对于Python中的字节串bytes和字符串以及转义字符的新的认识
事情的起因是之前同学叫我帮他用Python修改一个压缩包的二进制内容用来做fuzz,根据他的要求,把压缩包test.rar以十六进制的方式打开,每次修改其中一个十六进制字符串并保存为一个新的rar用来fuzz,于是我本来的打算是用传统的
open()函数来实现
file = open('test.rar','rb')
data = file.read()
通过open函数以二进制的方式打开,因为在Python中对二进制流的处理十分简单粗暴,默认的是以字节串bytes来表示的,形式则是以十六进制,比如b'\xff\x0f',可问题出现了,print(data)输出的字节串中的每一个十六进制数和使用工具hexedit打开显示的不完全一样,上例子

而Python中默认的输出结果为
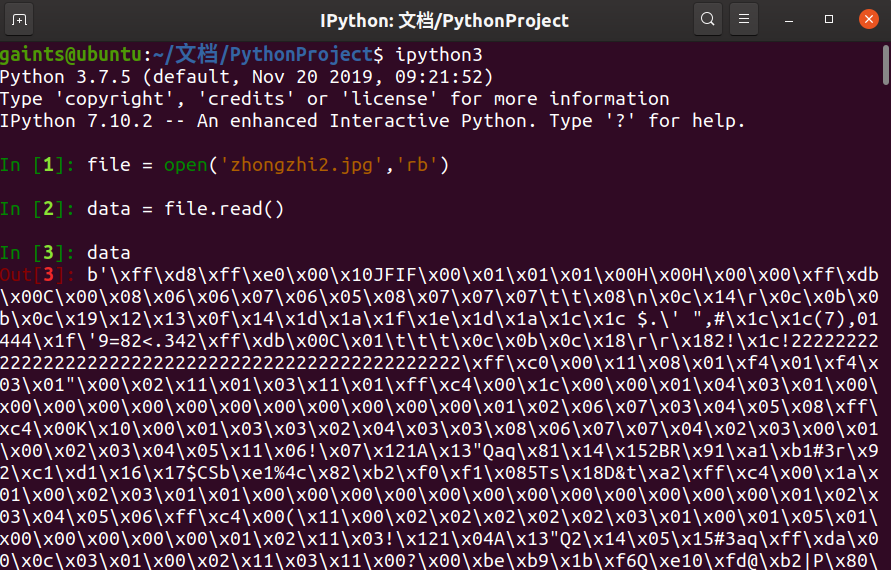
对照一看可以发现ff d8 ff e0 00 10 4a 46,而Python中是ff d8 ff e0 00 10 JFIF,不对,这是为啥?
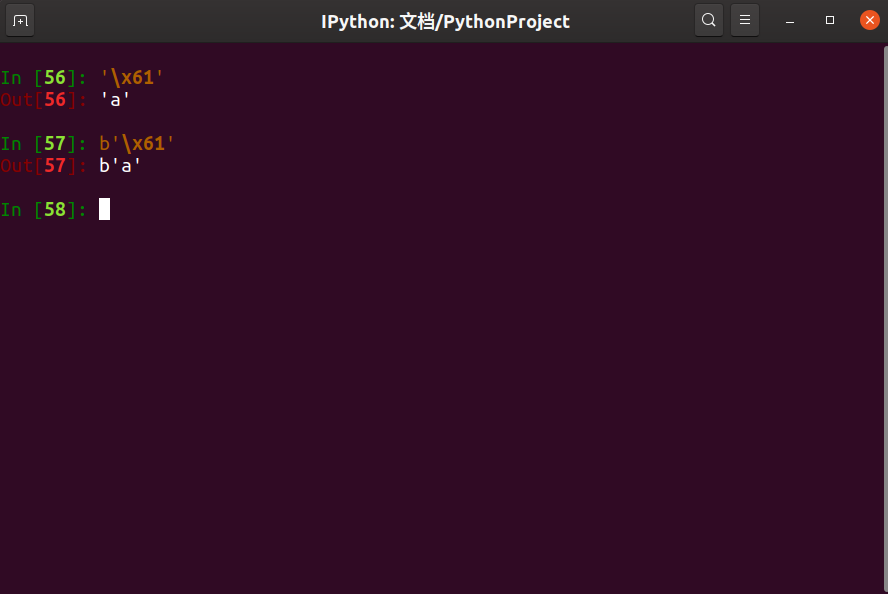
这就要说到Python中默认的转义机制了,通常我门知道的转义字符无非是\r \n \t等等,但是Python默认支持\x + 十六进制的转义字符,比如转义字符\x61,在终端输入\x61,返回的结果是字母a,而这是转义字符,它是字符串,如果是字节串形式的呢?答案是一样的
b'\x61' == b'a',OK,水落石出,Python默认情况下当遇到符合转义字符的字符串时会自动将他们转义,也就是说,在上面的hexedit中,'4a464946'的转义结果其实就是'JFIF',下面上证明:
按理来说,'a'编码后的字节串应为b'\x61',但在终端中使用encode编码之后结果显示是这样的:
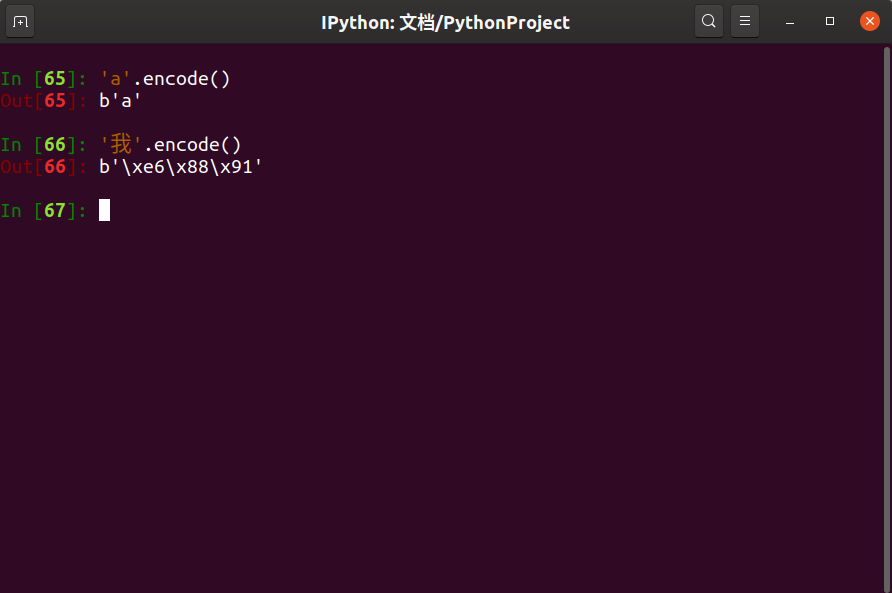
编码过后的字节串依然被Python给转义了,服
可见,无论是单纯的字符串还是字节串,只要符合转义,Python解释器会默认将其转义。
Python中有一个bytes类,其中一个方法fromhex()可以直接将十六进制字符转换为字节串形式,例如:
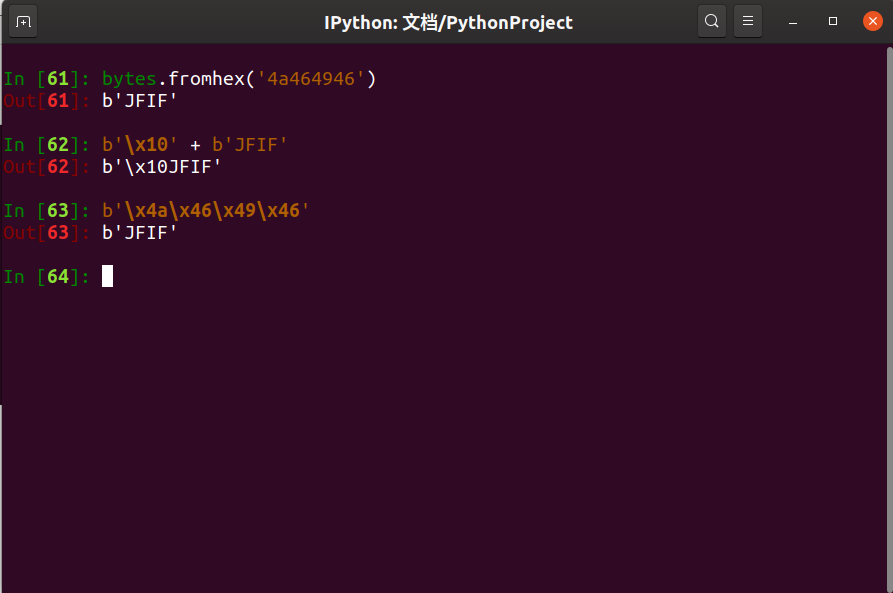
情况如上,也就是说其实Python的输出是没错的但是表现形式不一样而已,而原因就是它默认的转义机制。
下面介绍几个常用的关于字节串bytes和十六进制和十进制互相转换的方法
(1)
print(bin(1))#以二进制表示
print(hex(255))#将0-255内的十进制整数以十六进制表示(还是字符串)
print(ord('\x0f'),' ',ord(b'\xff'))#将十六进制转义字符串和字节串转换为十进制数字
print(bytes.fromhex('ff')) #将十六进制字符串转换为字节串
for i in '\xff\x0f':
print(i)#print默认会解码这些转义字符
for i in b'\xff\x0f':
print(i)#默然输出的是每个字节的十进制整数 %x表示将其格式化为十六进制字符串 字节串也是可迭代对象,但是没有字符串自带的方法多。
0b1
0xff
15 255
b'\xff'
ÿ
255
15
以后更新以十六进制读取任意文件并修改字节


 浙公网安备 33010602011771号
浙公网安备 33010602011771号