Python数据分析--------numpy数据打乱
一、shuffle函数:
import numpy.random
def shuffleData(data):
np.random.shufflr(data)
cols=data.shape[1]
X=data[:,0:cols-1]
Y=data[:,cols-1:]
return X,Y
二、np.random.permutation()函数
这个函数的使用来随机排列一个数组的,
一维数组:

对多维数组来说,是多维随机打乱而不是1维,例如:

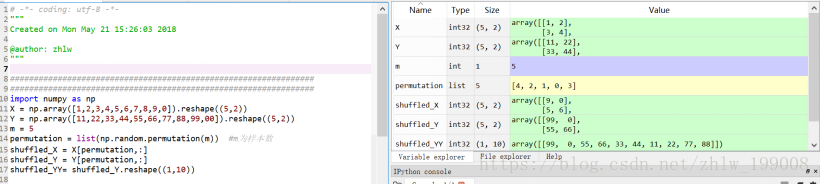
如果要利用次函数对输入数据X、Y进行随机排序,且要求随机排序后的X Y中的值保持原来的对应关系,可以这样处理:
permutation = list(np.random.permutation(m)) #m为样本数
shuffled_X = X[permutation]
shuffled_Y = Y[permutation].reshape((1,m))
图4中的代码是针对一维数组来说的,(图片中右侧为运行结果):

图5中的代码是针对二维数组来说的:
https://blog.csdn.net/zhlw_199008/article/details/80569167
三、sameple函数
sample()参数frac是要返回的比例,比如df中有10行数据,我只想返回其中的30%,那么frac=0.3
以下代码实现了从“CRASHSEV”中选出1,2,3,4的属性,乱序,然后取出前10000行,按行链接成新的数据,重建索引:

def unbanlance(un_data): data1 = un_data.loc[(data["CRASHSEV"] == 1)].sample(frac=1).iloc[:10000, :] data2 = un_data.loc[(data["CRASHSEV"] == 2)].sample(frac=1).iloc[:10000, :] data3 = un_data.loc[(data["CRASHSEV"] == 3)].sample(frac=1).iloc[:10000, :] data4 = un_data.loc[(data["CRASHSEV"] == 4)].sample(frac=1).iloc[:10000, :] ba_data = pd.concat([data1,data2,data3,data4], axis=0).sample(frac=1).reset_index(drop=True) #0是按行链接 return ba_data


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现