NLP学习(4)----word2vec模型
一. 原理
哈弗曼树推导: https://www.cnblogs.com/peghoty/p/3857839.html
负采样推导: http://www.hankcs.com/nlp/word2vec.html
https://github.com/kmkolasinski/deep-learning-notes/blob/master/seminars/2017-01-Word2Vec/slides.pdf
https://blog.csdn.net/u014595019/article/details/51884529
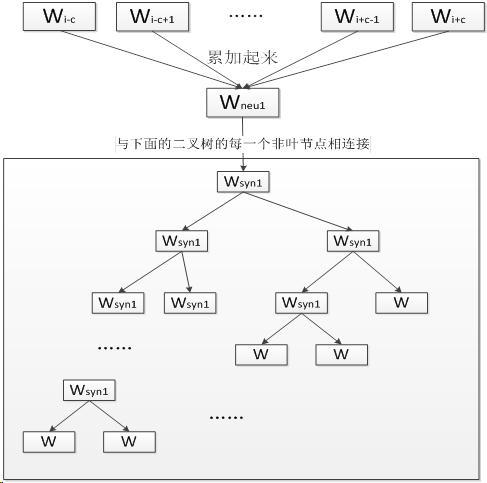
cbow与skip gram:https://zhuanlan.zhihu.com/p/37477611
层次化softmax与负采样对比:
转: https://blog.csdn.net/asdfsadfasdfsa/article/details/91436687
Hierarchical Softmax是一种对输出层进行优化的策略,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值。一开始我们可以用以词表中的全部词作为叶子节点,词频作为节点的权,构建Huffman树,作为输出。从根节点出发,到达指定叶子节点的路径是的。Hierarchical Softmax正是利用这条路径来计算指定词的概率,而非用softmax来计算。
即Hierarchical Softmax:[优化一]把 N 分类问题变成 log(N)次二分类,利用哈夫曼树构造很多二分类(sigmoid);
( 使用原始的softmax计算,是N分类,N代表词典个数,所以softmax计算量非常大需要对N个分类下的各自输出值)
Hierarchical softmax的缺点就是:虽然我们使用huffman树代替传统的神经网络,可以提高模型训练的效率,但是如果我们训练样本中的中心词w是一个很生僻的词,那么就需要沿着huffman树往下走很多,因为越是高频的词,越是靠近根节点
[优化二] 层次化softmax不必求神经网络隐藏层中的权值矩阵, 而是改求哈弗曼树中每个节点的权值向量, 这样就减少了计算
Negative Sampling(简写NEG,负采样),这是Noise-Contrastive Estimation(简写NCE,噪声对比估计)的简化版本:把语料中的一个词串的中心词替换为别的词,构造语料 D 中不存在的词串作为负样本。在这种策略下,优化目标变为了:较大化正样本的概率,同时最小化负样本的概率;
[优化] 在训练每个样本时, 原始神经网络隐藏层权重的每次都会更新, 而负采样只挑选部分权重做小范围更新
词汇表的大小决定了我们skip-gram 神经网络将会有一个非常大的权重参数,并且所有的权重参数会随着数十亿训练样本不断调整。negative sampling 每次让一个训练样本仅仅更新一小部分的权重参数,从而降低梯度下降过程中的计算量。
如果 vocabulary 大小为1万时, 当输入样本 ( "fox", "quick") 到神经网络时, “ fox” 经过 one-hot 编码,在输出层我们期望对应 “quick” 单词的那个神经元结点输出 1,其余 9999 个都应该输出 0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们为 negative word. negative sampling 的想法也很直接 ,将随机选择一小部分的 negative words,比如选 10个 negative words 来更新对应的权重参数。
NEG提高训练速度和精度的优化方法:
1.二次抽样高频词,舍弃
2.对于频次高的词提高采样的命中率
总结:
CBOW和SKip-gram是训练模型: 前者训练次数等同于样本次数V(即词典大小), 后者训练次数为KV,即每个样本训练K次(K是窗口大小)
层次化softmax和负采样是优化方法: 前者是将N分类的softmax改为logN层次二分类,将每个样本的每次训练更新原始求解所有隐藏层的权重矩阵改为求解哈弗曼节点权重矩阵; 后者是针对每个训练样本的每次训练,只更新部分隐藏权重矩阵
二. 实战(1)
自己动手写word2vec (一):主要概念和流程
自己动手写word2vec (二):统计词频
自己动手写word2vec (三):构建Huffman树
自己动手写word2vec (四):CBOW和skip-gram模型
https://github.com/multiangle/pyword2vec
(1) 分词 / 词干提取和词形还原。 中文和英文的nlp各有各的难点,中文的难点在于需要进行分词,将一个个句子分解成一个单词数组。而英文虽然不需要分词,但是要处理各种各样的时态,所以要进行词干提取和词形还原。
(2) 构造词典,统计词频。这一步需要遍历一遍所有文本,找出所有出现过的词,并统计各词的出现频率。
(3) 构造树形结构。依照出现概率构造Huffman树。如果是完全二叉树,则简单很多,后面会仔细解释。需要注意的是,所有分类都应该处于叶节点,像下图显示的那样[4]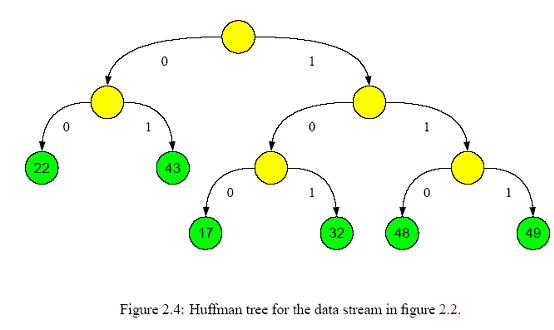
(4)生成节点所在的二进制码。拿上图举例,22对应的二进制码为00,而17对应的是100。也就是说,这个二进制码反映了节点在树中的位置,就像门牌号一样,能按照编码从根节点一步步找到对应的叶节点。
(5) 初始化各非叶节点的中间向量和叶节点中的词向量。树中的各个节点,都存储着一个长为m的向量,但叶节点和非叶结点中的向量的含义不同。叶节点中存储的是各词的词向量,是作为神经网络的输入的。而非叶结点中存储的是中间向量,对应于神经网络中隐含层的参数,与输入一起决定分类结果。
(6) 训练中间向量和词向量。对于CBOW模型,首先将词A附近的n-1个词的词向量相加作为系统的输入,并且按照词A在步骤4中生成的二进制码,一步步的进行分类并按照分类结果训练中间向量和词向量。举个栗子,对于绿17节点,我们已经知道其二进制码是100。那么在第一个中间节点应该将对应的输入分类到右边。如果分类到左边,则表明分类错误,需要对向量进行修正。第二个,第三个节点也是这样,以此类推,直到达到叶节点。因此对于单个单词来说,最多只会改动其路径上的节点的中间向量,而不会改动其他节点。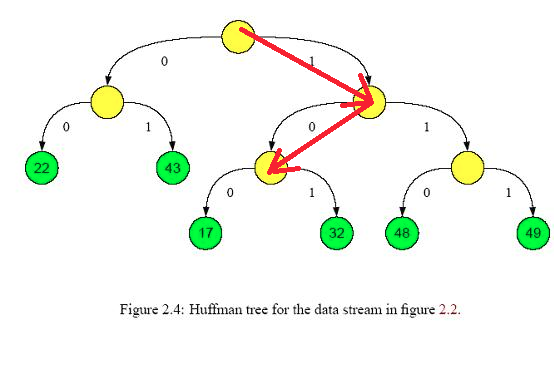

def __GoAlong_Huffman(self,word_huffman,input_vector,root): node = root #从root开始 自顶向下 e = np.zeros([1,self.vec_len]) #将误差初始化为零向量 for level in range(word_huffman.__len__()): # 一层层处理[正确路径的节点数] huffman_charat = word_huffman[level] # 根据Huffman码获知当前节点应该将输入分到哪一边 q = self.__Sigmoid(input_vector.dot(node.value.T)) grad = self.learn_rate * (1-int(huffman_charat)-q) # 计算当前节点的误差 e += grad * node.value # 累加误差 node.value += grad * input_vector #修正当前节点的中间向量 node.value = preprocessing.normalize(node.value) # 归一化 if huffman_charat=='0': #将当前节点切换到路径上的下一节点 node = node.right else: node = node.left return e
三. 实战(2)
https://blog.csdn.net/juanjuan1314/article/details/52116768
四. 源码解析(4)
https://www.aboutyun.com/thread-24275-1-1.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号