DRF之过滤 排序 分页
DRF之过滤 排序 分页
- 使用【过滤 排序 分页】都需要在继承了
GenericAPIView的视图类下使用 - 并指定类属性【queryset 和 serializer_class】
【一】过滤
# 所有过滤类都继承 【BaseFilterBackend】
from rest_framework.filters import BaseFilterBackend
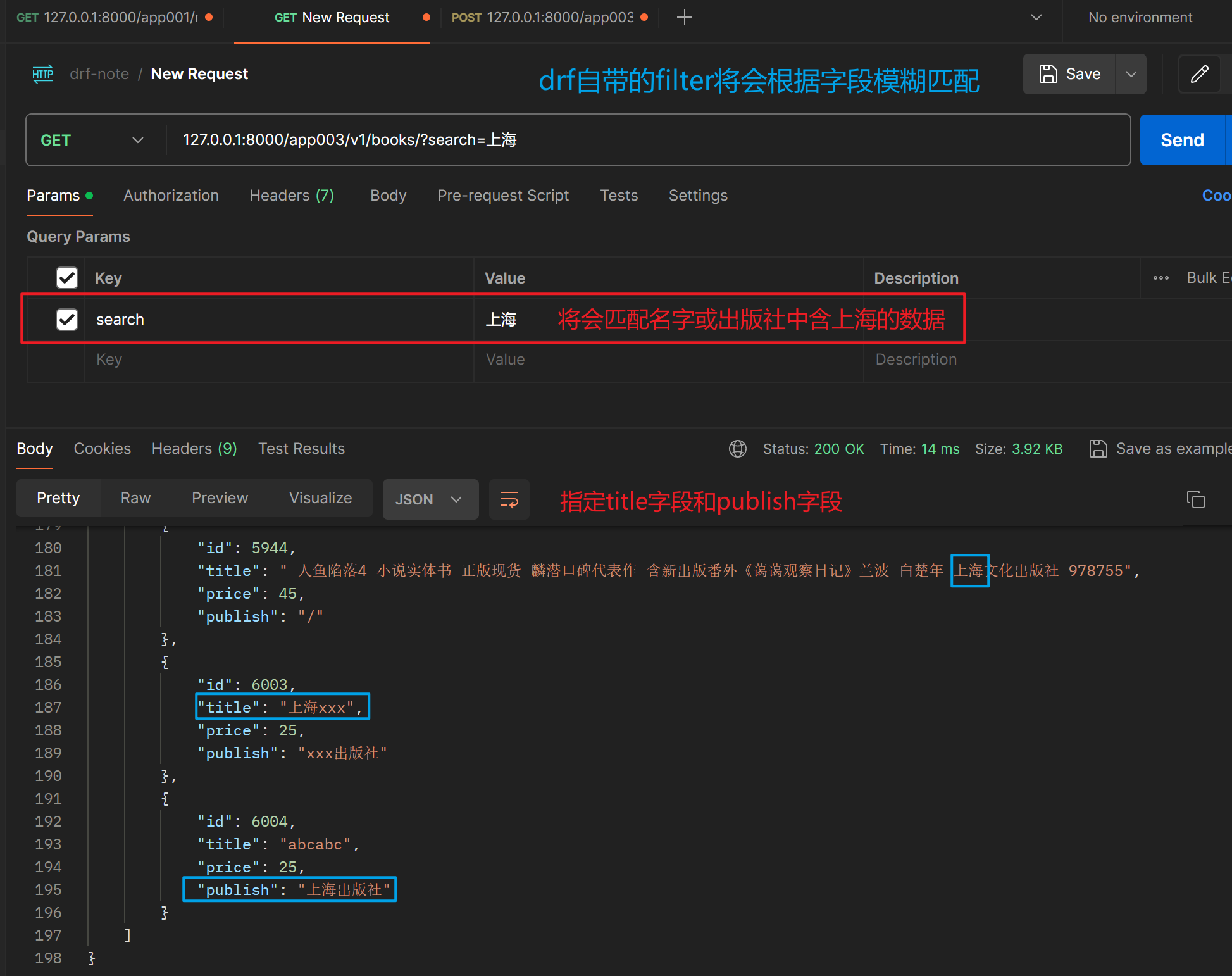
【1】drf自带的过滤
# 导入模块
from rest_framework.filters import SearchFilter
# SearchFilter : 模糊匹配
- 常用的配置属性
search_param: 这个属性用于指定 URL 查询参数的名称,该参数将用于搜索。默认值通常为"search"search_title: 用于在浏览器可视化界面中定义搜索输入字段的标题。这主要用于 API 浏览器。search_description: 类似于search_title,此属性用于定义搜索字段的描述,这同样显示在 API 浏览器中。search_fields: 这个属性是一个字符串列表,指定了哪些字段应当被包含在搜索中。- 字段可以指定一些前缀
^: 这个前缀表示进行前缀匹配,即以指定值开头的匹配。在 Django ORM 中,对应的查询方法是istartswith,表示大小写不敏感的前缀匹配。=: 这个前缀表示进行精确匹配,即完全匹配指定值的项。在 Django ORM 中,对应的查询方法是iexact,表示大小写不敏感的精确匹配。@: 这个前缀表示进行全文搜索,即在文本字段中进行全文搜索匹配。在 Django ORM 中,对应的查询方法是search,通常与数据库全文搜索功能配合使用。$: 这个前缀表示使用正则表达式进行匹配。在 Django ORM 中,对应的查询方法是iregex,表示大小写不敏感的正则表达式匹配。
- 字段可以指定一些前缀
【1.1】使用
- 使用过滤和排序都需要在继承了
GenericAPIView的视图类下使用
class BookView(ModelViewSet):
# 需要定义queryset
queryset = Book.objects.all()
serializer_class = BookSerializer
# 将过滤类配置在列表中
filter_backends = [SearchFilter]
# 指定过滤字段
search_fields = ['title', 'publish']
# search_fields = ['^title', '=publish']
### ^ 表示搜索时对 title 字段进行前缀匹配
### = 表示对 publish 进行精确匹配
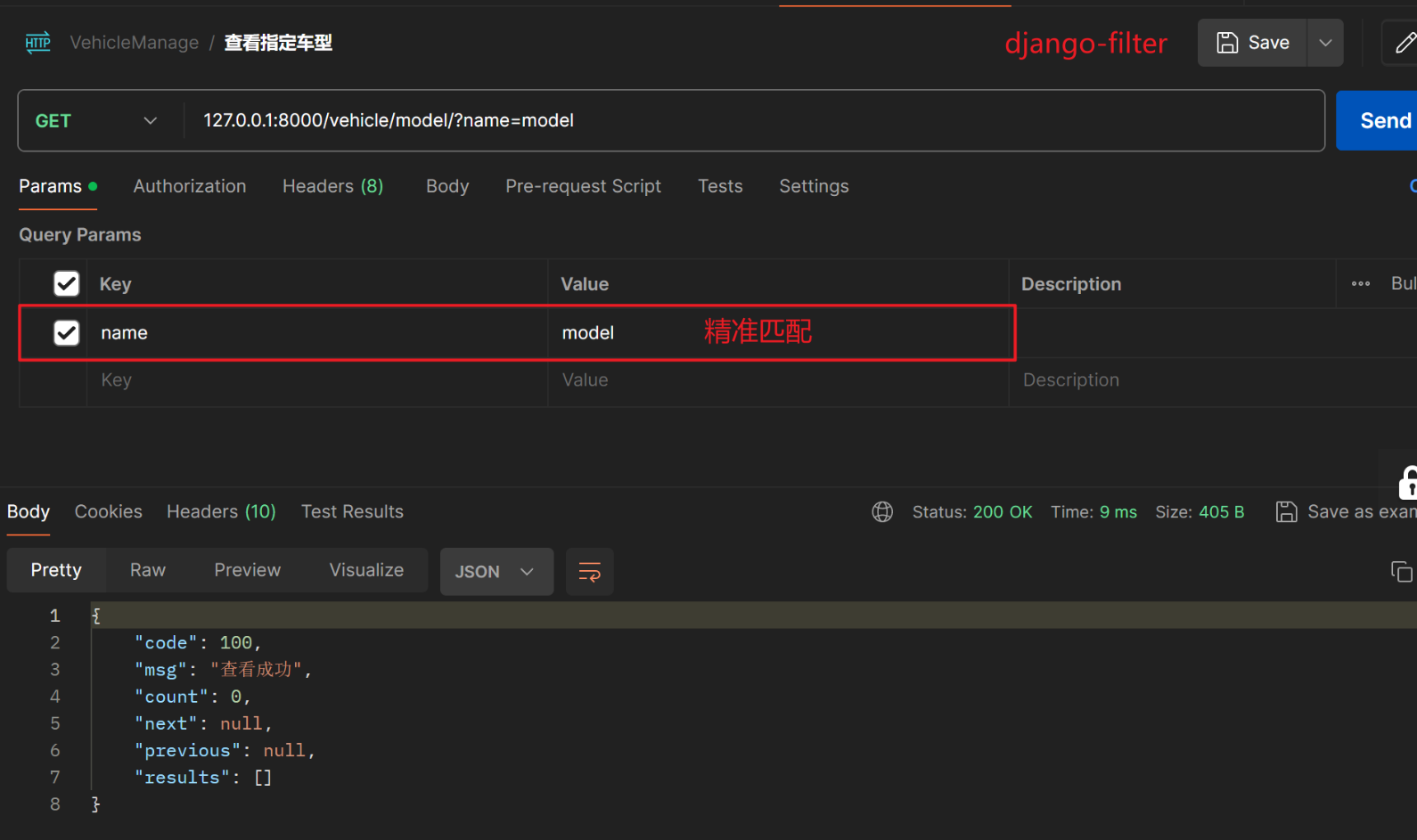
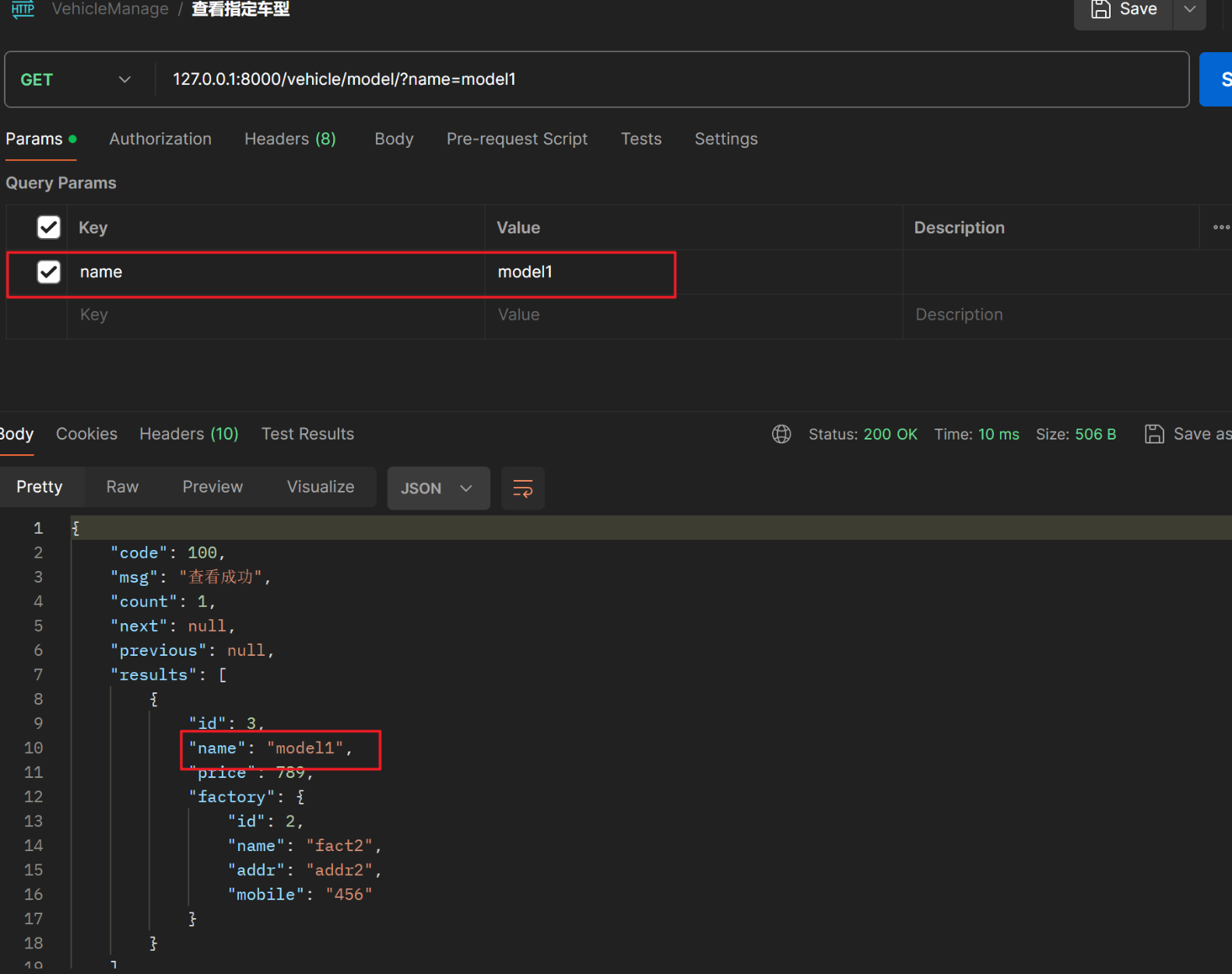
【2】第三方模块Django-filter
django-filter 功能还挺强大的,此处只演示精准匹配,其他过滤请移步官方文档或搜索一下
常用自定义过滤器或drf自带的就够用了
# 精准匹配
from django_filters.rest_framework import DjangoFilterBackend
class CarModelView(ModelViewSet):
queryset = CarModel.objects.all()
serializer_class = CarModelSerializer
# 第三方过滤模块,精准过滤
filter_backends = [DjangoFilterBackend]
# 以车型的名称过滤
filterset_fields = ['name']
【3】自定义过滤
# 继承【BaseFilterBackend】
from rest_framework.filters import BaseFilterBackend
class 过滤类(BaseFilterBackend):
# 重写 【filter_queryset】 方法
def filter_queryset(self, request, queryset, view):
'''
:param request: request对象
:param queryset: 待过滤的qs对象
:param view: 视图类
:return: 过滤后的qs
'''
return filtered_queryset
【3.1】实例
from rest_framework.filters import BaseFilterBackend
from django.db.models import Q
class CommonFilter(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
# 获取传入的参数
query_params = request.query_params
# 过滤书名
title = query_params.get('title')
# 比gt的值大
price_gt = query_params.get('price_gt')
# 比lt的值小
price_lt = query_params.get('price_lt')
if all([title, price_lt, price_gt]):
queryset = queryset.filter(Q(title__contains=title) | Q(price__gt=price_gt, price__lt=price_lt))
elif title:
queryset = queryset.filter(title__contains=title)
elif all([price_lt, price_gt]):
queryset = queryset.filter(price__gt=price_gt, price__lt=price_lt)
elif price_lt:
queryset = queryset.filter(price__lt=price_lt)
elif price_gt:
queryset = queryset.filter(price__gt=price_gt)
else:
pass
return queryset
【二】排序
# 排序使用drf自带的排序即可
from rest_framework.filters import OrderingFilter
# 也可以自定义 # 继承BaseFilterBackend # 重写【filter_queryset】方法即可
from rest_framework.filters import BaseFilterBackend
【1】OrderingFilter
from rest_framework.filters import OrderingFilter
- 常用的属性
ordering_param:- 这个属性用来定义用于排序的查询参数的名称。默认值是
"ordering"。当你想要通过 URL 参数来控制排序时,这是使用的参数名。
- 这个属性用来定义用于排序的查询参数的名称。默认值是
ordering_fields:- 这个属性定义了可以用于排序的字段列表。如果未指定此属性,则允许对所有模型字段进行排序。
- 指定这个属性后,只有在这个列表中的字段才可以用来排序。
ordering_description:- 用于描述排序参数的用途,这主要用于 API 文档和浏览器界面中。
【1.1】使用
class BookView(GenericViewSet, RetrieveModelMixin, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
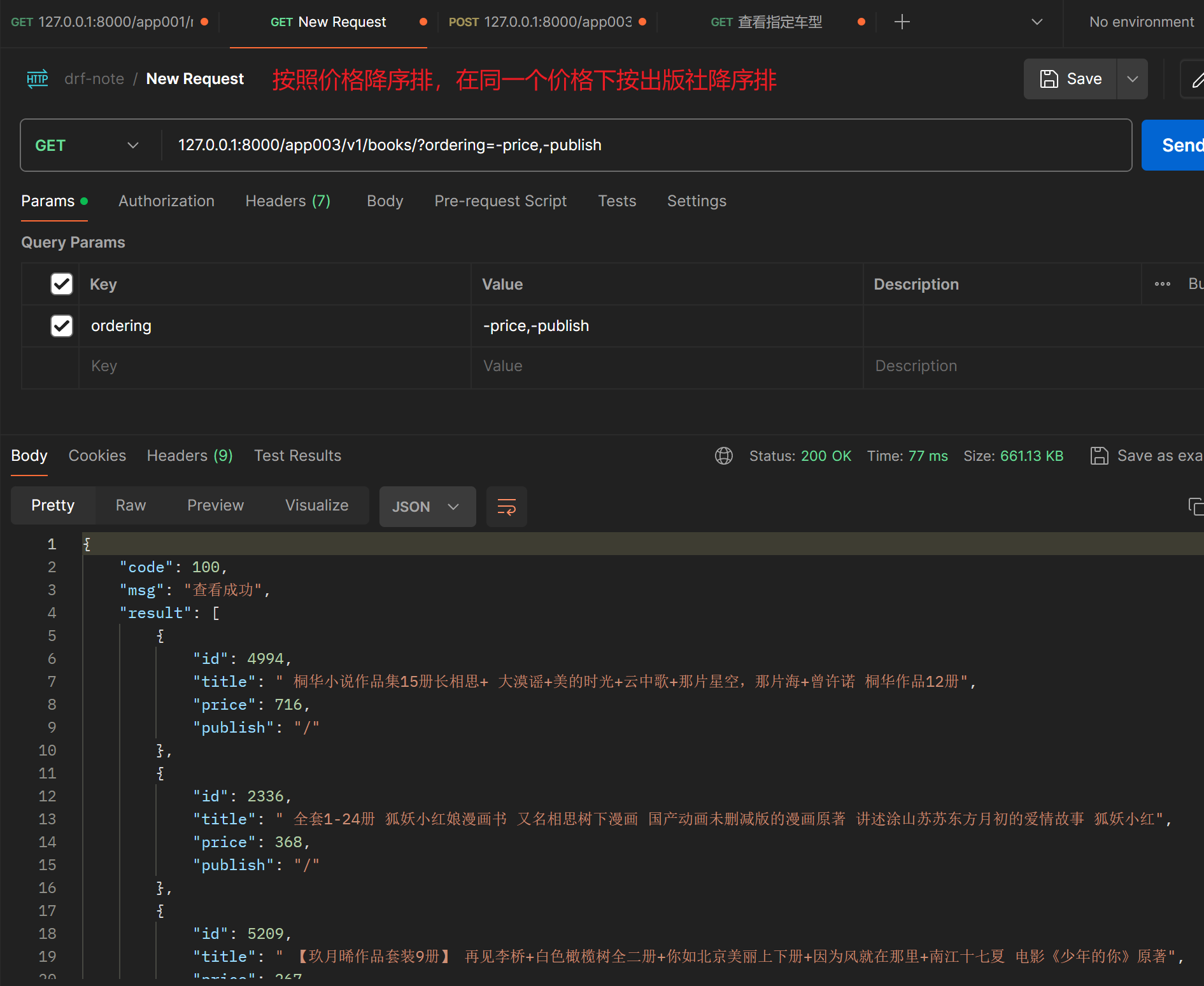
# 排序
filter_backends = [OrderingFilter]
ordering_fields = ['price', 'publish']
- 【注】只有在
ordering_fields中的字段使用ordering=字段才生效
【三】分页
# 分页drf自带了三种 # 基本上这三种也够用了
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
【1】PageNumberPagination
from rest_framework.pagination import PageNumberPagination
class CommonPagePagination(PageNumberPagination):
page_size = 2 # 每页展示2条数据
page_query_param = 'page' # 通过page参数指定页数
page_size_query_param = 'size' # 通过size指定展示条数
max_page_size = 10 # 最大的size条数 # 用户如果输入超过也只展示10条
last_page_strings = ('last',) # 通过page=last 可以跳转到最后一页
# 可以通过重写【get_paginated_response】方法定义返回格式
def get_paginated_response(self, data):
return Response({
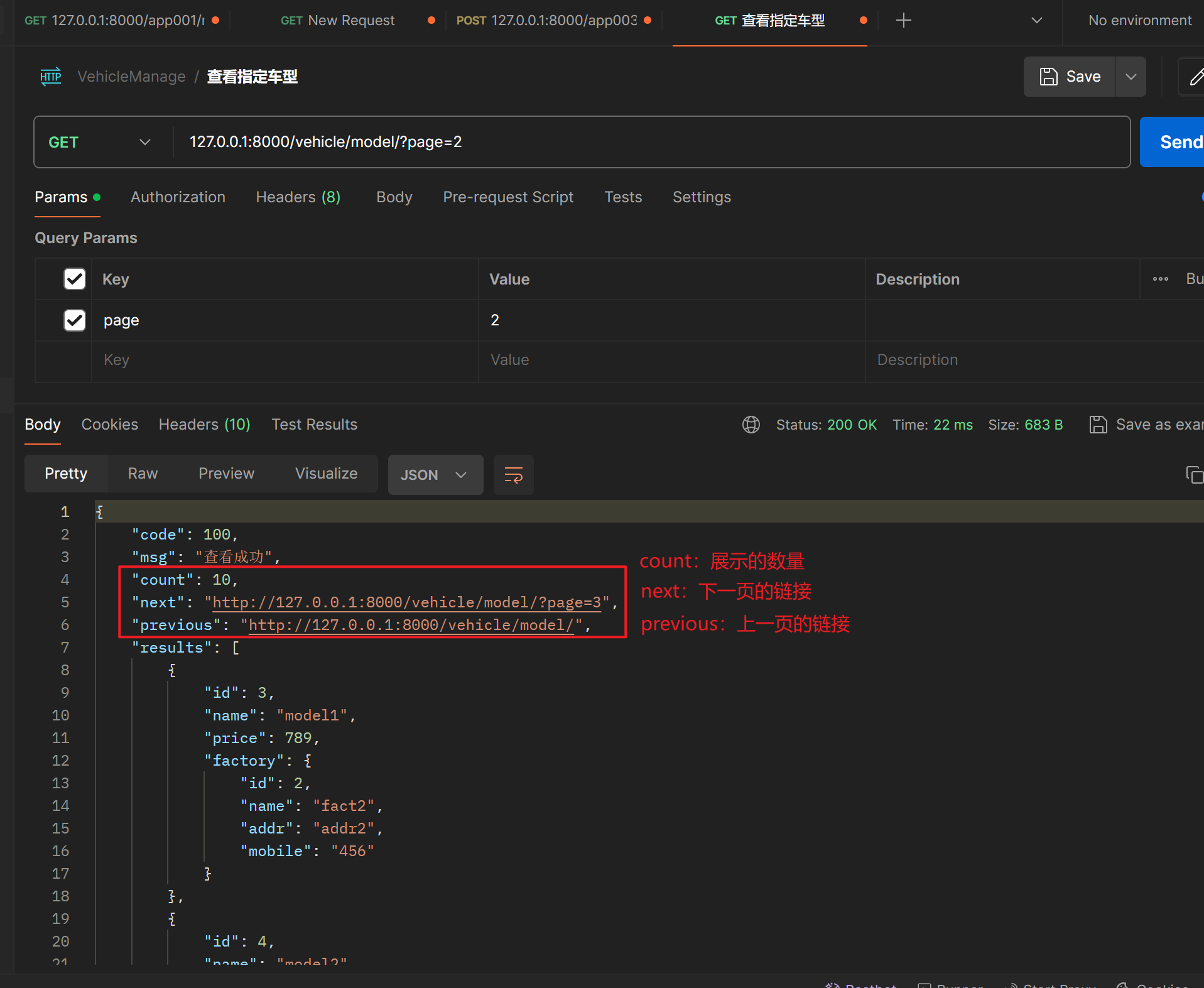
'code': 100,
'msg': '查看成功',
'count': self.page.paginator.count,
'next': self.get_next_link(),
'previous': self.get_previous_link(),
'results': data,
})
- 常用属性
page_size:- 每页返回的数据数量,默认为
None,表示不进行分页,返回所有数据。
- 每页返回的数据数量,默认为
page_size_query_param:- 用于指定每页数据量的查询参数名称,默认为
"page_size"。 - 可以通过 URL 查询参数来指定每页返回的数据量。
- 用于指定每页数据量的查询参数名称,默认为
max_page_size:- 每页数据量的最大值,默认为
None,表示不做限制。 - 如果用户指定的每页数据量超过
max_page_size,则会返回max_page_size的数据量。
- 每页数据量的最大值,默认为
page_query_param:- 用于指定页码的查询参数名称,默认为
"page"。 - 可以通过 URL 查询参数来指定要获取的页码。
- 用于指定页码的查询参数名称,默认为
page_size_query_description:- 用于描述每页数据量查询参数的用途,通常在 API 文档和浏览器界面中使用。
下述图片与上述展示代码不一致,设置的size 为10
############ 下图的count指的是数据总数为10,不是展示的数量 ##############
【2】LimitOffsetPagination
################### pagination.py ############
from rest_framework.pagination import LimitOffsetPagination
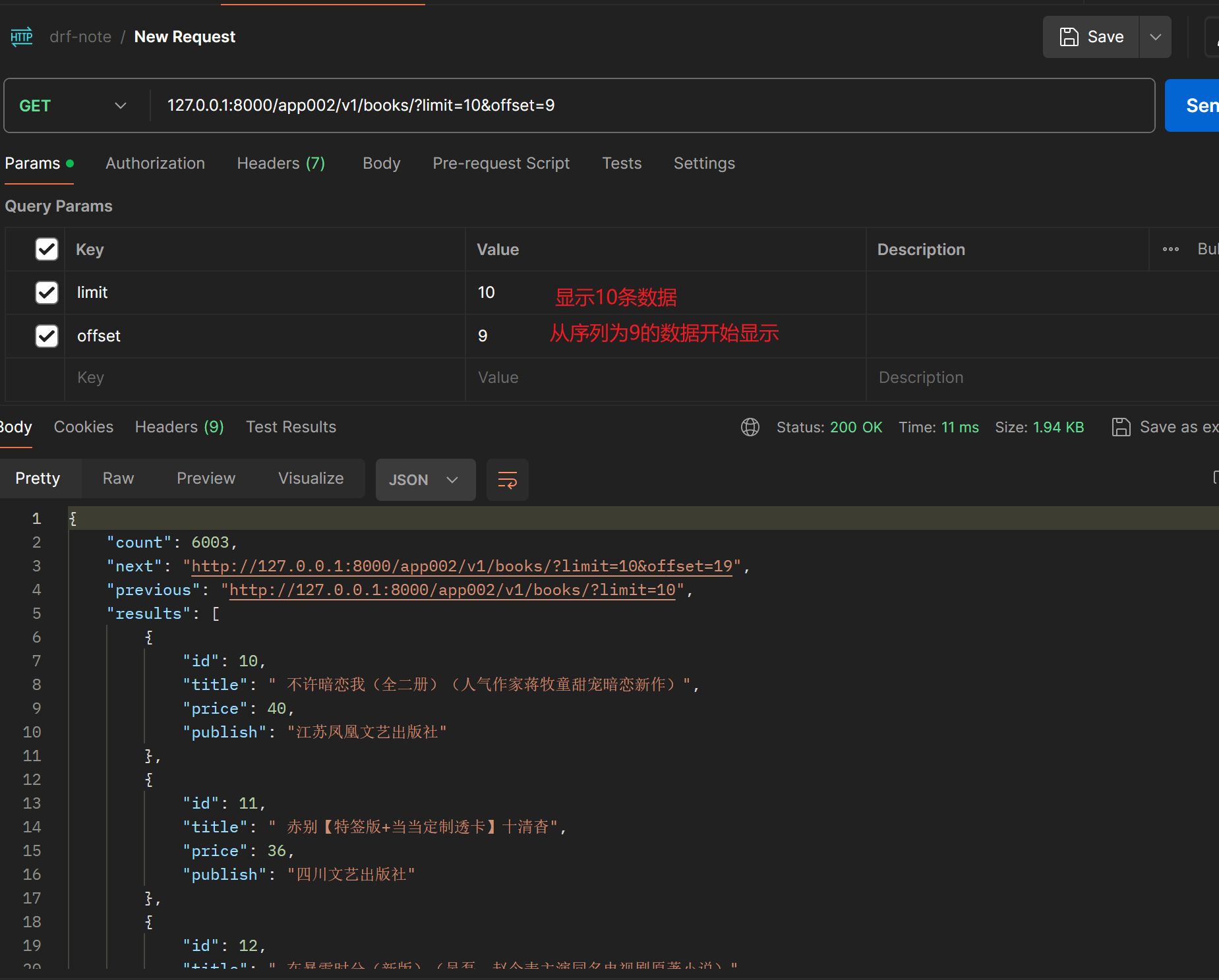
class CommonPagination(LimitOffsetPagination):
default_limit = 5
limit_query_param = 'limit'
offset_query_param = 'offset'
max_limit = 10
##################### views.py ########
class BookView(GenericViewSet, RetrieveModelMixin, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
# 【注】 分页只能使用一个,所以不需要使用列表
pagination_class = CommonPagination
- 常用属性
default_limit:- 默认的每页返回的数据数量,如果未指定,则默认为
None,表示不进行分页,返回所有数据。
- 默认的每页返回的数据数量,如果未指定,则默认为
limit_query_param:- 用于指定每页数据量的查询参数名称,默认为
"limit"。 - 可以通过 URL 查询参数来指定每页返回的数据量。
- 用于指定每页数据量的查询参数名称,默认为
offset_query_param:- 用于指定偏移量的查询参数名称,默认为
"offset"。 - 可以通过 URL 查询参数来指定数据的偏移量。
- 用于指定偏移量的查询参数名称,默认为
max_limit:- 每页数据量的最大值,默认为
None,表示不做限制。 - 如果用户指定的每页数据量超过
max_limit,则会返回max_limit的数据量。
- 每页数据量的最大值,默认为
limit_query_description:- 用于描述每页数据量查询参数的用途,通常在 API 文档和浏览器界面中使用。
offset_query_description:- 用于描述偏移量查询参数的用途,通常在 API 文档和浏览器界面中使用。
【3】CursorPagination
################### pagination.py ############
from rest_framework.pagination import CursorPagination
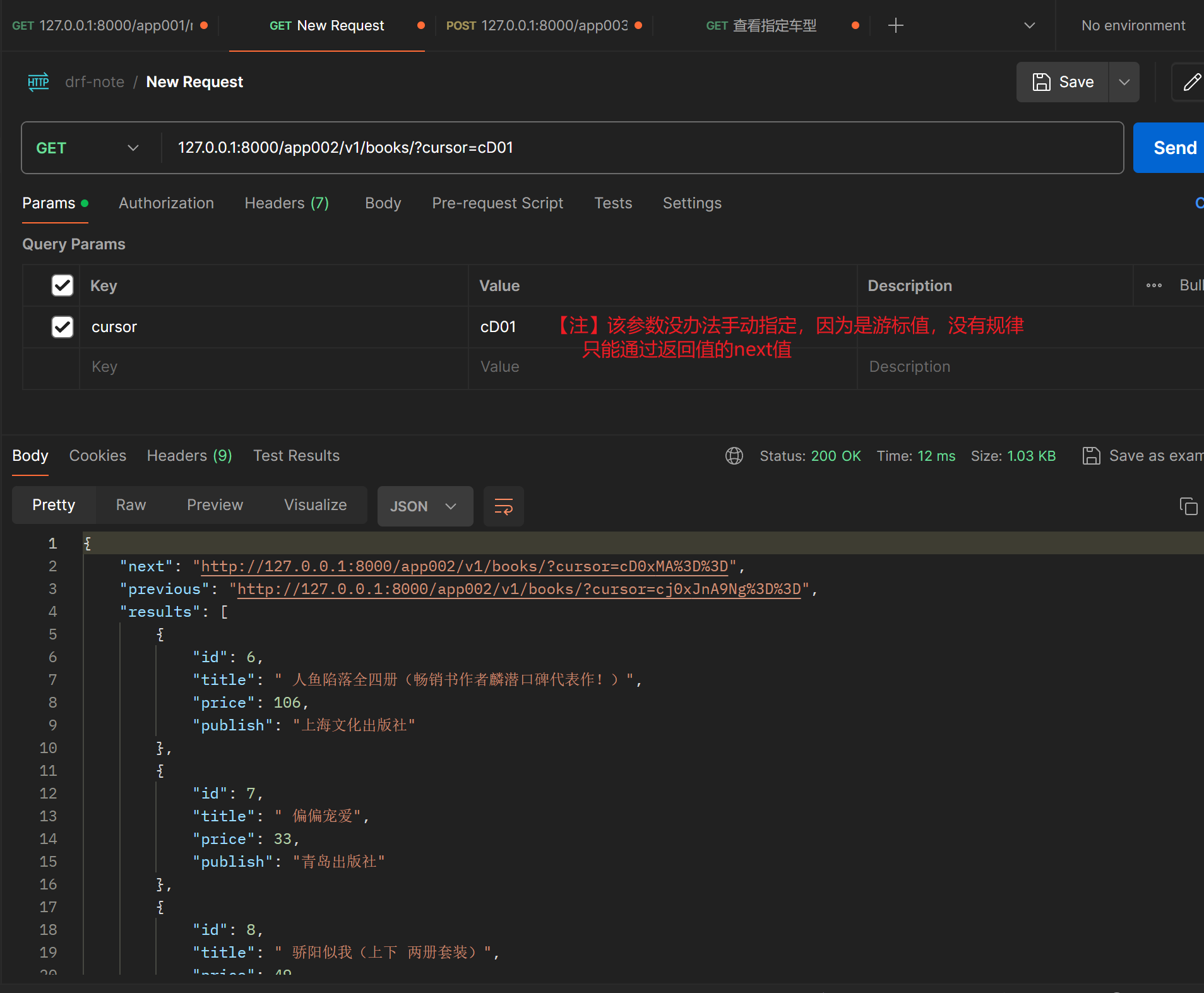
class CommonCursorPagination(CursorPagination):
cursor_query_param = 'cursor'
page_size = 5
ordering = 'id' # 该排序字段必须是数据中包含的
max_page_size = 20
##################### views.py ########
class BookView(GenericViewSet, RetrieveModelMixin, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
# 【注】 分页只能使用一个,所以不需要使用列表
pagination_class = CommonCursorPagination
- 常用属性
ordering:- 用于指定用于排序的字段或字段列表。必须是模型中存在的字段。
- 排序字段用于确保结果集的一致性,并允许游标分页正常工作。
cursor_query_param:- 用于指定游标查询参数名称,默认为
"cursor"。 - 客户端通过这个查询参数传递游标值。
- 用于指定游标查询参数名称,默认为
page_size:- 每页返回的数据数量,默认为
None,表示不进行分页,返回所有数据。
- 每页返回的数据数量,默认为
max_page_size:- 每页数据量的最大值,默认为
None,表示不做限制。 - 如果用户指定的每页数据量超过
max_page_size,则会返回max_page_size的数据量。
- 每页数据量的最大值,默认为
cursor_page_query_param:- 用于指定游标分页查询参数名称,默认为
"page"。 - 客户端通过这个查询参数指定要获取的页码。
- 用于指定游标分页查询参数名称,默认为
cursor_page_size:- 每次查询返回的最大结果集大小,默认为
None,表示不做限制。 - 如果结果集大小超过
cursor_page_size,则可能会被截断。
- 每次查询返回的最大结果集大小,默认为
【4】三种分页方式的区别
这三种分页方式在实现上有一些区别,主要体现在以下几个方面:
- 分页原理:
- PageNumberPagination:基于页码的分页方式,客户端通过指定页码来请求相应页的数据。
- LimitOffsetPagination:基于偏移量和限制数量的分页方式,客户端通过指定偏移量和每页数据数量来请求数据。
- CursorPagination:基于游标的分页方式,客户端通过游标来请求数据,游标指向结果集中的某个特定位置。
- 适用场景:
- PageNumberPagination:适用于数据量相对较小且页码比较直观的场景,例如博客文章列表等。
- LimitOffsetPagination:适用于需要精确控制数据范围的场景,但可能存在性能问题,特别是在数据量较大时。
- CursorPagination:适用于数据量较大、需要快速高效获取数据、或者需要实现无限滚动等需求的场景,因为它不需要在每次请求时计算偏移量,性能更好。
- 性能影响:
- PageNumberPagination 和 LimitOffsetPagination 都需要在每次请求时计算偏移量,因此在处理大数据量时可能存在性能问题,特别是在接近数据末尾时。
- CursorPagination 通过游标来定位数据,避免了每次请求都重新计算偏移量,因此在处理大数据量时性能更好,尤其是在数据集增长时。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号