计算广告(6)----爱奇艺广告技术沙龙(广告召回)
一、AI在视频广告中的应用:
1、广告的目的:
在一定周期,让尽可能多的人产生消费。
长周期:品牌广告(比如阿迪、nike等品牌),短周期:效果广告(比如平时打开网页出现在眼帘的广告)。
消费行为:购买、激活、安装、下载、点击。
2、如何传达消费价值:
匹配需求:用户行为(搜索、浏览、点击等)、统计特征(性别、年龄、地区等)
能够将用户想要看的广告适时地推到面前,让广告主的广告得到合理的投放。
展示价值:场景(点位)+效果(索引)
场景化投放:如用户台风天在大街上伞被吹走(这种场景),如果当场有个广告关于能够抵抗12级台风的伞,是很合适的。
3、AI(视频理解方面)的主要工作:
生成/推荐点位:场景
辅助创作素材:效果
4、点位
(1)场景化示意

创可贴:广告内容和视频内容十分贴切,比如图一中吃饭场景付费是采用支付宝,则视频中会出现支付宝支付界面的广告。
前情提要:图二可以看到人物下方会有饮料的广告,这广告可能和前情提要有相关的,比如这里哭得稀里哗啦的要来点饮料解渴。
video in:视频中后期加入广告,在视频中剪辑进入一个雪碧广告等。
(2)视频广告如何实现场景化
商业价值点=有消费需求的点位【找到这些点位,然后打上标签】
聚餐--想喝饮料、地铁---听点音乐、海滩----希望防晒、亲吻---来束玫瑰
---视频分析(如果要找到有商业价值的点位)
对象【人脸识别、姿态识别、服饰分类、目标检测、表情识别】
事件【行为识别、语音识别、意图理解、事件分类、文本挖掘】
场景【场景识别、地标识别、调性分析、音频分类、音乐识别】
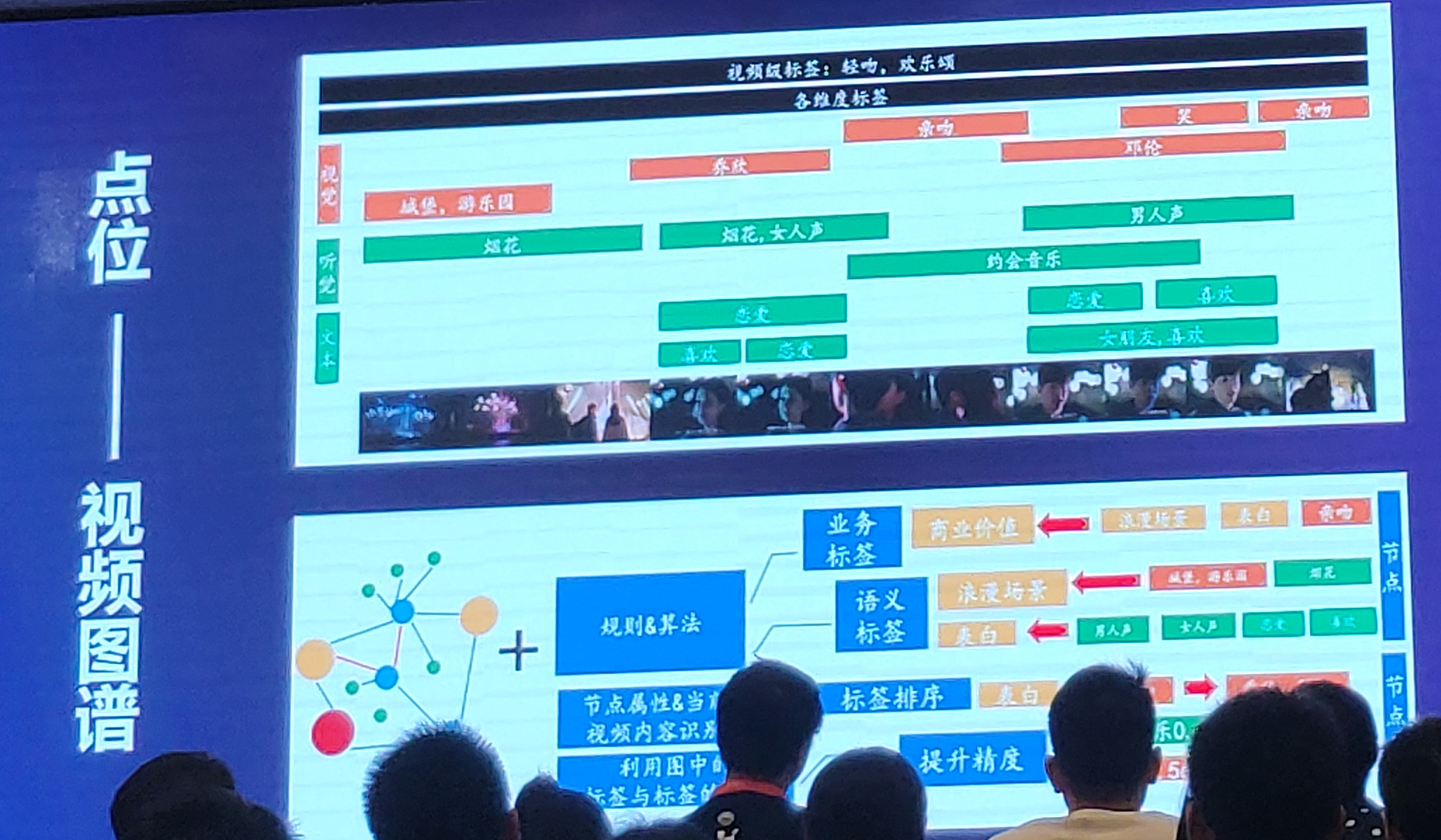
从各个维度来对视频分析,给视频打上标签,这些标签可以在之后被采用做推荐、匹配广告等。
但如果从这些识别中获得的标签可能不能很全面地给视频打上正确的标签,如在视频中用户常希望两个男女主角有浪漫的场景,而不是男二女二,这就涉及到人物和场景的交叉关联性。所以希望能更好的去训练更好的标签。
----视频图谱(怎么计算标签的重要性和相关性)
规则&算法----业务标签、语义标签
节点属性&当前视频内容识别---标签排序
利用图中的标签与标签的距离---提升精度
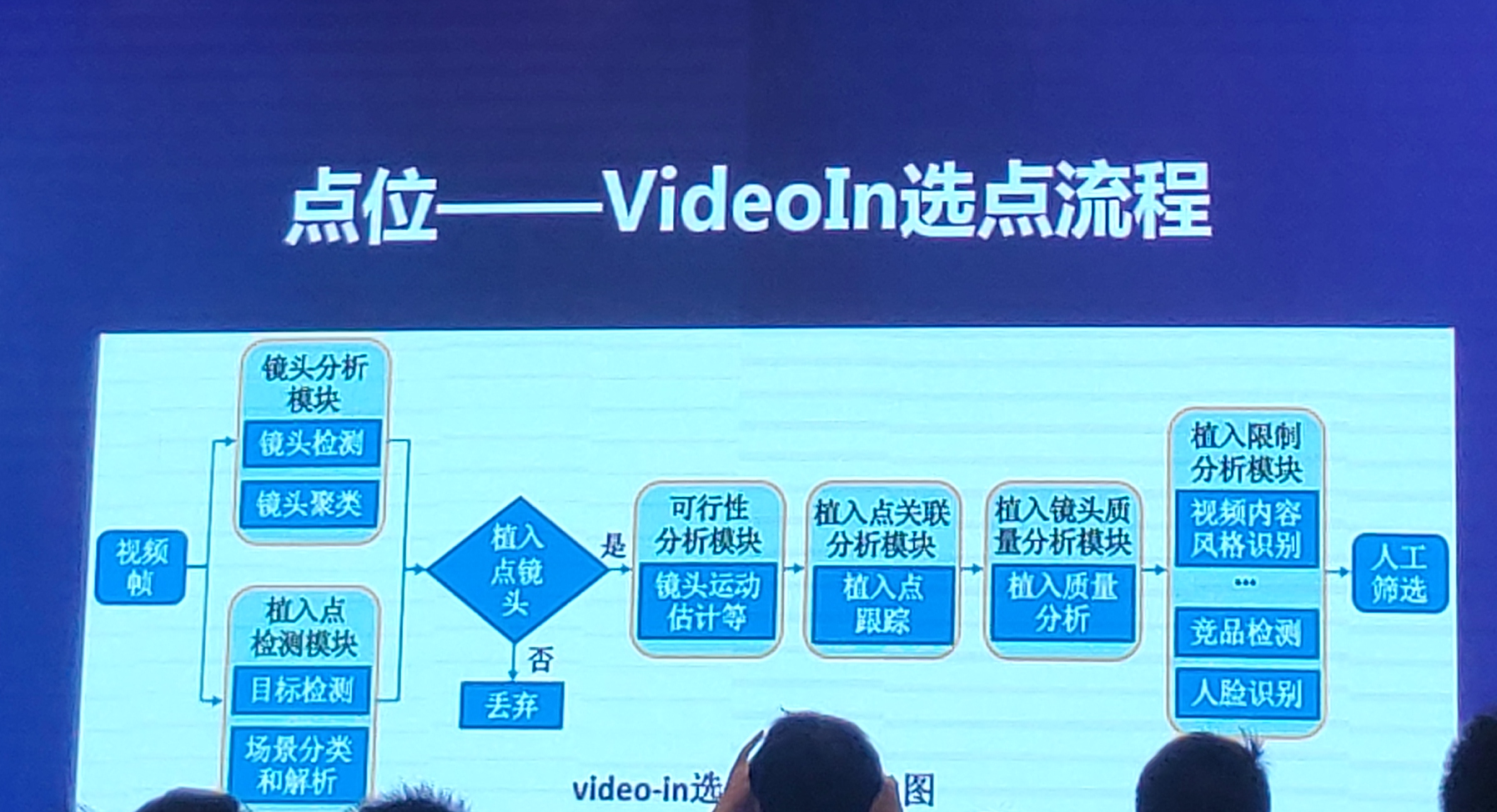
---VideoIn选点流程
二、360广告召回模块
1、展示广告业务介绍:
(1)媒体方在曝光之前将流量发给ADX(相当于将流量交给ADX进行广告拍卖),360自身也有一个AD Exchange(360 Max)。
(2)ADX发流量给DSP来对这次曝光进行竞价(360自身也有一个360点睛DSP)
(3)广告主对自身的需求设置一些广告投放返回给DSP
(4)DSP会根据这些广告投放来匹配相关的候选集,将候选集返回给ADX,DSP响应时间很短,在100ms左右
(5)最后ADX选择出价最高的DSP投放

2、常见的展示广告:
(1)广告侧边栏:具体投放广告的详情页
(2)整体的开屏广告:品牌广告
(3)信息流:嵌入新闻上下文中的广告,和文章内容形式保持一致

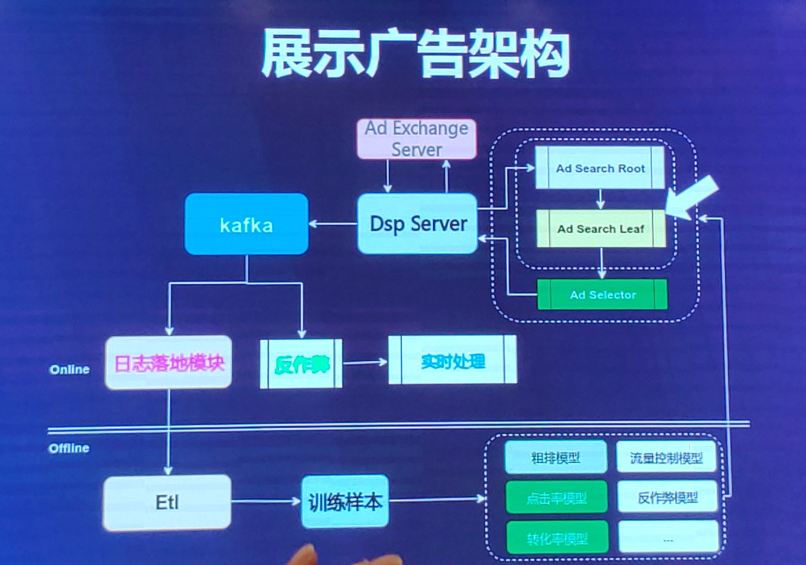
3、展示广告架构
(1)流量是从ADX中发给DSP端,
(2)DSP拿到流量之后进行Ad search Root和Ad Search Leaf两个模块,
Ad search Root是对流量进行识别,判断其为哪种类型流量,比如是属于kidword?信息流?banerge流量?,
然后将判定的流量类型交给Ad search Leaf【对广告进行召回】,这个模块选出相匹配的广告候选集,
之后再交给Ad Selector模块【精排】,即对广告的CTR或者CVR进行预估,选出top K个广告返回给DSP server。
(3)将一些广告点击、曝光、后序的日志写入kafka,用来做日志落地模块和反作弊。
一部分的日志用来做日志落地模块,分为线上和线下。
离线:将日志进入ETL以及训练样本模型。
一部分的日志用来做反作弊,比如实时的曝光反馈。
4、检索召回模块:
(1)DSP提供的一个流量请求Request包含(用户、context)。
(2)广告主设置的广告投放存在Ad meta db中,然后建成相关的广告索引(ad index),投放更新之后才会实时更新这个索引
(3)RTDB是根据用户和context上下文进行用户标签的实时更新和线下处理
(4)召回模块:结合Ad index和RTDB选出候选集
(5)过滤模块:根据规则、黑白名单、广告主的预算、pacing进行过滤等
(6)粗排模块:
(7)精排:LR、FFM……

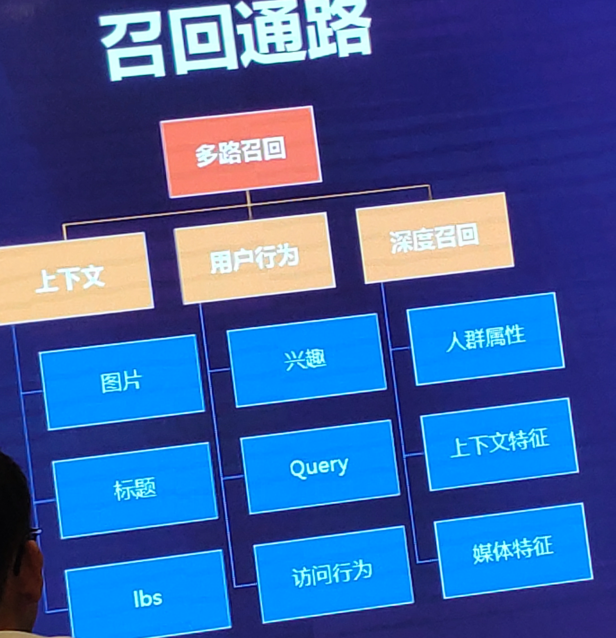
5、召回通路(多链路召回):
基于上下文:
图片(内容页:一个明星穿了哪件衣服,根据这件衣服投放哪件商品广告),做法:将图片向量化,计算广告商品和图片向量的相似度。
标题(文本NLP操作),基于文本召回
lbs(广告主自身设定某个区域,希望在该区域【标签】内进行投放)布尔召回
基于用户行为:
兴趣(根据一些profile打上一些用户兴趣标签):布尔召回
query(360搜索中的查询行为,NLP)基于文本召回
访问行为(哪些用户看了哪些商品,主要针对商品特征),item based CF、ALS、Neural MF
基于深度召回:
结合user profile、媒体特性、上下文特性等进入深度模型中进行召回
基于文本召回(标题、query)

6、召回模块演进

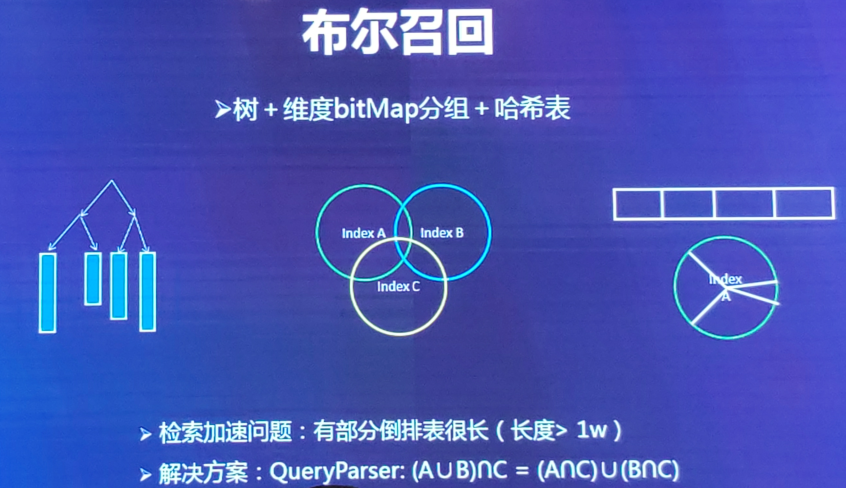
(1)布尔召回:基于倒排索引
倒排索引怎么构建?https://www.jianshu.com/p/86bd98551f4b
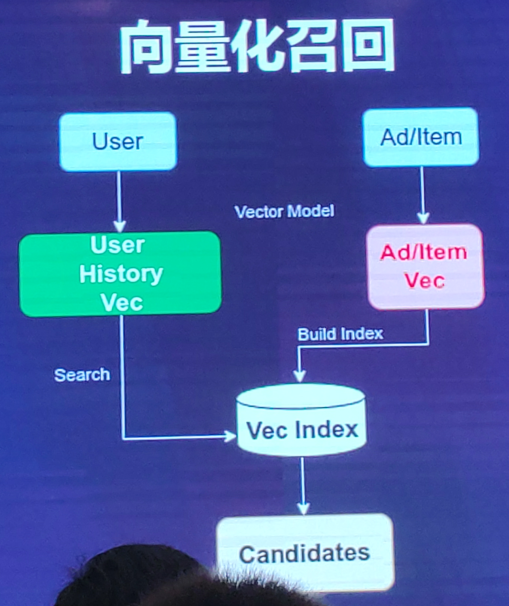
(2)向量化召回
向量化召回,主要通过模型来学习用户和物品的兴趣向量,并通过内积来计算用户和物品之间的相似性,从而得到最终的候选集。
其中,比较经典的模型便是Youtube召回模型。线下,可以计算用户embedding和项目embedding的内积。
向量化检索:但是在实际线上应用时,由于物品空间巨大,计算用户兴趣向量和所有物品兴趣向量的内积,耗时十分巨大,有时候会通过局部敏感Hash等方法来进行近似求解。
①【YouTube DNN将用户和item的特征转成向量进行相似度检索】
②基于深度语义检索模型(DSSM)

输入:用户query、与该query相关的项目D1,两个不相关的D2和D3。将query、D1、D2、D3都转成embedding,进入NN神经网络。
输出:最后softmax给三种项目打分α,正例分数尽可能高。
向量检索索引
- 基于树的方法
KD树是其下的经典算法。一般而言,在空间维度比较低时,KD树的查找性能还是比较高效的;但当空间维度较高时,该方法会退化为暴力枚举,性能较差,这时一般会采用下面的哈希方法或者矢量量化方法。因为高维空间的主要特点之一是,随着维数增加,任意两点之间最大距离与最小距离趋于相等
- 哈希方法
LSH(Locality-Sensitive Hashing)是其下的代表算法。文献[7]是一篇非常好的LSH入门资料。
对于小数据集和中规模的数据集(几个million-几十个million),基于LSH的方法的效果和性能都还不错。这方面有2个开源工具FALCONN和NMSLIB。
- 矢量量化方法
矢量量化方法,即vector quantization。在矢量量化编码中,关键是码本的建立和码字搜索算法。比如常见的聚类算法,就是一种矢量量化方法。而在相似搜索中,向量量化方法又以PQ方法最为典型。
对于大规模数据集(几百个million以上),基于矢量量化的方法是一个明智的选择,可以用用Faiss开源工具。
原文链接:https://blog.csdn.net/gaoyanjie55/article/details/81383434

LSH:https://blog.csdn.net/leadai/article/details/89391366
LSH的基本思想如下:我们首先对原始数据空间中的向量进行hash映射,得到一个hash table,我们希望,原始数据空间中的两个相邻向量通过相同的hash变换后,被映射到同一个桶的概率很大,而不相邻的向量被映射到同一个桶的概率很小。因此,在召回阶段,我们便可以将所有的物品兴趣向量映射到不同的桶内,然后将用户兴趣向量映射到桶内,此时,只需要将用户向量跟该桶内的物品向量求内积即可。这样计算量被大大减小。
关键的问题是,如何确定hash-function?在LSH中,合适的hash-function需要满足下面两个条件:
1)如果d(x,y) ≤ d1, 则h(x) = h(y)的概率至少为p1;
2)如果d(x,y) ≥ d2, 则h(x) = h(y)的概率至多为p2;
其中d(x,y)表示x和y之间的距离, h(x)和h(y)分别表示对x和y进行hash变换。
满足以上两个条件的hash function称为(d1,d2,p1,p2)-sensitive。而通过一个或多个(d1,d2,p1,p2)-sensitive的hash function对原始数据集合进行hashing生成一个或多个hash table的过程称为Locality-sensitive Hashing。
(3)深度树索引
布尔召回:倒排表的key-value的value值会越来越长,检索性能会越来越差。
向量检索:局限于模型的向量表达是否够好,局限于向量空间。
基于深度树的检索:解决检索性能以及全量检索。
【全量检索:因为协同过滤在召回的时候,并不能真正的面向全量商品库来做检索,系统只能在用户历史行为过的商品里面找到侯选的相似商品来做召回】
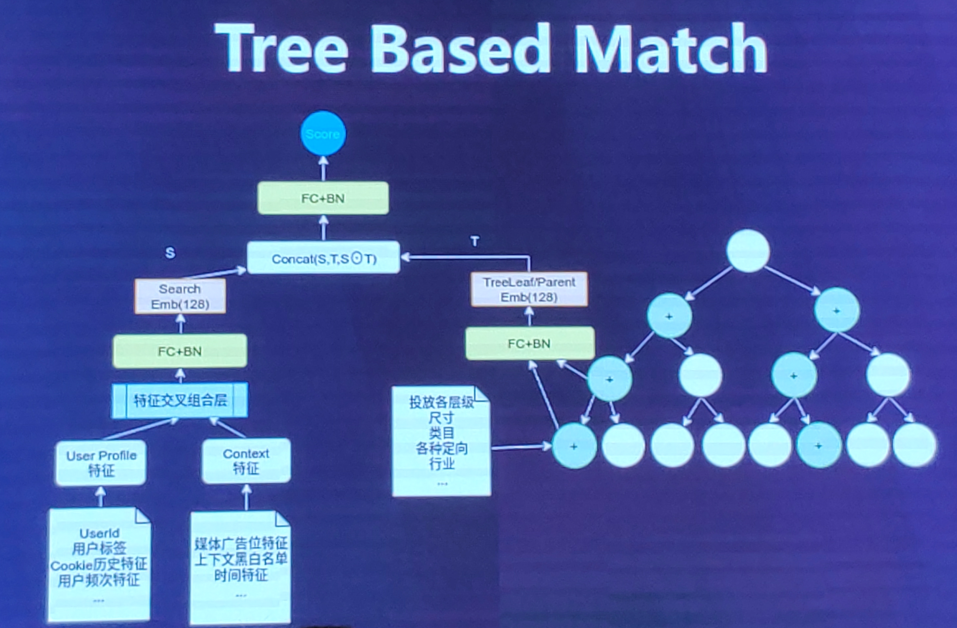
整体结构
1、(流量方)左边的用户属性特征(如性别、年龄等),上下文特征(媒体广告位,时间等特征)
2、左边特征进入特征交叉组合层,选择IPNN的模型
3、进入FC + BN转成search embedding(128),线上更新时,左边这个模型是实时更新的。
4、(广告主特征)右边特征包含广告投放的一些特征(尺寸、类目、行业等),即构成树的叶子节点。
5、构建树,将树的父节点和叶子节点进入FC+ BN,出来Tree Leaf/Parent embedding,然后和左边的search embedding进行concat,最后计算出一个score。
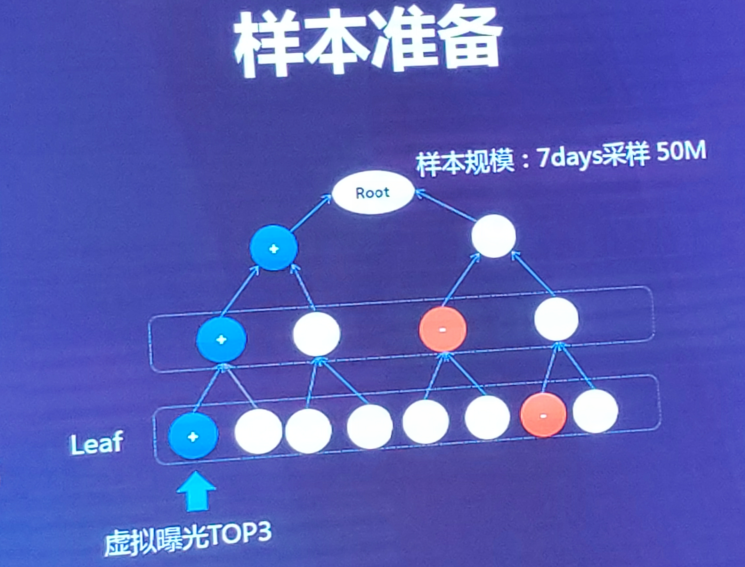
如何准备样本?
叶子节点的正例:top 3(ecpm最大),负例:2/3 叶子节点同层随机负采样 + 1/3 prerank低分样本。
父节点的正例:叶子节点向上回溯标正,即叶子节点最大的ecpm也为父节点最大的ecpm,负例:同层随机(没有直接往上回溯,因为易和正节点相交) 规模:7天的数据采样后5000万。
如何构建树?

每一层的父节点的最大期望和所有子节点中最大期望值是相等的。时间复杂度:2klog2(n)
如何生成树?
两种方式:随机生成+自下而上合成树
随机生成:初始时随机二分生成一棵树,将生成树的叶子embedding拿到,将其进行聚类,根据聚类结果重新生成一棵树来迭代。
自下而上合成树:先当这棵树不存在,然后将右边的特征样本放入DNN模型中先训练出叶子节点的embedding,然后再根据叶子节点的embedding向上聚类回溯成一颗树(kmeans或者根据曝光频次来聚类),之后再不断迭代聚类更新这棵树。

模型训练:

模型迭代收敛时,将树模型导到线上去。
模型loss:
交叉熵loss:拟合对应的样本是否曝光【点击加权】
triplet loss:叶子节点的正样本和用户特征距离尽可能相近,负样本距离尽可能远。

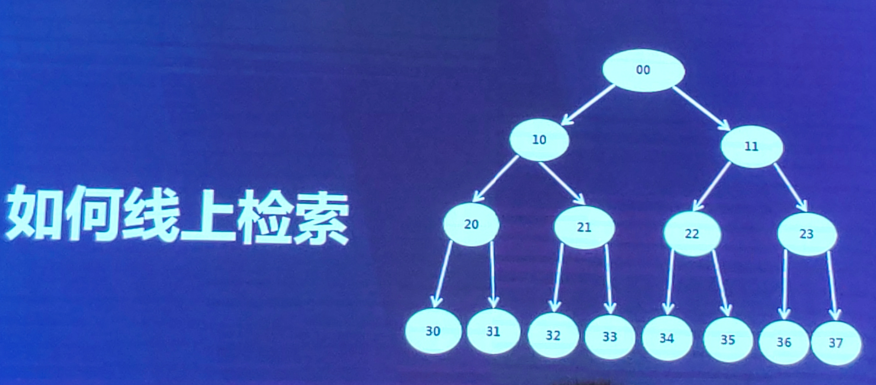
如何线上检索:beam search
如:选出top 3,
第一层:只有一个节点<3,被选出。
第二层:只有两个节点<3,两个都被选出。
第三层:选出其被选中的父节点的三个子节点。
第四层:选出其被选中的父节点的三个子节点。
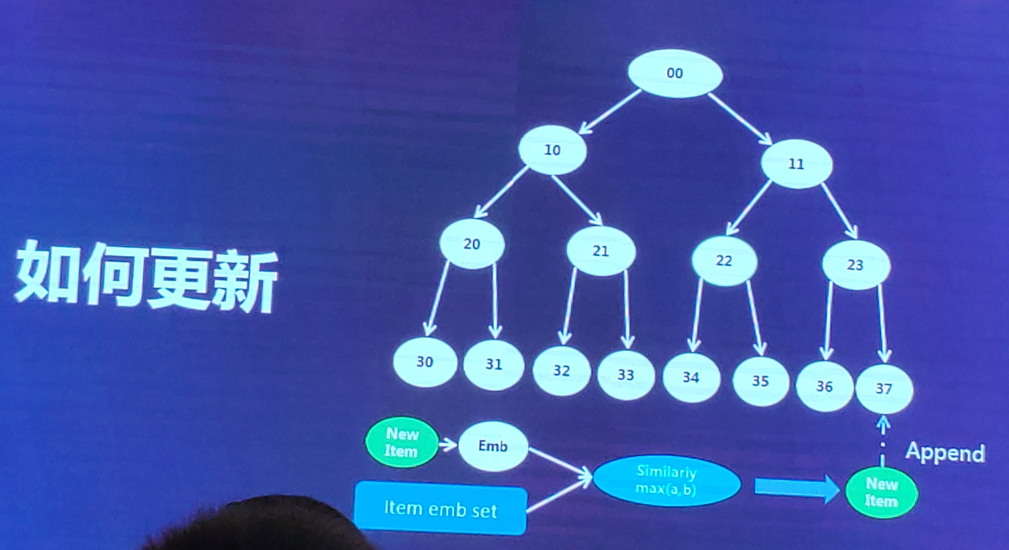
如果广告主新增候选集,怎么更新树?
新来一个样本,将其转化成embedding,在叶子节点的embedding集合中,计算相似度,找到与新样本最相似的叶子节点37,将该新样本加入这个叶子节点37的list中去,【线上训练时,叶子节点实际是一个cluster,一个列表,并不是一个单一的节点。】
性能优化:
避免feed dict。采用dataset API,可并行。

指标评价:
线下和线上分开评估。
线下:AUC、recall等
线上:业务指标:rpm,rpc,ctr等,树 的指标(检索时间性能)
召回/排序,评估时进行分桶的A/B Test

 浙公网安备 33010602011771号
浙公网安备 33010602011771号