python笔记3----第一个小爬虫
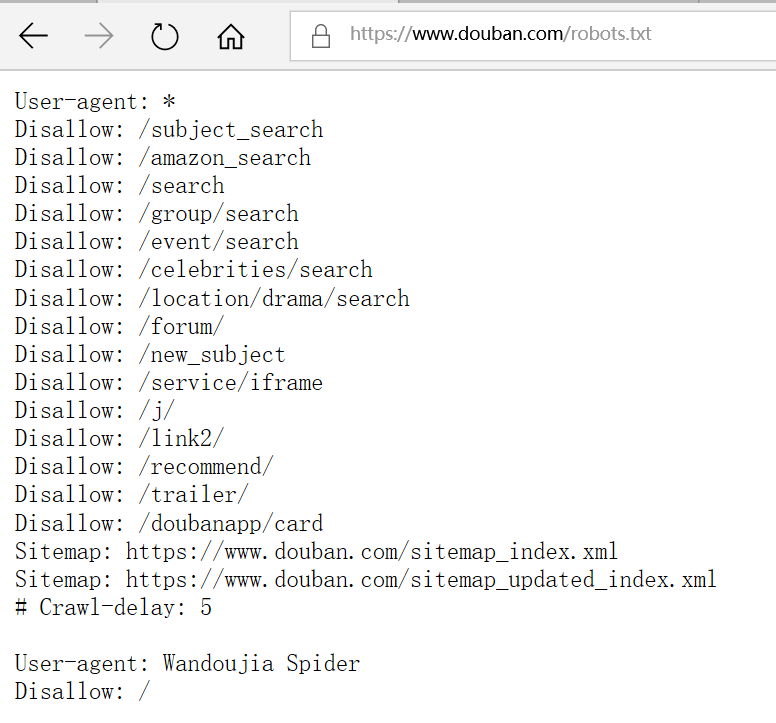
1、先看看要爬的网站有没有爬虫协议,可以看该网站有没有robots.txt,如豆瓣的:
2、requests模块:【requests是第三方,代码比python自带的urllib模块简单】
先加载requests模块,然后输入要抓取的地址:
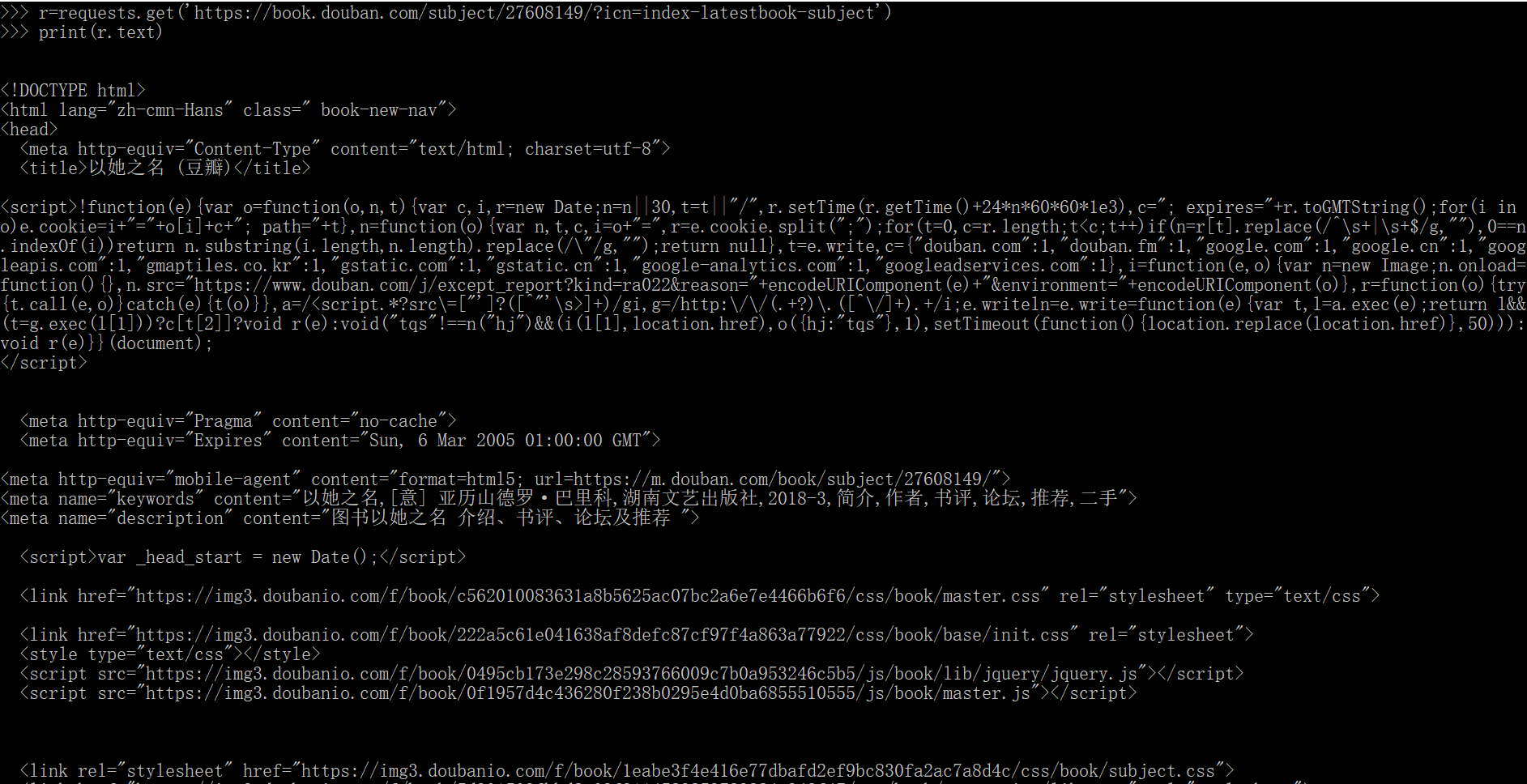
import requests r=requests.get(‘https://book.douban.com/subject/28135034/?icn=index-latestbook-subject') print(r.text)
结果如下:输出该网页的代码源
运用BeautifulSoup,BeautifulSoup是用来从HTML和xml中提取数据的Python库。
#导入BeautifulSoup
from bs4 import BeautifulSoup
#把要提取的源码加入汤里 soup=BeautifulSoup(r.text,'html')
#find_all函数是将<p class='comment-content’> </p>之间的字符串找出来 pattern=soup.find_all('p','comment-content')
#将每一个字符串打印出来。 for item in pattern: print(item.string)
运用正则表达式来获取评分:
#导入正则表达式模块
import re sum=0
#将正则表达式的字符串形式编译成pattern实例,观察源代码,评分是在以下的标签中,(.*?)是正则表达式,懒惰匹配 pattern_s=re.compile('<span class="user-stars allstars(.*?) rating"')
#使用Pattern实例处理文本并获得匹配结果 p=re.findall(pattern_s,r.text) for i in p:
#i是字符串,需要转化成整型 sum+=int(i) print(i) print(sum)
3、urllib模块小程序:
目的:将以下网页的出版社爬取出来

from urllib import request import re #读取数据 data=request.urlopen('https://read.douban.com/provider/all').read() #中文转码,将Unicode码转成utf-8,将中文显示出来 data=data.decode('utf-8') #观察网页,将需要爬取数据正则表达式写出来 pat='<div class="name">(.*?)</div>' #从数据源中爬取正则表达式中的数据,注意data要转成str res=re.compile(pat).findall(str(data)) #res为列表,所有数据集合的列表,可以打印出来 for item in res: print(item)
写入文件中,如写入‘E://1.txt'
file=open('E://1.txt','w') for item in res: file.write(item,'\n')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号