内置模块之多进程模块multiprocessing
内置模块之多进程模块multiprocessing
代码创建进程的方式
同步与异步的区别
from multiprocessing import Process
import time
def task(name):
print('task is running', name)
time.sleep(3)
print('task is over', name)
if __name__ == '__main__':
p1 = Process(target=task, args=('leethon',)) # 位置参数,用元组形式传
# p1 = Process(target=task, kwargs={name:'leethon',}) # 关键字参数,用字典形式
p1.start() # 异步 告诉操作系统创建一个新的进程,并在该进程中执行task函数
# task() # 同步
time.sleep(1)
print('主进程') # 当前进程继续执行它的程序
-
同步方式下,task和我们的主进程串行,必须等待task执行完毕后,主进程才会执行:
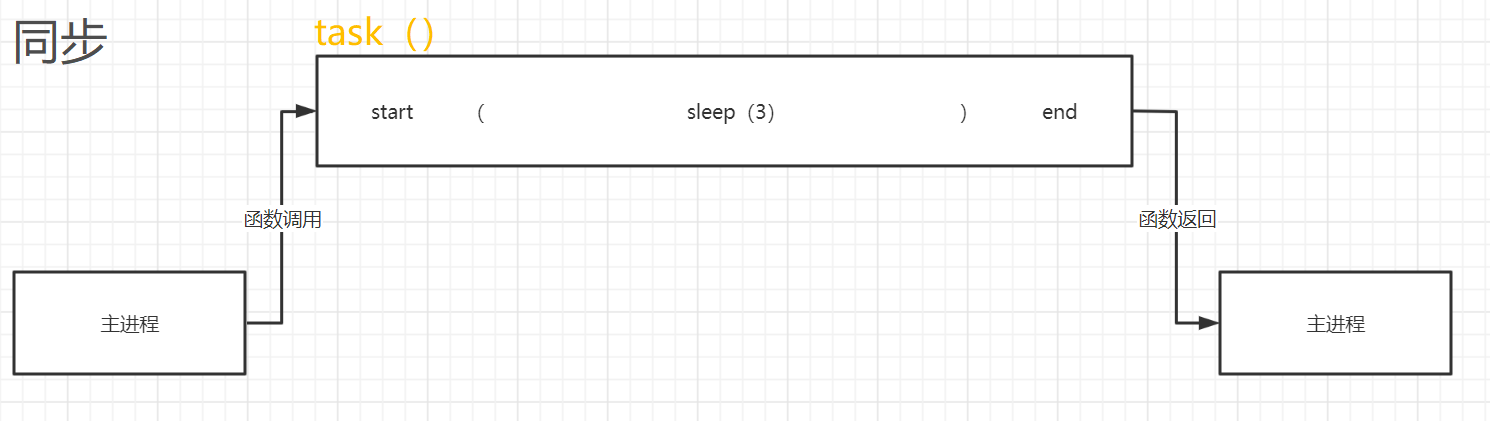
# 同步运行结果: task is running leethon task is over leethon 主进程 -
异步方式下,task和我们的主进程并行,且大量时间处于阻塞态,所以可以看做task和主进程是并发的,同时运行的。
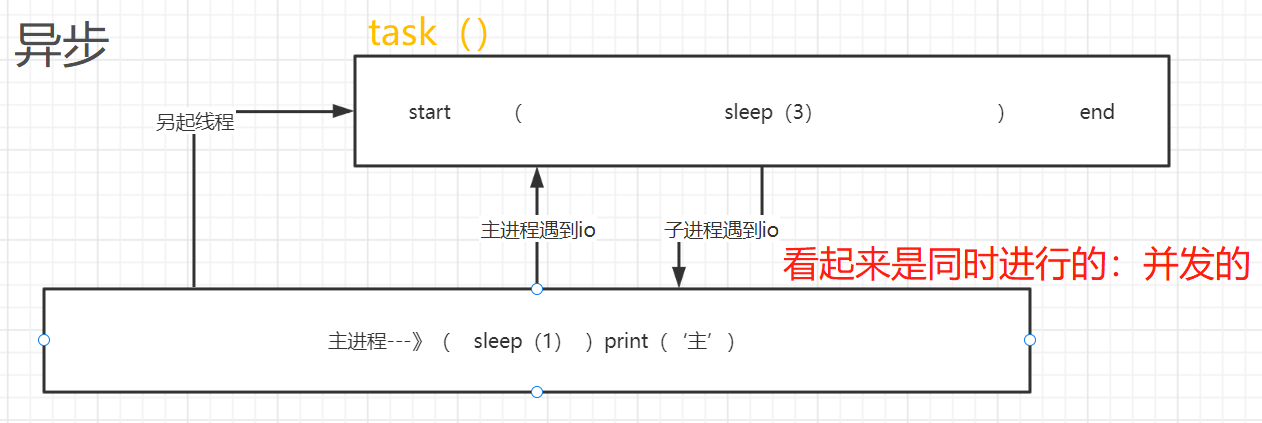
# 异步运行结果 task is running leethon # task起 主进程 # 一秒后主进程打印 task is over leethon # 3秒后task结束
创建进程的底层
在不同的操作系统中创建进程底层原理不一样
-
window
以导入模块的形式创建进程,这也是为什么我们在python中为什么将起进程这一操作放在
if __name__ == '__main__':的子代码下,为了防止导入模块再次起线程。 -
linux/mac
以拷贝代码的形式创建进程
创建方式2
from multiprocessing import Process
import time
class MyProcess(Process): # 继承Process类
def __init__(self, name, age): # 如果要传参,则通过这种方式,调用类名时触发
super().__init__() # 派生原本的方法
self.name = name # 创建完一个进程后,添加新的属性(或者导致修改原有属性)
self.age = age
def run(self): # 这就是方式1中的task,start时会运行其中的大爱吗
print('run is running', self.name, self.age)
time.sleep(3)
print('run is over', self.name, self.age)
if __name__ == '__main__':
obj = MyProcess('leethon', 18)
obj.start() # 启动子进程
time.sleep(1)
print('主进程')
# 运行结果
run is running leethon 18
主进程
run is over leethon 18
多进程实现TCP服务端并发
import socket
from multiprocessing import Process
def get_server():
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
return server
def get_talk(sock):
while True:
data = sock.recv(1024)
print(data.decode('utf8'))
sock.send(data.upper())
if __name__ == '__main__':
server = get_server()
while True:
sock, addr = server.accept()
# 开设多进程去聊天
p = Process(target=get_talk, args=(sock,)) # 每接收一个通道就开一个进程,传入通道
p.start()
进程的join方法(异步转同步)
基本使用方式
from multiprocessing import Process
import time
def task(name, n):
print('%s is running' % name)
time.sleep(n)
print('%s is over' % name)
if __name__ == '__main__':
p = Process(target=task, args=('leethon1', 1))
p.start() # 异步
p.join() # 主进程代码等待子进程代码运行结束再执行
print('主')
子进程的join方法是让主进程等待这个子进程结束后再继续执行后续操作,相当于将异步并发又变回了同步串行。
join方法小考察
from multiprocessing import Process
import time
def task(name, n): # 传入几就停几秒
print('%s is running' % name)
time.sleep(n)
print('%s is over' % name)
if __name__ == '__main__':
p1 = Process(target=task, args=('leethon1', 1))
p2 = Process(target=task, args=('leethon2', 2))
p3 = Process(target=task, args=('leethon3', 3))
start_time = time.time() # 标记开始时间
"""统计两种代码的运行时间"""
print(time.time() - start_time) # 得到总执行时间
##1 每启动一个进程后紧挨着join
p1.start()
p1.join()
p2.start()
p2.join()
p3.start()
p3.join()
"""运行结果:6s多,因为p1结束后才启动p2,相当于三个进程串行,所以一共1+2+3 = s"""
##2 先启动三个进程再最后统一join
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
"""运行结果:3s多,p1和p2、p3几乎同时启动,那么join结束后统计的时间就是取决于最长的那一个"""
进程间数据隔离
from multiprocessing import Process
import time
money = 1000
def task():
global money
money = 666
print('子进程的task函数查看money', money)
if __name__ == '__main__':
p1 = Process(target=task)
p1.start() # 创建子进程
time.sleep(3) # 主进程代码等待3秒
print(money) # 100
上述程序中,我们在子进程看似更改了全局变量的money,实际上我们联系底层,task的进程是通过导入模块的方式启动的,所以其实它改动的是它所在的模块的全局money而不会影响主进程的任何数据。
这就是进程间的数据隔离。
进程间通讯——IPC机制
IPC就是就是跨进程通信,为了能使多进程协调工作而让彼此隔离的进程有沟通的能力。
消息队列
存储数据的地方,所有的主进程和子进程都能对队列进行存取
基础使用
from multiprocessing import Queue
q = Queue(3) # 括号内可以指定存储数据的个数
# 往消息队列中存放数据
q.put(111)
print(q.full()) # 判断队列是否已满 # False
q.put(222)
q.put(333)
print(q.full()) # 判断队列是否已满 # True
# q.put(444) # 程序卡在这里
"""实际上put会等待队列有空位,如果队列为满,那就等有一个数据被取走后,再往队列里放"""
# 从消息队列中取出数据
print(q.get())
print(q.get())
# print(q.empty()) # 判断队列是否为空 # False
print(q.get())
# print(q.empty()) # 判断队列是否为空 # True
# print(q.get()) # 队列为空时,等待队列有数据再取
print(q.get_nowait()) # 不等待,立刻取数据,没有就报错
"""
full() empty() 在多进程中都不能使用!!!因为可能出现判断失误的情况
"""
多进程中使用
from multiprocessing import Process, Queue
def product(q): # 生产者
q.put('子进程p添加的数据')
def consumer(q): # 消费者
print('子进程获取队列中的数据', q.get())
if __name__ == '__main__':
q = Queue()
# 主进程往队列中添加数据
# q.put('我是主进程添加的数据')
p1 = Process(target=consumer, args=(q,)) # 将队列也作为参数传入
p2 = Process(target=product, args=(q,))
p1.start()
p2.start()
print('主')
# 执行结果
主
子进程获取队列中的数据
生产者消费者模型
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
翻译:
生产者是负责产生消息、数据的功能对象,消费者是负责是消耗消息、数据的功能对象。
而生产者与消费者虽然是对应的关系,却需要一个中介来完成数据的传递,如果没有类似消息队列的中介,也就意味着生产者所生产的东西马上要被消费者消费掉。
而可以充当生产者和消费者的中介的东西有消息队列、文件等。
进程对象的其他方法
查看进程号、终止进程、判断进程存活
# 1.如何查看进程号
from multiprocessing import Process, current_process
current_process() # <_MainProcess name='MainProcess' parent=None started
current_process().pid # 18792
import os # os 模块也可以查到
os.getpid() # 18792
os.getppid() # 2020 # 父进程的pid号
# 2.终止进程
p1.terminate()
'''
ps:计算机操作系统都有对应的命令可以直接杀死进程
如windows可以通过taskkill指令来杀死进程,通过help 指令名 可以查看win指令的详细用法
'''
3.判断进程是否存活
p1.is_alive()
守护进程
守护进程会随着守护的进程结束而立刻结束。
代码中,提现为父进程结束后,那么开启的子进程也不会继续执行了,直接结束。
from multiprocessing import Process
import time
def task(name):
print('子进程开始:%s' % name)
time.sleep(3)
print('子进程结束:%s' % name)
if __name__ == '__main__':
p1 = Process(target=task, args=('leethon',))
p1.daemon = True # 放在子进程开启之前,表示守护主进程
p1.start()
time.sleep(1)
print('主进程结束')
# 运行结果
子进程开始:leethon
主进程结束
# 没有子进程结束的打印
僵尸进程与孤儿进程
-
僵尸进程
进程执行完毕后并不会立刻销毁所有的数据,会有一些信息短暂保留下来。
比如进程号、进程执行时间、进程消耗功率等给父进程查看。
ps:所有的进程都会变成僵尸进程。
-
孤儿进程
子进程正常运行 父进程意外死亡 操作系统针对孤儿进程会派遣福利院管理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号