(2)pyspark建立RDD以及读取文件成dataframe
别人的相关代码文件:https://github.com/bryanyang0528/hellobi/tree/master/pyspark
1、启动spark
(1)SparkSession 是 Spark SQL 的入口。
(2)通过 SparkSession.builder 来创建一个 SparkSession 的实例,并通过 stop 函数来停止 SparkSession。
Builder 是 SparkSession 的构造器。 通过 Builder, 可以添加各种配置。

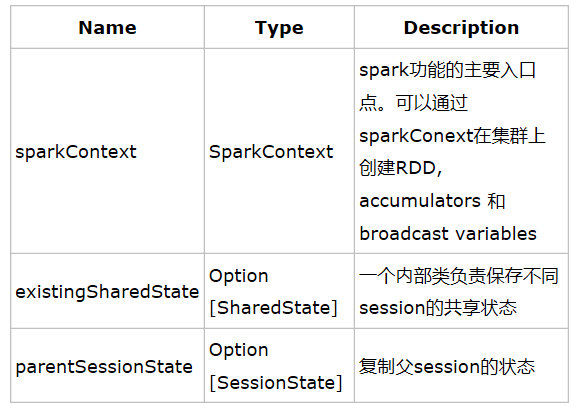
(3)在 SparkSession 的内部, 包含了SparkContext, SharedState,SessionState 几个对象。

2、建立RDD:
创建RDD的两种方法:
1 读取一个数据集(SparkContext.textFile()) : lines = sc.textFile("README.md")
2 读取一个集合(SparkContext.parallelize()) : lines = sc.paralelize(List("pandas","i like pandas"))

#take操作将前若干个数据汇集到Driver,相比collect安全
#collect操作将数据汇集到Driver,数据过大时有超内存风险 all_data = rdd.collect() all_data #take操作将前若干个数据汇集到Driver,相比collect安全 rdd = sc.parallelize(range(10),5) part_data = rdd.take(4) part_data #takeSample可以随机取若干个到Driver,第一个参数设置是否放回抽样 rdd = sc.parallelize(range(10),5) sample_data = rdd.takeSample(False,10,0) sample_data #first取第一个数据 rdd = sc.parallelize(range(10),5) first_data = rdd.first() print(first_data) #count查看RDD元素数量 rdd = sc.parallelize(range(10),5) data_count = rdd.count() print(data_count)
3、从text中读取,read.text
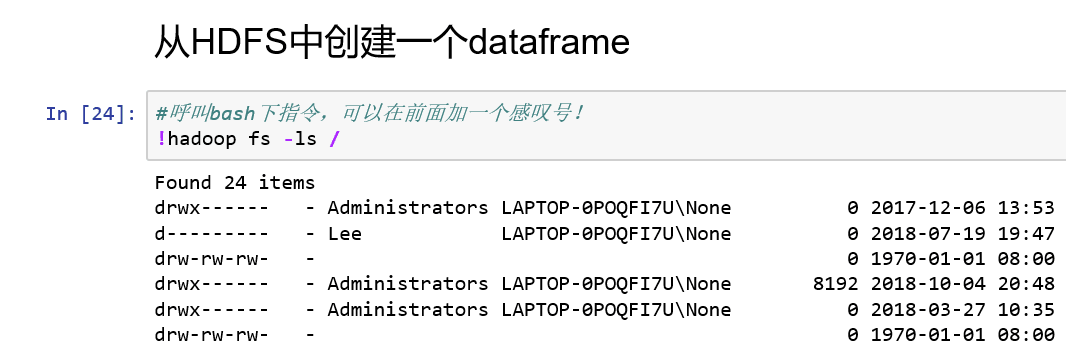
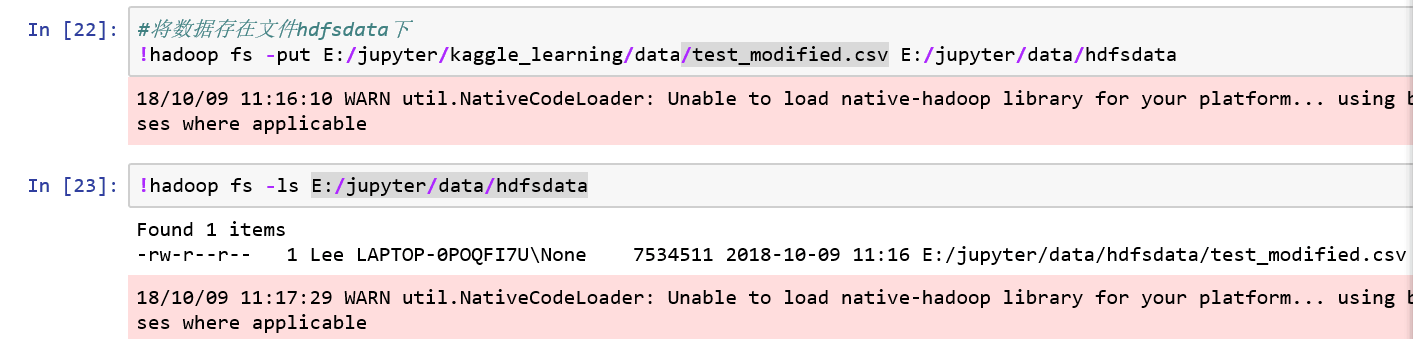
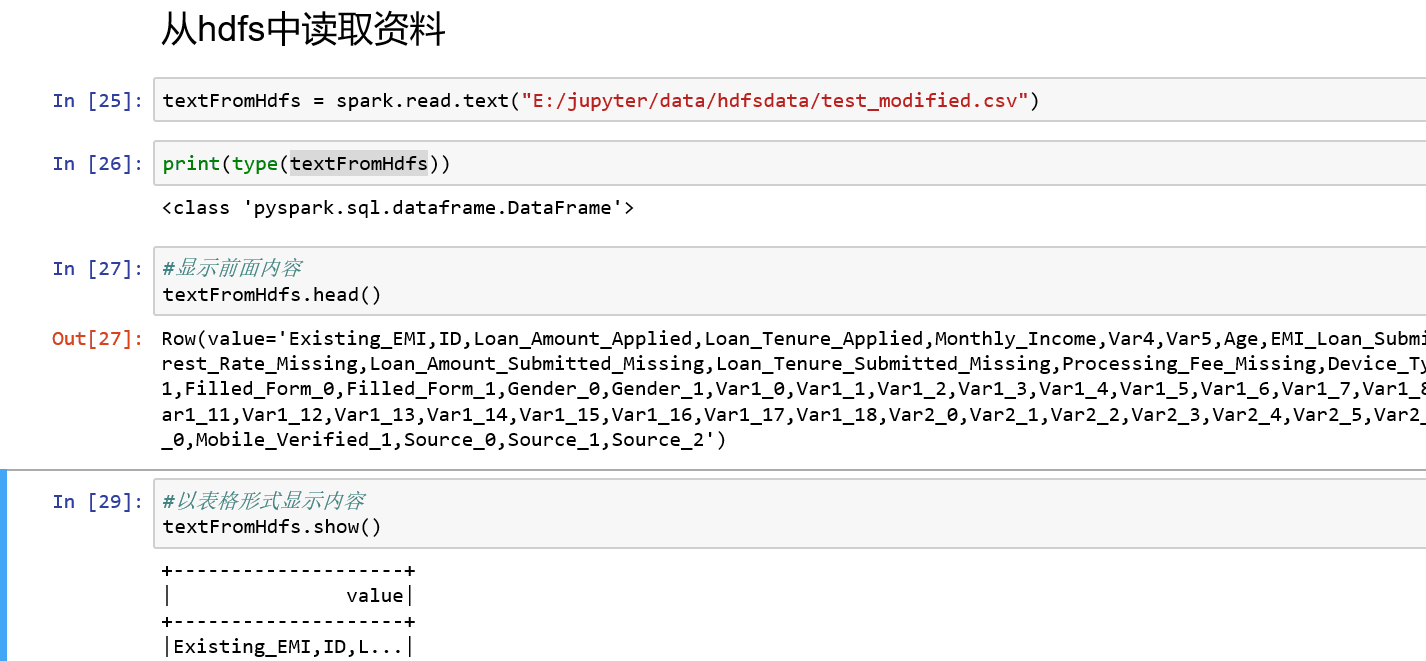
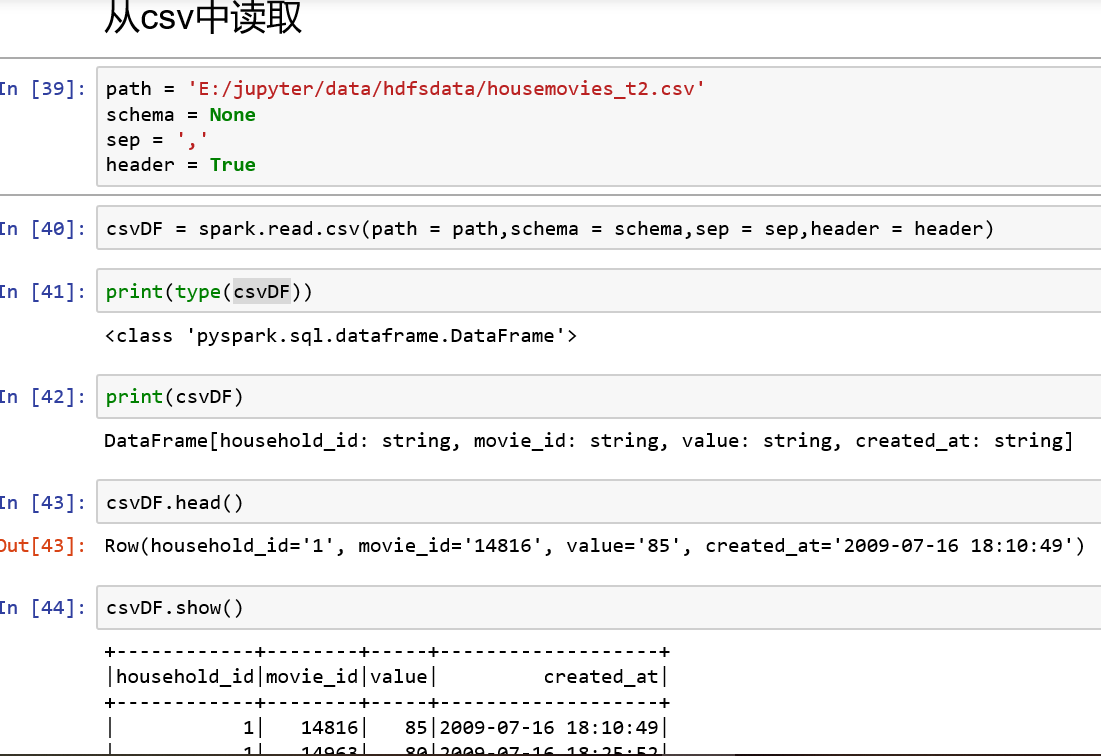
4、从csv中读取:read.csv
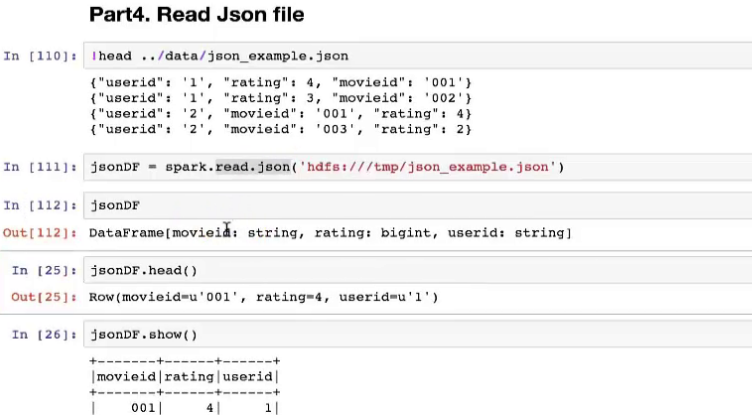
5、从json中读取:read.json
7、RDD与Dataframe的转换
(1)dataframe转换成rdd:
法一:datardd = dataDataframe.rdd
法二:datardd = sc.parallelize(_)
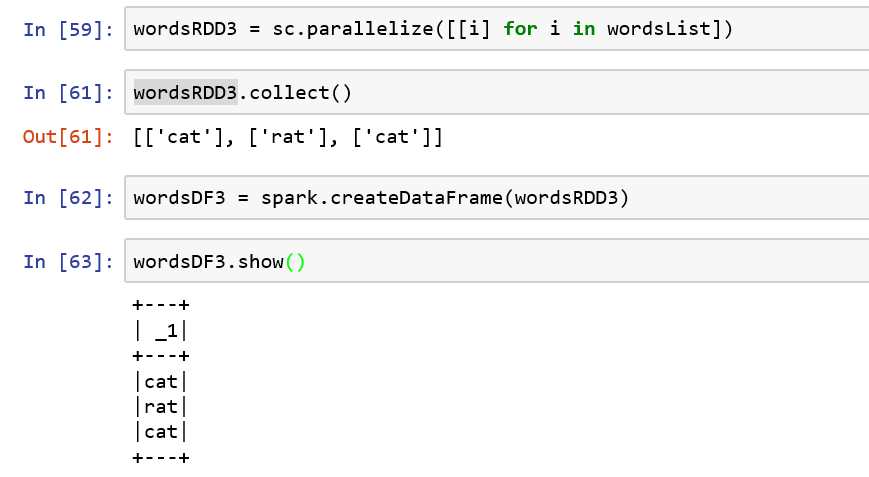
(2)rdd转换成dataframe:
dataDataFrame = spark.createDataFrame(datardd)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号