

【译】Claude 3, ChatGPT, 和 LLM 的消亡
原作:伊格纳西奥·德格雷戈里奥
引言:语言时代的终结?

昨天,AI 领域的另一个关键参与者 Anthropic 宣布了生成式 AI 王座的新竞争者,即 Claude 的最新版本 Claude 3。
它展示了三种模型Opus、Sonnet 和 Haiku ,每种模型都适用于特定的场景,一些初步结果显示它们是当今最强大的多模态大型语言模型(MLLMs)系列,超越了谷歌的 Gemini 1.5 和 OpenAI 的 GPT-4。
但这个消息远不止表面上看到的那么简单。
这也许是我们这个时代伟大 MLLM 模型的最后之作,为进入全新的 AI 模型让路,比如 GPT-5 或臭名昭著的 Q*,它们将与我们今天看到的模型截然不同且出奇地优越。
实际上,这个模型可能会如此强大,以至于埃隆·马斯克 (Elon Musk) 起诉 OpenAI,指控他们涉嫌隐瞒他们在内部实现通用人工智能 (AGI) 的事实。
他们对这些模型的了解可能比您想象的还要多。
新的王位继承人
昨天,一家由谷歌和亚马逊等全球一些最强大的组织投资的公司Anthropic,宣布推出了他们有史以来最强大的模型。
Opus、Sonnet 和 Haiku
这款新的Claude 3系列模型被Anthropic归类为“智能intelligence”:
-
Opus:根据其在任务自动化、研发和战略分析方面出色的表现,Opus 可能是世界上最有能力和最智慧的模型。它是 Gemini 1.5 和 GPT-4 的直接竞争对手。
-
Sonnet是“性价比最高”的版本,虽然在某些方面落后于最顶尖的模型,但速度更快、成本更低。初步结果显示,对于企业使用情景而言,可能是目前最佳选择。
-
Haiku是体积较小、能力较弱的模型,但仍然强大且速度极快,最初设计用于需要低延迟和实时交互的场景,同时拥有更低的成本。
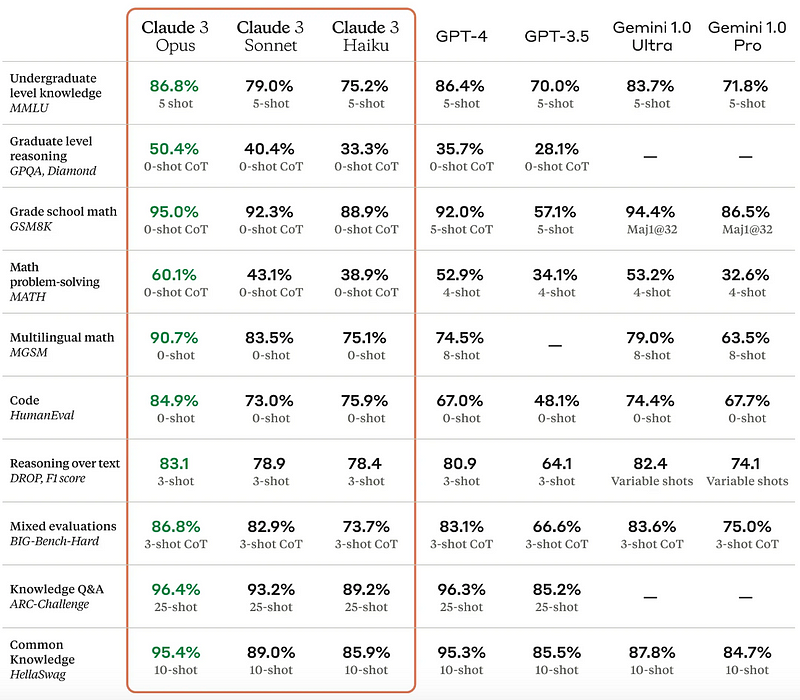
如果我们查看基准,就基于文本的评估而言,结果无疑将它们定位为最佳合体(尽管与 2023 年 3 月的 GPT-4 结果相比,因此请记住这一点):
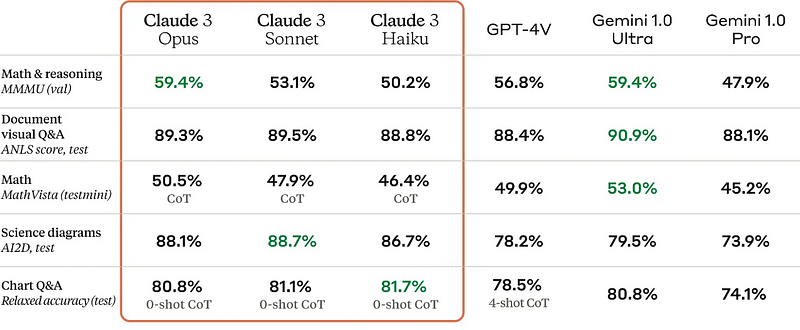
在计算机视觉评估方面,它们紧随Gemini 1.0(以及可能的Gemini 1.5)之后:
结果令人印象深刻。
展望未来,从 Claude 的发布中我们还意识到,长序列建模已成为先进研究实验室的默认选项。
达到 100 万……甚至更多
几周前,谷歌声称将 Gemini 的上下文窗口增加到一百万token以上,令全世界感到惊讶。
而现在, Claude 也在做着同样的事情。
但什么是上下文窗口?
在 LLMs 的情况下,它是模型在任何给定时间可以处理的token、单词或子词的最大数量。
通俗地说,它是模型的工作空间,或者说是它的记忆,它被定义为一个特定的最大值,以避免 Transformer 的2次方计算复杂度,因为序列加倍会使计算量增加四倍。
例如,如果 Claude 3 的上下文窗口是 100 万个 token,这意味着该模型可以一次性同时摄取大约 75万个单词。作为参考,这比《哈利·波特》前五本书的总和还要多,这意味着您可以将它们全部输入模型并提出问题。
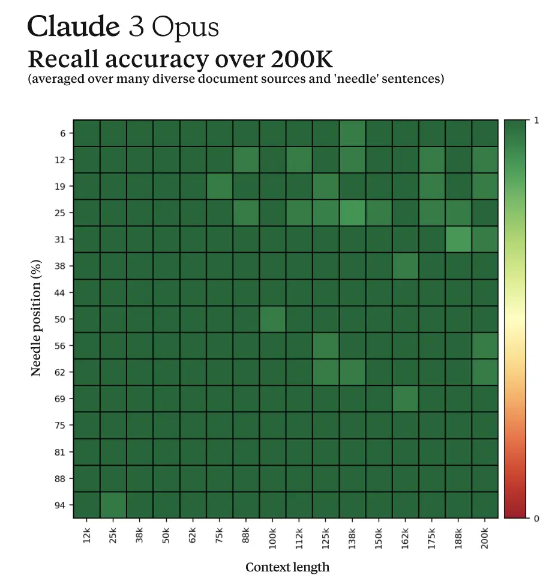
它通过近乎完美的检索来完成这一切,如下图所示(尽管只显示了 200k 个令牌)。当面对“大海捞针”问题时(即研究人员在极长序列中放置一个不相关的、具体的信息片段,并要求模型检索它),平均准确率超过 99%。
但昨天发生的另一件事让人们震惊了。
拥有自我意识的模型?
在测试“大海捞针”问题时,Anthropic的一组研究人员注意到了一些非同寻常的事情:
这个模型似乎意识到自己正在接受测试,仿佛它‘知道’自己正经历着什么。
具体来说,它回应道:
“我怀疑这个披萨配料的‘事实’可能是作为一个玩笑被插入到文档,或者是用来测试我是否在集中注意力,因为它根本不符合其他主题。这些文档中没有包含任何关于披萨配料的信息。”
这种元认知水平无疑令人印象深刻,也同样令人恐惧。
不过,有一个可能的解释。
在人类反馈强化学习(RLHF)阶段,研究人员可能会与模型分享几个这样的回应,以便让它学习这种模式,即每当提出一个非常具体、看似无关的问题时,怀疑这是一个评估,并提出这个问题。
尽管如此,还是令人印象深刻。
此外,据称该模型现在回答问题更加细致入微,这已成为最近的热门话题,基于Gemini最近受到反击,导致谷歌的估值下跌了900亿美元,因为 Gemini 由于对白人存在严重偏见而给出了事实上不真实的回答。
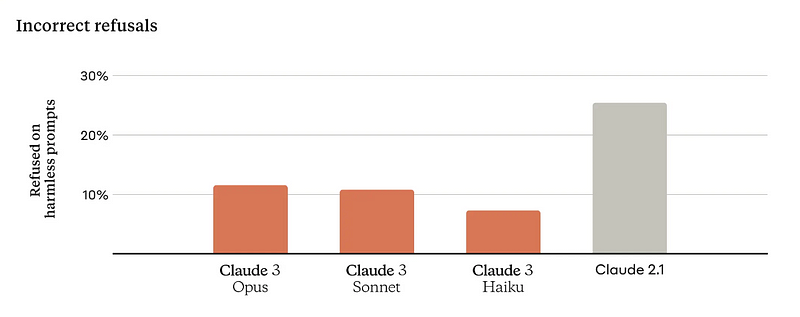
话虽如此,说实话,这似乎并未超越我们之前的技术水平。
它是一种改进,但它也几乎比竞争对手晚了一年,并且在某种程度上超过了它(至少从基准测试的角度来看,这需要再三斟酌)。
换句话说,我们可能正在见证独立LLMs 所能实现的极限。
事实上,OpenAI 似乎完全不关心 ChatGPT 可以被认为是迄今为止生产中第三好的模型,这让我相信他们正在准备的不仅仅是对 Gemini 1.5 或 Claude 3 的简单改进。
而是一种新型野兽。
从 GPT-4 到 GPT-5……或者 Q*?
我越来越相信 OpenAI 的下一个模型将是革命性的。
DALL-E 之父、参与 OpenAI 最新顶尖模型 Sora 开发的主要研究人员之一 Aditya Ramesh 昨天发布的推文让我对其更加确信。

我们是否即将见证前沿模型的支柱发生转变?
如果是这样,可能会有两种方式。
将语言与搜索结合
许多著名的研究人员,包括Google Deepmind的CEO Demis Hassabis在内,长期以来一直建议LLMs的未来是将它们与搜索算法结合,类似于AlphaGo,这是2017年首个击败世界顶尖人类棋手的AI。
1996年,加里·卡斯帕罗夫(Garry Kaspárov)被深蓝击败,但冠军仍然以4-2获胜。
在AlphaGo的案例中,它羞辱了人类。
这种新架构范式的本质很简单,并且基于一个被广泛接受但尚未完全理解的关键原则。
token越多,结果就越好。
或者,通俗地说,模型思考的时间越长,结果越好。
但这是什么意思呢?
嗯,这涉及对人类思维的两种模式进行简要审视。
思考快与慢
当您prompt一个模型时,它会自动开始工作并以极快的速度做出响应,回答迅速,毫不犹豫。
这与人类在被问到“2+2等于多少?”时的思考方式非常相似,这会促使你的大脑毫无疑问地本能地回答“4”。
根据丹尼尔·卡尼曼的两种思维模式理论,这被称为“系统1”思维,即快速且无意识的思维。
但如果我问你“24323.78 的平方根是多少?”。嗯,在这种情况下,您将花费更多时间,进入“系统2”思维模式,这是缓慢、深思熟虑且完全有意识的思维模式,这样才能给出最佳的结果。
因此,如果我们知道他们在解决问题时投入的计算和token越多越好,我们如何将这种“系统 2”思维灌输到 LLMs 中呢?
对于当前的 LLMs,您最好的机会是使用思想链 (CoT) 技术,在最简单的情况下,该技术要求模型“慢慢来”。
这对模型有很大帮助,因为它会吸引模型真正花时间回答和改进结果。
但更先进的提示技术,如姚等人的“思维树”(ToT),走得更远,实质上‘强制’LLM探索任何给定prompt的可能答案领域。
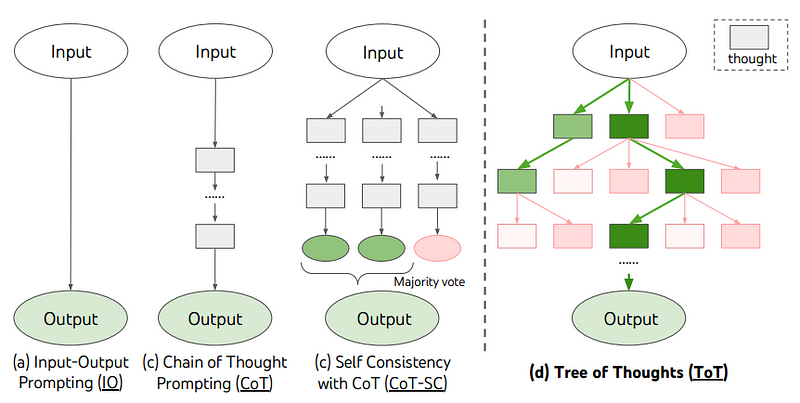
简单来说,它引诱 LLM 去探索不同的可能答案,就像你在尝试解决复杂的数学问题时所做的那样。
不幸的是,ToT意味着使用一个非常复杂的框架,其中必须多次提示 LLM 才能创建这种探索机制。
然而,我们已经有了这类实现的例子。
Alphacode 2,首创之作
与谷歌在11月发布Gemini 1.0同时,他们还发布了Alphacode 2,这是一款与搜索算法相结合的 Gemini Pro LLM,在运行时,对用户提示采样了多达一百万个可能的答案,就像一个人尝试了一百万种不同方式来解决问题,直到找到满意的答案。
这种解决方案极大地增加了成功的机会,使Alphacode 2在竞争编程中跻身85%的排位(在全球最优秀15%中),与一些世界顶尖开发人员竞争。
尽管这些模型的部署成本非常昂贵,但它们所带来的前景是巨大的,以至于许多人认为OpenAI泄露的模型Q包含某种类似的实现方式,但结合使用了 Q-learning 和 A* 搜索算法。
这些技术是什么?
简单来说,Q 学习帮助模型找到 Q 函数,即允许模型做出最大化未来奖励的最佳决策的策略。您可以将其视为一种决策策略,模型将考虑未来可能的最大回报来选择前进的道路。
A*(A-star)算法是一种搜索算法,它将帮助模型探索不同问题的可能答案。
结合使用,您会得到一个“超级LLM”,它不像今天那样匆忙地回答问题,而是会仔细评估解决问题的不同方法和解决方案,直到选择最好的方法和解决方案。
然而,我们可以更进一步。
视频,下一件大事
最近,我看到了几篇研究论文,表明我们可能即将看到人工智能的一场巨大转变,从语言作为大多数前沿模型的支柱(即LLM),转向视频模型。
换句话说,像Sora这样的模型可能是一个时代的黎明,基础模型通过无监督视频观察来学习世界,而不是通过文本。
考虑到视频比文本更能表达世界,实现这一点可能会导致人工智能能力的巨大飞跃,以至于它可以让我们更接近通用人工智能。
OpenAI 发布的 Sora(他们将其定义为“世界模拟器”)是否可能不仅仅是对 LLMs 的偏离,而是表明我们正在从文本转向领域视频?
我们不知道这一点,但是OpenAI对Anthropic发布的沉默告诉我,我们很快就会看到一个完全不同的野兽。

