Redis基础命令
Redis基础命令
【一】安装
【1】Redis
-
Redis中文文档:Redis 教程_redis教程
-
Redis unix系统官方安装地址:Downloads - Redis
-
win版本下载地址
【2】RESP
- [RESP-2022.5.1.exe | 实用工具集 (suyin-tools.cn)](https://suyin-tools.cn/Tools/PC/办公软件/Redis Desktop Manager/RESP-2022.5.1.exe)
【3】注意事项
【3.1】Redis安装选项
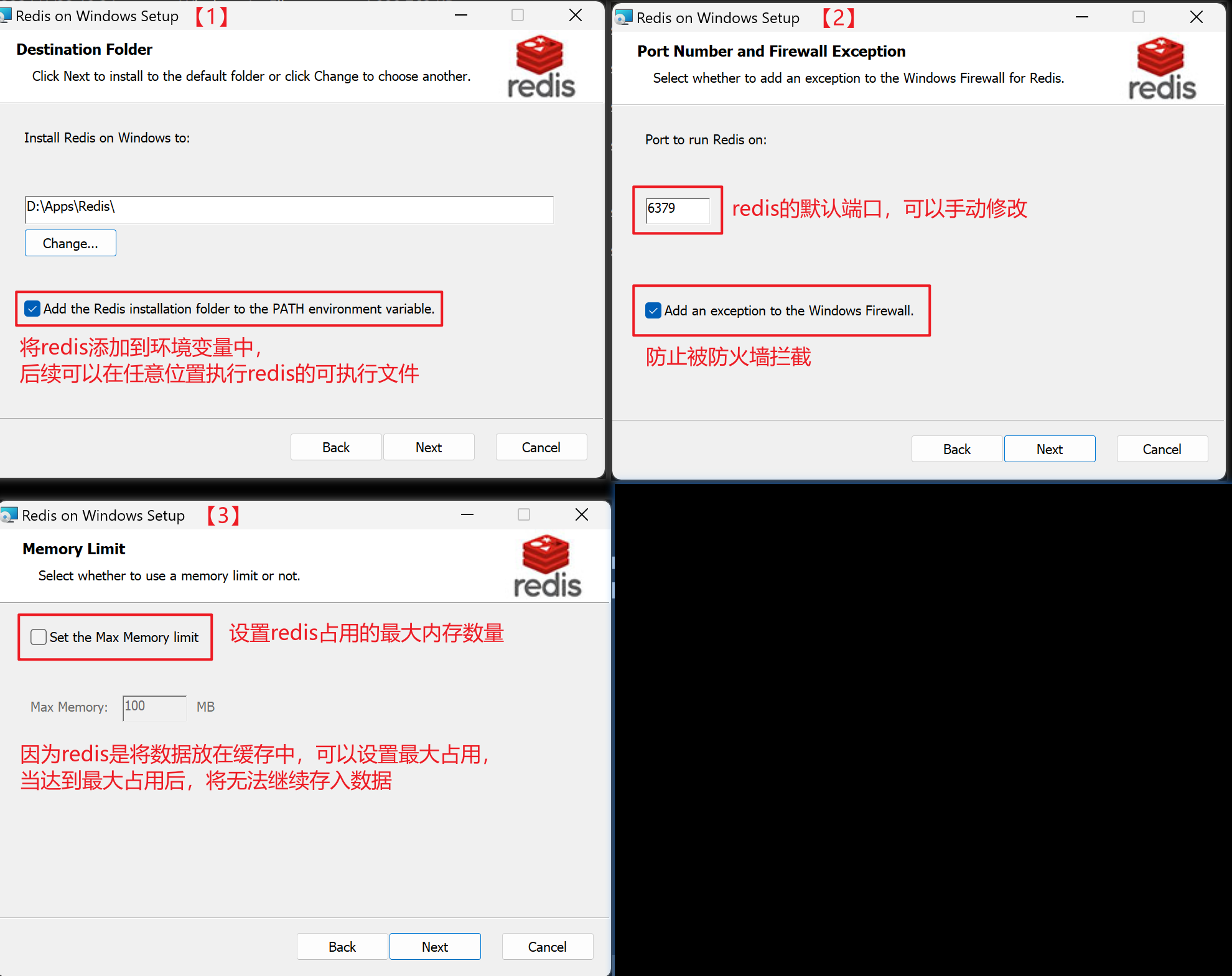
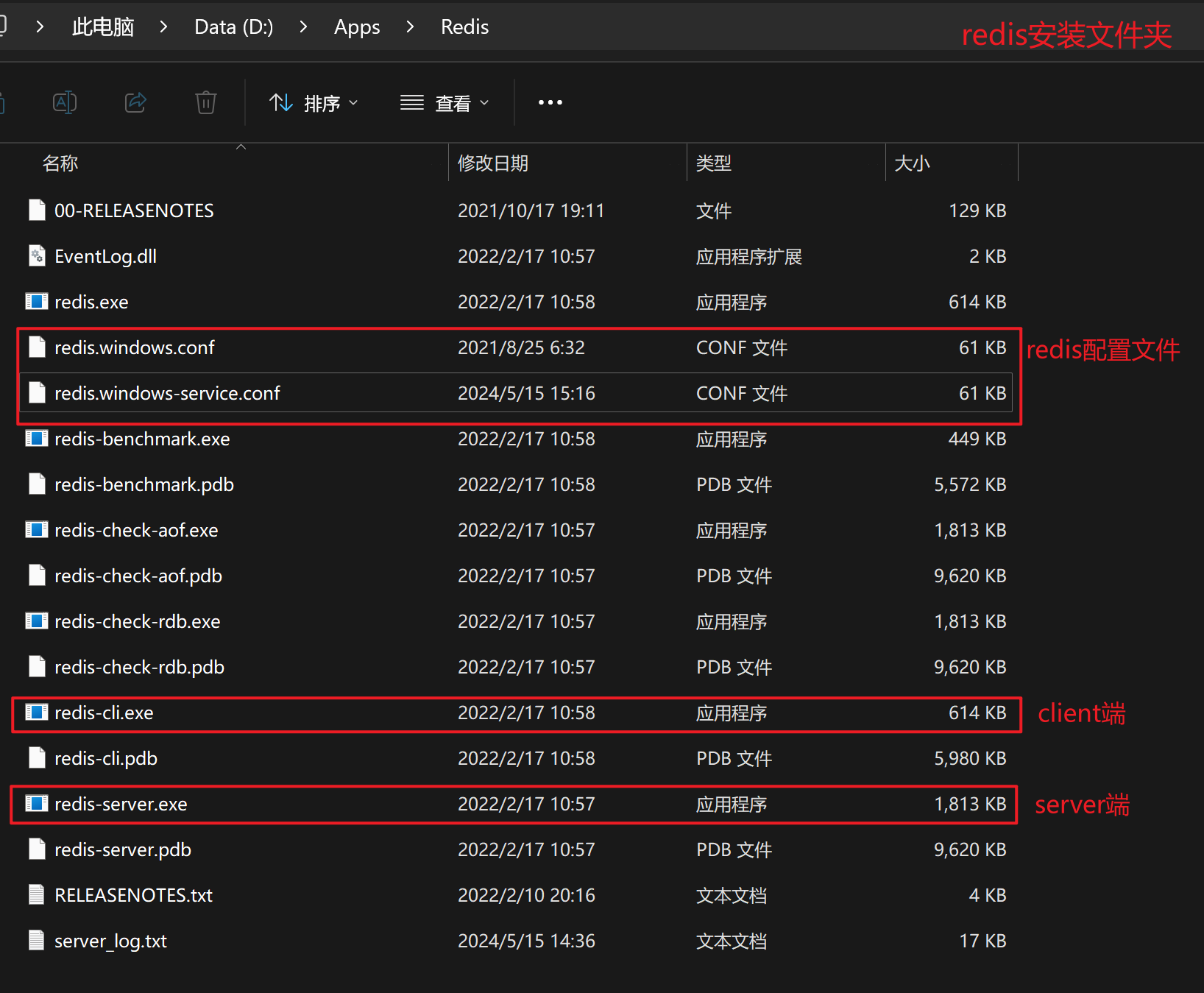
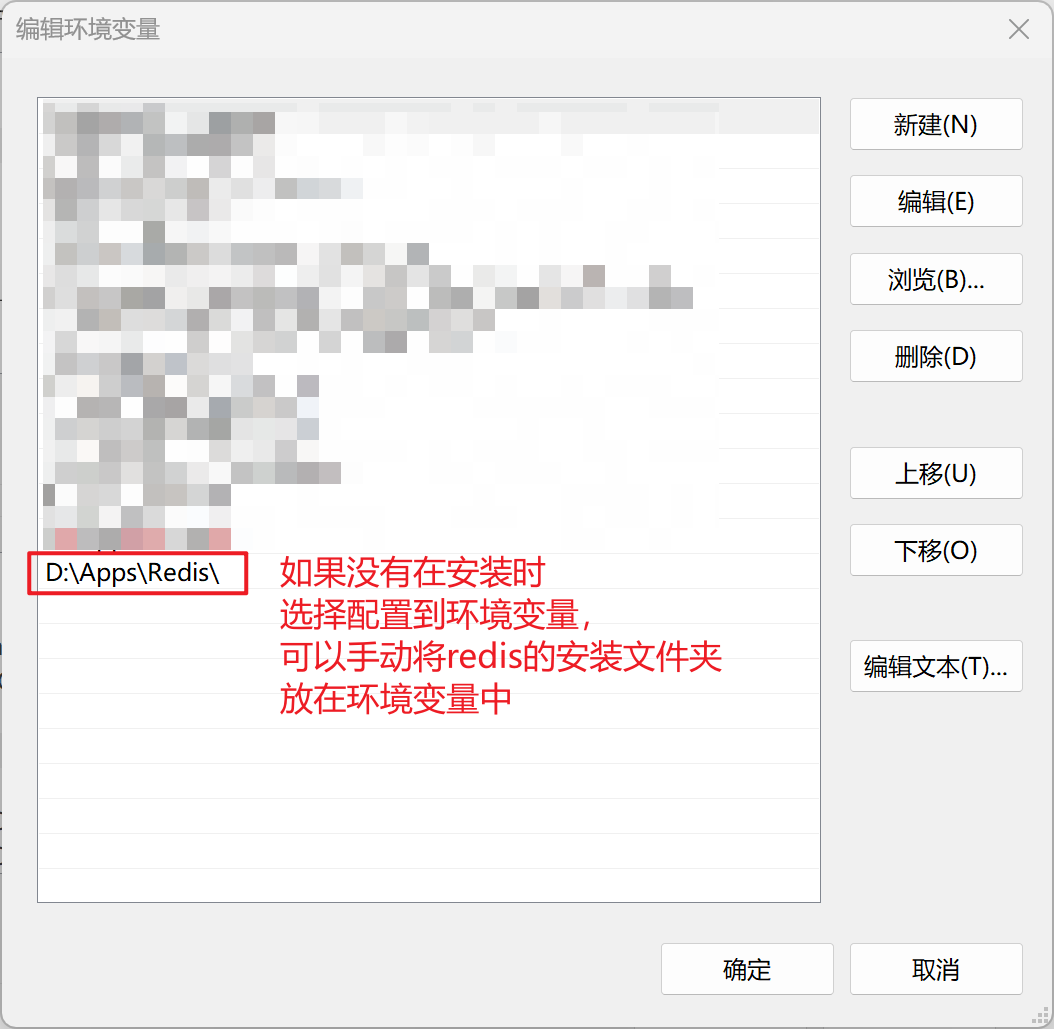
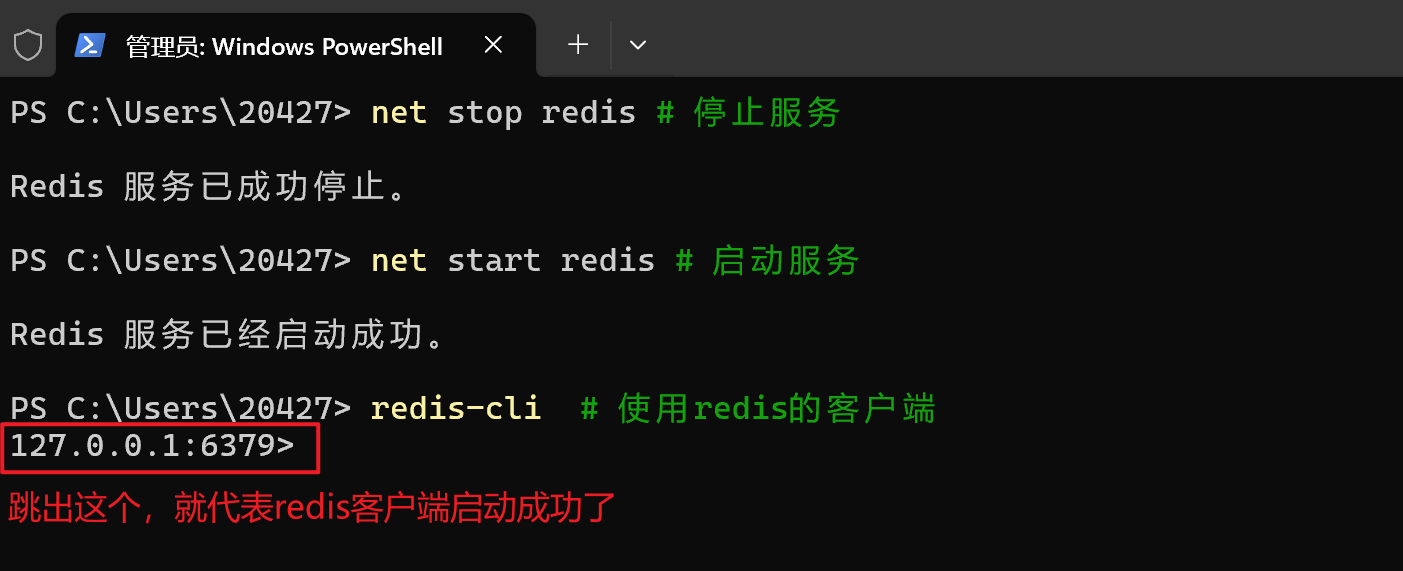
【3.2】Redis验证安装
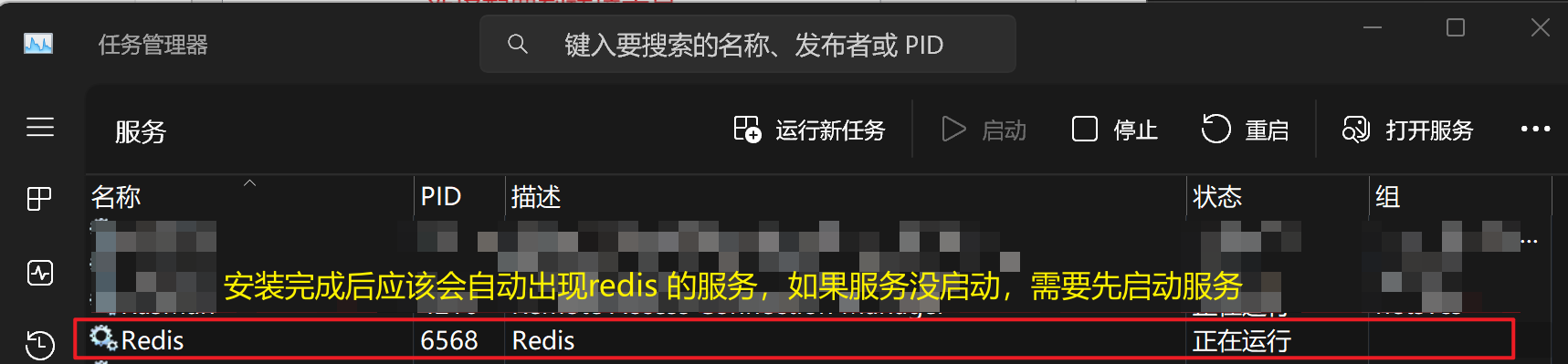
# 启动redis服务
# 需要使用管理员启动命令行
net start redis
redis-cli
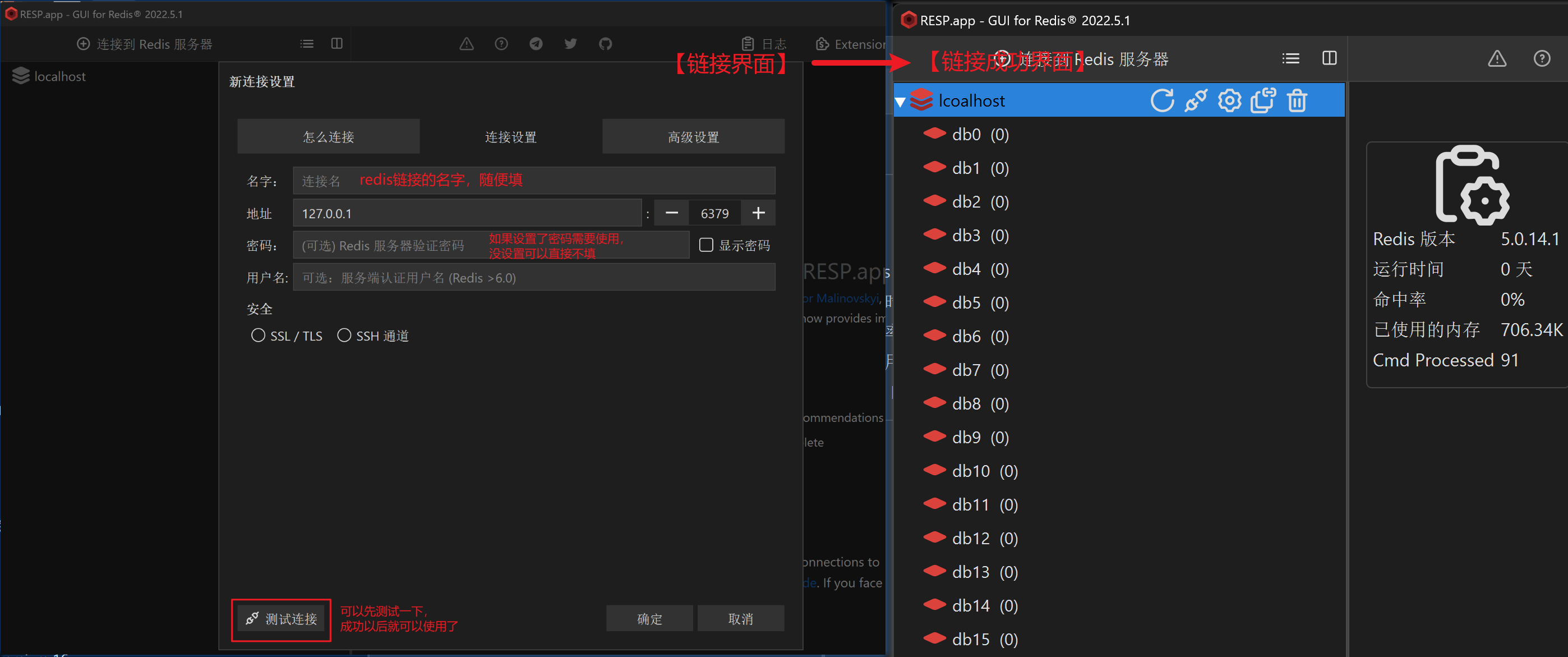
【3.3】RESP链接Redis
RESP下载安装包,修改安装位置即可
【二】基本使用
【1】配置文件
- Redis 配置_redis教程
- 可以通过修改 redis.conf 文件
【1.1】常用配置项
| 配置项 | 介绍 |
|---|---|
| port 6379 | 指定Redis监听端口,默认端口为6379 |
| timeout 300 | 当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能 |
| loglevel verbose | 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose |
| databases 16 | 设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id |
save <seconds> <changes> |
指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合 eg: save 900 1表示900秒(15分钟)内有1个更改就将数据同步到数据文件 |
| rdbcompression yes | 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大 |
| dbfilename dump.rdb | 指定本地数据库文件名,默认值为dump.rdb |
slaveof <masterip> <masterport> |
设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步 |
masterauth <master-password> |
当master服务设置了密码保护时,slav服务连接master的密码 |
| requirepass foobared | 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭 |
| maxclients 128 | 设置同一时间最大客户端连接数,默认无限制 |
maxmemory <bytes> |
指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。 |
| appendonly no | 指定是否在每次更新操作后进行日志记录 |
【2】基础命令
# 启动服务
# 使用windows的服务
net start redis # 启动
net stop redis # 停止
# 使用命令
redis-server # 配置文件启动
redis-server ./redis.windows-service.conf
# 关闭:在客户端
127.0.0.1:6379>shutdown # 友好关闭
下列命令直接在redis-cli中直接使用即可
eg:
127.0.0.1:6379> flushall
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | BGREWRITEAOF | 异步执行一个 AOF(AppendOnly File) 文件重写操作 |
| 2 | BGSAVE | 在后台异步保存当前数据库的数据到磁盘 |
| 3 | CLIENT KILL [ip:port] [ID client-id] | 关闭客户端连接 |
| 4 | CLIENT LIST | 获取连接到服务器的客户端连接列表 |
| 5 | CLIENT GETNAME | 获取连接的名称 |
| 6 | CLIENT PAUSE timeout | 在指定时间内终止运行来自客户端的命令 |
| 7 | CLIENT SETNAME connection-name | 设置当前连接的名称 |
| 8 | CLUSTER SLOTS | 获取集群节点的映射数组 |
| 9 | COMMAND | 获取 Redis 命令详情数组 |
| 10 | COMMAND COUNT | 获取 Redis 命令总数 |
| 11 | COMMAND GETKEYS | 获取给定命令的所有键 |
| 12 | TIME | 返回当前服务器时间 |
| 13 | COMMAND INFO command-name [command-name ...] | 获取指定 Redis 命令描述的数组 |
| 14 | CONFIG GET parameter | 获取指定配置参数的值 |
| 15 | CONFIG REWRITE | 对启动 Redis 服务器时所指定的 redis.conf 配置文件进行改写 |
| 16 | CONFIG SET parameter value | 修改 redis 配置参数,无需重启 |
| 17 | CONFIG RESETSTAT | 重置 INFO 命令中的某些统计数据 |
| 18 | DBSIZE | 返回当前数据库的 key 的数量 |
| 19 | DEBUG OBJECT key | 获取 key 的调试信息 |
| 20 | DEBUG SEGFAULT | 让 Redis 服务崩溃 |
| 21 | FLUSHALL | 删除所有数据库的所有key |
| 22 | FLUSHDB | 删除当前数据库的所有key |
| 23 | INFO [section] | 获取 Redis 服务器的各种信息和统计数值 |
| 24 | LASTSAVE | 返回最近一次 Redis 成功将数据保存到磁盘上的时间,以 UNIX 时间戳格式表示 |
| 25 | MONITOR | 实时打印出 Redis 服务器接收到的命令,调试用 |
| 26 | ROLE | 返回主从实例所属的角色 |
| 27 | SAVE | 异步保存数据到硬盘 |
| 28 | SHUTDOWN [NOSAVE] [SAVE] | 异步保存数据到硬盘,并关闭服务器 |
| 29 | SLAVEOF host port | 将当前服务器转变为指定服务器的从属服务器(slave server) |
| 30 | SLOWLOG subcommand [argument] | 管理 redis 的慢日志 |
| 31 | SYNC | 用于复制功能(replication)的内部命令 |
【三】基本数据类型
【总】简单命令总结
# 通用命令
delete key # 删除 key
type key # 返回 key 所储存的值的类型
exists key # 检查key是否存在,返回0或1
expire key seconds # 为key设置过期时间
expireat key timestamp # 通过时间戳设置过期时间啊
TTL key # 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)
keys pattern # 查找所有符合给定模式( pattern)的 key
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
rename key newkey # 修改 key 的名称
move key db # 将当前数据库的 key 移动到给定的数据库 db 当中
randomkey # 从当前数据库中随机返回一个 key
# 字符串:
set key value # 设置键值对
get key # 根据键获取值
mset k1 v1 k2 v2 ... # 创建多个
mget k1 k2 ... # 获取多个
setex key exp value # 设置有过期时间的键值对
incrby key increment # 将 key 所储存的值加上给定的增量值(increment)
# 列表:
rpush key value1 value2 ... # 在列表中添加一个或多个值
lpush key value1 value2 ... # 将一个或多个值插入到列表头部
lrange key bindex eindex # 获取列表指定范围内的元素
lindex key index # 通过索引获取列表中的元素
lpop key | rpop key # 弹出列表中指定的元素
linsert key before|after old_value new_value # 在列表的元素前或者后插入元素
# 哈希:
hset key field value # 将哈希表 key 中的字段 field 的值设为 value
hget key field # 获取存储在哈希表中指定字段的值
hmset key field1 value1 field2 value2 ... # 同时将多个 field-value (域-值)对设置到哈希表 key 中
hmget key field1 field2 # 获取所有给定字段的值
hkeys key # 获取所有哈希表中的字段
hvals key # 获取哈希表中所有值
hdel key field # 删除一个或多个哈希表字段
# 集合:
sadd key member1 member2 ... # 向集合添加一个或多个成员
sdiff key1 key2 ... # 返回给定所有集合的差集
sdiffstore newkey key1 key2 ... # 返回给定所有集合的差集并存储在 newkey 中
sinter key1 key2 ... # 返回给定所有集合的交集
sunion key1 key2 ... # 返回所有给定集合的并集
smembers key # 返回集合中的所有成员
spop key # 移除并返回集合中的一个随机元素
# 有序集合:
zadd key grade1 member1 grade2 member2 ... # 向有序集合添加一个或多个成员,或者更新已存在成员的分数
zincrby key grade member # 有序集合中对指定成员的分数加上增量 grade
zrange key start end # 通过索引区间返回有序集合成指定区间内的成员
zrevrange key start end # 返回有序集中指定区间内的成员,通过索引,分数从高到底
【0】通用命令
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | DEL key | 该命令用于在 key 存在是删除 key。 |
| 2 | DUMP key | 序列化给定 key ,并返回被序列化的值。 |
| 3 | EXISTS key | 检查给定 key 是否存在。 |
| 4 | EXPIRE key | seconds 为给定 key 设置过期时间。 |
| 5 | EXPIREAT key timestamp | EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。 |
| 6 | PEXPIRE key milliseconds | 设置 key 的过期时间亿以毫秒计。 |
| 7 | PEXPIREAT key milliseconds-timestamp | 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 |
| 8 | KEYS pattern | 查找所有符合给定模式( pattern)的 key 。 |
| 9 | MOVE key db | 将当前数据库的 key 移动到给定的数据库 db 当中。 |
| 10 | PERSIST key | 移除 key 的过期时间,key 将持久保持。 |
| 11 | PTTL key | 以毫秒为单位返回 key 的剩余的过期时间。 |
| 12 | TTL key | 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。 |
| 13 | RANDOMKEY | 从当前数据库中随机返回一个 key 。 |
| 14 | RENAME key newkey | 修改 key 的名称 |
| 15 | RENAMENX key newkey | 仅当 newkey 不存在时,将 key 改名为 newkey 。 |
| 16 | TYPE key | 返回 key 所储存的值的类型。 |
【1】字符串(string)
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | SET key value | 设置指定 key 的值 |
| 2 | GET key | 获取指定 key 的值。 |
| 3 | GETRANGE key start end | 返回 key 中字符串值的子字符 |
| 4 | GETSET key value | 将给定 key 的值设为 value ,并返回 key 的旧值(old value)。 |
| 5 | GETBIT key offset | 对 key 所储存的字符串值,获取指定偏移量上的位(bit)。 |
| 6 | MGET key1 [key2..] | 获取所有(一个或多个)给定 key 的值 |
| 7 | SETBIT key offset value | 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。 |
| 8 | SETEX key seconds value | 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。 |
| 9 | SETNX key value | 只有在 key 不存在时设置 key 的值。 |
| 10 | SETRANGE key offset value | 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始。 |
| 11 | STRLEN key | 返回 key 所储存的字符串值的长度。 |
| 12 | MSET key value [key value ...] | 同时设置一个或多个 key-value 对。 |
| 13 | MSETNX key value [key value ...] | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。 |
| 14 | PSETEX key milliseconds value | 这个命令和 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间,而不是像 SETEX 命令那样,以秒为单位。 |
| 15 | INCR key | 将 key 中储存的数字值增一 |
| 16 | INCRBY key increment | 将 key 所储存的值加上给定的增量值(increment)。 |
| 17 | INCRBYFLOAT key increment | 将 key 所储存的值加上给定的浮点增量值(increment)。 |
| 18 | DECR key | 将 key 中储存的数字值减一。 |
| 19 | DECRBY key decrement | key 所储存的值减去给定的减量值(decrement) 。 |
| 20 | APPEND key value | 如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。 |
【2】列表(list)
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | BLPOP key1 [key2 ] timeout | 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 2 | BRPOP key1 [key2 ] timeout | 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 3 | BRPOPLPUSH source destination timeout | 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 4 | LINDEX key index | 通过索引获取列表中的元素 |
| 5 | LINSERT key BEFORE|AFTER pivot value | 在列表的元素前或者后插入元素 |
| 6 | LLEN key | 获取列表长度 |
| 7 | LPOP key | 移出并获取列表的第一个元素 |
| 8 | LPUSH key value1 value2] | 将一个或多个值插入到列表头部 |
| 9 | LPUSHX key value | 将一个或多个值插入到已存在的列表头部 |
| 10 | LRANGE key start stop | 获取列表指定范围内的元素 |
| 11 | LREM key count value | 移除列表元素 |
| 12 | LSET key index value | 通过索引设置列表元素的值 |
| 13 | LTRIM key start stop | 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。 |
| 14 | RPOP key | 移除并获取列表最后一个元素 |
| 15 | RPOPLPUSH source destination | 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 |
| 16 | RPUSH key value1 [value2] | 在列表中添加一个或多个值 |
| 17 | RPUSHX key value | 为已存在的列表添加值 |
【3】哈希(hash)
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | HDEL key field2 [field2] | 删除一个或多个哈希表字段 |
| 2 | HEXISTS key field | 查看哈希表 key 中,指定的字段是否存在。 |
| 3 | HGET key field | 获取存储在哈希表中指定字段的值 |
| 4 | HGETALL key | 获取在哈希表中指定 key 的所有字段和值 |
| 5 | HINCRBY key field increment | 为哈希表 key 中的指定字段的整数值加上增量 increment 。 |
| 6 | HINCRBYFLOAT key field increment | 为哈希表 key 中的指定字段的浮点数值加上增量 increment 。 |
| 7 | HKEYS key | 获取所有哈希表中的字段 |
| 8 | HLEN key | 获取哈希表中字段的数量 |
| 9 | HMGET key field1 [field2] | 获取所有给定字段的值 |
| 10 | HMSET key field1 value1 [field2 value2 ] | 同时将多个 field-value (域-值)对设置到哈希表 key 中。 |
| 11 | HSET key field value | 将哈希表 key 中的字段 field 的值设为 value 。 |
| 12 | HSETNX key field value | 只有在字段 field 不存在时,设置哈希表字段的值。 |
| 13 | HVALS key | 获取哈希表中所有值 |
| 14 | HSCAN key cursor [MATCH pattern] [COUNT count] | 迭代哈希表中的键值对 |
【4】集合(set)
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | SADD key member1 [member2] | 向集合添加一个或多个成员 |
| 2 | SCARD key | 获取集合的成员数 |
| 3 | SDIFF key1 [key2] | 返回给定所有集合的差集 |
| 4 | SDIFFSTORE destination key1 [key2] | 返回给定所有集合的差集并存储在 destination 中 |
| 5 | SINTER key1 [key2] | 返回给定所有集合的交集 |
| 6 | SINTERSTORE destination key1 [key2] | 返回给定所有集合的交集并存储在 destination 中 |
| 7 | SISMEMBER key member | 判断 member 元素是否是集合 key 的成员 |
| 8 | SMEMBERS key | 返回集合中的所有成员 |
| 9 | SMOVE source destination member | 将 member 元素从 source 集合移动到 destination 集合 |
| 10 | SPOP key | 移除并返回集合中的一个随机元素 |
| 11 | SRANDMEMBER key [count] | 返回集合中一个或多个随机数 |
| 12 | SREM key member1 [member2] | 移除集合中一个或多个成员 |
| 13 | SUNION key1 [key2] | 返回所有给定集合的并集 |
| 14 | SUNIONSTORE destination key1 [key2] | 所有给定集合的并集存储在 destination 集合中 |
| 15 | SSCAN key cursor [MATCH pattern] [COUNT count] | 迭代集合中的元素 |
【5】有序列表(sorted set)
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | ZADD key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| 2 | ZCARD key | 获取有序集合的成员数 |
| 3 | ZCOUNT key min max | 计算在有序集合中指定区间分数的成员数 |
| 4 | ZINCRBY key increment member | 有序集合中对指定成员的分数加上增量 increment |
| 5 | ZINTERSTORE destination numkeys key [key ...] | 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中 |
| 6 | ZLEXCOUNT key min max | 在有序集合中计算指定字典区间内成员数量 |
| 7 | ZRANGE key start stop [WITHSCORES] | 通过索引区间返回有序集合成指定区间内的成员 |
| 8 | ZRANGEBYLEX key min max [LIMIT offset count] | 通过字典区间返回有序集合的成员 |
| 9 | ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] | 通过分数返回有序集合指定区间内的成员 |
| 10 | ZRANK key member | 返回有序集合中指定成员的索引 |
| 11 | ZREM key member [member ...] | 移除有序集合中的一个或多个成员 |
| 12 | ZREMRANGEBYLEX key min max | 移除有序集合中给定的字典区间的所有成员 |
| 13 | ZREMRANGEBYRANK key start stop | 移除有序集合中给定的排名区间的所有成员 |
| 14 | ZREMRANGEBYSCORE key min max | 移除有序集合中给定的分数区间的所有成员 |
| 15 | ZREVRANGE key start stop [WITHSCORES] | 返回有序集中指定区间内的成员,通过索引,分数从高到底 |
| 16 | ZREVRANGEBYSCORE key max min [WITHSCORES] | 返回有序集中指定分数区间内的成员,分数从高到低排序 |
| 17 | ZREVRANK key member | 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
| 18 | ZSCORE key member | 返回有序集中,成员的分数值 |
| 19 | ZUNIONSTORE destination numkeys key [key ...] | 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
| 20 | ZSCAN key cursor [MATCH pattern] [COUNT count] | 迭代有序集合中的元素(包括元素成员和元素分值) |
【四】Python操作数据库
【1】安装依赖
pip install redis
【2】基本使用
import redis
conn = redis.Redis(
host="localhost",
port=6379, # 端口
db=0, # 链接的数据库
password=None, # 如果需要密码可以填写
encoding="utf-8", # 字符的编码格式
decode_responses=False, # 是否将响应内容通过encoding解码
)
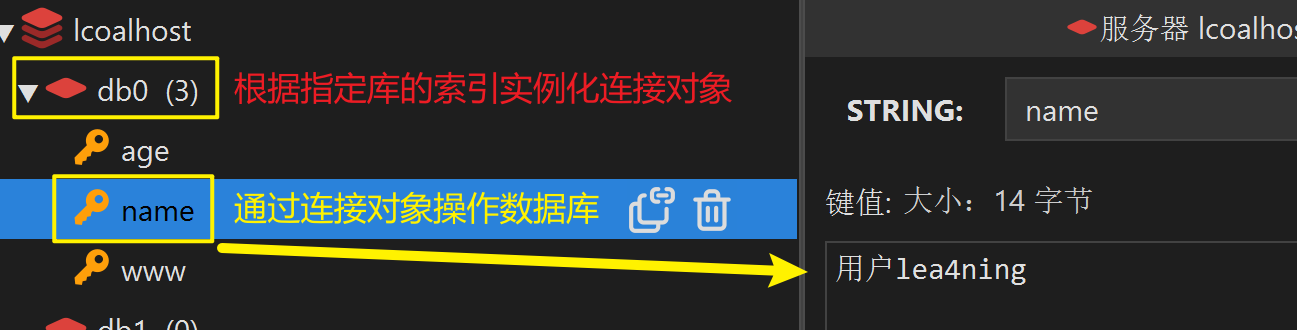
# 实例化得到redis链接对象后,就可以操作了
conn.set('name', '用户lea4ning') # 设置值
print(conn.get('name')) # b'\xe7\x94\xa8\xe6\x88\xb7lea4ning' # 返回字节
conn.mset({'age': 12, 'www': 222})
conn.close()
【补】scan和scan_iter
- python中redis进行模糊查询(keys()、scan()、scan_iter())_python redis scan-CSDN博客
- Redis中的scan:【SCAN | Docs (redis.io)】
scan和scan_iter是用于在 Redis 中迭代遍历 keys 的方法,特别是在处理大量 keys 或者需要在不阻塞 Redis 服务器的情况下进行遍历时非常有用
【补.1】基本语法
-
scan(cursor=0, match=None, count=None)- cursor :游标位置
- pattern:匹配的值
- count:每次渐进的值,并不是返回结果的数量,也可以理解为每次扫描的值
-
scan_iter(name, match=None, count=None)
【补.2】简单演示
import redis
conn = redis.Redis(decode_responses=True)
# 创建数据
# for i in range(1000):
# # 设置一个hash理性的数据
# conn.hset('map_demo', i, '鸡蛋_%s' % i)
print(conn.hkeys('map_demo')) # 打印出所有的键
print(conn.hscan('map_demo')) # 返回(游标值,{'key':'value','k':'v'...}) # 默认为10
print(conn.hscan_iter('map_demo')) # <generator object ScanCommands.hscan_iter at 0x00000220BC72AD50>
for h in conn.hscan_iter('map_demo'): # 生成器中每一条为(key,value)
print(h)
print('+++++++++++++++++')
【3】连接池
由于redis是单进程单线程的,所以不需要担心数据错乱
- redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。
- 默认,每个Redis实例都会维护一个自己的连接池。
- 可以直接建立一个连接池,然后作为实例化Redis实例的参数,这样就可以实现多个Redis实例共享一个连接池
import redis
POOL = redis.ConnectionPool(
# 参数与单个链接对象一致,使用连接池将会把链接对象的参数传递给每一个链接对象
host="localhost",
port=6379, # 端口
db=0, # 链接的数据库
decode_responses=True, # 是否将响应内容通过encoding解码
max_connections=5, # 最大连接数
)
# 使用多线程模拟
from threading import Thread
def func(i):
# 每个线程创建一个连接对象并获取值
# 如果线程数大于最大连接数将会报错 # redis.exceptions.ConnectionError: Too many connections
conn = redis.Redis(connection_pool=POOL)
print(conn.get(f'egg_{i}'))
conn.close()
if __name__ == '__main__':
# 创建对象造数据
conn = redis.Redis(connection_pool=POOL)
[conn.set(f'egg_{i}', i) for i in range(5)]
# 线程列表
t_list = []
# 创建5个线程
for i in range(5):
t = Thread(target=func, args=(i,))
t_list.append(t)
# 启动线程
[t.start() for t in t_list]
【4】redis实例常用命令
【4.1】字符串操作
# 1 set(name, value, ex=None, px=None, nx=False, xx=False)
# 1.1 基本使用
# conn.set('age',18)
# 1.2 ex使用:10s后过期,被清理掉
# conn.set('hobby','篮球',ex=10)
# 1.3 nx,如果设置为True,则只有name不存在时,当前set操作才执行,值存在,就修改不了,执行没效果
# conn.set('name','666',nx=True) # name存在,不会修改了
# 1.4 xx,如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值
# conn.set('name','666',xx=True) # name存在,会修改了,name不存在,不会新建
# conn.set('hobby','篮球',xx=True) # name存在,会修改了,name不存在,不会新建
#### redis实现分布式锁底层使用nx xx实现
# 2 setnx(name, value) 等同于 conn.set('name','666',nx=True)
# 设置值,只有name不存在时,执行设置操作(添加),如果存在,不会修改
# 3 setex(name, value, time) 设置过期时间过期时间秒
# conn.setex('hobby',4,'足球')
# 4 psetex(name, time_ms, value) 过期时间毫秒
# conn.psetex('hobby',5000,'sss')
# 5 mset(*args, **kwargs) 批量设置
# conn.mset({'name': 'xxx', 'age': 19, 'height': 183, 'weight': 140})
# 6 get(name) 获取值
# print(conn.get('weight'))
# 7 mget(keys, *args)
# res=conn.mget('name','age')
# res=conn.mget(['name','hobby','height'])
# print(res)
# 8 getset(name, value) 获取值然后设置新值
# res=conn.getset('name','sdsaf')
# print(res)
# 9 getrange(key, start, end) # 获取起始和结束位置的字符串 前闭后闭 取字节
# res=conn.getrange('name',0,1)
# print(res)
# 10 setrange(name, offset, value)
# conn.setrange('name',4,'xxss')
# 操作比特位
# 11 setbit(name, offset, value)
# 12 getbit(name, offset)
# 13 bitcount(key, start=None, end=None)
# 14 bitop(operation, dest, *keys)
# 15 strlen(name) 统计字节长度
# print(conn.strlen('name'))
# 15 incr(self, name, amount=1) # 自增,做计数器,性能高,单线程,没有并发安全问题,不会错乱
# conn.incr('age')
# conn.incrby('age',2)
# 16 incrbyfloat(self, name, amount=1.0)
# 17 decr(self, name, amount=1)
# conn.decrby('age',3)
# 18 append(key, value)
【4.2】哈希操作
# 1 hset(name, key, value)
# conn.hset('user-info-01','name','lqz')
# conn.hset('user-info-01','age',19)
# conn.hset('user-info-01','hobby','篮球')
# 2 hset(name, mapping)
# conn.hset('user-info-02',mapping={'name':'zhangsan','age':18})
# 3 hget(name,key)
# print(conn.hget('user-info-01','name'))
# 4 hmget(name, keys, *args)
# print(conn.hmget('user-info-01','name','age','hobby'))
# print(conn.hmget('user-info-01',['name','age','hobby']))
# 5 hgetall(name)
# print(conn.hgetall('user-info-02'))
# 6 hlen(name)
# print(conn.hlen('user-info-01'))
# 7 hkeys(name)
# print(conn.hkeys('user-info-01'))
# 8 hvals(name)
# print(conn.hvals('user-info-01'))
# 9 hexists(name, key)
# print(onn.hexists('user-info-02','hobby'))
# 10 hdel(name,*keys)
# conn.hdel('user-info-01','hobby','age')
# 11 hincrby(name, key, amount=1)
# conn.hincrby('user-info-01','age') # 有会自增,没有会创建并自增
# 12 hincrbyfloat(name, key, amount=1.0)
# 13 hscan(name, cursor=0, match=None, count=None)
# 14 hscan_iter(name, match=None, count=None)--与hscan一致,但是以迭代器形式返回
【4.3】数组操作
# 1 lpush(name, values) 从左向右操作
# conn.lpush('girls','小红')
# 2 rpush(name, values) 表示从右向左操作
# conn.rpush('girls','小紫')
# 3 lpushx(name, value) 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
# conn.lpushx('girls','古力娜扎')
# 4 rpushx(name, value) 表示从右向左操作
# 5 llen(name) # 返回数组的长度
# print(conn.llen('girls'))
# 6 linsert(name, where, refvalue, value))
# conn.linsert('girls','before','刘亦菲','上海刘亦菲')
# conn.linsert('girls','after','刘亦菲','北京刘亦菲')
# 7 r.lset(name, index, value)
# conn.lset('girls','0','xx')
# 8 r.lrem(name, value, num)
# conn.lrem('girls',1,'刘亦菲') # 从左侧删除一个符合条件
# conn.lrem('girls',-1,'刘亦菲')# 从右侧删除一个符合条件
# conn.lrem('girls',0,'刘亦菲')# 删除所有符合条件
# 9 lpop(name)
# 10 rpop(name) 表示从右向左操作
# print(conn.lpop('girls'))
# 11 lindex(name, index)
# print(conn.lindex('girls',1))
# 12 lrange(name, start, end)
# print(conn.lrange('girls',0,1))
# 13 ltrim(name, start, end)
# conn.ltrim('girls',1,3)
# 14 rpoplpush(src, dst)
# 15 blpop(keys, timeout) block--》阻塞
# res=conn.blpop('boys')
# print(res)
# 16 r.brpop(keys, timeout),从右向左获取数据
# 17 brpoplpush(src, dst, timeout=0)
【五】在Django中集成Redis缓存数据库
【1】导入redis模块生成的实例
# 生成链接池对象
### pool.py
import redis
POOL = redis.ConnectionPool(max_connections=10, decode_responses=True)
# 在使用时,导入链接池
from utils.pool import POOL
import redis
class RedisView(ViewSet):
def list(self, request):
# 从链接池中获取连接对象
conn = redis.Redis(connection_pool=POOL)
# 根据键获取值并自增1
conn.incrby('count')
# 获取值
count = conn.get('count')
return APIResponse(msg='您是第%s个访问的' % count)
【2】使用django-redis模块
# 安装
pip install django-redis
# settings.py
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100}
}
}
}
# 使用
from django_redis import get_redis_connection
# 导入 get_redis_connection
class RedisView(ViewSet):
def list(self, request):
conn = get_redis_connection() # 从池中获取一个链接
conn.incrby('count')
count = conn.get('count')
return APIResponse(msg='您是第%s个访问的' % count)
【3】将redis集成到django的缓存模块中
- 当我们在配置文件中配置了上述
CACHE={}后,当我们使用django的缓存时,将会自动与redis数据库交互 cache.set()和cache.get()将会从redis数据库中获取数据以及存放数据
# settings.py
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100}
}
}
}
- views.py
from rest_framework.response import Response
from django.core.cache import cache
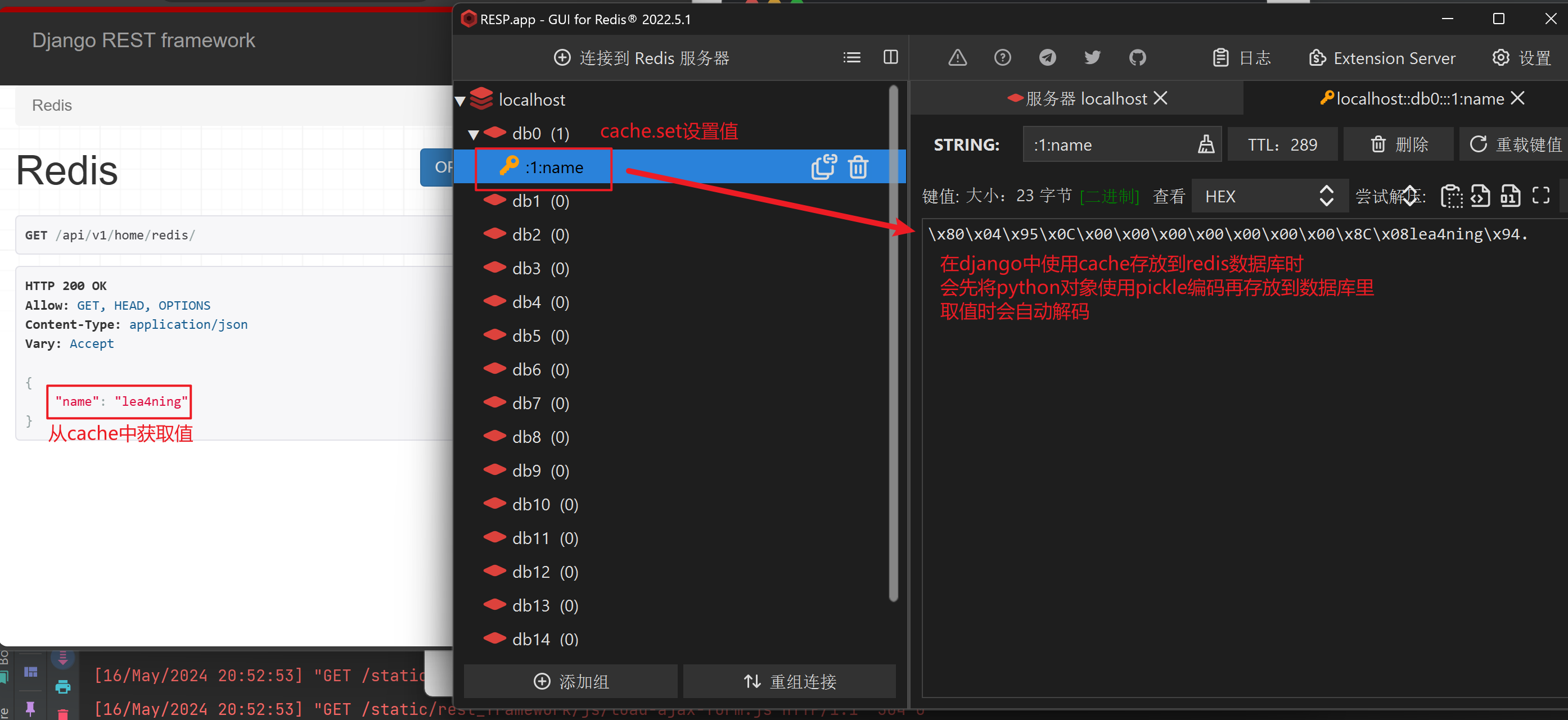
class RedisView(APIView):
def get(self, request):
cache.set('name', 'lea4ning')
name = cache.get('name')
return Response({'name': name})
【4】实例:访问首页轮播图时,使用缓存
- APIListModelMixin
class APIListModelMixin(ListModelMixin):
cache_key = None
def list(self, request, *args, **kwargs):
# 先断言 # 指定必须书写这个类属性
assert self.cache_key, APIException('必须指定类属性cache_key')
# 从缓存中获取
results = cache.get(self.cache_key)
if not results:
# 如果有缓存,直接返回缓存,如果没有创建缓存
res = super().list(request, *args, **kwargs)
results = res.data
cache.set(self.cache_key, results)
return APIResponse(results=results)
- views.py
class BannerView(GenericViewSet, APIListModelMixin):
# 过滤所有被删除或不被上架的轮播图 并按照排序等级排序 数字越低,优先级越高
queryset = Banner.objects.all().filter(is_delete=False, is_show=True).order_by('orders')[:settings.BANNER_COUNT]
serializer_class = BannerSerializer
# 缓存存放的键
cache_key = 'banner_list'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号