NLP学习(2)----文本分类模型
实战:https://github.com/jiangxinyang227/NLP-Project
一、简介:
1、传统的文本分类方法:【人工特征工程+浅层分类模型】
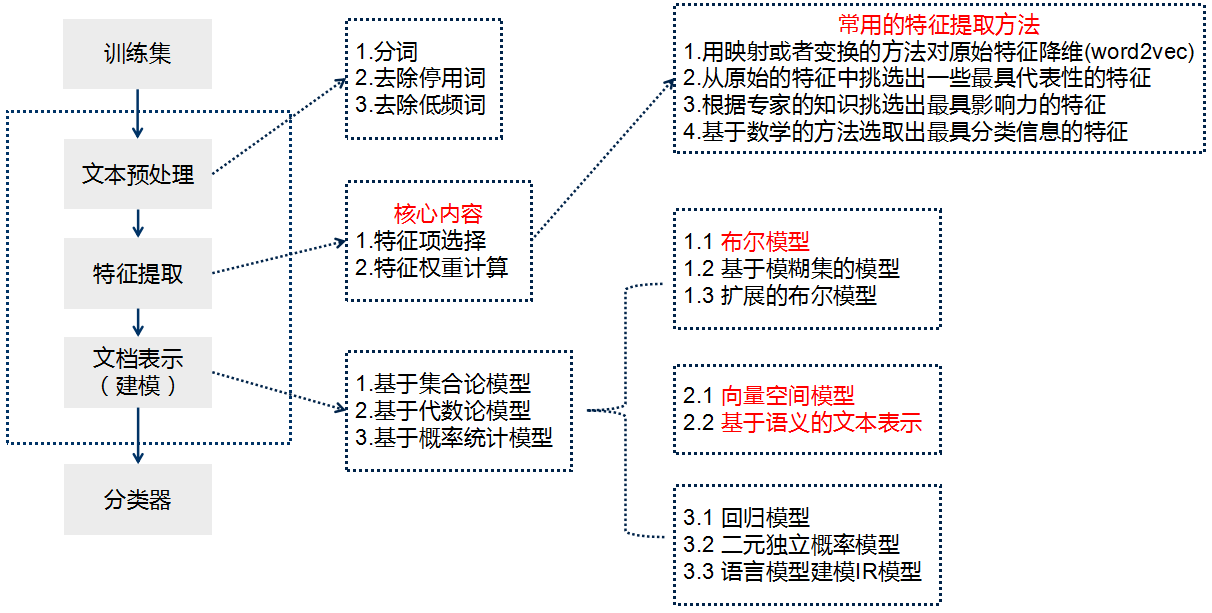
(1)文本预处理:
①(中文)
文本分词
-
- 正向/逆向/双向最大匹配;
- 基于理解的句法和语义分析消歧;
- 基于统计的互信息/CRF方法;
- WordEmbedding + Bi-LSTM+CRF方法
去停用词:维护一个停用词表
(2)特征提取
特征选择的基本思路是根据某个评价指标独立的对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。常用的评价有文档频率、互信息、信息增益、χ²统计量等。
特征权重主要是经典的TF-IDF方法及其扩展方法,主要思路是一个词的重要度与在类别内的词频成正比,与所有类别出现的次数成反比。
当选用数学方法进行特征提取时,决定文本特征提取效果的最主要因素是评估函数的质量。常见的评估函数主要有如下方法:
2.1 TF-IDF
TF:词频,计算该词描述文档内容的能力 IDF:逆向文档频率,用于计算该词区分文档的的能力
-
- 思想:一个词的重要程度与在类别内的词频成正比,与所有类别出现的次数成反比。
- 评价:a.TF-IDF的精度并不是特别高。b.TF-IDF并没有体现出单词的位置信息。
2.2 词频(TF)
词频是一个词在文档中出现的次数。通过词频进行特征选择就是将词频小于某一阈值的词删除。
-
- 思想:出现频次低的词对过滤的影响也比较小。
- 评价:有时频次低的词汇含有更多有效的信息,因此不宜大幅删减词汇。
2.3 文档频次法(DF)
它指的是在整个数据集中,有多少个文本包含这个单词。
-
- 思想:计算每个特征的文档频次,并根据阈值去除文档频次特别低(没有代表性)和特别高的特征(没有区分度)
- 评价:简单、计算量小、速度快、时间复杂度和文本数量成线性关系,非常适合超大规模文本数据集的特征选择。
2.4 互信息方法(Mutual information)
互信息用于衡量某个词与类别之间的统计独立关系,在过滤问题中用于度量特征对于主题的区分度。
-
- 思想:在某个特定类别出现频率高,在其他类别出现频率低的词汇与该类的互信息较大。
- 评价:优点-不需要对特征词和类别之间关系的性质做任何假设。缺点-得分非常容易受词边缘概率的影响。实验结果表明互信息分类效果通常比较差。
2.5 期望交叉熵
交叉熵反映了文本类别的概率分布和在出现了某个特定词的条件下文本类别的概率分布之间的距离 思想:特征词t 的交叉熵越大, 对文本类别分布的影响也越大。 评价:熵的特征选择不考虑单词未发生的情况,效果要优于信息增益。
2.6 信息增益
信息增益是信息论中的一个重要概念, 它表示了某一个特征项的存在与否对类别预测的影响。
-
- 思想:某个特征项的信息增益值越大, 贡献越大, 对分类也越重要。
- 评价:信息增益表现出的分类性能偏低,因为信息增益考虑了文本特征未发生的情况。 2.4.7 卡方校验
它指的是在整个数据集中,有多少个文本包含这个单词。
-
- 思想:在指定类别文本中出现频率高的词条与在其他类别文本中出现频率比较高的词条,对判定文档是否属于该类别都是很有帮助的.
- 评价:卡方校验特征选择算法的准确率、分类效果受训练集影响较小,结果稳定。对存在类别交叉现象的文本进行分类时,性能优于其他类别的分类方法。
2.7 其他评估函数
-
- 二次信息熵(QEMI)
- 文本证据权(The weight of Evidence for Text)
- 优势率(Odds Ratio)
- 遗传算法(Genetic Algorithm)
- 主成分分析(PCA)
- 模拟退火算法(Simulating Anneal)
- N-Gram算法
2.9 传统特征提取方法总结
传统的特征选择方法大多采用以上特征评估函数进行特征权重的计算。
但由于这些评估函数都是基于统计学原理的,因此一个缺点就是需要一个庞大的训练集,才能获得对分类起关键作用的特征,这需要消耗大量的人力和物力。
另外基于评估函数的特征提取方法建立在特征独立的假设基础上,但在实际中这个假设很难成立。
2.10 通过映射和变化来进行特征提取
特征选择也可以通过用映射或变换的方法把原始特征变换为较少的新特征 传统的特征提取降维方法,会损失部分文档信息,以DF为例,它会剔除低频词汇,而很多情况下这部分词汇可能包含较多信息,对于分类的重要性比较大。 如何解决传统特征提取方法的缺点:找到频率低词汇的相似高频词,例如:在介绍月亮的古诗中,玉兔和婵娟是低频词,我们可以用高频词月亮来代替,这无疑会提升分类系统对文本的理解深度。词向量能够有效的表示词语之间的相似度。
(3)文本表示
文本表示的目的是把文本预处理后的转换成计算机可理解的方式,是决定文本分类质量最重要的部分。传统做法常用词袋模型(BOW, Bag Of Words)或向量空间模型(Vector Space Model),最大的不足是忽略文本上下文关系,每个词之间彼此独立,并且无法表征语义信息。词袋模型的示例如下:
( 0, 0, 0, 0, .... , 1, ... 0, 0, 0, 0)一般来说词库量至少都是百万级别,因此词袋模型有个两个最大的问题:高纬度、高稀疏性。词袋模型是向量空间模型的基础,因此向量空间模型通过特征项选择降低维度,通过特征权重计算增加稠密性。
基于语义的文本表示:传统做法在文本表示方面除了向量空间模型,还有基于语义的文本表示方法,比如LDA主题模型、LSI/PLSI概率潜在语义索引等方法,一般认为这些方法得到的文本表示可以认为文档的深层表示,而word embedding文本分布式表示方法则是深度学习方法的重要基础,下文会展现。
(4)分类器:
贝叶斯、KNN、SVM、最大熵
2、基于深度学习的文本分类方法:
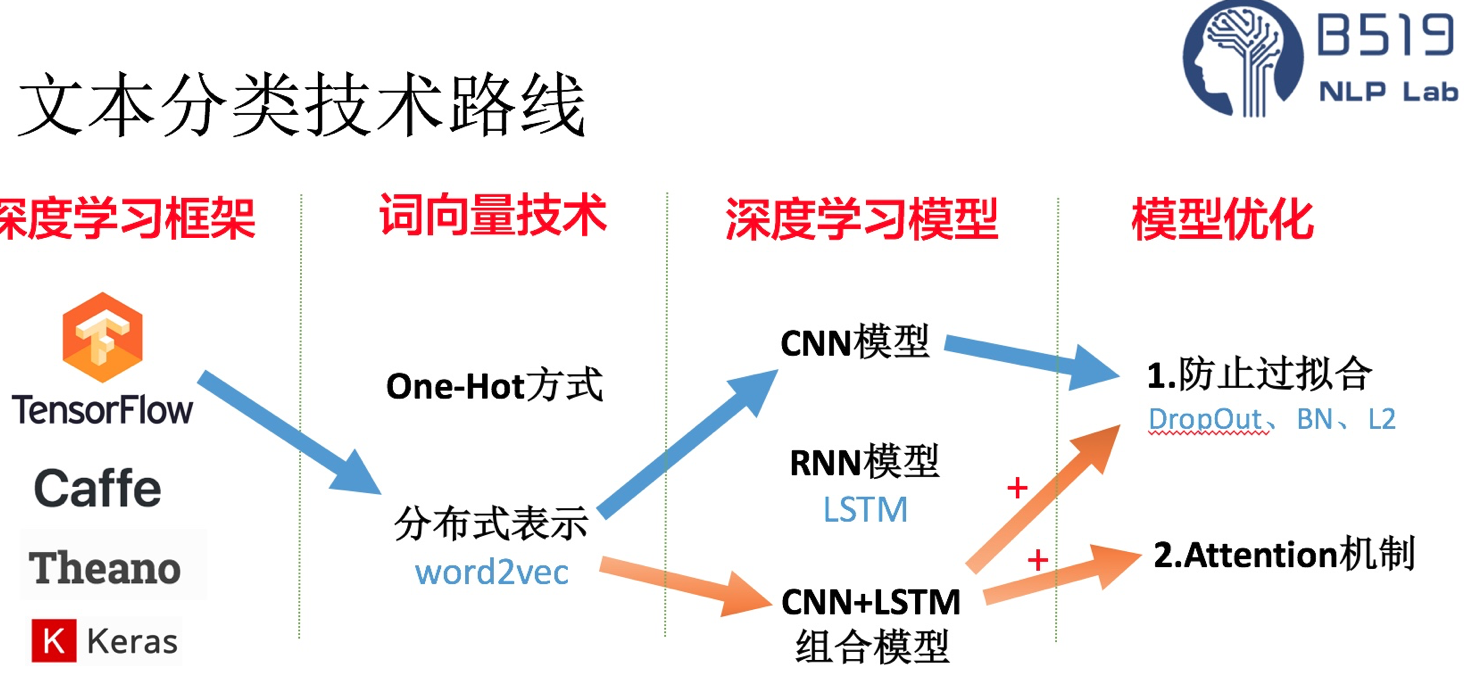
文本分类应用场景:情感分类、检测垃圾邮件、用户query的自动标签(query意图识别)、文章分类话题
文本数据准备:X为文本,Y为0,1标签。
文本预处理:(英文)词干提取、词性还原、大小写转换、词向量化,(中文)分词、去停用词、词性标注、词向量化
特征处理:https://www.jiqizhixin.com/articles/2018-10-29-10
文本向量化:TF-IDF、BOW、One-hot、分布式表示方式(word2vec、glove)等。
文本分类模型:(传统)贝叶斯、SVM、随机森林、KNN等,(深度学习)textCNN、FastText、RNN、LSTM、HAN、TextRNN(Bi-directional RNN)、TextRNN + Attention、TextRCNN(TextRNN + CNN)
业务例子:
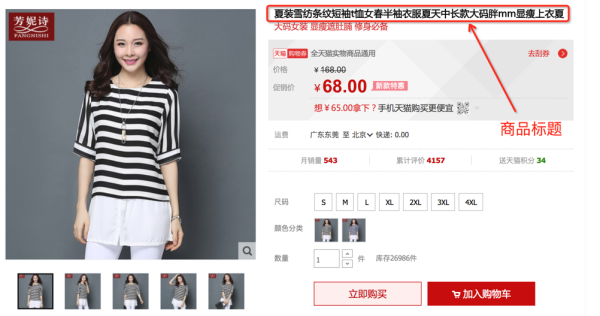
问题描述:淘宝商品的一个典型的例子见下图,图中商品的标题是“夏装雪纺条纹短袖t恤女春半袖衣服夏天中长款大码胖mm显瘦上衣夏”。淘宝网后台是通过树形的多层的类目体系管理商品的,覆盖叶子类目数量达上万个,商品量也是10亿量级,我们是任务是根据商品标题预测其所在叶子类目,示例中商品归属的类目为“女装/女士精品>>蕾丝衫/雪纺衫”。很显然,这是一个非常典型的短文本多分类问题。接下来分别会介绍下文本分类传统和深度学习的做法,最后简单梳理下实践的经验。
二、fasttext模型
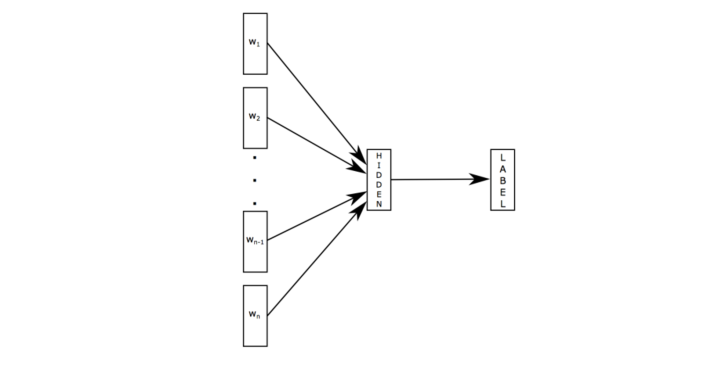
原理是把句子中所有的词向量进行平均(某种意义上可以理解为只有一个avg pooling特殊CNN),然后直接接 softmax 层。其实文章也加入了一些 n-gram 特征的 trick 来捕获局部序列信息。文章倒没太多信息量,算是“水文”吧,带来的思考是文本分类问题是有一些“线性”问题的部分[from项亮],也就是说不必做过多的非线性转换、特征组合即可捕获很多分类信息,因此有些任务即便简单的模型便可以搞定了。
实战:https://blog.csdn.net/Kaiyuan_sjtu/article/details/84404290
三、textCNN模型:
本篇文章的题图选用的就是14年这篇文章提出的TextCNN的结构(见下图)。fastText 中的网络结果是完全没有考虑词序信息的,而它用的 n-gram 特征 trick 恰恰说明了局部序列信息的重要意义。卷积神经网络(CNN Convolutional Neural Network)最初在图像领域取得了巨大成功,CNN原理就不讲了,核心点在于可以捕捉局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息。
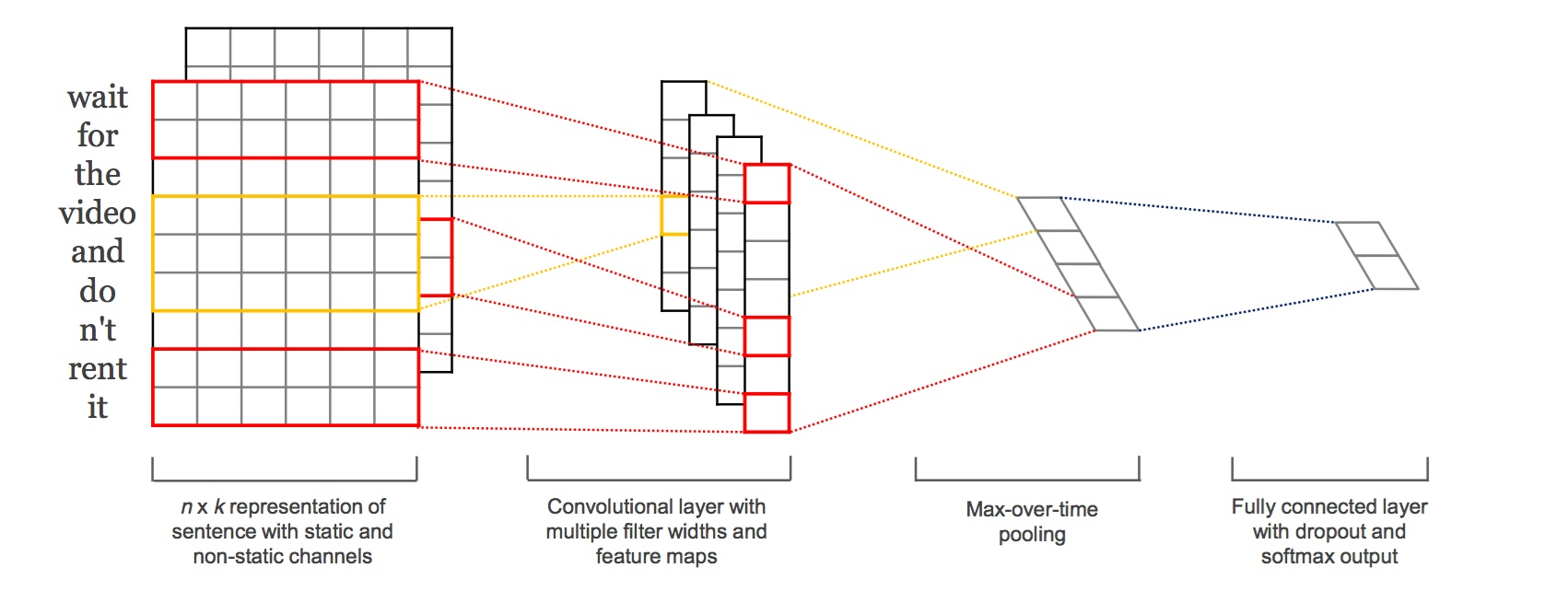
TextCNN的详细过程原理图见下:
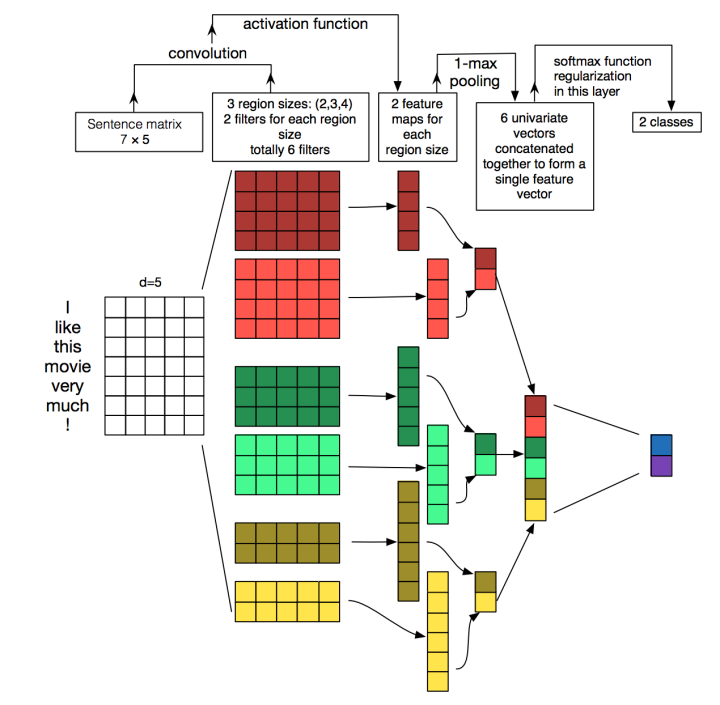
TextCNN详细过程:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点了。然后经过有 filter_size=(2,3,4) 的一维卷积层,每个filter_size 有两个输出 channel。第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了,最后接一层全连接的 softmax 层,输出每个类别的概率。
特征:这里的特征就是词向量,有静态(static)和非静态(non-static)方式。static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。non-static则是在训练过程中更新词向量。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛,当然如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
通道(Channels):图像中可以利用 (R, G, B) 作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
Pooling层:利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。比如在情感分析场景,举个例子:
“ 我觉得这个地方景色还不错,但是人也实在太多了 ”
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
四、TextCNN + Attention(Attention-based Convolutional Neural Networks for Sentence Classification)
https://blog.csdn.net/tcx1992/article/details/83344272
https://zhuanlan.zhihu.com/p/24890809
https://blog.csdn.net/liuchonge/article/details/69587681
Attention Pooling-based Convolutional Neural Network for Sentence Modeling
BasicCNN难以捕获长期的上下文信息和非连续词之间的相关性。这种弱点在dependency-based CNN中得以部分克服,但在实际使用中它总是需要额外的资源来获得良好的依赖树,例如口语处理。 一种新的基于注意力机制的CNN可以用来缓解这个问题。
图1展示了ATT-CNN模型的架构。 如图1所示,在输入层和卷积层之间引入了attention层。 具体地,attention层是为每个单词创建上下文向量。 上下文向量与单词向量拼接,作为单词新的表示,将其输入到卷积层。 直观来看,一对彼此远离的词往往联系较少。 因此,可以考虑将距离衰减添加到注意机制中。
attention机制的思想是在导出xxi的上下文向量gigi时学习将注意力集中在特定的重要单词上。 图1中的红色矩形表示gigi。注意机制是另外的MLP,与ATT-CNN的所有其他组件共同训练。 当预测句子类别时,该机制确定哪些单词应该比句子上的其他单词更受关注。 打分后的单词以加权和组合:
gi=∑j

四、TextRNN(Bi-direction RNN,双向LSTM)
尽管TextCNN能够在很多任务里面能有不错的表现,但CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。CNN本质是做文本的特征表达工作,而自然语言处理中更常用的是递归神经网络(RNN, Recurrent Neural Network),能够更好的表达上下文信息。具体在文本分类任务中,Bi-directional RNN(实际使用的是双向LSTM)从某种意义上可以理解为可以捕获变长且双向的的 "n-gram" 信息。
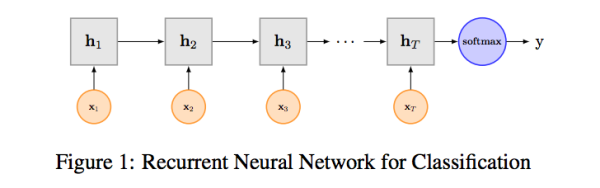
RNN算是在自然语言处理领域非常一个标配网络了,在序列标注/命名体识别/seq2seq模型等很多场景都有应用,Recurrent Neural Network for Text Classification with Multi-Task Learning文中介绍了RNN用于分类问题的设计,下图LSTM用于网络结构原理示意图,示例中的是利用最后一个词的结果直接接全连接层softmax输出了
五、TextRNN + Attention
CNN和RNN用在文本分类任务中尽管效果显著,但都有一个不足的地方就是不够直观,可解释性不好,特别是在分析badcase时候感受尤其深刻。而注意力(Attention)机制是自然语言处理领域一个常用的建模长时间记忆机制,能够很直观的给出每个词对结果的贡献,基本成了Seq2Seq模型的标配了。实际上文本分类从某种意义上也可以理解为一种特殊的Seq2Seq,所以考虑把Attention机制引入近来,研究了下学术界果然有类似做法。
Attention机制介绍:
详细介绍Attention恐怕需要一小篇文章的篇幅,感兴趣的可参考14年这篇paper NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE。
详细介绍Attention恐怕需要一小篇文章的篇幅,感兴趣的可参考14年这篇paper NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE。
以机器翻译为例简单介绍下,下图中 是源语言的一个词,
是目标语言的一个词,机器翻译的任务就是给定源序列得到目标序列。翻译
的过程产生取决于上一个词
和源语言的词的表示
(
的 bi-RNN 模型的表示),而每个词所占的权重是不一样的。比如源语言是中文 “我 / 是 / 中国人” 目标语言 “i / am / Chinese”,翻译出“Chinese”时候显然取决于“中国人”,而与“我 / 是”基本无关。下图公式,
则是翻译英文第
个词时,中文第
个词的贡献,也就是注意力。显然在翻译“Chinese”时,“中国人”的注意力值非常大。
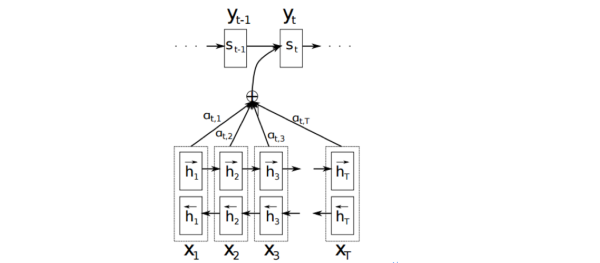
Attention的核心point是在翻译每个目标词(或 预测商品标题文本所属类别)所用的上下文是不同的,这样的考虑显然是更合理的。
TextRNN + Attention 模型:
我们参考了这篇文章 Hierarchical Attention Networks for Document Classification,下图是模型的网络结构图,它一方面用层次化的结构保留了文档的结构,另一方面在word-level和sentence-level。淘宝标题场景只需要 word-level 这一层的 Attention 即可。
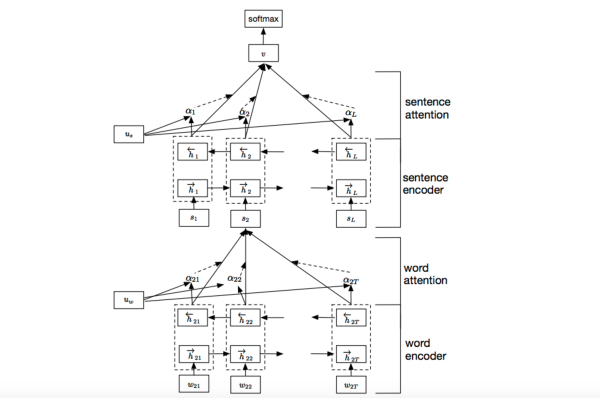
加入Attention之后最大的好处自然是能够直观的解释各个句子和词对分类类别的重要性。
六、TextRCNN(TextRNN + CNN)
我们参考的是中科院15年发表在AAAI上的这篇文章 Recurrent Convolutional Neural Networks for Text Classification 的结构:
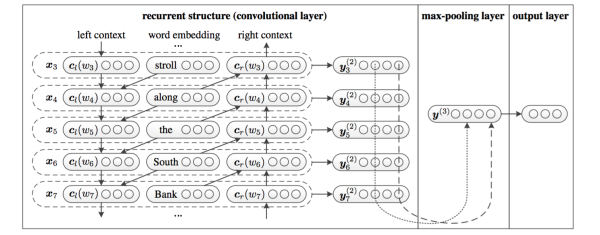
利用前向和后向RNN得到每个词的前向和后向上下文的表示:
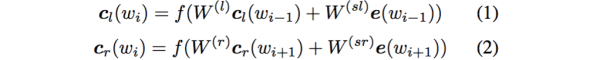
这样词的表示就变成词向量和前向后向上下文向量concat起来的形式了,即:
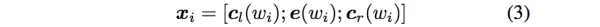
最后再接跟TextCNN相同卷积层,pooling层即可,唯一不同的是卷积层 filter_size = 1就可以了,不再需要更大 filter_size 获得更大视野,这里词的表示也可以只用双向RNN输出。
七、HAN(Hierarchy Attention Network)
相较于TextCNN,HAN最大的进步在于完全保留了文章的结构信息,并且特别难能可贵的是,基于attention结构有很强的解释性。
他的结构如下图所示:
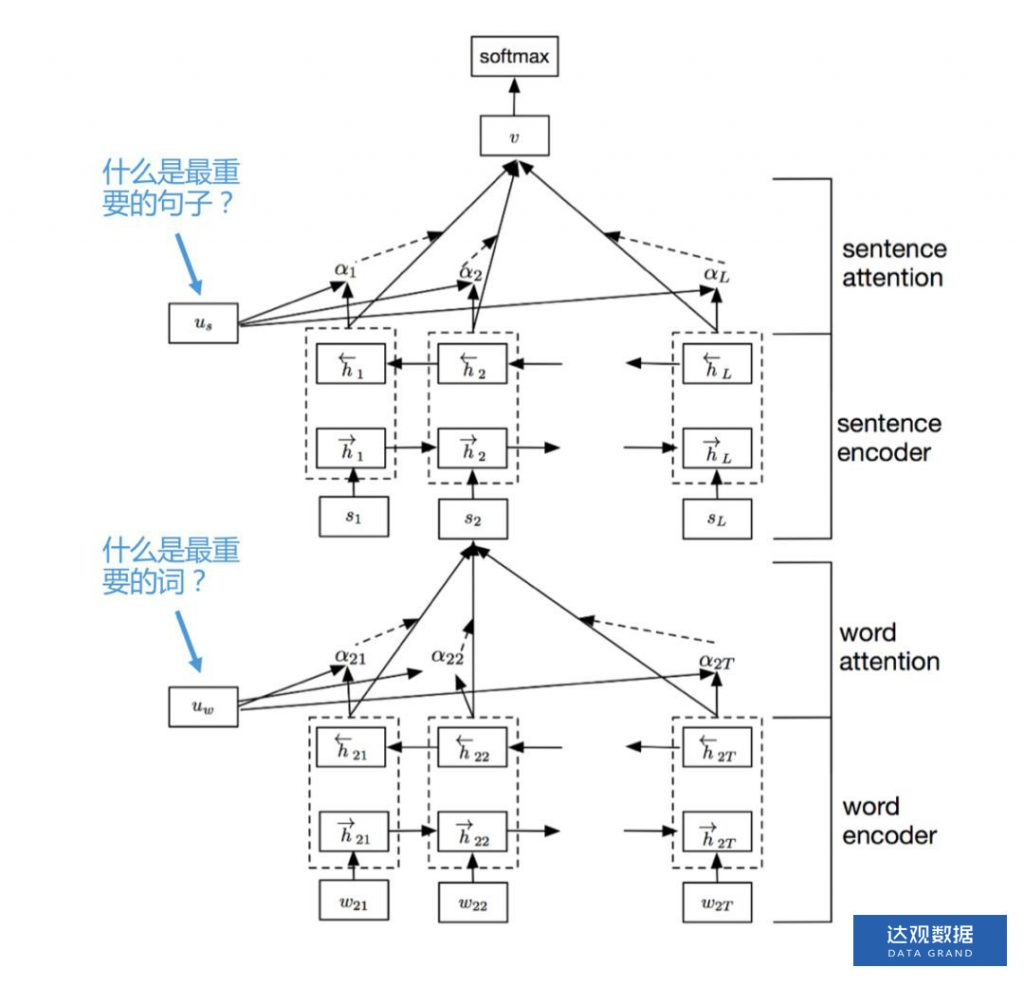
输入词向量序列后,通过词级别的Bi-GRU后,每个词都会有一个对应的Bi-GRU输出的隐向量h,再通过uw向量与每个时间步的h向量点积得到attention权重,然后把h序列做一个根据attention权重的加权和,得到句子summary向量s2,每个句子再通过同样的Bi-GRU结构再加attention得到最终输出的文档特征向量v向量,然后v向量通过后级dense层再加分类器得到最终的文本分类结果。模型结构非常符合人的从词->句子->再到篇章的理解过程。
最重要的是该模型在提供了更好的分类精度的情况下,可视化效果非常好。同时在调参过程中,我们发现attention部分对于模型的表达能力影响非常大,整个模型在所有位置调整L2-Loss对模型表达能力带来的影响远不如在两处attention的地方大,这同时也能解释为什么可视化效果比较好,因为attention对于模型的输出贡献很大,而attention又恰恰是可以可视化的。
下面我们来看一下他在法律领域罪名预测任务上的可视化效果。下面的可视化的结果并不是找了极少数效果好的,而是大部分情况下模型的可视化能够解释他的输出。需要注意的是,此处为了让不太重要句子中相对重要的词并不完全不可见,词的亮度=sqrt(句子权重)*词权重。
在非常长的文本中,HAN觉得中间那些完全是废话,不如那句“公诉机关认为”有用,就放弃了。

图5 HAN attention可视化1
如下图所示,模型虽然在文本第二行中看到了窃取的字样,但是他认为这个案件中主要的事件是抢劫,这就是保留文本结构的好处。

图6 HAN attention可视化2
可以看到并不是所有的深度学习模型都是不可以理解的,这种可解释性也会给实际应用带来很多帮助。
八、 DPCNN
上面的几个模型,论神经网络的层数,都不深,大致就只有2~3层左右。大家都知道何凯明大神的ResNet是CV中的里程碑,15年参加ImageNet的时候top-5误差率相较于上一年的冠军GoogleNet直接降低了将近一半,证明了网络的深度是非常重要的。
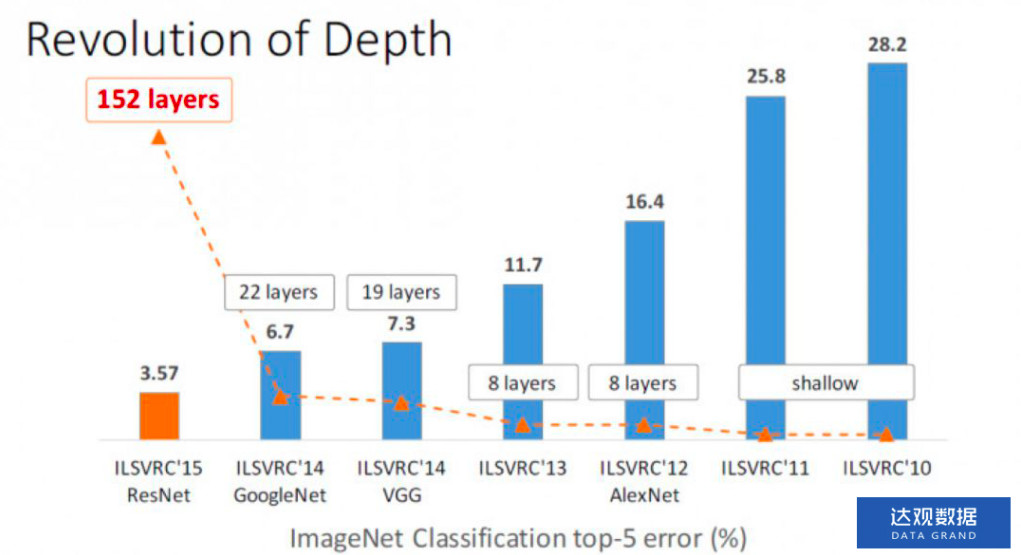
图7 ImageNet历年冠军
那么问题来了,在文本分类领域网络深度提升会带来分类精度的大幅提升吗?我们在一些比较复杂的任务中,以及数据量比较大(百万级)的情况下有提升,但不是ResNet那种决定性的提升。
DPCNN的主要结构如下图所示:
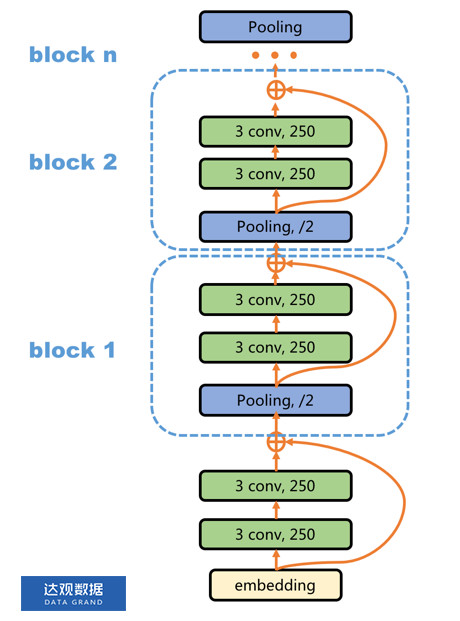
图8 DPCNN结构
从词向量开始(本文的重点在于模型的大结构,因此不去详解文中的region embedding部分,直接将整个部分认为是一种词向量的输出。)先做了两次宽度为3,filter数量为250个的卷积,然后开始做两两相邻的max-pooling,假设输入句子长度padding到1024个词,那么在头两个卷积完成以后句子长度仍然为1024。在block 1的pooling位置,max pooling的width=3,stride=2,也即序列中相邻的3个时间步中每一维feature map取这三个位置中最大的一个留下,也即位置0,1,2中取一个最大值,然后,移动2个时间步,在2,3,4时间步中取一次max,那么pooling输出的序列长度就是511。
后面以此类推,序列长度是呈指数级下降的,这也是文章名字Deep Pyramid的由来。然后通过两个卷积的非线性变换,提取更深层次的特征,再在输出的地方叠加上未经过两次卷积的quick connection通路(ResNet中使得深层网络更容易训练的关键)。因为每个block中的max pooling只是相邻的两个位置做max-pooling,所以每次丢失的结构信息很少,后面的卷积层又能提取更加抽象的特征出来。所以最终模型可以在不丢失太多结构信息的情况下,同时又做了比较深层的非线性变换。
我们实际测试中在非线性度要求比较高的分类任务中DPCNN会比HAN精度高,并且由于他是基于CNN的,训练速度比基于GRU的HAN也要快很多。
参考:
https://python.ctolib.com/km1994-sentiment_analysis_keras.html
https://cloud.tencent.com/developer/article/1335257
https://blog.csdn.net/u014248127/article/details/80774668
http://www.yidianzixun.com/article/0KNcfHXG
https://www.cnblogs.com/skykill/p/6785882.html
https://www.jianshu.com/p/7f35a4b33f45
https://cloud.tencent.com/developer/article/1005817
一文读懂深度学习:https://www.infoq.cn/article/swMEuzh-c96KgUdEGXgN
文本分类概述:https://blog.csdn.net/u014248127/article/details/80774668
实战:http://www.yidianzixun.com/article/0KNcfHXG
https://cloud.tencent.com/developer/article/1335257
CNN实战中文二分类:https://github.com/x-hacker/CNN_ChineseTextBinaryClassify/tree/master/CNN_%E4%B8%AD%E6%96%87%E4%BA%8C%E5%88%86%E7%B1%BB
https://github.com/Edward1Chou/Textclassification
文本分类的一些trip:https://www.zhihu.com/question/265357659 http://wulc.me/2019/02/06/%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB%E4%B8%AD%E7%9A%84%E4%B8%80%E4%BA%9B%E7%BB%8F%E9%AA%8C%E5%92%8C%20tricks/

