parse_url绕过
parse_url介绍
parse_url ( string $url [, int $component = -1 ] ) : mixed
此函数返回一个关联数组,包含现有 URL 的各种组成部分。如果缺少了其中的某一个,则不会为这个组成部分创建数组项。组成部分为:
- scheme – 如 http
- host 域名
- port 端口
- pass
- path 路径
- query – 在问号 ? 之后
- fragment – 在散列符号 # 之后
此函数并 不 意味着给定的 URL 是合法的,它只是将上方列表中的各部分分开。parse_url() 可接受不完整的 URL,并尽量将其解析正确。
注: 此函数对相对路径的 URL 不起作用。
DEMO
<?php
$url = "http://www.baidu.com/suning?v=1&k=2#id";
echo $url.'</br>';
$parts = parse_url($url);
var_dump($parts);
?>

这是正常的拆分,假设传入的是 http://www.baidu.com@2333.com/suning?v=1&k=2#id
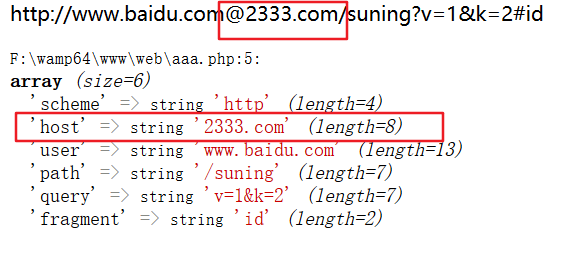
发现host变成了2333.com,这样host就可控了
DEMO
<?php $data = parse_url($_SERVER['REQUEST_URI']); var_dump($data); $filter=array("aaa","qqqq"); foreach($filter as $f) { if(preg_match("/".$f."/i", $data['query'])) { die("Attack Detected"); } } ?>
当我们输入参数输入aaa的时候,会被拦截
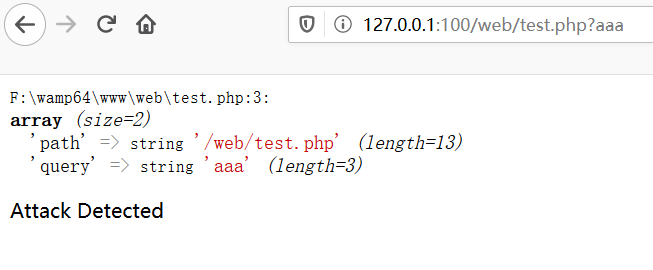
但是当在路径前输入在路径前多输入//,会使这个函数失效,这样就绕过了检测

多加了一个/ 导致 严重不合格的 URL,parse_url() 返回FALSE 这个是通用的绕过方法 (CTF常用 返回值False 用于逃逸判断)
参考链接
https://blog.csdn.net/q1352483315/article/details/89672426?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1
如有错误和不足请指出,谢谢

