HashMap详解
HashMap源码解析(以jdk1.8为例)

简介
HashMap是一个哈希表,它是 非线程安全的,且允许key和value为null.
HashMap采用 数组 + 链表 + 红黑树 的形式来存储数据.不保证插入顺序
put方法
- 判断table是否为空,如果为空或者大小为0,则调用resize()对table进行初始化
- 将key的hash运算后的值 与 数组长度-1 做一次 相与即hash(key) & (table.length-1),得到指定下标。取余的方法采用hash(key) & (table.length-1),等价于hash(key)%table.length.原因是HashMap要求数组的长度必须为2的指数,因此table-1的二进制低位全部为1,hash(key) & (table.length-1)相当于抹除其高位,剩下的就是余数。
- 如果table指定下标位置上为空,则新建一个链表,将键值对作为节点插入
- 否则依次遍历下标指向的链表上的每一个节点,通过key.equals()来判断是否是要找的那个entry。
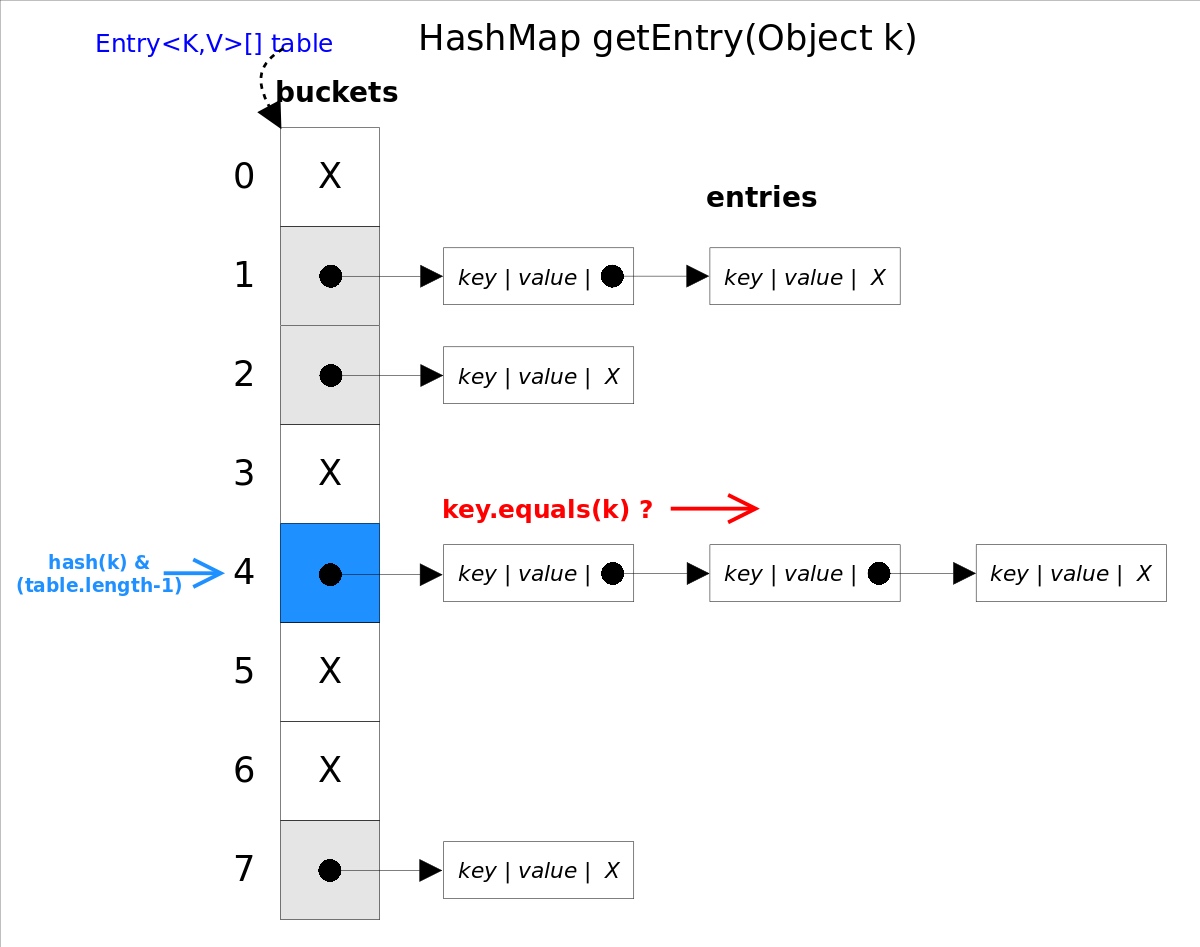
- 如果当前链表上没有相同的key,则采用尾插法向链表尾部插入数据。如果当链表插入完成后,链表存储的节点的个数>=8时,会调用treeifyBin方法,将链表转换成红黑树.(之所以选择8是根据概率得出的,注释里有说明),当节点删除完,红黑树大小<=6时,会退化成链表
如果有相同的Key,则覆盖
/** *
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
**/
初始化 && 扩容
HashMap在初始化的时候,如果没有指定 加载因子和容量, 会调用默认的构造函数,将加载因子设为 0.75,容量设为16。
扩容的时机
当HashMap中的元素个数超过 容量*加载因子时,HashMap会发生扩容。即++size > load factor * capacity ,这个过程发生在放入键值对之后。
每次扩容都会将当前的容量扩大2倍。为什么容量一定要2n 其实是因为取余方便。
扩容的具体过程
- 判断数组容量是否大于0
- 等于0则进行初始化
- 如果加载因子和容量都为0,则调用默认的大小和阈值
- 如果有设置加载因子和容量,则使用构造函数中的初始化的容量
- 大于0,则进行扩容,扩容后的容量大小为原来的两倍,之后将元素重新进行运算并复制到新的table当中。
1.7 和 1.8 jdk中HashMap的对比
插入方法上: 1.7采用头插法,1.8采用尾插法。
1.7中hashMap的实现是采用数组+链表的形式,采用头插法容易出现逆序,且在并发情况下会产生环形链表死循环问题
1.8后HashMap则采用数组+链表+红黑树的形式,当链表长度超过8时,则会将链表转成红黑树。且采用尾插法避免了并发情况下发生的死循环问题。但是仍不建议在并发情况下使用HashMap,而是使用ConcurrentHashMap
链表死循环问题
HashMap之所以在并发下的扩容造成死循环,是因为,多个线程并发进行时,因为一个线程先期完成了扩容,将原的链表重新散列到自己的表中,并且链表变成了倒序,后一个线程再扩容时,又进行自己的散列,再次将倒序链表变为正序链表。于是形成了一个环形链表
jdk 1.7中,当扩容完成后,会把数据从老的hash表中迁移到新的hash表中,高并发下,同时有两个或以上线程执行这段代码,会发生链表死循环。具体流程如下:
旧表因容量为2太小发生扩容,新建一个新的哈希表,大小为4
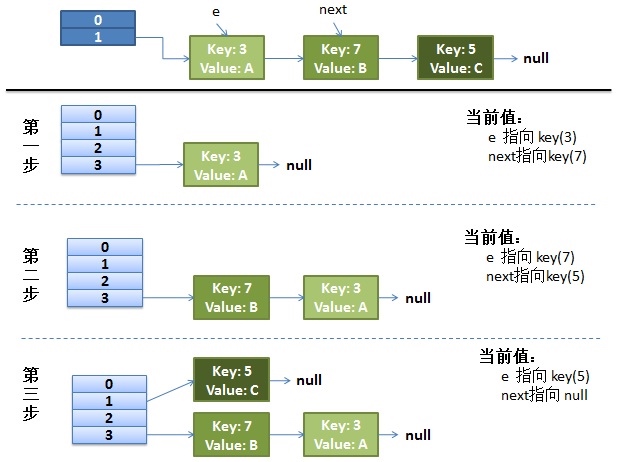
扩容并重新分配 旧表数据向新表逐个迁移
线程1卡在获取旧哈希表的链表上.此时线程1的e指向键值对3,next指向键值对7
而线程2已经完成了整个的数据再分配
- 将3分配到下标3
- 将5分配到下标1
- 将7分配到下标3
线程1回来继续执行
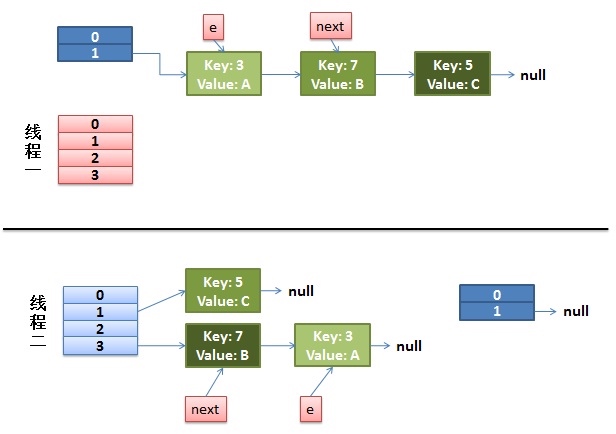
- 将节点3的next指针指向原下标3的链表,新数组下标3为null,所以和之前一样 e.next = newTable[i];
- 并将下标3指向节点3 newTable[i] = e;到此头插法完成
- 将e指向节点7 e = next; 而新一轮循环中,Entry
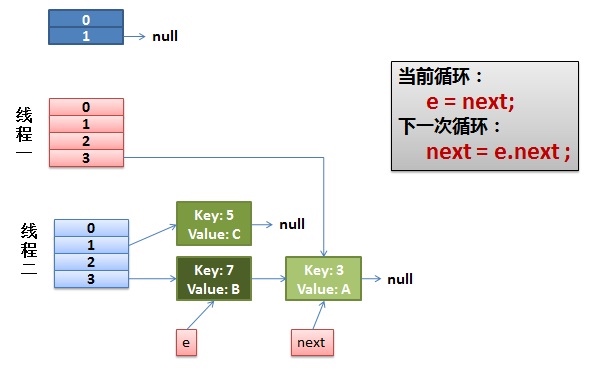
- 线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。又因为e = next,节点3再次被选为e,而next为null
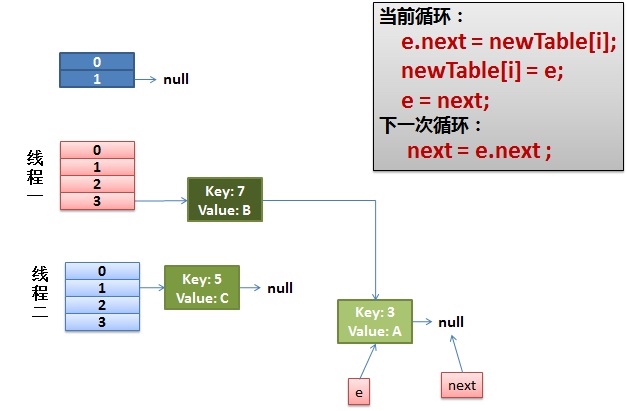
- 下一次循环中,将e插入到链表头部,接着e.next = newTable[i],节点3的next指针指向7,环形链表出现。可以发现是头插法导致了key(3).next 指向了 key(7)
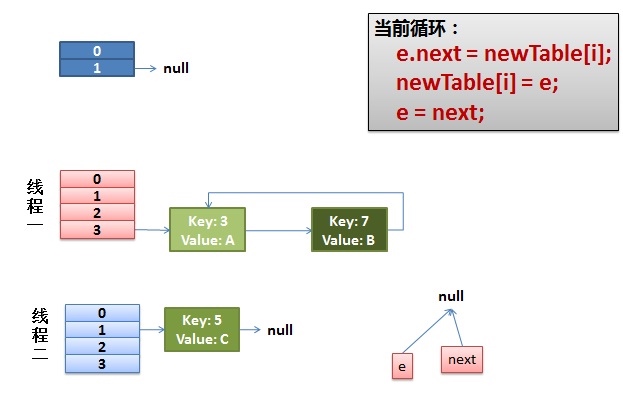
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;// <--假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
HashMap使用自定义类作为key
在HashMap中,查找key的比较顺序为:
- 计算对象的HashCode,看在表中下标是否存在链表。
- 检查对应链表中的对象和当前对象是否相等。
在自定义的对象没有重载hashCode方法和equals方法时,会默认调用Object类的这两个方法。
而在Object中,Hash Code的计算方法是根据对象的地址进行计算的
因此只要是不同的对象,即使他的内容相同,HashMap也不会把它们当成是同一个key了
同时,在Object默认的equals()中,也是根据对象的地址进行比较,
自然一不同对象的地址值是不相等的。
且 HashMap的Node数据结构中hash和key都是final类型的。
HashMap为什么要每次扩容都是2倍
向HashMap中添加元素putVal()中,会通过对元素的hash值进行 (n-1)&hash 的计算方式得出该元素在数组中的下标位置。
由于hashMap的长度是2n ,带来的好处是n-1后,得到的数字的二进制形式为01111……111,这样与hash相与得到值,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞。
