综合设计——多源异构数据采集与融合应用综合实践
| 课程名称 | 2024 数据采集与融合技术 |
|---|---|
| 组名与项目简介 | 组名:都给爷爬 项目目标:为心理疾病患者提供个性化音乐疗愈服务 项目背景:现有音乐软件需会员且推荐机制依赖热门趋势,难以满足心理疾病患者的特殊需求。我们希望通过开发一款免费公益的个性化音乐疗愈系统,帮助患者缓解心理压力、改善情绪,填补市场空白。 技术路线:Python(Django、TensorFlow)、爬虫技术、MySQL |
| 团队成员 | 102202135、102202146、102202127、102202125、102202139、102202109、102202128 |
| 项目目标 | 构建一个免费公益音乐疗愈平台,通过个性化推荐帮助心理疾病患者舒缓压力,提升情绪。系统结合患者和医生需求,智能推荐最适合的音乐疗愈方案,提供贴心的心理支持。 |
| 参考文献 | 1. OpenL3 项目 2. BERT 研究论文 3. 机器学习应用 4. CSDN 相关文章 |
- 项目代码仓库:Gitee - Music
- 在线体验:点击这里试玩
🌟 一、项目整体介绍
🔍 1. 项目背景与意义
根据《2022年国民心理健康调查报告》,我国心理健康问题日益严峻,抑郁风险检出率高达10.6%,焦虑风险检出率达到15.8%。随着社会节奏的加快和生活压力的增加,越来越多的人群面临心理健康的挑战,亟需有效的干预和支持手段。音乐疗法作为一种非侵入性且易于接受的辅助治疗方式,已被证明在缓解心理压力、改善情绪状态方面具有显著效果。然而,市面上的大多数音乐软件存在诸多局限:需要付费会员、推荐机制过于依赖热门趋势,缺乏对个体心理状态的精准匹配,难以满足心理疾病患者的特殊需求。
在此背景下,开发一款专门针对心理疾病患者的免费公益音乐疗愈系统显得尤为重要。该系统不仅能够提供个性化的音乐推荐,还能通过科学的算法和多模态数据分析,为用户量身定制疗愈方案,助力改善其心理健康状况。这一项目不仅具有重大的社会意义,还填补了市场在心理健康音乐疗愈领域的空白,能够为广大需要帮助的人群提供切实可行的支持。
🎯 2. 项目目标
本项目旨在构建一个个性化的音乐疗愈平台,专门为心理疾病患者提供定制化的音乐推荐服务,具体目标包括:
- 🎵 个性化推荐:通过深入分析用户的心理状态和音乐偏好,提供精准匹配的音乐疗愈方案,帮助用户缓解心理压力,改善情绪。
- 🆓 免费公益:确保平台的所有功能对用户完全免费,消除经济障碍,让更多有需要的心理疾病患者能够轻松获取音乐疗愈资源。
- 🔗 多模态数据融合:整合音频、文本、图像等多种数据源,提升推荐系统的准确性和有效性,确保推荐结果高度个性化。
- 🤖 智能推荐模块:利用先进的AI技术,根据用户输入的最近心情和心理状态,自动推荐适合的音乐类型,提供即时的心理支持。
- ☁️ 云平台部署:将项目部署到华为云平台,确保系统的高可用性和可扩展性,支持更多用户的同时提供稳定的服务。
📋 3. 项目需求分析
当前市面上的音乐软件存在以下主要问题,尤其在满足心理疾病患者的需求方面表现不足:
- 💰 高额的付费门槛:大多数优质功能需要付费会员,限制了低收入或经济困难患者的使用,无法实现资源的普惠性。
- 🎧 推荐机制缺乏个性化:现有软件的推荐机制过于依赖热门榜单和通用算法,忽视了用户的个体心理状态和特殊需求,导致推荐结果不够贴合。
- 🧠 缺乏针对性心理支持:现有音乐平台主要侧重于娱乐和消遣,缺少专门针对心理疗愈的功能模块,无法提供系统性的心理健康支持。
基于以上需求分析,本项目设计了一套专门针对心理疾病患者的个性化音乐疗愈系统,旨在通过科学的推荐算法和多模态数据分析,为用户提供量身定制的音乐治疗方案,满足其特定的心理健康需求。
🛠️ 4. 项目功能模块
本项目系统由多个功能模块组成,涵盖数据采集、特征提取与融合、推荐算法、用户交互等多个方面,具体包括:
🎼 4.1 多模态数据的特征提取和融合
- 🎧 音频特征提取:使用librosa库提取梅尔频谱图特征、MFCC特征、色度特征和谐波特征,深入分析音乐的音频属性。
- 📄 文本特征提取:利用BERT模型处理用户输入的文本数据,精准捕捉用户的情感和心理状态。
- 🖼️ 图像特征提取:采用预训练的ResNet50模型提取图像特征,为用户界面和视觉推荐提供支持。
- 🔗 特征融合:将多模态特征进行有效融合,生成综合特征向量,并将其存储至数据库,以备后续推荐使用。
🔀 4.2 混合推荐策略
- 结合基于内容的推荐(Content-based Recommendation)和基于协同过滤的推荐(Collaborative Filtering),综合两者的优势。
- 通过加权融合方式生成最终的推荐结果,默认配置为内容推荐权重0.6,协同过滤权重0.4,确保推荐的多样性与精准性。
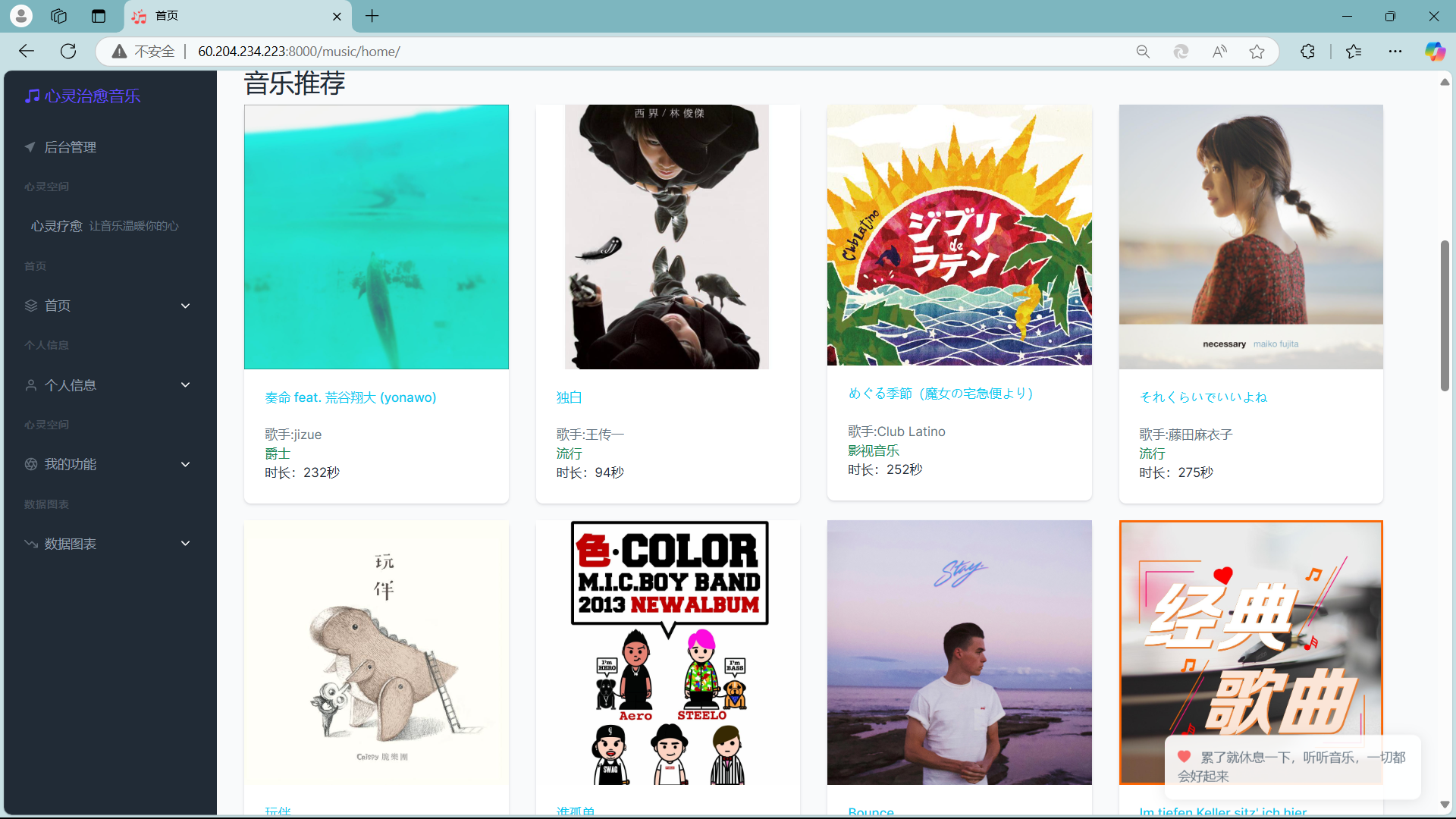
🤖 4.3 智能推荐模块
- 📝 心理状态输入:用户可输入最近的心情和心理状态,系统通过AI分析这些信息。
- 🎯 AI推荐:利用讯飞星火认知大模型API,根据用户的心理状态推荐适合的音乐类型,实现精准的音乐疗愈。
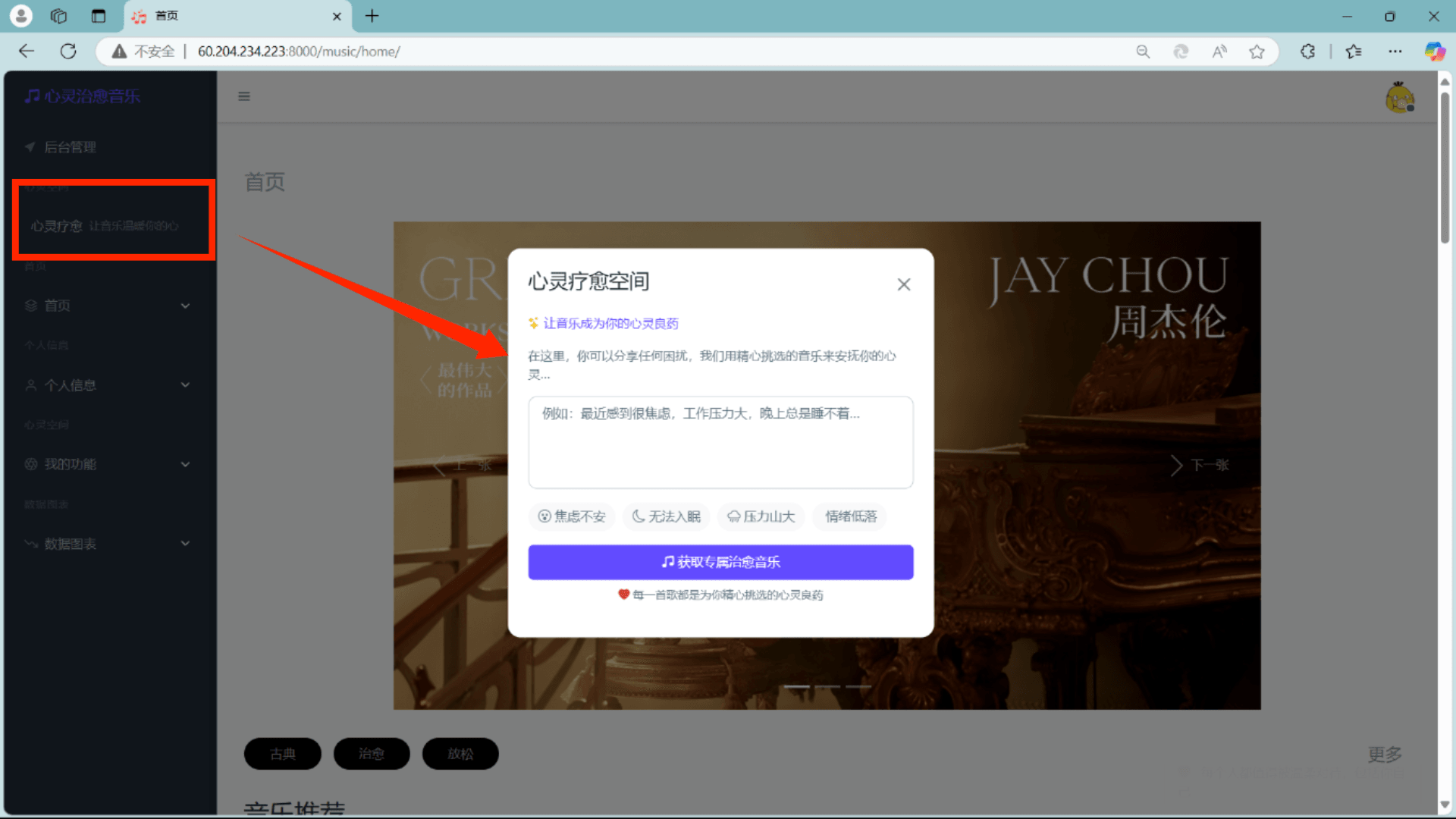
📡 4.4 数据采集模块
- 采用三层架构(基础工具层、歌单爬取层、歌曲爬取层),专门针对音乐心理疗愈推荐系统设计。
- 爬取古典、治愈、放松等类型的音乐数据,通过API接口获取歌单及歌曲信息,实现音频文件的下载、数据的清洗和持久化存储,确保数据的丰富性和高质量。
🎶 4.5 音乐浏览与管理
- 🔍 音乐搜索:提供强大的搜索功能,用户可根据关键词快速找到所需音乐。
- 🔥 热门歌单展示:展示当前流行的歌单,帮助用户发现新的音乐资源。
- 📈 音乐排行榜:根据播放量和用户反馈生成音乐排行榜,展示受欢迎的音乐作品。
👤 4.6 用户数据管理
- ❤️ 我的收藏:用户可以收藏喜欢的音乐,方便随时回听,增强用户体验。
- 📜 播放记录:记录用户的播放历史,辅助个性化推荐,提升推荐系统的精准度。
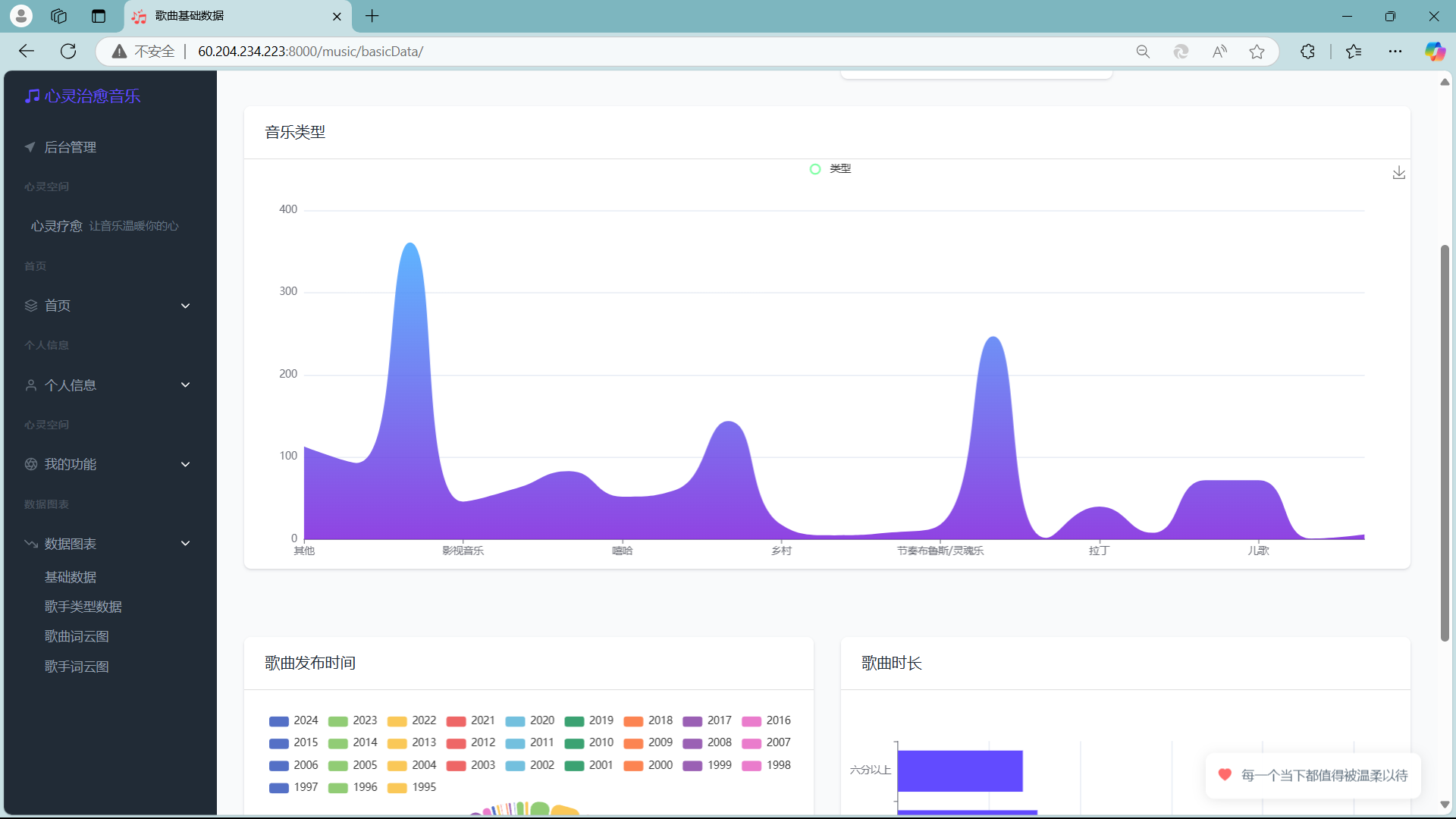
📊 4.7 数据可视化
- 提供音乐数据库的基础数据统计,包括总量、用户量、歌曲发布时间、歌曲时长、歌手类型等,通过直观的图表形式展示,帮助项目团队和用户了解平台的运行状况和音乐资源分布。
☁️ 4.8 项目部署模块
- 🌐 云平台选择:选择华为云作为部署平台,利用其稳定的云服务和高可用性,确保系统能够承载大量用户访问。
- 🔓 公网访问:通过配置服务器的公网IP,使得其他电脑和用户能够通过互联网访问和使用项目。
5. 项目架构 🚀
5.1 前端层 (Presentation Layer) 🎨
前端负责与用户交互,展示推荐结果和用户行为数据,确保流畅的用户体验。
技术栈:
- HTML5 + CSS3:构建网页结构和样式,保证响应式设计与跨平台兼容性。
- JavaScript:实现动态交互和数据处理逻辑。
- Bootstrap 5:提供快速布局开发,提升界面美观度和一致性。
功能实现:
- 展示歌曲推荐结果、用户偏好和推荐算法反馈的数据。
- 用户通过网页提交行为数据(如评分、评论、播放历史)。
- 通过 Django REST framework API 与后端进行数据交互。
5.2 后端层 (Business Layer) 🛠️
后端主要处理用户请求、管理数据存储和执行推荐算法及多模态特征的提取和融合。
技术栈:
- Python Django 框架:用于后端开发,管理数据与业务逻辑。
- Django REST framework (DRF):用于实现 API 服务,支持前后端分离架构。
核心模块与功能:
- 特征提取模块:提取文本(BERT)、图像(ResNet50)、音频(梅尔频谱图、MFCC)等多模态特征,通过并行处理提高效率。
- 推荐算法模块:结合内容推荐与协同过滤算法,使用加权融合提升推荐的准确性与多样性。
- 用户偏好建模模块:根据用户行为(收藏、评分、评论、播放历史)建立偏好模型。
- 特征融合模块:通过 多头注意力机制 和 线性投影 融合音频、图像、文本特征,输出统一的特征向量。
- 特征存储模块:利用 Django ORM 操作数据库,结合事务机制确保数据一致性,并通过缓存提高特征读取效率。
5.3 数据层 (Data Layer) 💾
数据层负责存储用户行为数据、歌曲信息及提取的多模态特征。
技术栈:
- MySQL:用于存储关系型数据,支持复杂查询和事务操作。
数据库结构:
- 歌曲信息表:存储歌曲的基本信息(如歌名、歌手、专辑等)及多模态特征。
- 用户行为数据表:记录用户的收藏、评分、评论和播放历史。
- 特征缓存表:存储提取的音频、图像、文本及融合特征,采用序列化存储以提高读取效率。
5.4 AI 接口 🤖
AI接口包括特征提取与推荐服务。
功能模块:
- 特征提取接口:
- 文本特征:基于 BERT 提取。
- 图像特征:基于 ResNet50 提取。
- 音频特征:利用自定义音频处理模型提取 梅尔频谱图 和 MFCC 特征。
- 提供异步和并行处理提高特征提取效率。
- 推荐接口:
- 结合用户行为数据与歌曲特征,通过加权融合的内容推荐与协同过滤算法生成最终推荐列表,返回给前端展示。
新增星火大模型:
为了提升推荐系统的智能化水平,新增了 星火大模型(Xinghuo Large Model)。该模型基于深度学习与大规模数据集训练,能够为推荐系统提供更精准的用户行为预测和个性化推荐。星火大模型通过对用户行为的深度理解,优化推荐算法,并能动态调整模型权重,进一步提高推荐的多样性和准确性。
5.5 爬虫模块 🕷️
爬虫模块负责从 千千音乐(https://music.91q.com)抓取歌曲与歌单信息。
功能点:
- 解析 API 请求,批量爬取歌曲信息。
- 将爬取的数据存储到数据库中,为推荐算法提供数据支持。
5.6 部署平台 🌐
系统部署在 华为云平台,以保证高可用性和稳定性。
部署特点:
- 提供弹性伸缩能力,应对高峰访问需求。
- 配合云数据库与缓存服务,优化系统性能。
二、个人工作部分
🛠️ 1. 多模态数据的特征提取和融合
在本项目中,多模态数据的特征提取与融合是提升推荐系统精准性和个性化程度的关键环节。我主要负责设计并实现了文本、图像和音频特征的提取流程,以及这些特征的有效融合与存储。以下是具体的工作内容与技术实现细节:
📄 1.1 文本特征提取 (TextFeatureExtractor)
文本特征提取部分采用了BERT(Bidirectional Encoder Representations from Transformers)模型,旨在捕捉用户输入文本的深层语义信息。具体实现步骤如下:
# 初始化BERT模型和分词器
self.tokenizer = AutoTokenizer.from_pretrained(
cache_dir,
local_files_only=True
)
self.model = AutoModel.from_pretrained(
cache_dir,
local_files_only=True
)
特征提取流程:
# 1. 文本预处理和分词
inputs = self.tokenizer(
text,
return_tensors="pt",
padding=True,
truncation=True,
max_length=512
)
# 2. 使用BERT模型提取特征
with torch.no_grad():
outputs = self.model(**inputs)
features = outputs.last_hidden_state[:, 0, :].squeeze()
关键点说明:
- 模型选择:采用预训练的BERT模型,能够有效捕捉文本的上下文语义关系。
- 特征维度:提取768维的文本特征向量,利用BERT模型的[CLS]标记作为整体文本的代表。
- 优化措施:限制输入文本长度为512个token,以平衡特征丰富性与计算效率,确保模型在处理长文本时依然保持高效。
🖼️ 1.2 图像特征提取 (ImageFeatureExtractor)
图像特征提取部分使用了预训练的ResNet50模型,通过提取图像的高级特征,为推荐系统提供丰富的视觉信息支持。
# 初始化ResNet50模型
self.model = models.resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
self.model = nn.Sequential(*list(self.model.children())[:-1])
# 图像预处理流程
self.transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
特征提取流程:
# 1. 图像预处理
image = self.transform(image).unsqueeze(0)
# 2. 使用ResNet提取特征
with torch.no_grad():
features = self.model(image)
features = features.squeeze()
关键点说明:
- 模型选择:采用ResNet50预训练模型,能够高效提取图像的深层次特征。
- 特征维度:输出2048维的图像特征向量,确保视觉信息的全面表达。
- 优化措施:支持本地和网络图片的处理,图像预处理包括调整大小、中心裁剪和标准化,以适应模型输入要求,提高特征提取的一致性和准确性。
🎵 1.3 音频特征提取 (AudioFeatureExtractor)
音频特征提取部分综合了多种音频特征,以全面描述音乐的音频属性,从而增强推荐系统的理解能力。
# 初始化参数
def __init__(self, sr=22050, duration=30):
self.sr = sr # 采样率
self.duration = duration # 处理时长
特征提取过程包含四个主要部分:
# 1. 梅尔频谱图特征
mel_spec = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
mel_features = np.mean(mel_spec, axis=1)
# 2. MFCC特征
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=20)
mfcc_features = np.mean(mfcc, axis=1)
# 3. 色度特征
chroma = librosa.feature.chroma_stft(y=y, sr=sr)
chroma_features = np.mean(chroma, axis=1)
# 4. 谐波特征
harmonic = librosa.effects.harmonic(y)
harmonic_features = np.mean(librosa.feature.spectral_contrast(y=harmonic, sr=sr), axis=1)
关键点说明:
- 特征组合:提取梅尔频谱图(128维)、MFCC(20维)、色度(12维)和谐波特征(7维),总计512维的音频特征向量,全面覆盖音乐的频谱、音高、节奏等多维度信息。
- 优化措施:仅处理音频前30秒,以提高处理效率,同时采用22050Hz的采样率,确保音质与计算资源的平衡。
- 特征描述:
- 梅尔频谱图:捕捉音频的频谱特性,反映音乐的能量分布。
- MFCC:描述音频的短时功率谱密度,广泛应用于语音和音乐分析。
- 色度特征:表示音频中的音高类别,反映音乐的和声结构。
- 谐波特征:捕捉音频中的谐波信息,反映音乐的音色特性。
🔗 1.4 特征融合及存储过程
在完成各模态特征的提取后,接下来是特征的融合与存储。这一过程确保了不同模态特征的有效整合,从而提升推荐系统的综合表现。
特征提取过程
首先,通过BaseFeatureExtractor类并行提取三种模态的特征,以提高处理效率:
def extract_features(self, song):
try:
with self.graph:
# 使用线程池并行提取三种特征
with ThreadPoolExecutor(max_workers=3) as executor:
# 提取音频特征
audio_future = executor.submit(
self.audio_extractor.extract_features,
song.songUrl.path
)
# 提取文本特征
text_content = f"{song.title} {song.singer} {song.albumTitle} {song.lyric}"
text_future = executor.submit(
self.text_extractor.extract_features,
text_content
)
# 提取图像特征
image_future = executor.submit(
self.image_extractor.extract_features,
song.img
)
关键点分析:
- 并行处理:利用
ThreadPoolExecutor实现音频、文本、图像特征的并行提取,显著提升整体特征提取的效率。 - 特征维度:
- 音频特征:512维
- 文本特征:768维(BERT模型输出)
- 图像特征:2048维(ResNet50输出)
🤝 特征融合过程
特征融合通过MultiModalFeatureFusion类实现,采用多头注意力机制和线性投影技术,将不同模态的特征整合为统一的向量表示:
class MultiModalFeatureFusion(nn.Module):
def __init__(self, audio_dim=512, text_dim=768, image_dim=2048, output_dim=256):
super().__init__()
# 特征降维层
self.audio_projection = nn.Linear(audio_dim, output_dim)
self.text_projection = nn.Linear(text_dim, output_dim)
self.image_projection = nn.Linear(image_dim, output_dim)
# 注意力层
self.attention = nn.MultiheadAttention(output_dim, num_heads=4)
# 最终融合层
self.fusion_layer = nn.Sequential(
nn.Linear(output_dim * 3, output_dim),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(output_dim, output_dim)
)
融合过程分析:
-
维度统一:
- 通过线性投影将音频、文本和图像特征分别降维至256维,确保不同模态特征在同一维度空间内进行融合。
-
多头注意力机制:
- 采用4头注意力机制,能够捕捉不同模态特征之间的复杂关联和重要性权重,提升融合特征的表达能力。
-
最终融合:
- 将降维后的三种特征向量拼接,通过全连接层进行融合。
- 使用ReLU激活函数和Dropout层,既增强了特征表达的非线性能力,又有效防止了模型的过拟合。
- 最终输出256维的融合特征向量,作为综合多模态信息的高效表示。
特征存储过程
特征存储通过FeatureCache类实现,确保提取的特征能够高效且可靠地存储与访问:
@classmethod
def batch_cache_features(cls, songs):
try:
# 获取特征提取器
extractor = cls.get_extractor()
# 批量提取特征
features_dict = extractor.process_songs(songs)
# 批量保存到数据库
with transaction.atomic():
for song_id, features in features_dict.items():
if features is not None:
song = next(s for s in songs if s.songId == song_id)
features_obj, _ = SongFeatures.objects.get_or_create(song=song)
# 序列化并存储特征
features_obj.audio_features = cls.serialize_features(features['audio'])
features_obj.text_features = cls.serialize_features(features['text'])
features_obj.image_features = cls.serialize_features(features['image'])
features_obj.fused_features = cls.serialize_features(features['fused'])
features_obj.save()
存储过程分析:
-
特征序列化:
- 使用
pickle模块将特征向量序列化,便于在数据库中存储复杂的numpy数组结构。
- 使用
-
数据库存储:
- 利用Django的ORM框架进行数据库操作,确保数据的一致性和完整性。
- 通过事务管理(
transaction.atomic())确保批量保存过程中的数据一致性,防止部分数据保存失败导致的不一致状态。 - 分别存储音频、文本、图像及融合后的特征向量,确保每个特征的独立性和可追溯性。
-
特征读取:
@staticmethod
def get_cached_features(song):
try:
features = SongFeatures.objects.get(song=song)
return {
'audio': FeatureCache.deserialize_features(features.audio_features),
'text': FeatureCache.deserialize_features(features.text_features),
'image': FeatureCache.deserialize_features(features.image_features),
'fused': FeatureCache.deserialize_features(features.fused_features)
}
except SongFeatures.DoesNotExist:
return None
特征读取分析:
- 缓存机制:通过
FeatureCache类实现快速读取特征,减少重复计算,提升系统响应速度。 - 异常处理:在特征不存在时返回
None,确保系统在缺失数据时的鲁棒性,避免因异常数据导致的系统崩溃。
🎯 2. 混合推荐算法
在本项目中,混合推荐算法的设计与实现是提升推荐系统性能的关键。我主要负责开发和优化结合基于内容的推荐(Content-based Recommendation)与基于协同过滤的推荐(Collaborative Filtering)的混合推荐策略。以下是具体的工作内容与技术实现细节:
🏗️ 2.1 推荐算法整体架构
本系统采用了混合推荐策略,通过结合内容推荐与协同过滤推荐的优势,提升了推荐结果的多样性和准确性。默认权重配置为内容推荐权重0.6,协同过滤权重0.4。这种加权融合的方法有效地平衡了个性化推荐与群体推荐的需求,确保了推荐结果既贴合用户的个人偏好,又能引入用户可能感兴趣的新内容。
👤 2.2 用户偏好建模
用户偏好建模是推荐系统的基础,通过分析用户的多维度行为数据,构建用户的兴趣画像。我设计了一个综合考虑收藏、评分、评论和播放历史的用户偏好模型,具体实现如下:
def get_user_preferences(self, user) -> Dict[int, float]:
preferences = defaultdict(float)
# 收集用户行为数据
collect_songs = CollectSong.objects.filter(user=user)
rate_songs = RateSong.objects.filter(user=user)
comment_songs = CommentSong.objects.filter(user=user)
history_songs = HistorySong.objects.filter(user=user)
# 为不同行为分配权重
for collect in collect_songs:
preferences[collect.song.songId] += 1.0 # 收藏权重最高
for rate in rate_songs:
preferences[rate.song.songId] += float(rate.rate) / 5.0 # 评分权重
for comment in comment_songs:
preferences[comment.song.songId] += 0.5 # 评论权重
for history in history_songs:
preferences[history.song.songId] += 0.3 * (history.play_count / 10) # 播放次数权重
关键点说明:
- 多维度行为建模:全面考虑用户的收藏、评分、评论和播放历史,构建多维度的用户偏好画像。
- 差异化权重分配:
- 收藏行为权重最高(1.0),体现用户对特定歌曲的强烈喜好。
- 评分权重根据评分高低动态赋值(0-1.0),反映用户对歌曲的具体评价。
- 评论行为权重为0.5,表示中等程度的兴趣。
- 播放次数权重为0.3 * (播放次数/10),反映用户的长期行为偏好。
- 权重归一化:通过对不同行为的权重进行合理分配,确保用户偏好的可比性和准确性。
🤝 2.3 协同过滤推荐算法
协同过滤推荐算法通过分析用户之间的相似性,挖掘潜在的音乐偏好。我实现了基于用户的协同过滤(User-based Collaborative Filtering),具体代码如下:
def collaborative_recommend(self, user, all_songs: List[Song], top_n: int) -> List[Tuple[Song, float]]:
try:
# 获取用户的行为记录
user_songs = set(CollectSong.objects.filter(user=user).values_list('song_id', flat=True))
# 找到相似用户
similar_users = CollectSong.objects.filter(song_id__in=user_songs).exclude(user=user)\
.values('user').annotate(common_songs=Count('user'))\
.order_by('-common_songs')[:50]
# 计算推荐分数
song_scores = defaultdict(float)
for similar_user in similar_users:
similarity = similar_user['common_songs'] / len(user_songs)
similar_user_songs = CollectSong.objects.filter(user_id=similar_user['user'])
for collect in similar_user_songs:
if collect.song.songId not in user_songs: # 排除已收藏歌曲
song_scores[collect.song] += similarity
关键点说明:
- 基于用户的协同过滤:通过分析用户之间的共同收藏行为,找到与当前用户最相似的前50位用户。
- 用户相似度计算:基于共同收藏的歌曲数量与当前用户收藏歌曲总数的比例,计算相似度。
- 相似用户筛选:选择前50个最相似的用户,以确保推荐的相关性和多样性。
- 排除机制:避免推荐用户已收藏的歌曲,确保推荐结果的新颖性。
- 评分累加:相似用户的推荐得分通过相似度进行加权累加,反映推荐歌曲的潜在吸引力。
📝 2.4 基于内容的推荐算法
基于内容的推荐算法通过分析用户的兴趣画像与歌曲的内容特征,推荐与用户偏好相似的歌曲。具体实现如下:
def content_based_recommend(self, user_preferences: Dict[int, float], all_songs: List[Song], top_n: int):
try:
if not user_preferences:
return []
# 构建用户特征向量
user_song_features = []
user_weights = []
for song_id, weight in user_preferences.items():
features = FeatureCache.get_cached_features(song)
if features is not None:
feat = torch.tensor(features['fused'], dtype=torch.float32)
user_song_features.append(feat)
user_weights.append(weight)
# 计算加权平均用户特征向量
user_profile = torch.sum(torch.stack(user_song_features) * torch.tensor(user_weights).unsqueeze(1), dim=0) / torch.sum(torch.tensor(user_weights))
# 计算相似度
similarities = []
for song in all_songs:
if song.songId not in user_preferences:
features = FeatureCache.get_cached_features(song)
if features is not None:
song_features = torch.tensor(features['fused'], dtype=torch.float32)
similarity = torch.nn.functional.cosine_similarity(user_profile, song_features, dim=0)
similarities.append((song, similarity.item()))
# 按相似度排序并返回前top_n
similarities.sort(key=lambda x: x[1], reverse=True)
return similarities[:top_n]
关键点说明:
- 用户画像构建:基于用户的收藏、评分、评论和播放历史,计算加权平均的用户特征向量,全面反映用户的音乐偏好。
- 特征表示:利用融合后的多模态特征(256维),确保用户和歌曲的特征表示具备丰富的语义信息。
- 相似度计算:采用余弦相似度衡量用户特征向量与歌曲特征向量之间的相似性,量化推荐歌曲的匹配度。
- 排除机制:避免推荐用户已交互的歌曲,确保推荐结果的新颖性和多样性。
🔀 2.5 混合推荐策略
混合推荐策略将基于内容的推荐与协同过滤推荐的结果进行加权融合,综合两者的优势,生成最终的推荐列表。具体实现如下:
def hybrid_recommend(self, user, all_songs: List[Song], top_n: int = 10) -> List[Song]:
try:
# 获取用户偏好
user_preferences = self.get_user_preferences(user)
# 获取两种推荐结果
content_recs = self.content_based_recommend(user_preferences, all_songs, top_n)
collaborative_recs = self.collaborative_recommend(user, all_songs, top_n)
# 合并推荐结果
song_scores = defaultdict(float)
# 加权融合
for song, score in content_recs:
song_scores[song] += score * self.content_weight
for song, score in collaborative_recs:
song_scores[song] += score * self.collaborative_weight
# 按综合得分排序并返回前top_n
sorted_songs = sorted(song_scores.items(), key=lambda x: x[1], reverse=True)
return [song for song, score in sorted_songs[:top_n]]
关键点说明:
- 线性加权融合:
- 内容推荐权重:0.6,强调个性化推荐,确保推荐结果贴合用户的具体偏好。
- 协同过滤权重:0.4,引入群体推荐的优势,提升推荐结果的多样性和发现新内容的可能性。
- 动态权重调整:权重配置可根据实际推荐效果和用户反馈进行调优,确保推荐系统的灵活性和适应性。
- 归一化处理:对内容推荐和协同过滤的推荐分数进行标准化处理,确保不同推荐源的分数在同一尺度上进行比较和融合。
- 排序机制:根据综合得分对推荐歌曲进行排序,选取前top_n的歌曲作为最终推荐结果,确保推荐列表的高质量和相关性。
混合推荐策略优势:
- 综合优势:结合内容推荐和协同过滤的优点,既能满足用户的个性化需求,又能通过群体推荐发现用户可能感兴趣的新内容。
- 推荐多样性:通过加权融合,推荐结果不仅贴合用户现有偏好,还能引入多样化的音乐资源,提升用户体验。
- 系统鲁棒性:在单一推荐策略效果不佳时,混合推荐策略能够通过另一种策略补充推荐结果,增强系统的鲁棒性和稳定性。
📝 2.6 推荐解释机制
为了提升用户对推荐结果的信任度和满意度,我还设计了推荐解释机制,通过多维度的解释为用户提供推荐理由。具体实现如下:
def explain_recommendation(self, user, song: Song) -> str:
try:
explanation = f"为您推荐《{song.title}》的原因:\n"
# 基于内容的解释
similar_songs = self.get_similar_songs(song)
if similar_songs:
similar_songs.sort(key=lambda x: x[1], reverse=True)
top_similar = similar_songs[:3]
song_names = [f"{s.title} (相似度: {s.similarity:.2f})" for s in top_similar]
explanation += "• 与您喜欢的歌曲相似:\n" + "\n".join(song_names) + "\n"
# 协同过滤的解释
similar_users = CollectSong.objects.filter(song=song).values('user').annotate(count=Count('user'))
if similar_users.exists():
user_count = similar_users.count()
explanation += f"• 有 {user_count} 位用户收藏了这首歌\n"
return explanation
except Exception as e:
return "推荐解释不可用。"
关键点说明:
- 内容相似度:基于用户喜欢的歌曲,推荐与之相似的歌曲,提供相似度评分,帮助用户理解推荐的原因。
- 社会化推荐:展示有多少其他用户也收藏了该歌曲,增加推荐的可信度和社交认同感。
- 具体数据支持:通过具体的相似度评分和用户数量,提供量化的推荐理由,使推荐解释更具说服力。
- 人性化展示:采用自然语言描述推荐理由,提升用户体验和理解度。
🛠️ 2.3 心灵疗愈推荐模块
智能推荐模块是系统的核心功能之一,我在前端和后端的设计与实现中,确保了用户能够通过简单的操作获取精准的音乐推荐。这一模块不仅涉及到AI接口的集成,还包括用户界面的友好设计和推荐逻辑的高效实现。
🔌 2.3.1 系统接口与AI集成
为了实现智能推荐功能,我集成了讯飞星火认知大模型的API接口,利用其强大的自然语言处理能力分析用户的心理状态,并基于此推荐合适的音乐类型。具体实现如下:
class AIMusicRecommender:
def __init__(self):
self.url = "https://spark-api-open.xf-yun.com/v1/chat/completions"
self.music_types = [
"轻音乐", "古典", "新世纪", "民谣", "爵士", # 舒缓、放松类型
"流行", "世界音乐", "自然音乐", # 情感表达类型
"中国特色", "电音", "摇滚" # 能量释放类型
]
🎵 2.3.2 音乐类型分类体系
为了更好地匹配用户的心理状态,我设计了一个详细的音乐类型分类体系,涵盖舒缓放松类、情感表达类和能量释放类,每类包含多种具体的音乐类型:
-
舒缓放松类:
- 轻音乐:适合缓解焦虑
- 古典音乐:帮助心理平静
- 新世纪音乐:适合冥想放松
- 民谣:促进情感共鸣
- 爵士:缓解压力
-
情感表达类:
- 流行音乐:情绪调节
- 世界音乐:开阔心境
- 自然音乐:助眠放松
-
能量释放类:
- 中国特色音乐:文化认同感
- 电音:能量释放
- 摇滚:压力释放
📝 2.3.3 心理治疗导向的系统提示
为了引导AI模型更好地理解并推荐合适的音乐类型,我设计了心理治疗导向的系统提示,明确了推荐的原则和可选音乐类型:
system_content = (
"你是一个专业的音乐治疗师,专门为有心理困扰的人提供音乐疗愈建议。"
"根据用户描述的心理状态,你需要推荐最适合的音乐类型来帮助他们:"
"\n\n可选的音乐类型包括:{}\n\n"
"请根据以下原则推荐:\n"
"1. 焦虑症状:优先考虑轻音乐、古典音乐等舒缓类型\n"
"2. 抑郁情绪:建议节奏温和的民谣、爵士等能引起共鸣的类型\n"
"3. 失眠问题:推荐新世纪、自然音乐等助眠类型\n"
"4. 压力管理:可以考虑流行、摇滚等帮助释放压力的类型\n"
"5. 情绪调节:世界音乐、中国特色音乐等能带来新体验的类型\n"
)
关键点说明:
- 明确角色:AI被设定为专业的音乐治疗师,增强其在推荐过程中的专业性和可信度。
- 推荐原则:根据不同的心理状态,优先推荐对应的音乐类型,确保推荐的针对性和有效性。
- 可选音乐类型:提供具体的音乐类型选项,方便AI在推荐时进行选择和权衡。
🎚️ 2.3.4 音乐类型权重分配
为了进一步优化推荐结果,我设计了音乐类型的权重分配机制,根据不同音乐类型的治疗效果赋予不同的权重:
def get_type_weights(self, recommended_types: List[str]) -> dict:
# 基础权重定义
base_weights = {
"轻音乐": 1.0, # 最适合舒缓情绪
"古典": 1.0, # 有助于心理平静
"新世纪": 0.9, # 适合放松冥想
"民谣": 0.8, # 情感共鸣
"爵士": 0.8, # 缓解压力
"流行": 0.7, # 情绪调节
"世界音乐": 0.7, # 开阔心境
"自然音乐": 0.9, # 助眠放松
"中国特色": 0.7, # 文化认同
"电音": 0.6, # 能量释放
"摇滚": 0.6 # 压力释放
}
关键点说明:
- 基础权重定义:根据不同音乐类型的治疗效果,赋予不同的基础权重,确保推荐结果的有效性和针对性。
- 动态调整:权重配置可根据实际使用反馈和效果进行动态调整,提升推荐系统的灵活性和适应性。
🔄 2.3.5 心理疗愈推荐流程
整个心理疗愈推荐流程由用户输入处理、音乐类型推荐和具体音乐推荐三部分组成,确保系统能够根据用户的心理状态提供精准的音乐疗愈服务。
(1) 用户输入处理
- 用户描述心理状态和困扰:用户在前端界面输入近期的心情和心理状态,如“最近感到很焦虑,工作压力大,晚上总是睡不着...”
- 系统传递文本给AI模型:将用户输入的文本通过AI接口传递给讯飞星火认知大模型进行分析。
- AI模型分析心理状态:AI模型根据输入文本分析用户的心理状态,并推荐适合的音乐类型。
(2) 音乐类型推荐
- AI模型推荐音乐类型:根据心理治疗原则,AI模型选择1-3个最适合的音乐类型。
- 系统提取推荐的音乐类型并计算权重:系统根据AI模型的推荐结果,提取相应的音乐类型,并根据预设的权重进行打分。
- 权重计算考虑:
- 基础治疗效果权重:根据音乐类型的治疗效果赋予不同的基础权重。
- 推荐顺序权重:越靠前的推荐类型权重越高,确保首选类型的优先推荐。
(3) 具体音乐推荐
- 根据推荐的音乐类型筛选歌曲:系统根据推荐的音乐类型,从数据库中筛选符合条件的歌曲。
- 结合混合推荐系统的两个维度:
- 基于内容的推荐:考虑歌曲的音频、文本、图像特征,确保推荐的歌曲与用户偏好高度匹配。
- 协同过滤推荐:结合其他用户的听歌行为,发现潜在的音乐偏好,提升推荐结果的多样性和新颖性。
前端设计:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>智能推荐</title>
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
</head>
<body>
<h1>个性化音乐推荐</h1>
<textarea id="userInput" placeholder="请输入您的心情和心理状态"></textarea><br>
<button id="recommendBtn">获取推荐</button>
<div id="recommendations"></div>
<div id="moodDialog" class="mood-dialog">
<div class="mood-content">
<div class="mood-header">
<h3><i class="bi bi-heart-pulse text-danger"></i> 心灵疗愈空间</h3>
<button type="button" class="btn-close" onclick="closeMoodDialog()"></button>
</div>
<div class="mood-body">
<p class="mood-tip">
<i class="bi bi-stars text-warning"></i>
<span class="text-primary">让音乐成为你的心灵良药</span>
</p>
<p class="mood-tip text-muted small">
在这里,你可以分享任何困扰,我们用精心挑选的音乐来安抚你的心灵...
</p>
<textarea id="moodText" class="form-control" rows="4"
placeholder="例如:最近感到很焦虑,工作压力大,晚上总是睡不着..."></textarea>
<div class="mood-suggestions mt-3">
<span class="mood-tag" onclick="insertMood('焦虑')">
<i class="bi bi-emoji-dizzy"></i> 焦虑不安
</span>
<span class="mood-tag" onclick="insertMood('失眠')">
<i class="bi bi-moon"></i> 无法入眠
</span>
<span class="mood-tag" onclick="insertMood('压力大')">
<i class="bi bi-cloud-rain"></i> 压力山大
</span>
<span class="mood-tag" onclick="insertMood('心情低落')">
<i class="bi bi-heart-break"></i> 情绪低落
</span>
</div>
<button class="btn btn-primary w-100 mt-3" onclick="submitMood()">
<i class="bi bi-music-note-beamed"></i> 获取专属治愈音乐
</button>
<p class="text-center text-muted mt-2 small">
<i class="bi bi-heart-fill text-danger"></i>
每一首歌都是为你精心挑选的心灵良药
</p>
</div>
</div>
</div>
</body>
</html>
关键点说明:
- 用户界面:设计了简洁直观的用户界面,用户可以在文本框中输入心情和心理状态,点击“获取推荐”按钮获取个性化音乐推荐。
- 交互设计:使用jQuery进行异步请求,确保用户体验流畅,无需刷新页面即可获取推荐结果。
- 治愈话语:在用户界面中集成了治愈话语的展示模块,通过定期随机显示温暖的话语,提升用户的心理舒适度和系统的亲和力。
💖 2.3.6 治愈话语实现
为了在用户使用过程中提供额外的心理支持,我设计并实现了治愈话语模块,定期向用户展示温暖的话语,提升用户的心理舒适度。
<div id="healingWords" class="healing-words" style="display: none;">
<i class="bi bi-heart-fill"></i>
<span id="healingText"></span>
</div>
<script>
// 治愈话语列表
const healingMessages = [
"音乐是最温柔的良药,让我们一起感受它的治愈力量",
"每一个当下都值得被温柔以待",
"你的心情我们都懂,让音乐陪伴你度过这一刻",
"生活总有起起落落,但音乐永远在这里等你",
"累了就休息一下,听听音乐,一切都会好起来",
"愿这些音符能抚平你内心的波澜",
"相信明天会更好,让我们一起期待",
"你并不孤单,音乐一直都在陪伴着你",
"每个人都值得被温柔对待,包括你自己",
"让音乐带你进入一个温暖的世界"
];
// 显示治愈话语的函数
function showHealingWords() {
const container = document.getElementById('healingWords');
const textElement = document.getElementById('healingText');
const randomMessage = healingMessages[Math.floor(Math.random() * healingMessages.length)];
textElement.textContent = randomMessage;
container.style.display = 'block';
// 5秒后隐藏
setTimeout(() => {
container.style.display = 'none';
}, 5000);
}
// 定期显示治愈话语
setInterval(showHealingWords, 8000); // 每8秒显示一次
// 页面加载后立即显示一次
setTimeout(showHealingWords, 2000);
</script>
关键点说明:
- 治愈话语列表:预定义了一系列温暖且治愈的话语,旨在在用户使用过程中提供额外的心理支持。
- 动态展示:通过JavaScript定期随机显示治愈话语,避免重复和单调,提升用户体验。
- 视觉效果:结合图标和样式设计,使治愈话语的展示更加直观和吸引人,增强用户的心理舒适感。
🖥️ 2.3.7 后端设计
智能推荐模块的后端设计负责处理用户输入,调用推荐算法,并将推荐结果返回给前端。具体实现如下:
# views.py
from django.shortcuts import render
from django.http import JsonResponse
from .recommendation import HybridRecommender
from .feature_cache import FeatureCache
def get_recommendations(request):
user_id = request.GET.get('user_id')
user_input = request.GET.get('input') # 用户输入的心情和心理状态
# 提取用户输入的文本特征
text_features = TextFeatureExtractor().extract_features(user_input)
# 获取所有歌曲的融合特征
all_songs = Song.objects.all()
song_features = [FeatureCache.get_cached_features(song) for song in all_songs]
# 计算内容推荐分数
content_scores = compute_content_scores(text_features, song_features)
# 计算协同过滤分数
collaborative_scores = compute_collaborative_scores(user_id)
# 混合推荐
recommender = HybridRecommender()
recommended_song_ids = recommender.recommend(user_id, content_scores, collaborative_scores)
# 返回推荐结果
recommendations = Song.objects.filter(id__in=recommended_song_ids).values('id', 'title', 'artist')
return JsonResponse({'recommendations': list(recommendations)})
关键点说明:
- 用户输入处理:接收用户输入的心情和心理状态,通过
TextFeatureExtractor提取文本特征,为推荐算法提供依据。 - 特征匹配与推荐计算:基于提取的文本特征和用户偏好,计算内容推荐分数和协同过滤分数,确保推荐结果的多样性和相关性。
- 推荐结果返回:将最终的推荐结果通过JSON格式返回给前端,确保前后端的高效交互。
| 课程名称 | 2024 数据采集与融合技术 |
|---|---|
| 组名与项目简介 | 组名:都给爷爬 项目目标:为心理疾病患者提供个性化音乐疗愈服务 项目背景:现有音乐软件需会员且推荐机制依赖热门趋势,难以满足心理疾病患者的特殊需求。我们希望通过开发一款免费公益的个性化音乐疗愈系统,帮助患者缓解心理压力、改善情绪,填补市场空白。 技术路线:Python(Django、PyTorch、TensorFlow)、爬虫技术、MySQL |
| 团队成员 | 102202135、102202146、102202127、102202125、102202139、102202109、102202128 |
| 项目目标 | 构建一个免费公益音乐疗愈平台,通过个性化推荐帮助心理疾病患者舒缓压力,提升情绪。系统结合患者和医生需求,智能推荐最适合的音乐疗愈方案,提供贴心的心理支持。 |
| 参考文献 | 1. OpenL3 项目 2. BERT 研究论文 3. 机器学习应用 4. CSDN 相关文章 |
个人项目总结
回顾整个项目的实施过程,我心中充满了感慨与成就感。这不仅是一段技术上的探索之旅,更是一次自我突破与成长的宝贵经历。
在项目初期,为了更好地理解和参与项目的各个环节,我自学了大量新知识,特别是Vue和Django框架,这一过程充满了挑战。面对陌生的技术栈,我经历了无数次的试错与调试,但每当成功实现一个功能,内心的成就感与满足感便油然而生,激励我不断前行。
在此次项目中,我独立完成了一个关键模块的前后端开发以及AI接口的接入。这不仅考验了我的编程能力,更锻炼了我在实际项目中解决问题的能力。从设计用户界面到实现后端逻辑,再到与AI模型的无缝对接,每一步都需要细致的思考与不懈的努力。尤其是在与AI接口的集成过程中,面对接口调用的不确定性和调试的复杂性,我一度感到困惑与压力,但通过不断查阅资料、与团队成员讨论,最终顺利完成了任务。
在特征融合方面,我深入学习了多模态数据处理的相关知识。为不同类型的数据选择合适的模型进行特征提取,是一个充满挑战的过程。文本、图像和音频数据的特征维度差异巨大,如何在融合过程中保持信息的完整性与表达的准确性,成为我面临的主要难题。通过反复实验与优化,我逐步掌握了多头注意力机制和线性投影等技术,成功实现了高效且精准的特征融合。这一过程不仅提升了我的技术水平,也让我对多模态数据处理有了更深刻的理解。
此外,我还自学了一些基础的推荐算法,并独立构建了混合推荐算法。尽管在算法的设计与实现过程中遇到了诸多难题,但每一次的突破与进步,都让我感受到无比的喜悦与满足。虽然推荐效果的具体评估尚待进一步分析,但这一过程中所积累的经验与知识,已经为我今后的项目开发打下了坚实的基础。
项目的成功离不开团队成员的支持与合作。在此,我要衷心感谢每一位组员。感谢你们在项目中的支持与合作,感谢你们的理解和包容。正是有了你们的共同努力和无私付出,项目才能够顺利推进并最终完成。未来的道路上,我期待与大家继续携手前行,共同创造更多的精彩。
总结这段旅程,我深感自己在技术能力、项目开发以及团队协作等方面都有了显著的成长。尽管过程中充满了艰辛与挑战,但正是这些经历,让我更加坚定了在软件开发领域不断探索与前行的信念。未来,我将继续学习与积累,力求在更多项目中发挥自己的所长,与团队一起创造更大的价值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号