面试常见问题
基础部分
1.看代码
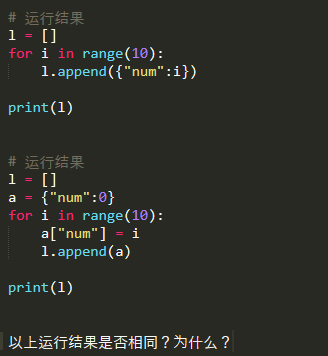
解释:


字典是可变对象,在下方的 l.append(a)的操作中是把字典 a 的引用传到列表 l 中,当后续操作修改 a[‘num’]的值的时候,l 中的值也会跟着改变,相当于浅拷贝。
2. 4G 内存怎么读取一个 5G 的数据?
方法一:
可以通过生成器,分多次读取,每次读取数量相对少的数据(比如 500MB)进行处理,处理结束后在读取后面的 500MB 的数据。
方法二:
可以通过 linux 命令 split 切割成小文件,然后再对数据进行处理,此方法效率比较高。可以按照行数切割,可以按照文件大小切割。
3.输入某年某月某日,判断这一天是这一年的第几天?
import datetime def day_of_year(): year = input("年份:") month = input("月份:") day = input("天:") date1 = datetime.date(year=int(year),month=int(month),day=int(day)) date2 = datetime.date(year=int(year),month=1,day=1) return (date1-date2).days + 1 print(day_of_year())
4. os.path 和 sys.path 分别代表什么
os.path 主要是用于对系统路径文件的操作。
sys.path 主要是对 Python 解释器的系统环境参数的操作(动态的改变 Python 解释器搜索路径)。
5.模块和包的区别
python中,模块是搭建程序的一种方式,每一个Python代码文件都是一个模块,并可以引用其他模块,比如对象和属性
一个包含许多 Python 代码的文件夹是一个包。一个包可以包含模块和子文件夹
6.对字典d = {'a':24,'g':52,'i':12,'k':33}的values进行排序
d = {'a':24,'g':52,'i':12,'k':33}
temp = sorted(d.items(),key=lambda x:x[1])
print(temp)
from operator import itemgetter
sorted_ed = sorted(d.items(), key=itemgetter(1))
print(sorted_ed)
7.分析下列三个函数执行效率大小

利用程序分析包分析代码性能
import random import cProfile lIn = [random.random() for i in range(100**3)] # 随机赋值,值越大越明显 cProfile.run('f1(lIn)') cProfile.run('f2(lIn)') cProfile.run('f3(lIn)')
利用装饰器分析执行性能
import time def outter(func): def inner(*args): beign = time.time() func(*args) use_time = time.time()-beign print(use_time) return inner @outter # f1=outter(f1)(lIn) def f1(lIn): l1 = sorted(lIn) l2 = [i for i in l1 if i<0.5] return [i*i for i in l2] @outter def f2(lIn): l1 = [i for i in lIn if i<0.5] l2 = sorted(l1) return [i*i for i in l2] @outter def f3(lIn): l1 = [i*i for i in lIn] l2 = sorted(l1) return [i for i in l2 if i<(0.5**0.5)] import random temp = [random.random() for i in range(100000)] f1(temp) f2(temp) f3(temp)
8.python内存管理机制
内存管理机制:引用计数,垃圾回收,内存池
应用计数制:python内部使用应用计数,来保持追踪内存中的对象,所有对象都有引用计数;
垃圾回收机制:当一个对象的引用计数为0的时候,它将会被垃圾回收机制处理;
内存池机制:python提供了对内存的垃圾收集机制,它将不用的内存放到内存池而不是返回给操作系统
垃圾回收机制:引用计数,标记清除,分代回收
9.filter、map、reduce的作用?
1:Map:主要包括两个参数,函数和列表。 将函数的结果以列表的形式返回。
会将一个函数映射到一个输入列表的所有元素。
规范:map(lambda x: x * x,[y for y in range(3)])
大多数时候,我们要把列表中的所有元素一个个的传递给一个函数,并收集输出。
2:Filter:包括两个参数function,list。根据function的返回值是True, 来过滤list的参数中的项,最后返回结果。
过滤列表中的元素,并且返回一个由所有符合要求的元素构成的列表。
符合要求 即函数映射到该元素时返回值为True.
3: Reduce:从列表中取出头两个元素并传递到一个二元函数中去, 求出值,再添加到序列中继续循环下一个值,直到最后一个值。
当需要对一个列表进行计算并返回结果时,reduce是一个很有用的函数。
例:当你需要计算一个整数列表的乘积时。通常在python中,你可能会使用基本的for循环来完成任务。
10.什么是可变,不可变类型?
# 可变不可变指的是内存中的值是否可以被改变 # 不可变类型指的是对象所在内存块里面的值不可以改变,如字符串,元祖 # 可变类型则是可以改变,有列表,字典
11. 1,2,3,4,5可以组成多少个互不相同且不重复的三位数?
使用python内置的排列组合函数itertools(不放回抽样排列)
product 笛卡尔积 (有放回抽样排列)
permutations 排列 (不放回抽样排列)
combinations 组合,没有重复 (不放回抽样组合)
combinations_with_replacement 组合,有重复 (有放回抽样组合)
import itertools goal = list(itertools.permutations('12345',3)) print(goal) # 返回所有结果
12.metaclass的作用:

设计模式相关
1.手写一个单例模式,或者通过装饰器实现一个单例模式
2.单例模式应用场景有哪些?
资源共享的情况下,避免由于资源操作时导致的性能或损耗等。如日志文件,应用配置
控制资源的情况下,方便资源之间的互相通信。如线程池等
3.函数装饰器的作用?
让其他函数在不需要做任何代码的变动的前提下增加额外的功能
如:插入日志、性能测试、事务处理、缓存、权限的校验等场景
4.谈谈对面向对象的理解?
面向对象是相对于面向过程而言的
面向过程是一种基于功能分析的,以算法为中心的程序设计方法
面向对象是一种基于结构,以数据为中心的程序设计思想
网络编程相关
1. 谈谈你对多进程,多线程,以及协程的理解,项目是否用?
进程:一个运行的程序(代码)就是一个进程,进程是系统资源分配的最小单位。进程都拥有自己独立的内存空间,之间数据不共享,开销大
线程:调度执行的最小单位,也叫执行路径,不能独立存在,一个进程至少有一个线程,叫主线程。多个线程之间共享内存(数据共享,全局变量共享),从而极大提高了程序的运行效率
协程:用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快
2.什么是线程竞争?
线程是非独立的,同一个进程里线程是数据共享的,当各个线程访问数据资源时会出现竞争状态即:数据几乎同步会被多个线程占用,造成数据混乱 ,即所谓的线程不安全那么解决多线程竞争利用了锁。
锁的好处:确保某段共享数据资源只能由一个线程从头到尾完整执行
锁的坏处:阻止了线程并发执行。包含锁定某段代码实际只能以单线程模式执行,效率降低
锁的致命问题:死锁
3.死锁概念?
若干子线程在系统资源竞争时,都在等待对方对某部分资源解除占用状态,结果是谁也不愿先解锁,互相干等着,程序无法执行下去,这就是死锁。
4.GIL锁?
GIL 锁:全局解释器锁(只在 cpython 里才有)
作用:限制多线程同时执行,保证同一时间只有一个线程执行,所以 cpython 里的多线程其实是伪多线程
5.进程和线程的使用场景?
多进程适合在 CPU 密集型操作(cpu 操作指令比较多,如位数多的浮点运算)。
多线程适合在 IO 密集型操作(读写数据操作较多的,比如爬虫)。
6.请简述浏览器是如何获取一枚网页的?
1.在用户输入目的 URL 后,浏览器先向 DNS 服务器发起域名解析请求
2.在获取了对应的 IP 后向服务器发送请求数据包
3.服务器接收到请求数据后查询服务器上对应的页面,并将找到的页面代码回复给客户端
4.客户端接收到页面源代码后,检查页面代码中引用的其他资源,并再次向服务器请求该资源
5.在资源接收完成后,客户端浏览器按照页面代码将页面渲染输出显示在显示器上
7.cookie和session的区别?
1.cookie 数据存放在客户的浏览器上,session 数据放在服务器上
2.cookie 不是很安全,别人可以分析存放在本地的 cookie 并进行 cookie 欺骗考虑到安全应当使用session
3.session 会在一定时间内保存在服务器上。当访问增多,会比较占用服务器的性能考虑到减轻服务器性能方面,应当使用 cookie
4.单个 cookie 保存的数据不能超过 4K,很多浏览器都限制一个站点最多保存 20 个 cookie
5.将登陆信息等重要信息存放为 SESSION 其他信息如果需要保留,可以放在 cookie 中
8.get和post请求区别?
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST么有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中。
如果我告诉你,你死记硬背的这些所谓“标准答案”不是面试官想要的,你肯定不服,首先从安全性讲,get和post都一样,没啥所谓的哪个更安全
get请求参数在url地址上,直接暴露,post请求的参数放body部分,按F12也直接暴露了,所以没啥安全性可言
“GET参数通过URL传递,POST放在Request body中”这个其实也不准,post请求也可以没body,也可以在url传递呢?
如果我告诉你get请求和post请求本质上没区别,你肯定不信!
GET和POST有一个重大区别,简单的说:
GET产生一个TCP数据包;POST产生两个TCP数据包。
长的说:
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
详情可以参考这篇《GET和POST两种基本请求方法的区别 》
9.说说 HTTP 和 HTTPS 区别?
HTTP 协议传输的数据都是未加密的,也就是明文的,因此使用 HTTP 协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了 SSL(Secure Sockets Layer)协议用于对 HTTP 协议传输的数据进行加密,从而就诞生了 HTTPS。简单来说,HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,要比 http 协议安全。
主要区别:
1.https 协议需要到 ca 申请证书,一般免费证书较少,因而需要一定费用。
2.http 是超文本传输协议,信息是明文传输,https 则是具有安全性的 ssl 加密传输协议。
3.http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
4.http 的连接很简单,是无状态的;HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全。
10.HTTP请求报文与响应报文格式
请求报文包含三部分:
a、请求行:包含请求方法、URI、HTTP版本信息
b、请求头部(headers)字段
c、请求内容实体(body)
响应报文包含三部分:
a、状态行:包含HTTP版本、状态码、状态码的原因短语
b、响应头部(headers)字段
c、响应内容(body)实体
11.什么是DNS?
域名解析服务。将主机名转换为IP地址。如将http://www.cnblogs.com/主机名转换为IP地址:211.137.51.78
12.什么是Http协议无状态协议?怎么解决Http协议无状态协议?
(1)、无状态协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息
(2)、无状态协议解决办法: 通过1、Cookie 2、通过Session会话保存。
13.HTTP状态码
- 200 请求已成功,请求所希望的响应头或数据体将随此响应返回。
- 201 请求已经被实现,而且有一个新的资源已经依据请求的需要而建立,且其 URI 已经随Location 头信息返回
- 202 服务器已接受请求,但尚未处理
- 301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
- 302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
- 303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
- 304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
- 305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
-
307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
- 401 当前请求需要用户验证。如果当前请求已经包含了 Authorization 证书,那么401响应代表着服务器验证已经拒绝了那些证书
- 403 服务器已经理解请求,但是拒绝执行它。与401响应不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交
- 404 请求失败,请求所希望得到的资源未被在服务器上发现
- 500 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器的程序码出错时出现。
- 501 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
- 502 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
-
503 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复。
代码优化
1.优化算法时间复杂度
2.减少冗余数据
3.合理使用深浅拷贝
4.使用dict和set查找元素
5.合理使用生成器和yield
6.循环的优化
7.优化多个判断表达式的顺序
8.使用join合并迭代器中的字符串
9.使用合适的格式化字符串方式
10.不借用中间变量交换连个两个变量的值
数据库相关
数据库优化方案:
1、创建数据表时把固定长度的放在前面()
2、将固定数据放入内存: 例如:choice字段 (django中有用到,数字1、2、3…… 对应相应内容)
3、char 和 varchar 的区别(char可变, varchar不可变 )
4、联合索引遵循最左前缀(从最左侧开始检索)
5、避免使用 select *
6、读写分离 - 实现:两台服务器同步数据
- 利用数据库的主从分离:主,用于删除、修改、更新;从,用于查; 读写分离:利用数据库的主从进行分离:主,用于删除、修改更新;从,用于查
7、分库 - 当数据库中的表太多,将某些表分到不同的数据库,例如:1W张表时
- 代价:连表查询
8、分表
- 水平分表:将某些列拆分到另外一张表,例如:博客+博客详情
- 垂直分表:讲些历史信息分到另外一张表中,例如:支付宝账单
9、加缓存
- 利用redis、memcache (常用数据放到缓存里,提高取数据速度)
如果只想获取一条数据:
- select * from tb where name=‘alex’ limit 1
▍1、什么是Python?为什么它会如此流行?
Python是一种解释的、高级的、通用的编程语言。
Python的设计理念是通过使用必要的空格与空行,增强代码的可读性。
它之所以受欢迎,就是因为它具有简单易用的语法。
▍2、为什么Python执行速度慢,我们如何改进它?
Python代码执行缓慢的原因,是因为它是一种解释型语言。它的代码在运行时进行解释,而不是编译为本地语言。
为了提高Python代码的速度,我们可以使用CPython、Numba,或者我们也可以对代码进行一些修改。
1. 减少内存占用。
2. 使用内置函数和库。
3. 将计算移到循环外。
4. 保持小的代码库。
5. 避免不必要的循环
▍3、Python有什么特点?
1. 易于编码
2. 免费和开源语言
3. 高级语言
4. 易于调试
5. OOPS支持
6. 大量的标准库和第三方模块
7. 可扩展性(我们可以用C或C++编写Python代码)
8. 用户友好的数据结构
▍4、Python有哪些应用?
1. Web开发
2. 桌面GUI开发
3. 人工智能和机器学习
4. 软件开发
5. 业务应用程序开发
6. 基于控制台的应用程序
7. 软件测试
8. Web自动化
9. 基于音频或视频的应用程序
10. 图像处理应用程序
▍5、Python的局限性?
1. 速度
2. 移动开发
3. 内存消耗(与其他语言相比非常高)
4. 两个版本的不兼容(2,3)
5. 运行错误(需要更多测试,并且错误仅在运行时显示)
6. 简单性
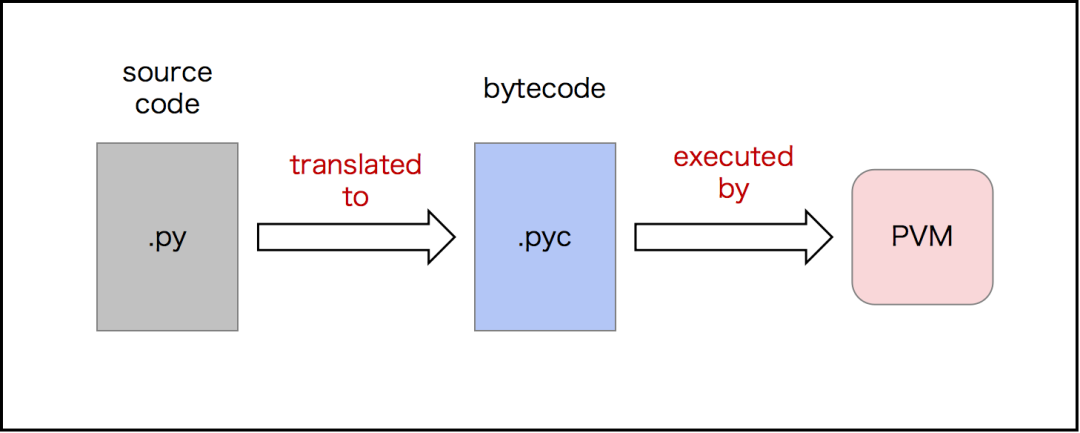
▍6、Python代码是如何执行的?
首先,解释器读取Python代码并检查是否有语法或格式错误。
如果发现错误,则暂停执行。如果没有发现错误,则解释器会将Python代码转换为等效形式或字节代码。
然后将字节码发送到Python虚拟机(PVM),这里Python代码将被执行,如果发现任何错误,则暂停执行,否则结果将显示在输出窗口中。
▍7、如何在Python中管理内存?
Python内存由Python的私有headspace管理。
所有的Python对象和数据结构都位于一个私有堆中。私用堆的分配由Python内存管理器负责。
Python还内置了一个的垃圾收集器,可以回收未使用的内存并释放内存,使其可用于headspace。
▍8、解释Python的内置数据结构?
Python中主要有四种类型的数据结构。
列表:列表是从整数到字符串甚至另一个列表的异构数据项的集合。列表是可变的。列表完成了其他语言中大多数集合数据结构的工作。列表在[ ]方括号中定义。
例如:a = [1,2,3,4]
集合:集合是唯一元素的无序集合。集合运算如联合|,交集&和差异,可以应用于集合。{}用于表示一个集合。
例如:a = {1,2,3,4}
元组:Python元组的工作方式与Python列表完全相同,只是它们是不可变的。()用于定义元组。
例如:a =(1,2,3,4)
字典:字典是键值对的集合。它类似于其他语言中的hash map。在字典里,键是唯一且不可变的对象。
例如:a = {'number':[1,2,3,4]}
▍9、解释//、%、* *运算符?
//(Floor Division)-这是一个除法运算符,它返回除法的整数部分。
例如:5 // 2 = 2
%(模数)-返回除法的余数。
例如:5 % 2 = 1
**(幂)-它对运算符执行指数计算。a ** b表示a的b次方。
例如:5 ** 2 = 25、5 ** 3 = 125
▍10、Python中的单引号和双引号有什么区别?
在Python中使用单引号(' ')或双引号(" ")是没有区别的,都可以用来表示一个字符串。
这两种通用的表达方式,除了可以简化程序员的开发,避免出错之外,还有一种好处,就是可以减少转义字符的使用,使程序看起来更简洁,更清晰。
▍11、Python中append,insert和extend的区别?
append:在列表末尾添加新元素。 insert:在列表的特定位置添加元素。 extend:通过添加新列表来扩展列表。 numbers = [1,2,3,4,5] numbers.append(6) print(numbers) >[1,2,3,4,5,6] ## insert(position,value) numbers.insert(2,7) print(numbers) >[1,2,7,3,4,5,6] numbers.extend([7,8,9]) print(numbers) >[1,2,7,3,4,5,6,7,8,9] numbers.append([4,5]) >[1,2,7,3,4,5,6,7,8,9,[4,5]]
▍12、break、continue、pass是什么?
break:在满足条件时,它将导致程序退出循环。
continue:将返回到循环的开头,它使程序在当前循环迭代中的跳过所有剩余语句。
pass:使程序传递所有剩余语句而不执行。
▍13、区分Python中的remove,del和pop?
remove:将删除列表中的第一个匹配值,它以值作为参数。
del:使用索引删除元素,它不返回任何值。
pop:将删除列表中顶部的元素,并返回列表的顶部元素。
numbers = [1,2,3,4,5] numbers.remove(5) > [1,2,3,4] del numbers[0] >[2,3,4] numbers.pop() >4
▍14、什么是switch语句。如何在Python中创建switch语句?
switch语句是实现多分支选择功能,根据列表值测试变量。
switch语句中的每个值都被称为一个case。
在Python中,没有内置switch函数,但是我们可以创建一个自定义的switch语句。
switcher = {
1: "January",
2: "February",
3: "March",
4: "April",
5: "May",
6: "June",
7: "July",
8: "August",
9: "September",
10: "October",
11: "November",
12: "December"
}
month = int(input())
print(switcher.get(month))
> 3
march
▍15、举例说明Python中的range函数?
range:range函数返回从起点到终点的一系列序列。
range(start, end, step),第三个参数是用于定义范围内的步数。
# number for i in range(5): print(i) > 0,1,2,3,4 # (start, end) for i in range(1, 5): print(i) > 1,2,3,4 # (start, end, step) for i in range(0, 5, 2): print(i) >0,2,4
▍16、==和is的区别是?
==比较两个对象或值的相等性。
is运算符用于检查两个对象是否属于同一内存对象。
lst1 = [1,2,3] lst2 = [1,2,3] lst1 == lst2 >True lst1 is lst2 >False
▍17、如何更改列表的数据类型?
要将列表的数据类型进行更改,可以使用tuple()或者set()。
lst = [1,2,3,4,2]
# 更改为集合
set(lst) ## {1,2,3,4}
# 更改为元组
tuple(lst) ## (1,2,3,4,2)
▍18、Python中注释代码的方法有哪些?
在Python中,我们可以通过下面两种方式进行注释。
1. 三引号''',用于多行注释。
2. 单井号#,用于单行注释。
▍19、!=和is not运算符的区别?
!=如果两个变量或对象的值不相等,则返回true。
is not是用来检查两个对象是否属于同一内存对象。
lst1 = [1,2,3,4]
lst2 = [1,2,3,4]
lst1 != lst2
>False
lst1 is not lst2
>True
▍20、Python是否有main函数?
是的,它有的。只要我们运行Python脚本,它就会自动执行。
▍21、什么是lambda函数?
Lambda函数是不带名称的单行函数,可以具有n个参数,但只能有一个表达式。也称为匿名函数。
a = lambda x, y:x + y
print(a(5, 6))
> 11
▍22、iterables和iterators之间的区别?
iterable:可迭代是一个对象,可以对其进行迭代。在可迭代的情况下,整个数据一次存储在内存中。
iterators:迭代器是用来在对象上迭代的对象。它只在被调用时被初始化或存储在内存中。迭代器使用next从对象中取出元素。
# List is an iterable lst = [1,2,3,4,5] for i in lst: print(i) # iterator lst1 = iter(lst) next(lst1) >1 next(lst1) >2 for i in lst1: print(i) >3,4,5
▍23、Python中的Map Function是什么?
map函数在对可迭代对象的每一项应用特定函数后,会返回map对象。
▍24、解释Python中的Filter?
过滤器函数,根据某些条件从可迭代对象中筛选值。
# iterable
lst = [1,2,3,4,5,6,7,8,9,10]
def even(num):
if num%2==0:
return num
# filter all even numbers
list(filter(even,lst))
---------------------------------------------
[2, 4, 6, 8, 10]
▍25、解释Python中reduce函数的用法?
reduce()函数接受一个函数和一个序列,并在计算后返回数值。
from functools import reduce
a = lambda x,y:x+y
print(reduce(a,[1,2,3,4]))
> 10
▍26、什么是pickling和unpickling?
pickling是将Python对象(甚至是Python代码),转换为字符串的过程。
unpickling是将字符串,转换为原来对象的逆过程。
▍27、解释*args和**kwargs?
*args,是当我们不确定要传递给函数参数的数量时使用的。
def add(* num): sum = 0 for val in num: sum = val + sum print(sum) add(4,5) add(7,4,6) add(10,34,23) --------------------- 9 17 67
**kwargs,是当我们想将字典作为参数传递给函数时使用的。
def intro(**data): print("\nData type of argument:",type(data)) for key, value in data.items(): print("{} is {}".format(key,value)) intro(name="alex",Age=22, Phone=1234567890) intro(name="louis",Email="a@gmail.com",Country="Wakanda", Age=25) -------------------------------------------------------------- Data type of argument: <class 'dict'> name is alex Age is 22 Phone is 1234567890 Data type of argument: <class 'dict'> name is louis Email is a@gmail.com Country is Wakanda Age is 25
▍28、解释re模块的split()、sub()、subn()方法?
split():只要模式匹配,此方法就会拆分字符串。
sub():此方法用于将字符串中的某些模式替换为其他字符串或序列。
subn():和sub()很相似,不同之处在于它返回一个元组,将总替换计数和新字符串作为输出。
import re string = "There are two ball in the basket 101" re.split("\W+",string) --------------------------------------- ['There', 'are', 'two', 'ball', 'in', 'the', 'basket', '101'] re.sub("[^A-Za-z]"," ",string) ---------------------------------------- 'There are two ball in the basket' re.subn("[^A-Za-z]"," ",string) ----------------------------------------- ('There are two ball in the basket', 10)
▍29、Python中的生成器是什么?
生成器(generator)的定义与普通函数类似,生成器使用yield关键字生成值。
如果一个函数包含yield关键字,那么该函数将自动成为一个生成器。
# A program to demonstrate the use of generator object with next() A generator function def Fun(): yield 1 yield 2 yield 3 # x is a generator object x = Fun() print(next(x)) ----------------------------- 1 print(next(x)) ----------------------------- 2
▍30、如何使用索引来反转Python中的字符串?
string = 'hello'
string[::-1]
>'olleh'
▍31、类和对象有什么区别?
类(Class)被视为对象的蓝图。类中的第一行字符串称为doc字符串,包含该类的简短描述。
在Python中,使用class关键字可以创建了一个类。一个类包含变量和成员组合,称为类成员。
对象(Object)是真实存在的实体。在Python中为类创建一个对象,我们可以使用obj = CLASS_NAME()
例如:obj = num()
使用类的对象,我们可以访问类的所有成员,并对其进行操作。
class Person: """ This is a Person Class""" # varable age = 10 def greets(self): print('Hello') # object obj = Person() print(obj.greet) ---------------------------------------- Hello
▍32、你对Python类中的self有什么了解?
self表示类的实例。
通过使用self关键字,我们可以在Python中访问类的属性和方法。
注意,在类的函数当中,必须使用self,因为类中没有用于声明变量的显式语法。
▍33、_init_在Python中有什么用?
“__init__”是Python类中的保留方法。
它被称为构造函数,每当执行代码时都会自动调用它,它主要用于初始化类的所有变量。
▍34、解释一下Python中的继承?
继承(inheritance)允许一个类获取另一个类的所有成员和属性。继承提供代码可重用性,可以更轻松地创建和维护应用程序。
被继承的类称为超类,而继承的类称为派生类/子类。
▍35、Python中OOPS是什么?
面向对象编程,抽象(Abstraction)、封装(Encapsulation)、继承(Inheritance)、多态(Polymorphism)
▍36、什么是抽象?
抽象(Abstraction)是将一个对象的本质或必要特征向外界展示,并隐藏所有其他无关信息的过程。
▍37、什么是封装?
封装(Encapsulation)意味着将数据和成员函数包装在一起成为一个单元。
它还实现了数据隐藏的概念。
▍38、什么是多态?
多态(Polymorphism)的意思是「许多形式」。
子类可以定义自己的独特行为,并且仍然共享其父类/基类的相同功能或行为。
▍39、什么是Python中的猴子补丁?
猴子补丁(monkey patching),是指在运行时动态修改类或模块。
from SomeOtherProduct.SomeModule import SomeClass
def speak(self):
return "Hello!"
SomeClass.speak = speak
▍40、Python支持多重继承吗?
Python可以支持多重继承。多重继承意味着,一个类可以从多个父类派生。
▍41、Python中使用的zip函数是什么?
zip函数获取可迭代对象,将它们聚合到一个元组中,然后返回结果。
zip()函数的语法是zip(*iterables)
numbers = [1, 2, 3]
string = ['one', 'two', 'three']
result = zip(numbers,string)
print(set(result))
-------------------------------------
{(3, 'three'), (2, 'two'), (1, 'one')}
▍42、解释Python中map()函数?
map()函数将给定函数应用于可迭代对象(列表、元组等),然后返回结果(map对象)。
我们还可以在map()函数中,同时传递多个可迭代对象。
numbers = (1, 2, 3, 4)
result = map(lambda x: x + x, numbers)
print(list(result))
▍43、Python中的装饰器是什么?
装饰器(Decorator)是Python中一个有趣的功能。
它用于向现有代码添加功能。这也称为元编程,因为程序的一部分在编译时会尝试修改程序的另一部分。
def addition(func): def inner(a,b): print("numbers are",a,"and",b) return func(a,b) return inner @addition def add(a,b): print(a+b) add(5,6) --------------------------------- numbers are 5 and 6 sum: 11
▍44、编写程序,查找文本文件中最长的单词
def longest_word(filename): with open(filename, 'r') as infile: words = infile.read().split() max_len = len(max(words, key=len)) return [word for word in words if len(word) == max_len] print(longest_word('test.txt')) ---------------------------------------------------- ['comprehensions']
▍45、编写程序,检查序列是否为回文
a = input("Enter The sequence") ispalindrome = a == a[::-1] ispalindrome >True
▍46、编写程序,打印斐波那契数列的前十项
fibo = [0,1] [fibo.append(fibo[-2]+fibo[-1]) for i in range(8)] fibo > [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
▍47、编写程序,计算文件中单词的出现频率
from collections import Counter def word_count(fname): with open(fname) as f: return Counter(f.read().split()) print(word_count("test.txt"))
▍48、编写程序,输出给定序列中的所有质数
lower = int(input("Enter the lower range:")) upper = int(input("Enter the upper range:")) list(filter(lambda x:all(x % y != 0 for y in range(2, x)), range(lower, upper))) ------------------------------------------------- Enter the lower range:10 Enter the upper range:50 [11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
▍49、编写程序,检查数字是否为Armstrong
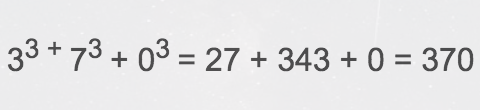
将每个数字依次分离,并累加其立方(位数)。
最后,如果发现总和等于原始数,则称为阿姆斯特朗数(Armstrong)。
num = int(input("Enter the number:\n")) order = len(str(num)) sum = 0 temp = num while temp > 0: digit = temp % 10 sum += digit ** order temp //= 10 if num == sum: print(num,"is an Armstrong number") else: print(num,"is not an Armstrong number")
▍50、用一行Python代码,从给定列表中取出所有的偶数和奇数
a = [1,2,3,4,5,6,7,8,9,10] odd, even = [el for el in a if el % 2==1], [el for el in a if el % 2==0] print(odd,even) > ([1, 3, 5, 7, 9], [2, 4, 6, 8, 10])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号