selenium模块
selenium模块
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
所以我们可以用selenium模块可以比requests多做这么几件事:
- 执行js代码
- 仿真浏览器操作,就像人在操作浏览器一样
准备工作:
# 安装模块
pip install selenium
# 根据不同的浏览器,安装浏览器驱动,如谷歌浏览器,访问以下路径
https://registry.npmmirror.com/binary.html?path=chromedriver/
# 上述路径,是一个镜像站,集合了很多浏览器驱动
在网站中,我们需要对应浏览器驱动的版本来下载驱动:
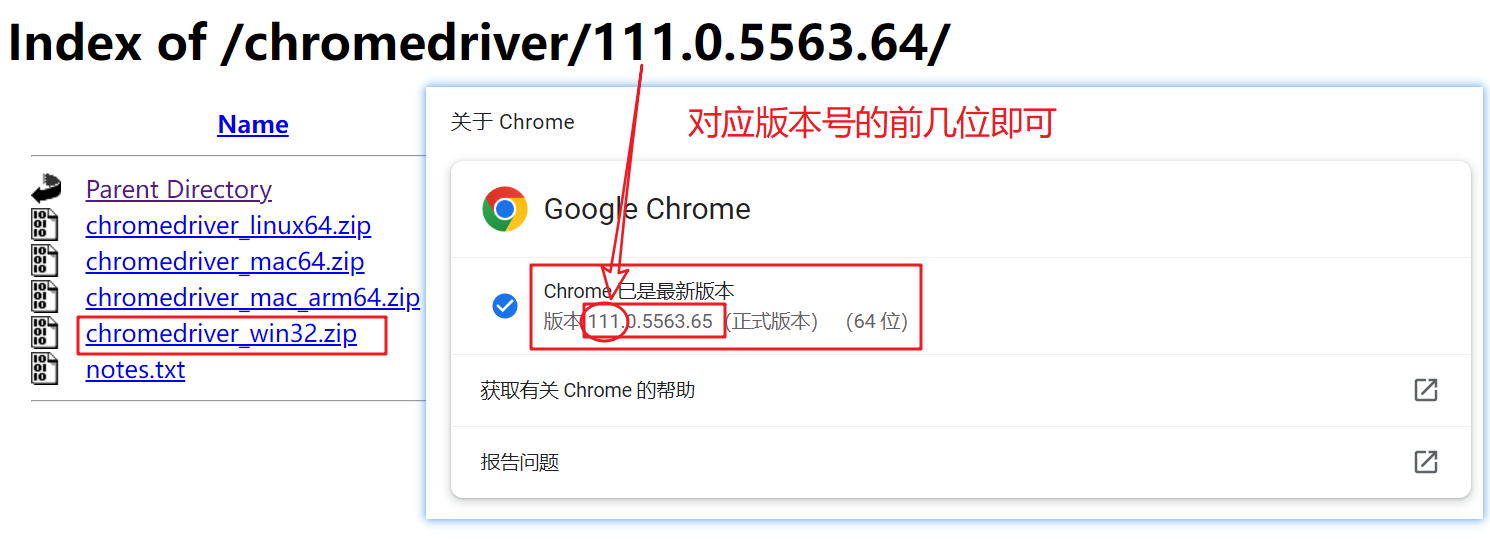
下载压缩包后,进行解压缩,将其中的执行文件chromedriver.exe放在合适的位置。
基础使用
打开浏览器
from selenium import webdriver
browser = webdriver.Chrome(executable_path='chromedriver.exe')
# Chrome就是打开谷歌浏览器,需要指定驱动的路径
访问页面
from selenium import webdriver
import time
browser = webdriver.Chrome(executable_path='chromedriver.exe')
browser.get('https://www.baidu.com/s?ie=UTF-8&wd=%E4%BD%A0%E4%B8%AA%E5%B8%85%E9%80%BC') # 输入一个网址,browser就会去往那个网址
time.sleep(8)
程序结束时,似乎因为浏览器对象被回收的原因,会自动关闭页面,所以sleep几秒看看打开的界面是什么样。
取出当前页面内容
browser.page_source # html格式的文本
无界面浏览
selenium模块提供了一些浏览的选项,以提升程序访问页面的效率。
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
# 指定浏览器分辨率
chrome_options.add_argument('window-size=1920x3000')
# 隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('--hide-scrollbars')
# 不加载图片, 提升速度
chrome_options.add_argument('blink-settings=imagesEnabled=false')
# 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
chrome_options.add_argument('--headless')
# 手动指定使用的浏览器位置(指定驱动,如果option配置了,到时候就不需要用executable_path指定了)
chrome_options.binary_location = r"chromedriver.exe"
# 开启浏览器
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('网址')
# 类似于timeout,等待加载,但最多等10秒
browser.implicitly_wait(10)
# 打印一下结果,验证我们虽然隐藏了界面,但真的请求到了数据
print(browser.page_source)
基础用法总结
-
webdriver.Chrome(chrome_options=chrome_options)按配置产生浏览器对象,假设寄存于变量browser -
option配置可指定分辨率、滚动条、图片加载、显示界面、浏览器驱动等。 -
browser的属性和方法属性 含义 get('网址') 在地址栏键入网址访问 page_source 请求当前页面资源文本 implicitly_wait(sec) 等待页面加载,最多等待sec秒
更多使用
查找标签
from selenium.webdriver.common.by import By
by = By.ID # 根据标签的id属性查找
value = 'login' # 查找的值为login
browser.find_element(by, value) # 找一个,结果为标签
browser.find_elements(by, value) # 找所有,组织为列表
查找的标签依据By所提供的查找方式:
| 类型 | 含义 |
|---|---|
| ID | id属性 |
| NAME | name属性 |
| TAG_NAME | 标签类型 |
| CLASS_NAME | 类class属性 |
| LINK_TEXT | 标签内部文本 |
| PARTIAL_LINK_TEXT | 标签文本模糊匹配 |
| CSS_SELECTOR | CSS选择器 |
都通过value值来提供最终查找的值,如:
# 查找id为d1的标签的所有p儿子标签
browser.find_elements(by=By.CSS_SELECTOR, value='#d1>p')
# 查找登录按钮(特征是内部文本时登录)
btn=browser.find_element(by=By.LINK_TEXT, value='登录')
获取标签属性
上一步查找标签中,会返回一个标签对象,假设存于变量tag
tag对象会有以下属性:
| 属性 | 含义 |
|---|---|
| tag.get_attribute('属性名') | 拿标签中指定属性的值 |
| tag.id | 常用的id属性值 |
| tag.location | 标签的位置信息 |
| tag.tag_name | 标签的类型,如a标签为a |
| tag.size | 标签的尺寸信息 |
等待元素被加载
有两种等待,但是一般只用上文提到的那种:
| browser.implicitly_wait(10) |
|---|
等待浏览器加载标签,但是指定时间后没有加载出则抛异常。
元素和浏览器操作
我们在获取tag和browser对象后,可以对其进行一些事件操作:
| 方法 | 操作 |
|---|---|
| tag.click() | 点击标签 |
| tag.send_keys() | input标签输入内容 |
| tag.clear() | input标签清空内容 |
| browser.maximize_window() | 浏览器窗口最大化 |
| browser.save_screenshot('main.png') | 截屏保存到指定路径 |
| browser.window_handles | 选项卡列表 |
| browser.switch_to.window(browser.window_handles[0]) | 切换到第一个选项卡 |
| browser.switch_to.frame('frame的id') | 切换到id值为指定id的frame标签 |
| browser.get_cookies() | 获取该界面的所有cookie,拿到列表套字典 |
| browser.add_cookie(cookie) | 向浏览器中添加cookie |
| browser.back() | 返回上一界面 |
| browser.forward() | 向前一个界面 |

诸如此类还有很多,这里不多赘述,总的来说就是人能进行的浏览器操作都有对应的对象方法可以用。
执行js代码
对应开发者模式下,我们可以在控制台执行js代码。
browser.execute_script('js语句') # 引号内部的相当于用script标签包裹了
我们可以用此功能完成以下的功能:
滚动浏览器屏幕
browser.execute_script('scrollTo(0,document.documentElement.scrollHeight)')
打卡新的选项卡(新页面)
browser.execute_script('window.open()')
有时候,selnium提供给我们的标签方法,如click会失效(可能是因为反扒检测到了),那么我们就可以用执行js代码的方式去执行,需要在execute_script中传入额外的参数execute_script(js语句,参数1,参数2),这时js代码中需要对这些参数进行处理,如下。
login_btn = bro.find_element(By.LINK_TEXT, '登录')
browser.execute_script("arguments[0].click()", login_btn) # arguments是对额外参数的总结,可以插入到js语句中。
动作链
selnium支持一些基础动作以外的动作,如按住鼠标拖动等,这有时可以用于滑动验证码等动作。
drag_and_drop拿起一个标签并放到某个位置,这个动作是跃迁式的,可能会被检测到不是人的动作
actions=ActionChains(bro) #拿到动作链对象
actions.drag_and_drop(sourse,target) #把动作放到动作链中,准备串行执行
actions.perform()
click_and_hold 将鼠标按住
move_by_offset 按偏移量移动
# 按照匀速的向右侧移动
ActionChains(bro).click_and_hold(sourse).perform()
distance=target.location['x']-sourse.location['x']
track=0
while track < distance:
ActionChains(bro).move_by_offset(xoffset=2,yoffset=0).perform()
track+=2
其实这匀速的运动也可能被一些策略给检测到,但是爬取和反扒就是互相过招。
