(5)pyspark----共享变量
如果想在节点之间共享一份变量,spark提供了两种特定的共享变量,来完成节点之间的变量共享。
(1)广播变量(2)累加器
二、广播变量
概念:
广播变量允许程序员缓存一个只读的变量在每台机器上,而不是每个任务保存一个拷贝。例如,利用广播变量,我们能够以一种更有效率的方式将一个大数据量输入集合的副本分配给每个节点。
一个广播变量可以通过调用SparkContext.broadcast(v)方法从一个初始变量v中创建。广播变量是v的一个包装变量,它的值可以通过value方法访问。
用途:比如一个配置文件,可以共享给所有节点。比如一个Node的计算结果需要共享给其他节点。
声明:broadcast
调用broadcast,Scala中一切可序列化的对象都可以进行广播。
sc.broadcast(xxx)
引用广播变量数据:value
可在各个计算节点中通过 bc.value来引用广播的数据。

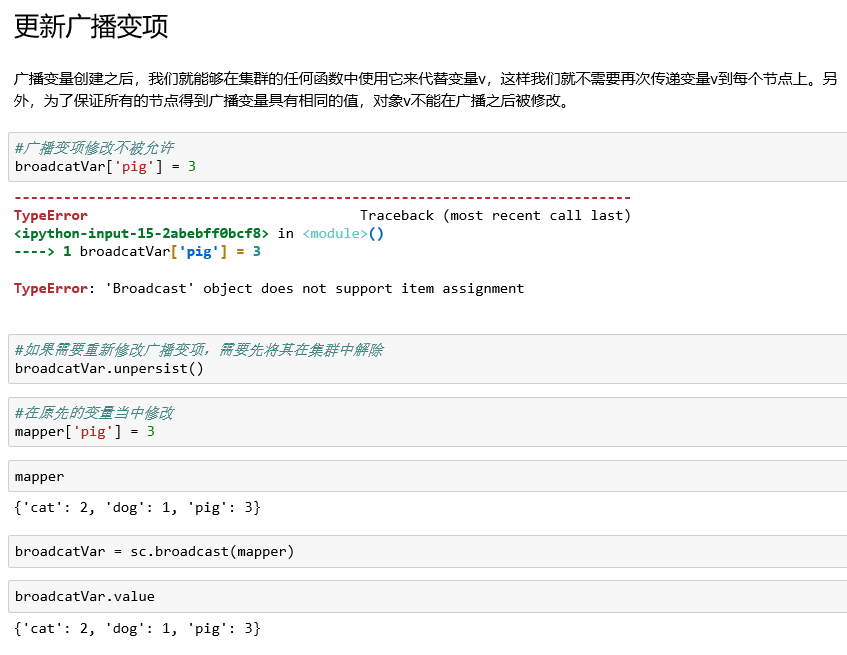
更新广播变量:unpersist
由于广播变量是只读的,即广播出去的变量没法再修改,
利用unpersist函数将老的广播变量删除,然后重新广播一遍新的广播变量。
bc.unpersist()
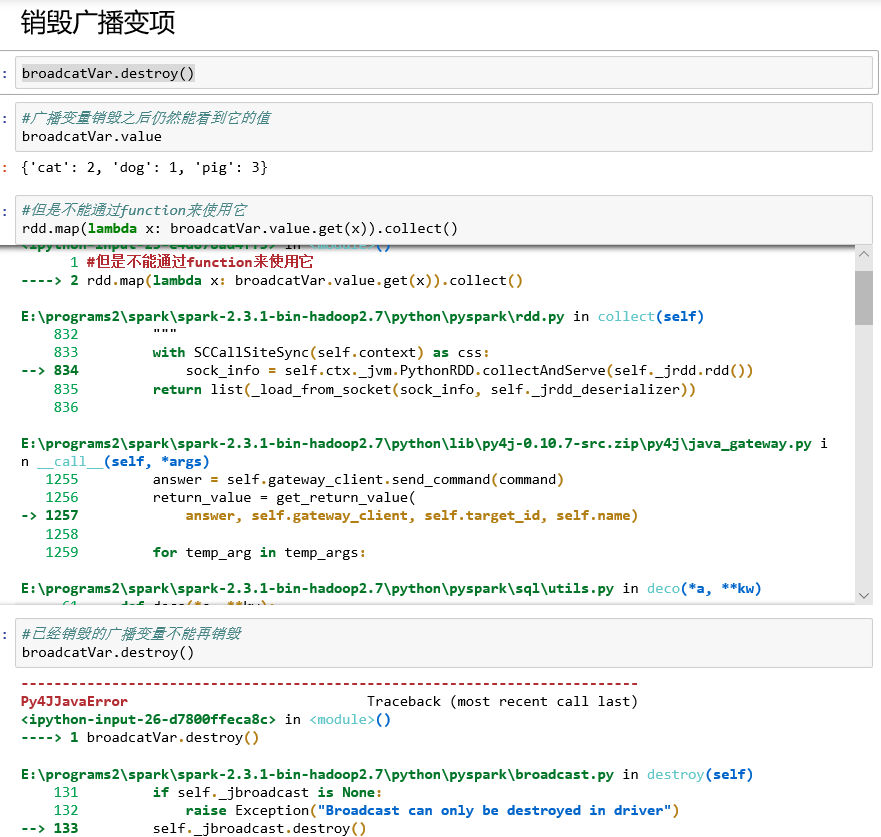
销毁广播变量:destroy
bc.destroy()可将广播变量的数据和元数据一同销毁,销毁之后就不能再使用了。
三、累加器
概念:
累加器是一种只能利用关联操作做“加”操作的变数,因此他能够快速执行并行操作。而且其能够操作counters和sums。Spark原本支援数值类型的累加器,程序员可以自行增加可被支援的类型。如果建立一个具体的累加器,其可在spark UI上显示。
用途:
对信息进行聚合,累加器的一个常见的用途是在调试时对作业的执行过程中事件进行计数。
创建累加器:accumulator
调用SparkContext.accumulator(v)方法从一个初始变量v中创建。
运行在集群上的任务可以通过add方法或者使用+=操作来给它加值。然而,它们无法读取这个值。和广播变量相反,累加器是一种add only的变项。
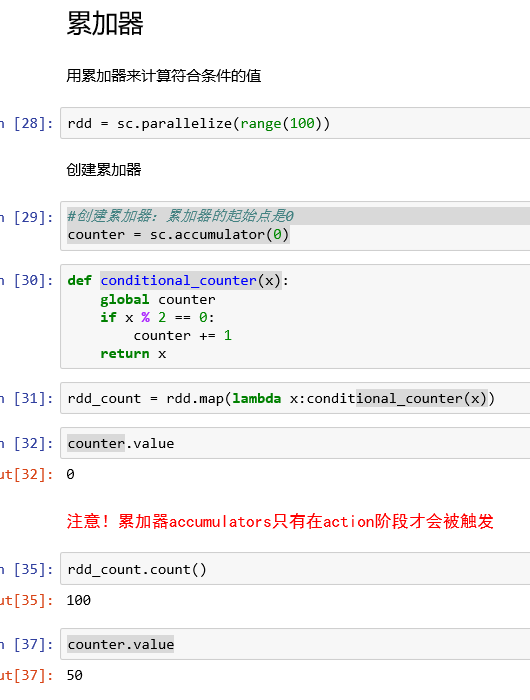
累加器的陷阱
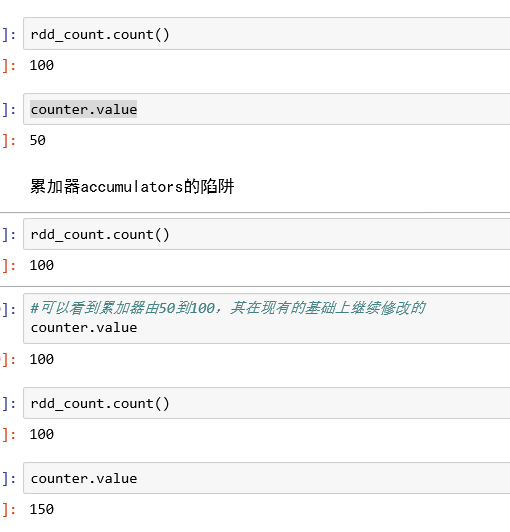
打破累加器陷阱:persist函数

存累加器初始值:

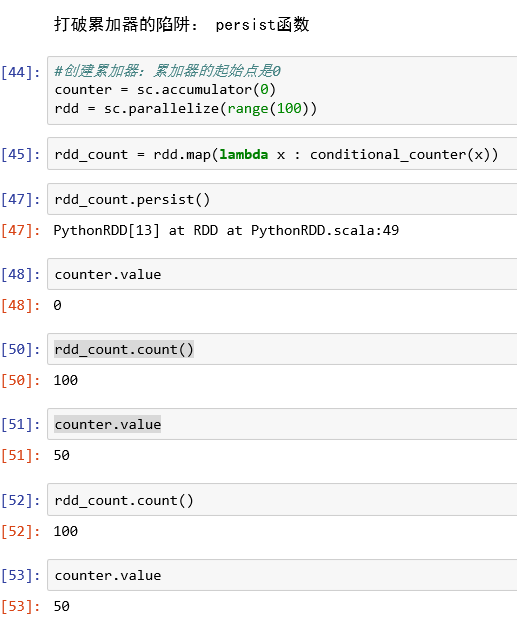
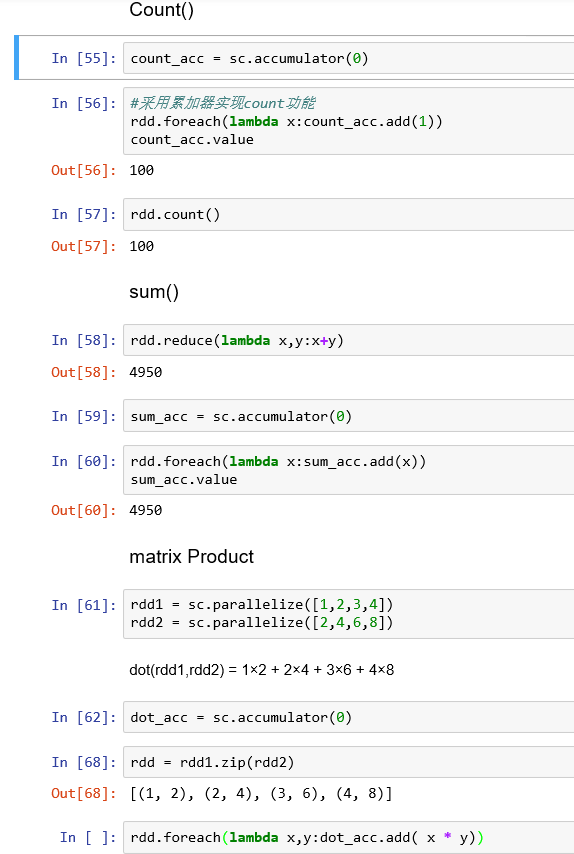
累加器实现一些基本的功能: