python模块之requests模块
requests模块
主要就是使用python的内置模块urllib,模拟浏览器发送http请求,比起内置模块urllib,requests更加便捷
pip install requests
requests发送请求
请求类型
发送get请求和post请求:
import requests
requests.get('访问网址')
requests.post('访问网址')
携带参数和请求头
requests.get('网址?xxx=xxx&yyy=yyy')
requests.get('网址',params={'name':"lqz",'age':19})
requests.get('网址',headers={'cookies':"blabla","User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'})
现在很多网站都有防爬意识,所以会在检测请求头和cookies等内容,来校验你是否是通过正常渠道来访问网站的,当然这种简单的防爬措施也容易绕过
url编码解码
请求参数中,如果是有中文,那么在地址栏中会做url的编码,如彭于晏:%E5%BD%AD%E4%BA%8E%E6%99%8F
这个编码在内置模块中可以通过
from urllib.parse import quote,unquote
print(quote('彭于晏')) # url编码
print(unquote('%E5%BD%AD%E4%BA%8E%E6%99%8F')) # url解码
携带请求体数据
携带请求体数据的方式有三种:
- urlencoded
- application/json
- form-data
# urlencoded格式用data传
requests.get('网址',data={'query_id':"111111",'password':'sdfsdf='})
# json格式数据用json传
requests.post(url='网址',json={'xxx':'yyy'})
# 携带请求头,指定数据类型
requests.post(url='xxxx',
data={'xx':1,},
headers={
'content-type':'application/json'
})
携带cookie
cookie其实也是作为请求头数据,只是浏览器会有自动程序对cookie做存储处理,所以比较重要,一般http相关的模块都会对其开设单独的方法。
cookies='从浏览器网路请求中复制过来'
requests.get('网址',cookies=cookies)
requests.session
session是requests的一个方法,它会产生一个session对象,继承了requests发送请求的方法。
并且会将响应数据中的cookies存储到session对象中,下一次再用session发送请求时,就会自动携带上次响应返回的cookies数据了,这种一般用于请求头中返回cookies信息的接口,如登录接口:
data = {
'username': '',
'password': '',
}
session = requests.session()
session.post('登录接口网址',data=data)
session.get('其他需要登录认证的网址') # 自动将登录信息也携带了
响应对象Response
requests进行请求后,会得到一个响应对象的返回值,这个响应对象是一个Response对象,它有:
| 属性 | 含义 |
|---|---|
| text | 响应体的字符串 |
| content | 响应体的二进制 |
| iter_content | 二进制内容迭代对象(下载图片视频) |
| json() | 有些http请求回来的是json数据,那么可以直接通过这个方法转成对应格式的数据 |
| status_code | 响应状态码 |
| headers | 响应头 |
| cookies | cookies属性 |
| cookies.items() | cookies的键值对 |
| url | 请求地址 |
| history | 重定向前的请求地址 |
| encoding | 响应编码格式 |
ps:Response的内容,凭借我们的经验,大概可以分为这几种:静态xml文件、静态资源(各类文件)、接口返的json数据
requests其他功能
ssl认证
http协议明文传输,而https协议其实就是http协议+ssl/tls协议
HTTPS 存在不同于 HTTP 的默认端口及一个加密/身份验证层(在HTTP与TCP之间)
简单来说ssl层为http传输增加了安全加密的属性,客户端和服务端传输之前,会让服务端将证书发给客户端查看,证书有误时,是否继续通讯由用户决定。
那么在我们使用requests发送请求时,会偶现一些网站没有证书或证书过期,则会给我们的批量请求带来不便。有以下几个方法解决此问题:
-
不验证证书
respone=requests.get('https://www.12306.cn',verify=False) -
关闭警告
from requests.packages import urllib3 urllib3.disable_warnings() -
手动携带证书(一般我们没有)
import requests respone=requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key')) print(respone.status_code)
http协议的版本变化
- 0.9:底层基于tcp,每次http请求,都是建立一个tcp连接,三次握手,请求结束需要四次挥手
- 1.1:请求头中有个参数Keep-alive,会使三次握手后的tcp连接不断开,让多个http请求共用一个tcp连接
- 2.x:多路复用,多个请求使用同一个数据包,再根据请求的id号归属响应,所以不同请求可以混杂在一起顺着一次传输进行交互。
目前来说1.1版本仍然是主流的http版本。
使用代理proxy*
客户端通过代理商向服务端发送请求时,会隐藏自己的个人ip,这种代理称为正向代理。我们在用同一个ip批量请求时,可能会触发网站的保护机制,封禁我们ip对网站的访问权限。
所以使用代理爬网站的信息,会安全一些。
res = requests.post('https://www.cnblogs.com',proxies={'http':'60.167.91.34:33080'})
# 键值对 http :代理ip+port , https :代理ip+port
客户端使用代理服务,一般需要上网找代理,有收费的和免费的。
高匿代理和透明代理
透明代理会在请求中携带请求头,
X-Forwarded-For: client1, proxy1, proxy2, proxy3,这样服务端就可以拿到发起请求客户端的真实的ip,但现在一般都是高匿代理
搭建代理池
公司一般会花钱买代理池,但是我们也可以通过开源软件proxy_pool去建立免费的代理池:https://github.com/jhao104/proxy_pool
搭建步骤:
-
pycharm打开安装依赖(IDE可能会自动安装)
-
修改配置文件中的redis地址(这个项目就是将爬取的免费代理存入redis)
-
爬取网上的免费代理
python proxyPool.py schedule -
启动代理池服务端(基于上一步爬到的代理池)
python proxyPool.py server -
地址栏输入对应路由
http://127.0.0.1:5010/get/ # 随机返回一个代理 http://127.0.0.1:5010/get/ # 获取所有的代理 -
使用随机代理发送请求
import requests from requests.packages import urllib3 urllib3.disable_warnings() #关闭警告 # 获取代理 res = requests.get('http://127.0.0.1:5010/get/').json() proxies = {} if res['https']: proxies['https'] = res['proxy'] else: proxies['http'] = res['proxy'] # 通过随机代理向cnblog发post请求 res = requests.post('https://www.cnblogs.com', proxies=proxies,verify=False print(res) -
将上述程序制作成一个循环,那么我们就可以不断的切换ip去获取网站的响应内容了
其他
| 参数 | 功能 | 演示 |
|---|---|---|
| timeout | 设定连接超时 | requests.get('网址',timeout=0.01) |
| ConnectionError | 连接异常 | 可以try...except捕获它 |
| files | 上传文件 | requests.post('网址', files={'file':文件对象}) |
使用requests爬取视频网站视频
import requests
from requests.packages import urllib3
from bs4 import BeautifulSoup
from threading import Thread
urllib3.disable_warnings()
# 从本地挂起的代理池随机取出代理
def get_proxy():
proxy_info = requests.get('http://127.0.0.1:5010/get/').json()
proxies = {
'https' if proxy_info['https'] else 'http': proxy_info['proxy']
}
return proxies
访问首页,搜集每条信息的id号
除了id号,有一些资源可能还有其他的标识,我们这里就用id号。
在进行翻页或者下拉时,网站一般会向后端服务器发请求拿数据,我们可以通过检测看到这些请求的网址规律
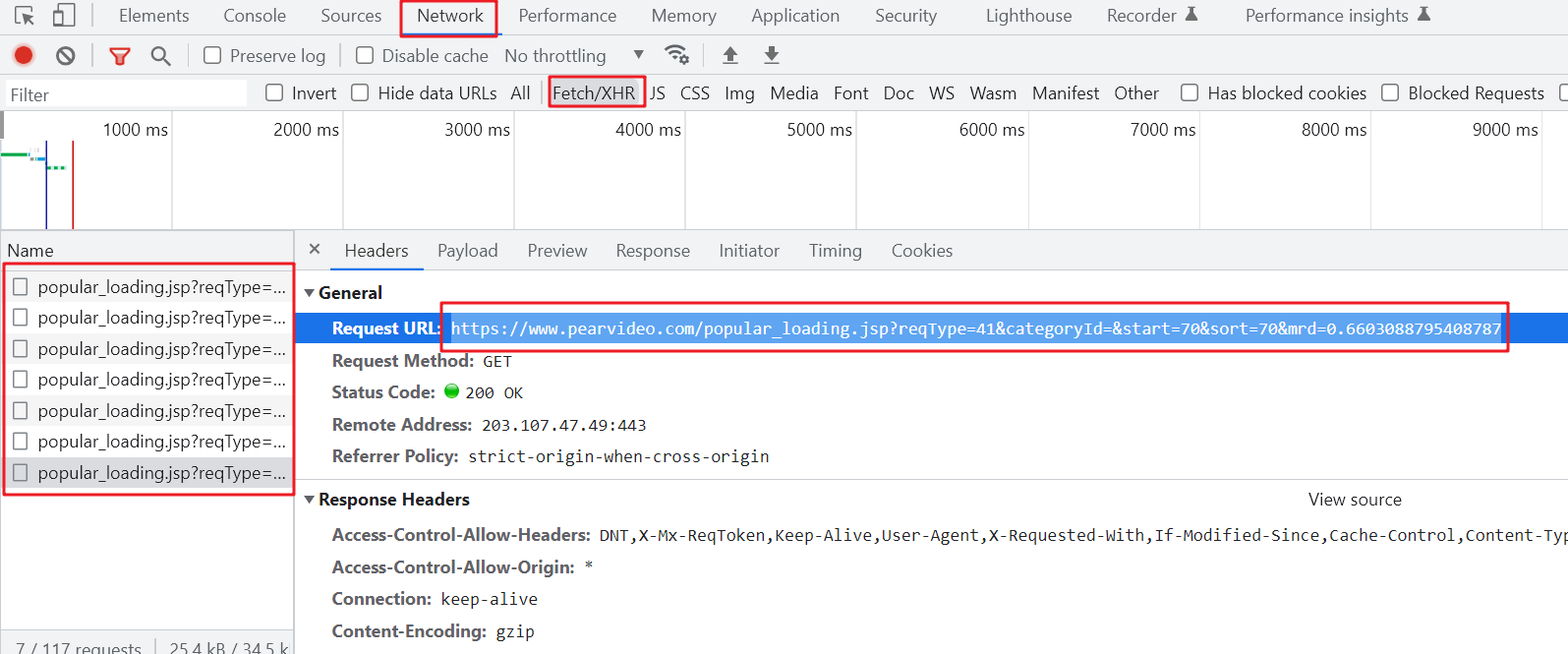
查看Response,或者我们拿请求url在地址栏再去请求,看拿到什么数据,这里是拿到了一些li标签,其中包括带网址的a标签,结合页面中点击进详情页,这个信息应当很重要。
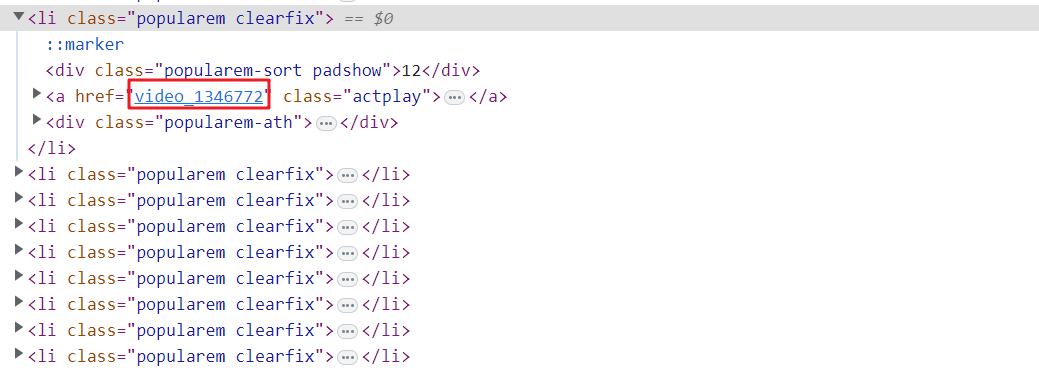
# 循环请求,拿到多条视频详情的id号
video_id_list = []
for i in range(1, 4): # 翻页取号
response = requests.get(
f'https://www.pearvideo.com/popular_loading.jsp?reqType=41&categoryId=&start={i * 10}&sort={i * 10}')
soup = BeautifulSoup(response.text, 'lxml')
a_labels = soup.select('li>a.actplay')
video_id_list += [a_label.attrs['href'].split('_')[-1]
for a_label in a_labels]
根据id号,找到访问资源的请求接口
原思路是访问每个详情页,对视频资源请求的网址进行匹配整理,但是访问详情页,它其中的视频地址是通过再发ajax获取的,所以,我们要在network中找到这个ajax请求,对其进行规律探索,发现就是https://网址?contId={video_id},根据id号即可拼接得到。
而我们手动访问这个网址时,会发现response与它页面上ajax返回的json数据不一样,经过对比,发现原请求中多了一个请求头。
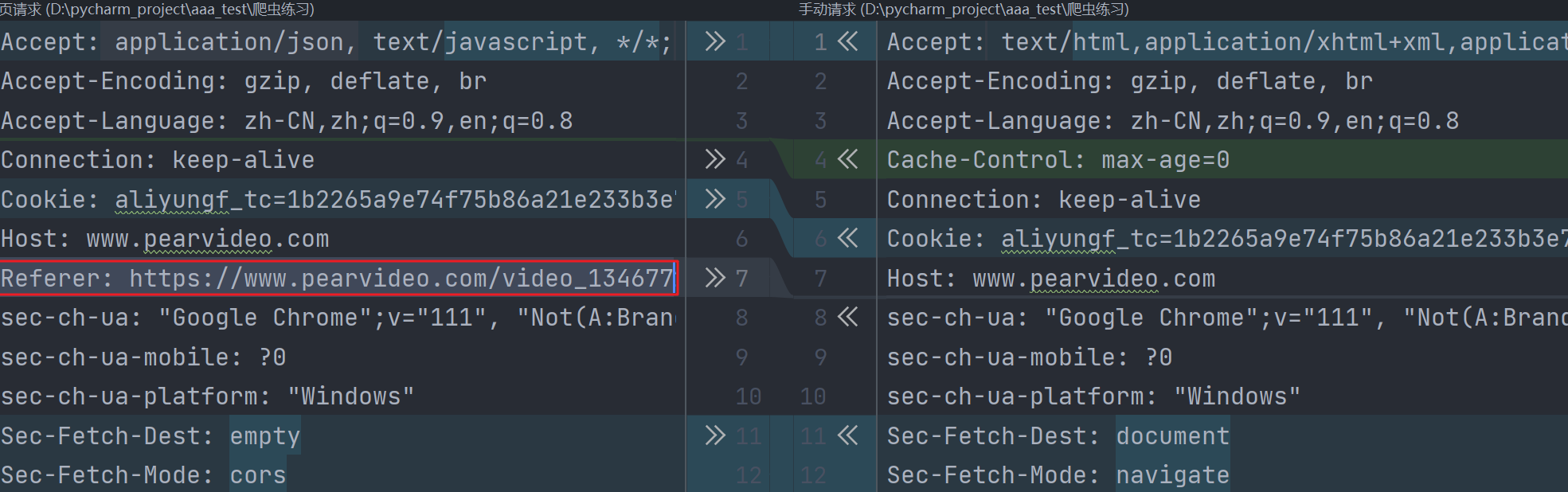
Referer:常见的反扒手段,会校验一下此请求之前的请求,所以我们携带这个请求头即可。
def download(video_id):
proxy = get_proxy()
# 请求视频信息的ajax请求,这个请求中,需要对Referer做校验
url = f"https://www.pearvideo.com/videoStatus.jsp?contId={video_id}"
res = requests.get(url, proxies=proxy, headers={
'Referer': f'https://www.pearvideo.com/video_{video_id}'
})
# 返回的json数据中,有一个为访问视频的网址,并需要经过一定处理变成访问静态视频资源的网址
src_url = res.json()['videoInfo']['videos']['srcUrl']
src_url = src_url.replace(src_url.split('/')[-1].split('-')[0], f'cont-{video_id}')
# 返回的网址:"https://video.pearvideo.com/mp4/adshort/20180517/1678962066841-12085786_adpkg-ad_hd.mp4"
# 渲染的网址:"https://video.pearvideo.com/mp4/adshort/20180517/cont-1346772-12085786_adpkg-ad_hd.mp4"
video = requests.get(src_url, proxies=proxy)
# 存入本地
with open(f"videos/{video_id}.mp4", 'wb') as f:
for line in video.iter_content():
f.write(line)
提交异步任务去下载
下载是IO操作,不占用cpu性能,所以用异步可以大大提高效率。
# download(video_id_list[0])
# 提交异步任务
for video_id in video_id_list:
print(f'{video_id}正爬取中。。。')
t = Thread(target=download, args=(video_id,))
t.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号