Python数据分析1------数据存取
1、CSV格式数据:
1.1普通读取和保存
可以以纯文本形式打开,可以保存多条记录,每条记录的数据之间默认用逗号来分隔,csv就是逗号分割值的英文缩写。
保存为csv文件:
import pandas as pd
data=pd.DataFrame(数据源)
data.to_csv('文件名.csv',index = False,encoding = 'utf-8,mode='a'') index= False的意思是不把index保存进文件中,mode='a'是表示以追加的方式加入文件中
读取csv文件: read_csv
参数详解:https://www.jianshu.com/p/366aa5daaba9【比如一些日期参数,大文件参数】
- 参数:head 、names :# 这里的header=None是表示第一行的数据不取为列名,自己另外取名为names=['a','b','c']。如果不加header=None则表示第一行作为列名。
dataframe=pd.read_csv('地址加文件名.csv',header=None,names=['a','b','c']) print(dataframe)
- 参数:encoding :# 遇到 ‘utf-8’ codec can’t decode byte 0xba in position 0: invalid start byte 但是又必须要中文解码,解决办法是设置read_csv中encoding = ‘GB2312’
注意:读取csv文件还有别的方法:read_table(' 文件位置 ', names=' dataframe的列名 ',encoding='utf-8' ,sep='|' )
- 参数:chunksize——分块读取大文件:https://blog.csdn.net/zm714981790/article/details/51375475 。read_csv中有个参数chunksize,通过指定一个chunksize分块大小来读取文件,返回的是一个可迭代的对象TextFileReader。
reader = pd.read_table('tmp.sv', sep='|', chunksize=4) for chunk in reader: print(chunk)
- 参数:iterator :指定iterator=True 也可以返回一个可迭代对象TextFileReader :
reader = pd.read_table('tmp.sv', sep='|', iterator=True) reader.get_chunk(5)
# open读取代码: with open(filepath,'r') as f: for line in f: print(line) #pandas读取代码: chunk_data = pd.read_csv('./data/train_data/showctr.txt', sep = '\t', quoting = csv.QUOTE_NONE, header = None, names=['query','show', 'click','rate'],iterator = True) largeshow = pd.DataFrame() smallshow = pd.DataFrame() count = 0 loop = True while loop: try: chunksize = 100000 show_data = chunk_data.get_chunk(chunksize) show_data = show_data.dropna(axis = 0,subset=['query']) largeshow = pd.concat([largeshow,show_data[show_data['show'] >= 1000]],axis = 0) smallshow = pd.concat([smallshow,show_data[show_data['show'] < 1000]],axis = 0) count += 1 except StopIteration: loop = False print("shape of show_rawdata , large_show and small_show ", count * chunksize, largeshow.shape ,smallshow.shape)

1.2、csv文件读取:
以下方式读出来的不是dataframe,是列表形式
from numpy import loadtxt dataset=loadtxt('***.csv',delimiter=",") 【逗号为分隔符】
1.3、csv文件追加
f=open(path,'a+',newline='')#newline设定可以让写出的csv中不包含空行 writer=csv.writer(f) for row in range(b.shape[0]): writer.writerow(b.iloc[row])#按行将数据写入文件中 f.close()
df.to_csv('my_csv.csv', mode='a', header=False)
2、Excel文件的读取和保存
保存:
dataframe=pd.DataFrame(数据源)
dataframe.to_excel('文件名.xlsx',sheet_name='表名')
读取:
dataframe=pd.read_excel('文件名.xlsx')
print(dataframe)
3、sql文件读取:read_sql
读取sql文件之前需要安装好mysql以及python连接mysql的模块PyMySQL,直接命令pip install pymysql。
在数据库中新建一个数据库test,然后新建一个表students,插入数据。
在读取mysql数据之前要将mysql的服务启动:net start mysql。
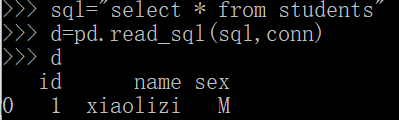
import pymysql import pandas as pd #连接数据库为test conn=pymysql.connect(host="127.0.0.1",user="root",passwd="123456",db="test") #查询的表为students sql="select * from students" data=pd.read_sql(sql,conn) print(data)
结果如下:输出结果为dataframe
4、读取html文件:read_html
这个函数主要读取HTML中table的数据。
本地的HTML文件代码如下:
<html> dnfnjefwnkndsn <table> <tr><td>7</td><td>9</td></tr> <tr><td>5</td><td>8</td></tr> <tr><td>2</td><td>6</td></tr> </table> </html>
读取代码如下:
import pandas as pd htl=pd.read_html('E:\wenjian\data\test.html') print(htl)
结果如下:

读取网络上的HTML的数据也一样。只要将本地地址换成网络地址就行。
5、读取文本数据(txt文件、dat文件、out文件):read_table
dataframe写入文本数据代码:
def text_save(filename, data):#filename为写入CSV文件的路径,data为要写入数据列表. file = open(filename,'a') for i in range(len(data)): s = str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符 file.write(s) file.close() print("保存文件成功")
6、小例子实现:
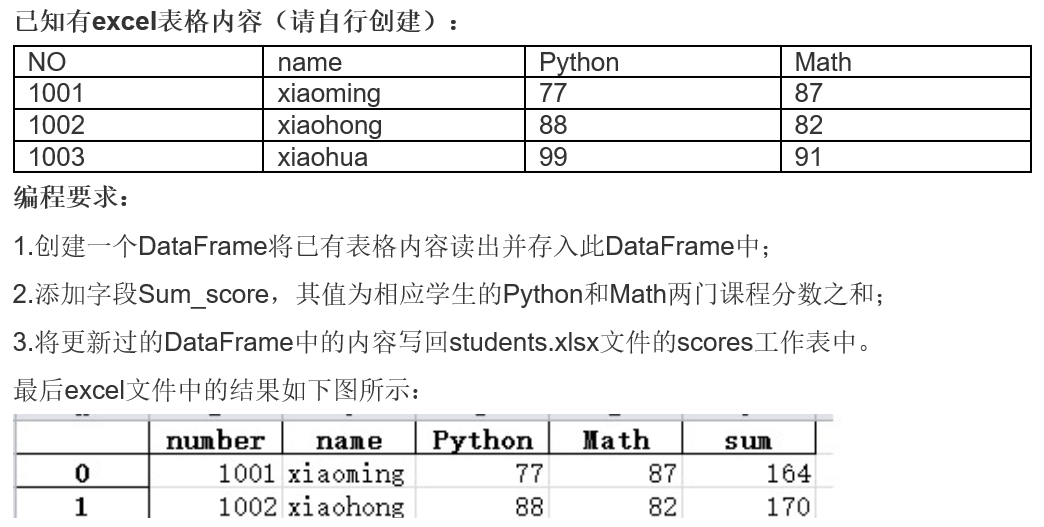
import pandas as pd df=pd.read_csv('test_csv.csv') df['Sum_score']=df['Python']+df['Math'] print(df) df1=df.rename(columns={'Sum_score':'sum'}) print(df1) df1.to_excel('test_csv.xlsx',sheet_name='scores')
7、json文件读取:
json文件中的数据形式和字典很像,比如:
d1 = {'1':2, '2':3, '3':4}
d2 = {'1':3, '2':4, '3':5}
d1为一个json对象,d2也是一个json对象。如果一个data.json文件中同时存储着d1和d2,则在读取json文件时不能同时解析两个对象,因为这两个对象中的key是一样的
#调用read函数全部读取json文件中的数据会报错,因为不能同时读取相同的json对象。需要用readlines()函数,一行一行的读取。 import json with open('data.json','r') as f: data=f.read() data=json.loads(data) print(data) #调用readlines()函数读取,并加载进一个列表当中 data_list=[] with open(r'data.json','r') as f: for line in f.readlines(): dic = json.loads(line) data_list.append(dic)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号