数据采集第三次作业
作业①:使用Scrapy框架爬取中国气象网的所有图片
本次作业的目标是使用Scrapy框架,分别实现单线程和多线程的爬虫,爬取中国气象网(http://www.weather.com.cn)中的所有图片。在爬取过程中,我们需要控制总页数不超过46页,总下载的图片数量不超过146张。爬取到的图片将存储在images子文件夹中,同时在控制台输出下载的图片URL信息。
1.项目结构
首先,我们创建了一个名为 weather_images 的Scrapy项目。项目结构如下:
weather_images/
├── weather_images/
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders/
│ ├── __init__.py
│ ├── single_thread_spider.py
│ └── multi_thread_spider.py
├── images/ # 下载的图片将存储在此文件夹
├── run_spiders.py
├── run_single.py # 可选:单独运行单线程爬虫
├── run_multi.py # 可选:单独运行多线程爬虫
├── scrapy.cfg
2.单线程爬虫
代码实现
以下是单线程爬虫的完整代码。该爬虫通过设置CONCURRENT_REQUESTS为1,确保请求是串行进行的,同时设置DOWNLOAD_DELAY为1秒,控制请求频率。
# weather_images/weather_images/spiders/single_thread_spider.py
import scrapy
from weather_images.items import WeatherImagesItem
from urllib.parse import urljoin
class SingleThreadSpider(scrapy.Spider):
name = 'single_thread_spider'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn']
custom_settings = {
'CONCURRENT_REQUESTS': 1, # 单线程
'DOWNLOAD_DELAY': 1, # 下载延迟1秒
}
def __init__(self, *args, **kwargs):
super(SingleThreadSpider, self).__init__(*args, **kwargs)
self.page_count = 0
self.max_pages = 46 # 最大页数限制
self.image_count = 0
self.max_images = 146 # 最大图片数量限制
def parse(self, response):
self.page_count += 1
self.logger.info(f'Parsing page {self.page_count}: {response.url}')
# 提取所有图片URL
image_urls = response.css('img::attr(src)').getall()
full_image_urls = [urljoin(response.url, img_url) for img_url in image_urls]
# 限制图片数量
if self.image_count + len(full_image_urls) > self.max_images:
full_image_urls = full_image_urls[:self.max_images - self.image_count]
self.image_count += len(full_image_urls)
for img_url in full_image_urls:
self.logger.info(f'Downloading image: {img_url}')
item = WeatherImagesItem()
item['image_urls'] = full_image_urls
yield item
if self.page_count >= self.max_pages or self.image_count >= self.max_images:
self.logger.info('Reached maximum page or image limit.')
return
# 提取下一页URL(假设有分页)
next_page = response.css('a.next::attr(href)').get()
if next_page:
next_page_url = urljoin(response.url, next_page)
yield scrapy.Request(next_page_url, callback=self.parse)
作业心得
在本次作业中,我首先搭建了一个基于Scrapy框架的爬虫项目,目标是爬取中国气象网的所有图片。为了实现单线程爬取,我在爬虫的custom_settings中将CONCURRENT_REQUESTS设置为1,并设置了1秒的下载延迟。这确保了爬虫在爬取过程中每次只发送一个请求,避免对目标网站造成过大的压力。
通过控制page_count和image_count,我成功地限制了爬虫的运行范围,确保总页数不超过46页,总下载的图片数量不超过146张。这种控制机制不仅符合作业要求,也有助于避免因爬取过多数据而导致的资源浪费。
在实现过程中,我深入理解了Scrapy的请求调度和数据管道机制。尤其是在图片下载方面,利用ImagesPipeline自动处理图片的下载和存储,大大简化了代码复杂度。同时,通过在控制台输出下载的图片URL,我能够实时监控爬虫的运行状态,确保爬取过程的透明性和可控性。
总体来说,单线程爬虫的实现过程让我更加熟悉了Scrapy框架的基本用法,以及如何通过配置参数来控制爬虫的行为。这为后续实现更高效的多线程爬虫打下了坚实的基础。
3.多线程爬虫
代码实现
为了提升爬取效率,我进一步实现了一个多线程的爬虫。通过设置CONCURRENT_REQUESTS为32,并将DOWNLOAD_DELAY设置为0.5秒,实现了并发请求的功能,从而加快了爬取速度。
# weather_images/weather_images/spiders/multi_thread_spider.py
import scrapy
from weather_images.items import WeatherImagesItem
from urllib.parse import urljoin
class MultiThreadSpider(scrapy.Spider):
name = 'multi_thread_spider'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn']
custom_settings = {
'CONCURRENT_REQUESTS': 32, # 多线程
'DOWNLOAD_DELAY': 0.5, # 下载延迟0.5秒
}
def __init__(self, *args, **kwargs):
super(MultiThreadSpider, self).__init__(*args, **kwargs)
self.page_count = 0
self.max_pages = 46 # 最大页数限制
self.image_count = 0
self.max_images = 146 # 最大图片数量限制
def parse(self, response):
self.page_count += 1
self.logger.info(f'Parsing page {self.page_count}: {response.url}')
# 提取所有图片URL
image_urls = response.css('img::attr(src)').getall()
full_image_urls = [urljoin(response.url, img_url) for img_url in image_urls]
# 限制图片数量
if self.image_count + len(full_image_urls) > self.max_images:
full_image_urls = full_image_urls[:self.max_images - self.image_count]
self.image_count += len(full_image_urls)
for img_url in full_image_urls:
self.logger.info(f'Downloading image: {img_url}')
item = WeatherImagesItem()
item['image_urls'] = full_image_urls
yield item
if self.page_count >= self.max_pages or self.image_count >= self.max_images:
self.logger.info('Reached maximum page or image limit.')
return
# 提取下一页URL(假设有分页)
next_page = response.css('a.next::attr(href)').get()
if next_page:
next_page_url = urljoin(response.url, next_page)
yield scrapy.Request(next_page_url, callback=self.parse)
作业心得
在实现多线程爬虫的过程中,我主要关注如何通过增加并发请求数来提升爬取效率,同时保持对目标网站的友好性。通过将CONCURRENT_REQUESTS设置为32,并将下载延迟减半至0.5秒,多线程爬虫能够同时处理多个请求,大幅缩短了爬取所需的时间。
尽管多线程爬虫在速度上有显著提升,但也带来了新的挑战。例如,如何确保在高并发下依然能够准确控制爬取的页数和图片数量。为此,我在爬虫的parse方法中,依然保持了对page_count和image_count的严格控制,确保爬虫不会超出预定的范围。
此外,多线程爬虫的实现让我更深入地理解了Scrapy的异步机制和资源管理。通过合理配置并发请求数和下载延迟,我能够在提升爬取效率的同时,避免对目标网站造成过大的压力。这种平衡不仅是高效爬虫设计的关键,也是实际应用中需要重点考虑的问题。
最终,多线程爬虫在更短的时间内成功下载了图片,且所有图片均正确存储在images文件夹中。控制台实时输出的图片URL信息也验证了爬虫的稳定性和可靠性。
运行脚本
为了方便地在PyCharm中运行爬虫,我编写了一个运行脚本run_spiders.py,允许用户选择运行单线程或多线程爬虫。以下是该脚本的完整代码:
# run_spiders.py
import sys
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from weather_images.spiders.single_thread_spider import SingleThreadSpider
from weather_images.spiders.multi_thread_spider import MultiThreadSpider
def main():
print("请选择要运行的爬虫类型:")
print("1. 单线程爬虫 (single_thread_spider)")
print("2. 多线程爬虫 (multi_thread_spider)")
choice = input("请输入选项 (1 或 2): ")
settings = get_project_settings()
process = CrawlerProcess(settings)
if choice == '1':
print("启动单线程爬虫:single_thread_spider")
process.crawl(SingleThreadSpider)
elif choice == '2':
print("启动多线程爬虫:multi_thread_spider")
process.crawl(MultiThreadSpider)
else:
print("无效的选项。请运行脚本并输入 1 或 2。")
sys.exit(1)
process.start()
if __name__ == '__main__':
main()
4.相关配置文件
1. items.py
# weather_images/weather_images/items.py
import scrapy
class WeatherImagesItem(scrapy.Item):
image_urls = scrapy.Field()
images = scrapy.Field()
2. pipelines.py
# weather_images/weather_images/pipelines.py
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
class CustomImagesPipeline(ImagesPipeline):
def __init__(self, store_uri, download_func=None, settings=None):
super().__init__(store_uri, download_func, settings)
self.image_count = 0
self.max_images = 146 # 最大下载图片数量
@classmethod
def from_crawler(cls, crawler):
return cls(
store_uri=crawler.settings.get('IMAGES_STORE'),
settings=crawler.settings
)
def get_media_requests(self, item, info):
if self.image_count >= self.max_images:
return
for image_url in item.get('image_urls', []):
if self.image_count >= self.max_images:
break
self.image_count += 1
self.logger.info(f'Downloading image: {image_url}') # 在控制台输出图片 URL
yield Request(image_url)
def item_completed(self, results, item, info):
return item
3. settings.py
# weather_images/weather_images/settings.py
BOT_NAME = 'weather_images'
SPIDER_MODULES = ['weather_images.spiders']
NEWSPIDER_MODULE = 'weather_images.spiders'
# 禁止遵循 robots.txt
ROBOTSTXT_OBEY = False
# 默认并发请求数
CONCURRENT_REQUESTS = 16 # 可在爬虫中覆盖
# 默认下载延迟
DOWNLOAD_DELAY = 1 # 可在爬虫中覆盖
# 启用图片管道
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
'weather_images.pipelines.CustomImagesPipeline': 300,
}
# 图片存储路径
IMAGES_STORE = 'images'
# 图片最小高度和宽度
IMAGES_MIN_HEIGHT = 0
IMAGES_MIN_WIDTH = 0
# 日志级别
LOG_LEVEL = 'INFO'
# 用户代理(可选)
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' \
'AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/58.0.3029.110 Safari/537.3'
5.运行过程与截图
1. 运行单线程爬虫
在PyCharm中运行run_spiders.py,选择1启动单线程爬虫。

图1:单线程爬虫运行截图
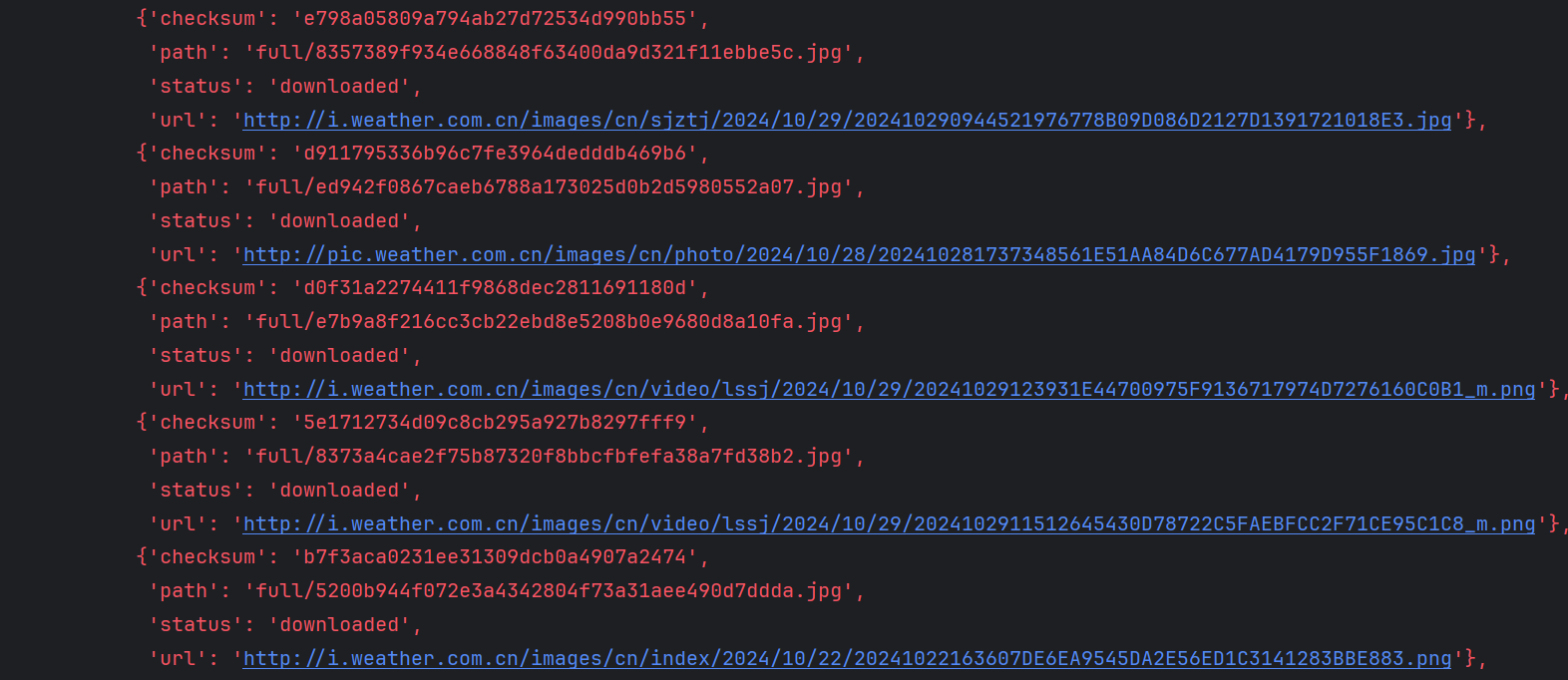
图2:url信息输出截图
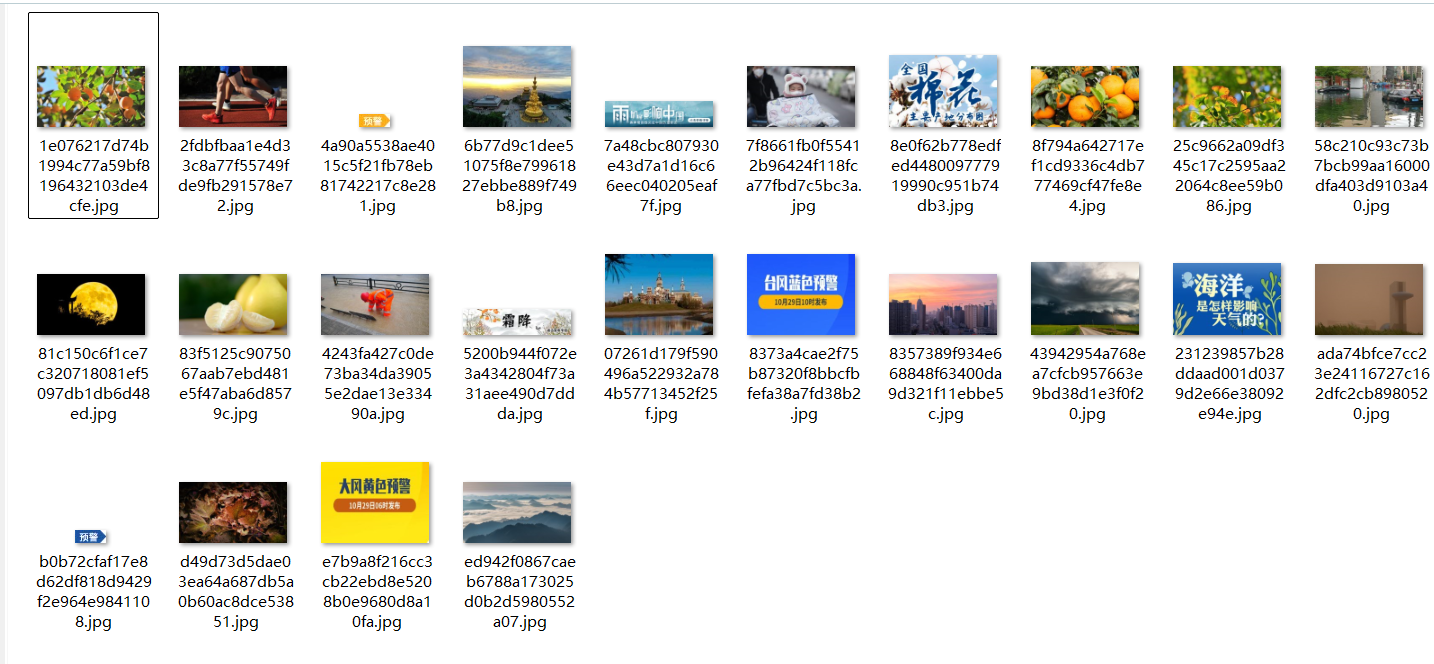
图3:下载图片截图
2. 运行多线程爬虫
在PyCharm中运行run_spiders.py,选择2启动多线程爬虫。

图4:多线程爬虫运行截图
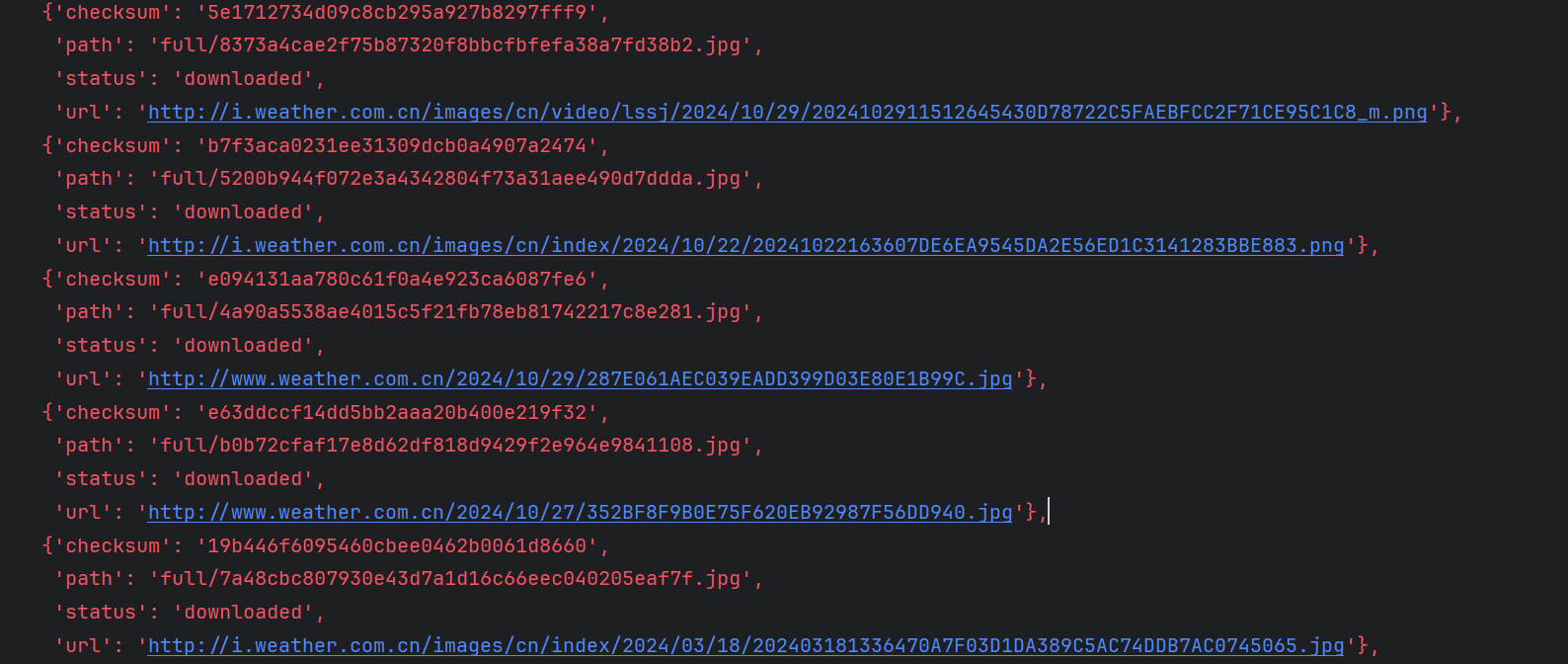
图5:url信息输出截图
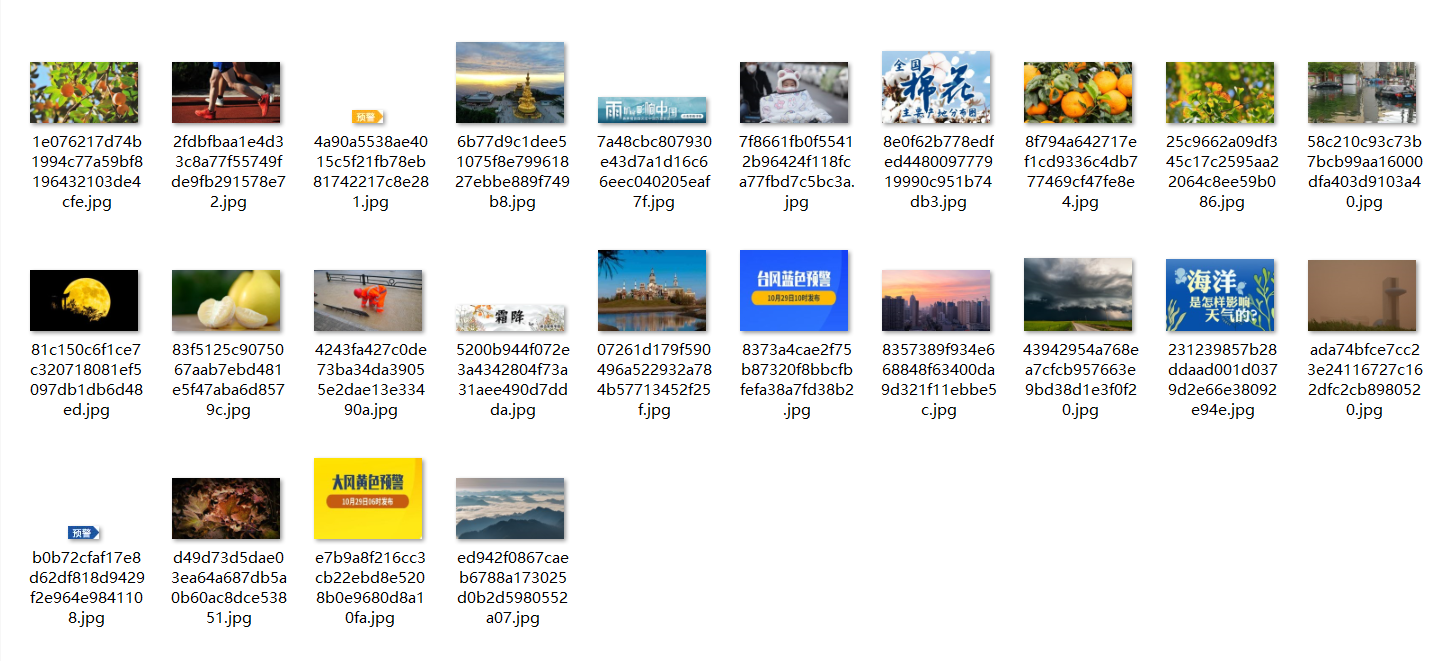
图6:下载图片截图
6.Gitee文件夹链接
https://gitee.com/lan-minlong/crawl_project_2024/tree/master/作业3/1/weather_images
7.总结
通过本次作业,我深入学习和实践了Scrapy框架在单线程和多线程爬虫中的应用。以下是本次作业的一些关键收获:
-
Scrapy框架的灵活性:Scrapy提供了强大的配置选项,通过调整
CONCURRENT_REQUESTS和DOWNLOAD_DELAY,可以轻松实现单线程和多线程的爬虫,满足不同的爬取需求。 -
资源控制的重要性:在爬取过程中,合理控制爬取的页数和图片数量,不仅能够节省资源,还能避免对目标网站造成过大的压力。这对于遵守网络伦理和法律法规尤为重要。
-
异步编程的理解:通过多线程爬虫的实现,我更好地理解了异步编程和并发请求的原理,这对于处理大规模数据爬取任务具有重要意义。
-
调试和监控的技巧:在爬虫运行过程中,通过控制台日志输出,可以实时监控爬虫的运行状态,快速定位和解决潜在问题。
-
数据管道的应用:利用
ImagesPipeline自动处理图片的下载和存储,大大简化了代码复杂度,同时确保了下载过程的高效和稳定。
总的来说,本次作业不仅巩固了我对Scrapy框架的理解和应用能力,也提升了我在实际项目中设计和优化爬虫的综合能力。未来,我将继续深入学习更多高级功能,提升爬虫的效率和稳定性,以应对更加复杂和多样化的数据采集任务。
作业②:使用Scrapy框架爬取东方财富网股票信息并存储到MySQL数据库
在本次任务中,我们将通过使用Scrapy框架结合Selenium自动化获取动态加载的网页内容,爬取东方财富网(https://www.eastmoney.com/)的股票数据。爬取的数据包括股票代码、股票名称、最新报价、涨跌幅、涨跌额、成交量、振幅、最高价、最低价、今开、昨收等信息。最终,我们将数据存储到MySQL数据库,并确保数据输出格式符合要求。
一、实验目标
- 熟练掌握Scrapy框架中的
Item、Pipeline及数据序列化输出方法。 - 使用Scrapy框架和Xpath提取网页中的动态股票信息。
- 将爬取的数据存储到MySQL数据库中,并根据要求输出。
二、实验步骤
1. 创建Scrapy项目
首先,创建一个Scrapy项目来管理我们的爬虫:
scrapy startproject stock_spider
2. 配置爬虫
在stock_spider/spiders/目录下创建一个新的爬虫 stock_selenium_spider.py,代码如下:
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from stock_spider.items import StockSpiderItem
from scrapy.selector import Selector
import time
import re
class StockSeleniumSpider(scrapy.Spider):
name = 'stock_selenium_spider'
allowed_domains = ['eastmoney.com']
start_urls = ['https://quote.eastmoney.com/center/gridlist.html#hs_a_board']
def __init__(self, *args, **kwargs):
super(StockSeleniumSpider, self).__init__(*args, **kwargs)
# 设置Selenium的WebDriver
chrome_options = Options()
chrome_options.add_argument('--headless') # 无头模式
self.driver = webdriver.Chrome(options=chrome_options)
def parse(self, response):
# 使用Selenium获取动态加载的页面内容
self.driver.get(response.url)
time.sleep(3) # 等待页面完全加载
# 获取页面的HTML内容
page_source = self.driver.page_source
selector = Selector(text=page_source)
# 提取股票信息
rows = selector.xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr')
for row in rows:
item = StockSpiderItem()
# 股票代码
item['bStockNo'] = row.xpath('./td[2]/a/text()').get()
# 股票名称
item['bStockName'] = row.xpath('./td[3]/a/text()').get()
# 最新报价
item['newPrice'] = row.xpath('./td[5]/span/text()').get()
# 涨跌幅
item['priceChange'] = row.xpath('./td[6]/span/text()').get()
# 涨跌额
item['priceChangeAmount'] = row.xpath('./td[7]/span/text()').get()
# 成交量
item['volume'] = row.xpath('./td[8]/text()').get()
# 振幅
item['amplitude'] = self.parse_number(row.xpath('./td[10]/text()').get())
# 最高
item['highPrice'] = self.parse_number(row.xpath('./td[11]/span/text()').get())
# 最低
item['lowPrice'] = self.parse_number(row.xpath('./td[12]/span/text()').get())
# 今开
item['todayOpen'] = self.parse_number(row.xpath('./td[13]/span/text()').get())
# 昨收
item['yesterdayClose'] = self.parse_number(row.xpath('./td[14]/text()').get())
yield item
def parse_number(self, value):
""" 处理带单位的数值(如:19.30万 -> 193000, 2.5亿 -> 250000000)"""
if value is None:
return None
value = value.strip()
# 去掉非数字字符(保留数字、点、负号)
value = re.sub(r'[^\d.-]', '', value)
# 如果原值包含 '万',则乘以 10,000
if '万' in value:
value = float(value.replace('万', '')) * 10000
# 如果原值包含 '亿',则乘以 100,000,000
elif '亿' in value:
value = float(value.replace('亿', '')) * 100000000
else:
value = float(value)
return value
def closed(self, reason):
# 关闭WebDriver
self.driver.quit()
3. 定义Item
我们在items.py中定义了股票数据的字段:
import scrapy
class StockSpiderItem(scrapy.Item):
bStockNo = scrapy.Field() # 股票代码
bStockName = scrapy.Field() # 股票名称
newPrice = scrapy.Field() # 最新报价
priceChange = scrapy.Field() # 涨跌幅
priceChangeAmount = scrapy.Field() # 涨跌额
volume = scrapy.Field() # 成交量
amplitude = scrapy.Field() # 振幅
highPrice = scrapy.Field() # 最高
lowPrice = scrapy.Field() # 最低
todayOpen = scrapy.Field() # 今开
yesterdayClose = scrapy.Field() # 昨收
4. 配置MySQL Pipeline
在pipelines.py中定义MySQL数据存储的逻辑:
import mysql.connector
class MySQLPipeline:
def open_spider(self, spider):
# 连接MySQL数据库
self.conn = mysql.connector.connect(
host='localhost',
user='root', # 你的数据库用户名
password='llmmll', # 你的数据库密码
database='stock_info' # 数据库名称
)
self.cursor = self.conn.cursor()
self.create_table()
def close_spider(self, spider):
# 关闭数据库连接
self.cursor.close()
self.conn.close()
def create_table(self):
# 创建股票信息表
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stock_data (
id INT AUTO_INCREMENT PRIMARY KEY,
bStockNo VARCHAR(10),
bStockName VARCHAR(50),
newPrice FLOAT,
priceChange VARCHAR(10),
priceChangeAmount VARCHAR(20),
volume VARCHAR(20),
amplitude FLOAT,
highPrice FLOAT,
lowPrice FLOAT,
todayOpen FLOAT,
yesterdayClose FLOAT
)
''')
self.conn.commit()
def process_item(self, item, spider):
# 插入数据到表
self.cursor.execute('''
INSERT INTO stock_data (bStockNo, bStockName, newPrice, priceChange, priceChangeAmount,
volume, amplitude, highPrice, lowPrice, todayOpen, yesterdayClose)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
''', (
item['bStockNo'],
item['bStockName'],
item['newPrice'],
item['priceChange'],
item['priceChangeAmount'],
item['volume'],
item['amplitude'],
item['highPrice'],
item['lowPrice'],
item['todayOpen'],
item['yesterdayClose']
))
self.conn.commit()
return item
5. 设置数据库和爬虫配置
在settings.py中启用MySQL存储和设置爬虫相关配置:
# Enable MySQL Pipeline
ITEM_PIPELINES = {
'stock_spider.pipelines.MySQLPipeline': 1,
}
# MySQL数据库配置
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'stock_info'
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'llmmll'
6. 运行爬虫
在命令行中执行以下命令运行爬虫:
scrapy crawl stock_selenium_spider
三、数据存储与展示
爬取的数据将存储在名为stock_data的MySQL数据库表中,表结构如下(取前十条):
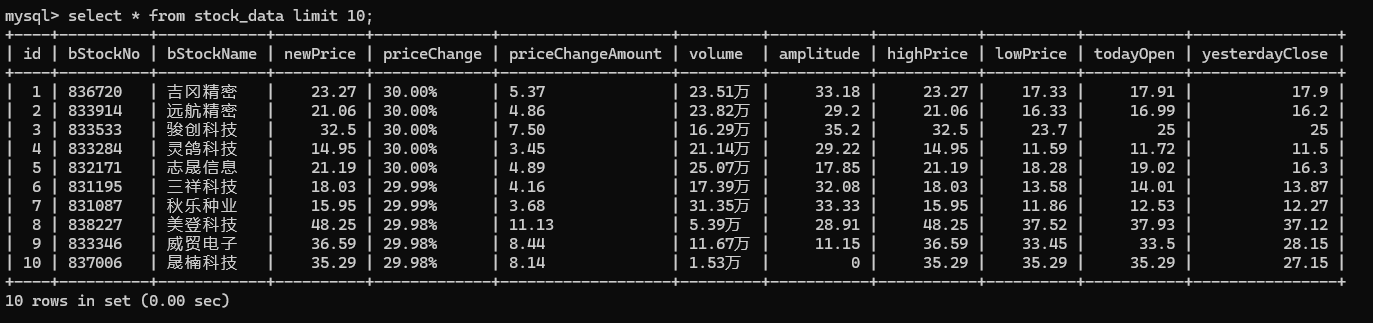
图7:数据库结构截图
四、Gitee文件夹链接
https://gitee.com/lan-minlong/crawl_project_2024/tree/master/作业3/2/stock_spider
五、总结
在这一过程中,我遇到了一些挑战:
①动态加载的页面数据:东方财富网的股票列表是通过 JavaScript 动态加载的,Scrapy 的默认请求并不能抓取到动态加载的内容,解决方案是通过 Selenium 获取页面源代码。
②数据的提取与处理:对于页面中的数值数据(如“成交量”或“振幅”),需要进行单位的转换,如万转化为 10,000 亿转化为 100,000,000。
③数据存储:将抓取到的数据存储到 MySQL 数据库,并确保数据的插入过程无误。
本次实践中将Selenium 与 Scrapy 的结合,Scrapy 非常适合处理静态网页的抓取,但对于动态加载的页面,Selenium 提供了一种有效的解决方案。虽然这会增加抓取过程的时间,但对于动态内容,Selenium 无疑是一个很好的工具。
存储数据到 MySQL 中的操作非常重要,尤其是在处理大规模数据时,确保数据能够正确存入数据库并且易于查询是非常关键的。本次实验,通过Scrapy的管道机制实现了自动化存储,方便爬虫程序的编写。
实验③:外汇网站数据爬取与存储
一、实验目的
本次实验的主要目的是通过使用Scrapy框架和MySQL数据库,爬取中国银行外汇数据,并将数据存储到MySQL数据库中。通过该实验,熟练掌握Scrapy中Item、Pipeline的数据序列化输出方法,学习如何使用Xpath提取网页内容并进行数据存储。
二、实验步骤
1. exchange_spider.py
在exchange_spider.py文件中,我们定义了一个名为ExchangeSpider的爬虫,爬虫会访问中国银行外汇页面并解析页面数据。
import scrapy
from foreign_exchange.items import ForeignExchangeItem
class ExchangeSpider(scrapy.Spider):
name = 'exchange_spider'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
# 获取表格
rows = response.xpath('//div[2]/table[@align="left"]//tr')
# 如果有数据,继续处理每一行
for row in rows[1:]:
item = ForeignExchangeItem()
# 提取每一行中的相关数据
item['currency'] = row.xpath('./td[1]/text()').extract_first()
item['tbp'] = row.xpath('./td[2]/text()').extract_first()
item['cbp'] = row.xpath('./td[3]/text()').extract_first()
item['tsp'] = row.xpath('./td[4]/text()').extract_first()
item['csp'] = row.xpath('./td[5]/text()').extract_first()
item['time'] = row.xpath('./td[6]/text()').extract_first()
yield item
代码说明:
start_urls:指定爬虫的起始URL。parse方法:使用Xpath选择器抓取表格数据,并提取每行的相关字段(币种、现汇买入价、现钞买入价、现汇卖出价、现钞卖出价、更新时间)。ForeignExchangeItem:我们在items.py中定义的Item类,用于存储爬取到的数据。
2. items.py
在items.py中,我们定义了ForeignExchangeItem类,用于保存外汇信息。
import scrapy
class ForeignExchangeItem(scrapy.Item):
currency = scrapy.Field() # Currency
tbp = scrapy.Field() # TBP
cbp = scrapy.Field() # CBP
tsp = scrapy.Field() # TSP
csp = scrapy.Field() # CSP
time = scrapy.Field() # Time
每个字段对应页面表格中的一列,scrapy.Field()用于定义每个字段。
3. pipelines.py
在pipelines.py文件中,我们实现了MySQL数据存储的逻辑。主要包括在爬虫启动时连接MySQL数据库、创建表格以及在爬虫关闭时关闭数据库连接。
import mysql.connector
from mysql.connector import Error
class MySQLPipeline:
def open_spider(self, spider):
# 在爬虫启动时连接到 MySQL 数据库
try:
self.conn = mysql.connector.connect(
host='localhost',
database='foreign_exchange_db',
user='root',
password='llmmll'
)
if self.conn.is_connected():
self.cursor = self.conn.cursor()
self.create_table()
print('MySQL Database connected.')
except Error as e:
print(f"Error: {e}")
raise
def close_spider(self, spider):
# 爬虫关闭时关闭连接
if self.conn.is_connected():
self.cursor.close()
self.conn.close()
print('MySQL Database connection closed.')
def create_table(self):
# 创建存储数据的表(如果不存在)
create_table_query = """
CREATE TABLE IF NOT EXISTS exchange_data (
id INT AUTO_INCREMENT PRIMARY KEY,
currency VARCHAR(20),
tbp DECIMAL(10, 2),
cbp DECIMAL(10, 2),
tsp DECIMAL(10, 2),
csp DECIMAL(10, 2),
time VARCHAR(20)
)
"""
self.cursor.execute(create_table_query)
def process_item(self, item, spider):
# 将抓取到的数据存入数据库
insert_query = """
INSERT INTO exchange_data (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(insert_query, (
item['currency'],
item['tbp'],
item['cbp'],
item['tsp'],
item['csp'],
item['time']
))
self.conn.commit()
return item
代码说明:
open_spider:在爬虫启动时连接到MySQL数据库,并创建exchange_data表(如果不存在)。process_item:将爬取的数据插入到数据库表中。close_spider:在爬虫关闭时关闭数据库连接。
4. settings.py
在settings.py中,我们启用了MySQL Pipeline来处理数据存储。
ITEM_PIPELINES = {
'foreign_exchange.pipelines.MySQLPipeline': 1,
}
5. 运行爬虫
在命令行中执行以下命令运行爬虫:
scrapy crawl exchange_spider
三、数据库结构以及结果展示
数据将存储在MySQL数据库foreign_exchange_db中的exchange_data表内,结果展示如下:
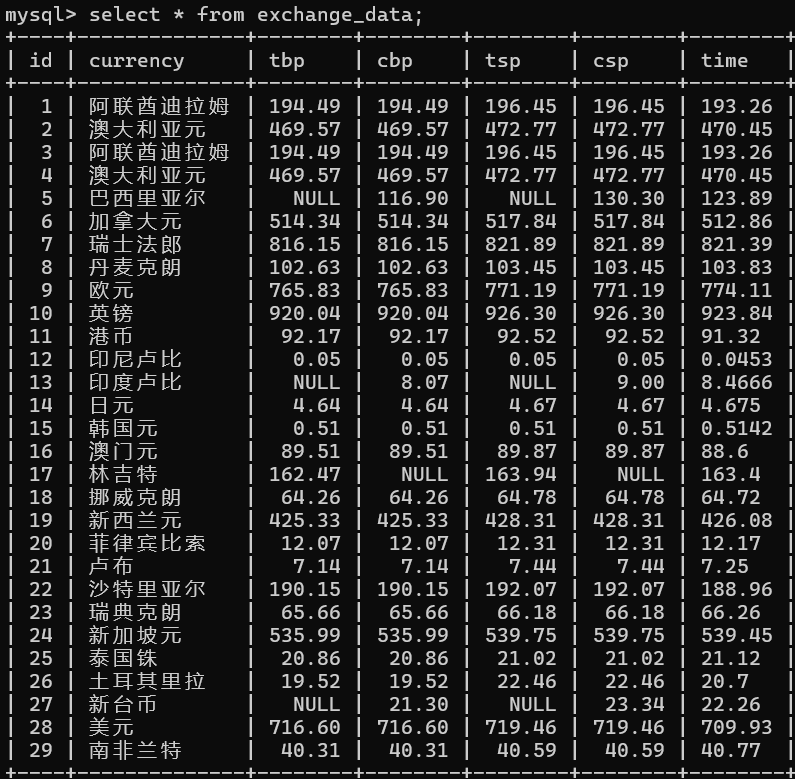
图8:数据库结构截图
四、Gitee文件夹链接
https://gitee.com/lan-minlong/crawl_project_2024/tree/master/作业3/3/foreign_exchange
五、实验总结
通过本次实验,我对使用Scrapy框架爬取网页数据并将其存储到MySQL数据库的过程有了更加深入的理解。整个流程涵盖了爬虫的设计、数据提取、序列化以及与数据库的交互,使我能够更好地掌握数据抓取与存储的技巧,并深入理解了Scrapy框架中的核心概念,如Item、Pipeline和Xpath选择器的使用。
在实践过程中,Scrapy的灵活性和扩展性给了我很大的帮助。尤其是在处理网页中的表格数据时,Xpath选择器提供了一种高效且直观的方式来提取所需的信息。通过合理设计爬虫中的parse方法,我可以精确地从复杂的HTML结构中获取到每一行的外汇信息。这一过程不仅考验了我对HTML和Xpath语法的理解,也让我对如何处理网页中的重复数据和格式不规范的数据有了更深的认识。
总的来说,这次实验不仅提升了我对Scrapy框架的理解和应用能力,也让我更深入地了解了如何将数据抓取与数据库存储结合起来,为后续的爬虫开发和数据分析工作打下了坚实的基础。通过实际的编码实践,我进一步认识到编写高效、稳定的爬虫需要仔细的调试与优化,同时也要具备一定的系统思维,以便在复杂的场景中灵活应对各种技术挑战。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号