
【译】DeepSeek的模型分析
原作:阿尔贝托·罗梅罗

与 o1 相比,R1 的表现如何?
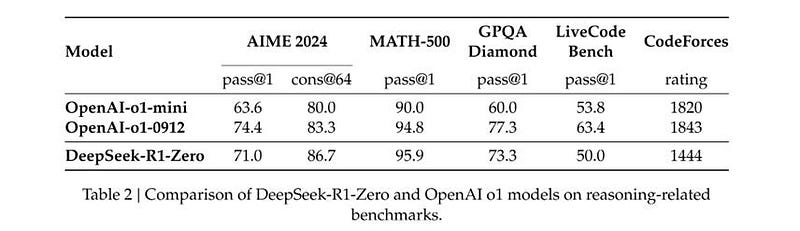
DeepSeek 在六个相关基准(如 GPQA Diamond 和 SWE-bench Verified)以及其他替代测试(如 Codeforces 和 AIME)上对 R1 和 o1 进行了一对一比较。列表中遗漏了 ARC-AGI 和 FrontierMath,但考虑到 OpenAI 存在“不公平”的优势,我理解其他实验室可能会选择忽略这些测试。
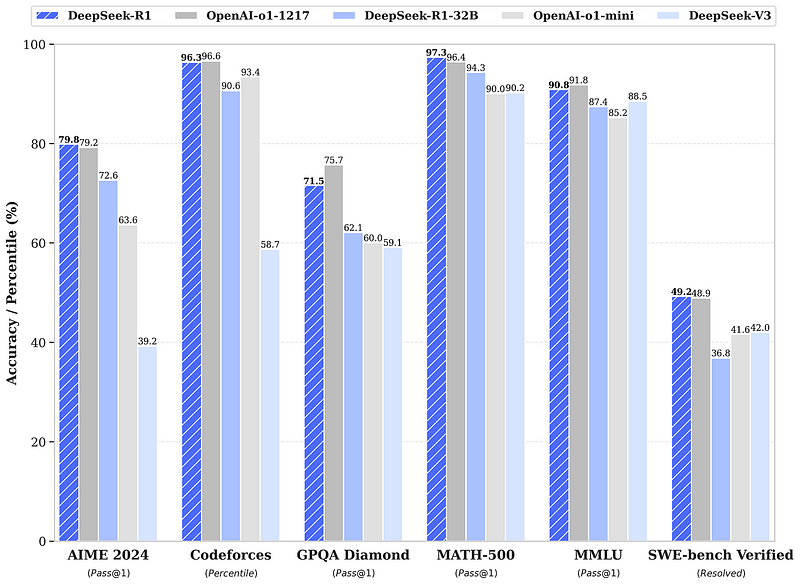
R1 和 o1 在评估中基本上是相同的模型,最大的差异在于 GPQA Diamond(71.5%对 75.7%)上的 4 个百分点差距。为了进行比较,以下是 o1 与 GPT-4o(OpenAI 的最佳非推理模型)在三个基准测试上的表现(Anthropic 的 Claude 3.5 和 Google DeepMind 的 Gemini 2.0 与 GPT-4o 相当):
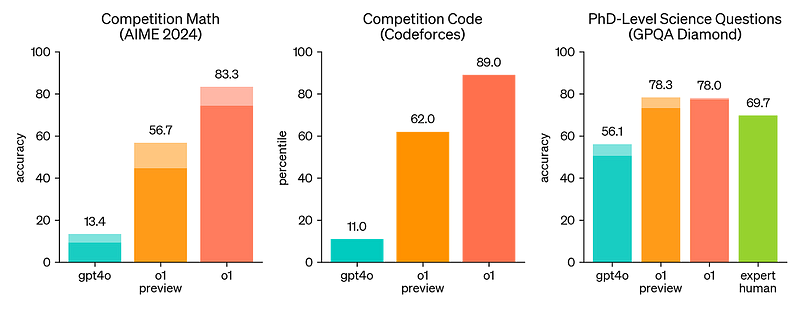
在 Codeforces(编程)上,R1 与 GPT-4o 之间差距达 85%,AIME(数学)为 75%,GPQA Diamond(科学)为 15%。简言之,DeepSeek 打造出的模型与 OpenAI 的顶级模型相当,在美国实验室中也处于领先地位(值得一提的是,OpenAI 已宣布推出性能更优的 o3,但尚未开始在未来几个月内全面推广)。DeepSeek 稳居领奖台,开源 R1 更是将奖金拱手相让。
好的,让我们来聊聊他们还提供了哪些内容,因为 R1 只是 DeepSeek 发布的八个开源模型之一。还有 R1-Zero,这将会带来很多讨论话题。R1 和 R1-Zero 的不同之处在于,后者在训练后期并没有依赖人工标注数据进行指导。换句话说,DeepSeek 让它自行探索推理的方法。关于这一点,我们稍后会详细说明。
然后,还有另外六个模型,它们是通过在 R1 蒸馏数据上训练较弱的基础模型(Qwen 和 Llama)创建的。对于那些不知道的人来说,蒸馏是一个大型强大模型使用合成数据“教导”一个较小、功能较弱的模型的过程。蒸馏是我关于 GPT-5 的推测文章的核心。R1 蒸馏模型比原始模型好得多这一事实进一步证明了我的假设:GPT-5 是存在的,并且正在内部用于蒸馏。以下是六个蒸馏模型的结果表:
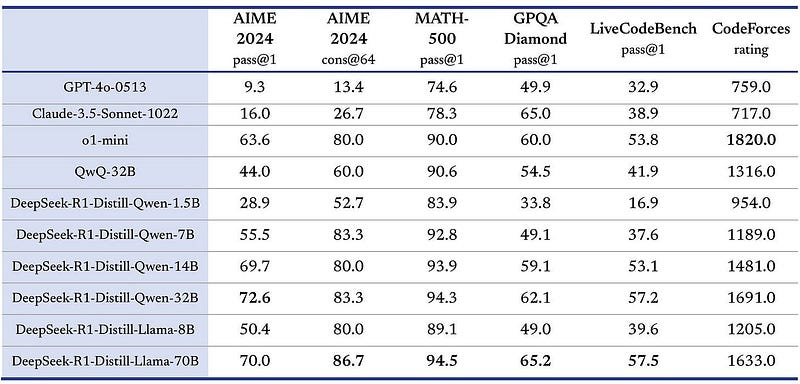
当一家 AI 公司推出多个模型时,往往是最强大的模型成为焦点。让我来解释一下这背后的含义:一个 14 亿参数的 R1 蒸馏 Qwen-14B 模型——比 2020 年的 GPT-3 小 12 倍——其性能与 OpenAI 的 o1-mini 相当,甚至优于 GPT-4o 或 Claude Sonnet 3.5 等顶级非推理模型。这真是令人惊叹。蒸馏技术对弱模型的提升如此显著,以至于再进行后训练已经没有必要了。直接挖掘你的大型模型即可,而且这样做不会增加推理成本。
讨论成本时,DeepSeek 似乎以 5-10%的成本建成了 R1(这已经是对 OpenAI 的输入输出定价非常宽容了)。这就像是以 50 美元的价格从小米或华为买到一部类似谷歌像素或苹果 iPhone 的手机,而原价超过 1000 美元,功能和质量却一模一样。这是怎么做到的?他们是在亏本经营吗?他们是否找到了让这些模型如此便宜的方法,而 OpenAI 和谷歌却视而不见?他们是不是在效仿 Meta 的做法,将模型变成一种商品?疑问重重,OpenAI 可能更倾向于封闭式的问题。
总结一下:R1 是一个顶尖的推理模型,开源,能够将弱模型提炼成强大的模型。成本仅为同类模型的几分之一。而且它源自中国。令人惊叹。
如果我要写一篇关于 OpenAI 模型的文章,我就会在这里结束,因为他们只提供演示和基准测试。但 DeepSeek 还发布了一份详细的技术报告,而 OpenAI、谷歌和 Anthropic 都没有这样做过。那么我们的朋友究竟是谁呢?一个中国公司竟然在做 OpenAI 被赋予去做的工作,这真是让人忍俊不禁。不过,玩笑就到这里吧。现在是时候打开这篇论文了。这是一份非常珍贵的文件。让我们来看看我觉得最有趣的部分。
如果人工智能不再需要我们人类,那会怎样?
我们已经见识过 R1 的出色之处。那么 R1-Zero 又如何呢?DeepSeek 对 R1 和 R1-Zero 的处理方式,让人想起 DeepMind 对待 AlphaGo 和 AlphaGo Zero 的策略(两者之间有许多相似之处,或许 OpenAI 从未成为 DeepSeek 的灵感来源)。
让我稍微深入一点(不多)来解释 R1 和 R1-Zero 之间的区别。两者都包括一个预训练阶段(大量来自网络的训练数据)和一个后训练阶段。前者是共享的,即 R1 和 R1-Zero 都基于 DeepSeek-V3,而后者是有所不同的。
预训练完成后,R1 接收了一小部分高质量的人类示例(监督微调,SFT)。这通常是人们从基础模型(即开箱即用的 GPT-4)训练聊天模型(ChatGPT)的方式,但数量更多。DeepSeek 希望将 SFT 的使用降到最低。为了提升 R1 的推理能力,他们增加了一层简单的强化学习(RL)。没有使用复杂的技术,如 MCTS 或 PRM(无需查找这些缩写)。此外,他们还允许 R1 在推理阶段进行思考,即现在广为人知的测试时计算(TTC),这是 OpenAI 在 o1-preview 中引入的扩展定律。一旦引入 RL 和 TTC,R1 就与 o1 类似。R1-Zero 与之相同,只是去掉了 SFT。
不用专业术语来说:R1 先是无休止地上网(预训练),接着阅读了由人类编写的推理指南(SFT),最后进行了自我实验(RL+TTC)。而 R1-Zero 则没有阅读任何指南。它在大量网络数据上完成了预训练,随后直接进入了强化学习阶段:“现在自己去学习推理。”仅此而已。
DeepMind 在 2016-2017 年间,从 AlphaGo 发展到 AlphaGo Zero 的过程中采取了类似的做法。AlphaGo 通过掌握规则并从数百万场人类对局中学习来学会下围棋,但一年后,它决定仅凭规则,不依赖任何人类数据来训练 AlphaGo Zero。结果 AlphaGo Zero 击败了 AlphaGo。遗憾的是,开放性推理比围棋更具挑战性;R1-Zero 的表现略逊于 R1,存在一些问题,如可读性不佳(此外,两者在基础模型中仍然高度依赖大量人类生成数据——与能够仅依靠物理定律重建人类文明的 AI 相去甚远)。
这就是 R1 与 R1-Zero 的对比样子:(经过润色)这就是 R1 与 R1-Zero 的对比情况:
然而,R1-Zero 的相对成功仍然令人印象深刻。DeepSeek 对这款模型评价道:
研究发现,强化学习赋予 DeepSeek-R1-Zero 强大的推理能力,无需额外监督微调数据。这一成就引人注目,凸显了该模型仅通过强化学习就能有效学习和泛化的能力。
据我们所知,OpenAI 尚未尝试过这种方法(他们采用的是更复杂的强化学习算法)。以下是与 o1-preview 的对比基准结果,供参考。
但是,假设它表现得更好呢?假设通过向它们展示整个互联网,然后告诉它们用简单的强化学习(RL)来思考,而不使用基于人类数据的强化学习(SFT),就能得到更好的推理模型结果呢?假设——请稍等——甚至不需要预训练阶段呢?我认为在原则上这是可能的(原则上可以从物理定律中重建整个人类文明,但我们不是在这里写阿西莫夫的小说)。
与其向 Zero-type 模型展示数百万个人类语言和推理的例子,不如教它们逻辑、推理、归纳、谬误、认知偏差、科学方法和哲学探究的基本规则,让它们找到人类无法想象出的更优思考方法
没有人能像 AlphaZero 那样下棋。当 DeepMind 展示它时,人类象棋大师们首先将其与其他 AI 引擎如 Stockfish 进行比较。不久,他们便意识到它的风格更接近人类——优雅而独特。我听说有人将 AlphaZero 比作已故的世界象棋冠军米哈伊尔·塔尔:他大胆、富有想象力,经常做出令人意想不到的牺牲,这些牺牲帮助他赢得了许多比赛。
我想象,要为数学、科学和推理构建这样的 AI 程序可能比下棋或围棋更难,但并非不可能:一个超凡脱俗的智能,却又充满人性化的推理机器。这正是 DeepSeek 在 R1-Zero 上所尝试的,几乎做到了。我已经迫不及待地想要知道故事的下一章了。
但让我们再大胆猜测一番,你知道我总是喜欢这样。想象一下,如果零型模型在变得越来越厉害的同时也变得越来越奇怪,那又会是怎样的情景呢?
DeepSeek 在训练 R1-Zero 时发现很难读懂模型的响应。它开始混合语言。这又让我想起了 DeepMind。AlphaGo Zero 学会了比 AlphaGo 更好的下围棋,但在人眼中也更奇怪。最终,AlphaGo 向我们学习,但 AlphaGo Zero 必须通过自我对弈找到自己的方法。它没有我们的数据,所以它没有我们的缺点。更重要的是,它也没有我们的礼貌。
这个问题引发思考:有没有比我们更高效的世界推理方法?更智能的 AI 是否会不仅变得更聪明,而且变得越来越难以被我们解读?
我认为答案是肯定的:随着人工智能变得越来越聪明,它将经历两个不同的阶段。首先,它会不可思议地接近人类的个性,并展现出类似人类的“反思”和“探索解决问题的不同方法”的涌现行为,正如 DeepSeek 研究人员对 R1-Zero 所说。以下是从论文中摘录的一个“啊哈时刻”的例子:

但最终,随着人工智能的智慧超出我们的认知范围,它变得异常神秘;与我们理解的逻辑越来越远,就像 AlphaGo Zero 一样。它宛如一颗在漫长椭圆轨道上运行的彗星,短暂地在我们太阳系中亮相,随后便消失在浩瀚宇宙的深处。
我觉得很难为“人类的方式是最好的思考方式”这一观点辩护。我们只是在应对自身的缺陷(求生存的需求)、局限性(语言的线性特征)和认知盲点(我真的比所有人聪明,还是只是自欺欺人?)或许还有更佳的思考方式。难以理解的异族方法。
也许 OpenAI 不仅因为竞争原因隐藏了 o1 的思考过程,还因为意识到一个令人不安的事实:看到 AI 在句子中间从英语跳到其他语言,再变成符号,最后变成看似乱码,最终给出正确答案,这会让人感到不安;“到底发生了什么?你是怎么找到这个答案的?我完全不明白!!”
相信我,你真的不想窥探超越自己的实体的内心。那样会让你吓得不轻。我现在脊背都在发凉。
IV. 更优的基础模型、模型蒸馏与强化学习取得胜利
无论如何,科幻小说先放一边,还有其他一些东西引起了我的注意。DeepSeek 用简单易懂的语言解释了 R1、R1-Zero 以及精炼模型成功与失败之处。所有秘密都在其中。除了我之前提到的,还有三个结论格外引人注目。
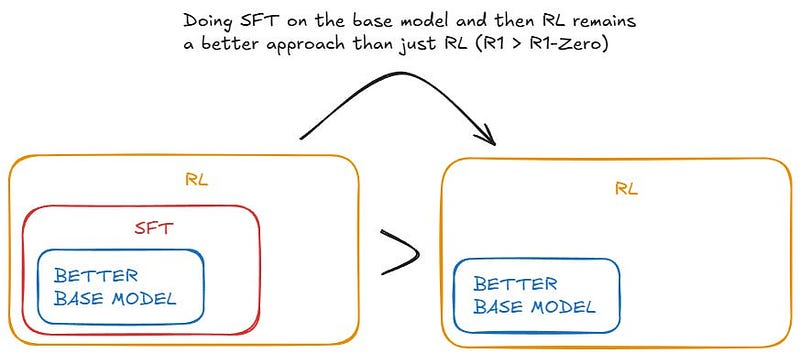
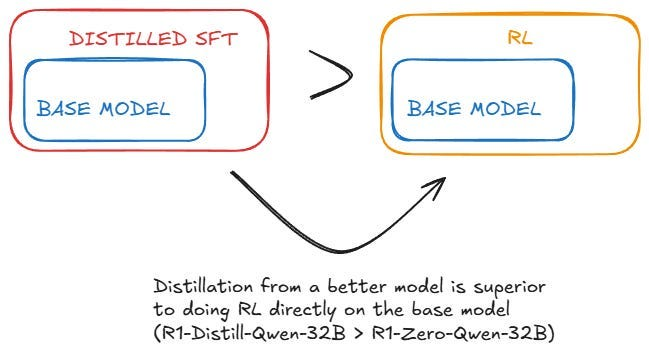
首先,从强大模型中进行蒸馏 SFT 来提升较弱模型的效果,比直接在较弱模型上应用 RL 更有效。换句话说,提升一个较小的、较弱的模型时,不应采用构建较大模型时使用的方法,而应将较大的模型作为指导者:
以 Qwen2.5–32B(Qwen,2024b)为基础模型,直接对 DeepSeek-R1 进行蒸馏优于在其上应用强化学习。这证明了更大基础模型发现的推理模式对于提升推理能力至关重要。将更强大的模型蒸馏成更小的模型能够取得显著效果,而依赖本文所述的规模化强化学习的小型模型则需要庞大的计算资源,甚至可能无法达到蒸馏的效果。
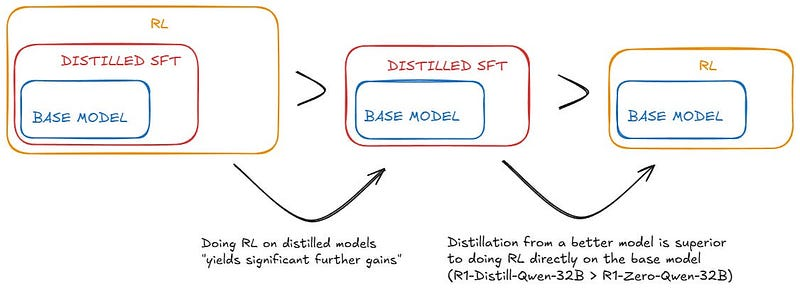
第二个结论是自然而然的延续:在小模型上实施强化学习依然具有价值。
我们发现,对这些模型进行蒸馏后再应用强化学习(RL)可以获得显著的额外收益。我们认为这一点值得进一步研究,因此在此仅展示简单 SFT 蒸馏模型的结果。
他们最终得出结论,要想提升能力底线,仍需持续优化基础模型。R1 和 R1-Zero 均基于 DeepSeek-V3,但最终 DeepSeek 必须训练 V4、V5 等后续版本(这需要投入巨额资金)。同样,仅靠 OpenAI 使用 GPT-5 来不断改进 o 系列是不够的。总有一天,他们必须训练出 GPT-6。
虽然蒸馏策略既经济又有效,但要突破智能的边界,可能还需要更强大的基础模型和更大规模的强化学习。这样的表述更加自然易懂。
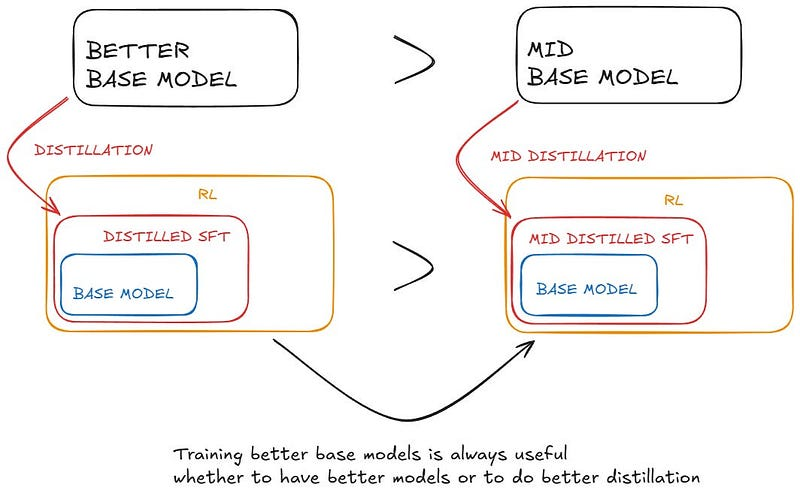
整个故事可以用这张图来概括: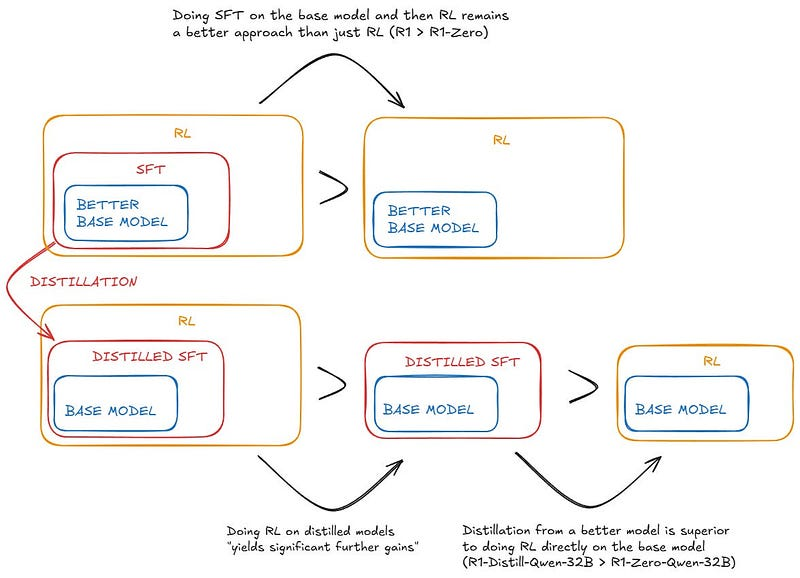

 浙公网安备 33010602011771号
浙公网安备 33010602011771号