tensorflow实战笔记(20)----textRNN
https://www.cnblogs.com/jiangxinyang/p/10208227.html
https://www.cnblogs.com/jiangxinyang/p/10241243.html
一、textRNN模型
https://www.jianshu.com/p/e2f807679290
https://github.com/gaussic/text-classification-cnn-rnn
https://github.com/DengYangyong/Chinese_Text_Classification
【双向LSTM/GRU】
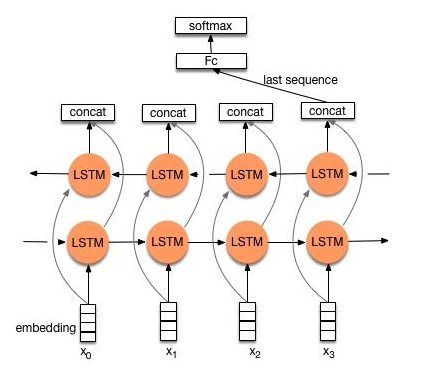
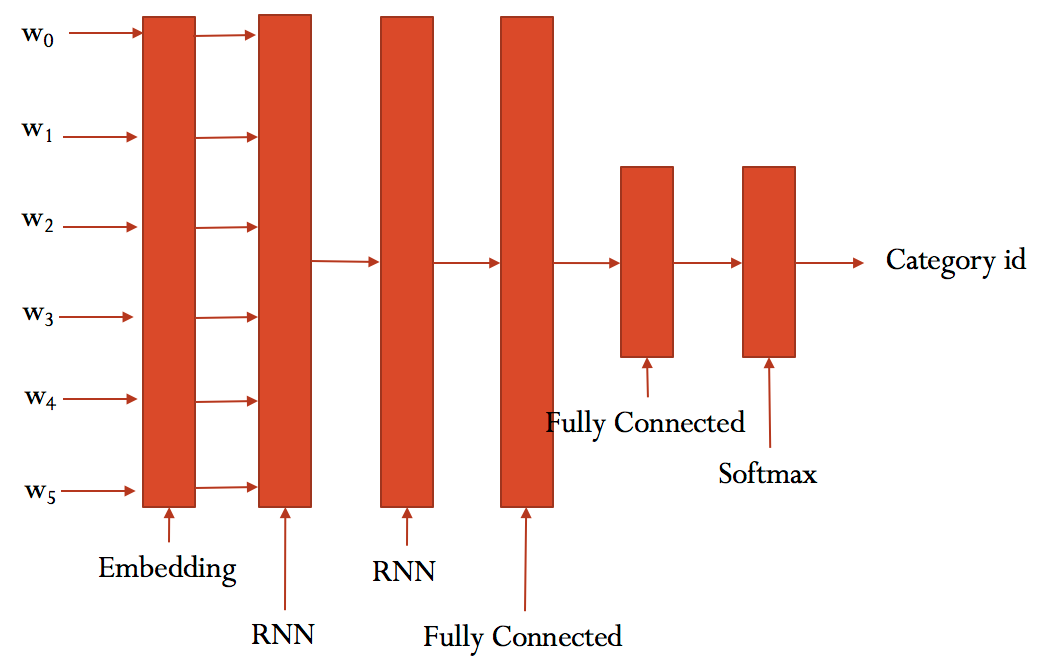
二、代码:
注意:数据输入:embedded_mat 【word_id,vec】 和 traindata【word_ids,label】
模型结构:
class TRNNConfig(object): """RNN config""" embedding_dim = 100 seq_length = 36 num_classes = 1 num_layers= 2 # hidden layers number hidden_dim = 128 rnn = 'gru' # rnn type dropout_keep_prob = 0.8 learning_rate = 0.001 batch_size = 512 num_epochs = 10 print_per_batch = 100 save_per_batch = 10 class TextRNN(object): """rnn model""" def __init__(self, config , embedding_matrix): self.config = config self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x') self.input_y = tf.placeholder(tf.float32, [None ,self.config.num_classes ], name='input_y') self.keep_prob = tf.placeholder(tf.float32, name='keep_prob') self.embedding_matrix = embedding_matrix self.rnn() def rnn(self): def lstm_cell(): return tf.nn.rnn_cell.LSTMCell(self.config.hidden_dim, state_is_tuple=True) def gru_cell(): return tf.nn.rnn_cell.GRUCell(self.config.hidden_dim) def dropout(): if (self.config.rnn == 'lstm'): cell = lstm_cell() else: cell = gru_cell() return tf.nn.rnn_cell.DropoutWrapper(cell, output_keep_prob=self.keep_prob) ## embedding layers with tf.device('/gpu:0'),tf.variable_scope(name_or_scope='embedding', reuse=tf.AUTO_REUSE): W = tf.Variable( tf.constant(self.embedding_matrix, dtype=tf.float32, name='pre_weights'), name="W", trainable=True) embedding_inputs = tf.nn.embedding_lookup(W, self.input_x) ## 2 RNN layers with tf.variable_scope(name_or_scope='rnn', reuse=tf.AUTO_REUSE): cells = [dropout() for _ in range(self.config.num_layers)] rnn_cell = tf.nn.rnn_cell.MultiRNNCell(cells, state_is_tuple=True) _outputs, _ = tf.nn.dynamic_rnn(cell=rnn_cell, inputs=embedding_inputs, dtype=tf.float32) last = _outputs[:, -1, :] ## FC layers with tf.variable_scope(name_or_scope='score1', reuse=tf.AUTO_REUSE): # fc1 + dropout + relu fc = tf.layers.dense(last, self.config.hidden_dim, name='fc1') fc = tf.contrib.layers.dropout(fc, self.keep_prob) fc = tf.nn.relu(fc) with tf.variable_scope(name_or_scope='score2', reuse=tf.AUTO_REUSE): # fc2 + dropout + BN + sigmoid self.logits = tf.layers.dense(fc, self.config.num_classes, name='fc2') self.logits = tf.contrib.layers.dropout(self.logits, self.keep_prob) fc_mean , fc_var = tf.nn.moments(self.logits , axes = [0] ,) scale = tf.Variable(tf.ones([self.config.num_classes])) shift = tf.Variable(tf.zeros([self.config.num_classes])) epsilon = 0.001 self.logits = tf.nn.sigmoid(tf.nn.batch_normalization(self.logits , fc_mean, fc_var, shift , scale , epsilon),name = "logits") self.y_pred_cls = tf.cast(self.logits > 0.5, tf.float32,name = "predictions") ## adam optimizer with tf.variable_scope(name_or_scope='optimize', reuse=tf.AUTO_REUSE): cross_entropy = tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.input_y) self.loss = tf.reduce_mean(cross_entropy) self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss) ## acc with tf.variable_scope(name_or_scope='accuracy', reuse=tf.AUTO_REUSE): correct_pred = tf.equal(self.y_pred_cls, self.input_y) self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
训练步骤:
def batch_iter(x, y, batch_size=128): data_len = len(x) num_batch = int((data_len - 1) / batch_size) + 1 for i in range(num_batch): start_id = i * batch_size end_id = min((i + 1) * batch_size, data_len) yield x[start_id:end_id], np.array(y[start_id:end_id]).reshape(-1,1) def get_time_dif(start_time): """time function""" end_time = time.time() time_dif = end_time - start_time return timedelta(seconds=int(round(time_dif))) def feed_data(x_batch, y_batch, keep_prob): feed_dict = { model.input_x: x_batch, model.input_y: y_batch, model.keep_prob: keep_prob } return feed_dict def evaluate(sess, x_, y_): """ test loss ,acc""" data_len = len(x_) batch_eval = batch_iter(x_, y_, 128) total_loss = 0.0 total_acc = 0.0 for x_batch, y_batch in batch_eval: batch_len = len(x_batch) feed_dict = feed_data(x_batch, y_batch, 1.0) y_pred_class,loss, acc = sess.run([model.y_pred_cls,model.loss, model.acc], feed_dict=feed_dict) total_loss += loss * batch_len total_acc += acc * batch_len return y_pred_class,total_loss / data_len, total_acc / data_len def train(): print("Configuring TensorBoard and Saver...") tensorboard_dir = 'tensorboard/textrnn' if not os.path.exists(tensorboard_dir): os.makedirs(tensorboard_dir) # Output directory for models and summaries timestamp = str(int(time.time())) out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs/textrnn", timestamp)) print("Writing to {}\n".format(out_dir)) # Summaries for loss and accuracy loss_summary = tf.summary.scalar("loss", model.loss) acc_summary = tf.summary.scalar("accuracy", model.acc) # Train Summaries train_summary_op = tf.summary.merge([loss_summary, acc_summary]) train_summary_dir = os.path.join(out_dir, "summaries", "train") train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph) # Dev summaries dev_summary_op = tf.summary.merge([loss_summary, acc_summary]) dev_summary_dir = os.path.join(out_dir, "summaries", "dev") dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph) # Checkpoint directory. Tensorflow assumes this directory already exists so we need to create it checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints")) checkpoint_prefix = os.path.join(checkpoint_dir, "model") if not os.path.exists(checkpoint_dir): os.makedirs(checkpoint_dir) saver = tf.train.Saver(tf.global_variables(), max_to_keep=1) # Session os.environ["CUDA_VISIBLE_DEVICES"] = "2" config_ = tf.ConfigProto() config_.gpu_options.allow_growth=True # allocate when needed session = tf.Session(config = config_) session.run(tf.global_variables_initializer()) train_summary_writer.add_graph(session.graph) dev_summary_writer.add_graph(session.graph) print('Training and evaluating...') start_time = time.time() total_batch = 0 best_acc_val = 0.0 last_improved = 0 require_improvement = 10000 # If more than 1000 steps of performence are not promoted, finish training flag = False for epoch in range(config.num_epochs): print('Epoch:', epoch + 1) batch_train = batch_iter(x_train, y_train, config.batch_size) for x_batch, y_batch in batch_train: feed_dict = feed_data(x_batch, y_batch, config.dropout_keep_prob) # save % 10 if total_batch % config.save_per_batch == 0: s = session.run(train_summary_op, feed_dict=feed_dict) train_summary_writer.add_summary(s, total_batch) # print % 100 if total_batch % config.print_per_batch == 0: # feed_dict[model.keep_prob] = 0.8 loss_train, acc_train = session.run([model.loss, model.acc], feed_dict=feed_dict) y_pred_cls_1,loss_val, acc_val = evaluate(session, x_dev, y_dev) # todo s = session.run(dev_summary_op, feed_dict=feed_dict) dev_summary_writer.add_summary(s, total_batch) if acc_val > best_acc_val: # save best result best_acc_val = acc_val last_improved = total_batch saver.save(sess = session, save_path=checkpoint_prefix, global_step=total_batch) # saver.save(sess=session, save_path=save_path) improved_str = '*' else: improved_str = '' time_dif = get_time_dif(start_time) msg = 'Iter: {0:>6}, Train Loss: {1:>6.2}, Train Acc: {2:>7.2%},' \ + ' Val Loss: {3:>6.2}, Val Acc: {4:>7.2%}, Time: {5} {6}' print(msg.format(total_batch, loss_train, acc_train,loss_val, acc_val, time_dif, improved_str)) session.run(model.optim, feed_dict=feed_dict) # run optim total_batch += 1 if total_batch - last_improved > require_improvement: # early stop print("No optimization for a long time, auto-stopping...") flag = True break if flag: break def test(): start_time = time.time() session = tf.Session() session.run(tf.global_variables_initializer()) saver = tf.train.import_meta_graph(path + '.meta') saver.restore(sess=session, save_path=save_path) print('Testing...') y_pred,loss_test, acc_test = evaluate(session, x_test, y_test) msg = 'Test Loss: {0:>6.2}, Test Acc: {1:>7.2%}' print(msg.format(loss_test, acc_test)) batch_size = 128 data_len = len(x_test) num_batch = int((data_len - 1) / batch_size) + 1 y_pred_cls = np.zeros(shape=len(x_test), dtype=np.int32).reshape(-1,1) for i in range(num_batch): start_id = i * batch_size end_id = min((i + 1) * batch_size, data_len) feed_dict = { model.input_x: x_test[start_id:end_id], model.keep_prob: 1.0 } y_pred_cls[start_id:end_id] = session.run(model.y_pred_cls, feed_dict=feed_dict) if __name__ == '__main__': print('Configuring RNN model...') config = TRNNConfig() model = TextRNN(config,embedded_mat) option='train' if option == 'train': train() else: test()
inference:
print("test begining...") from tensorflow.python.tools.inspect_checkpoint import print_tensors_in_checkpoint_file ndim = 36 graph = tf.Graph() with graph.as_default(): os.environ["CUDA_VISIBLE_DEVICES"] = "2" config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.4 config.gpu_options.allow_growth = True sess = tf.Session(config=config) sess.run(tf.global_variables_initializer()) with sess.as_default(): saver = tf.train.import_meta_graph("runs/textrnn/1563958299/checkpoints/model-5000.meta") saver.restore(sess=sess, save_path="runs/textrnn/1563958299/checkpoints/model-5000") print_tensors_in_checkpoint_file(save_path,"embedding/W",True) new_weights = graph.get_operation_by_name("embedding/W").outputs[0] embedding_W = sess.run(new_weights) feed_dict = {model.input_x: testx,model.keep_prob: 1.0} # logits = scores.eval(feed_dict=feed_dict) logits = session.run(model.logits, feed_dict=feed_dict) y_pred_cls = session.run(model.y_pred_cls, feed_dict=feed_dict) print('logits:',logits) print('pred:',y_pred_cls)
