
哈希表的概念及冲突方法的介绍
目录
1哈希表
1.2概念
哈希表(Hash)是一种基于计算的查找方法
 哈希表是一种映像,是从关键字空间到存储地址空间的一种映象。
哈希表是一种映像,是从关键字空间到存储地址空间的一种映象。
注意:哈希表是一种存储结构,它并非适合任何情况,主要适合记录的关键字与存储地址存在某种函数关系的数据
1.2装填因子
哈希表的设计主要解决哈希冲突。实际上哈希冲突主要和3个因素相关:
 所以需要设计好的哈希函数和设计解决冲突的方法是哈希表设计的重点。
所以需要设计好的哈希函数和设计解决冲突的方法是哈希表设计的重点。
2.哈希函数
2.1直接定址法

2.2其它哈希函数

 5、数值分析法
5、数值分析法
取关键字的后几位,或者列之列的
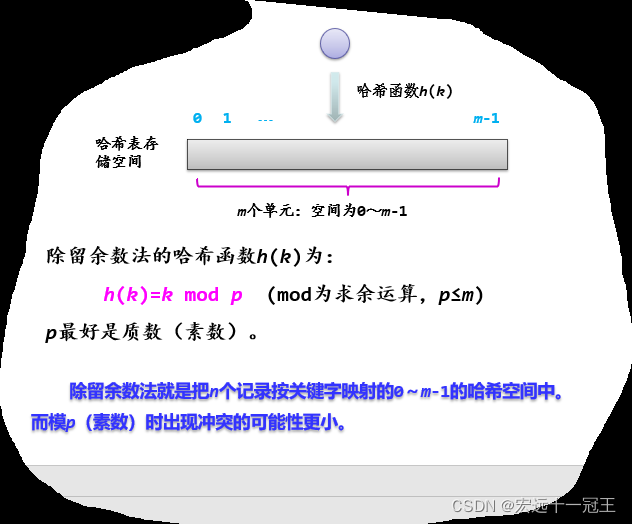
2.3除留余数法
3.哈希冲突处理方法
3.1开放定址法
开放定址就是当发生冲突后,重新给冲突的关键字重新找一个新的位置去存储,例如,如果你买到了电影票,到电影时已经开映了,你的位置被别人占用了,你需要找一个空位置。这就是开放定址法的思路。
线性探测法
冲突时,直接一个个探测下一个值是否发生冲突


平方探测法

伪随机探测法

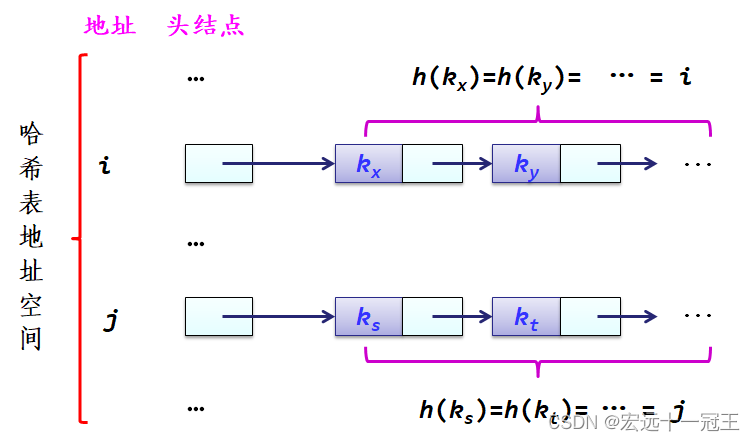
3.2 拉链法
就是把所有的同义词用单链表链接起来的方法。
3.再哈希法

4、部分实现过程
4.1除留余数法
void Inityu(int *range,int length){
// 除余初始化哈希表
for(int i= 0;i<30;i++){
// 50为总空间
int index = Name[i].A_sum %50;
//flag标记该位置是否已经被使用
if(Hash[index].flag !=1){
Hash[index].flag =1;
Hash[index].m = Name[i].A_sum;
Hash[index].key = Name[i].key;
// printf("%s\n",Hash[index].key);
}
else{
int k = 0; //指引伪随机数系列的当前长度
bool is_find = false;
while(!is_find){
int new_index = (index+range[k])%50;
// 采用伪随机数处理冲突
if(Hash[new_index].flag!=1){
Hash[new_index].flag =1;
Hash[new_index].m = Name[i].A_sum;
Hash[new_index].key = Name[i].key;
is_find =true;
}
else{
k = (k+1)%length;
}
}
}
}
}
伪随机法
这里是将随机数保存在一个数组中,然后在处理冲突时可以直接使用那个生成的随机数组
//生成随机数
for(int i =0;i<10;i++){
// 生成随机数
int temp = 1+rand()%20;
range[i] = temp;
printf("%d\n",temp);
}
全部代码
这里对名字进行映射,我们将名字的后4位对应Ansi码相加,然后再进行除留余数法的哈希函数,最后再用伪随机法去处理哈希冲突
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#include <malloc.h>
#include <stdbool.h>
typedef struct {
char *key;
int A_sum;
}name;
typedef struct {
int m;
char * key; //关键字
int flag; //标记是否有使用过
}elem;
name Name[30];
elem Hash[50];
//对名字按字典序进行插入排序
void InsertSort(int *range,int length){
for(int i =1;i<length;i++){
if(range[i]<range[i-1]){
int temp = range[i];
int j;
for(j = i-1;temp<range[j]&&j>=0;j--){
range[j+1] = range[j];
}
range[j+1] = temp;
// printf("%d\n",temp);
}
}
}
void InitName(int *range) {
//姓名表的初始化
Name[0].key = "lvsongxian";
Name[1].key = "yuanlei";
Name[2].key = "daiziwen";
Name[3].key = "chenyonghui";
Name[4].key = "zhangliang";
Name[5].key = "liubei";
Name[6].key = "sunshangxiang";
Name[7].key = "liyuanfang";
Name[8].key = "huge";
Name[9].key = "liuyifei";
Name[10].key = "anyixuan";
Name[11].key = "wangbaoqiang";
Name[12].key = "yangyiming";
Name[13].key = "hujing";
Name[14].key = "guowen";
Name[15].key = "xuyang";
Name[16].key = "lilu";
Name[17].key = "shenjinfeng";
Name[18].key = "xuhui";
Name[19].key = "huangjing";
Name[20].key = "guanyu";
Name[21].key = "chenlong";
Name[22].key = "huangliang";
Name[23].key = "liyan";
Name[24].key = "haojian";
Name[25].key = "zhangfei";
Name[26].key = "shuxiang";
Name[27].key = "sunyingjie";
Name[28].key = "wangbo";
Name[29].key = "zhaoqing";
//初始化名字关键字
for(int i = 0;i<30;i++){
int length = strlen(Name[i].key);
if(length>4){
int sum =0;
char *str = Name[i].key;
for(int j =length-1;j>=length-4;j--){
sum +=toascii(str[j]);//转换为Ansi码
}
Name[i].A_sum = sum;
}
else{
int sum =0;
char *str = Name[i].key;
for(int j =length-1;j>=0;j--){
sum +=toascii(str[j]);
}
Name[i].A_sum = sum;
}
}
// printf("");
int Max_length = sizeof (Hash)/sizeof (Hash[0]);
for(int j = 0;j<Max_length;j++){
Hash[j].key ="";
Hash[j].flag =0;
Hash[j].m =0;
}
for(int i =0;i<10;i++){
// 生成随机数
int temp = 1+rand()%20;
range[i] = temp;
printf("%d\n",temp);
}
};
//取名字的后四位字母的Asil码之和
void Inityu(int *range,int length){
// 除余初始化哈希表
for(int i= 0;i<30;i++){
// 50为总空间
int index = Name[i].A_sum %50;
//flag标记该位置是否已经被使用
if(Hash[index].flag !=1){
Hash[index].flag =1;
Hash[index].m = Name[i].A_sum;
Hash[index].key = Name[i].key;
// printf("%s\n",Hash[index].key);
}
else{
int k = 0; //指引伪随机数系列的当前长度
bool is_find = false;
while(!is_find){
int new_index = (index+range[k])%50;
// 采用伪随机数处理冲突
if(Hash[new_index].flag!=1){
Hash[new_index].flag =1;
Hash[new_index].m = Name[i].A_sum;
Hash[new_index].key = Name[i].key;
is_find =true;
}
else{
k = (k+1)%length;
}
}
}
}
}
int main() {
int range[5];
for(int i =0;i<5;i++){
range[i]= 0;
}
InitName(&range);
InsertSort(&range,10);
Inityu(&range,10);
// 打印结果
for(int i =0;i<50;i++){
if(Hash[i].key!=""){
printf("%d\t\t%s\n",i,Hash[i].key);
}
}
return 0;
}
总结
本人菜鸡一枚,如果有写错的话,望各位大佬指正,这里只实现了一个冲突方法,对哈希表的基础知识进行粗略的总结。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号