
【译】基于AI的产品:从构建到失败
原作:Lan Chu
引言:构建一个酷炫而精美的演示很容易,但构建最终产品则不然。

2022 年秋天,我正在做一个很酷的项目。是的,您猜对了 - 使用公司特定的数据微调预训练的 LLM (Bert)。
然而,很快,ChatGPT 就发布了,并席卷了全世界。当存在超级强大的 LLM 时,我尝试微调 LLM 的意义何在?
我一直是 Bert 的超级粉丝,所以当 ChatGPT 发布时,我也陷入了这种热潮中。我的意思是,谁不会呢?人工智能的前景就像一个闪亮的新玩具,我迫不及待地想玩它。在本文中,我想分享一位渴望通过 GenAI 产生影响的 (NLP) 数据科学家的旅程。
我从 2023 年初开始参与 GenAI 项目,当时大老板想用这项新技术做点什么。我意识到自己是多么幸运,并不是每个高管都愿意探索 GenAI 的前沿。很快,我们就加入了 AzureOpenAI 的用户列表,聚会正式开始💃。
构建一个很酷的演示很容易
OpenAI 模型有14亿参数,但我需要让事情按照公司技术堆栈和安全策略进行。
对于一个项目,我必须为人工智能应用程序开发前端和后端解决方案。一周内,我需要学习几件事。我必须在 Azure 上部署一个模型端点,我可以将其用于我的应用程序。在前端方面,我学会了使用 Streamlit 构建应用程序。这相对容易。仅仅一天之内,我就在本地启动并运行了一个应用程序。现在应用程序已经构建完成,是时候向世界展示它了。
坦白的说,这并不容易。我需要确保应用程序遵循公司的安全策略。我们没有部署应用程序的标准工作流程,所以我必须自己解决很多事情。我需要学习如何使用 Azure 管道的 yml 文件并通过 Azure 的 Web 应用程序服务部署本地应用程序。我的日子还充满了找出适当的访问管理、在 Azure blob 存储上存储数据或管理 Hive 存储中的用户数据。这是一个陡峭的、甚至令人难以承受的学习曲线。
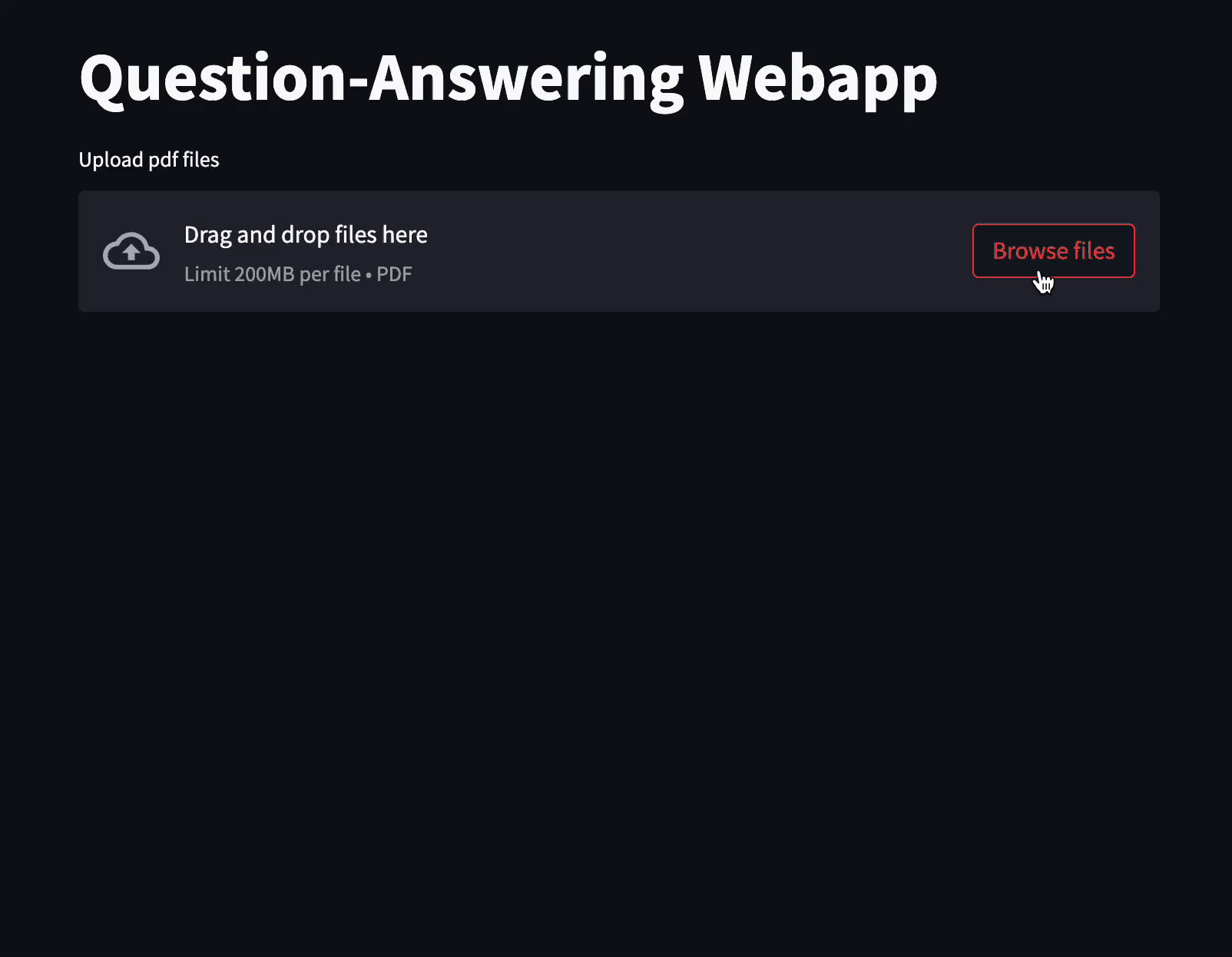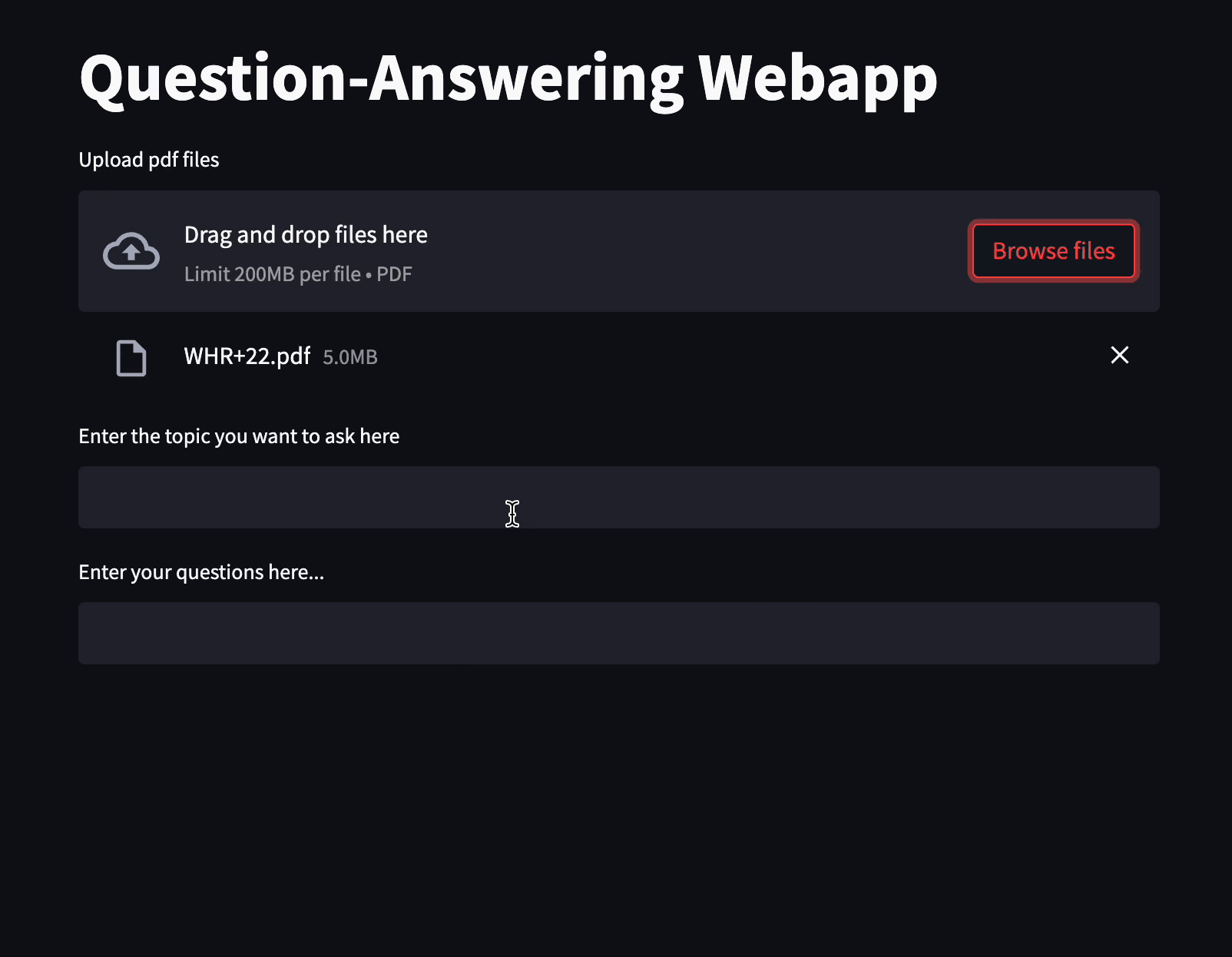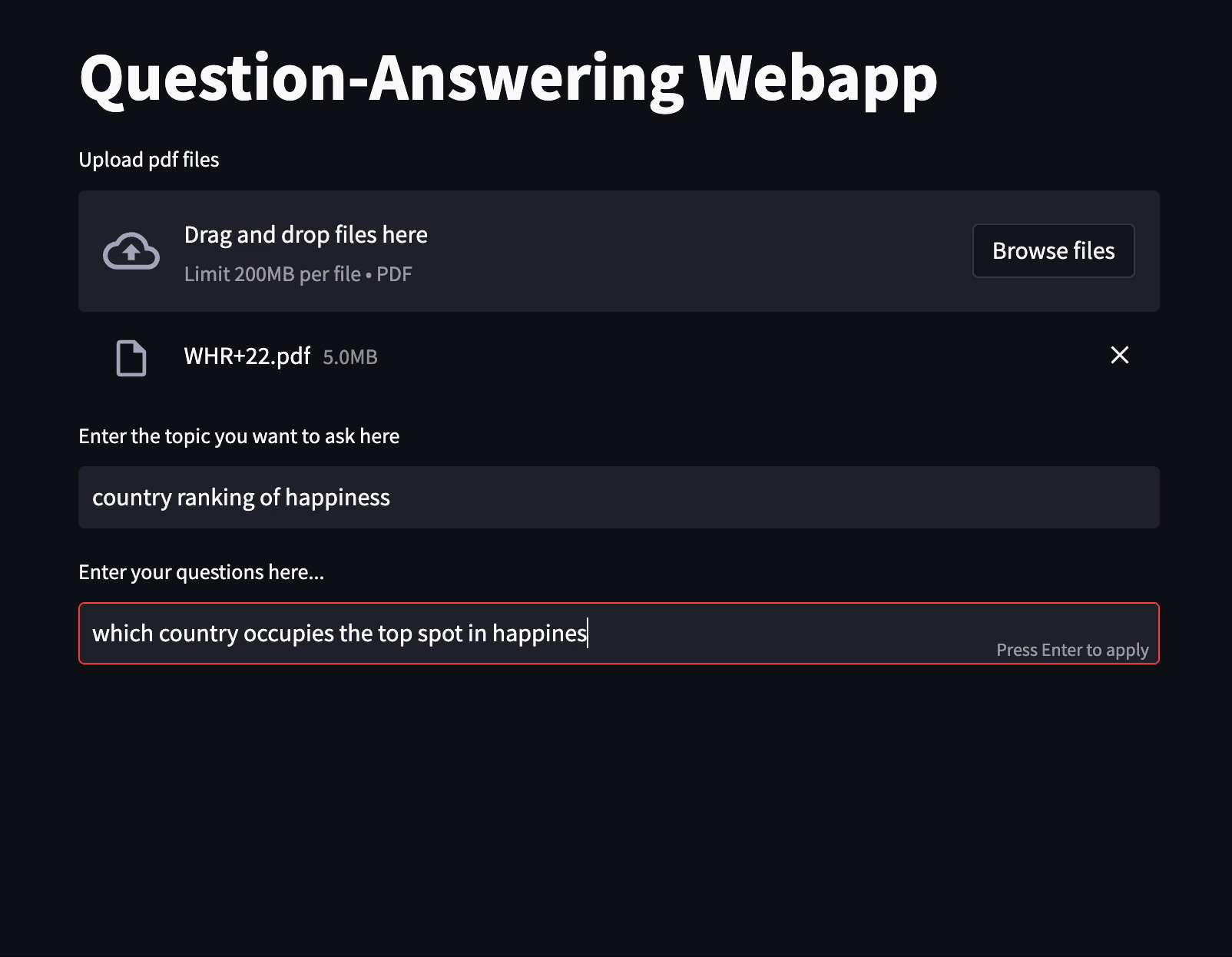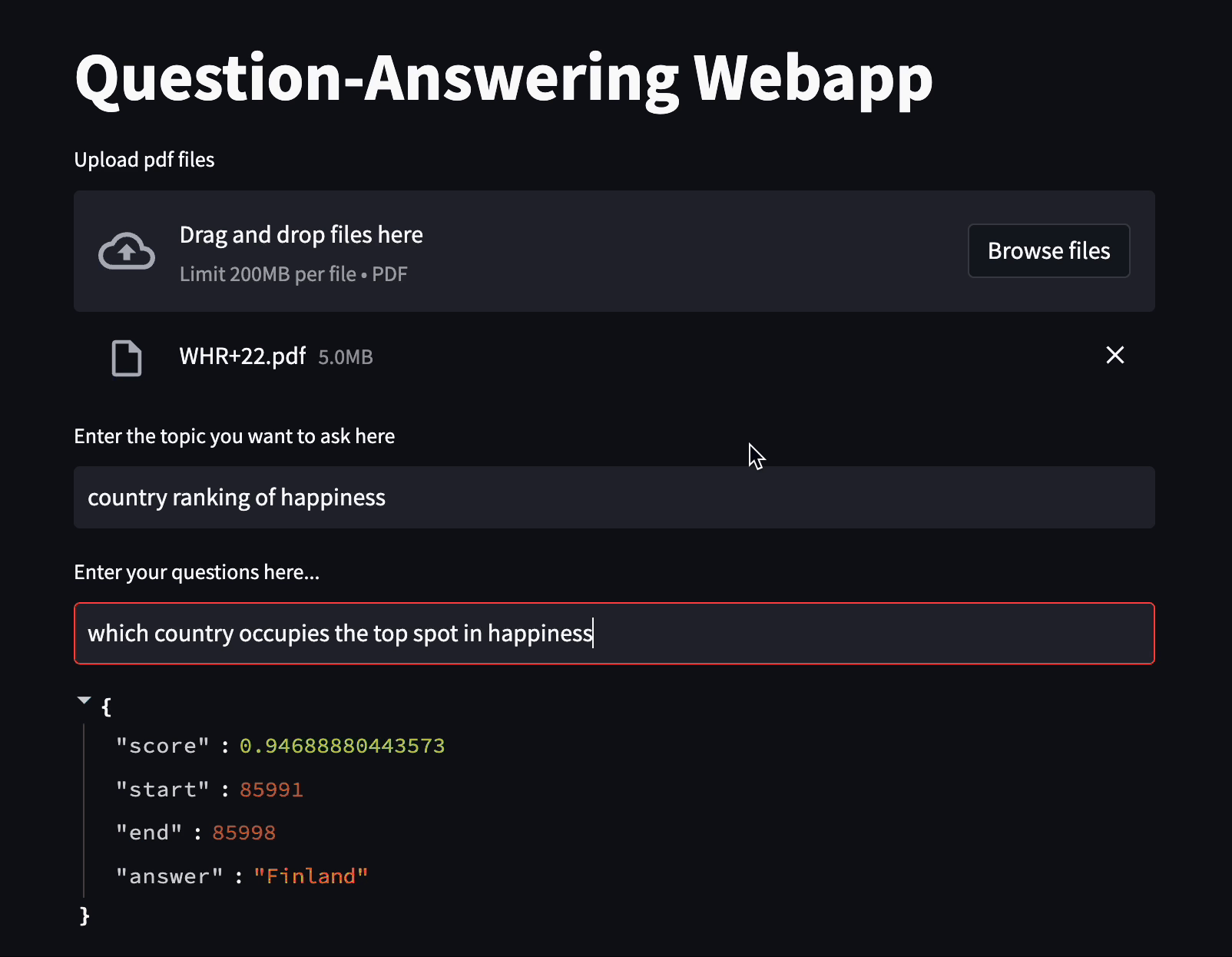
问答 Web 应用程序的示例。
然而,这种感觉并没有持续多久。事实上,很快我就意识到仅仅调用模型和提示是不够的。这只是冰山一角。
原型就是原型。他们对大规模改进持开放态度。
很快,问题就来了
第一个问题称为令牌限制。

如果您使用 LLM 模型,迟早您会遇到麻烦,因为模型会返回最大上下文长度错误,并且它表示您已经超出了模型的限制!你可以说,没问题,GPT-4 提供了 128k 的上下文长度,瞧,问题解决了。
好吧,就是这样。
像 GPT 这样的语言模型在长时间对话中维持上下文的方式是通过“上下文压缩”。这意味着当模型获得超过其上下文窗口大小的新输入时,它必须丢弃最旧的输入,为新输入腾出空间。在此过程中,它通过其内部状态来跟踪先前的上下文,这是对丢弃的信息的一种压缩摘要。

随着对话时间的延长,“上下文压缩”的质量可能会下降,从而导致所谓的上下文漂移,即模型可能开始失去对关键细节或对话的整体线索的跟踪。
因此,增加上下文长度并不能解决问题。在某些时候,您将再次达到令牌限制。
我需要学习如何解决这个问题。这是一个优先事项,否则,人们就无法继续下去。
幻觉与现实
然后,出现了幻觉与事实的对比。 ChatGPT 很神奇,但也并不是那么神奇。
人们说你必须写正确的prompt,这是真的。通过正确的提示,您可以看到输出的巨大改进。同时,即使有你能想到的最好的prompt,它仍然会给你错误的答案。不幸的是,当你最不希望它产生幻觉时,它却产生最多的幻觉。当你提出困难的问题时,它很可能是错误的。
你开始质疑——模型到底能理解吗?如果是的话,就不会犯这些错误了。
也许是时候相信它并没有那么令人惊奇了。至少不是一直如此。

而且因为 chatGPT 本质上是一个概率模型,它预测接下来会出现哪个令牌,所以每个令牌预测的一点误差可能会累积起来,当模型沿着路径创建许多令牌时,它会产生无意义的结果。
就像坐在飞向月球的火箭里一样。起初,微小的偏差似乎没什么大不了的,但在漫长的旅程中,你最终会错过月球并迷失在太空中。
幸运的是,温度和 top_p 采样等参数是控制 Chat-GPT 系列模型行为的强大工具,可以在进行 API 调用时使用。通过调整这些参数,可以实现不同程度的随机性和控制。问题是,尝试设置这些超参数也需要时间,而且是大量的时间。

再现性
祝你好运。
今年我运行了几个 GenAI 项目。对于一个项目,我需要分析央行对经济前景的担忧情绪。输出将用于预测模型。对于这个项目,获得可靠且可重复的输出至关重要。
然而,ChatGPT 的输出并不总是可重现的。默认情况下,聊天完成是不确定的,这意味着模型输出可能因请求而异。
ChatGPT 基于 Transformer 架构构建,该架构在 Transformer 层之上包含一个线性层。线性层将 Transformer 层的输出转换为一组分数,以预测句子中的下一个单词/标记。每个可能的下一个标记都会获得一个分数。然后将这些分数通过 SoftMax 函数来获取概率。选择概率最高的单词作为预测。我有另一篇文章解释了 ChatGPT 的工作原理。

由于接下来可能出现的单词有很多,因此模型的响应方式存在一定的随机性。
这让我对这个项目无法放心,因为每次调用模型时,我都不知道到底会得到什么输出。这让我害怕,在商业上,这是致命的意外。
幸运的是,您可以通过调整一些模型设置(例如温度)来最大限度地降低这种风险。最近,OpenAI 实施了种子变量以提高可重复性。开发人员现在可以在聊天完成请求中指定 seed 参数,以实现一定程度的复现能力。这很棒!
这是一个过程。我们需要制作原型、收集反馈、评估和迭代
随着我的人工智能应用程序的部署和测试,我收到了反馈。例如,一些用户表示分块策略的输出效果不佳。该模型往往会跳过重要的细节。另一位用户评论说模型的输出波动太大,应该更加循序渐进。
这很正常,因为 GenAI 是一个新事物,我也只是在学习。从这些反馈中,我有了一些提高输出质量的想法。
例如,针对不同类型的NLP任务,我采用不同的方法来调用模型。 回答问题应该使用不同于总结的策略。
少样本学习也是一种非常有用的技术。它使预先训练的人工智能模型能够从少量示例中学习,并将学习成果应用到新的、未见过的数据中。就我而言,这在处理央行演讲中的复杂主题时非常有用。

尽管如此,由于我同时运行多个项目 - 是的,这应该归咎于我,我觉得一旦添加一个功能,就会出现一个新的功能请求,无论是来自同一个项目还是不同的项目。没有足够的时间来调整我已经开发的内容。它就像一个循环。每次我完成添加新功能时,都会有其他事情发生。
- 首先,必须解决代币限制问题。
- 接下来,它需要能够读取更多文件格式。
- 我们还创建一个实时反馈功能来跟踪模型的性能。
- 或者“你能以格式良好的 PDF 形式返回输出吗?”
- 人们可以继续要求一个闪亮的新功能,比如“你能把它做得像 chat.openai.com 一样吗”?
感觉就像做了一顿丰盛的饭菜,却没有时间坐下来吃。所以这不是一个好主意。
这就像早上 8:00 喝一杯龙舌兰酒开始新的一天。 — 比尔·英蒙
同时,我必须向用户解释为什么当前的输出不是那么好。这并不总是一次轻松的谈话。人们想要他们想要的东西。如果你无法交付,那么问题是什么并不重要。
换句话说,我已经构建了许多产品的演示版本,但无法调整它们,而且它们都不会让产品脱颖而出。我觉得我正在失去信誉。
GenAI 以用户为中心
人工智能素养不是关于如何微调预先训练的人工智能模型或从头开始构建新的人工智能模型,而是更多关于如何正确使用人工智能。
这是因为GenAI是以用户为中心的。
让我举一个例子。我构建了一个 MVP(最小可交付) 应用程序,允许用户上传文档并具有聊天界面。一位用户来找我说该应用程序不再接收文档了。
结果用户问的是:“你能看到附件吗”?
该模型回应道:“作为人工智能语言模型,我无法看到或感知文档……”

显然,我设置的方式是用户可以上传文档,然后我从上传的文档中提取文本并将其提取到 chatGPT。也就是说,该模型只能“看到”文本,无法像我们人类在屏幕上看到的那样“看到”传统意义上的附加文档。鉴于我设置该工具的方式,提出了一个错误的问题。
如果您要求摘要或回答问题,它完全可以正常工作。
我记得查看了用户对原型的反馈,结果远非令人满意。事实上,用户给该工具打了 1 分(满分 5 分),称它不接收文件。伤心🥲。
这就是为什么我认为 GenAI 项目还应该专注于教育人们如何使用人工智能,从高层次理解 GenAI 的工作原理到不同的提示策略。
GenAI 输出评估
评估 GenAI 模型的输出既重要又具有挑战性。
回到 GenAI 时间的前一天,您只需将数据分成训练/测试/验证集 - 在训练集上训练您的模型并评估验证和测试集的性能。在监督学习中,我们使用 R 平方、精度、召回率或 F 值来评估性能。如何评估大型语言模型?生成新文本时的基本事实是什么?
如果不评估模型的输出,我们如何确定它正在做它应该做的事情?是的,人类的判断起着至关重要的作用,但如果每个人工智能的输出都需要人类的评估,那么我们只是将一项手动任务换成了另一项手动任务,未能实现使用AI节省时间的目标。

在撰写这篇文章时,我正在尝试不同的评估策略。以文本摘要为例,最常见的指标之一是使用 ROUGE 分数。在以后的文章中,我将撰写有关评估 LLM 输出的不同技术。
管理预期——GenAI 并非针对特定问题量身定制
我记得看过吴恩达的演讲,他在演讲中提到,快进到今天,人工智能格局已经发生了巨大的变化。
过去,数据团队需要在构建和部署AI应用程序之前,构建和部署机器学习模型,这可能需要数月甚至一年的时间。
借助 ChatGPT 或 Bard 等即用型大型语言模型,您可以使用基于 prompt 的 AI 工作流程在很短的时间内部署应用程序,如下所示:

我希望这是真的。如果您的目标只是展示炫酷的演示,以及使用人工智能为您的项目获得更多资金的潜力,当然,你可以这样做。但对于一个真实且有影响力的产品呢?我非常怀疑这是否那么容易。 GenAI 模型是通用的,并不针对特定的业务问题。

过去,机器学习模型总是为了解决特定问题而构建的。您可以构建推荐系统来推荐在 Amazon 上购买哪些产品或在 Netflix 上观看哪些电影。自 2018 年首次开发 Bert 以来,语言模型主要用于特定任务,并且在这些狭窄任务上表现良好。例如,您始终需要针对特定任务(例如 POS 标记、问答或情感分析)微调预训练的通用 Bert 模型。例如,如果我专门为了理解可持续发展主题而微调 BERT 模型,我不会指望它成为理解金融或法律文本的专家。
鉴于目前AI行业的炒作,预期管理非常关键。
商业教训
我可以确定,用“总结文档”之类的标准 prompt 调用 OpenAI 的模型不足以构建最终产品。
如前所述,像 ChatGPT 这样的预训练 GenAI 模型是通用模型,可以做很多事情。然而,它们并不是针对特定的业务问题而定制的。如果您想要一个能够改变业务的最终产品,GenAI 必须被当作一个真实的项目来对待。首先必须了解业务痛点,并为您期望该产品带来什么以及您愿意投资的资源设定明确的目标。
GenAI 项目需要合适的人才才能成功。它不仅需要一个能看到GenAI 的潜力,富有远见的领导者 ,还需要一个融合多种技能的团队。它需要最终用户了解他们的痛点以及他们想要什么。它需要了解模型如何工作的数据科学家、机器学习工程师/云平台工程师和IT硬件人员来帮助进行AI应用程序的访问管理、部署和维护。显然,它需要风险人员的参与来减轻潜在的风险。
为你的实验设定时间限制。分配固定的时间段,在规定的时间范围内探索AI功能。制作原型、收集反馈、评估和迭代。这种方法有助于澄清实验结束时要做出的决定。
我想用阿瑟·克拉克的一句话来结束:
当一位杰出且年长的科学家声称某件事是可能的时,他几乎肯定是对的。
当他说某事不可能时,他很可能是错的。

也就是说,我不会做空人工智能。我认为这样做是不明智的。和所有成熟的职业一样,每一个职业在一开始都曾经不成熟。人工智能也是如此。但我们生活在一个变革的时代。在过去的十年里,我们看到深度学习领域取得了如此多的突破,而且它不会很快停止。每隔几年,就会有人发明一些疯狂的东西,让你彻底重新考虑什么是可能的。老实说,我对 ChatGPT 或 Bard 感到非常满意。我认为他们很棒。关键问题不是是否应该接受人工智能,而是如何接受。由于GenAI是一个新事物,我们仍然有很多不确定性需要解决。 GenAI 方法应支持该技术的逐步采用,同时最大限度地降低风险并促进学习。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 推荐几款开源且免费的 .NET MAUI 组件库
· 实操Deepseek接入个人知识库
· 易语言 —— 开山篇
· 【全网最全教程】使用最强DeepSeekR1+联网的火山引擎,没有生成长度限制,DeepSeek本体