
【译】算法 vs AI vs AGI:为初学者消除误区
原作:普利瑟姆
在计算机科学和人工智能领域,理解从传统算法(Algorithms)到人工智能(AI:Artificial Intelligence)再到通用人工智能(AGI:Artificial General Intelligence)的演变至关重要。
在这篇综合指南中,我深入研究这些技术的复杂性,通过识别猫的任务来说明每个阶段的关键差异和进步。
我还试图消除一些人的误解,他们认为或假设人工智能或通用人工智能就像一个大算法。但是它不是!
我将用轻松的语言解释这些高度抽象的数学。

传统算法:计算的基石
使用传统算法进行猫识别

几何特征提取:
眼睛:建模为椭圆形,定义为

该方程表示以笛卡尔坐标系中的点 (h,k) 为中心的椭圆,其中 a 为长半轴的长度,b 为短半轴的长度。胡须和
毛皮纹理:使用傅立叶变换进行分析

算法实现:
边缘检测:Sobel 或 Canny 边缘检测器,计算梯度以查找边界。
基于区域的分割:例如,K 均值聚类,可最大限度地减少每个聚类内的方差:

维度和形状分析:
PCA:将数据投影到低维空间,同时保持大部分方差,使用协方差矩阵的特征分解计算。
挑战和限制:
- 缺乏灵活性:如果不手动重新编程,就无法适应新数据或变化。
- 计算复杂性:高分辨率图像会显着增加计算负载。
- 概念刚性:需要编写一套全新的规则来检测自行车或热狗。 同样的算法将不起作用。
人工智能:学习机器的出现
用于对象识别的深度学习架构
AI 模型是元学习器。 将它们视为元算法,它会查看数据集中许多猫的图片,并在内部编写自己的算法来识别任何猫。
猫识别的神经网络模型:
输入层:图像的像素被输入网络。
隐藏层:这些层,尤其是在深层网络中,创建特征的分层表示:
- 低层可能会检测边缘或简单形状。
- 高层将这些结合起来以识别更复杂的结构,例如面部特征。
输出层:提供图像是猫的概率。

用于猫识别的 CNN:
隐藏层的数学表示:卷积层执行类似于
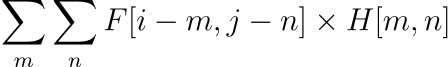
这表示两个函数(或离散设置中的数组)F 和 H 的卷积。索引 i 和 j 通常在数组 F 的维度上运行,m 和 n 在 H 的维度上运行。此卷积运算是许多领域的基本操作,包括信号处理和图像处理。
用于序列数据的 RNN 和 LSTM(Long short term memory,长短时记忆网络):
数学建模:LSTMs 使用门(gates)来控制信息流, 门(gates)的方程如下

其中,ft表示 LSTM 单元在时间 t 的遗忘门(forget gate)。函数 σ 通常表示 sigmoid 激活函数。 Wf是遗忘门(forget gate)的权重矩阵,[ht−1,xt] 是先前隐藏状态 ht−1和当前输入 xt的串联,bf是遗忘门(forget gate)的偏置项。这个门决定了有多少过去的信息(来自之前的细胞状态)需要传递到未来。
优化技术:
反向传播:使用链式法则通过网络传播误差。
梯度下降:

其中,Wnew表示更新后的参数值,Wold表示之前的参数值,α是学习率,∇J(Wold)是成本函数J相对于参数Wold的梯度。该方程是机器学习和优化领域的基础,描述了如何在最小化成本函数的方向上更新参数。
高级概念:
- 用于数据增强的 GAN:生成合成数据,增强训练集。
- 迁移学习:使预先训练的模型适应新任务,例如在 ImageNet 上训练的模型。
人工智能跨对象的多功能性

- 泛化:通过在不同的数据集上进行训练,完全相同的人工智能架构可以学习识别各种物体,包括猫、表演、包、自行车、书籍和数百万其他物体。
- 元学习:人工智能作为一种“元算法”或“元学习器”,不仅为猫编写自己的内部算法,还为“黑匣子”中的数百万个对象编写自己的内部算法,而无需我们手动编写算法。并且同一个模型学习了所有的对象。
多模态AI和专家组合 (MoE)
多模态人工智能集成了图像、声音和文本等各种数据类型,增强了理解和决策。专家混合 (MoE) 框架通过动态地将任务分配给专用模型来进一步细化此过程。
多模态意味着有一个由不同人工智能模型(如上一节)组成的单一人工智能“有机体”,每个模型都执行视觉、语言、声音等专门任务。由元学习“门函数(gating function)”控制。

多模态AI的数学方面
特征级融合:
数学上表示为

其中 xi 是来自不同模态(视觉、语言、声音)的特征,z 是组合特征向量。
重点是要理解,每种模式的特征提取来自专门针对该模式的不同人工智能模型(如上一节),并且每种模式的组合特征也将由元学习器学习。
决策层融合:
涉及组合模型输出,例如通过加权平均:

其中 yi 是各个模型的输出,wi 是它们的权重。
混合专家框架
门(Gating)控网络函数:确定给定输入的专家,表示为

其中 gi(x) 是专家 i 的门函数,Wi 是学习参数。

通向AGI(通用人工智能)之路
AGI 的想法是,它是许多多模式元学习器的组合,作为一个有凝聚力、共生的有机体运行。 类似于我们的大脑设计。
大脑设计
大脑的基本架构包含执行不同任务的区域。 大脑被认为具有“通用智能”,因为它可以执行许多不同类型的活动,这些活动是这些区域共同作用的集体结果。
有时,即使某些区域受到影响,它也可以发挥作用,因为学习被其他区域接管(同时失去某些功能)。 这就是“通用智能”的原因。
这种通用智能的基本能力基于神经元设计及其连接性。神经元的基本结构在整个大脑中通常是一致的,但其特定结构存在差异,与其在不同大脑区域内的功能和位置相对应。
从根本上来说,大多数神经元都有一个共同的结构,包括:
- 细胞体(Soma):包含细胞核,是神经元的代谢中心。
- 树突:接收来自其他神经元的信号的分支状结构。
- 轴突:一种长而细的突起,将信号传输到其他神经元、肌肉或腺体。
- 轴突末端:轴突的端点,信号在此发送到其他神经元。
- 突触:神经元与其他神经元、肌肉或腺体进行交流的连接处。
- 髓鞘(在许多神经元中):一层脂肪层,可隔离许多神经元的轴突,提高信号传输速度。
然而,在这个总体框架内,存在一些变化:
- 大小和长度:体细胞的大小以及轴突和树突的长度可能有很大差异。例如,一些神经元具有非常长的轴突(例如从脊髓延伸到脚的轴突),而另一些神经元则短得多(例如大脑内部的轴突)。
- 树突的形状和复杂性:树突树的复杂性和形状各不相同。一些神经元,例如大脑皮层中的锥体细胞,具有复杂的树突结构,而其他神经元则较简单。
- 突触密度:神经元上突触的数量可能会有所不同,影响它如何整合来自其他神经元的信息。
- 使用的神经递质类型:不同的神经元可能释放不同的神经递质,这会影响发送到其他神经元的信号类型(抑制性或兴奋性)。
- 髓磷脂的存在:一些神经元有髓鞘,而另一些则没有。髓鞘形成影响沿轴突的信号传输速度。
AGI概念
- 超越专业化:AGI 的目标是在各种任务和领域复制类人智能。
- 像大脑一样:与大脑类似,元学习者的“神经元”结构在所有模式中都很常见。
- 设计:与大脑类似,AGI 是多组元学习器,按模块排列并由其他元学习器控制(类似于 Expert 的 Mixture,但更高级)
AGI的组成部分
- 适应性学习:从有限数据中学习并进行概括的能力。
- 认知推理:模仿人类推理过程。
- 情商:理解并回应情绪暗示。
进化轨迹
从传统算法到AI再到AGI概念的历程代表了计算能力的巨大转变。传统算法采用基于规则的方法,可以提供精度,但缺乏灵活性。
AI引入了学习能力,使系统能够适应和泛化各种任务。多模式AI和 MoE 架构的出现进一步增强了这种适应性。
仍处于起步阶段的AGI预示着未来机器可以与人类智能相媲美,这标志着人工智能领域的一个重要里程碑。这种演变不仅展示了计算技术的进步,而且为我们如何处理复杂问题和模拟认知过程开辟了新视野。
