函数概念及python函数语法
函数
函数的应用场景
函数是广泛应用于编程语言的一个方法,能够用于解决代码冗余的问题。
我们来看这么一个场景:
# 校验程序
userinfo = { # 用字典存储用户的状态
'name': 'leethon',
'is_pass': True,
'readable': True,
}
if userinfo.get('name') == 'leethon' and \ # 每个条件都满足了
userinfo.get('is_pass') is True and \
userinfo.get('readable') == True:
# 校验用户状态成功可以进行读取操作等
pass
userinfo['is_pass'] = False # 用户状态发生变化
if userinfo.get('name') == 'leethon' and \
userinfo.get('is_pass') is True and \ # 这一个条件没有满足不执行
userinfo.get('readable') == True:
# 校验用户状态成功可以进行读取操作等
pass
在上述场景中,可以看见当多次需要校验的时候,那段庞杂的校验每次都要重新写一遍,使代码有很多重复的部分,这种情况多了很占用空间。而且抛去这一点不谈,当需要校验时,重新找到这段代码复制过来也是十分麻烦的,所以就要用到我们今天要说的主角——函数。
# 函数演示
def checkout(userinfo):
if userinfo.get('name') == 'leethon' and \
userinfo.get('is_pass') is True and \
userinfo.get('readable') == True:
# 校验用户状态成功可以进行读取操作等
pass
userinfo = { # 用字典存储用户的状态
'name': 'leethon',
'is_pass': True,
'readable': True,
}
checkout(userinfo)
userinfo['is_pass'] = False # 用户状态发生变化
checkout(userinfo)
对比两份程序可以看出,当我们想用那一段庞杂的代码时,就不用在重新写一段了,只要在用的时候简单的写一句checkout(userinfo)就达到了同样的效果。
而具体的操作将在下文继续详解。
函数的语法结构
- 基础结构
def 函数名(): # 定义
函数体代码
函数名() # 调用
函数的定义与调用
-
定义:def后面跟函数名加括号冒号,下一行缩进开始写函数体代码。这个过程是定义。
这个过程也被描述为把函数体代码封装起来,函数带着功能属性。
-
调用:当我们想使用某个已经定义了的函数功能时,只需要用函数名加括号的形式就能使用,这个过程叫做调用。
三种进阶结构
在基本结构上,我们还可以加入参数和返回值得到另外三种结构
-
空函数结构
def 函数名(): pass # 指什么都不做当我们在定义一个函数的时候,有时可能只是先确定一个大概的功能,但还没有具体的函数体代码,那我们就可以用pass执行一个空语句,这样做仅仅是为了补全代码结构,防止报错。
-
含参结构
def 函数名(参数): # 定义 函数体代码 函数名(对应参数) # 调用当定义时,括号里有变量名,则这些变量为参数。
在调用阶段可以填入数据值,这些参数变量会以一定的方式接受变量。
-
含返回值结构
def 函数名(): # 定义 函数体代码 return 一个值 print(函数名()) # 调用函数,并打印返回值这里先简单的书写一下结构,在后文再进行说明。
函数的返回值
什么是返回值
在我们学习内置方法pop时,我们称这种删除列表元素的方法成为‘弹出’
而实际上pop是python的内置函数,我们在执行完这个函数完得到的值就是返回值,这个返回值不仅能打印,如果是数字还能用于计算,等等。
总的来说,就是调用函数时,函数返回给调用者的信息。
l1 = [1, 2, 3, 4]
print(l1.pop()) # 4
# 执行了删除末尾元素的功能,并且拿到了这个元素,还能打印
print(l1.pop() + 6) # 9
# 第二次执行了删除末尾元素的功能,即拿到了3这个元素,与6进行加和,得到了9
以上是拿到返回值和使用返回值的一些简单用法。
返回值的实现 —— return
返回值的关键字是return,它只能在def下的函数体中使用。
-
函数体中可以没有return,视为没有返回值,或者返回值为None
-
函数体可以单独使用return,函数体代码的结束,返回值同样为None
def func(): print('我是函数体代码') print('看到我就结束了') return print('我应该是不会被打印的,你可以试试') func() ## 运行结果 我是函数体代码 看到我就结束了 -
return后可以跟一个数据值,返回值为这个数据值
def func(): return '我是返回值' print(func()) # 我是返回值 -
return后可以跟多个数据值(用逗号隔开),会自动将多个数据值组合为元组作为返回值
def func(): return 111, 222 ,333 print(func()) # (111, 222, 333)
总的来说,调用函数时,会执行到return之前的函数体代码,并得到一个返回值,这个返回值是return后面的数据值。
函数的参数(重点)
根据定义阶段,函数名()括号内部有没有变量,可以将函数分为无参函数和有参函数。
无参函数不必多说了,就是上文的基础结构函数。
而有参函数,能够让调用者向函数内部提供数据值,可以理解为返回值是函数对外输出,而参数是向函数内输入。
有参函数的定义与调用结构如下:
# 例
def func(name, age): # 定义阶段
print(name,age)
func('leethon', 18) # 调用阶段
# leethon 18
在这个例子中,定义阶段括号内的参数是变量名形式,而调用阶段括号内的参数是数据值形式。
形参与实参
关于有参函数,我们要提出两个概念。
- 形参:形式参数,指定义阶段在括号里面的变量名,它们占据定义时函数体代码的结构
- 实参:实际参数,指调用阶段在括号里面的数据值,它们实际参与代码的操作与运算
# 例子
def my_sum(num1, num2): # num1和num2就是形参
print(num1,num2) # 在函数体中,功能上打印num1和num2,但定义时,只检查语法
return num1 + num2
print(my_sum(1, 2)) # 调用前面的函数,这里括号里的1和2就是实参
# 实参实际被打印出来了,是实际参与了函数体代码的操作
## 运行结果
1 2
3
##
1.先是定义了函数my_sum,定义了形参num1,num2
2.调用了函数my_sum
3.传入了实参,1和2
4.执行函数体代码,打印了1和2
5.返回了两个参数的和,为3,由print打印了出来。
有参函数定义和调用的过程图示:
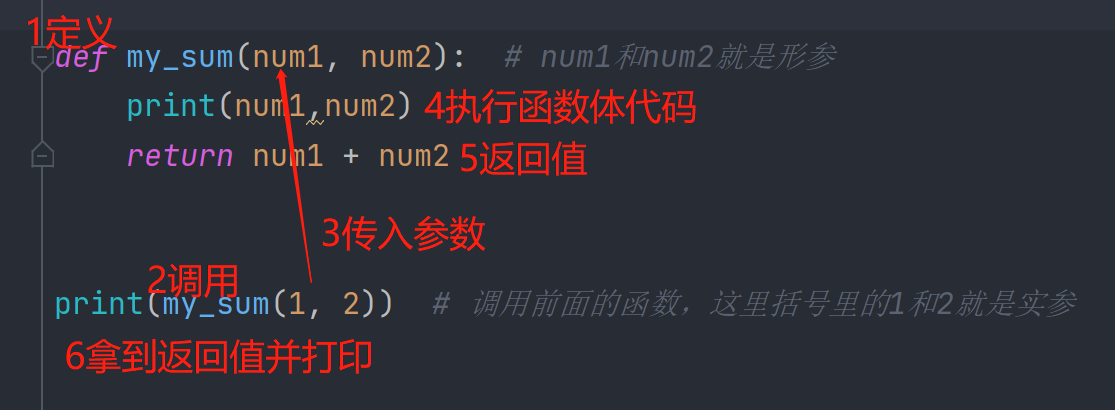
再次强调:形参与实参分别于定义和调用阶段使用,形参为变量名形式,实参为数据值形式。
关于传入实参也有以下的方法。
位置实参
按位置依次的将参数传到对应的形参。
def func(a, b, c):
print(a, b, c)
func(1, 2, 3) # 1 2 3
"""
当实参与形参数量一致时,对应位置上的实参会传到对应位置的形参
即a=1,b=2,c=3
"""
func(1, 2) # 报错,需要3个参数,只给了两个
func(1, 2, 3, 4) # 报错,需要3个参数,给了4个
"""
当形参和实参的数量对应不上时,会报错,必须按照数量传
"""
在上文我们提到过,形参是变量名形式,那它也应做到见名知义的效果,让我们知道第一个位置传什么,第二个位置传什么。
def register(username, password): # 伪代码,描述代码功能,用于占位,暂且搁置具体的代码实现
"""注册功能代码"""
register('leethon', 123) # 第一个位置传用户名,第二个位置传密码
那么这种按位置传参的方法,如果要传参数,就得找到对应形参的位置才能传参,比方说上面这个例子,我们先想起来传入密码,后想起来传入用户名,甚至有更多的参数,那么位置传参就像列表存信息一样难找。
这时候就要介绍一下关键字实参了。
关键字实参
在调用阶段,括号里写形参变量名=实参的样式,就是关键字传参法,又可以叫关键字实参。
def func(a, b, c):
print(a, b, c)
func(a=1, c=2, b=3) # 1 3 2
"""
突破了位置函数的位置限制
用变量名=数据值的格式来指定将某个实参传给对应的值
"""
func(b=1, c=3, a=6) # 6 1 3
"""完全打乱也没有问题"""
补充:两种实参混用
如果两种实参混用,是什么情况呢。
-
情况1
def func(a, b, c): print(a, b, c) # 情况1 func(1, c=3, b=2) # 1 2 3第一个按照位置传参传给a了,b和c则按照关键字传参
-
情况2
# 情况2 func(3, a=1, b=2) # TypeError: 参数a接收了多个数据值报错,参数a只能接收一个变量,这里却显示接收了多个。
分析:第一个实参是根据位置传的参数,那么就是将3传给了a,而后续又有a=1的关键字实参,又想给参数a传值,所以传值就产生了冲突。
-
情况3
# 情况3 func(b=2, 1, c=3) # SyntaxError: 位置参数跟在关键字参数后面报错,语法上不支持将位置参数放到关键字参数的后面。
换句话说,位置参数一定要在关键字参数的前面。
总结,在位置形参与关键字形参混用时:
-
位置实参和关键字实参的总和依旧要保证与形参一致
-
排在前面的形参被实参按位置传值后,不能再被关键字传值了
-
先按位置传递参数,再按关键字传递参数,语法上也做了相应的限制
位置参数在前,关键字参数在后(简记:简单形式的在前,复杂的跟在后面)
默认参数
在我们使用函数的很多场景下,也可能用到默认值。
当我们利用函数注册很多人的信息时,可以封装注册一个人信息的函数
def register(name, gender):
"""注册功能,录入姓名和性别"""
register('leethon', 'male') # 注册1
register('jason', 'male') # 注册2
register('franky', 'male') # 注册3
在上述场景中,很多注册的性别都是男的,那么我们可以认为,在这个注册群体中,注册的人默认是男性,但是我们仍然在每次注册时都要选择男性作为参数输入,比较麻烦。
这时就要用到默认参数,定义形参时对其进行赋值:
def register(name, gender='male'):
"""注册功能,录入姓名和性别"""
print(name, gender)
register('leethon') # 注册1 leethon male
register('jason') # 注册2 jason male
register('franky', 'male') # 注册3 franky male
register('lalisa', 'female') # 注册4 lalisa female
我们会发现,形参有两个,而注册1、注册2只有传入了一个参数,却并没有报错。
这是因为默认参数的逻辑就是,当没有给这个参数传入值的时候,默认为定义形参时赋值的数据值。
而注册3和注册4中,我们传入了两个参数,那么就按照位置实参的传入方式传值,形参gender因为被传入了值,就遵循新传入的值而覆盖了默认的值。
补充:默认参数的定义位置
def func(a, b='222', c): # 直接报错,SyntaxError:非默认函数跟在了默认函数后面
print(a, b, c)
func(111, 333)
语法上,默认函数必须跟在非默认函数的后面,这样的限制也是为了方便实参准确的传入。
可变长形参(*和**)
在上文的举例中,我们把形参与实参的数量一一对应:
- 要保证形参有默认值或者有值传入。
- 要保证实参不多余,能对应到形参,不虚空传值。
而在python语法中,还有一种语法来接收传入的实参数据值,那就是可变长形参。
-
*变量名形式的形参变量# 例 def func(*a): print(a) func() # () func(1, 2) # (1, 2) func(1, 2, 3) # (1, 2, 3) func(1, 2, 3, 4) # (1, 2, 3, 4) func(1, 2, 3, 4, 5, 6, 7, 8) # (1, 2, 3, 4, 5, 6, 7, 8)*a的结构是*变量名,*不是变量的一部分,但是在定义阶段在形参前加上*,会赋予形参接收所有位置参数的功能。在上述代码里,无论我传入多少实参,都会组织为元组形式,被
*后的变量a吸收。*变量名也可以搭配其他形参使用。def func(a, *b): print(a, b) func() # 报错,因为至少要传入一个实参给a func(1, 2) # 1(2,) func(1, 2, 3) # 1 (2, 3) func(1, 2, 3, 4) # 1 (2, 3, 4) func(1, 2, 3, 4, 5, 6, 7, 8) # 1 (2, 3, 4, 5, 6, 7, 8)a变量按位置接收实参后,后面的可变长参数b变量接收剩余的所有参数。
def func1(*a, b): # 定义阶段没有报错 print(a, b) func1(1, 2, 3, 4) # 调用阶段报错,说参数b应该传入一个参数 func1(1, 2, 3, b=4) # (1, 2, 3) 4 """ 定义阶段没有报错,但是调用时,a优先接收了所有位置实参,无法通过位置实参传入b 只能通过关键字实参将值传入b。 """ -
**变量名形式的形参变量def func(**k): print(k) func() # {} func(1, 2) # TypeError:函数func不接受位置参数,但是却传入了两个位置实参 func(name='leethon', age=18) # {'name': 'leethon', 'age': 18} func(1, name='leethon', age=18) # TypeError:函数func不接受位置参数,但是却传入了1个位置实参**变量名的形式定义的形参变量k可以接收剩余的所有关键字实参,并将其组织成字典形式。上述代码中,可以看出,k变量只接收了关键字实参,不会接收位置实参,可以接收很多个关键字实参,也可以在没有接收到实参时,组织一个空字典。
同样,
**变量名也可以搭配其他的形参使用。def func(a=111, **k): print(a, k) func() # 111 {} func(1, 2) # TypeError:函数func只接收一个位置参数,但是却传入了两个位置实参 func(name='leethon', age=18) # 111 {'name': 'leethon', 'age': 18} func(1, name='leethon', age=18) # 1 {'name': 'leethon', 'age': 18} func(name='leethon', a=22, age=18) # 22 {'name': 'leethon', 'age': 18} ''' 这次我们搭配默认的变量名来使用,分析五种情况如下 ''' # 第一种状况 没有传入实参,那么a取默认值,可变长参数k取空字典 # 第二种状况 传入两个位置实参,报错了,因为func函数只需要一个位置参数传给a, 剩下只能由k接收多余的关键字实参,而多余的位置实参无法接收。 # 第三种状况 没有传入位置实参给a赋值,a取默认参数111,其他关键字实参被组织成了字典被k接收 # 第四种状况 通过位置实参给a赋值了,a覆盖为1,其他关键字实参被组织成了字典被k接收 # 第五种状况 三个实参都是关键字实参,其中有一个a=22关键字传参让a覆盖为22, 其他关键字传参组织为字典传给了可变长变量k
ps:虽然*和**后的变量可以任意命名,但由于其特别好用和常用,
我们常常将可变长变量固定写为*args和**kwargs
*和**搭配实参使用
在调用时我们可能会遇到这样一个场景:
def func(a, b, c):
print(a, b, c)
l1 = [111, 222, 333]
func(l1[0], l1[1], l1[2]) # 111 222 333
将列表、元组这种容器类型的数据中的元素一个个的赋值给func的形参。
但是这样一个个输入索引太麻烦了。我们可以用*列表的形式‘打散’列表并分别的赋值给形参。
def func(a, b, c):
print(a, b, c)
l1 = [111, 222, 333]
func(*l1) # 111 222 333
# 同样,除了列表、元组、字符串、集合、字典也同样可以使用*做组合
## 字符串
s1 = 'she'
func(*s1) # s h e 以单个字符为单位打散了
## 集合
set1 = {111, 222, 333}
func(*set1) # 333 222 111 集合无序的打散了
## 字典
d1 = {'aa': 1, 'bb': 2, 'cc': 3}
func(*d1) # aa bb cc 只取出键然后打散了
于是可以将*列表|元组|字符串|字典|集合理解为通过for循环以位置实参的形式传给了形参。
*数据值是打散数据值以位置实参的形式传入函数,
而**字典则是打散字典以关键字实参的形式传入函数,如下。
def func(a, b, c):
print(a, b, c)
d1 = {'a': 1, 'b': 2, 'c': 3}
func(**d1) # 等价于func(a=1, b=2, c=3)
# 1 2 3
进阶补充:形参定义顺序总结
在学习了一般形参(非默认参数)、默认参数和两种可变长形参后,我们来整理一套,在定义函数时合理的形参书写顺序。
def func(任意数量的一般形参, 任意数量的默认参数, *args, **kwargs):
'''函数体代码'''
# 例
def func1(a, b, c=10, *args, **kwargs):
"""
首先,a和b必须传入参数,可以通过位置实参传入,也可以通过关键字实参传入。
其次,默认形参,必须放在非默认形参之后(语法规定,也是防止传参冲突的情况)
最后,接收位置实参的形参*args,**kwargs
"""
扩展了解:命名关键字形参
def func(*args, is_people=True, **kwargs):
"""
这个与上面形参定义顺序不同,将一个默认参数放到了*args的后面,
这样做,当我们进行位置传参时,所有位置实参都会被args全数吸收
那么,默认参数就无法通过位置传参得到值,只能通过关键值传参得到外界的传值
又可以说,无论位置参数传了多少,只要不通过is_people传值,那就为默认值True
"""
# 内置函数print
print(1, 2, 3) # 1 2 3并换行
print(1, 2, 3, 4, end='') # 1 2 3 4 不换行
print(1, 2, 3, 4, 5) # 1 2 3 4 5 换行
## 无论位置实参传了多少,只要不通过end关键字传参,就默认换行
print定义源码:
def print(self, *args, sep=' ', end='\n', file=None): # end默认为换行,且跟在*args后
'''print的函数代码'''
练习
将上一篇文章中的注册功能和登录功能封装为函数(定义并调用)
def register(): # 注册功能
while True:
# 输入用户名和密码
username = input('注册的用户名:')
password = input('请输入密码:')
# 判断用户名是否存在
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
for line in f:
user, pwd = line.strip().split('|')
if user == username:
print('用户名已经存在,请更换用户名')
break
else:
# 注册,把用户和密码存到文件里
with open(r'userinfo.txt', 'a', encoding='utf8') as f1:
f1.write(f'{username}|{password}\n')
print(f'用户{username}注册成功')
break
def login(): # 登录功能
while True:
# 输入用户密码
username = input('请输入用户名:')
password = input('请输入密码:')
# 核验密码登录
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
for line in f:
user, pwd = line.strip().split('|')
if user == username and pwd == password:
print('登录成功')
break
else:
print('用户名或密码输入错误,请重新输入')
break
while True:
choice = input('1注册|2登录|q退出:')
if choice == '1':
register()
elif choice == '2':
login()
elif choice == 'q':
break
else:
print('请输入有效的编号!')


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具