python面向对象编程思想及语法基础
python面向对象编程思想及语法基础
面向过程与面向对象
-
面向过程编程
过程即流程,面向过程就是按照固定的流程解决问题。
如我们在ATM+购物车实战项目里面中的:
注册功能 登录功能 转账功能。。。
需要列举出每一步的流程,并且随着步骤的深入,问题的解决越来越简单。
以流程为轴编程就是面向过程的编程思想。
-
面向对象编程
对象是数据与功能的集合体,举个例子,现在有一个游戏角色,这个角色拥有各种属性,它等级18,能够对敌人造成伤害,有生命值,代码可以表示为:
level = 18 def damage(): print('对敌人造成伤害') life_val = 1000而这个角色拥有了这些属性之后,其属性会发生什么样的变化,则是玩家进行控制的,其过程并不是程序员直接写死的。
这个拥有形形色色属性的个体就是对象。
编程中,以构筑对象属性为轴,就是面向对象的编程思想。
在日常的编程中,实际上这两种编程思想是相互交合使用的,只是在不同的应用场景下使用的占比不同罢了。
类与对象
直接说还是有些抽象,我们结合选课系统的例子来展开
在各高校的网站常常有一个选课系统,假设我们是xx高校的学生。
首先,学生可以对课程进行选择,选择完成后这个学生的课程栏就增加了一门课程,被选择的课程呢也增加了一名学生。
其次,不止一个学生可以对课程进行选择,可能有成千上万的学生通过这个程序选课。
最后,不止一门课程可以被选择,有很多门课程可供挑选。
至此,让我们来引出面向对象的用法。
-
每一个学生和每门课程都是一个个的对象,它们会因为每个学生对象的选择而改变属性
stu1_school = 'xx高校' # 学生1的学校 def stu1_choose(): # 学生1的选课功能 print('stu1选择课程') stu1_classes.append('选到的课') stu2_school = 'xx高校' def stu2_choose(): print('stu2选择课程') stu2_classes.append('选到的课') course1_stus = [] # 课程1的学生名单 -
学生对象都有选课功能,都有课程栏
# 每个学生其实都有相同的属性和功能,所以可以归为一类,避免代码冗余 def get_stu(): school = 'xx高校' def choose(): print('选择课程') classes.append('选到的课') stu_dict = { 'classes':classes, 'choose':choose } return stu_dict stu1 = get_stu() # 得到了学生1 stu2 = get_stu() # 得到了学生2 -
课程对象都有本门课程的学生名单
那同理也可以使用一个get_course的函数来快速定义多个课程对象
而实际上,python中对于造出有相同属性和功能的对象提供了一个很好用的语法——类
产生类和对象的方法 —— class
不同的学生可以通过一个类来产生:
class Student:
school = 'xx高校'
def choose(self):
print('选择课程')
stu1 = Student() # 学生对象1
stu2 = Student() # 学生对象2
类和函数一样拥有局部名称空间,定义类后,会先运行一遍类体中的代码(class关键字的子代码块),然后产生一个类的局部名称空间,将内部的名字放进去,比如这里就是定义了类Student,其局部空间内放入了school和choose两个名字。
print(Student.__dict__) # 查看学生对象的名称空间
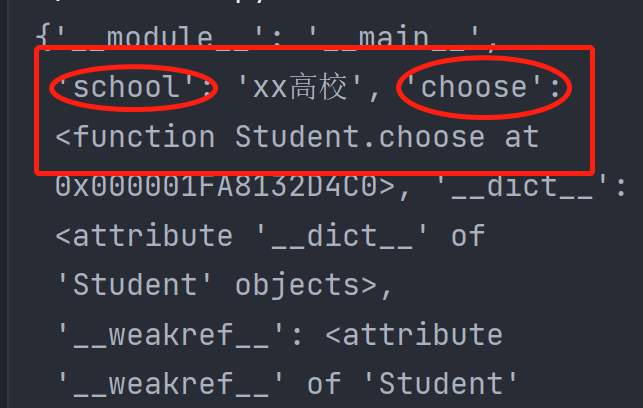
而每个学生对象通过Student类产生后,可以通过句点的方式访问到类中属性。
stu1 = Student() # 学生对象1
stu2 = Student() # 学生对象2
print(stu1.school) # xx高校
print(stu2.school) # xx高校
但是stu1和stu2通过__dict__的方式来检查它们的名称空间,发现是没有任何内容的。
print(stu1.__dict__) # {}
这是因为对象的共有属性,python解释器都让我们通过访问类的方式来拿,而不让每个对象再存一份属性了,是为了减少冗余代码和变量占用内存。
对象独有的数据
不过,选课系统中,每个学生其实是有不同的,也就意味着每个对象是有独有属性的。
比如学生对象有学生编号,学生姓名,学生的课程列表等等,这些每个学生就不能共用一份数据了,因为它们本身就是不一样的。
我们能自然的想到,如果想往一个对象里填入不同的值,那我们直接往它的__dict__中添加键值对就可以了:
stu1 = Student() # 学生对象1
stu1.__dict__['index'] = 1
stu1.__dict__['name'] = 'leethon'
stu1.__dict__['classes'] = [] # 一开始课程表为空列表
stu2 = Student() # 学生对象2
stu2.__dict__['index'] = 2
stu2.__dict__['name'] = 'alex'
stu2.__dict__['classes'] = []
这样我们就可以通过stu1来访问stu1独有的属性和类的公用属性了。
print(stu1.school) # xx高校
print(stu1.name) # leethon
不过这样冗余的代码肯定还是要封装成函数的:
def init(stu_obj, index, name): # 传入一个学生对象,index,name
stu_obj.__dict__['index'] = index
stu_obj.__dict__['name'] = name
stu_obj.__dict__['classes'] = []
这个函数可以快速的帮我们进行学生对象的初始化,但是这个函数存在于全局名称空间中,除了学生对象,课程对象也可以调用它,这就违背了我们将一类对象的数据和功能集合起来的原则。
所以我们应该将初始学生属性的函数放在Student类体内。
class Student:
school = 'xx高校'
def init(self, index, name):
self.index = index # 类或对象中的属性都可以用句点的方式来代替__dict__[]
self.name = name # self.__dict__['name'] = name
self.classes = []
这样我们就可以在得到一个学生对象后快速的对其进行独有属性的设置了。
stu1 = Student()
stu1.init(1, 'leethon')
print(stu1.__dict__) # {'index': 1, 'name': 'leethon', 'classes': []} # stu1独有的属性已完成设置
快速初始化 —— __init__方法
而实际上,python为了进一步简化这个过程,给我们提供了一个更简便的语法,__init__
当我们调用类来产生对象时,会自动运行__init__函数下代码。
class Student:
school = 'xx高校'
def __init__(self, index, name):
self.index = index # self.__dict__['index'] = index
self.name = name
self.classes = []
def choose(self):
print('选择课程')
stu1 = Student(1, 'leethon') # 学生对象1
stu2 = Student(2, 'alex') # 学生对象2
在上述代码中,可以注意到,我们调用类时,类()的括号中传入了两个实参,实际上这两个实参是传给__init__的形参的。
- 调用类时传入的实参是传递给
__init__函数的形参的 - 传入的两个实参是传给后面两个位置形参的
- 第一个形参self是用于接收对象本身的,也就是stu1产生时self形参接收的是stu1(不要深究)
对象差异化功能
在选课系统中,我们还想使每个学生对象都能够独自选课,但是功能都是类体中共有的,谁调都是调这个函数,如何做到学生对象运行的函数有差异呢。
self方法
其实在前面说到init方法时,就提到了将对象本身传入函数中这一方案,试想,当一个对象将自己传入函数,则函数就可以通过句点的方式访问对象所有的属性(数据和功能),函数使用这些对象自己所有的属性来运行函数,不就做到了每个对象的差异化功能了吗。
class Student:
school = 'xx高校'
def __init__(self, index, name):
self.index = index # self.__dict__['index'] = index
self.name = name
self.classes = []
def choose(self, course_name): # self 传入调用此方法的对象
print(f'{self.name}选择课程{course_name}')
self.classes.append(course_name)
stu1 = Student(1, 'leethon') # 学生对象1
stu2 = Student(2, 'alex') # 学生对象2
# 每个对象同样调用choose函数的不同结果
stu1.choose('语文') # leethon选择课程语文
stu2.choose('数学') # alex选择课程数学
print(stu1.classes, stu2.classes) # ['语文'] ['数学']
在上述代码中,有以下要注意的:
-
self接收调用此函数的对象,省去了我们自己传入对象的麻烦
stu1.choose('语文')相当于替换了Student.choose(stu1, '语文') -
除了传入self对象自己,还可以额外传其他的参数。
动静态方法
动态方法
在上述的self方法中,类体中的函数会默认的传入调用这个函数的对象本身。
而类中函数还可以取消自动传入对象,转而去自动传入类,只需要给类体中的函数加装一个装饰器如下:
class Student:
school = 'xx高校'
@classmethod # 绑定类方法的语法糖
def choose(cls):
print(cls)
stu1 = Student() # 得到两个由Student类产生的对象
stu2 = Student()
# 分别调用类中的choose方法
stu1.choose() # <class '__main__.Student'>
stu2.choose() # <class '__main__.Student'>
类体中加装语法糖@classmethod的函数,就称之为绑定给类的动态方法。
与上文中self方法(实际上是默认绑定对象的动态方法)的区别在于:
- 绑定对象的动态方法是默认的类体函数方法,会自动传入调用函数的对象本身。
- 绑定类的动态方法是需要装饰器加装的,加装后,会自动传入调用函数的类本身或者对象所属类
静态方法
有了绑定对象和绑定类的动态方法,还有不绑定的静态方法,即不会因为调用者不同而发生运行程序的变化,与我们在全局空间内定义的函数别无二致,正常的传参和运行。
这样的函数定义在类体中需要加装静态方法装饰器的语法糖@staticmethod
class Student:
school = 'xx高校'
@staticmethod # 静态方法的语法糖
def choose(a):
print(a)
stu1 = Student()
stu2 = Student()
stu1.choose(10) # 10
stu2.choose(10) # 10
类体中这样的静态函数无论是哪个对象对其调用,其运行结果只取决于调用时传入的形参,而与调用者无关。
