Python爬虫2------爬虫屏蔽手段之代理服务器实战
1、代理服务器:
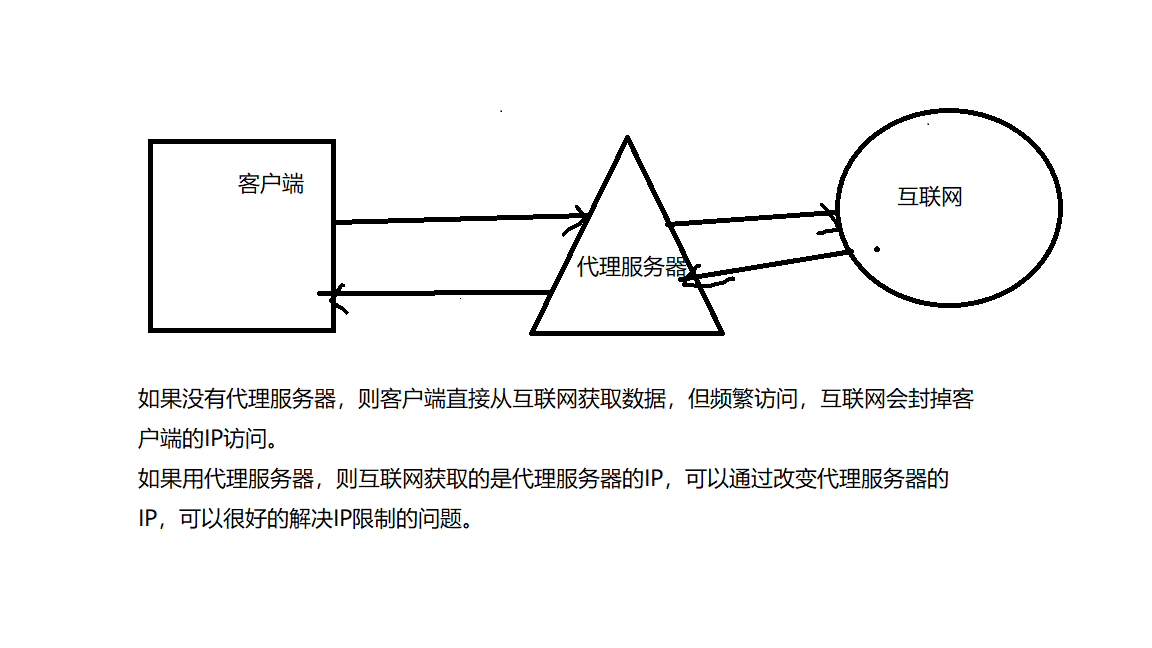
一个处于客户端与互联网中间的服务器,如果使用代理服务器,当我们浏览信息的时候,先向代理服务器发出请求,然后由代理服务器向互联网获取信息,再返回给我们。
2、代码:
import urllib.request #proxy_addr="117.36.103.170:8118",为代理服务器的IP和端口 #url为要爬取数据的地址 def use_proxy(url,proxy_addr): #采用ProxyHandler函数来设置代理服务器,函数参数为字典,字典的键为"http",值为代理服务器的IP地址,IP地址和端口可以在www.xicidaili.com中找。 proxy=urllib.request.ProxyHandler({"http":proxy_addr}) #建立opener,bulid_opener的第一个参数为proxy,第二个参数固定为urllib.request.HTTPHandler opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler) #将opener设置为全局,下面的操作就可以运用该opener了。 urllib.request.install_opener(opener) data=urllib.request.urlopen(url).read().decode("utf-8","ignore") return data proxy_addr="125.118.79.44:6666" url="http://www.baidu.com" data=use_proxy(url,proxy_addr) print(len(data))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号