爬虫初识
爬虫初识
【一】爬虫介绍
【1】定义
- 爬虫是一种自动化获取互联网数据的技术,通过模拟浏览器行为,向目标网站发送请求并获取响应,然后解析响应中的数据。
- 应用领域:爬虫可以应用于各种网站数据的获取
【2】工作原理
- 爬虫通过发送HTTP请求,模拟浏览器行为,获取网站的响应,并解析响应中的数据。
【3】分类
- 通用爬虫 vs. 专用爬虫:
- 通用爬虫:用于抓取互联网上的大量网页,如搜索引擎爬虫(例如Googlebot、Bingbot等)。
- 专用爬虫:针对特定的网站、领域或任务设计,如价格比较爬虫、新闻聚合爬虫等。
- 按照工作方式分类:
- 单线程爬虫:一次只能处理一个请求的爬虫。
- 多线程/并发爬虫:可以同时处理多个请求,提高爬取效率。
- 异步爬虫:利用异步编程技术,在发送请求时不会阻塞程序的执行,可以更高效地处理大量的请求。
- 按照爬取深度分类:
- 表面爬虫:只爬取网页上的静态内容,不会深入到网页内部的链接。
- 深度爬虫:会跟踪网页内部的链接,继续爬取链接指向的页面,形成一个更深的爬取结构。
- 按照目标网站类型分类:
- 静态网站爬虫:用于爬取静态网页的内容。
- 动态网站爬虫:能够处理JavaScript等动态内容,爬取动态网页的内容。
- 基于数据获取方式分类:
- 基于API的爬虫:通过调用网站提供的API接口获取数据。
- 基于页面解析的爬虫:直接解析网页内容获取数据。
【4】Python爬虫的常用库
-
requests库
- 用于发送HTTP请求,方便地发送GET、POST等请求,并获取响应。
- 应用领域:爬虫可以使用requests库来发送请求和获取响应。
-
BeautifulSoup库
-
用于解析HTML和XML文档,方便地提取其中的数据。
-
应用领域:爬虫可以使用BeautifulSoup库来解析网页并提取需要的数据。
-
-
Selenium库
- 用于模拟浏览器行为,模拟用户在浏览器中的操作,如点击、输入等。
- 应用领域:爬虫可以使用Selenium库来模拟用户行为,获取需要的数据。
-
Scrapy框架
-
提供了一套完整的爬虫开发流程,包括发送请求、获取响应、解析响应、存储数据等步骤。
-
应用领域:爬虫可以使用Scrapy框架进行爬虫开发。
-
【5】爬虫的注意事项
-
爬虫的合法性
- 在进行爬虫开发时,需要遵守相关的法律法规,如《计算机软件保护条例》、《互联网信息服务管理办法》等。
-
爬虫的速度
- 需要注意爬虫的速度,避免对目标网站造成过大的负担。
-
爬虫的稳定性
- 需要注意爬虫的稳定性,避免因为网络波动等原因导致爬虫中断。
-
爬虫的数据存储
- 需要注意数据的存储方式,避免因为数据量过大导致存储不足。
【6】爬虫的基本流程
- 确定爬取目标:
- 确定要爬取的网站或者网页。
- 确定要提取的信息类型,例如文本、图片、链接等。
- 发送HTTP请求:
- 向目标网站发送HTTP请求,请求页面的内容。
- 可能需要设置请求头,包括用户代理信息等,以模拟正常浏览器行为。
- 获取网页内容:
- 接收网站返回的响应,获取页面的HTML代码或其他标记语言。
- 可能需要处理响应,例如处理重定向、处理HTTP错误等。
- 解析网页内容:
- 使用解析库(如Beautiful Soup、lxml等)解析HTML或其他标记语言,提取出所需信息。
- 根据需要,可能需要使用正则表达式或XPath来定位和提取特定的内容。
- 处理数据:
- 对提取的数据进行清洗、转换、去重等处理,以确保数据的质量和一致性。
- 可能需要将数据存储到数据库、文件或者其他数据存储介质中。
- 存储数据:
- 将处理后的数据存储到指定的存储介质中,如数据库、文件系统等。
- 根据需求,可能需要定期更新已存储的数据。
- 处理链接:
- 如果需要爬取更多页面,解析当前页面中的链接,将新的链接加入爬取队列。
- 保持跟踪已经爬取的页面,避免重复爬取或者进入死循环。
- 控制爬取速度:
- 为了避免对目标网站造成过大的负担或者被封禁,需要控制爬取速度,避免过快地发送请求。
- 可以使用延时等手段来控制爬取速度。
- 处理异常情况:
- 处理网络请求超时、页面解析错误等异常情况,确保爬虫的稳定性和健壮性。
- 可以记录日志、发送警报等方式来监控和处理异常情况。
【7】常见的反爬虫措施
-
频率限制
-
网站会针对某个IP地址或用户账号设置请求频率限制,如单位时间内只允许发送一定数量的请求。
-
一旦超出限制,网站会对该IP或账号进行处罚,如暂时封禁或限制访问。
-
-
封IP和封账号
-
网站可以通过监测异常行为,如频繁请求、高并发等来判断是否有恶意爬取行为,并对相关IP地址或账号进行封禁。
-
为了规避封禁,爬虫可以使用代理池来随机切换IP地址,或使用大量小号(账号池)轮流发送请求。
-
-
请求头中带加密信息
-
网站可能要求请求头中包含特定的加密信息,如Referer(来源页面地址)和User-Agent(浏览器标识),用于验证请求的合法性。
-
爬虫需要模拟真实浏览器的请求头信息,以避免被检测为非法爬虫。
-
-
响应回来的数据是加密
-
为了防止直接获取数据,网站可能会对返回的数据进行加密或编码,爬虫需要解密或解码才能获取到有效信息。
-
这种情况下,爬虫可能需要分析加密算法或从其他渠道获取解密密钥。
-
-
验证码反扒
-
网站为了防止机器自动注册、恶意爬取等行为,可能会在关键操作前设置验证码。
-
爬虫需要通过第三方平台或自己破解验证码来进行自动化操作。
-
-
JS加密
-
网站可能使用JavaScript对核心代码进行了压缩和混淆,以
ers() -> function()的形式,ers.somethin() -> function somethin(),并添加了一些晦涩的加密方法。 -
爬虫需要逆向工程来还原和理解这些加密算法,并编写相应的代码进行解密。
-
-
手机设备唯一ID号
-
网站可能会根据爬虫请求的设备唯一标识符(例如IMEI、Android ID、iOS设备ID等)进行识别和限制。
-
爬虫可能需要模拟不同设备的请求,或者通过修改设备信息达到绕过检测的效果。
-
需要注意的是,对于某些网站,爬虫绕过这些反爬虫措施可能涉及到违法行为,建议在合法范围内开展爬虫活动,遵守相关法律法规和网站的使用规定。
【8】补充知识
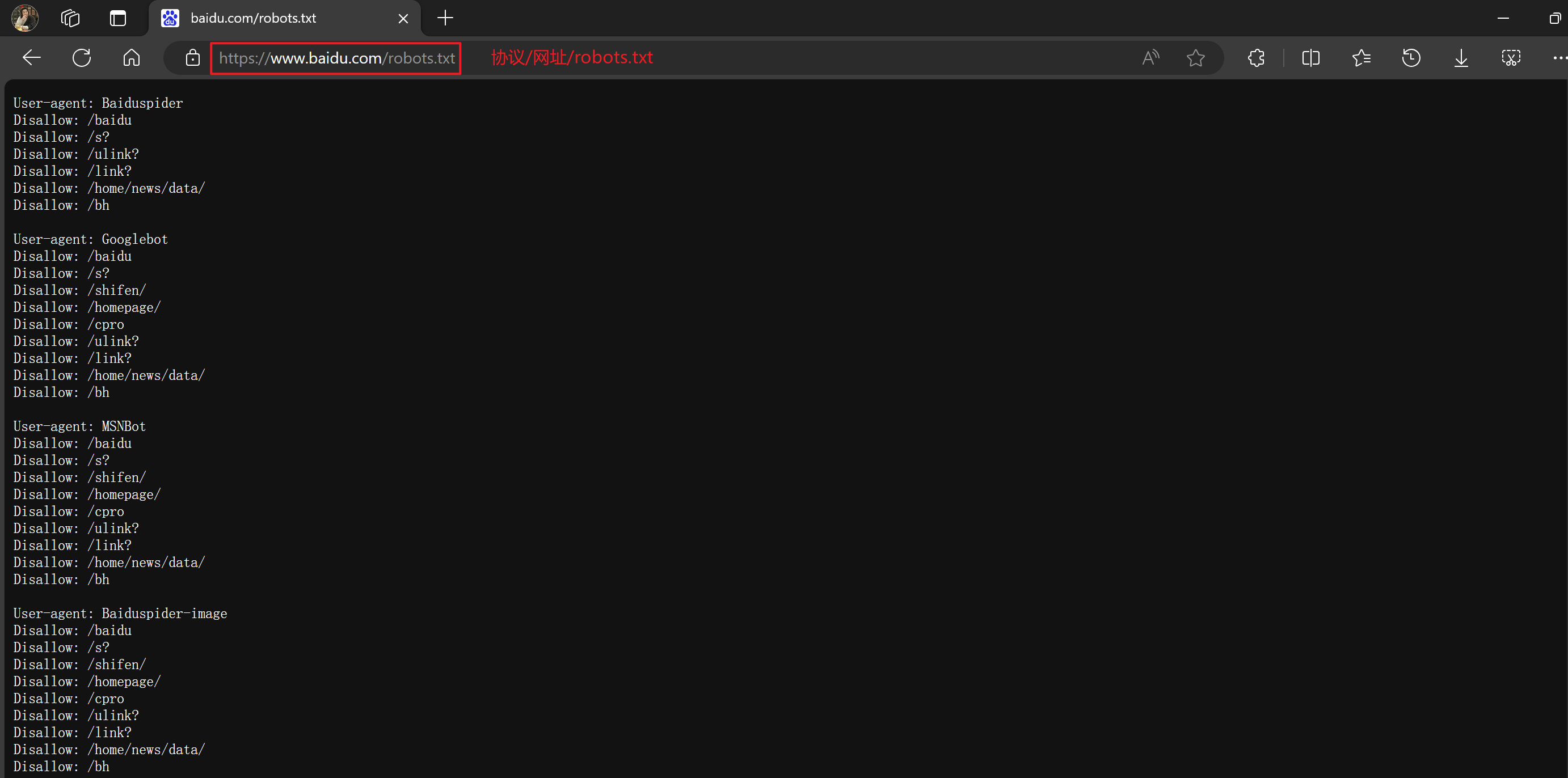
【8.1】爬虫协议robots.txt
-
"robots.txt" 是一种遵循 Robot Exclusion Protocol(机器人排除协议)的文本文件,用于向网络爬虫指示它们是否可以访问和抓取网站上的特定页面或内容。这个协议是为了让网站管理员能够控制搜索引擎爬虫(也称为网络爬虫或网络机器人)的行为,以避免过度访问或抓取网站,或者保护敏感内容不被抓取。
-
在网站的根目录下放置一个名为 "robots.txt" 的文件,然后在这个文件中定义一些规则,来告诉搜索引擎爬虫哪些页面可以访问,哪些不可以访问。这个文件可以包含一些规则,如:
-
User-agent: 指定适用于哪些爬虫的规则。比如 "*" 代表适用于所有爬虫。
-
Disallow: 指定不允许访问的页面或目录。
-
Allow: 指定允许访问的页面或目录。
-
Crawl-delay: 指定爬取的延迟时间,以控制爬虫的访问频率。
-
【8.2】seo优化 和 sem优化
【8.2.1】seo优化
SEO(Search Engine Optimization,搜索引擎优化)是一种通过改善网站结构、内容质量和相关性,以及增加外部链接等手段,来提高网站在搜索引擎中的排名和可见性的策略和技术。以下是一些常见的SEO优化方法:
- 关键词研究与优化:
- 通过分析用户搜索习惯和竞争对手,确定目标关键词。
- 将关键词合理地分布在网站标题、描述、内容和URL中。
- 网站结构优化:
- 确保网站结构清晰,易于导航和理解。
- 使用简洁的URL结构,包含关键词,并避免动态参数。
- 使用HTML标签(如
<h1>、<h2>等)来组织内容,并提高关键词的权重。
- 内容优化:
- 创作高质量、有价值、原创的内容,吸引用户点击和分享。
- 使用多媒体内容(如图片、视频)丰富页面,提高用户体验。
- 更新和优化旧内容,保持网站活跃性和权威性。
- 内部链接优化:
- 在网站内部建立良好的内部链接结构,方便用户和搜索引擎爬虫浏览和索引网站。
- 使用相关的锚文本(anchor text)进行内部链接,提高关键词的相关性。
- 外部链接建设:
- 获取高质量的外部链接(Backlinks),提高网站的权威性和可信度。
- 通过合作、内容营销、社交媒体等方式,增加外部链接的数量和质量。
- 技术性优化:
- 优化网站加载速度,减少页面加载时间。
- 确保网站在不同设备上(如移动设备)的兼容性和可访问性。
- 使用网站地图(sitemap)和robots.txt文件指导搜索引擎爬虫索引网站内容。
- 用户体验优化:
- 确保网站设计简洁清晰,易于浏览和导航。
- 提供高质量的用户体验,包括快速加载速度、易于阅读的内容和简单的操作流程。
【8.2.2】sem优化(花钱买关键字)
SEM(Search Engine Marketing,搜索引擎营销)是一种通过付费方式在搜索引擎中推广网站,以提高网站在搜索结果中的曝光度和点击量的营销方式。与SEO不同,SEM主要是通过付费广告的方式来获得流量和曝光度。以下是一些SEM优化的方法:
- 关键词研究与优化:
- 进行关键词研究,确定最具有商业价值和竞争优势的关键词。
- 选择合适的关键词进行竞价广告投放,以确保广告的曝光度和点击量。
- 广告文案优化:
- 编写吸引人的广告文案,突出产品或服务的特点和优势。
- 使用诱人的呼唤动作(Call-to-Action),鼓励用户点击广告。
- 目标定位与定位优化:
- 确定目标受众,根据其特征和行为定位广告。
- 不断优化广告定位,以提高广告的转化率和投资回报率(ROI)。
- 广告投放策略优化:
- 确定合适的广告投放策略,包括广告投放时间、地域和设备等。
- 不断监测和调整广告投放策略,以适应市场变化和用户需求。
- 监测与分析:
- 定期监测广告效果,包括点击量、转化率、成本等指标。
- 分析广告数据,发现潜在的优化机会和问题,并采取相应的措施进行优化。
- 竞价管理与优化:
- 对竞价广告进行管理和优化,包括调整出价、关键词匹配方式等。
- 优化广告质量得分,以提高广告的排名和质量。
- Landing Page优化:
- 优化广告点击后的着陆页(Landing Page),确保页面内容与广告相关,并提供清晰的转化路径。
- 提高着陆页的加载速度,减少跳出率,提高转化率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号