7、A Design of Group Recommendation Mechanism Considering Opportunity Cost and Personal Activity Using Spark Framework---使用Spark框架的基于机会成本以及个人活动群组推荐机制
来源EDB2018---EDB
一、摘要:
组推荐是将一种项目(例如产品、服务)推荐给由多个成员组成的组的方法。
最小痛苦法(least Misery)是一种具有代表性的群体推荐方法,其能够推荐考虑群体不满意的项目,但存在推荐准确率低的缺点。
均值法推荐精度较高,但是不能考虑群体的不满意项目。
本文提出一种基于机会成本和个人活动的群组推荐方法,【机会成本,当选择特定项目时所丢弃的剩余项目的最大值】,其优点:考虑了准确度以及满意度。
二、介绍:
协同过滤是一种传统的推荐算法,可以给用户推荐新的项目。
推荐方法主要分为两类:(1)个人推荐(2)组推荐
群组推荐旨在……,但是代表性的群组推荐方法包括最小痛苦、最大快乐、均值等。其中,最小痛苦方法会推荐群组不满意的项目,但存在推荐准确率低的缺点。
本文考虑群组的不满意程度,考虑机会成本和个人活动,提出一种提高准确度的群体推荐方法。
三、相关研究:
1、推荐过程:
群组推荐过程分为三个阶段:群组搜索、群组建模和群组评分预测。
- 组搜索【理解成群组发现】:考虑推荐项目的形成群组,通常将具有相似偏好的用户分到同一组。
- 群组建模:融合组中各个成员的偏好形成群组偏好。
- 群组评分预测:生成群组队每一个项目的预测评分,然后根据预测的评分对群组进行推荐。
2、机会成本和个人活动:
机会成本指用户放弃任何项目的最高价值。利用机会成本意味着当有几种备选方案可供选择时作出合理的决策。
在【6】中,在确定旅行地点的情况下,他们通过根据成员的角色改变权重来将权重应用于偏好计算,但是很难计算成员在组中的角色。
在【7】中,提出了一种通过每个成员之间的社会联系来设置不同的权重,但是在一些情况下,不能讲友谊看成相对关系。
3、协同过滤CF:
协同过滤是对目标用户推荐与其具有相似偏好的用户喜欢的项目,用户之间的相似度度量是通过用户过去购买项目的偏好项目信息来度量的。
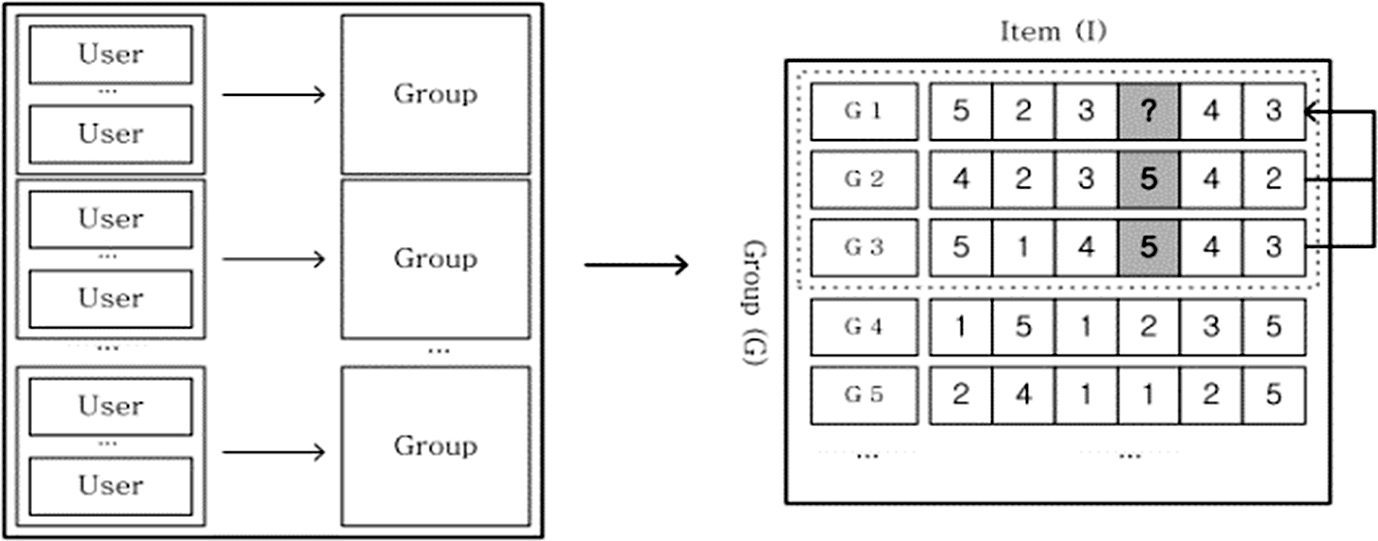
上图显示了通过CF进行群组推荐的示例,组和组之间的相似度可以通过融合的组偏好来计算。上图中,组1对项目4的偏好可以通过组1和组2、组3的相似度来计算。
4、矩阵分解MF和交替最小二乘法
MF是一种挖掘用户-项目之间隐性关系的预测评分的方法,其具有高准确度。【8】
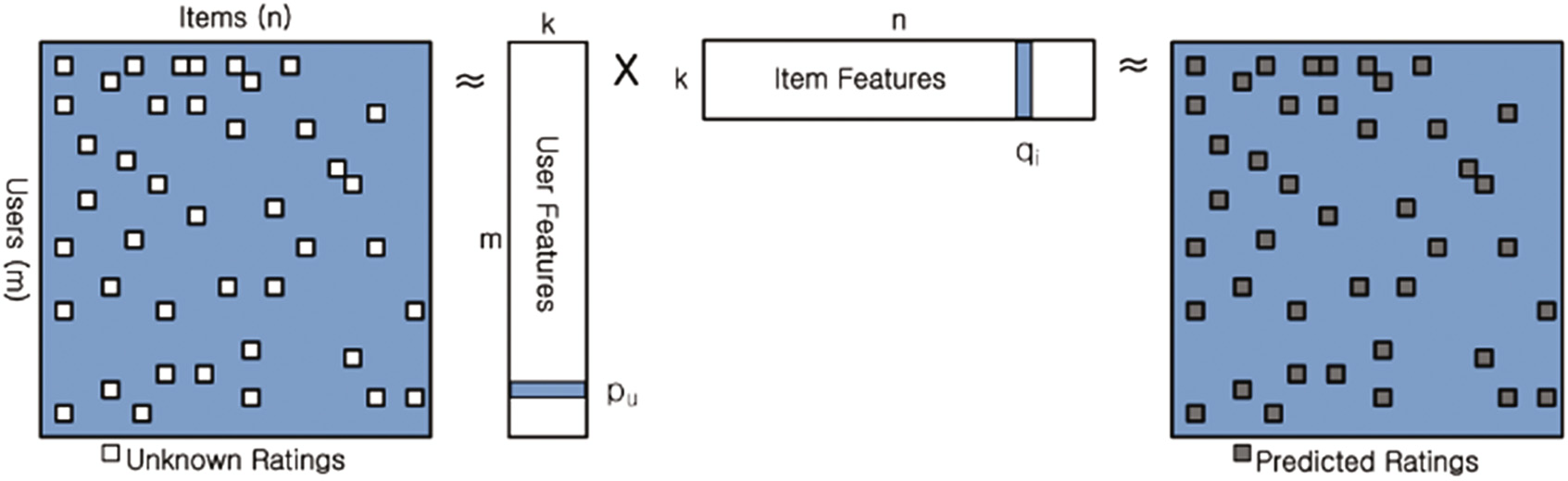
ALS是一种MF优化方法。计算是分布式的。【9】
5、Hadoop和Spark
四、基于激活成本和个人活动的群组推荐方法
1、群组搜索:K-均值聚类
在群组推荐中,采用K-均值聚类方法构造具有相似偏好成员的群组,计算欧几里得距离。
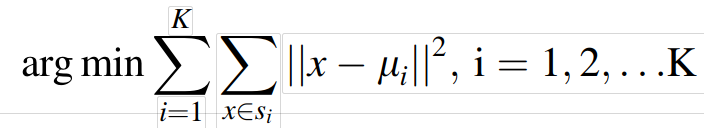
2、组建模:机会成本和损失
K-均值聚类得到的群组表示为 G = {g1,g2,g3……,gk},K = 1,2,……,【K表示K个组】
组的评分 rgki 设为群组成员的均分:【rgki 表示为第k组对第i个项目的评分】【r ulki表示第k组的第l个用户对项目i的评分】
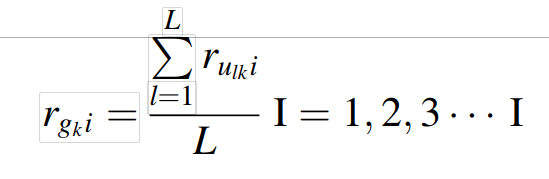
为了获得 群组中每个成员的机会成本 ,先在群组评分中搜索具有最高价值的项目,然后将搜索得到的项目的个人评分作为每个成员的机会成本。
通过选择的特定项目,可从不满程度的每个成员的评分中减去机会成本,从而获得损失。该值越大,群组选择所产生的不满情绪越大。因此,损失越大,在评分中所要求的权重越小,且权重越大,就越有可能提出考虑小组成员不满意的建议。
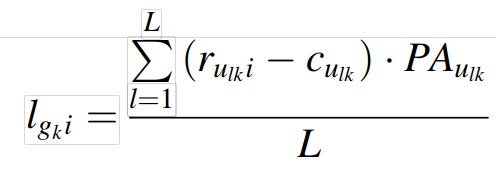
以上l gki表示某个特定项目i的机会成本损失,第k组第l个成员的个人活动均值,c表示第k组第l个成员的机会成本。L表示K群组中的人的总数。
3、组建模:个人活动
为了测量群组中每个成员的影响,这里定义重复性和帮助性准则。
- 重复性是通过群组中每个用户评估项目数量来度量的,且其参与小组活动的程度。
|GI|是组G所有成员评估项目的数量。|Sum|是群组G={u1,u2,……,um}中第m个用户对项目评估的数量。E表示评估的重复性:
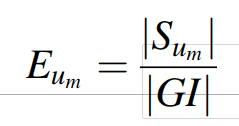
评估的有用性是指由某一组中由特定成员对其他成员的评估文本内容,对其进行归一化:H即用户m的评估有用性。
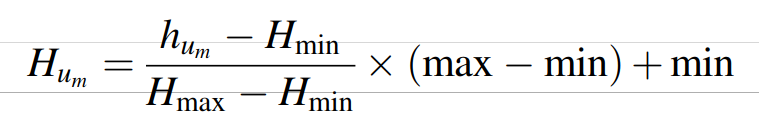
群组G成员的个人活动PA被定义为PA:
![]()
4、偏好评估的准则:
RMSE(均方根误差)
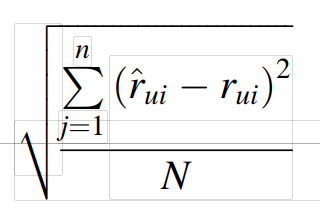

 浙公网安备 33010602011771号
浙公网安备 33010602011771号