强化学习(6)---马尔可夫过程
一、概念
1、finite MDP:如果一个强化学习任务满足马尔科夫性质,那么就可以把这个任务叫做马尔科夫过程。如果状态空间和动作空间是有限的,那么就叫做有限马尔科夫过程,即finite MDP。
2、状态S、动作A、转移概率P、期望价值r、
一个典型的finite MDP 由状态集、动作集和一步内的环境动态性来定义。
给定状态和动作
,下一个可能状态
的可能性由下式给出:
这个等式叫做转移概率。
相似的,给定任何当前的状态和动作,和
,以及下一个状态
,下一个reward的期望价值由下式给出:
这些等式完整描述了finite MDP的动态性质。
我们本书中的大多理论的前提假设就是环境是finite MDP。
3、policy:
是状态空间到动作空间的映射图,它定义了给定状态下做出给定动作的概率。
4、Value Functions(s)
这个function自变量是状态,用来判断在某个给定状态下做出某个动作的好坏程度。
好坏程度用什么来定义呢?这里我们使用“未来的期望奖励”来定义,也可以说期望返回值。
显然agent在未来期望得到的奖励取决于它做出什么决策。因此,value function在定义的时候和policy有关。
在某个policy 的前提下,某个状态
的value function
,定义为从当前状态
开始,按照policy
的规则,一直走下去的期望返回值。公式如下:
我们把上式的叫做policy
下的状态-价值函数。
5、value function(a)
同样的,我们也可以类似的定义一个在policy 规则下,在状态为
时动作为
的value function,表示为
。公式如下:
我们把叫做policy
下的动作-价值函数。
6、value fun递归方式
对于任何policy 和任何状态s,当前状态的value和其后的可能状态的value之间的关系如下式:
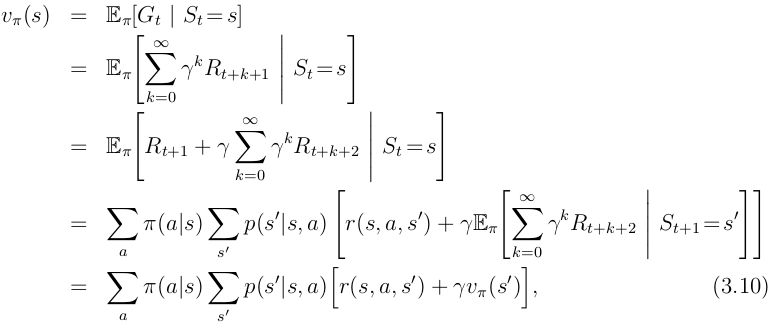
注意表示期望奖励,当奖励是确定性的情况下,也就等于即时奖励(immediate reward)。该式叫做policy
的贝尔曼方程。贝尔曼方程对从当前状态起之后的所有可能性进行了平均化,并按照发生的概率给予不同的权重。
二、优化的value function
粗略地说,解决一个强化学习问题,也就是意味着找到一个policy,在这个policy下可以获得最好的长期期望奖励。对于finite MDP来说,我们可以用下面的方式精确的定义一个最优policy。如果我们说一个policy 比另外一个policy
更好,或者一样好,那么其实就是说,对于状态空间中的所有的状态s,按照前一个policy
得到的
都比后一个policy
得到的
要大(或者相等)。至少存在一个policy,使得它可以好于或者等于其他所有的policies,这个policy就叫做最优policy(optimal policy)。尽管有可能最优policy有多个,我们用
来表示。最优policies对应的value function是相同的,用
表示,定义如下:
同样的,最优policies的最优action-value function也是相同的,用表示,定义如下:
另外,和
之间的关系式如下:
因为仍然是价值函数,因此,它也有对应的贝尔曼方程写法,叫做贝尔曼最优方程。贝尔曼最优方程的含义就是,在最优policy下某状态的value,一定等于当前状态下最优动作的期望返回值(in long run)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号