

MySQL基本语法 约束条件 查询条件
MySQL基础语法
- 在MySQL中,SQL语句都是要以英文状态下的分号结尾【;】
- SQL语句中的中括号部分表示可选
【引】MySQL的基本概念
- 以excel文件举例
【1】库
- 相当于excel所在的文件夹
【2】表
- 相当于excel文件
【3】字段
- 相当于excel文件的表头
【4】记录
- 相当于excel 文件中的一行行数据

【一】注释
- 单行注释:
--,# - 多行注释:
/*+*/
-- 单行注释
# 单行注释
/*
多行注释
*/
【二】针对库的SQL语句
【1】增加库
create database [if not exists] 数据库名 [character set 编码字符集];
-- 示例
create database db1;
create database if not exists db1 charset='utf8mb4';

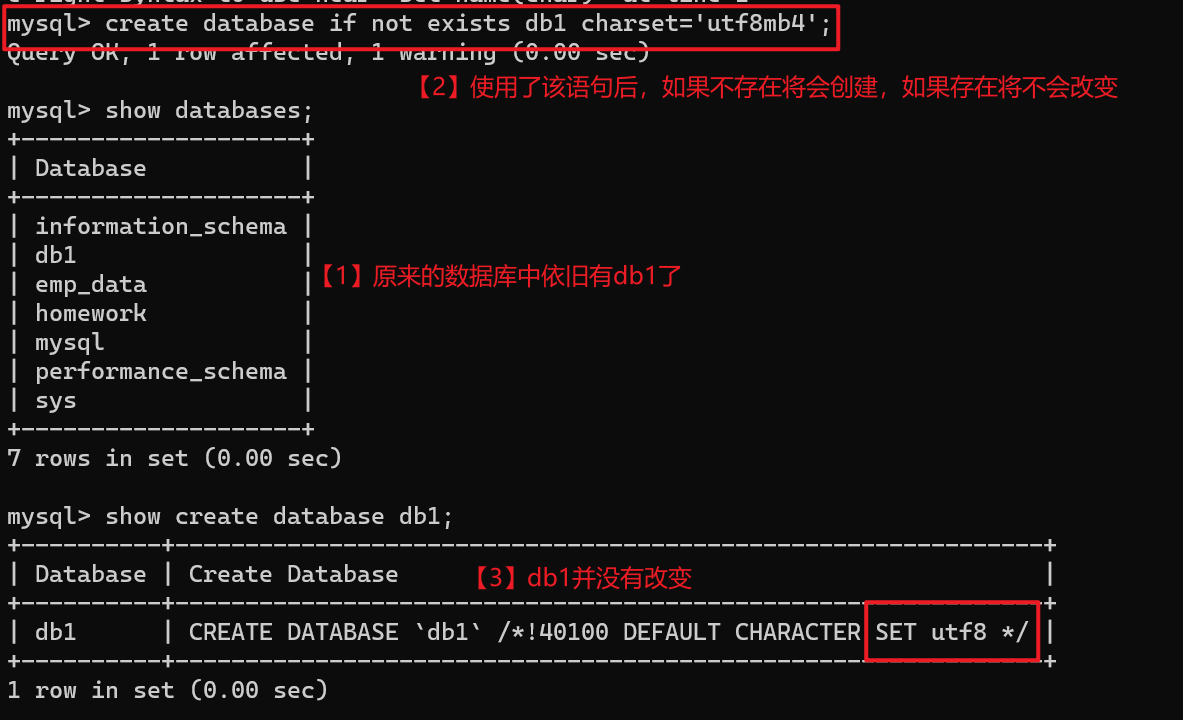
【2】查看库
show databases;
-- 查看库的详细信息
show create database db1;
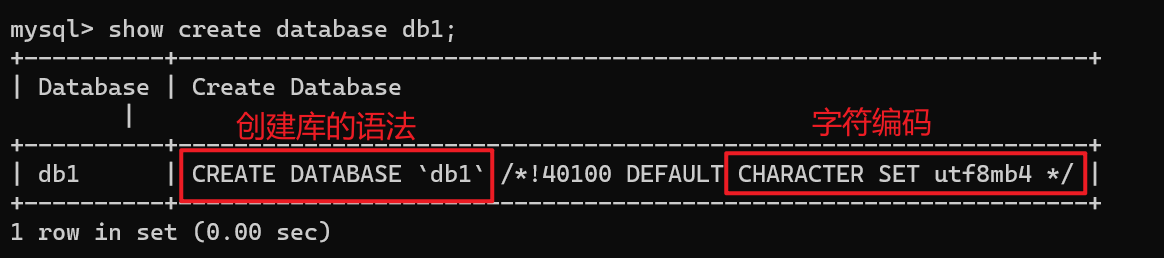
show databases like '%schema'; -- 查看名字中含指定字符的库
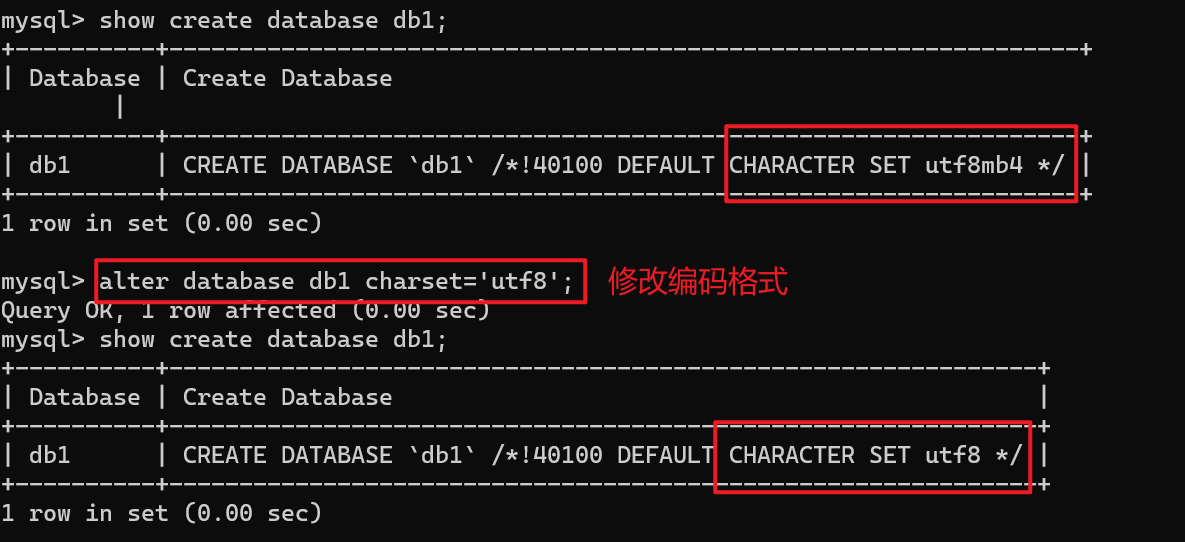
【3】修改库
alter database 数据库名 [character set 编码字符集];
-- 修改库(基本上不用,直接删掉直接创建)
alter database db1 charset='utf8';
【4】删除库
drop database [if exists] 数据库名;
drop database db1;
-- 不要轻易使用(测试环境随便使用,线上环境一般情况下你是没有权限)
【5】以绝对路径的形式操作不同的库
create table db2.t1(id int);
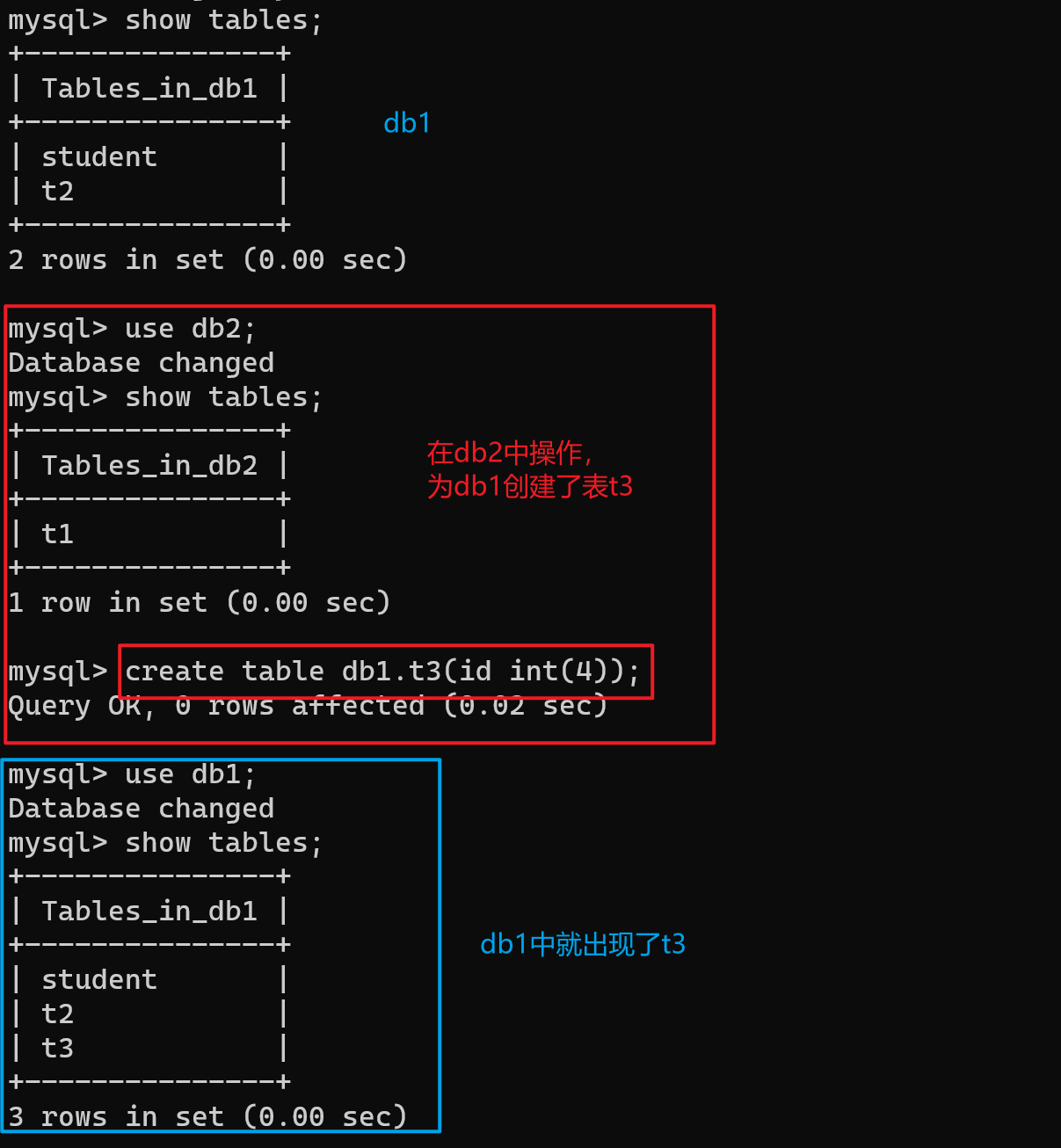
【三】针对表的SQL语句
- 针对表时,需要先进入到库中,才能修改表
use 库名;
-- 相当于双击db1的文件夹
use db1;
-- 进入到某个数据库后没办法再退回之前状态,但可以通过use进行切换

select database(); -- 查看当前使用的数据库
【1】增加表
-- create table 表名,字段名,字段类型 缺一不可
create table [if not exists] 表名 (
字段名1 数据类型[数据修饰符1] [约束条件1],
字段名2 [数据修饰符1] [约束条件1] ,
字段名3 数据类型[数据修饰符1] [约束条件1]
-- 注意,最后一段定义语句,不能有英文逗号的出现,否则报错。
-- 字段名不可以重复
) [engine = 存储引擎 character set 字符集];
-- 示例
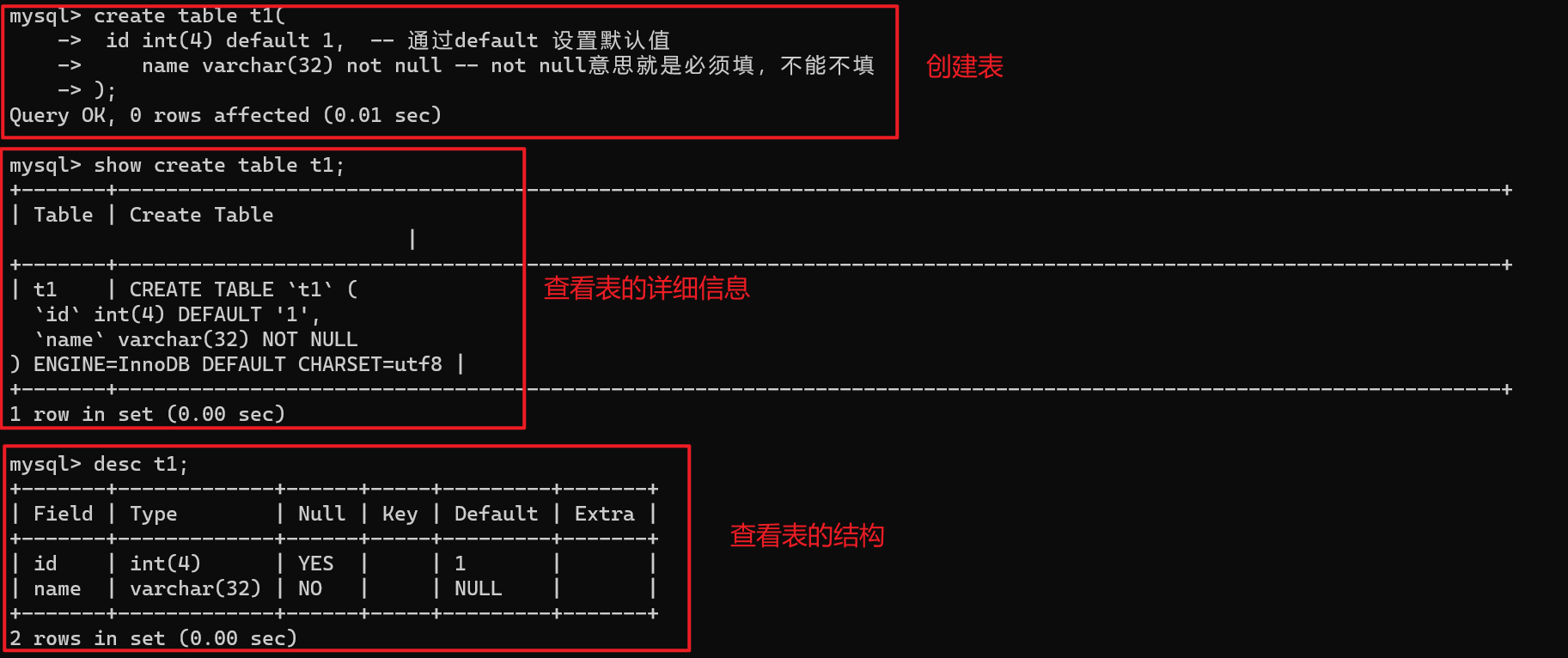
create table t1(
id int(4) default 1, -- 通过default 设置默认值
name varchar(32) not null -- not null意思就是必须填,不能不填
);
【2】查看表
show tables; -- 查看库中的所有表
show create table t1; -- 查看指定表的详细信息
describe t1; -- 查看表结构(完整)
desc t1; -- 查看表结构(简写)
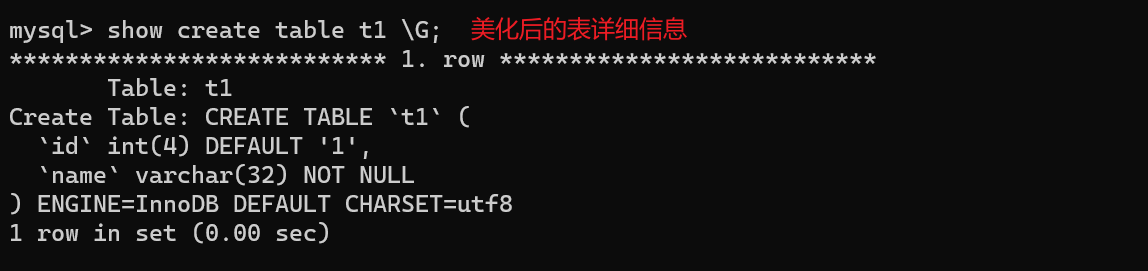
show create table t1 \G;
-- 将表的详细信息格式化,可以美观一些
【3】修改表
-- rename
alter table t1 rename t2; -- 修改表名
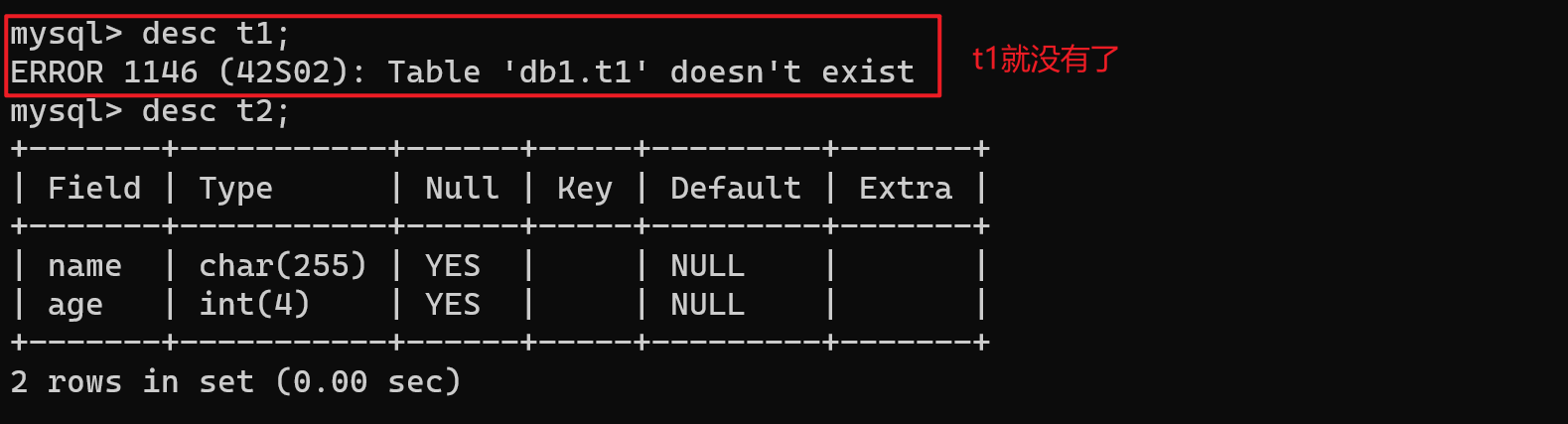
【4】删除表
drop table t2;
truncate table t2; -- 清空表中的数据,但保留结构
- 相当于将excel中,表头下面的数据删除,但保留表头
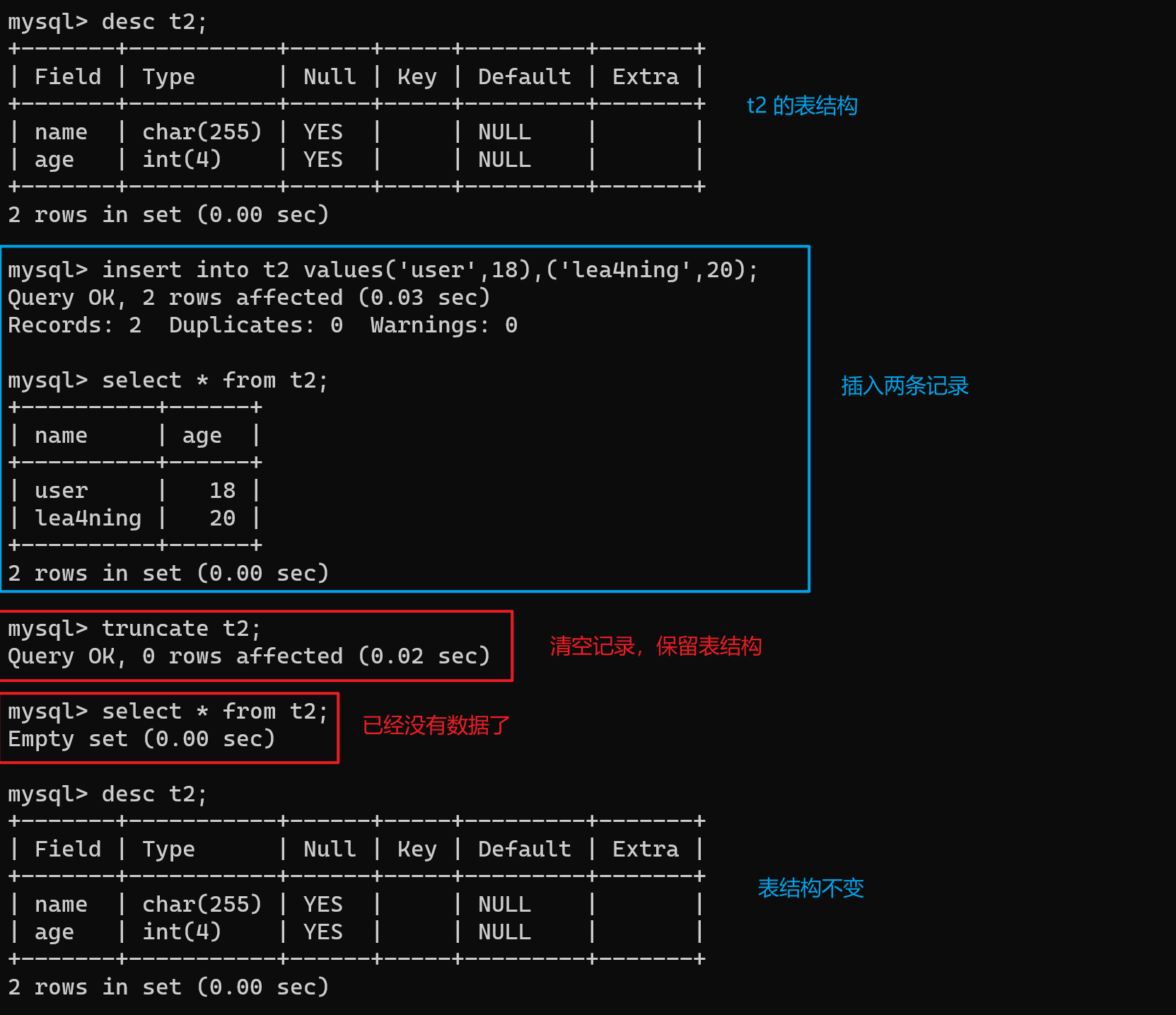
【三】针对字段的SQL语句
【1】查看字段
desc t2; -- 通过查看表结构就可以查看字段的具体信息
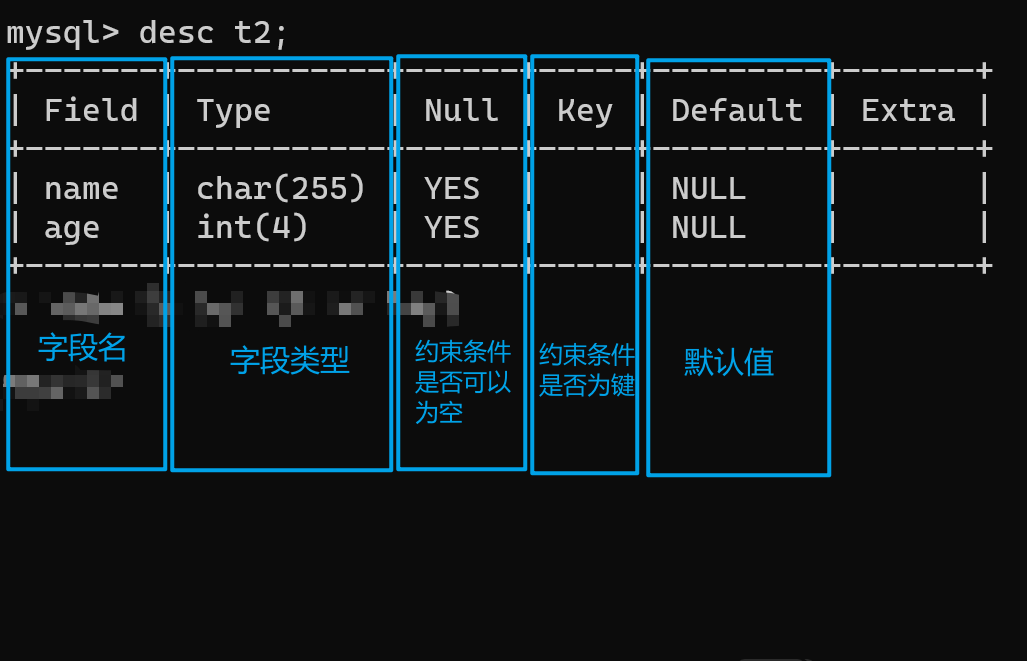
EXTRA列的内容通常包含了与列相关的额外信息,如 AUTO_INCREMENT(自增列)、DEFAULT_GENERATED(默认生成的值,通常与 GENERATED ALWAYS AS 相关)、VIRTUAL GENERATED(虚拟生成列)等。这些信息提供了关于列属性的更多细节。
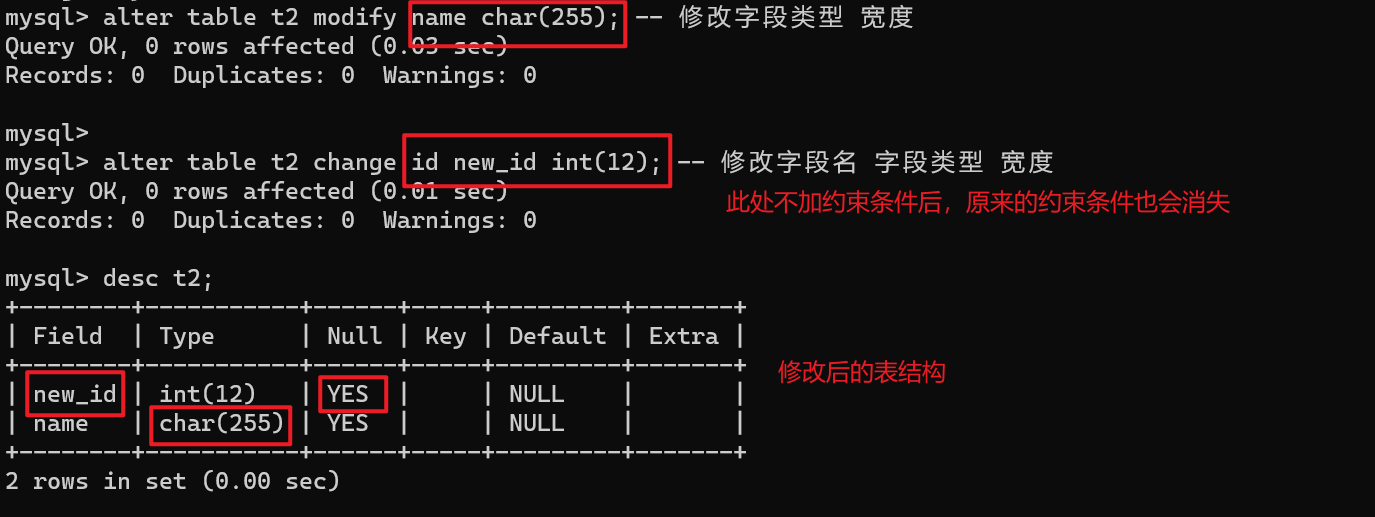
【2】修改字段
-- modify
alter table t2 modify name char(255); -- 修改 字段类型 宽度
-- change
alter table t2 change id new_id int(12); -- 修改字段名 字段类型 宽度
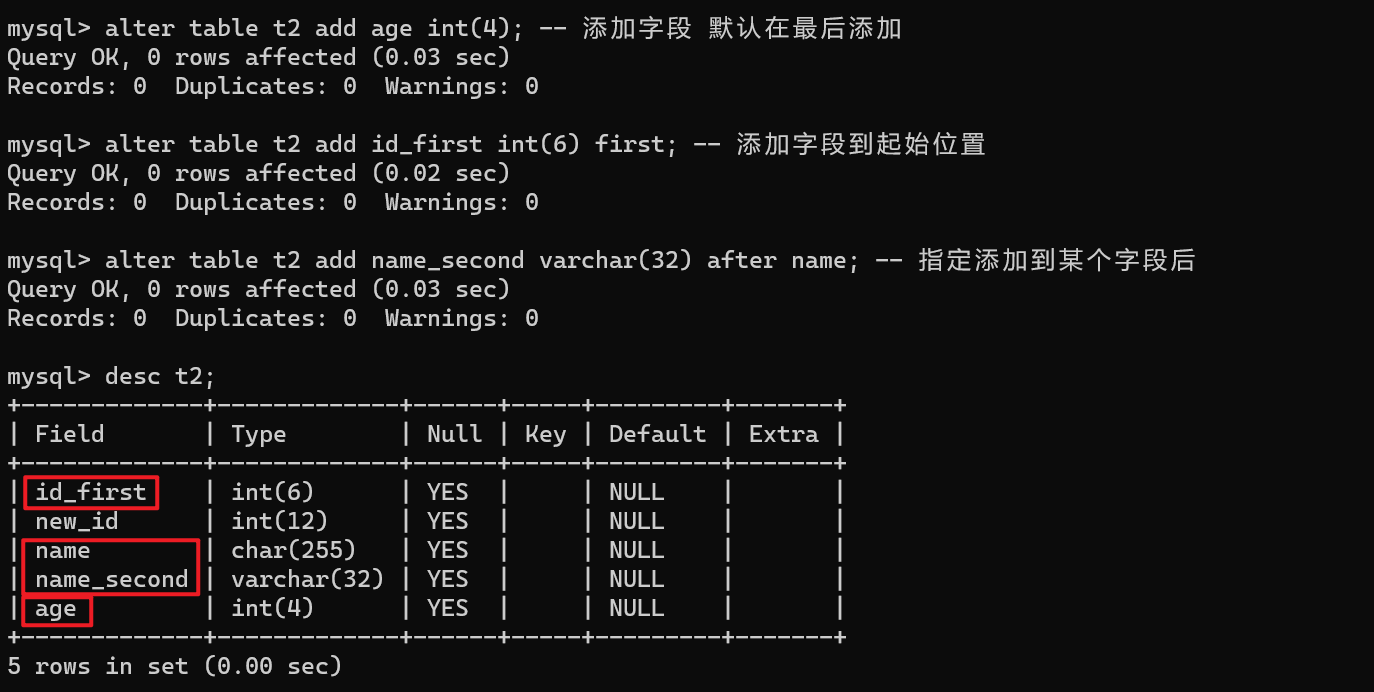
【3】添加字段
-- add
alter table t2 add age int(4); -- 添加字段 默认在最后添加
alter table t2 add id_first int(6) first; -- 添加字段到起始位置
alter table t2 add name_second varchar(32) after name; -- 指定添加到某个字段后
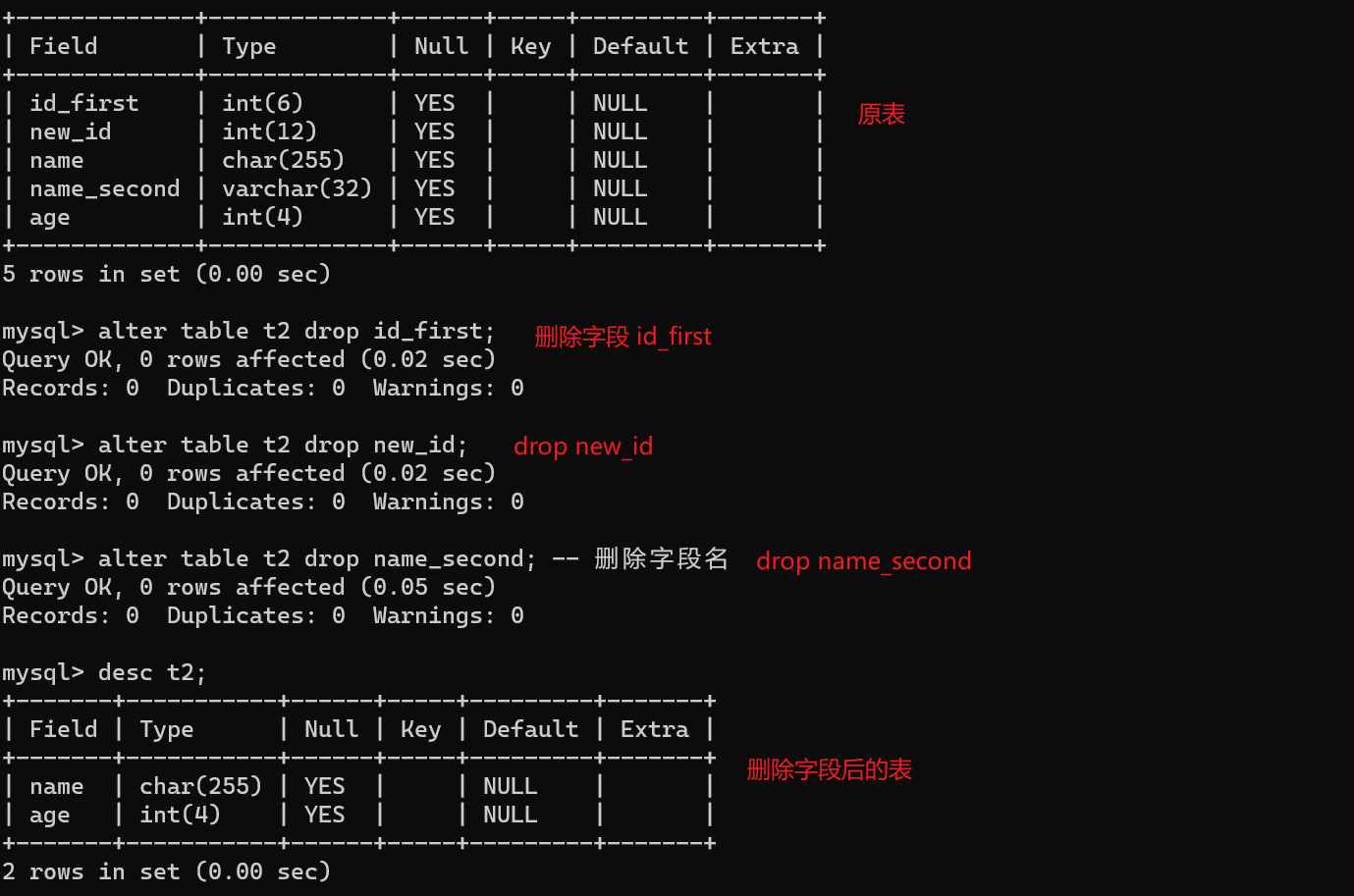
【4】删除字段
-- drop
alter table t2 drop age; -- 删除字段名
【四】针对记录的SQL语句
【1】查看记录
-
数据量大的时候不建议使用
-
数据会冲击服务器导致瘫痪
SELECT *|field1,filed2 ... FROM tab_name
-- 【*】 表示所有信息
-- 【field1】 可以设置查看的字段
-- 示例
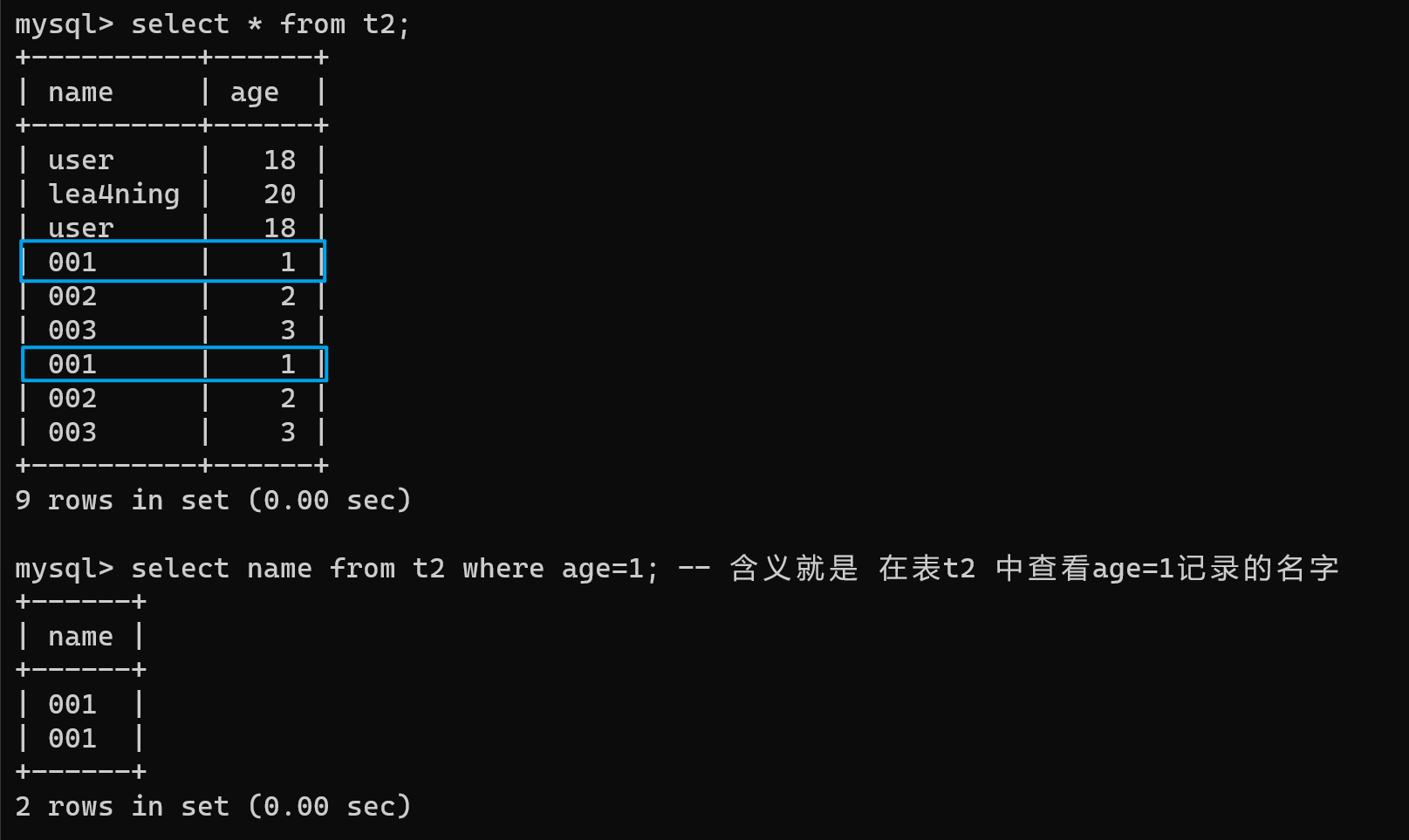
select * from t2;
-- 可以通过设置筛选条件查看指定条件的记录
SELECT *|field1,filed2 ... FROM tab_name 筛选条件;
-- 最简单的就是where 筛选指定内容
-- 关于筛选条件,具体的可看下面的筛选条件章节,会详细介绍
-- 示例
select name from t2 where age=1; -- 含义就是 在表t2 中查看age=1记录的名字
/*执行顺序为
from t2 :查看是否有t2这个表
where age=1 :查看是否有符合age=1这个条件的记录
select name :查看记录中的name值
【2】增加记录
INSERT [INTO] <表名> [ <列名1> [ , … <列名n>] ] VALUES (值1) [… , (值n) ];
-- 示例
insert into t2(name,age) value('user',18);
insert t2(name,age) value('lea4ning',20);
-- 多条数据
insert t2 values('001',1),('002',2),('003',3);
insert into t2(name,age) values('001',1),('002',2),('003',3);
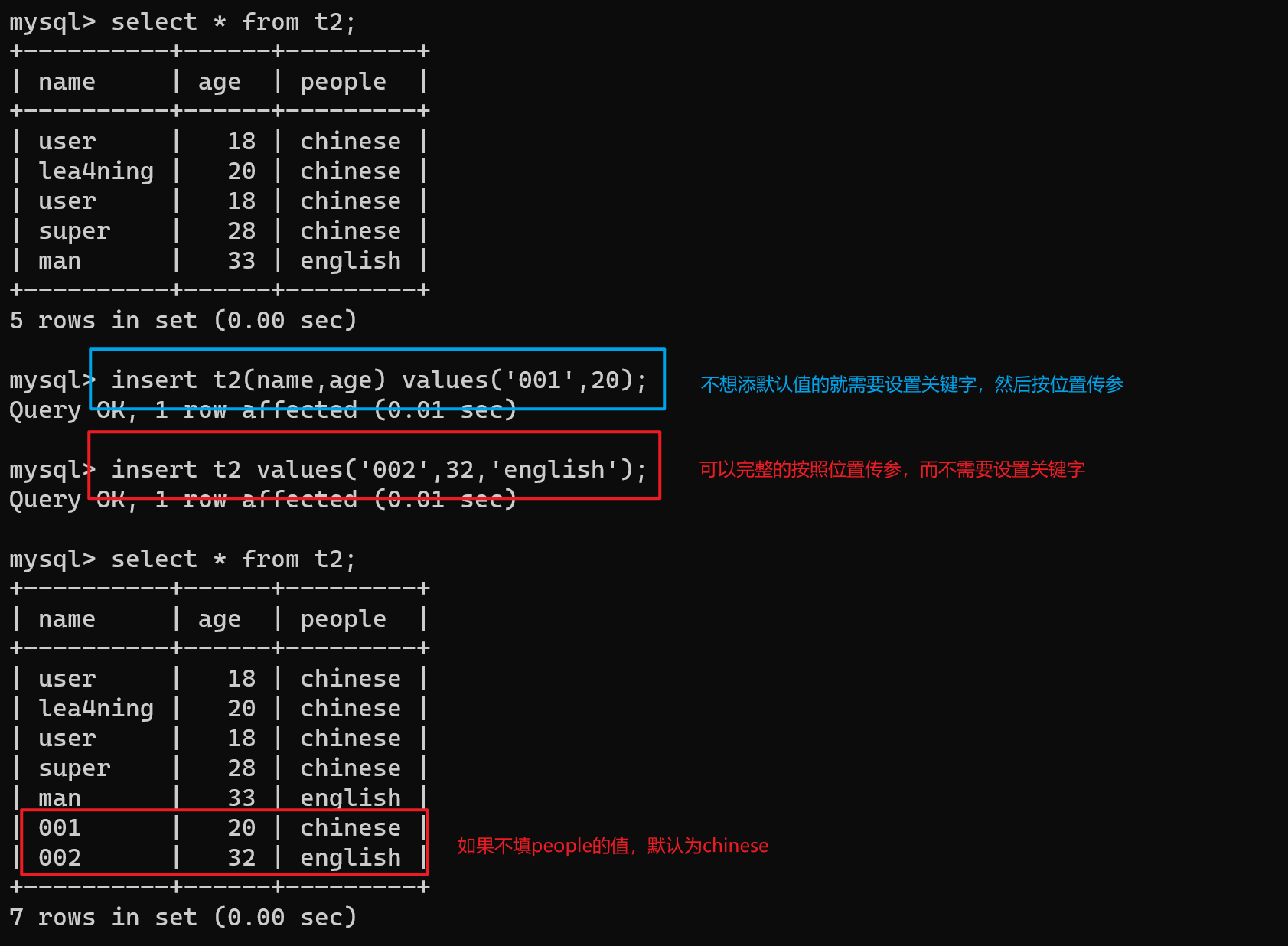
- 当设置字段值时,约束条件设置了允许为空或默认值,在传值的时候是可以不填,但如果有不填的值,需要通过指定关键字(字段名)传值
alter table t2 add people(varchar(32) default "chinese");
-- 添加一个字段 设置默认值
insert t2(name,age) values('001',20);
insert t2 values('002',32,'english');
【3】修改记录
update 表名 set 字段名=字段值 where 筛选条件; -- 执行更新语句或删除语句时,一定要注意条件的设置
-- 示例
update t2 set age=100 where name='001'; -- 含义为将name=001的age设置为100
-- 需要注意,修改后的值也必须符合字段类型
update t2 set age=100; -- 如果不设置筛选条件,将会把所有的记录全部更改值!!一定要注意!
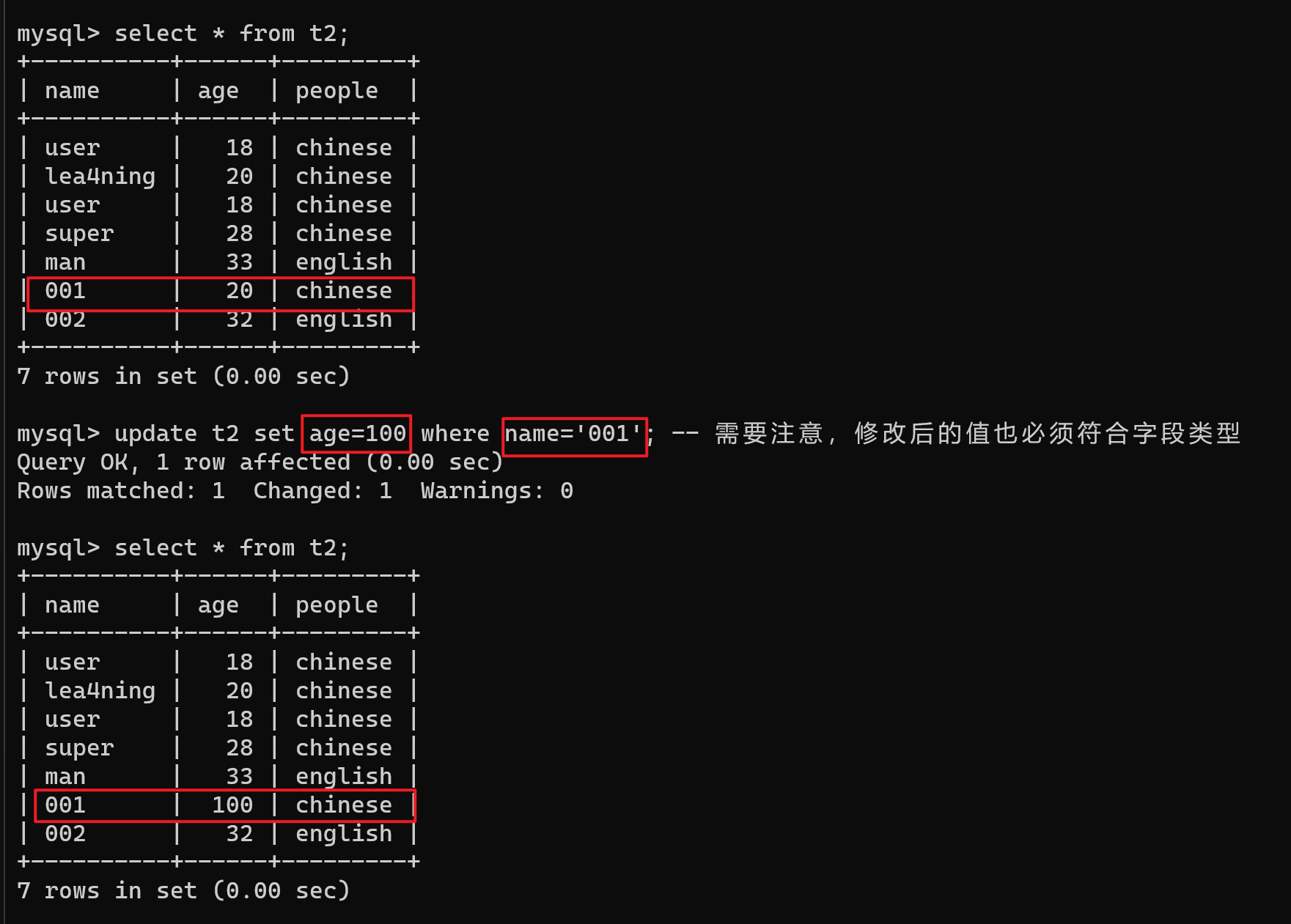
【4】删除记录
delete from 表名 where 筛选条件;
-- 示例
delete from t2 where name='002'; -- 删除符合条件的顺序,只要符合条件都删
delete from t2; -- 删除所有数据
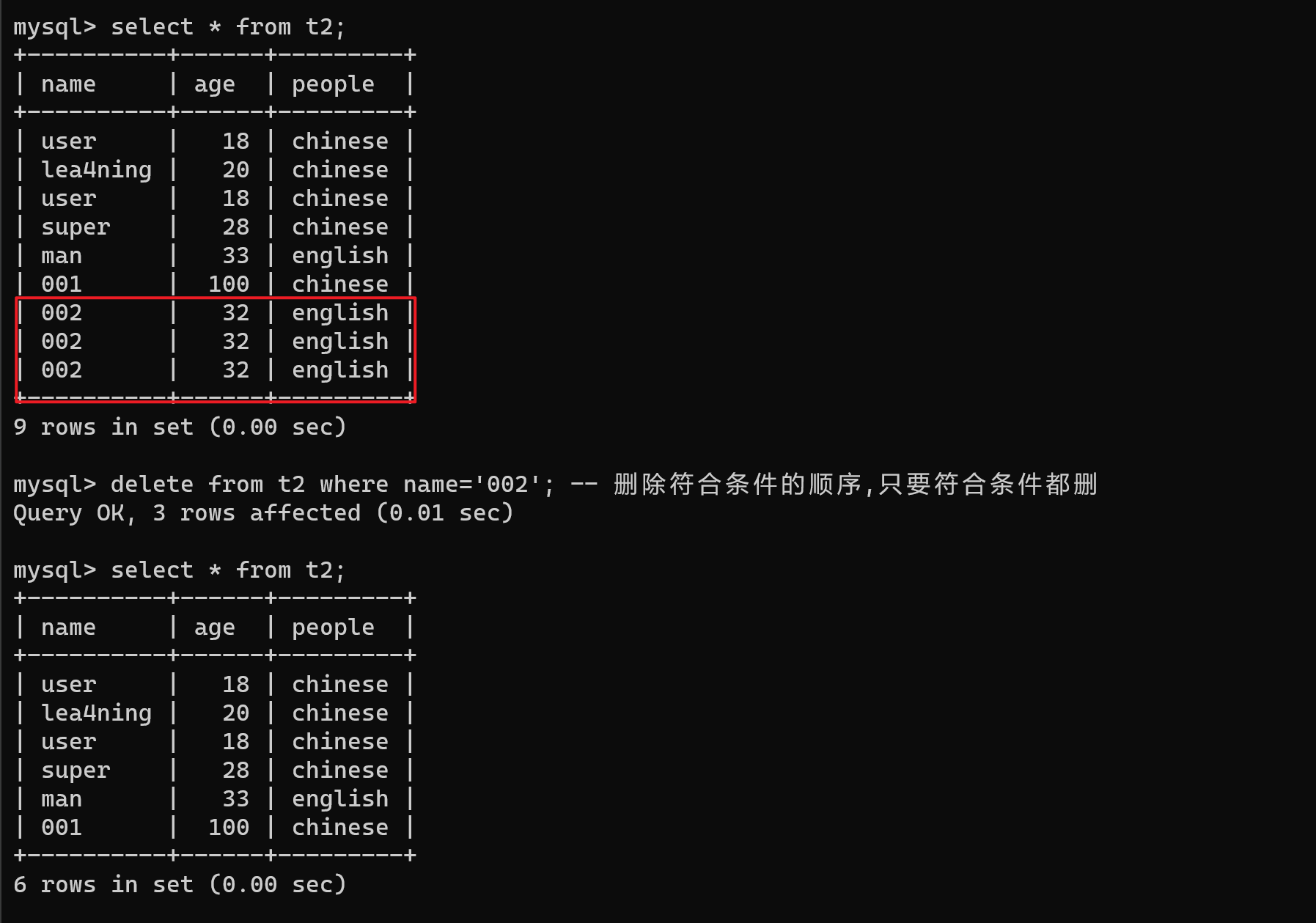
delete from t2; -- 删除所有数据,与truncate效果类似
【练】基础语法小练习
-
提示1
-
约束条件中有一个自增,当出现下一个记录时,会自动加一,具体请看高级语法中的约束条件
-
自增只有将字段设为主键是才可以使用:(
-
关于主键,具体看后面的高级语法中
-
字段名 字段类型 auto_increment primary key
-
-
提示2
- 输出结果时,可以通过
as来设置输出的表头名
- 输出结果时,可以通过
练习一:创建课程表
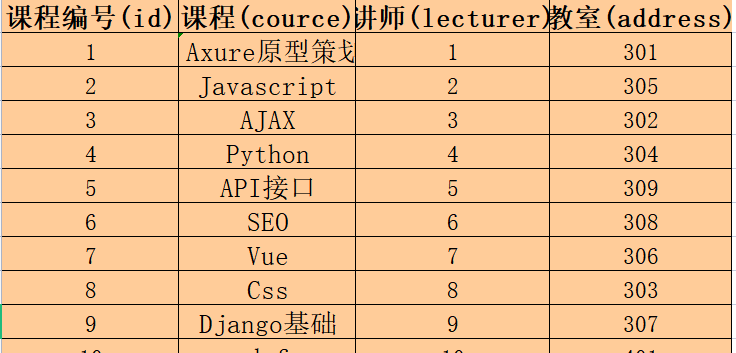
-- 在sql语句中,只要没有分号结尾,都会被当成一句语句,所以可以通过换行来更清晰的显示
create database db_course;
use db_course;
-- comment 只是注释,不是输出的表头
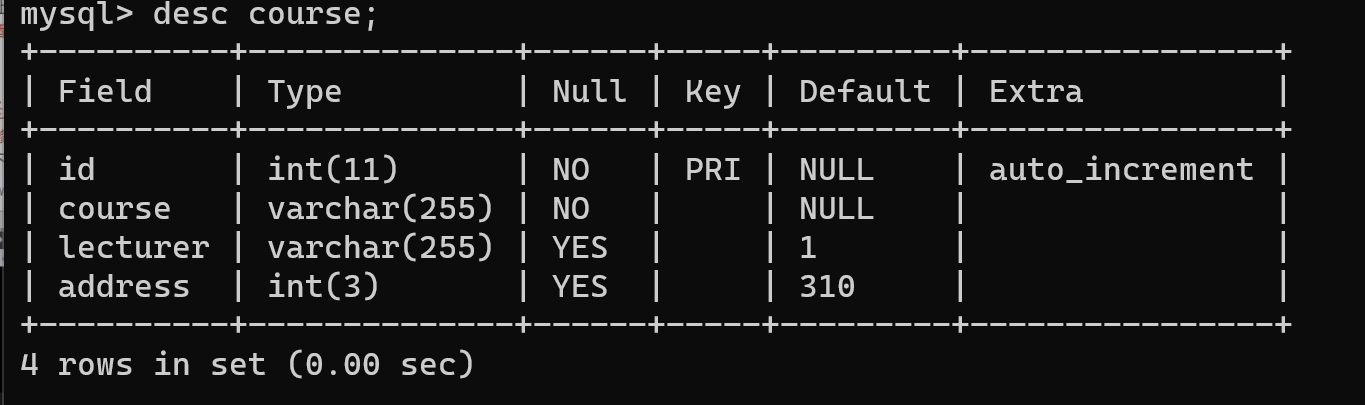
create table course(
id int auto_increment primary key comment '课程编号(id)',
course varchar(255) not null comment '课程(course)',
lecturer varchar(255) default '1' comment '讲师(lecturer)',
address int(3) default 310 comment '教室(address)'
);
insert course value(1,'Axure原型策划','1',301);-- 设置了主键的第一条数据,必须要传值
insert course(course,lecturer,address) values
('JS','2',305),('AJAX','3',302),('Python','3',307);-- 添加数据即可
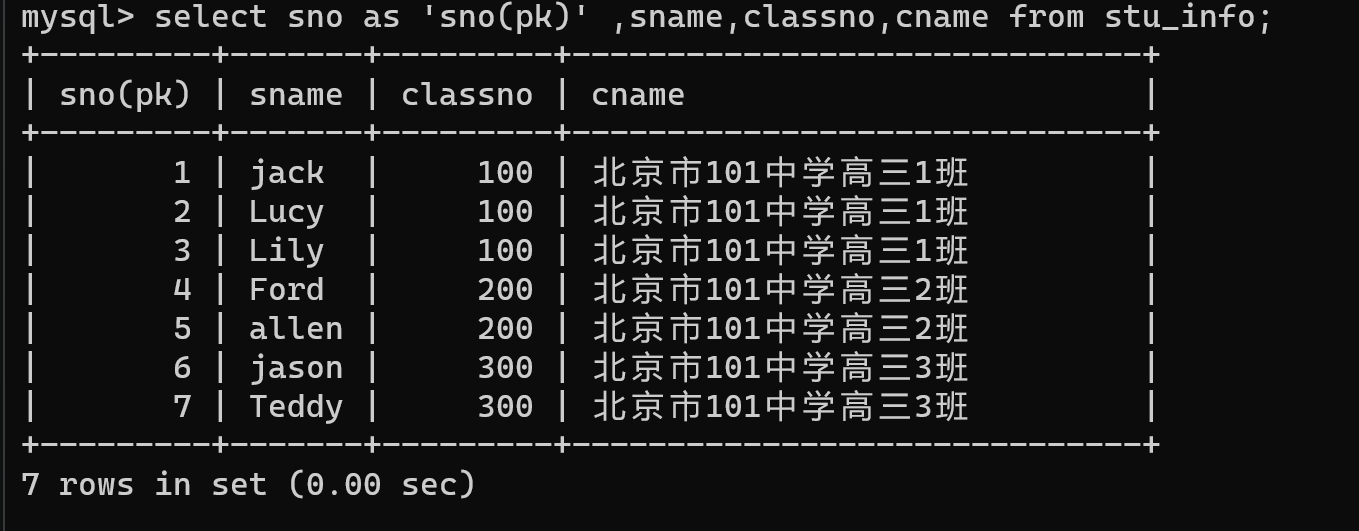
select id as '课程编号(id)',course as '课程(course)',lecturer as '讲师(lecturer)',address '教室(address)' from course;

练习二:存储学生信息表
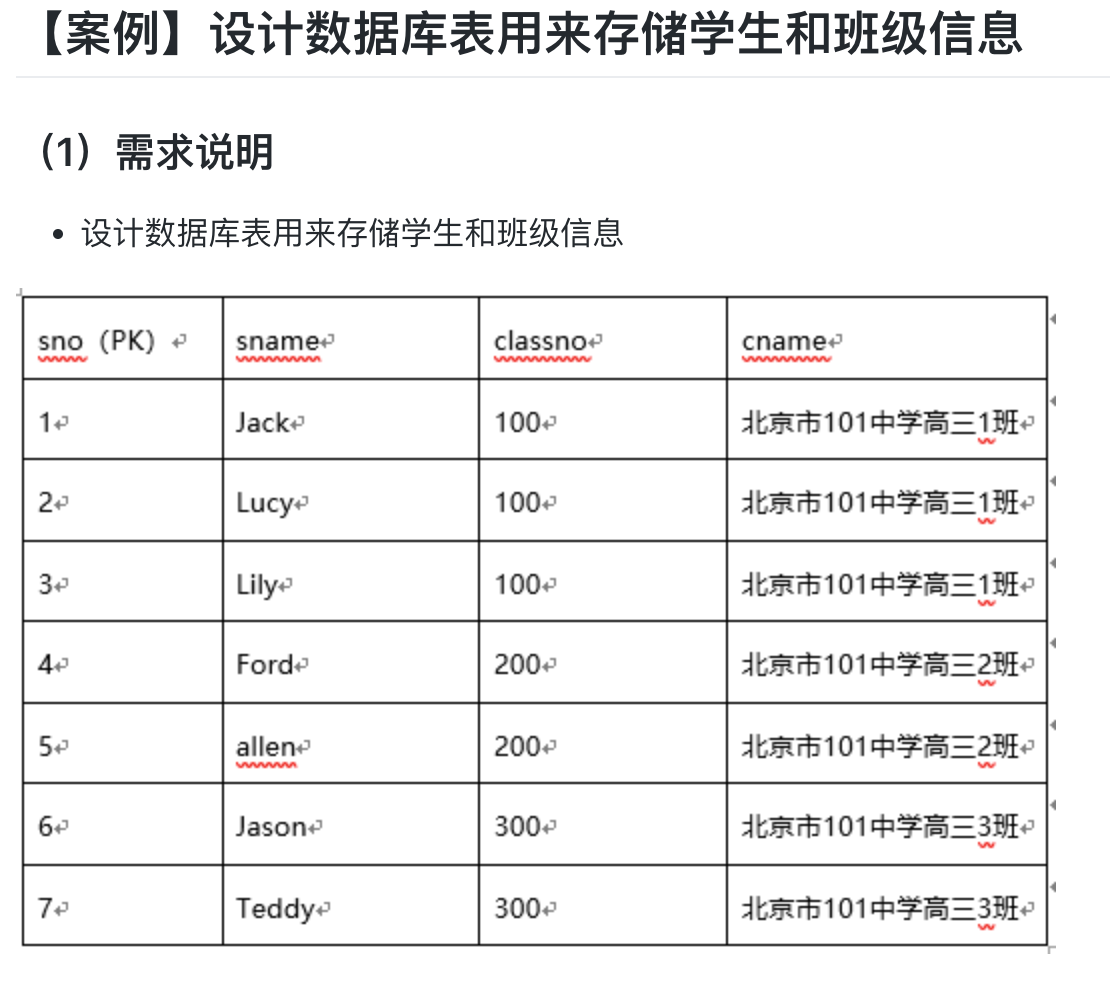
create table stu_info(
sno int auto_increment primary key ,
sname varchar(255) not null,
classno int(3) default 100 ,
cname varchar(255) default '北京市101中学高三1班'
);
insert stu_info(sno,sname) value(1,'jack');
insert stu_info(sname) value('Lucy');
insert stu_info(sname) value('Lily');
insert stu_info(sname,classno,cname) value('Ford',200,'北京市101中学高三2班');
insert stu_info(sname,classno,cname) value('allen',200,'北京市101中学高三2班');
insert stu_info(sname,classno,cname) value('jason',300,'北京市101中学高三3班');
insert stu_info(sname,classno,cname) value('Teddy',300,'北京市101中学高三3班');
MySQL高级语法
【五】约束条件
# 标准的建表语句
CREATE TABLE [IF NOT EXISTS] 库名.表名 (
字段名1 数据类型1 [数据修饰符1] [约束条件1],
字段名2 数据类型2 [数据修饰符2] [约束条件2],
...
PRIMARY KEY (主键字段),
FOREIGN KEY (外键字段) REFERENCES 关联表(关联字段),
...
);
# IF NOT EXISTS: 可选项,表示如果表已存在,则不创建。适用于避免重复创建表的情况。
# 库名.表名: 可选,表示在哪个数据库中创建表。如果不指定库名,默认是当前数据库。
# 字段名 数据类型 [数据修饰符] [约束条件]: 指定表的各个字段。数据修饰符和约束条件是可选的,可以根据需要添加。
# PRIMARY KEY: 定义主键,用于唯一标识表中的每一行。
# FOREIGN KEY: 定义外键,用于关联其他表的字段。关联的字段在 REFERENCES 后面指定。
- 约束条件可多个嵌套
【1】数据修饰符
-
长度/大小(Length/Size):
- 对于字符型数据类型(如
CHAR、VARCHAR),可以指定存储的最大长度。
VARCHAR(255) - 对于字符型数据类型(如
-
精度和标度(Precision and Scale):
- 用于数值型数据类型,指定数字的总位数和小数点后的位数。
DECIMAL(10, 2) -
是否允许 NULL 值:
- 用于表示该列是否允许存储 NULL 值。
column_name INT NULL -- 允许为空(默认) column_name INT NOT NULL -- 不允许为空 -
UNSIGNED:
- 用于整数型数据类型,表示该列只存储非负整数。
INT UNSIGNED -
ZEROFILL:
- 用于整数型数据类型,如果数值位数不足,则用零填充。
INT ZEROFILL -
字符集和排序规则(Character Set and Collation):
- 用于指定字符型数据类型的字符集和排序规则。
VARCHAR(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci
-- 示例展示
create database db1;
-- 切换库
use db1;
-- 建表
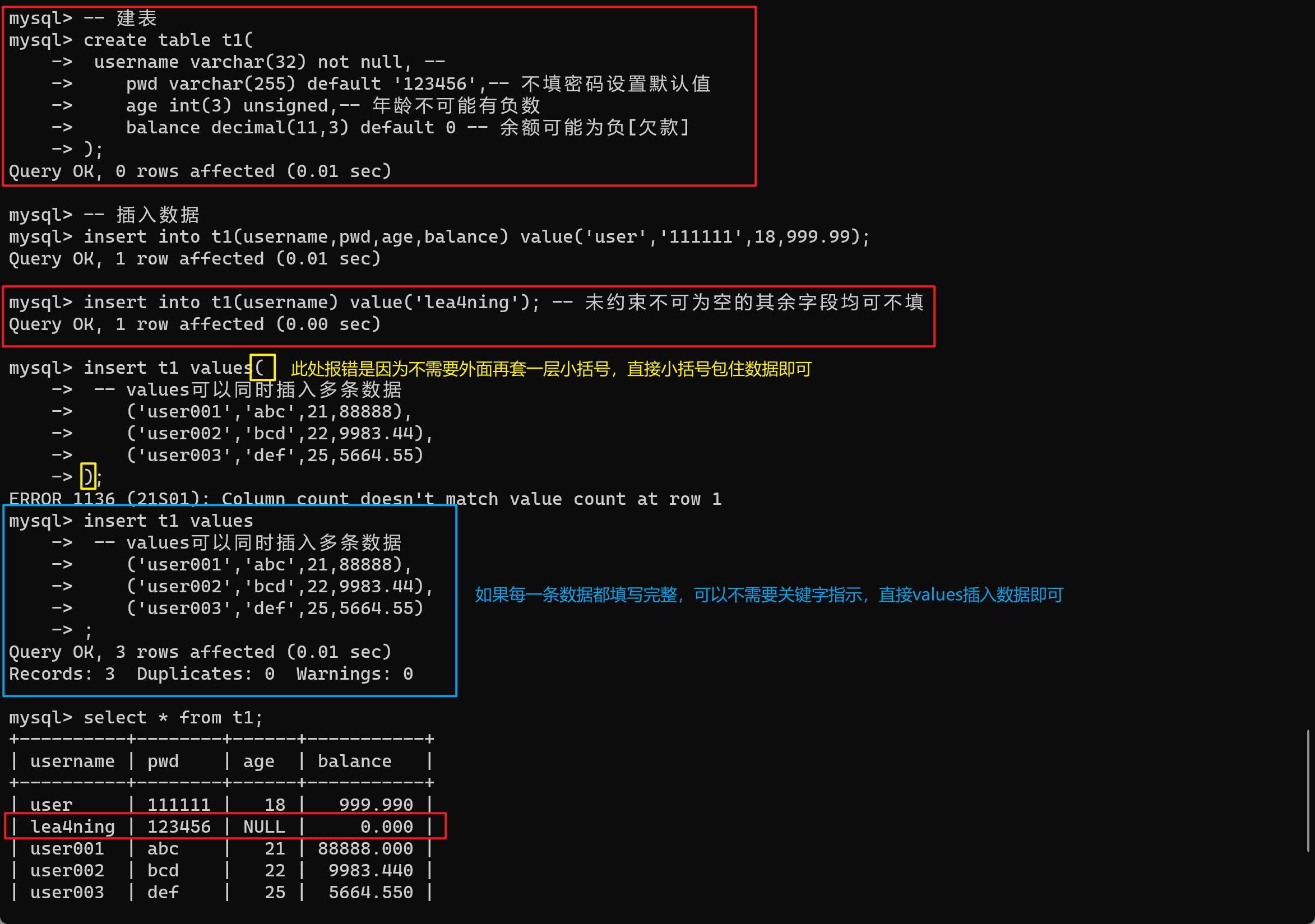
create table t1(
username varchar(32) not null, --
pwd varchar(255) default '123456',-- 不填密码设置默认值
age int(3) unsigned,-- 年龄不可能有负数
balance decimal(11,3) default 0 -- 余额可能为负[欠款]
);
-- 插入数据
insert into t1(username,pwd,age,balance) value('user','111111',18,999.99);
insert into t1(username) value('lea4ning'); -- 未约束不可为空的其余字段均可不填
insert t1 values
-- values可以同时插入多条数据
('user001','abc',21,88888),
('user002','bcd',22,9983.44),
('user003','def',25,5664.55),
('user004','fgh',35,-1145.14)
-- balance 可以设置复数,而age不可以设置复数
;
【2】约束条件
5. unique # 唯一
-- 单列唯一
create table t1 (id int, name varchar(32) unique);
-- 多列唯一
create table t2 (
id int,
ip varchar(32),
port varchar(32),
unique(ip, port)
# ip+port 不能重复
# 单独就可以重复
);
6. 主键(primary key)
"""主键单纯从约束上来看,它相当于是非空且唯一 unique not null"""
id unique not null ---------> id primary key
create table t8 (id int primary key);
create table t8 (id int unique not null);
-
主键约束(PRIMARY KEY):
- 用于唯一标识表中的每一行。
- 确保列中的值是唯一的,且不为空。
- 一个表只能有一个主键。
CREATE TABLE example ( id INT PRIMARY KEY, name VARCHAR(255) );- 单纯从约束上来看,它相当于是非空且唯一 unique not null
-
外键约束(FOREIGN KEY):
- 外键具体可看另一篇文章【外键】
- 用于在两个表之间建立关联。
- 确保外键列中的值在关联表的主键列中存在。
- 用于维护表之间的引用完整性。
CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, FOREIGN KEY (customer_id) REFERENCES customers(customer_id) ); -
唯一约束(UNIQUE):
- 确保列中的值是唯一的,但可以包含 NULL 值。
- 一个表可以有多个唯一约束。
-- 单列唯一 create table t6 (id int, name varchar(32) unique); -- 多列唯一 create table t7 ( id int, ip varchar(32), port varchar(32), unique(ip, port) ); # ip+port 不能重复 # 单独就可以重复 -
检查约束(CHECK):
- 用于确保列中的值满足指定的条件。
- 可以定义多个 CHECK 约束。
CREATE TABLE products ( product_id INT, price DECIMAL(10, 2) CHECK (price > 0) );- 需要注意的是,MySQL 默认情况下对
CHECK约束的支持相对较弱,且在表的创建时可能会被忽略。具体来说,MySQL会解析和识别CHECK约束,但并不会强制执行。
-
默认值约束(DEFAULT):
- 用于为列指定默认值,如果插入行时未提供该列的值,则使用默认值。
CREATE TABLE students ( student_id INT, name VARCHAR(255), grade CHAR(1) DEFAULT 'A' -- 不指定grage默认为A ); -
自增(AUTO_INCREMENT)
- 自增:每一次主动比上一次加1
- 一般情况下,它配合主键使用
create table id_data ( id int primary key auto_increment);- delete 一条记录后的自增键会继续增加
- 通过
alter table 表名 auto_increment=0重新设置自增的值
-- 示例展示
create database db2;
-- 切换库
use db2;
-- 建表
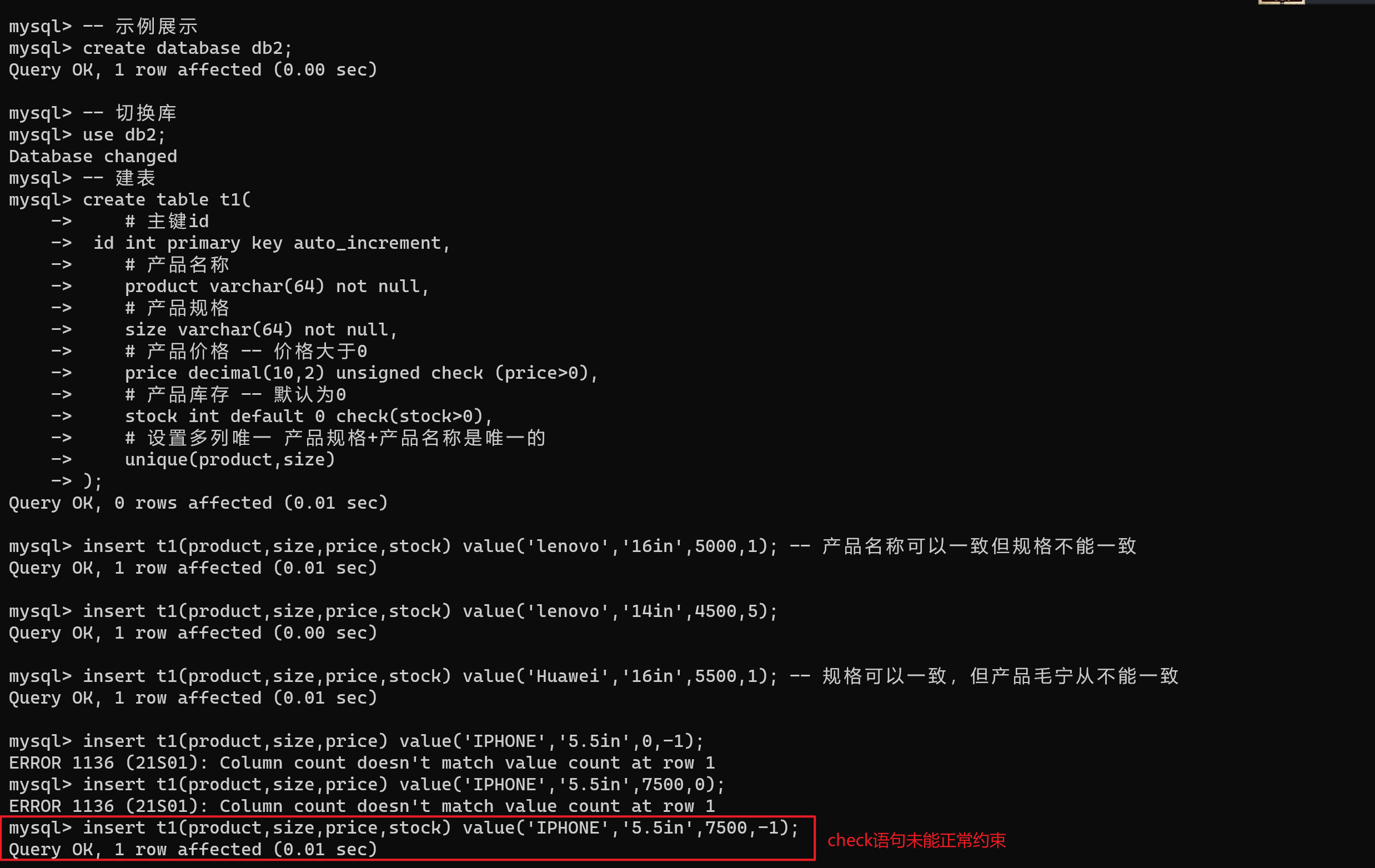
create table t1(
# 主键id
id int primary key auto_increment,
# 产品名称
product varchar(64) not null,
# 产品规格
size varchar(64) not null,
# 产品价格 -- 价格大于0
price decimal(10,2) unsigned check (price>0),
# 产品库存 -- 默认为0
stock int default 0 check(stock>0),
# 设置多列唯一 产品规格+产品名称是唯一的
unique(product,size)
);
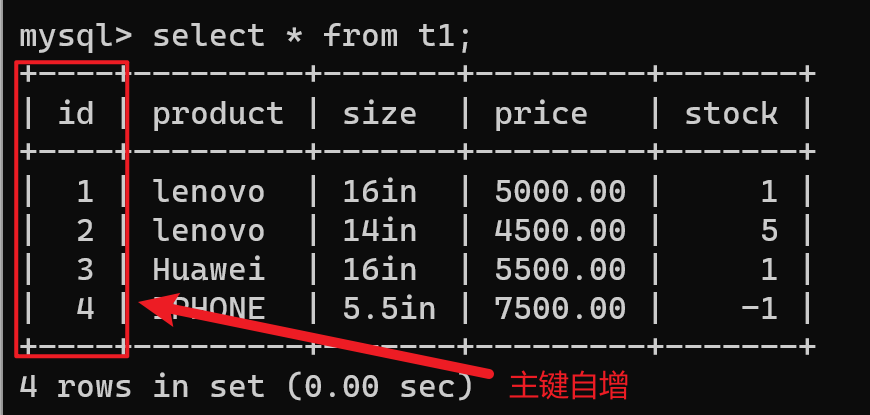
insert t1(product,size,price,stock) value('lenovo','16in',5000,1); -- 产品名称可以一致但规格不能一致
insert t1(product,size,price,stock) value('lenovo','14in',4500,5);
insert t1(product,size,price,stock) value('Huawei','16in',5500,1); -- 规格可以一致,但产品名称不能一致
insert t1(product,size,price,stock) value('IPHONE','5.5in',7500,-1); -- check语句未生效 mysql并不会强约束
【六】查询条件
# 在你刚开始接触mysql查询的时候,建议你按照查询的优先级顺序拼写出你的sql语句
"""
先是查哪张表 【from 表名】
再是根据什么条件去查 【查询条件】
再是对查询出来的数据筛选展示部分 【select 字段名】
"""
- 注:查询条件可以叠加 不限制只能有一个查询条件
【0】数据准备
drop table if exists emp_data; -- 如果已经存在就将原表删除
create database emp_data; -- 创建新库
use emp_data;
-- 建表
create table emp(
# 主键自增
id int not null unique auto_increment,
name varchar(20) not null,
sex enum("male","female") not null default "male",
age int(3) unsigned not null default 28,
hire_date date not null, -- 入职时间
post varchar(50), -- 岗位
post_comment varchar(100), -- 岗位描述
salary double(15,2), -- 工资
office int, -- 办公室
depart_id int -- 部门编号
);
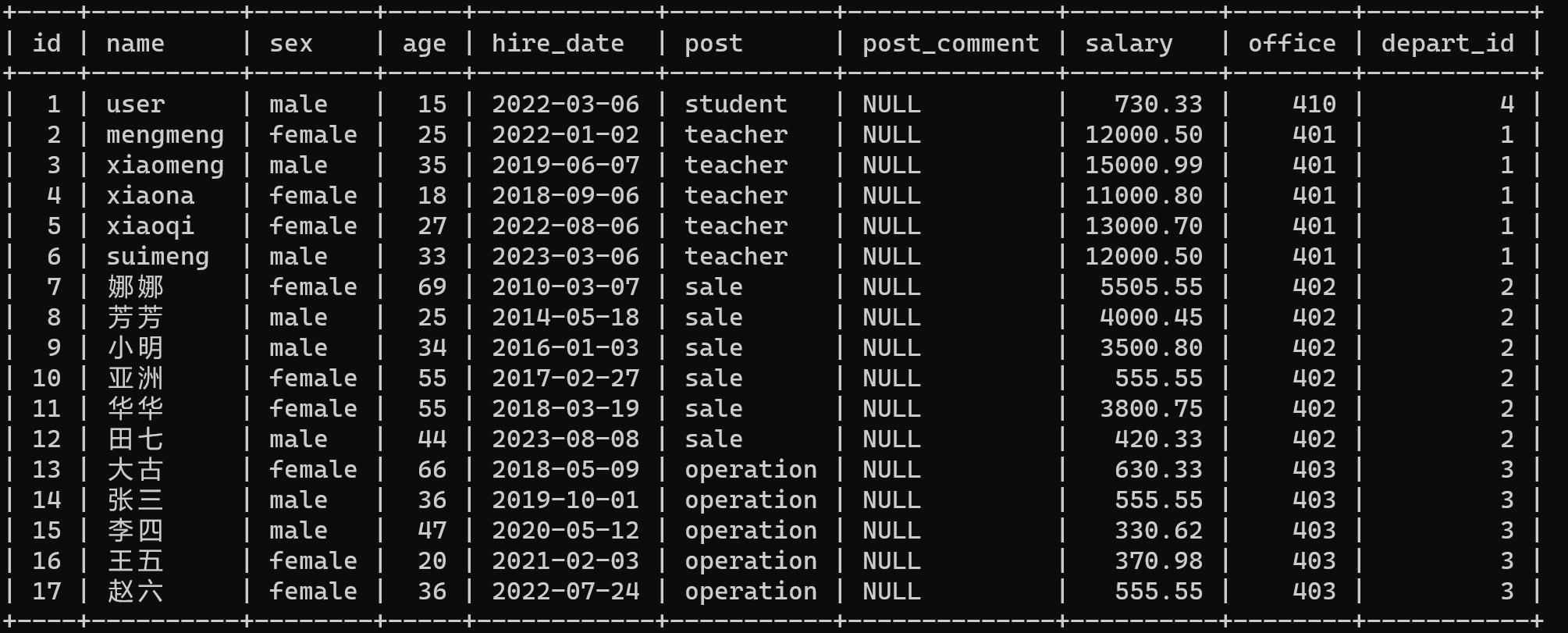
insert into emp(name, sex, age, hire_date, post, salary, office, depart_id) values
("user", "male", 15, '20220306', "student", 730.33, 410, 4),
("mengmeng", "female", 25, '20220102', "teacher", 12000.50, 401, 1), # 以下是教学部
("xiaomeng", "male", 35, '20190607', "teacher", 15000.99, 401, 1),
("xiaona", "female", 18, '20180906', "teacher", 11000.80, 401, 1),
("xiaoqi", "female", 27, '20220806', "teacher", 13000.70, 401, 1),
("suimeng", "male", 33, '20230306', "teacher", 12000.50, 401, 1), # 以下是销售部
("娜娜", "female", 69, '20100307', "sale", 5505.55, 402, 2),
("芳芳", "male", 25, '20140518', "sale", 4000.45, 402, 2),
("小明", "male", 34, '20160103', "sale", 3500.80, 402, 2),
("亚洲", "female", 55, '20170227', "sale", 555.55, 402, 2),
("华华", "female", 55, '20180319', "sale", 3800.75, 402, 2),
("田七", "male", 44, '20230808', "sale", 420.33, 402, 2), # 以下是运行部
("大古", "female", 66, '20180509', "operation", 630.33, 403, 3),
("张三", "male", 36, '20191001', "operation", 555.55, 403, 3),
("李四", "male", 47, '20200512', "operation", 330.62, 403, 3),
("王五", "female", 20, '20210203', "operation", 370.98, 403, 3),
("赵六", "female", 36, '20220724', "operation", 555.55, 403, 3);
【1】关键字之where查询
-- 基础查询语句
select 查询字段 from 表 where 查询条件;
-
查询优先级:先查表是否存在【from】再根据条件查询【where】最后查找字段是否存在【select】
-
and
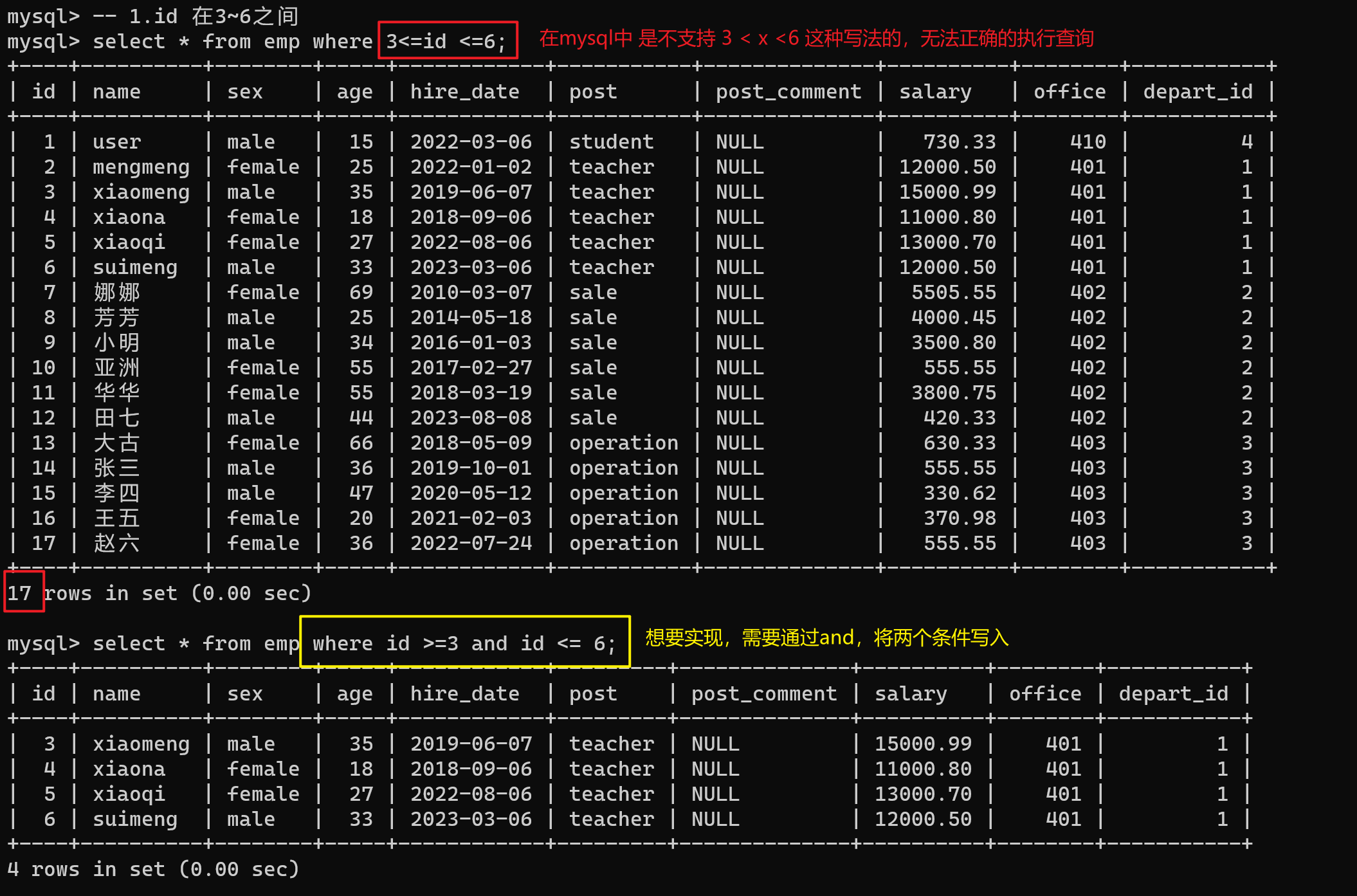
-- 需求:查询id 在3 -6 的人员姓名
-- 先分析 再执行
# 1.查询id在3-6之间
# 2.人员姓名
-- 1.id 在3~6之间
select name from emp where 3<=id <=6; -- MySQL不能正确的识别,无法执行
select name from emp where id >=3 and id <= 6; -- 正确执行了
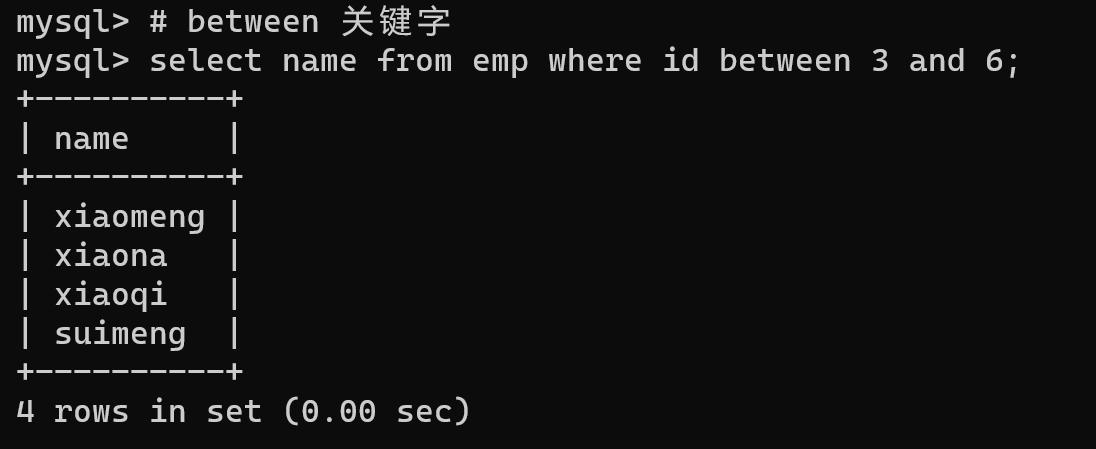
# between 关键字
select name from emp where id between 3 and 6; -- 通过关键字between能更方便的执行
-
or / in
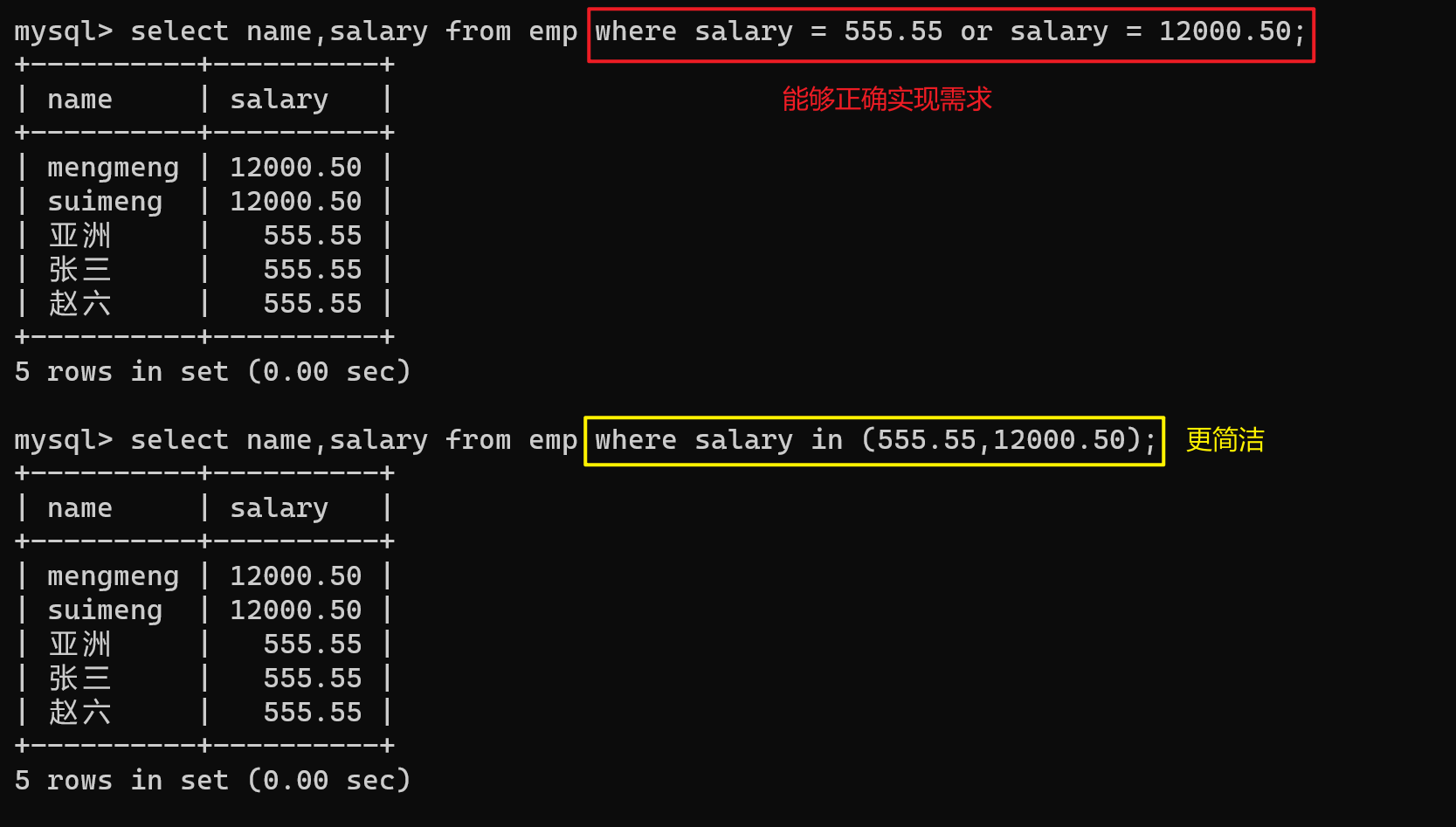
-- 需求:查询工资为555.55或工资为12000.50的员工姓名
-- 先分析 再执行
# or
select name,salary from emp where salary = 555.55 or salary = 12000.50;
# in -- 更方便的方法
select name,salary from emp where salary in (555.55,12000.50);
-
not in 【not 取反】
-- 需求:查询薪资不在555.55,12000.50,范围的员工姓名
select name,salary from emp where salary not in (555.55,12000.50);
【1.1】关键字like 模糊查询
- 没有明确的筛选条件
- 关键字:like
- 关键符号:
%:匹配任意个数任意字符_:匹配单个个数任意字符
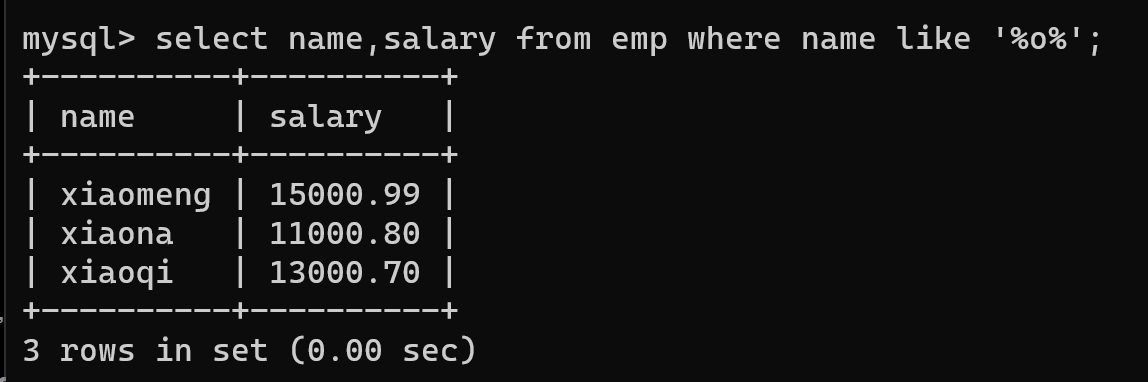
-- 需求:查询员工姓名中包含o字母的员工姓名和薪资
select name,salary from emp where name like '%o%';
-- % 代表开头任意字符
-- o 需要包含的字母
-- % 代表结尾可以是任意字符
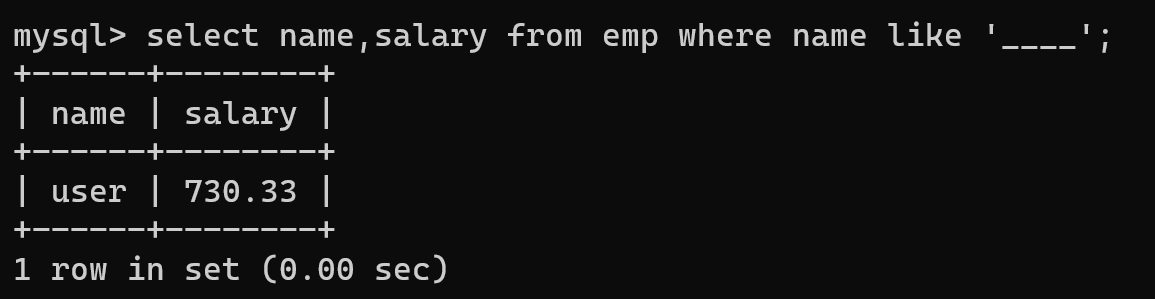
-- 需求:查询员工姓名是由四个字符组成的员工姓名与其薪资
select name,salary from emp where name like '____';
-
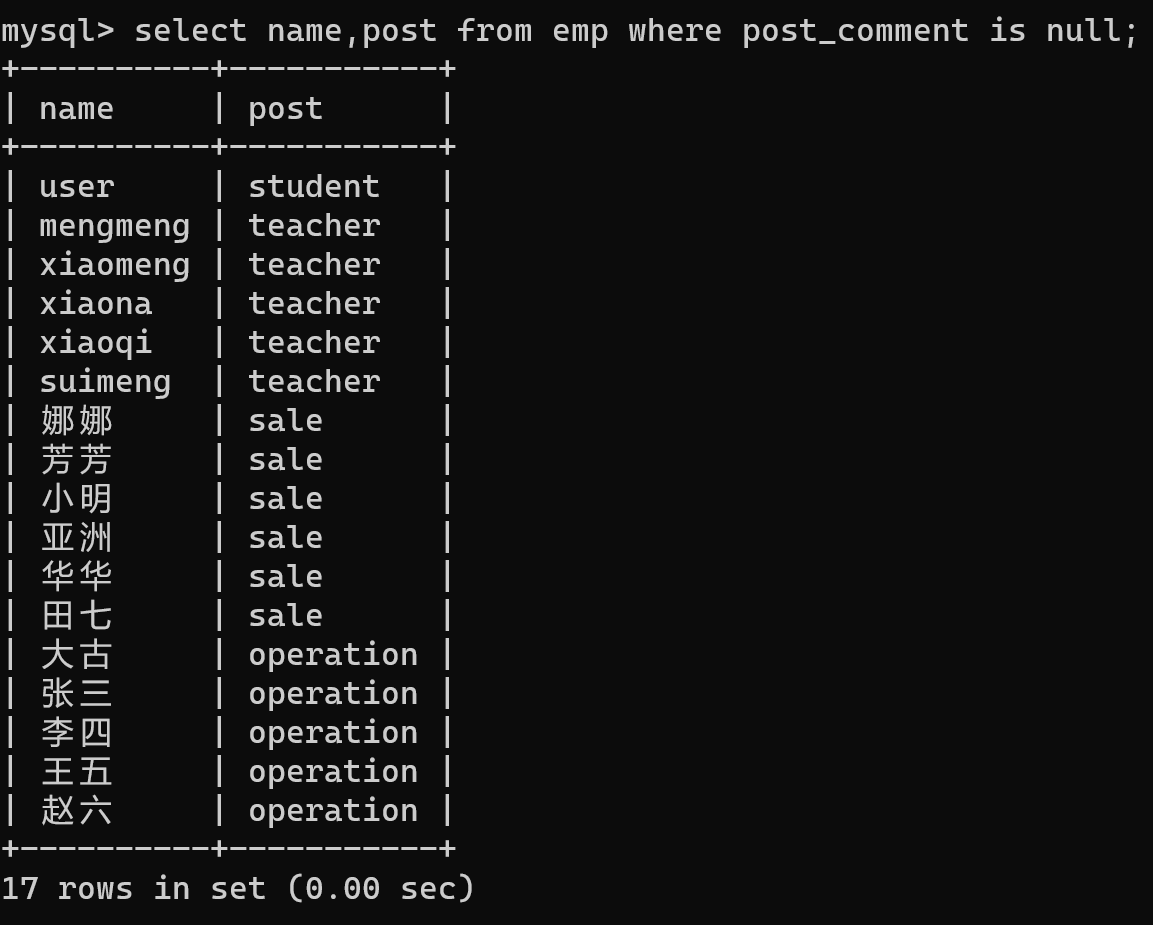
查询空值
-- 需求:查询岗位描述为空的员工名与岗位名 -- 提示:针对null不能用等号,只能用is
select name,post from emp where post_comment is null;
【2】关键字之group by 分组
- 按照某个指定的条件将单个个体分成一个个整体
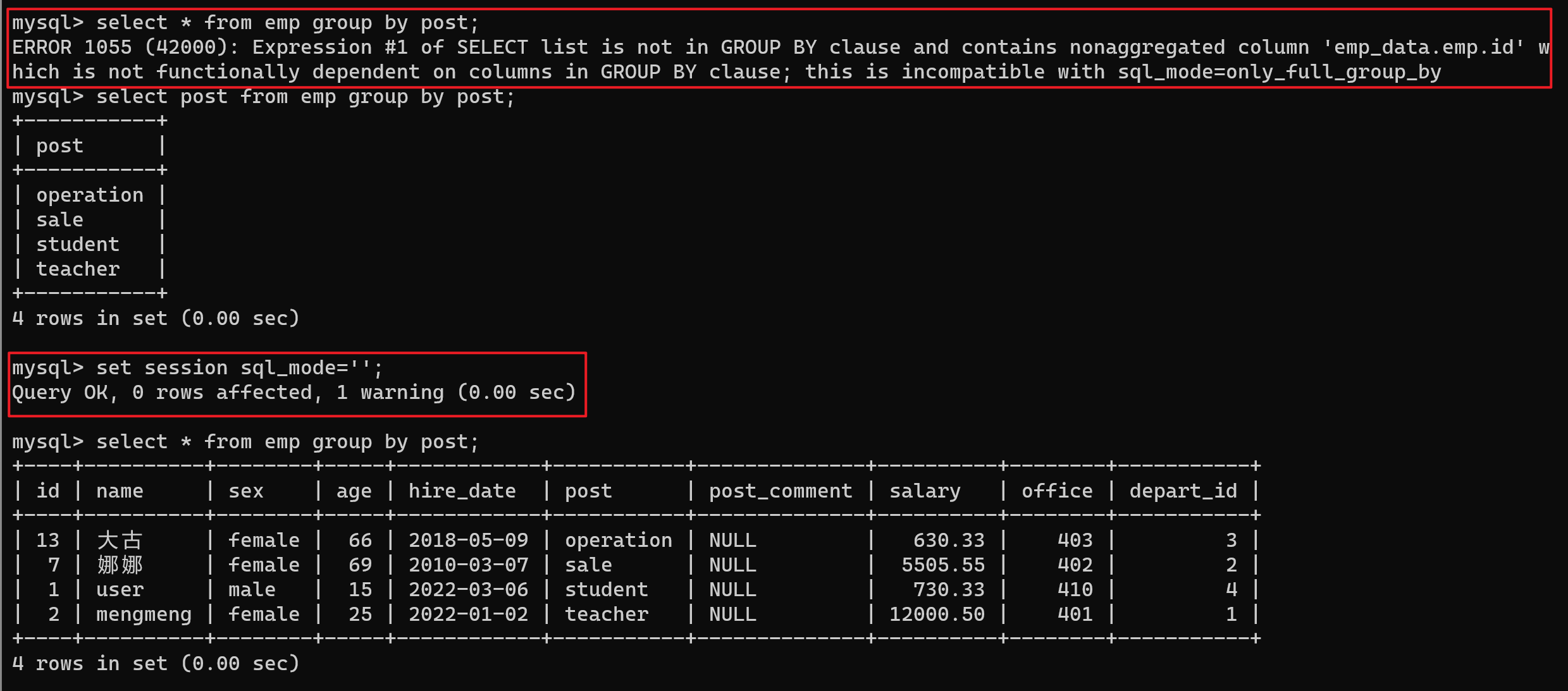
select * from emp group by post;
-- 该语句直接运行可能会报错
-- 严格模式【ONLY_FULL_GROUP_BY】要求 【GROUP BY】子句中的列必须是【SELECT】 列的子集
select post from emp group by post;
- 注:严格模式修改最好保留原本的,只去除不需要的,不要像我这样清空
【2.1】聚合函数
- 只是单纯的分组是没有意义的,分组后的好处就是可以通过聚合函数来获得指定条件的数据
-- 聚合函数需要在分组后才可使用
sum max min avg count
总和 最大 最小 平均 计数
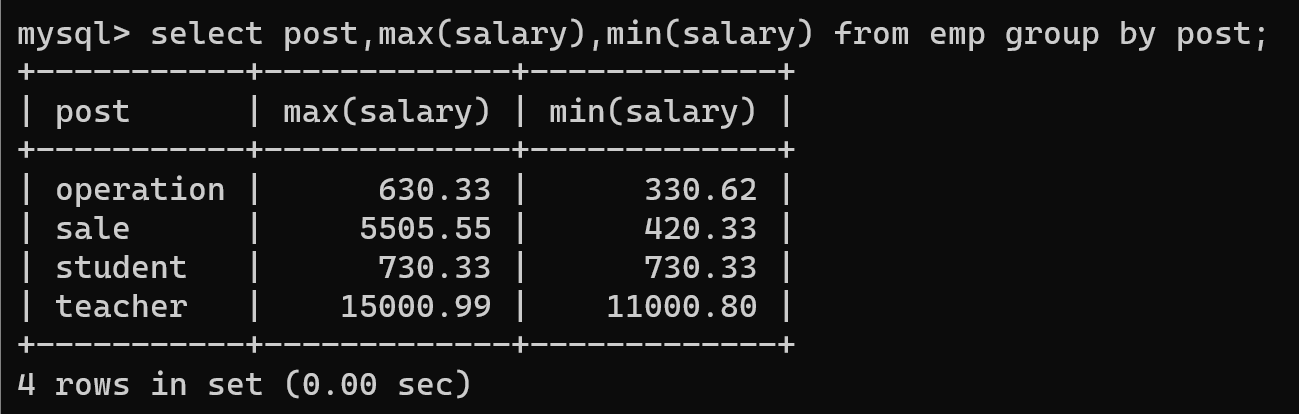
max / min
-- 需求 求最高薪资和最低薪资的员工姓名和部门
-- 同样需要将严格模式【ONLY_FULL_GROUP_BY】关闭
select post,max(salary),min(salary) from emp group by post;
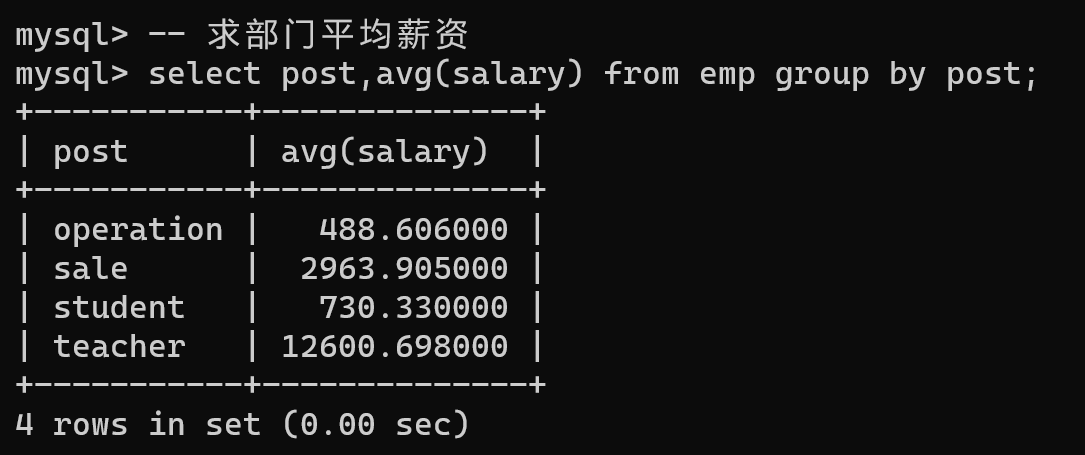
avg
-- 求部门平均薪资
select post,avg(salary) from emp group by post;
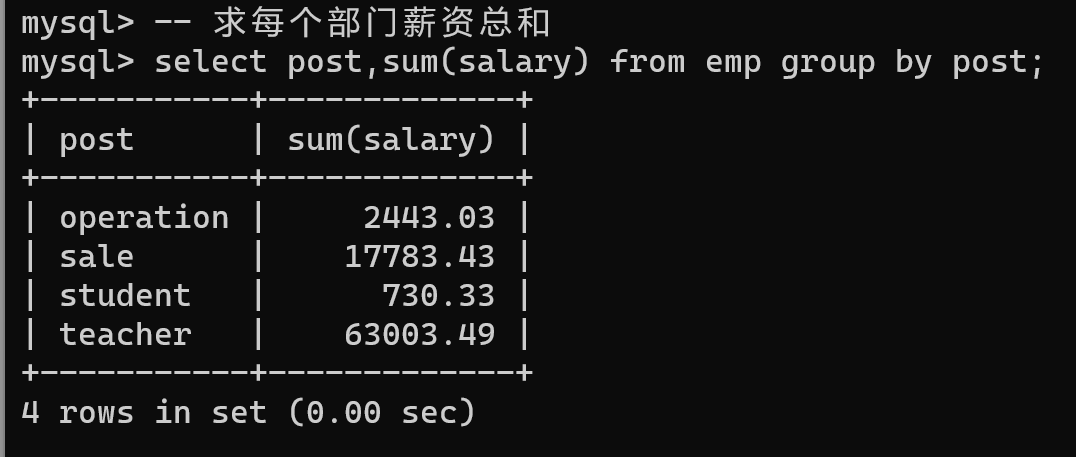
sum
-- 求每个部门薪资总和
select post,sum(salary) from emp group by post;
count
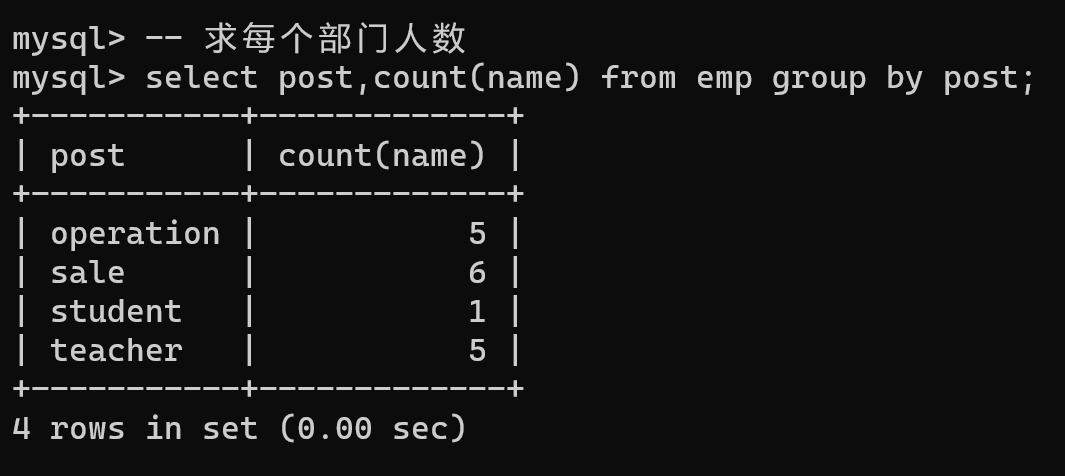
-- 求每个部门人数
select post,count(name) from emp group by post;
-- 求每个部门中都有多少条数据(与计算人数差不多)
select count(*) from emp group by post;
【2.2】as 显示名称
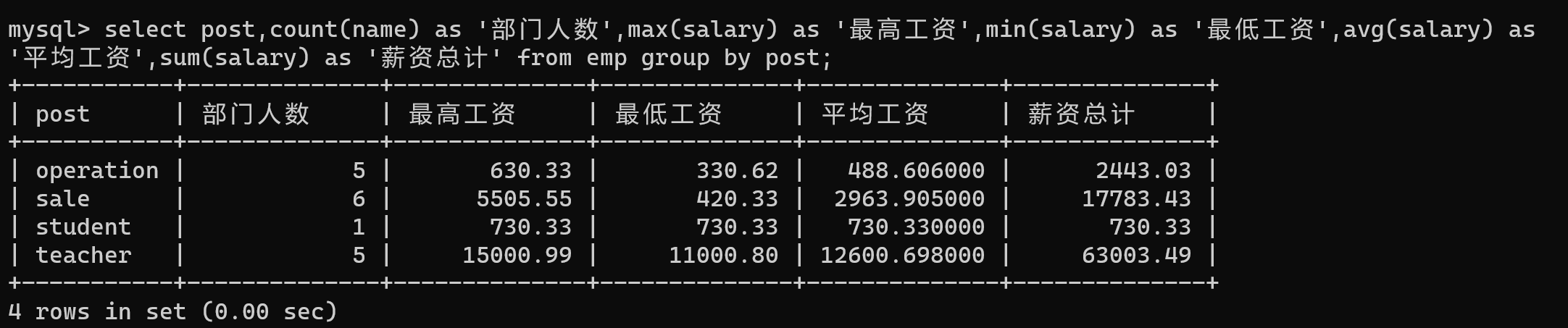
- 可以看到显示的名称还挺丑的count(name)
- 可以通过as为字段设置显示的名称
- 也可以省略as 直接空格也可以, 但一般推荐使用 防止代码不可读
select post,count(name) as '部门人数',max(salary) as '最高工资',min(salary) as '最低工资',avg(salary) as '平均工资',sum(salary) as '薪资总计' from emp group by post;
【2.3】聚合函数 group_concat
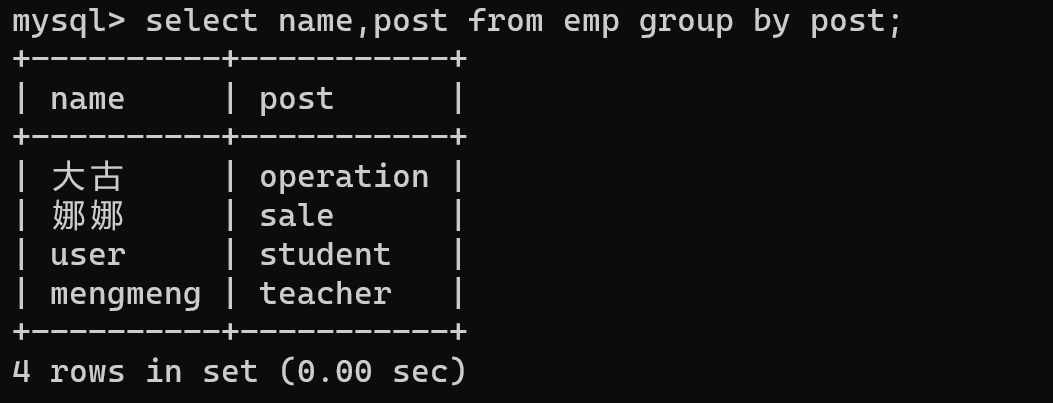
- 通过group by 后的数据,当涉及到多条数据时其实只可以显示每个部门的第一条数据
-- 需求 查看每一个部门的员工
select name,post from emp group by post;
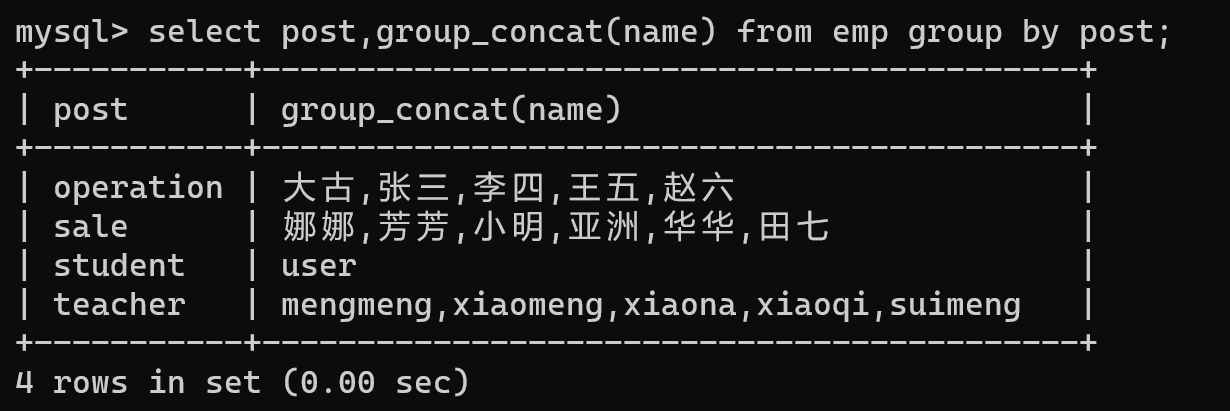
- group_concat 关键字就可以将数据拼接展示
select post,group_concat(name) from emp group by post;
-- 更多的用法
# 拼接【姓名,工资,[分隔符]】 -- 可以拼多条数据
select post,group_concat(name,salary,':') as 部门详细工资 from emp group by post;
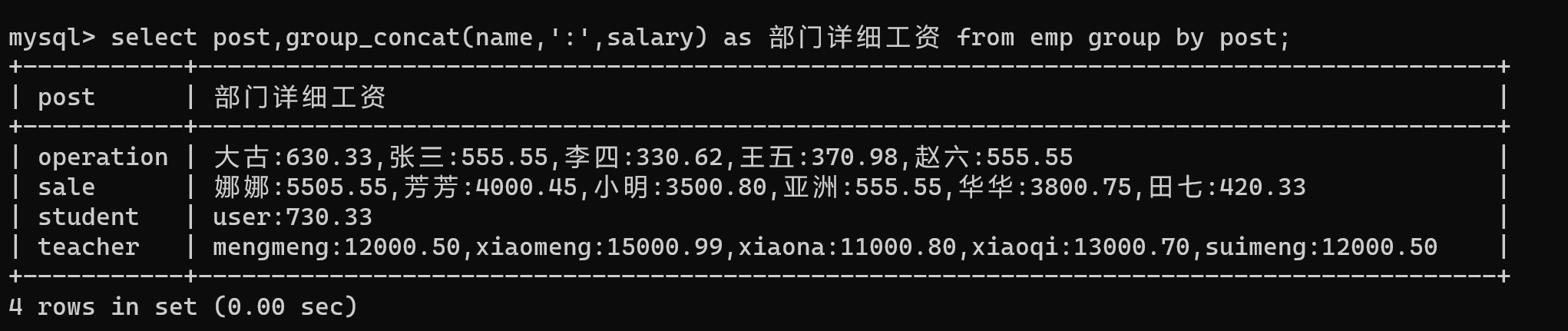
【2.4】聚合函数 having 筛选
- where与having都是筛选功能 但是有区别
- where在分组之前对数据进行筛选
- having在分组之后对数据进行筛选
-- 需求:统计各部门年龄在30岁以上的员工平均薪资,并且保留平均薪资大于1000的部门.
# 先筛选出年龄在30岁以上的
select * from emp where age > 30;
# 在进行分组,按照部门分组
select avg(salary) as avg_salary from emp where age > 30 group by post;
# 保留平均薪资大于1000的部门
select post,avg(salary) as avg_salary from emp where age > 30 group by post having avg(salary) > 1000;

【3】关键词之distinct 去重
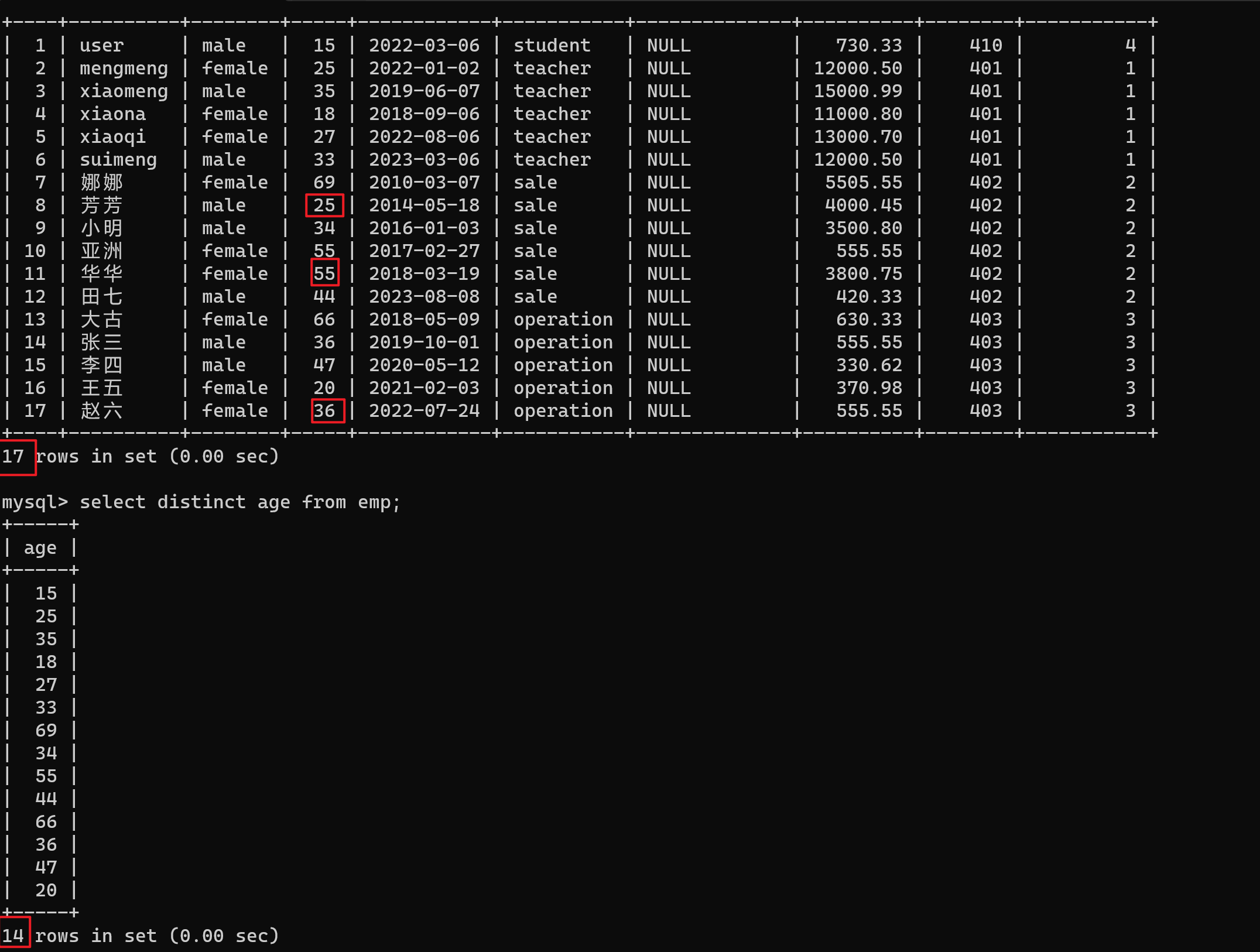
-- 对年龄去重
select distinct age from emp;
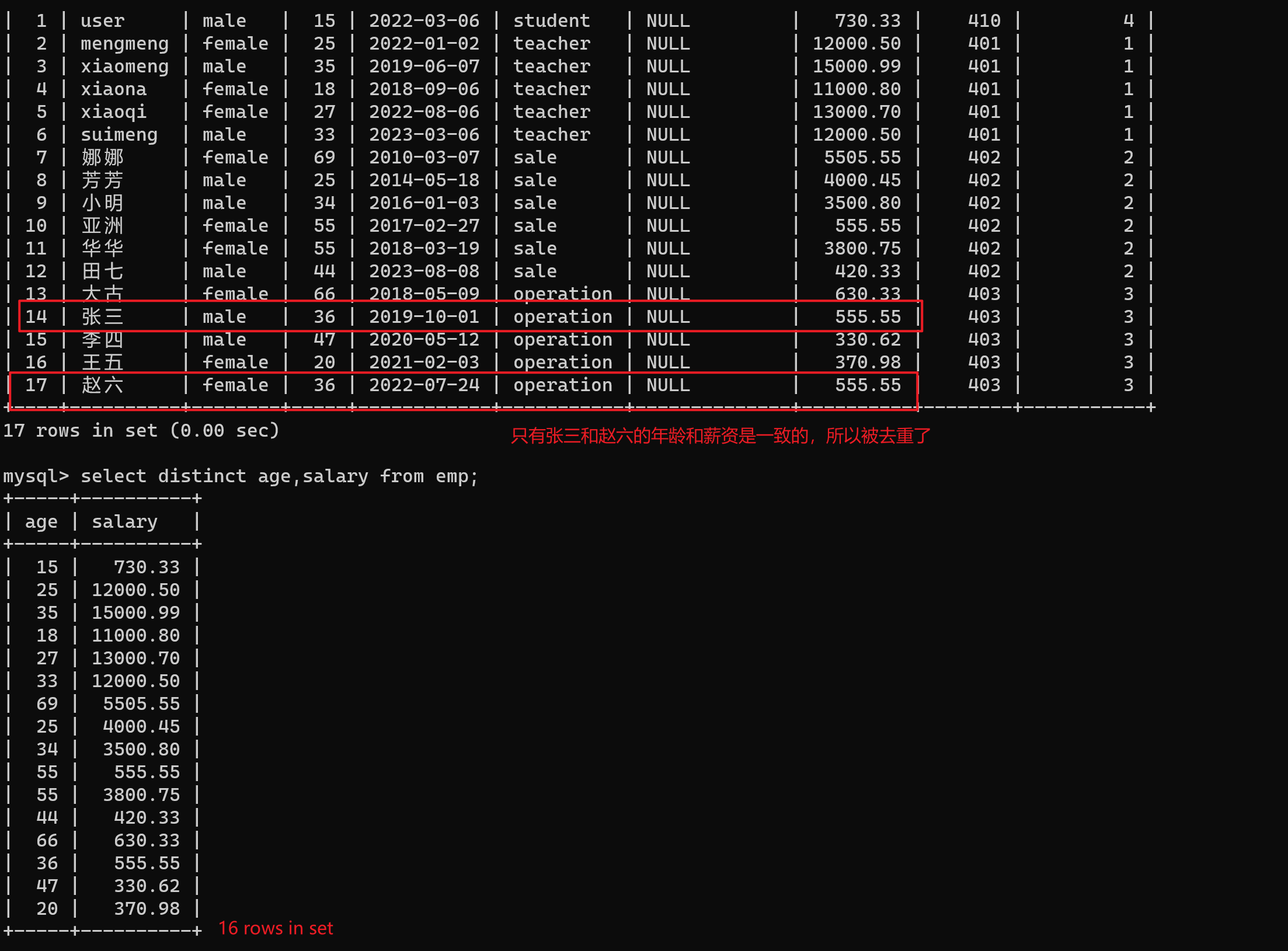
-- 去重age和salary一致的
select distinct age,salary from emp;
【4】关键字之order by排序
select 字段名 from 表名 order by 排序字段 asc/desc
# asc 升序 默认值
# desc 降序
-- 示例
select * from emp order by salary; #默认升序排
select * from emp order by salary desc; #降序排
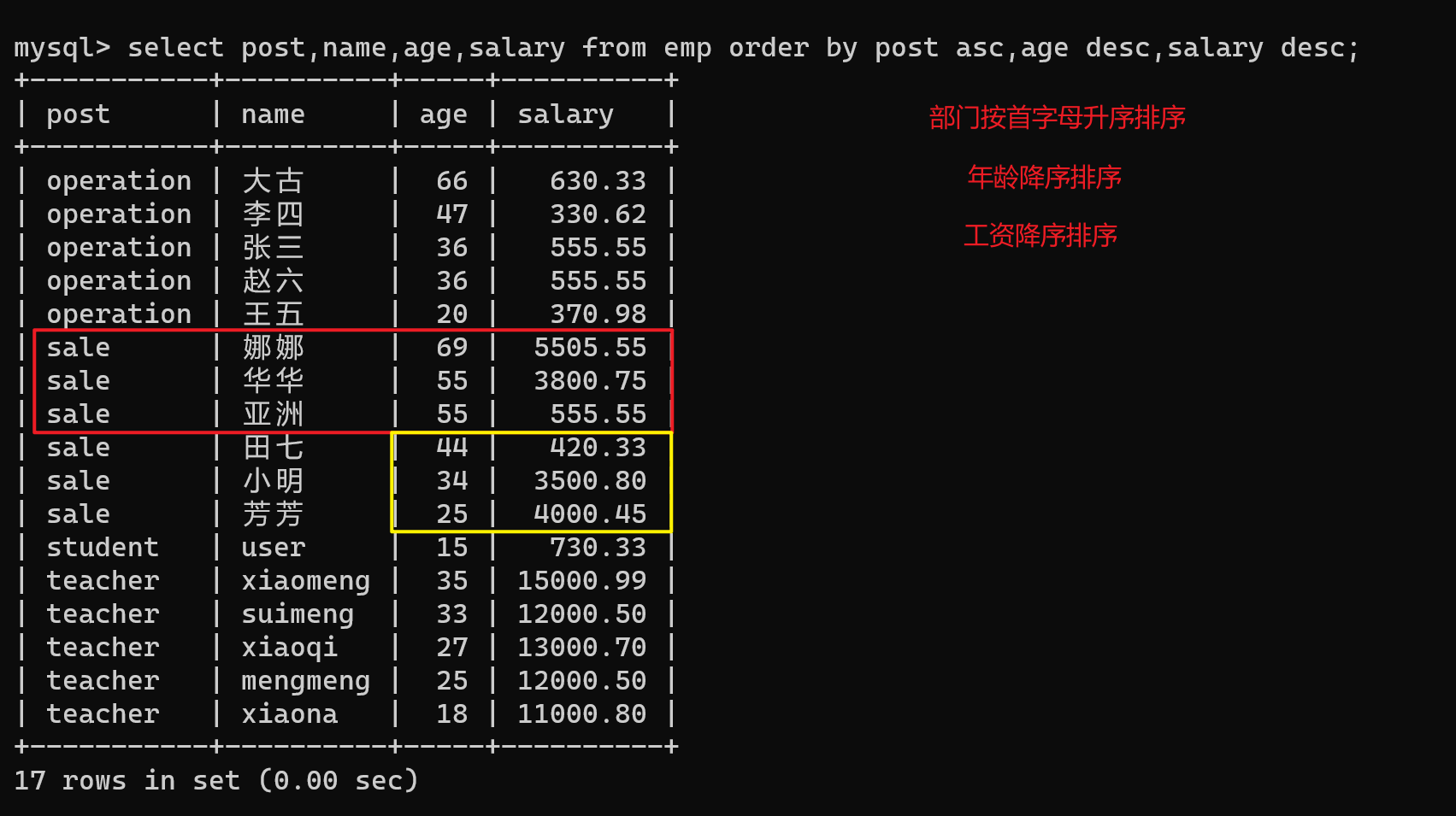
- 多字段排序,如果想让后面的字段排序生效,前提:前面的排序字段必须一样
select post,name,age,salary from emp order by post asc,age desc,salary desc;
-- 需求 :计各部门年龄在20岁以上的员工平均工资,并且保留平均工资大于1000的部门,然后对平均工资进行排序
# 20岁以上的员工
select * from emp where age > 20;
# 各部门的平均薪资
select avg(salary) from emp where age > 20 group by post having avg(salary) > 1000;
select avg(salary) from emp where age > 20 group by post having avg(salary) > 1000 order by avg(salary) desc;
【5】关键字之limit 限制展示
-- 单个参数
select * from 表名 limit 展示条数;
# 默认从第一条开始
-- 两个参数
select * from 表名 limit 起始位置,展示条数;
-
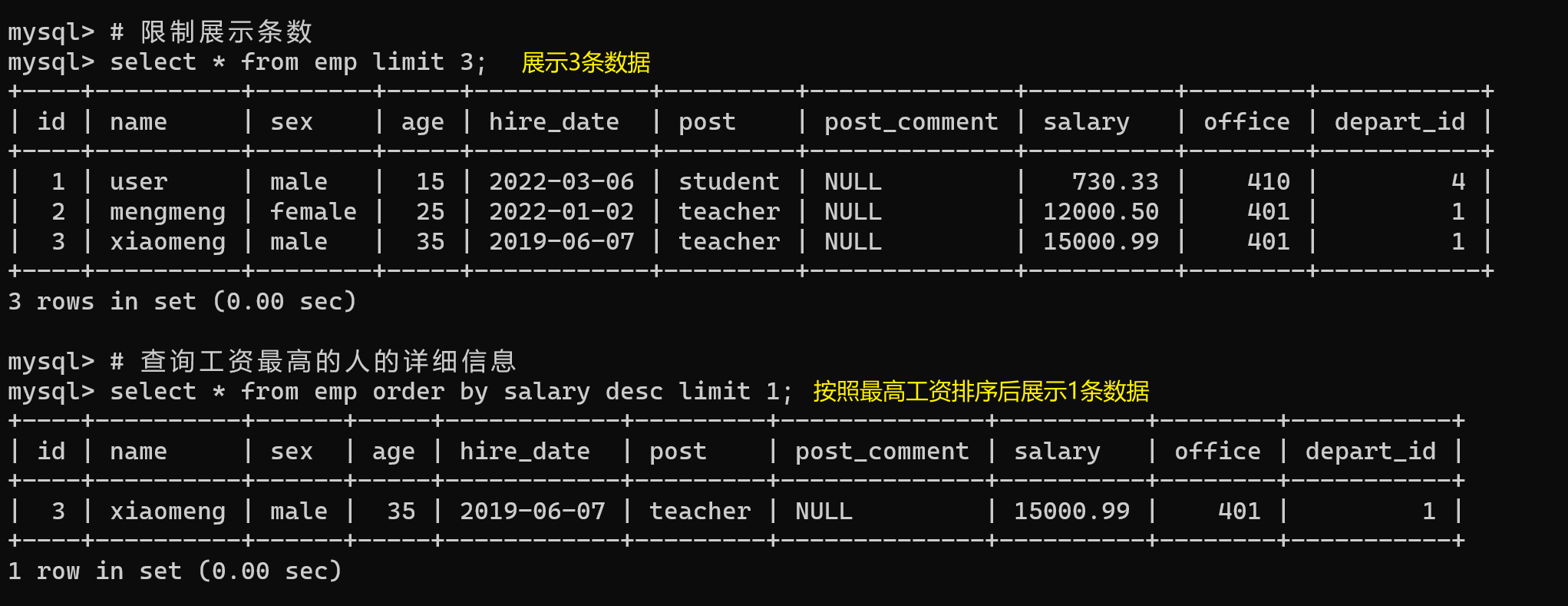
单个参数
# 限制展示条数
select * from emp limit 3;
# 查询工资最高的人的详细信息
select * from emp order by salary desc limit 1;
-
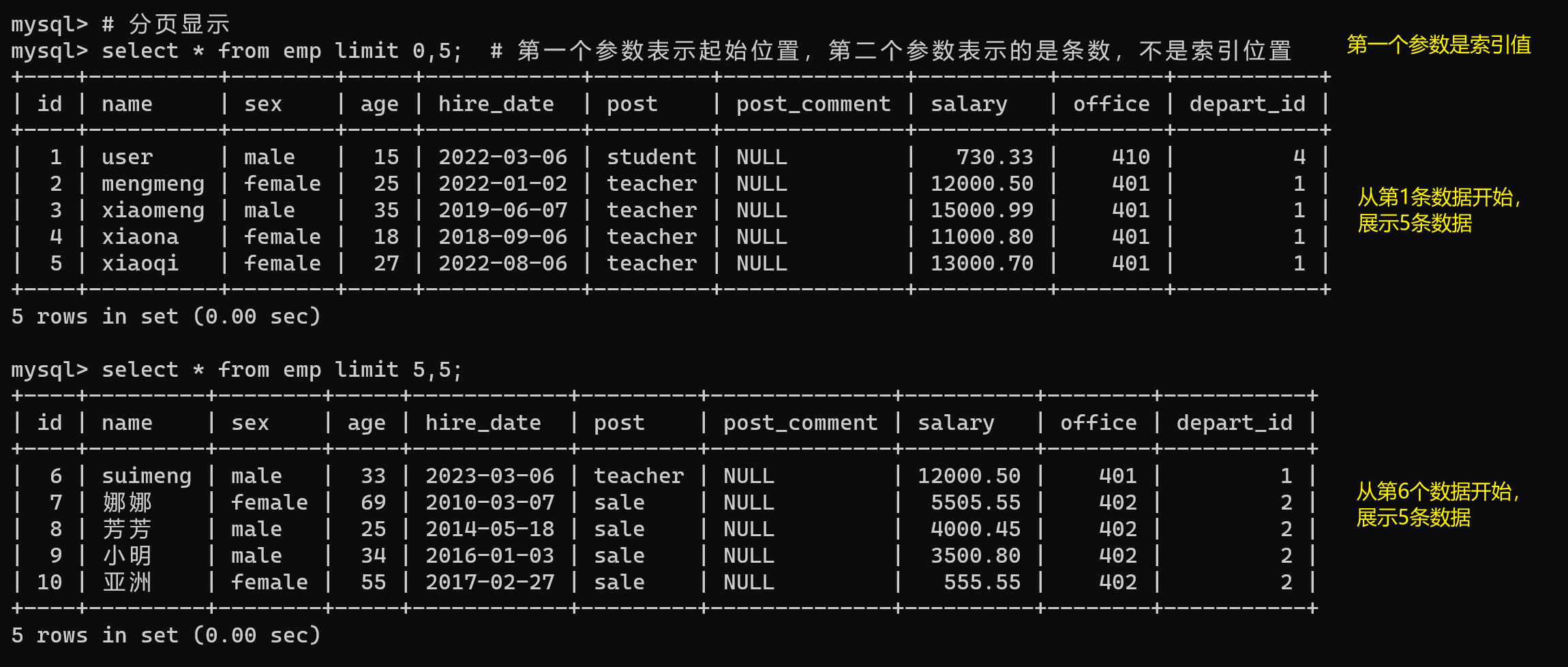
两个参数:作分页展示
# 分页显示
select * from emp limit 0,5; # 第一个参数表示起始位置,第二个参数表示的是条数,不是索引位置
select * from emp limit 5,5;
【6】关键字之regexp正则
-- 支持正则表示式查询
select * from emp where name regexp '^j.*(n|y)$';
select * from emp where name regexp '^x'; -- 查询名字以x开头

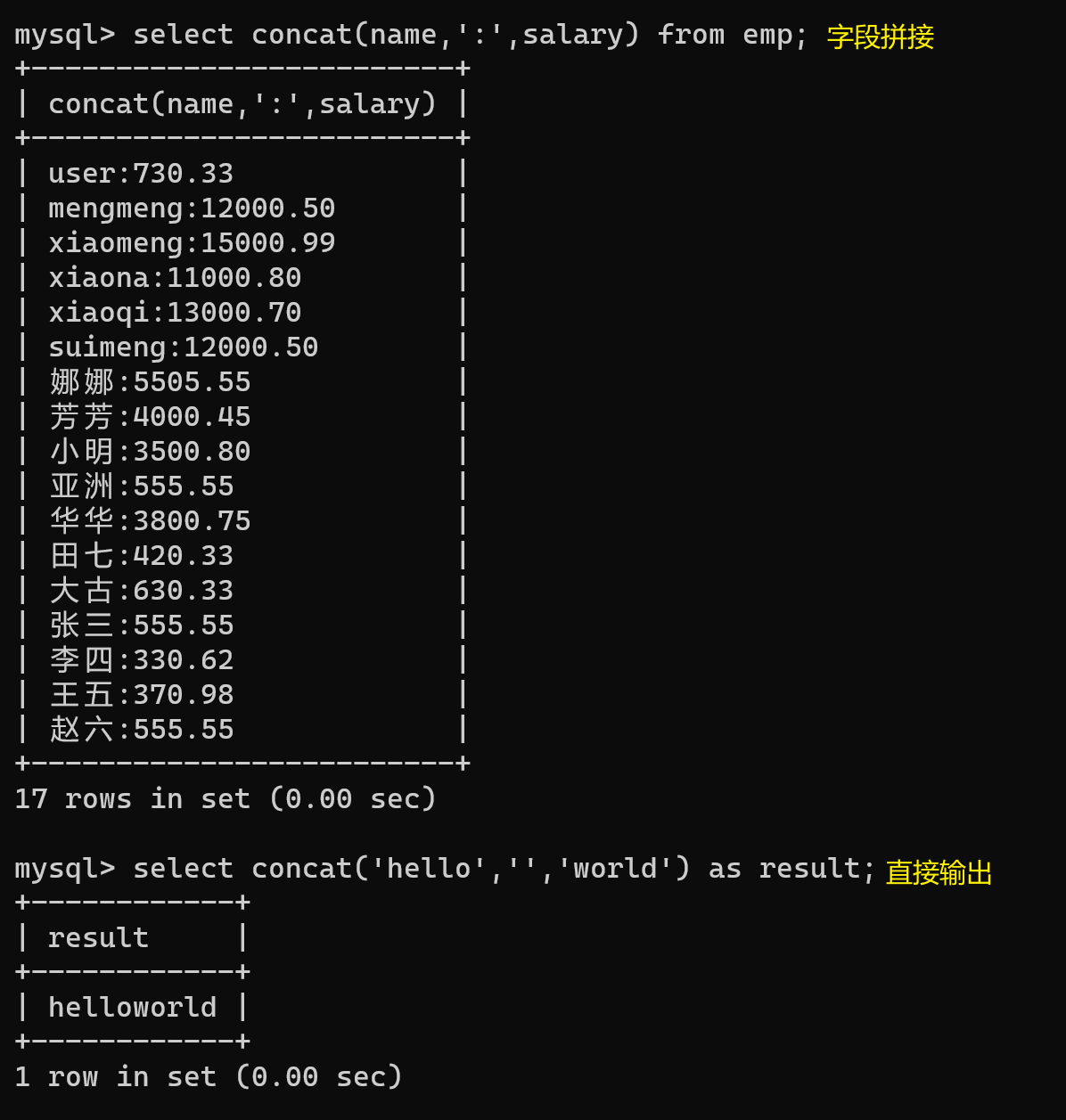
【7】concat 字符串函数
- 与group_concat 功能类似,不过不需要分组后才能使用
-- 拼接字符串
select concat(string1,string2) from *;
-- 直接输出拼接值
select concat(string1,string2) as 字段;
select concat('hello','','world') as result;
select concat(name,':',salary) from emp;
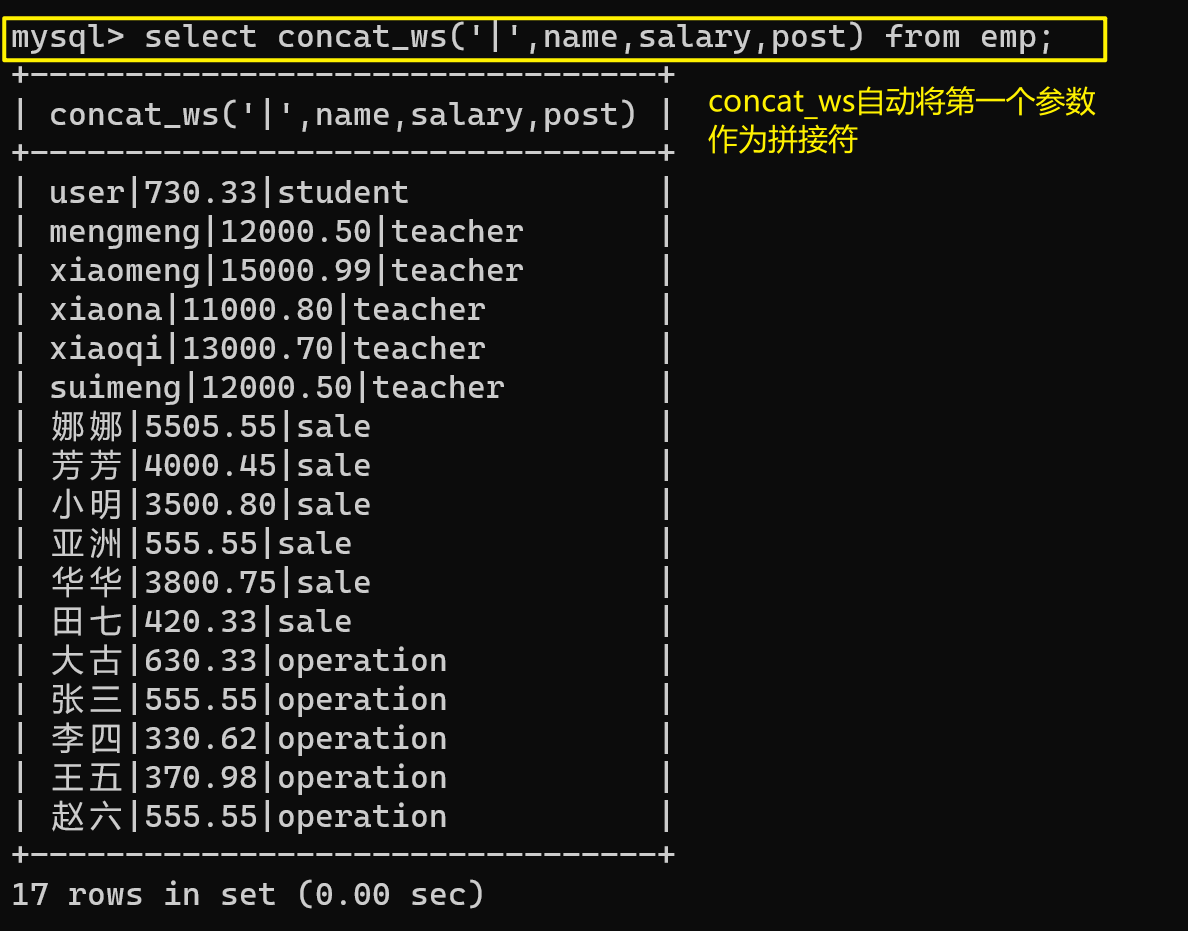
【7.1】concat_ws('分隔符',字段)自动将分隔符拼接
select concat_ws('|',name,salary,post) from emp;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· DeepSeek 开源周回顾「GitHub 热点速览」
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了