有表示行头,shell的通配符中也有^,也表示行头,都能够识别到,因此,不加引号没问题。但是推荐使用正则时加上引号。
.:匹配任意单个字符。类似通配符中的?
表示任意一个字符。注意,不是2个,也不是0个,只能是1个字符。
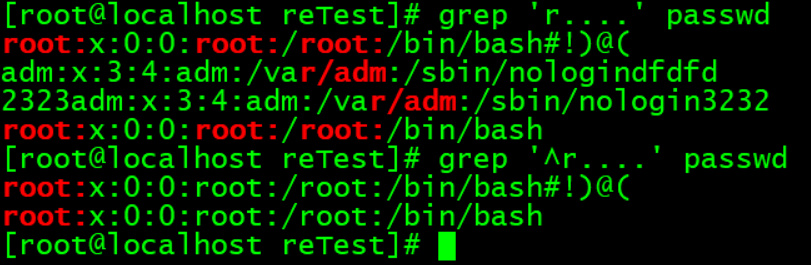
第一个表示过滤出r后面跟4个字符的内容,无论这4个字符是什么。
第二个表示过滤出行首是r后面跟4个字符的内容。
*:表示前面的字符,出现0次或者多次。
注意,和通配符中的所表示的意义不同。
这里的意思表示它前面的那个字符可以出现任意多次,任意既可以是0次,也可以是n次。
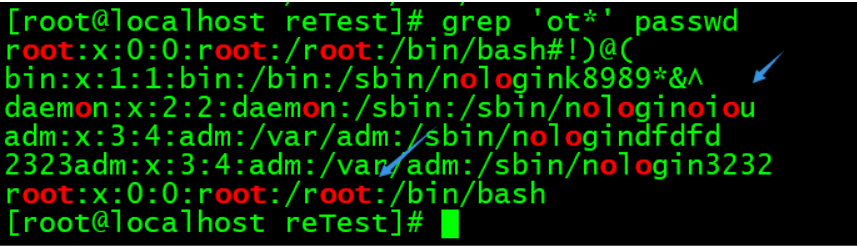
例子中,ot*,表示这个t可以出现也可以不出现,如果出现的话,可以出现多次,因此,类似o,ot,ottt这样的都可以匹配到。
上面oot也匹配到,因为,第一个o表示它后面没有出现t,所以匹配到,第二个o表示后面出现了一个t,所以匹配到。

可以看到,所有的行都匹配到,因为行首的r可以不出现,所以,其它的行也都匹配到了。
.*:表示任意多个字符。

+:表示前面的字符,出现1次或者多次。
+,前面的字符出现1次或者多次,不能是0次(即一次都不出现不行)。
grep支持的正则表达式的元字符有限,如果想使用更多的元字符,需使用grep -E或者egrep。
[root@localhost reTest]# cat test
t
to
tom
tommm
tommmmaaa
[root@localhost reTest]#

?:表示前面的字符,出现0次或者1次。
[root@localhost reTest]# cat test
t
to
tom
tommm
tommmmaaa
[root@localhost reTest]#
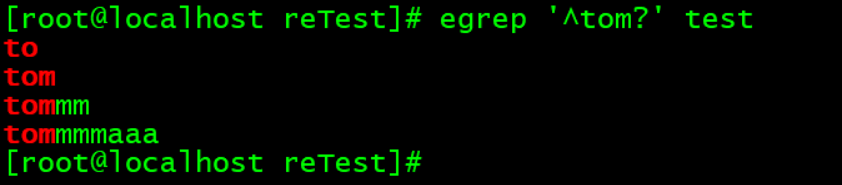
后面有多个m的也显示出来了,原因是后面的m被看成是普通的字符了,没有匹配到,只有匹配到的才红色显示。
*可以认为是+和?的结合体。
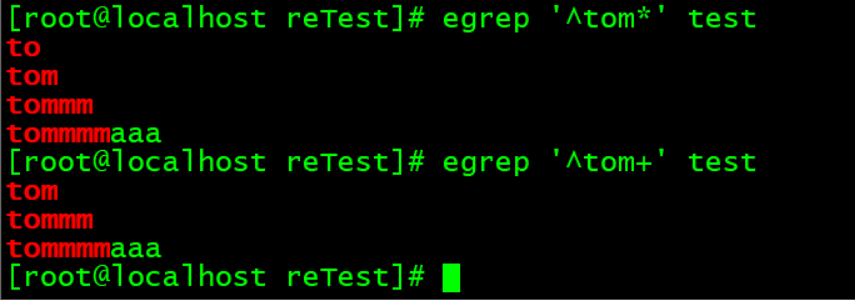
红色部分为匹配到的内容。
默认是贪婪匹配,即尽可能多的匹配内容。
懒惰匹配,即尽量少的去匹配内容。
懒惰匹配:
在末尾加上?即可。

可以看到仍然是贪婪匹配。
因为grep,grep –E或者egrep,的正则表达式,不支持懒惰匹配(末尾加上?的方式)方式,因此,让其使用Perl的正则表达式即可支持懒惰匹配了。
指定-P选项,让grep使用perl的正则表达式。
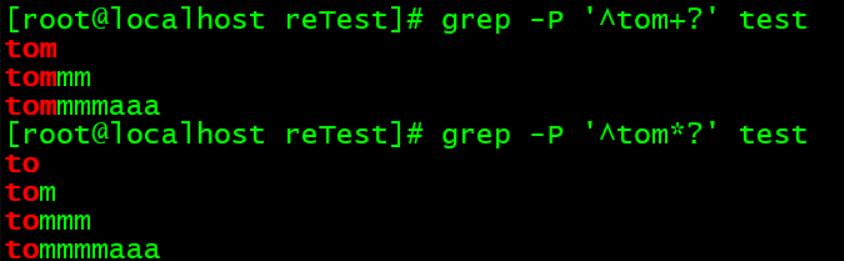
可以看到,是尽可能少的去匹配内容。
*表示前面字符出现0次或者多次,那么最少就是出现0次了。所以,只匹配到to内容。
+?也是同理。
[]:表示中括号中的任意一个字符。注意,只能是1个字符。
匹配[]中的任意单个字符。
[root@localhost reTest]# cat test
t
to
tom
tommm
tommmmaaa
A1122345
a223455
12232344
[root@localhost reTest]#

匹配[]中的A或者a或者5内容。

可以看到,使用懒惰匹配,仍然能够匹配到aaa和55。
因为从左向右匹配内容的时候,遇到了5,然后看它是[Aa5]中的内容,并且出现了一次,并且是懒惰匹配,因此,匹配到了第一个5,然后会继续向右匹配内容,同理,匹配到了第二个5,因此,这是发生了两次匹配过程。而不是贪婪匹配,一次匹配过程就匹配到了55。
[^ ]:当^出现在[]中的时候,表示取反,否定的意思。

\<单词\>等同于\b单词\b
\<:表示以某个单词开头。
\>:表示以某个单词结尾。
[root@localhost reTest]# cat test
t
to
tom
tommm
tommmmaaa
A1122345
a223455
12232344
tom jack luce
leo pall fuckyou etc sdfsf
[root@localhost reTest]#
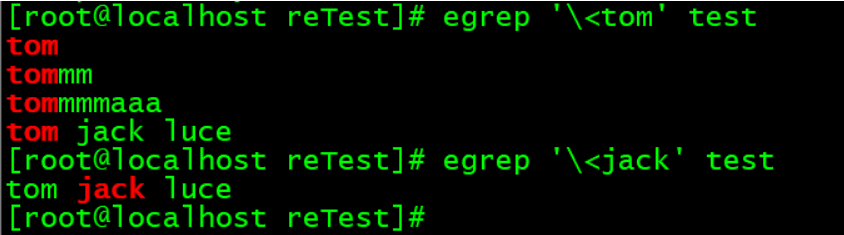
注意,\<表示以某个单词开头,不是行首。
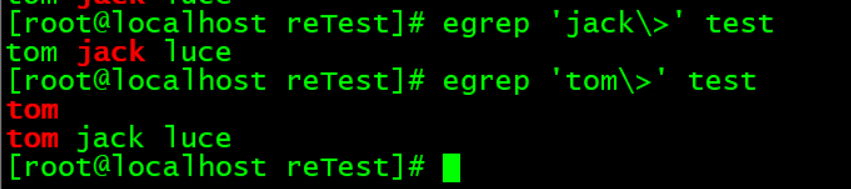
注意,\>表示以某个单词结尾,不是行尾。

精确匹配某个单词。

单词:前后两边有空格的,当中没有符号的,就是单词。与字典中的单词不是同一个概念。
\(\):分组,反向引用。
分组:即使用\(\)将某个内容括起来。
反向引用:\(\),将关键字括起来,后面可以对其再次引用。
\(\)xxxx\(\),这里会对每个括号中的内容做一个标记。第一个括号中的内容标记为1,第二个括号中的内容标记为2,以此类推。
[root@localhost reTest]# cat test
tomaaabbbtom
leofuckyouleofuckyou
[root@localhost reTest]#

[root@localhost reTest]# cat test
tomaaabbbtom
tombobxxxbobtomtombobxxx
[root@localhost reTest]#


使用-P选项,指定使用perl的正则表达式,此时分组直接写括号即可。
tom后面有3个字符,然后后面可能又出现了这3个字符,但是不知道这3个字符是什么的情况下,可以使用分组,后面再引用这3个字符。
\{n\}:表示前面的字符出现n次。
\{n,\}:表示前面的字符最少出现n次,最多不限。
\{n,m\}:表示前面的字符最少出现n次,最多出现m次。
[root@localhost reTest]# cat test
1
12
123
1234
12345
123456
1234567
[root@localhost reTest]#
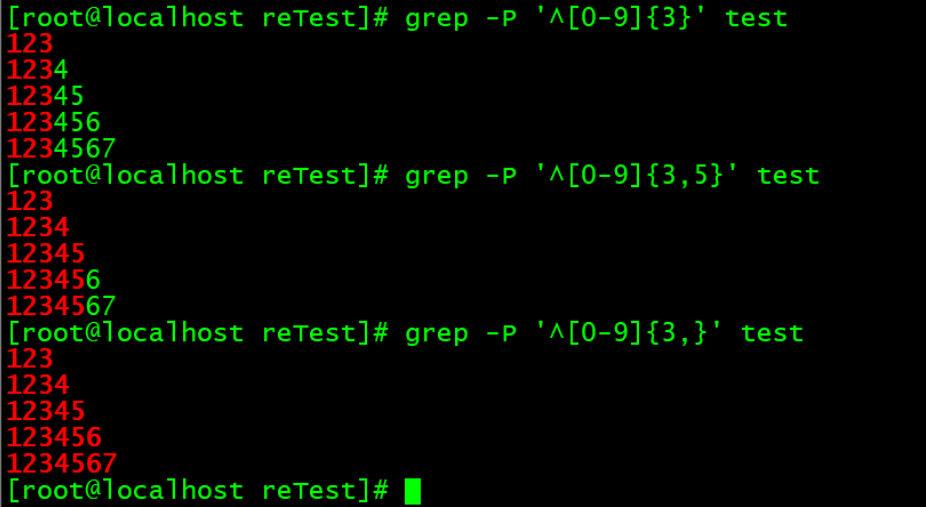
其它元字符
\d:数字0-9
[root@localhost reTest]# cat test
tom123jac1k
[root@localhost reTest]#

过滤tom后面有数字的,这样的内容。
\D:非数字
\s:空格,tab,注意,不能够表示\n
\S:非空格
\w:表示一个字符,可以是,字母(大小写)、数字、_(下划线)。注意,不能够匹配空格。
\W:表示,除了字母(大小写)、数字、_,之外的内容。
查找所有非空格的行
grep -P '^\S+$' /etc/yum.conf
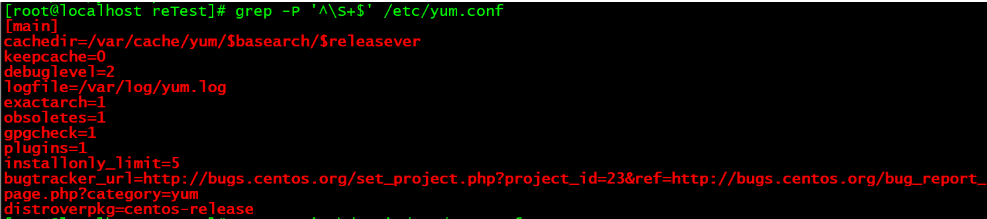
查找含有数字的行
grep -P '.*\d+.*' /etc/yum.conf


