python模块理论
python模块理论
py文件都可以被导入或者导入其他py文件,而内部具有一定的功能(代码)的py文件就是模块的一种。python最初因为模块被称之为调包侠,因为程序员觉得python调模块太简单不够高贵,而随着时间的发展项目的复杂度越来越高,调模块的方便快捷变得真香了,我直呼:优雅,太优雅了。
python 模块可以表现为如下的形式:
- py文件(又称模块文件)
- 含多个py文件的文件夹(按照模块功能的不同划分不同的文件夹存储)
- 已被编译为共享库或DLL的c或C++扩展(了解)
- 使用C编写并链接到python解释器的内置模块(了解)
模块类型
-
自定义模块:程序员自己写的模块
-
内置模块:python解释器提供的模块
-
第三方模块:大佬写的模块,一般从网上下载来导入
这第三方模块是python流行的主要原因之一
导入模块的两种句式
在导入模块前有几点需要强调:
- 被导入的py模块是导入文件,被执行的py文件是执行文件,需要加以区分
- 开发项目时,py文件的名字一般是纯英文,不要出现
模块.py这种命名 - 导入模块文件时不需要填写后缀名
结合这三点来展开,如何导入文件
-
import句式
# 执行文件内部--文件名:src.py import md print(md.name) # 模块内部-- 文件名:md.py print('啦啦啦') name = 'from md' ## 运行src.py文件的结果是 啦啦啦 from md-
先执行 执行文件src.py,产生一个执行文件的名称空间。
-
使用import语句,后跟模块的文件名(不加后缀名)。
此时会执行被导入的文件,产生一个被导入文件的名称空间。
-
导入文件执行完后,回到执行文件,此时import执行完毕,执行文件的空间产生一个模块的名字md,模块也导入完成。
-
在执行文件中使用该模块名+
.的方式可以使用模块名称空间中的所有的名字。

-
-
from。。。import。。句式
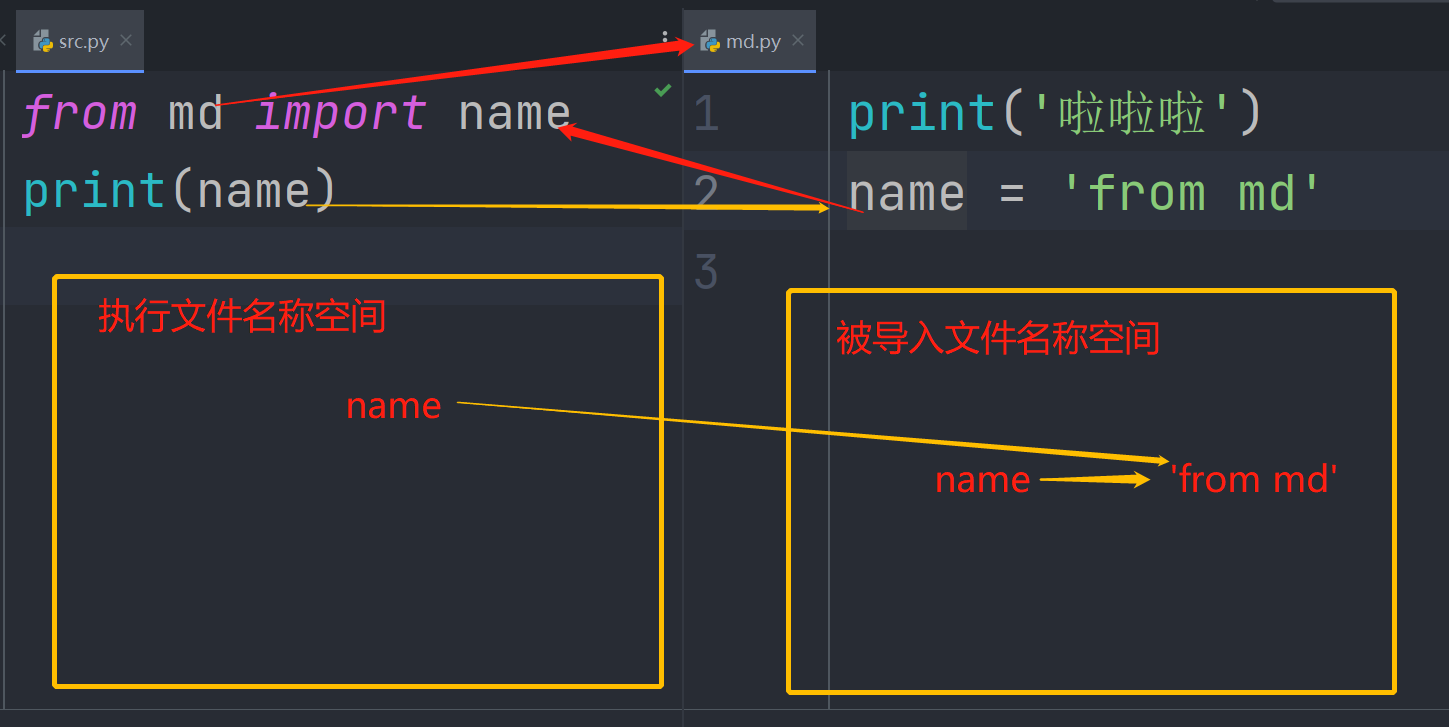
# 执行文件内部--文件名:src.py from md import name print(name) # 模块内部-- 文件名:md.py print('啦啦啦') name = 'from md' ## 运行src.py文件的结果是 啦啦啦 from md-
先执行 执行文件src.py,产生一个执行文件的名称空间。
-
执行from。。import语句,此时会执行被导入的文件,产生一个被导入文件的名称空间。
-
导入文件执行完后,回到执行文件,此时from。。import。。执行完毕,执行文件的空间得到名字name
-
执行文件中可以使用名字name引用被导入模块中name(所绑定的值)。
-
导入模块的补充说明
-
两种导入模式的特点
import句式,使用用模块名称空间中的名字都需要
模块.变量名的方式才可以用,虽然略显麻烦一点点,但是同时也避免了两个文件的名称空间中的名称出现冲突而from。。import。。句式,使用模块名称空间中的名字则有可能与执行文件的名称冲突,只是在使用这个名字时就不用前缀模块名了。
-
重复导入模块
解释器在执行import某个模块时,只会导入并执行一次这个模块,后续如果重复的导入这个语句就不会再执行了。
-
给代入的模块或名字起别名
# 比方说模块的名字十分的长时,在每次引用时就显得十分冗杂 import ilovepython as lovepy # 给模块起别名 lovepy.func() # 效力等于原本的ilovepython.func() from ilovepython import leethonyouaremygodness as leegod # 给导入的名字改名 print(leegod) # 还可以同时改多个名字 from md import hername as babe,hisname as hate # 用逗号隔开多个‘导入变量 as 重命名’ -
涉及多个模块导入
# 方式1:模块功能相似度不高时,用多句import导入 import aaa import bbb # 方式2:模块功能相似度高时,可以用单句,逗号隔开多个模块 import aaa,AAA -
导入模块中所有的名字
from a import * # *默认是将模块名称空间中所有的名字导入 # 模块中可以用all来限定拿出的名字 __all__ = ['名字1', '名字2'] # 针对*可以限制拿的名字,但是只针对这种导入方式
循环导入问题
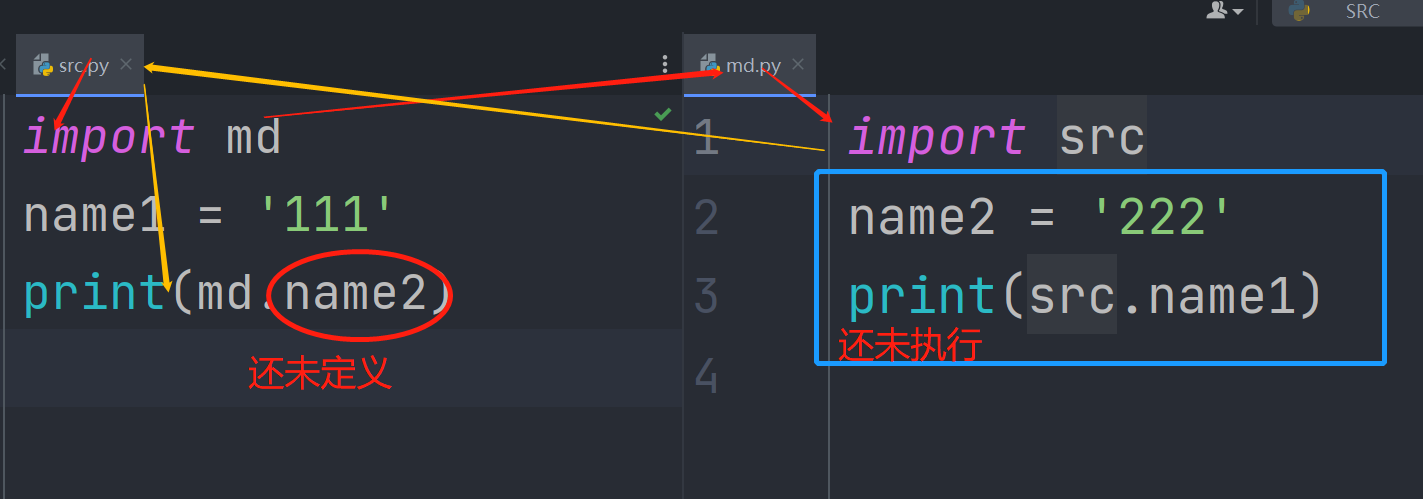
循环导入指两个文件彼此导入对方,并且相互使用各自名称空间中的名字,容易导致报错。
如图,先跟着红箭头执行import md时转到md,再跟着黄箭头import src时转回src,导致md内部的名字还没定义时,src中就擅自引用了,导致报错。
如何解决循环导入问题:
-
确保名字在使用之前就已经准备完毕(无可奈何的补救措施)
-
在编写代码的过程中就应该尽可能避免出现循环导入
判断文件是否为执行文件
上文我们强调,谁为执行文件,谁为导入文件要分的清,而在程序执行过程中也有需要判断文件是否为执行文件的场景。
实际上,执行文件所在文件夹就是项目根目录,是项目的基准,是很重要的概念。
是sys.path中的第一条。
怎么判断文件是否为执行文件呢?
__name__内置变量,在py文件的任何位置都可以获取name值。
- 当py文件被作为执行文件时,
__name__的值是__main__ - 当py文件被作为被导入模块时,
__name__的值是文件名
所以我们就可以用下列语句根据是否是执行文件决定是否执行下文的代码:
if __name__ == '__main__':
print('我是执行文件 我可以运行这里的子代码')
这样的语句常应用于以下的场景中:
- 模块开发者,需要试运行功能,但不希望被导入时执行
- 项目启动文件通常要判断
模块名的查找顺序
导入模块时,模块名字的查找顺序:
-
内置模块:如time、sys等内置模块名的优先级最高,在自定义模块的时候尽量不要与内置模块名冲突,防止自己的模块失效。
-
执行文件所在的sys.path(系统环境变量)
sys.path可以通过导入sys模块来调用,打印可以得到一个路径组成的列表。
import sys print(sys.path) # ['当前执行文件所在文件夹','其他路径1','其他路径2',...,'其他路径n',] 在模块名不是内置模块时,就会按照这个顺序来找模块
绝对路径与相对路径导入
在上文中,我们提到,模块在导入时,会查找执行文件的文件夹。
而如果执行文件所在文件夹没有对应的模块名,就会报错,但是在一些项目中,我们的自定义模块可能与执行文件并不在同一个文件夹,怎么导入呢。如下图:
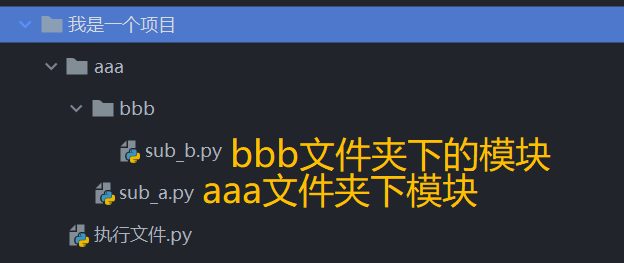
aaa和执行文件同在项目文件夹下,aaa中含bbb文件夹和sub_a模块,bbb文件夹下含sub_b模块。
我们想要导入sub_b模块或者sub_a模块,就不能光指定文件名了,还要写出路径。
# 导入sub_a
from aaa import sub_a # 可以精确到模块名
# 导入sub_b中的变量name
from aaa.bbb.sub_b import name # 也可以精确到模块名
# 多级文件夹用多个点来描述层级
上述的导入模块的方式也叫绝对路径导入,是基于执行文件所在文件夹来描述路径的。
而除了绝对路径导入,还有相对路径导入:
比方说,我们在sub_a中导入sub_b模块,在执行文件中导入sub_a模块
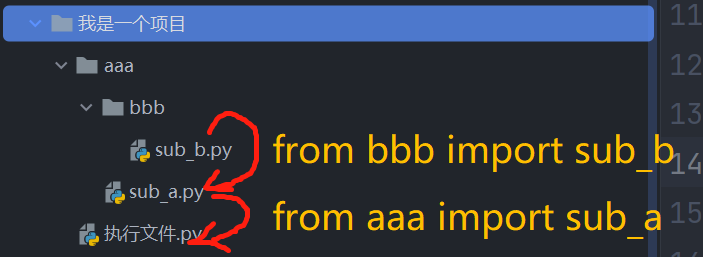
在执行我们的执行文件时,会执行并导入sub_a模块,但在执行到from bbb import sub_b时会报错,抛出异常:说没有bbb名字。
这是因为:我们从sub_a文件出发,的确可以找到bbb文件夹,但是bbb格式是绝对路径,是基于执行文件所在文件来描述的,但是执行文件所在的文件夹是没有bbb的,所以报错。
这时可以用相对路径的格式:
# sub_a.py内
from .bbb import sub_b # 相对路径导入模块
# 需要说明
.在路径中表示当前目录
..在路径中表示上一层目录
..\..在路径中表示上上一层目录
相对路径的基准是当前模块本身,不基于执行文件。
包
多个py文件的集合>>文件夹。
我们一般会规范每个集合为包的py模块文件夹中含__init__.py文件(Python2中要求必须有,Python3中不作要求)
虽然python3对包的要求降低了,不需要__init__.py也可以识别,但是为了兼容性考虑最好还是加上__init__.py,这样一些python2的文件也可以导入这个模块。
-
导入包中的部分模块、
from aaa import md1,md2 -
直接导入包
import aaa # aaa的 __init__文件中可以导入一些包中的模块, # aaa的 __init__文件也可以直接获取一些名字 from md1 import * from md2 import *导入包名其实就是导包下面的
__init__.py文件,该文件内有什么名字就可以通过包名点什么名字。
编程思想的转变
- 面条版阶段:所有的代码全部堆叠在一起
- 函数版阶段:根据功能的不同封装不同的函数
- 模块版阶段:根据功能的不同拆分成不同的py文件
这个过程是一个不断将代码拆分开来的过程,对于初学者来说很难适应,似乎代码变得越来越复杂,越来越分散,不好管理。
但实际上,越来越复杂的不是我们写代码的模式,而是代码的量级在不断上升,原本的面条版和函数版的代码结构不能满足我们对项目进行管理的需求,如果有一个项目有上千行上万行代码,如果不分文件,那么对其进行维护将十分的困难。
软件目录开发规范
当代码量上升到项目级别,我们就要考虑项目的规范问题,下面整理了编写软件时经常使用的规范:
实际上就是一层层文件夹怎么命名:
myproject # 项目文件夹,可以自定义命名
- bin # 存放项目启动的文件 的文件夹
start.py # 启动文件,也可以命名为软件的名字等
- conf # 配置文件夹,全程configuration--配置
setting.py # 里面通常放一些大写的常量,作为软件起始需要的变量
- core # 核心文件夹,存放一些核心逻辑功能文件
src.py # 存放一些核心的功能
- interface # 接口文件,存放一些接口文件 # 接口可以理解为数据与用户的交互过渡层。
purchase.py
user.py
account.py # 根据业务逻辑分类对应某类功能的接口
- db # 数据及其处理文件夹 --- 可能被其他软件代替,如mysql
userdata.txt # 用户数据等数据文件
db_handler.py # 数据处理的相关功能
- log # 主要存放项目日志文件
log.log # 项目日志文件
- lib # 项目公共功能文件夹
common.py
- README.md # 项目说明书
- requirements.txt
# 模块环境说明书!!!一个字母不能错,这个文件可以帮助项目参与者快捷的下载模块
