Python并发编程之进程池,线程池
【一】进程池和线程池
【0】池
-
池的概念:
- 资源管理: 池用于管理和维护一组资源(如进程或线程),而不是每次需要时都创建和销毁这些资源。这有助于减少创建和销毁的开销。
- 并发处理: 池允许并发地执行多个任务,每个任务由池中的一个资源处理。这提高了程序的并发性能。
- 任务队列: 池通常与任务队列结合使用。任务被提交到队列,然后由池中的资源异步地处理这些任务。这样可以有效地分配和利用资源。
-
好处:
- 资源重用: 池允许重复使用已经创建的资源,而不是为每个任务都创建一个新的资源。这减少了资源创建和销毁的开销,提高了程序的效率。
- 性能提升: 池的并发执行机制可以显著提高程序的性能。通过同时执行多个任务,池允许利用多核处理器和多线程/进程的优势。
- 避免资源耗尽: 在一些并发场景下,如果不使用池,可能会导致系统资源耗尽,例如过多的进程或线程。池通过限制资源的数量和管理任务队列,避免了这些问题。
- 简化代码: 池提供了高级别的接口,简化了并发编程的复杂性。通过将任务提交到池,开发人员可以更专注于任务逻辑,而无需手动管理底层的并发细节。
- 控制并发度: 池允许开发人员控制并发度,即同时执行的任务数量。这可以根据系统资源和应用需求进行调整,避免过度并发导致性能下降。
- 当规定好了池的大小,如果超出池容量的任务将会等待,进程或线程使用的资源就是固定的
- 比如我为我的池分配了任务,这些任务所需的资源为1G,资源就固定为1G,不会超出这个大小
【1】进程池
进程池是一种用于管理和重复使用进程的机制,它可以提高并发性能、减少资源开销,并简化进程的创建和销毁过程。在 Python 中,可以使用 multiprocessing 模块提供的 Pool 类来创建进程池。
Pool 类的主要目标是提供一种方便的方式来并行执行函数。它创建一组工作进程,并分配任务给这些进程。
使用进程池的优势包括:
- 并行执行: 进程池可以同时运行多个任务,提高程序的并发性能。
- 资源重用: 进程池会在初始化时创建一组工作进程,并在多次执行任务时重复使用这些进程,减少了创建和销毁进程的开销。
- 简化代码: 使用进程池可以更方便地并行执行函数,而无需手动管理多个进程的细节。
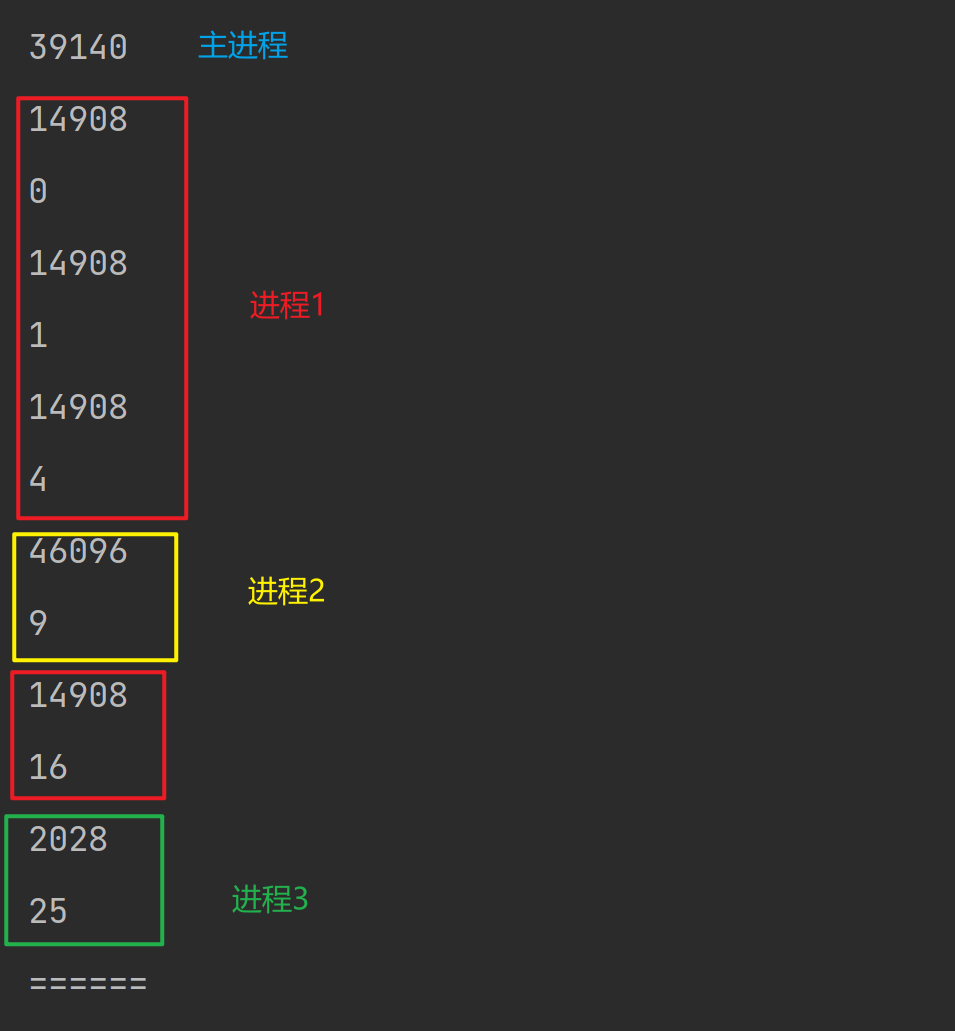
import os
from multiprocessing import Pool,Process
def f1(n):
print(os.getpid())
return n * n
if __name__ == '__main__':
# 创建进程池
pool = Pool(3)
print(os.getpid())
for i in range(6):
# 设置6个任务
res = pool.apply(f1, args=(i,))
print(res)
print("======")
'''等价于'''
# 并且当进程池多,任务少,计算机会自动调节,不会进程全开,可以减少资源的消耗
# 且进程池大小固定,固定资源消耗
process_list = [Process(target =f1,args=(n,) for n in range(3))]
[process.start() for process in process_list]
[process.join() for process in process_list]
【1.1】参数介绍
'''来自源码'''
def Pool(self, processes=None, initializer=None, initargs=(),
maxtasksperchild=None):
...
def __init__(self, processes=None, initializer=None, initargs=(),
maxtasksperchild=None, context=None):
process:- 要创建的进程数,如果省略,将默认使用cpu_count()的值
initializer:- 是每个工作进程启动时要执行的可调用对象,默认为None
initargs:- 是要传给initializer的参数组
maxtasksperchild:- 指定每个子进程执行的任务数量上限。一旦子进程执行了指定数量的任务,该子进程将会被终止,然后新的子进程将会被创建
【1.2】常用方法
map(func, iterable[, chunksize=None]):- 作用:将函数
func应用于iterable中的每个元素,返回结果列表。类似于内置函数map(),但使用进程池并行处理。 - 参数:
func: 要映射的函数。iterable: 要处理的可迭代对象。chunksize: 每个任务的数据块大小,影响任务的划分方式。
- 作用:将函数
imap(func, iterable[, chunksize=None]):- 作用:返回一个迭代器,通过迭代获取并行处理的结果。与
map()类似,但是不会立即返回结果列表,而是在需要时逐步获取。 - 参数同
map()。
- 作用:返回一个迭代器,通过迭代获取并行处理的结果。与
apply(func, args=(), kwds={}):- 作用:将函数
func应用于参数args和关键字参数kwds,返回结果。 - 参数:
func: 要执行的函数。args: 函数的位置参数,以元组形式传递。kwds: 函数的关键字参数,以字典形式传递。
- 作用:将函数
apply_async(func, args=(), kwds={}, callback=None, error_callback=None):- 作用:异步地将函数
func应用于参数args和关键字参数kwds。返回一个AsyncResult对象,可用于获取异步执行的结果。 - 参数:
func: 要执行的函数。args: 函数的位置参数,以元组形式传递。kwds: 函数的关键字参数,以字典形式传递。callback: 在任务完成时调用的回调函数。error_callback: 在任务发生异常时调用的回调函数。
- 作用:异步地将函数
map_async(func, iterable[, chunksize=None, callback=None, error_callback=None]):- 作用:异步地将函数
func应用于iterable中的每个元素,返回一个AsyncResult对象,可用于获取异步执行的结果。 - 参数:
func: 要映射的函数。iterable: 要处理的可迭代对象。chunksize: 每个任务的数据块大小,影响任务的划分方式。callback: 在任务完成时调用的回调函数。error_callback: 在任务发生异常时调用的回调函数。
- 作用:异步地将函数
close():- 作用:关闭进程池,阻止添加新的任务。已经添加的任务将继续执行。
terminate():- 作用:立即终止所有的工作进程,不等待它们完成。
join():- 作用:等待所有工作进程完成。
【1.3】基于进程池优化TCP协议的高并发程序
【1.3.1】回顾
'''server'''
from socket import *
from multiprocessing import Process
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
def talk(conn, client_addr):
while True:
try:
msg = conn.recv(1024)
if not msg: break
decode_msg = msg.decode('utf8')
if decode_msg == 'q':
print(f"【{client_addr}】断开连接!")
conn.send(b'q')
break
print(f"来自【{client_addr}】的消息【{decode_msg}】")
conn.send(msg.upper())
except Exception as e:
print(f"出现了错误:{e}")
break
if __name__ == '__main__': # windows下start进程一定要写到这下面
while True:
conn, client_addr = server.accept()
p = Process(target=talk, args=(conn, client_addr))
p.start()
'''client'''
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
send_msg = input("请输入转为大写的字母:").strip()
if not send_msg.isalpha():
print("请输入字母!")
continue
send_msg = send_msg.encode('utf8')
client.send(send_msg)
recv_msg = client.recv(1024)
if recv_msg == b'q':
print("已断开与服务器的连接")
break
print(recv_msg.decode('utf8'))
- 问题:
- 当同一时刻,接入的客户端非常多时,来一个客户端开设一个,将会对CPU造成很大的压力
【1.3.2】优化
from socket import *
from multiprocessing import Pool
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
def talk(conn, client_addr):
while True:
try:
msg = conn.recv(1024)
if not msg: break
decode_msg = msg.decode('utf8')
if decode_msg == 'q':
print(f"【{client_addr}】断开连接!")
conn.send(b'q')
break
print(f"来自【{client_addr}】的消息【{decode_msg}】")
conn.send(msg.upper())
except Exception as e:
print(f"出现了错误:{e}")
break
if __name__ == '__main__': # windows下start进程一定要写到这下面
'''创建线程池,限制同一时间只接受3个客户端,第4个将等待'''
pool = Pool(3)
while True:
conn, client_addr = server.accept()
pool.apply_async(talk, args=(conn, client_addr))
- 客户端不变
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
send_msg = input("请输入转为大写的字母:").strip()
if not send_msg.isalpha():
print("请输入字母!")
continue
send_msg = send_msg.encode('utf8')
client.send(send_msg)
recv_msg = client.recv(1024)
if recv_msg == b'q':
print("已断开与服务器的连接")
break
print(recv_msg.decode('utf8'))
【1.4】multiprocessing 模块与concurrent.futures 模块中的进程池区别
multiprocessing 模块中的 Pool 类与 concurrent.futures 模块中的 ProcessPoolExecutor 类都提供了进程池的实现,但它们之间有一些细微的区别。
- 模块的归属:
multiprocessing.Pool属于multiprocessing模块,专门用于并行处理。concurrent.futures.ProcessPoolExecutor属于concurrent.futures模块,提供通用的并发执行框架,其中包括线程池和进程池。
- API 的设计:
multiprocessing.Pool的 API 设计更为简单,适合于简单的并行任务。concurrent.futures.ProcessPoolExecutor的 API 设计更加通用,与concurrent.futures模块中的其他执行器(如ThreadPoolExecutor)保持一致,提供更多灵活性。
- 上下文管理器:
concurrent.futures.ProcessPoolExecutor支持使用with语句作为上下文管理器,可以更方便地管理资源的释放。multiprocessing.Pool也可以使用with语句,但在某些情况下可能需要注意。
- 异常处理:
concurrent.futures.ProcessPoolExecutor使用concurrent.futures模块的异常处理机制,可以通过as_completed或wait方法获取异常。multiprocessing.Pool使用imap和imap_unordered等方法时,异常处理相对较为复杂,可能需要使用特定的方式来获取异常。
- 其他特性:
multiprocessing.Pool提供了一些额外的方法,如map_async、imap_unordered等,用于更灵活地处理异步任务。concurrent.futures.ProcessPoolExecutor提供了submit方法,使得可以更方便地提交任务,并获取Future对象。
总体而言,选择使用哪个取决于具体的需求。如果只需要进行简单的并行任务,multiprocessing.Pool 可能更为直观和简单。如果需要更通用的并发执行框架,并且希望在不同类型的执行器之间切换,可以考虑使用 concurrent.futures.ProcessPoolExecutor。
【2】线程池
在 Python 中,线程池的常用实现是使用 concurrent.futures 模块提供的 ThreadPoolExecutor 类。
【2.1】参数介绍
'''来自源码'''
def __init__(self, max_workers=None, thread_name_prefix='',
initializer=None, initargs=()):
max_workers:- 作用:指定线程池中最大的线程数。
- 类型:整数。
- 默认值:
None,表示根据系统的情况自动选择合适的线程数。
thread_name_prefix:- 作用:为线程池中的线程设置一个名称前缀,用于标识线程池中的线程。
- 类型:字符串。
- 默认值:空字符串。
initializer:- 作用:一个可调用对象,当线程被启动时会调用这个函数。
- 类型:可调用对象,通常是一个函数。
- 默认值:
None,表示不需要初始化函数。
initargs:- 作用:传递给初始化函数
initializer的参数,以元组形式提供。 - 类型:元组。
- 默认值:空元组。
- 作用:传递给初始化函数
【2.2】常用方法
以下是线程池中的一些主要方法和操作:
-
ThreadPoolExecutor(max_workers=None):- 作用:创建线程池对象,指定最大线程数
max_workers。
- 作用:创建线程池对象,指定最大线程数
-
submit(func, \*args, \**kwargs):- 作用:将函数
func提交到线程池执行,并返回一个Future对象,用于获取函数执行的结果。 - 参数:
func: 要执行的函数。args: 函数的位置参数,以元组形式传递。kwargs: 函数的关键字参数,以字典形式传递。
- 作用:将函数
-
map(func, \*iterables, timeout=None, chunksize=1):- 作用:将函数
func应用于iterables中的每个元素,返回结果列表。类似于内置函数map(),但使用线程池并行处理。 - 参数:
func: 要映射的函数。iterables: 要处理的可迭代对象。timeout: 每个线程最大执行时间。chunksize: 每个任务的数据块大小,影响任务的划分方式。
- 作用:将函数
-
shutdown(wait=True):- 作用:关闭线程池,阻止添加新的任务。已经添加的任务将继续执行。
- 参数:
wait: 如果为True,则等待所有任务完成后再关闭。
-
map_async(func, \*iterables, callback=None):- 作用:异步地将函数
func应用于iterables中的每个元素,返回一个Future对象,用于获取异步执行的结果。 - 参数:
func: 要映射的函数。iterables: 要处理的可迭代对象。callback: 在任务完成时调用的回调函数。
- 作用:异步地将函数
-
submit(func, \*args, \**kwargs):- 作用:类似于
ThreadPoolExecutor的submit()方法,将函数func提交到线程池执行,并返回一个Future对象。
- 作用:类似于
-
as_completed(fs, timeout=None):- 作用:返回一个生成器,迭代在
fs中完成的Future对象。 - 参数:
fs: 一个包含Future对象的可迭代对象。timeout: 每个线程最大执行时间。
- 作用:返回一个生成器,迭代在
-
wait(fs, timeout=None, return_when=ALL_COMPLETED):- 作用:等待给定的
Future对象集合完成。 - 参数:
fs: 一个包含Future对象的可迭代对象。timeout: 每个线程最大执行时间。return_when: 指定在何时返回,可以是ALL_COMPLETED、FIRST_COMPLETED或FIRST_EXCEPTION。
- 作用:等待给定的
from concurrent.futures import ThreadPoolExecutor
# def __init__(self, max_workers=None, thread_name_prefix='',initializer=None, initargs=())
def task(m, n):
print(m + n)
# return m + n
if __name__ == '__main__':
# 定义一个线程池,容量为3
pool = ThreadPoolExecutor(3)
# 通过submit提交任务
pool.submit(task, m=1, n=2)
pool.submit(task, m=2, n=3)
pool.submit(task, m=3, n=4)
pool.shutdown() # 相当于join,将会等待线程池中的任务全部完成
print("====")
【3】使用回调函数获取任务结果
- 在进程池和线程池中,都是可以通过回调函数来获取到任务执行的结果
【3.1】进程池 multiprocessing.Pool
- 通过
apply_async方法指定callback参数
from multiprocessing import Pool
def square(x):
return x * x
def callback(result):
'''回调函数一般是为了对任务执行结果继续加工'''
result +=1
print(f"回调函数|{result}")
if __name__ == "__main__":
# 支持with语句
with Pool() as pool:
result_list = []
# Pool默认大小是cpu数量
# 通过apply_async提交任务
result_async1 = pool.apply_async(square, (10,), callback=callback)
result_async2 = pool.apply_async(square, (5,), callback=callback)
result_async3 = pool.apply_async(square, (2,), callback=callback)
result_list.append(result_async1)
result_list.append(result_async2)
result_list.append(result_async3)
# print(result_async1) # <multiprocessing.pool.ApplyResult object at 0x000001C8DC903D60>
# 获取异步任务的返回值
for result in result_list:
'''可以通过回调函数打印值,也可以通过.get()拿到值'''
print(f"主进程打印|{result.get()}")
# 等待所有异步任务完成
pool.close()
pool.join()
print("====")
# 回调函数|101
# 回调函数|26
# 回调函数|5
# 主进程打印|100
# 主进程打印|25
# 主进程打印|4
# ====
【3.2】进程池concurrent.futures.ProcessPoolExecutor
from concurrent.futures import ProcessPoolExecutor
def task(m, n):
# 任务是返回两个参数相加的和
return m + n
# 通过回调函数来获取任务的返回值
def callback(res):
'''
:param res: 需要通过一个形参去接收需要任务返回的结果
'''
# print(res)
# 通过res.result()来获得值
print(res.result())
# 注:callback函数不应该返回东西了,无法通过变量来接收返回值
return res.result()
if __name__ == '__main__':
# 定义一个进程池,容量为3
pool = ProcessPoolExecutor(3)
# 通过submit提交任务
# 通过【.add_done_callback(回调函数)】获取值
res = pool.submit(task, m=1, n=2).add_done_callback(callback)
res1 = pool.submit(task, m=2, n=3).add_done_callback(callback)
res2 = pool.submit(task, m=3, n=4).add_done_callback(callback)
pool.shutdown() # 相当于join,将会等待线程池中的任务全部完成
print(res) # None
print("====")
【3.3】线程池concurrent.futures.ThreadPoolExecutor
- 与【3.2】基本一致,通过
add_done_callback(callback)获取值
from concurrent.futures import ThreadPoolExecutor
def task(m, n):
# 任务是返回两个参数相加的和
return m + n
# 通过回调函数来获取任务的返回值
def callback(res):
'''
:param res: 需要通过一个形参去接收需要任务返回的结果
'''
# print(res)
# 通过res.result()来获得值
print(res.result())
# 注:callback函数不应该返回东西了,无法通过变量来接收返回值
return res.result()
if __name__ == '__main__':
# 定义一个线程池,容量为3
pool = ThreadPoolExecutor(3)
# 通过submit提交任务
# 通过【.add_done_callback(回调函数)】获取值
res = pool.submit(task, m=1, n=2).add_done_callback(callback)
res1 = pool.submit(task, m=2, n=3).add_done_callback(callback)
res2 = pool.submit(task, m=3, n=4).add_done_callback(callback)
pool.shutdown() # 相当于join,将会等待线程池中的任务全部完成
print(res) # None
print("====")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号