垃圾回收机制GC
垃圾回收机制GC
我们已经知道,name = 'leethon'这一赋值变量的操作,是将变量与数据值相绑定。
而数据值是存储到内存中的,有时变量会重新赋值即绑定其他数据值,而使得原本的数据值无法通过变量找到,那么它存储到内存中就变得没有意义,如果这样被变量抛弃的数据值过多,就会占用内存过多的资源。
这样无法通过变量找到的数据值,我们称之为‘垃圾’,而在python语言中,会自动的回收这些垃圾,而回收的逻辑原理有十二字真言:引用计数、标记清除、分代回收
引用计数
引用计数的原理是,数据值每绑定一个变量,其引用计数就会增加1,每解除一个变量绑定,引用计数就会减去1,当一个数据值的引用计数为0时,则会被当成垃圾回收掉。这样就简单的实现了垃圾数据的回收。
# 比如我们进行以下两句代码的执行
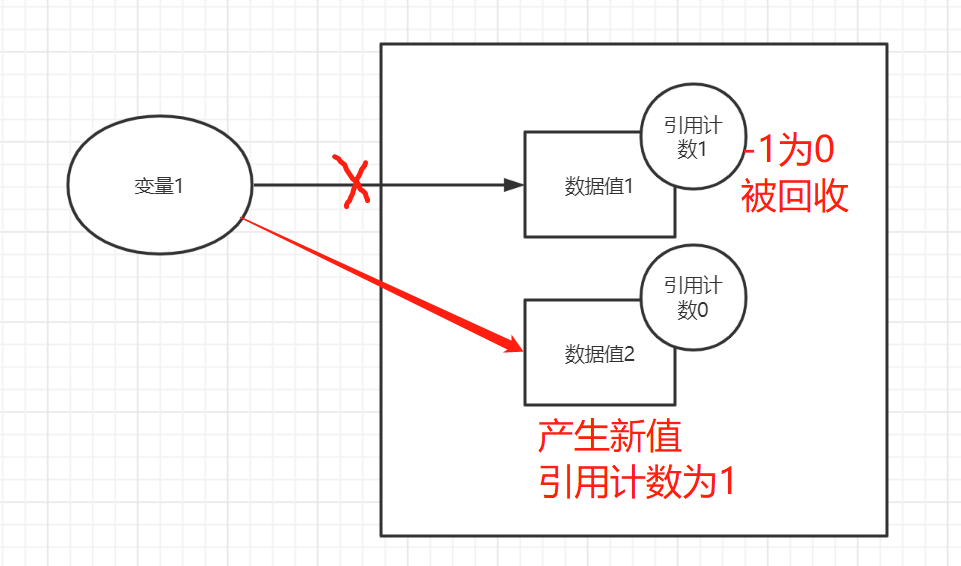
变量1 = 数据值1 # 数据值1为新值,引用计数为1
变量1 = 数据值2 # 数据值2为新值,引用计数为1,数据值1被迫与变量1断开连接,引用计数-1清零
标记清除
标记清除主要是用于解决循环引用的问题。
首先,我们先说明一下,哪些状况下,会使引用计数增加:
- 被变量绑定时
- 被列表索引和字典键索引时
那么又在什么情况下,引用计数会减少呢:
- 变量重新赋值或del时与数据值断开绑定
- 索引的列表或字典等被回收时,自然也会断开与其引用数据的绑定
那么可以看到,引用计数来解决垃圾问题是有隐患的,那就是循环引用问题
# 看以下一段程序
l1 = ['a'] # 两变量分别绑定了一个列表
l2 = ['b'] # 两个不同的列表分别引用计数为1
l1.append(l2) # l1 = ['a', l2] 列表2的引用计数加为2
l2.append(l1) # l2 = ['b', l1] 列表1的引用计数加为1
del l1 # l1变量断开,列表1引用计数-1
del l2 # l2变量断开,列表2引用计数-1
如图所示:
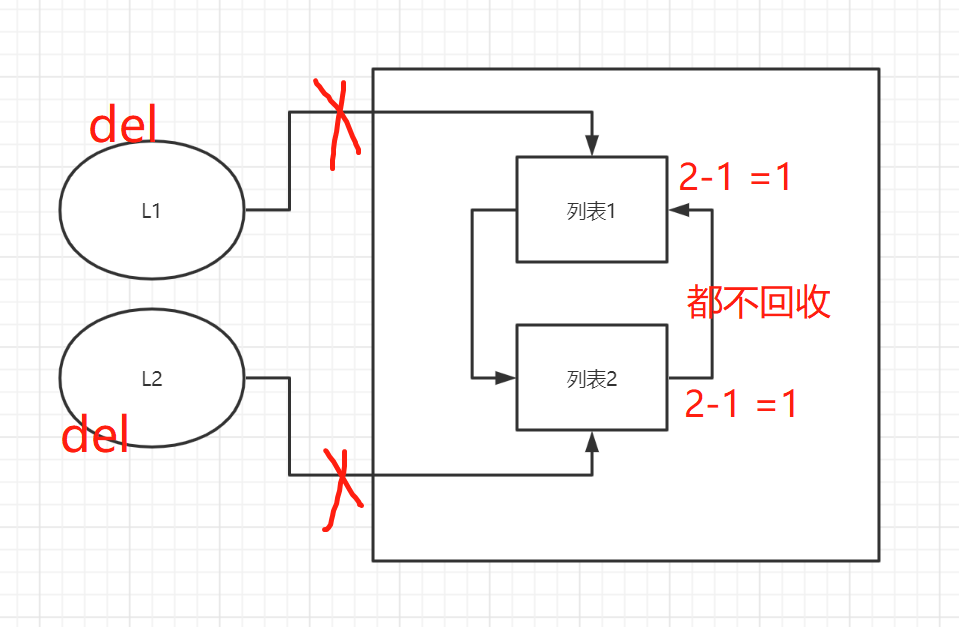
会发现,最终内存中的数据值,虽然两个列表相互引用,但是已经没有变量能够找到这两个数据值了,符合‘垃圾’的定义,但是却没有被回收。
于是,有一个机制,当内存占用临界时,程序会停止运行,扫描程序中的所有数据,把产生循环的数据打上标记,最后清除掉,名为标记清除。
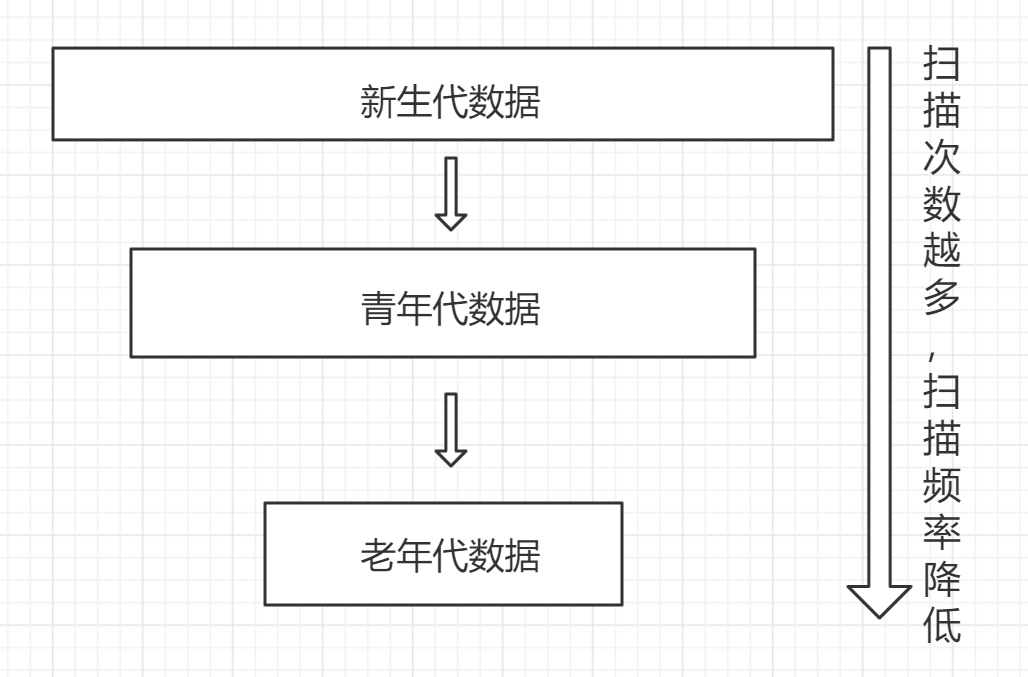
分代回收
标记清除的频繁运行,会导致程序运行的不通畅,于是我们还需要一个机制,来减少标记清除的次数,且依然能达到清理垃圾的效果。
比起一次性扫描所有数据,一次性扫描少量数据,显然对程序执行的影响比较小。
而对于新产生的数据采用较频繁的扫描,对于多次扫描都为发现标记的数据,则认为是不易产生循环引用的数据,采取频率较低的扫描检查,这个就叫分代回收。