Python数据分析2------数据探索
一、数据探索
数据探索的目的:及早发现数据的一些简单规律或特征
数据清洗的目的:留下可靠数据,避免脏数据的干扰。
两者没有严格的先后顺序,经常在一个阶段进行。
分为:
(1)数据质量分析(跟数据清洗密切联系):缺失值分析、异常值分析、一致性分析、重复数据或含有特殊符号的数据分析
(2)数据特征分析(分布、对比、周期性、相关性、常见统计量等):
二、数据探索操作
- 查看数据前5行:dataframe.head()


- #查看dataframe的大小:dataframe.shape
三、缺失值分析
(通过describe与len直接发现,通过0数据发现)
(1)缺失值发现:
比方说一个dataframe:dataframe.describe()得到count结果与len(dataframe[某个属性])对比,若少则表明有缺失值。
若一个dataframe中的0数据过多且不合理,则表明这个属性也存在缺失值。
操作:
- dataframe.isnull() #元素级别的判断,把对应的所有元素的位置都列出来,元素为空或者NA就显示True,否则就是False

- dataframe.isnull().any() #列级别的判断,只要该列有为空或者NA的元素,就为True,否则False

- missing = dataframe.columns [ dataframe.isnull().any() ].tolist() #将为空或者NA的列找出来
- dataframe [ missing ].isnull().sum() #将列中为空或者NA的个数统计出来
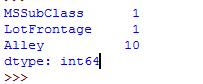
- # 缺失值比例 len(data["Age"] [ pda.isnull(data["Age"]) ]) / len(data))
(2)缺失值处理方式:(删除、插补、不处理)
- 缺失值少:插补(均值插补、中位数插补、众数插补、固定值插补、最近数据插补、回归插补、拉格朗日插值、牛顿插值法、分段插值、用预测值填充 等)
- 缺失值多:不处理,不使用该类型数据
- 缺失值适中:将缺失当做新的一类,如one-hot来处理
操作:
插补:
- dataframe.loc [ dataframe [ column ] .isnull() , column ] = value 将某一列column中缺失元素的值,用value值进行填充。
- data.Age.fillna(data.Age.mean(),inplace=True) 将age列缺失值填充均值。
- dataframe [age] [ dataframe.age.isnull() ] = dataframe.age.dropna().mode().values #众数填补 , mode()函数就是取出现次数最多的元素。
- dataframe ['age'].fillna(method='pad') #使用前一个数值替代空值或者NA,就是NA前面最近的非空数值替换
- dataframe ['age'].fillna(method='bfill',limit=1) #使用后一个数值替代空值或者NA,limit=1就是限制如果几个连续的空值,只能最近的一个空值可以被填充。
- df.interpolate():对于时间序列的缺失,可以使用这种方法。
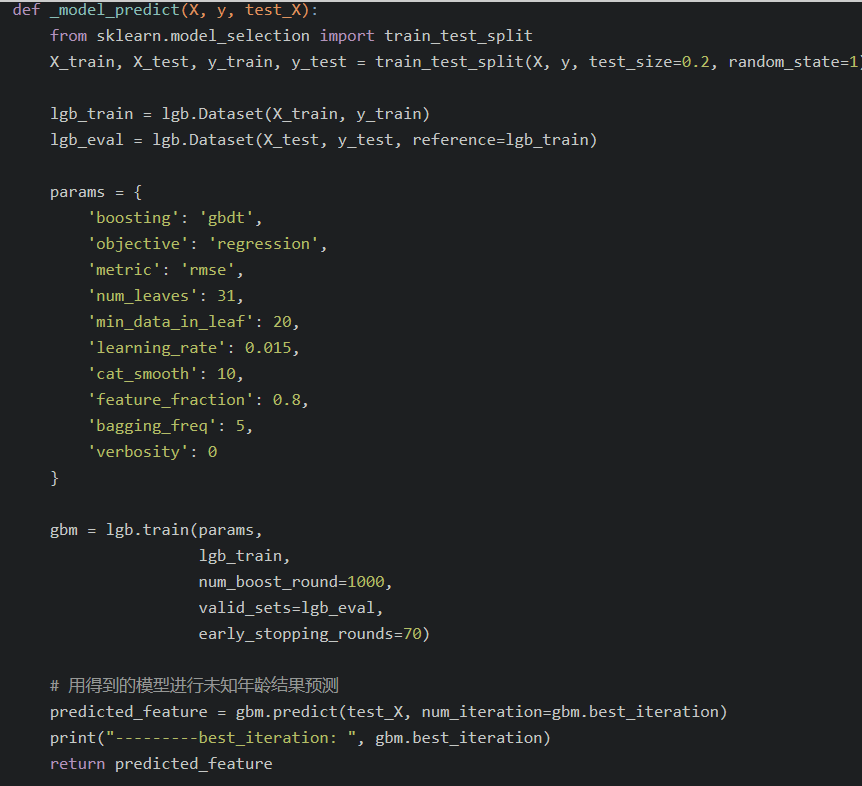
- import lightgbm as lgb :采用lgb来预测缺失值填补

删除:
- new_drop = dataframe.dropna ( axis=0,subset=["Age","Sex"] ) 【在子集中有缺失值,按行删除】
- new_drop = dataframe.dropna ( axis=1) 【将dataframe中含有缺失值的所有列删除】
(2)异常值发现:(通过散点图和箱型图发现)
异常值发现:
先画数据的散点图。观察偏差过大的数据,判断其是否为异常值。
或者画箱型图,箱型图识别异常值比较客观,因为它是根据3σ原则,如果数据服从正态分布,若超过平均值的3倍标准差的值被视为异常值。
异常值处理方式:视为缺失值、删除、修补(平均数、中位数等)、不处理。
中位数比平均值插值好一点,因为受异常值影响较小。
4、数据特征分析:
分布分析:(画直方图)
先确定极差(max-min)、组数、组距,然后根据这三个来画直方图(hist函数)。
可以大范围查看数据,也可以缩小范围进行分析,这需要具体数据具体分析。
通常数据有很多属性,可以将属性两两画直方图,通过直方图来分析数据符合什么分布,比如正态分布,线性分布等。如果使用上所有的数据范围过大,分布过于集中不明显,可以将其集中的数据缩小到一个小范围中再画直方图进行分析。
小例子:将data中price列数据值为0的变为缺失值,然后再给其赋值为中位数,假设中位数为36
import pandas as pd data['price'][(data['price']==0)]=None for i in data.columns: for j in data.index: if (data[i].isnull())[j]: data[i][j]='36'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号