软考知识点笔记
计算机基础知识
计算机结构
DMA方式(Direct Memory Access)(成组数据传递方式):是一种直接内存操作,CPU在收到总线请求后,会在当前的总线周期结束后,按DMA信号的优先级线后作出响应。
指令寄存器是CPU中的关键寄存器,其内容为正在执行的指令,其位数取决于指令字长。
累加寄存器AC:通用寄存器,为ALU提供一个工作区,用来暂存数据。
计算机体系结构分类——Flynn分类法
单指令流但数据流(SISD)
单处理器系统
单指令流多数据流(SIMD)
阵列处理机
多质量流单数据流(MISD)
多指令流多数据流(MIMD)
CISC和RISC
| 指令系统类型 | 指令 | 寻址方法 | 实现方式 | 其他 |
|---|---|---|---|---|
| CISC(复杂) | 数量多,使用频率差别大,可变长格式 | 支持多种 | 微程序控制技术(微码) | 研制周期长 |
| RISC(精简) | 数量少,使用频率解决。将复杂指令拆分未多个简单指令 | 支持方式少 | 增加了通用寄存器;硬布线控制为主;适合采用流水线 | 优化编译,有效支持高级语言 |
CISC系统中的指令可以对主存单元中的数据直接进行处理。典型的CISC通常都有指令能够直接对主存单元中的数据进行处理,其执行速度较慢。
I/O系统
I/O系统可以由五种不同的工作方法,分别是:
程序控制方法、程序查询方法、DMA工作方法、通道方式、I/O处理机。
程序查询方法:
采用用户程序直接控制主机与外部设备之间输入/输出操作。这种方法下的CPU和I/O设备使串行工作的。
通道控制方法:
在一定的硬件基础上利用软件的手段实现对I/O的控制和传送,更多地面对了CPU的接入,使主机和外设并行工作程度更高。
I/O处理机:
专门负责输入/输出的处理机。可以有独立的存储器、运算部件和指令控制部件。
流水线
流水线的执行时长
流水线周期:执行时间中最长的一段(取指、分析、执行)
流水线计算公式
理论公式
1条指令执行时间 + (指令条数-1) * 流水线周期
实践公式
(段数+指令数-1)*流水线周期 段数指执行指令的流程数(K)
流水线吞吐率计算
流水线的吞吐率是指在单位时间内流水线 所完成的任务数量 或输出的结果数量。
若各流水级需要的时间不同,则流水线必须选择各级中时间较大者为流水级的处理时间
流水线最大吞吐量
忽略指令建立所需要的时间
流水线加速比计算
加速比越高,使用流水线产生的效果越好
流水线的效率
每一个工作段耗时相似的流水线效率较高
层次化存储结构
Cache(高速缓存存储器)
在计算机的存储系统体系中,Cache是访问最快的层次(除寄存器)
使用Cache改善系统性能的依据是程序的局部性原理
Cache存储器一般采用静态随机访问存储器(SRAM)技术,这种存储器的速度比动态RAM快,能够跟得上CPU的要求,弥合了CPU的主存之间的速度差距。
如果h代表CPU对Cache的访问命中率,t1表示Cache的周期时间,t2表示主存储器周期时间,设"Cache+主存储器“的系统平均周期为t3,则:
(1-h)又称失效率(未命中率)
Cache的地址映射:
常见的映射方法又直接映射、相联映射、组相联映射。
替换算法:
①随机替换算法
②先进先出替换算法
③近期最少使用算法
④优化替换算法
Cache的命中率必须提高,一般要达 90%以上
局部性原理
主存
磁盘结构和参数
一般使用磁道旋转一周所用的时间的一半作为平均等待时间。
位密度:沿磁道方向,单位长度存储二进制信息的个数。
道密度:沿磁道半径方向,磁盘
非格式化容量公式:
格式化容量公式:
数据传输效率公式:
总线
什么是总线
总线是连接各个部件的信息传输线,使各个部件共享的传输介质
总线的分类
总线分为内部总线、系统总线和通信总线。
系统总线又分为三类,数据总线,地址总线和控制总线。
差错控制
系统可靠性分析与设计
编程语言
Prolog(ProgramminginLogic) 是一种逻辑编程语言
Python、Java、C++ 都是面向对象点解释型计算机程序设计语言
Lisp 是一种函数式编程语言
常见的命名对象又:变量、函数、数据类型
操作系统知识
BIOS系统(基本输入输出系统)
BIOS(Basic Input Output System),是一组固化到计算机内主板上的一个ROM芯片上的程序,它保存着计算机最重要的基本输入输出的程序,开机之后自检程序和系统自启动程序,它可从CMOS中读写系统设置的具体信息。
PV操作
实现进程同步和互斥的常用方法,P操作和V操作是低级通信原语,在执行期间不可分割。
其中P操作表示申请一个资源,V操作表示释放一个资源。
P操作的定义: S:=S-1, 若S>=0,则执行P操作的进程继续执行;若S<0,则将该进程设为阻塞状态,并将其插入阻塞队列。
V操作的定义: S:=S+1,若S>0,则执行V操作的进程继续执行;若S<=0,则从阻塞状态唤醒一个进程,并将其插入就绪队列,然后执行V操作的进程继续。
周期
时钟周期
时钟周期也称为振荡周期,定义为时钟脉冲的倒数(可以这样来理解,时钟周期就是单片机外接晶振的倒数,例如12M的晶振,它的时间周期就是1/12 us),是计算机中最基本的、最小的时间单位。在一个时钟周期内,CPU仅完成一个最基本的动作。
机器周期
在计算机中,为了便于管理,常把一条指令的执行过程划分为若干个阶段,每一阶段完成一项工作。例如,取指令、存储器读、存储器写等,这每一项工作称为一个基本操作。完成一个基本操作所需要的时间称为机器周期。
指令周期
指令周期是执行一条指令所需要的时间,一般由若干个机器周期组成。指令不同,所需的机器周期数也不同。5
中断
计算运行过程中,遇到突发事件,要求CPU暂时停止正在运行的程序,转去为突发事件服务,服务完毕,再自动返回原程序继续执行。
中断时为了提高CPU的工作效率和处理随机发生的事件而设置的。为了保证中断处理完成后能够返回原程序继续执行,必须把中断前的程序断点,通用寄存器内容,程序内容字等保存起来,即保存现场 。等待中断处理完毕,再恢复中断时的断电和通用寄存器的内容等,即恢复现场,以便正确返回原程序继续运行。
数据库技术
数据库基本概念
分片透明
用户或应用程序不需要知道逻辑上访问的表具体是怎么分块存储的。
复制透明
采用复制技术的分布方法,用户不需要知道数据是复制到哪些节点,如何复制的。
位置透明
用户无须知道数据存放的物理位置。
逻辑透明
即局部数据模型透明,是指用户或应用程序无须知道局部场地使用的是哪种数据模型。
Armstrong公理
公理
设U 是关系模式R 的属性集,F 是R 上成立的只涉及U 中属性的函数依赖集。函数依赖的推理规则有以下三条:
自反律:若属性集Y 包含于属性集X,属性集X 包含于U,则X→Y 在R 上成立。(此处X→Y是平凡函数依赖)
增广律:若X→Y 在R 上成立,且属性集Z 包含于属性集U,则XZ→YZ 在R 上成立。
传递律:若X→Y 和 Y→Z在R 上成立,则X →Z 在R 上成立。
其他的所有函数依赖的推理规则可以使用这三条规则推导出。
公理的推论
合并规则:若X→Y,X→Z同时在R上成立,则X→YZ在R上也成立。
分解规则:若X→W在R上成立,且属性集Z包含于W,则X→Z在R上也成立。
伪传递规则:若X→Y在R上成立,且WY→Z,则XW→Z。
完整性约束
完整性约束包括:实体完整性约束、参照完整性约束和用户自定义完整性约束。
数据库规范化理论
数据库中的无损连接分解和是否保持函数依赖的判定
无损连接的判定:
1、若分解后的的关系模式是形如{U1,U2},且
2、如果是两个以上{U1,U2,U3....}
计算机网络
网络互联设备
物理层
中继器:中继器只是简单的信号放大。
数据链路层
交换机
网络层
路由器
三层交换机
网络技术标准与协议
TCP/IP协议(重量级协议)
Internet,可扩展,可靠,应用最广,牺牲速度和效率

ICMP(因特网控制协议)ping控制 DHCP(动态IP地址分配)
ARP(地址解析) IP转MAC TFTP(小文件传输协议)
RARP(反向地址解析) MAC转IP SNMP(简单网络管理协议)
TCP(可靠的协议) 通信时建立连接
UDP(不可靠协议) 通信时不建立连接
POP3协议是适用于C/S结构的脱机模型的电子邮件协议。
SMTP协议是简单的邮件传输协议。
IMAP协议是由美国华盛顿大学所研发的一种邮件获取协议。
MIME协议可提供的安全电子邮件服务。
三次握手🤝协议:
第一次握手:建立连接时,客户端发送syn包到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的syn(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
UDP与TCP的主要区别:
UPD不一定提供可靠的**数据传输。该协议不能保证数据准确无误地到达目的地。
UDP在许多方面非常有效,在数据传输过程中延迟小、数据传输效率高。
当某个程序的目标是尽快地传呼尽可能多的信息时,可使用UDP。
IPX/SPX协议
NOVELL,路由,大型企业网,网络游戏
NETBEUI协议
IBM,非路由,快速
防火墙基础知识
DMZ区
DMZ是指非军事化区,也称周边网络,可以位于防火墙之外也可以位于防火墙之内。非军事化区一般用来防止提供公共网络服务的设备。这些设备由于必须被公共网络访问,所以无法提供与内部网络主机相等的安全性。
使用Web方式收发电子邮件时,必须设置账号密码登录
应用级网关可以工作在OSI七层模型的任意一层上,能够检查进出的数据包,通过网关复制传递数据,防止在受信任服务器和客户机与不受信任的主机间直接建立联系。应用级网关
域名解析
递归查询
主机向本地域名服务器一般采用递归查询
迭代查询
本地域名服务器向根域名服务器查询通迭代查询。
数据结构与算法
算法复杂度
时间复杂度
主项定理Master Method
常用于分析根据递归方程分析算法的时间复杂度
设\(T(n)=aT({n\over b})+h(n) \qquad a\geq 1 \quad;\quad b > 1 \qquad h(n)为不参与递归的复杂度函数\)
判断\(n^{\log_ba}\)与\(h(n)\)的大小关系:
① \(=\Theta(h(n))\) 该方法的复杂度为\(\Theta(h(n)\times \lg n)\)
① \(>\Theta(h(n))\) 该方法的复杂度为\(\Theta(n^{\log_b a})\)
① \(<\Theta(h(n))\) 该方法的复杂度为\(\Theta(h(n))\)
广义表
二叉树
图
排序算法
排序算法比较
| 排序方法 | 最优时间 | 平均时间 | 最坏时间 | 辅助空间 | 是否稳定 |
|---|---|---|---|---|---|
| 选择排序 | O(\(n^2\)) | O(\(n^2\)) | O(\(n^2\)) | O(\(1\)) | 不稳定 |
| 直接插入排序 | O(\(n\)) | O(\(n^2\)) | O(\(n^2\)) | O(\(1\)) | 稳定 |
| 冒泡排序 | O(\(n\)) | O(\(n^2\)) | O(\(n^2\)) | O(\(1\)) | 稳定 |
| 希尔排序 | O(\(n^{1/3}\)) | O(\(n^2\)) | O(\(1\)) | 不稳定 | |
| 快速排序 | O(\(n\log n\)) | O(\(n\log n\)) | O(\(n^2\)) | O(\(\log n\)) | 不稳定 |
| 堆排序 | O(\(n\log n\)) | O(\(n\log n\)) | O(\(n\log n\)) | O(\(n\log n\)) | 不稳定 |
| 归并排序 | O(\(n\log n\)) | O(\(n\log n\)) | O(\(n\log n\)) | O(\(n\)) | 稳定 |
KMP算法
计算next数组
next数组是模版串每一位及其之前的字符串中,前缀和后缀公共部分的最大长度的集合。
计算机安全知识
加密算法
对称加密算法(加密时输入的密码与解密时输入的密码一致)
DES算法
DES是一种迭代的分组密码,输入/输出都是64位,使用一个56位的密钥和附加的8位奇偶校验位。攻击DES的主要技术是穷举。
由于DES的密钥长度较短,为了提高安全性,出现了使用112位密钥对数据进行三次加密的算法,称为3DES.
IDEA算法
128位密钥、64位数据块。比DES的加密性好,对计算机功能要求相对低,PGP。
RC-5算法
RC-5是一种对称密码算法,使用可变参数的分组迭代密码体制,其中可变参数为分组长(为2倍字长w位),密钥长(按字节数计b)和迭代轮数(以RC-5-w/r/b)。
非对称加密技术(加密密码与解密密码不一致)
RSA算法
ECC算法
加密算法中,对称加密算法比非对称加密效率要高
信息摘要
MD5消息摘要算法:是一种被广泛使用的密码散列函数,可以产生处一个128位(16字节)的散列值,用于验证信息传输的完整性,MD5的典型应用即数字签名。
数字签名
SHA-I安全哈希算法:主要适用于数字签名标准里面定义的数字签名算法,SHA-I会产生一个
位的消息摘要。
数字信封与PGP
PGP是一个基于RSA公钥加密体系的邮件加密系统。
网络安全漏洞
网络安全漏洞通常是指网络节点的系统软件或应用软件在逻辑上的缺陷。
编译原理
语法制导翻译
基于属性文法的处理过程,对单词符号串进行语法分析,构造语法分析树,然后根据需要构造属性依赖图,遍历语法图并再语法树的各结点处按语义规则进行计算。
系统开发和运行知识
结构化分析的输出
结构化分析输出结果由以下几部分组成:
分层的数据流图、数据词典、加工逻辑说明(小说明)、补充材料
软件活动
软件描述
软件开发
软件有效性验证
软件进化
统一过程(UP)
统一过程主要分五个阶段:开启阶段(inception),细化阶段(elaboration),构建阶段(construction),移交阶段(transition),生产(production),每个阶段达到某个里程碑时结束。
初启阶段:里程碑是生命周期目标
精化阶段:里程碑是生命周期框架
构建阶段:里程碑是生命周期架构
移交阶段:里程碑是初始运作功能
产生阶段:里程碑是产品发布
软件过程模型
软件过程模型就是一种开发策略,这种策略针对软件工程的各个阶段提供了一套范形,使工程的进展达到预期的目的。
瀑布模型
原型模型:适用于需求不明确
快速原型模型
增量模型
螺旋模型:集成了瀑布模型和快速原型模型的优点,加入风险分析
V模型
喷泉模型:面向对象的软件过程模型
软件能力成熟度模型(CMM)
初始级(initial):工作无序,项目进行过程中常放弃当初的计划。管理无章法,缺乏健全的管理制度。开发项目成效不稳定,项目成功主要依靠项目负责人的经验和能力,他一但离去,工作秩序面目全非。
可重复级(Repeatable):管理制度化,建立了基本的管理制度和规程,管理工作有章可循。 初步实现标准化,开发工作比较好地按标准实施。 变更依法进行,做到基线化,稳定可跟踪,新项目的计划和管理基于过去的实践经
验,具有重复以前成功项目的环境和条件。
已定义级(Defined):开发过程,包括技术工作和管理工作,均已实现标准化、文档化。建立了完善的培训制度和专家评审制度,全部技术活动和管理活动均可控制,对项目进行中的过程、岗位和职责均有共同的理解 。
已管理级(Managed):产品和过程已建立了定量的质量目标。开发活动中的生产率和质量是可量度的。已建立过程数据库。已实现项目产品和过程的控制。可预测过程和产品质量趋势,如预测偏差,实现及时纠正。
优化级(Optimizing):可集中精力改进过程,采用新技术、新方法。拥有防止出现缺陷、识别薄弱环节以及加以改进的手段。可取得过程有效性的统计数据,并可据进行分析,从而得出最佳方法。
能力成熟度模型集成(CMMI)
CL0(未完成的):过程域未执行或未得到CL1中定义的所有目标。
CL1(已执行的):过程将可标识的输入工作产品转换成可标识的输出工作产品,以实现支持过程域的特定目标。
CL2(已管理的):集中于已管理的过程的制度化。
CL3(已定义的):集中于已定义的过程的制度化。
CL4(定量管理的):集中于可定量管理的过程的制度化。
CL5(优化的):使用量化(统计学)手段改变和优化过程域,以满足客户要求的改变和持续改进计划中的过程域的功效。
工作量估算模型COCOMOII
在COCOMOII中规模表示为源代码千行数(KSLOC)。常用的方法有工作分解结构、类比评估技术、Parkson原则、专家判定技术、功能点分析法等。
功能点分析法是基于数学理论,适用于项目等各个阶段,是COCOMOII提倡的一种方法。有三种不同的规模估算选择:对象点、功能点、代码行。
ISO/IEC 9126软件质量模型

ISO/IEC 9126软件质量标准包括6个质量特性和21个质量子特性
(1)功能性(Functionality):
功能性是指与软件所具有的各项功能及其规定性质有关的一组属性。
a:适合性(Suitability):与规定任务能否提供一组功能以及这组功能的适合程度有关的软件属性。适合程度的例子是面向任务系统中,由子功能构成功能是否合适、表容量是否合适等。
b:准确性(Accuracy):于能否得到正确或相符的结果或效果有关的软件属性。此属性包括计算值所需的准确程度。
c:互操作性(互用性,Interoperability):与同其他指定系统进行交互的能力有关的软件属性。为避免可能与可替换性的含义相混淆,此处用互操作性(互用性)而不用兼容性。
d:依从性(Compliance):使软件遵循有关的标准、约定、法规及类似规定的软件属性。
e:安全性(Security):以防止对程序及数据的非授权的故意或意外访问的能力有关的软件属性。
(2)可靠性(Reliability)
可靠性是指在规定运行条件下和规定时间周期内,与软件维护其性能级别的能力有关的一组属性。
可靠性反映的是软件中存在的需求错误、设计错误和实现错误而造成的失效情况:
a:成熟性(Maturity):与由软件故障引起失效的频度有关的软件属性。
b:容错性(Fault Tolerance):与在软件故障或违反指定接口的情况下,维持规定的性能水平的能力有关的软件属性。指定的性能水平包括失效防护能力。
c:可恢复性(Recoverability):与在失效发生后重建其性能水平并恢复直接受影响数据的能力,以及为达此目的所需的事件和努力有关的软件属性。
(3)可用性(Usability):可用性是指根据规定用户或隐含用户的评估所做出的关于与使用软件所需要的努力程度有关的一组属性。包括:
a:可理解性(Understandability):与用户为认识逻辑概念及其应用范围所花的努力有关的软件属性。
b:易学性(Learnability):与用户为认识逻辑概念及其应用范围所花的努力有关的软件属性。
c:可操作性(Operability):与用户为操作和运行控制所需的努力有关的软件属性。
(4)效率(Efficiency):效率是指在规定条件下,与软件性能级别和所使用资源总量之间的关系有关的一组属性。包括:
a:时间特性(Time Behaviour):与软件执行其功能时响应和处理事件及吞吐量有关的软件属性。
b:资源特性(Resource Behaviour):与在软件执行其功能时所使用的资源数量及其使用时间有关的软件属性。
(5)可维护性(Maintainability):可维护性是指与软件进行修改的难易程度有关的一组属性。包括:
a:可分析性(Analysability):与为诊断缺陷 或失效原因及为判定待修改的部分所需努力有关的软件属性。
b:可改变性(Changeability):与进行修改、排除错误或适应环境变化所需努力有关的软件属性。
c:稳定性(Stability):与修改所造成的未预料结果的风险有关的软件属性。
d:可测试性(Testability):与确认已修改软件所需的努力有关的软件属性。此子特性的含义可能会被研究中的修改加以改变。
(6)可移植性(Portability):可移植性是指与一个软件从一个环境转移到另一个环境运行的能力有关的一组属性。包括:
a:适应性(Adaptability):与软件无须采用有别于为该软件准备的活动或手段就可能适应不同的规定环境有关的软件属性。
b:可安装性(Installability):与在指定环境下安装软件所需努力有关的软件属性。
c:依从性(一致性,Conformance):使软件遵循与可移植性有关的标准或约定的软件属性。
d:可替换性(Replaceability):与软件在该软件环境中用来替代指定的其他软件的机会和努力有关的软件属性。为避免和互用性的含义混淆,此处用可替换性而不用兼容性。
内聚和耦合
内聚:(由低到高)
①偶然内聚:模块间毫无关系
②逻辑内聚:几个逻辑上相关的功能被放在同一个模块中。
③时间内聚:一个模块完成的功能必须再同一模块中。
④过程内聚:一个模块内部的处理成分是相关的,且必须以待定的次序执行。
⑤通信内聚:一个模块的所有成分都作同一个数据集。
⑥顺序内聚:一个成分的输出作为另一个成分的输出。
⑦功能内聚:模块的所有成分对于完成单一功能都是必须的。
耦合:(由强到弱)
①内容耦合:一个模块直接修改或作为另一个模块的数据。
②公共耦合:共同引用一个全局数据项。
③控制耦合:一个模块再界面上传递一个信号控制另一个模块。
④标记耦合:模块间通过参数传递复杂的内部数据结构。
⑤数据耦合:模块间通过参数传递基本类型的数据。
⑥非直接耦合:模块间没有信息传递。
耦合度
耦合是模块之间的相对独立性(互相连接的紧密程度)的度量。
耦合的强弱取决于模块间接口的复杂度、调用模块的方式、通过界面传送数据的多少。
模块间的耦合度是指模块之间的依赖关系,包括控制关系、调用关系、数据传递关系。
模块间联系越多,其耦合性越强,同时表示其独立性越差(降低耦合性,可以提高其独立性)。
软件调试方法
归纳法 :从测试所暴露的问题出发,收集所有正确或不正确的数据,分析他们之间的关系,提出假想的错误原因,用这些数据来证明或反驳,从而查出错误所在。
试探法 :调试人员分析错误的症状,猜测问题所在的位置,利用再程序中设置输出语句,分析寄存器,存储器的内容等手段获得错误的线索,一步步地试探和分析错误的所在。这种方法效率低,适合结构比较简单的程序。
回溯法 :调试人员从发现错误的位置开始,人工沿着程序的控制流程往回跟踪代码,直至找到错误根源为止。
对分查找法:这种方法主要用于缩小错误范围,如果已经知道程序中的变量再若干位置的正确取值,可以再这些位置上给这些变量以正确值,观察程序运行的输出结果。
演绎法 :根据测试结果,列出所有可能的错误;分析已有的数据,排除不可能和彼此矛盾的原因;对其余的原因,选择可能性最大的,利用已有的数据完善该假设,使假设更具体;用假设来解释所有的原始测试结果,如果成立,则假设证实。
软件维护工具
1.版本控制工具
2.文档分析工具
3.开发信息库工具
4.逆向工程工具
5.再工程工具
6.配置管理支持工具
面向对象设计原则
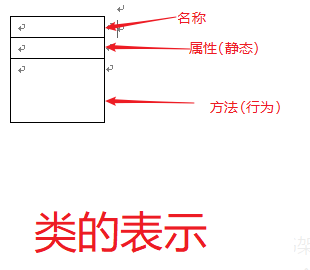
类
类可以分为三种类型,分别是实体类、边界类、控制类。
实体类
存储和管理系统内部的信息,它可可以有行为,但这些行为必须与它所代表的实验对象密切相关。
控制类
用于描述外部参与者与系统之间的交互,它位于系统和外部边界的交接处,包括所有的窗体、报表、打印机和扫描仪等硬件的接口,以及与其他系统的接口。
边界类
设计模式的分类
创建型模式
| 设计模式 | 说明 |
|---|---|
| 抽象工厂模式(Abstract Factory) | 提供一系列接口,可以创建一系列相关或相互依赖的对象,而无需指定它们 具体的类。 |
| 构建器模式(Builder) | 将一个复杂类的表示与其构造相分离,使得相同的构建过程能够得出不同的表示。 |
| 工厂方法模式(Factory Method) | 定义一个创建对象的接口,但由于子类决定需要实例化哪一个类。工厂方法使得子类实例化的过程推迟。 |
| 原型模式(Prototype) | 用原型实例指定创建对象的类型,并且通过拷贝这个原型来创建新的对象。 |
| 单例模式(Singleton) | 保证一个类只有一个实例,并且提供一个访问它的全局访问点。 |
结构型模式
| 设计模式 | 说明 | 关键字 |
|---|---|---|
| 适配器模式(Adapter) | 将一个类的接口转换成用户希望得到的另一种接口。它使原本不相容的接口得以协同工作。 | 转接接口 |
| 桥接模式(Bridge) | 将类的抽象部分和它的实现部分分离开来,使它们可以独立地变化。 | 继承树拆分 |
| 组合模式(Composite) | 将对象组合成树型结构以表示“整体-部分”的层次结构,使得用户对单个对象和组合对象的使用具有一致性。 | 树形目录结构 |
| 装饰模式(Decorator) | 动态地给一个对象添加一些额外的职责。它提供了用子类扩展功能的一个灵活的替代,比派生一个子类更加灵活。 | 附加职责 |
| 外观模式(Facade) | 定义一个高层接口,为子系统中的一组接口提供一个一致的外观,从而简化了该子系统的使用。 | 对外统一接口 |
| 享元模式(Flyweight) | 提供支持大量细粒度对象共享的有效方法。 | |
| 代理模式(Proxy) | 为其他对象提供一种代理以控制这个对象的访问。 |
行为型模式
| 设计模式 | 说明 | 关键字 |
|---|---|---|
| 职责链模式(Chain Of Responsibility) | 通过给多个对象处理请求的机会,减少请求的发送者于接收者之间的耦合。将接收对象链接起来,在链中传递请求,直到有一个对象处理这个请求。 | 传递职责 |
| 命令模式(Command) | 将一个请求封装为一个对象,从而可用不同的请求对客户进行参数化,将请求排队或记录请求日志,支持可撤销的操作。 | 日志记录,可撤销 |
| 解释器模式(Interpreter) | 给定一种语言,定义它的文法表示,并定义一个解释器,该解释器用来根据文法表示来解释语言中的句子。 | |
| 迭代器模式(Iterator) | 提供一种方法来顺序访问一个聚合对象中的各个元素而不需要暴露该对象的内部表示。 | |
| 中介者模式(Mediator) | 用一个中介对象来封装以系列的对象交互。它使各对象不需要显式地相互调用。从而达到低耦合,还可以独立地改变对象间的交互。 | 不直接引用 |
| 备忘录模式(Memento) | 在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,从而可以在以后将该对象恢复到原先保存的状态。 | |
| 观察者模式(Observer) | 定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并自动更新。 | |
| 状态模式(State) | 允许一个对象在其内部状态改变时改变它的行为。 | 状态变成类 |
| 策略模式(Strategy) | 定义一系列算法,把它们一个个封装起来,并且使它们之间可互相替换,从而让算法可以独立于使用它的用户而变化。 | 多方案切换 |
| 模板方法模式(Template Method) | 定义一个操作中的算法骨架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构即可重新定义算法的某些特定步骤。 | |
| 访问者模式(Visitor) | 表示一个作用于某对象结构中的各元素的操作,使得在不改变各元素的类的前提下定义作用于这些元素的新操作。 |
数据流图(DFD)
数据流图基本概念
数据流图中的基本图形元素包括数据流、加工、数据存储和外部实体。其中,数据流、加工和数据存储用于构建系统内部的数据处理模型,而外部实体表示存在于系统之外的对象。
UML建模
静态结构:主要包括用例图、类图、和包图
动态结构:主要包括活动图、状态图、序列图和协作图。
交互视图:描述了执行系统功能的各个角色之间相互传递消息的顺序关系,主要包括序列图、协作图
UML4种关系
关联关系:是一种拥有的关系,它使一个类知道另一个类的属性和方法。

聚合关系:聚合是关联的特例。聚合关系中的总体和部分是能够分离的,他们能够具有各自的生命周期,部分能够数据多个总体对象。

组合关系:组合关系式关联关系的一种特例。这样的关系比聚合更强。它相同也体现了总体与部分的关系。

依赖关系:依赖关系式类与类之间的连接,表示一个类依赖于还有一个类的定义。bind、friend.

泛化关系:泛化关系式一个类(子类、子接口)继承另外一个类(父类、父接口)的功能。

实现关系:实现关系指的是一个class类实现interface接口(能够是多个)的功能。

用例图
用例图是用来描述系统功能的技术,表示一个系统中用例与参与者及其关系的图,主要用于需求分析阶段。
用例图的基本组成元素:参与者、用例、元素之间的关系。
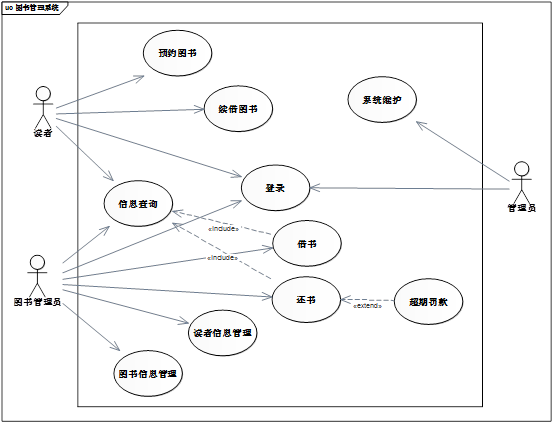
用例间的关系
泛化关系
与参与者的泛化关系相似,用例的泛化关系将特化的用例与一般化的用例联系起来。子用例继承了父用例的属性、操作和行为序列,并且可以增加属于自己的附加属性和操作。父用例同样可以定义为抽象用例。

用例之间的泛化关系表示为一根实线三角箭头,箭头指向父用例一方。
依赖关系(包含、扩展)
包含关系
包含指的是一个用例(基用例)可以包含其他用例(包含用例)具有的行为,其中包含用例中定义的行为将被插入基用例定义的行为中。
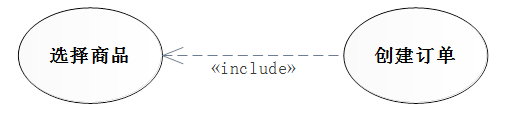
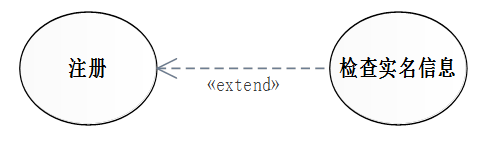
扩展关系
扩展指的是一个用例(扩展用例)对另一个用例(基用例)行为的增强。
包含、扩展的区别:
根本区别,包含是无条件执行,扩展是有条件执行。图的起点不同,终点也不同。
| 特性 | include | extend |
|---|---|---|
| 作用 | 增强基用例的行为 | 增强基用例的行为 |
| 执行过程 | 包含用例一定会执行 | 扩展用例可能被执行 |
| 对基用例的要求 | 再没有包含用例的情况下,基用例可用是也可以不是良构的 | 在没有扩展用例的情况下,基用例一定是良构的 |
| 表示法 | 箭头指向包含用例 | 箭头指向基用例 |
| 基用例对增强行为的可见性 | 基用例可用看到包含用例,并决定包含用例的执行 | 基用例对扩展用例一无所知 |
| 基用例每执行一次,增强行为的执行次数 | 只执行一次 | 取决于条件(0到多次) |
类图与对象图
顺序图
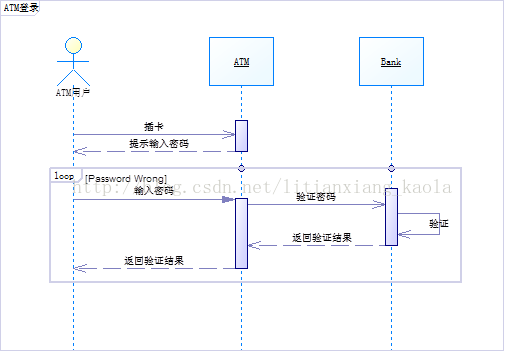
活动图
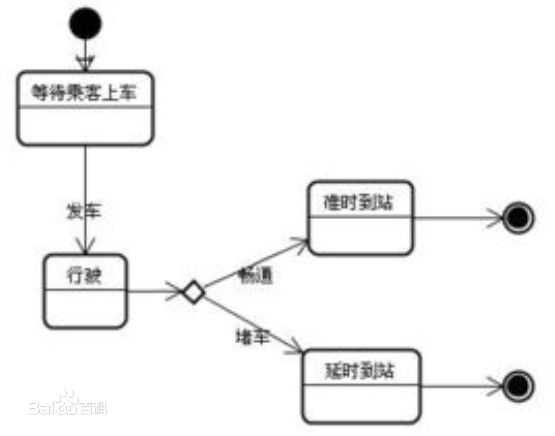
状态图
通信图
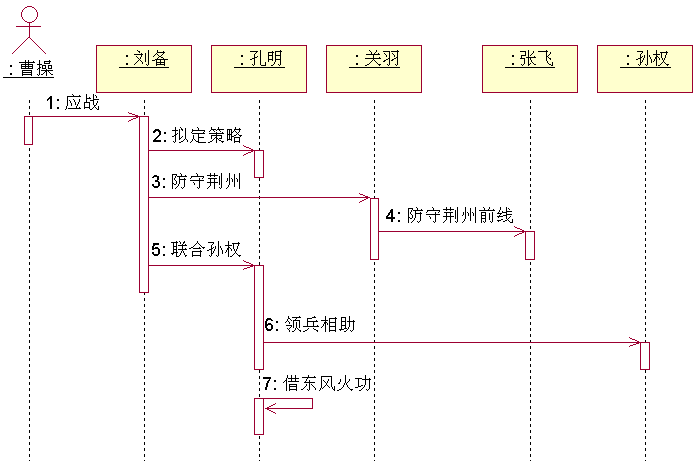
时序图
UML时序图(序列图)是一种交互图,它由一组对象或参与者以及它们之间可能发送的消息构成。
构成序列图的基本元素包括对象、生命线、消息
协作图
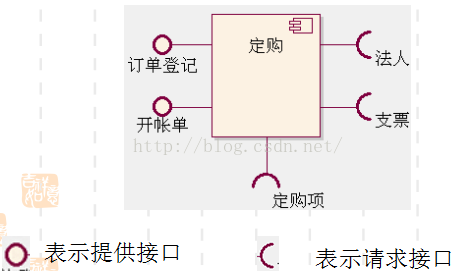
构件图(Component Diagram)
构件图 = 构件(Component) + 接口(Interface) + 关系(Relationship) + 端口(Port) + 连接器(Connector)
构件图是用来表示系统中构件与构件之间,类或接口与构件之间的关系图。由源代码文件、二进制代码文件、可执行文件或动态链接库等构件构成,并通过依赖关系相连接。
构件图用于表示系统的静态设计实现视图
在面向对象系统的物理方面进行建模要用到两种图:组件图和配置图。
2、接口
供接口用“棒棒糖”式的图形表示,即由一个封闭的圆形与一条直线组成。
需接口用“插座”式的图形表示,即由一个半圆与一条直线组成。
法律知识
软件著作权
软件著作权人,是指依法享有软件著作权等自然人、法人或其他组织。
软件著作权自软件开发完成之日起产生。
保护期限
| 权力类型 | 保护期限 |
|---|---|
| 署名权、修改权、保护作品完整权 | 没有限制 |
| 发表权、使用权、获得报酬权、发行权、出租权、信息网络传播权、翻译权、使用许可权、转让权 | 作者终生及其死亡后的50年 |
| 注册商标 | 有效期10年(若注册人死亡或倒闭1年后,未转移则可注销,期满后6个月内容必须续注) |
| 发明专利权 | 保护期20年(从申请日起) |
| 实用新型和外观设计专利权 | 保护期未10年(从申请日开始) |
| 商业秘密 | 不确定,公开后公众可用 |
商标权可用通过续注延长拥有期限,而著作权、专利权和设计权的保护期限都是有限期的。A

 浙公网安备 33010602011771号
浙公网安备 33010602011771号