算法简介及二分法查找
算法及二分法
算法
算法就是解决问题的有效方法,一个算法可能是针对某个问题而设计的,也可以是针对某些问题而设计。
在python中,如何对列表进行一系列操作的内置方法是一系列的算法,这些算法也只能操作列表。
如果我们想算1+1,上面的内置方法就压根算不了,并不是算法不够好,而是术业有专攻。
而一般来说,我们对于复杂问题的解决方式更加被认可为算法,算法有高效的也有低效的。
查找算法
比如说有一个有序的列表[11, 23, 44, 64, 71, 78, 91, 107, 114, 125, 131, 201, 210, 212, 456, 678],我想在这个表里查找一个目标值如125,该设计一个什么样的算法。
在我们已学的知识里,只要用for循环遍历一遍,实际上就可以解决了。
l1 = [11, 23, 44, 64, 71, 78, 91, 107, 114, 125, 131, 201, 210, 212, 456, 678] # 一个很长的列表,长度为n
for num in l1: # 逐一进行遍历
if num == 125:
print('找到了')
break
else:
print('没找到啊')
但是,对于查找来说,这个算法并不高效。
如果要找的元素列表里根本没有,那不是每一次都要将列表整整的遍历一遍吗?
针对这个问题,我们要注意到列表是有序的,那么在我们的目标值小于当前遍历的值时,就不必再往后遍历了。这样就可以平均缩短一半的遍历时间:
l1 = [11, 23, 44, 64, 71, 78, 91, 107, 114, 125, 131, 201, 210, 212, 456, 678] # 一个很长的列表,长度为n
for num in l1:
if num == 123:
print('找到了')
break
elif num > 123:
print('列表里面没有啊')
break
else: # 遍历到最后一个元素678,都比目标值小的时候会走到这里。
print('列表里面没有啊')
如果列表很长,但是要找到的元素很靠后呢?
上述算法虽然缩短了一半的平均时间,但这样的提升并不算大,如果列表长度是20000,那平均每次遍历就是10000次。并没有质的提升。
这是就要提到经典的二分算法了。
二分法查找
l1 = [11, 23, 44, 64, 71, 78, 91, 107, 114, 125, 131, 201, 210, 212, 456, 678]
target = 107 # 随时更改目标值
while l1:
mid_index = len(l1) // 2 # 每次循环从列表取中间值
if l1[mid_index] == target:
print('找到了')
break
elif l1[mid_index] > target: # 如果目标值小于中间值
l1 = l1[:mid_index] # 则目标值在左边,去半左边列表
elif l1[mid_index] < target: # 如果目标值大于中间值
l1 = l1[mid_index + 1:] # 则目标值在右边,去右半边列表
else:
print('列表中没有目标值')
我们来理一理,107是怎么被找到呢:
- 首先要先与列表中心114做比对,小于114,所以向左得到一个新的列表
[11, 23, 44, 64, 71, 78, 91, 107,] - 进入下一次循环,与新列表中心71做比对,大于71,向右得到一个新列表
[78, 91, 107,] - 进入下一次循环,新的中心是91,大于91,向右得到一个新的列表
[107,] - 下一次循环,新中心是107,找到了!
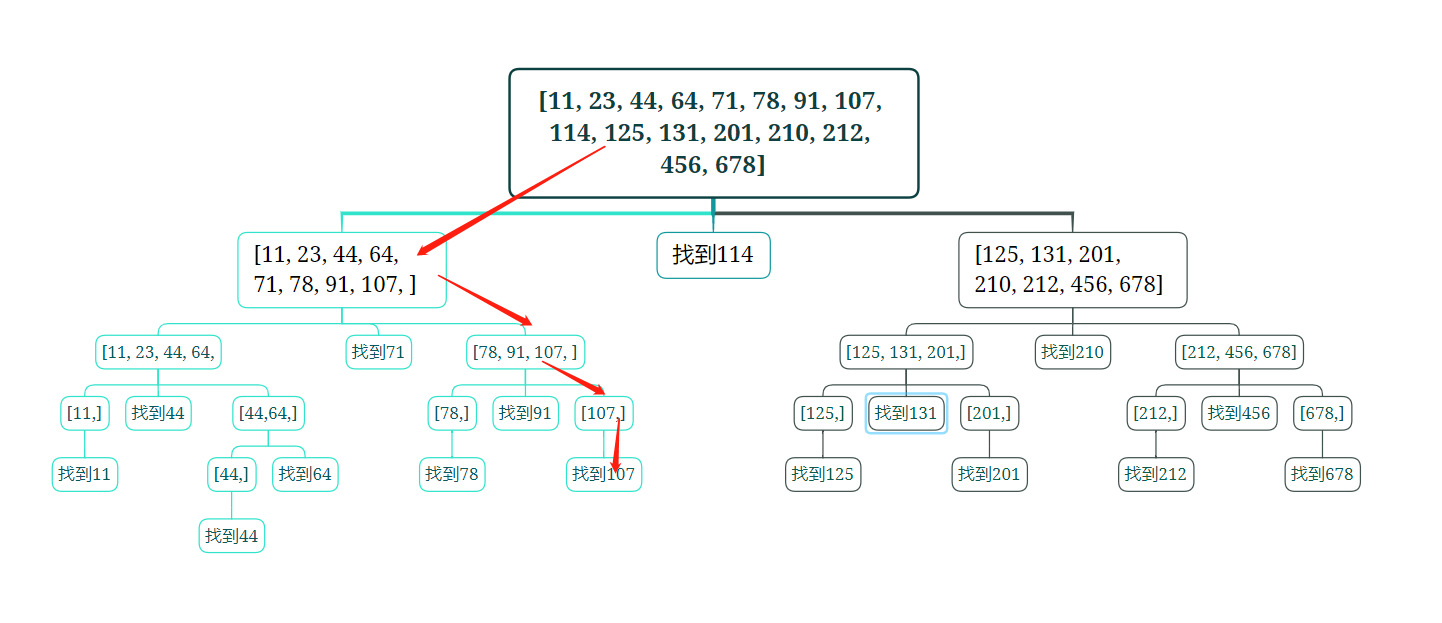
在这样的查询算法中,列表不不断的分成两段,无论你的列表有多少层,查找次数都不会超过log2^n,其中n为列表的长度,如果有20000长度的列表,则最多只需要查找14次就能够查找到,这个遍历次数的降低是数量级的降低!
如果列表不是很长,而且经常取头部的数据,那显然直接用for循环的算法反而更优于二分法查找。
所以还是那句话,算法是针对某类问题设计的,它的高效或低效是对它要解决的问题而言的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通