Python并发编程之多进程与多线程
多进程与多线程
【一】概要
- 在Python中,有两种主要的并发编程方式:多进程和多线程。
【二】常用方法
- 多进程
import multiprocessing
import os
def run_task(i):
'''os模块中有getpid方法,可以获取当前进程的pid'''
print(f"{i}子进程{os.getpid()}正在运行!")
'''windows中开启进程必须在该语句下,否则将会报错'''
if __name__ == '__main__':
p_list = []
for i in range(1, 5):
p = multiprocessing.Process(target=run_task, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("主进程已结束")
'''
1子进程19788正在运行!
2子进程23884正在运行!
4子进程888正在运行!
3子进程18212正在运行!
主进程已结束
'''
- 多线程
import threading
import os
def run_task(i):
'''os模块中有getpid方法,可以获取当前进程的pid'''
# 同一个进程下的子线程PID一致
print(f"{i}子线程{os.getpid()}正在运行!")
'''windows中开启进程必须在该语句下,否则将会报错'''
if __name__ == '__main__':
p_list = []
for i in range(1, 5):
'''与进程参数一致'''
p = threading.Thread(target=run_task, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("主进程已结束")
'''
1子线程27700正在运行!
2子线程27700正在运行!
3子线程27700正在运行!
4子线程27700正在运行!
主进程已结束
'''
【三】详解
【1】多进程
【1.1】多进程特点
- 独立内存空间: 每个进程有自己独立的内存空间,进程间的数据不共享,通信需要通过特定的机制来实现。
- 资源隔离: 进程之间相互独立,一个进程的崩溃不会影响其他进程,因为它们有独立的内存空间。
- 适用于 CPU 密集型任务: 适用于需要大量计算的任务,因为每个进程都有自己的 Python 解释器和全局解释器锁(GIL)。
- 创建进程的开销较大: 创建新的进程涉及到较大的开销,因为需要复制父进程的内存空间。
- 在Python中,可以使用
multiprocessing模块来实现多进程编程。
【1.2】基本模板
import multiprocessing
def run_task(i):
'''需要执行的任务'''
if __name__ == '__main__':
p_list = []
for i in range(1, 5):
# target:任务的函数名,不加括号
# args:任务的参数,没有则忽略,有则添元组
p = multiprocessing.Process(target=run_task, args=(i,))
# 启动进程
p.start()
p_list.append(p)
for p in p_list:
# join是为了帮助当子进程全部执行完毕后,主进程才结束
p.join()
print("主进程已结束")
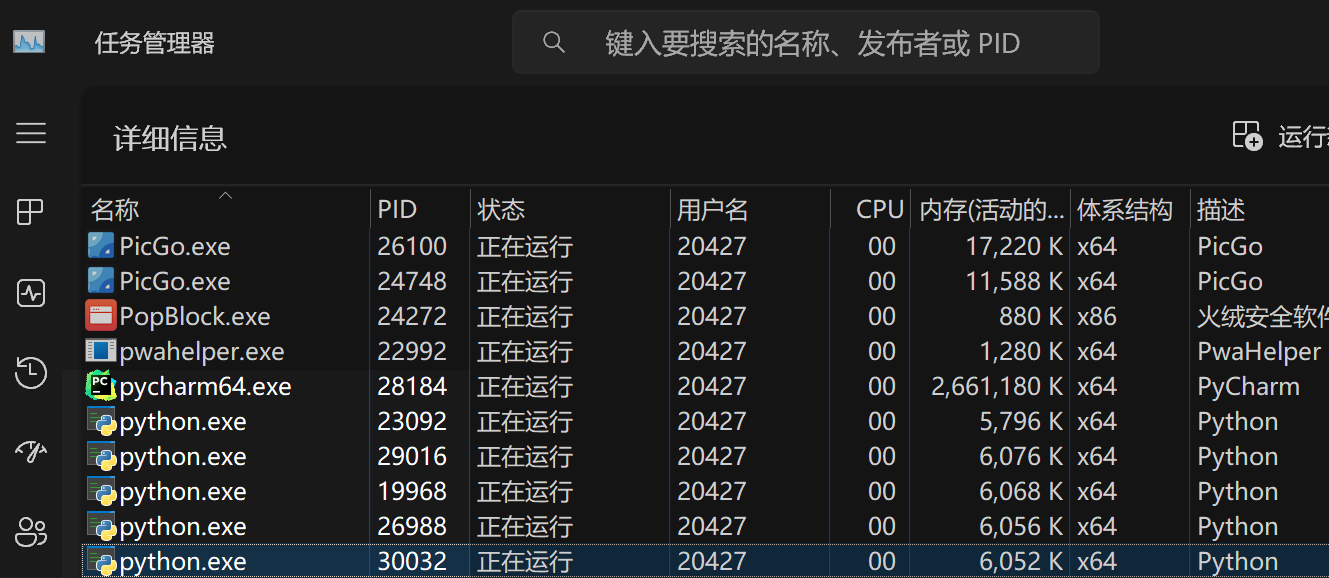
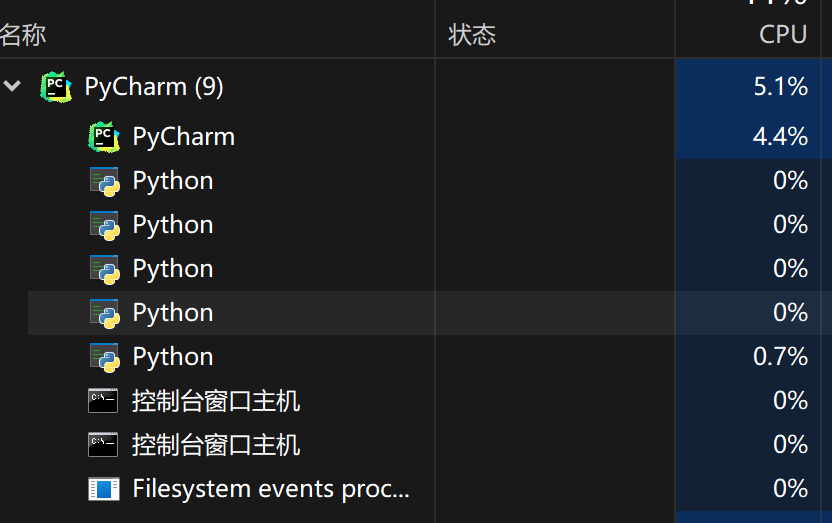
- 当进程启动,会在任务管理器中看到进程
- pycharm是父进程
- 当代码未运行,将不会出现其余python进程
- 当代码运行时,其中一个是主进程,其余是创建出来的子进程,好像没办法看出来
- 但是可以通过阻塞,查看进程的消失顺序
import multiprocessing
import os
import time
def run_task(i):
print(f"{i}子进程{os.getpid()}正在运行!")
time.sleep(5)
if __name__ == '__main__':
p_list = []
for i in range(1, 5):
p = multiprocessing.Process(name=f"task_{i}",target=run_task, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
time.sleep(10)
print("主进程已结束")
'''由于运行时间不一致会导致顺序与创建不一致'''
'''由于出现了阻塞,当阻塞结束时,所有进程将在同一时间继续运行'''
'''有点像异步?'''
# 3子进程26988正在运行!
# 1子进程29016正在运行!
# 2子进程19968正在运行!
# 4子进程30032正在运行!
# 主进程已结束
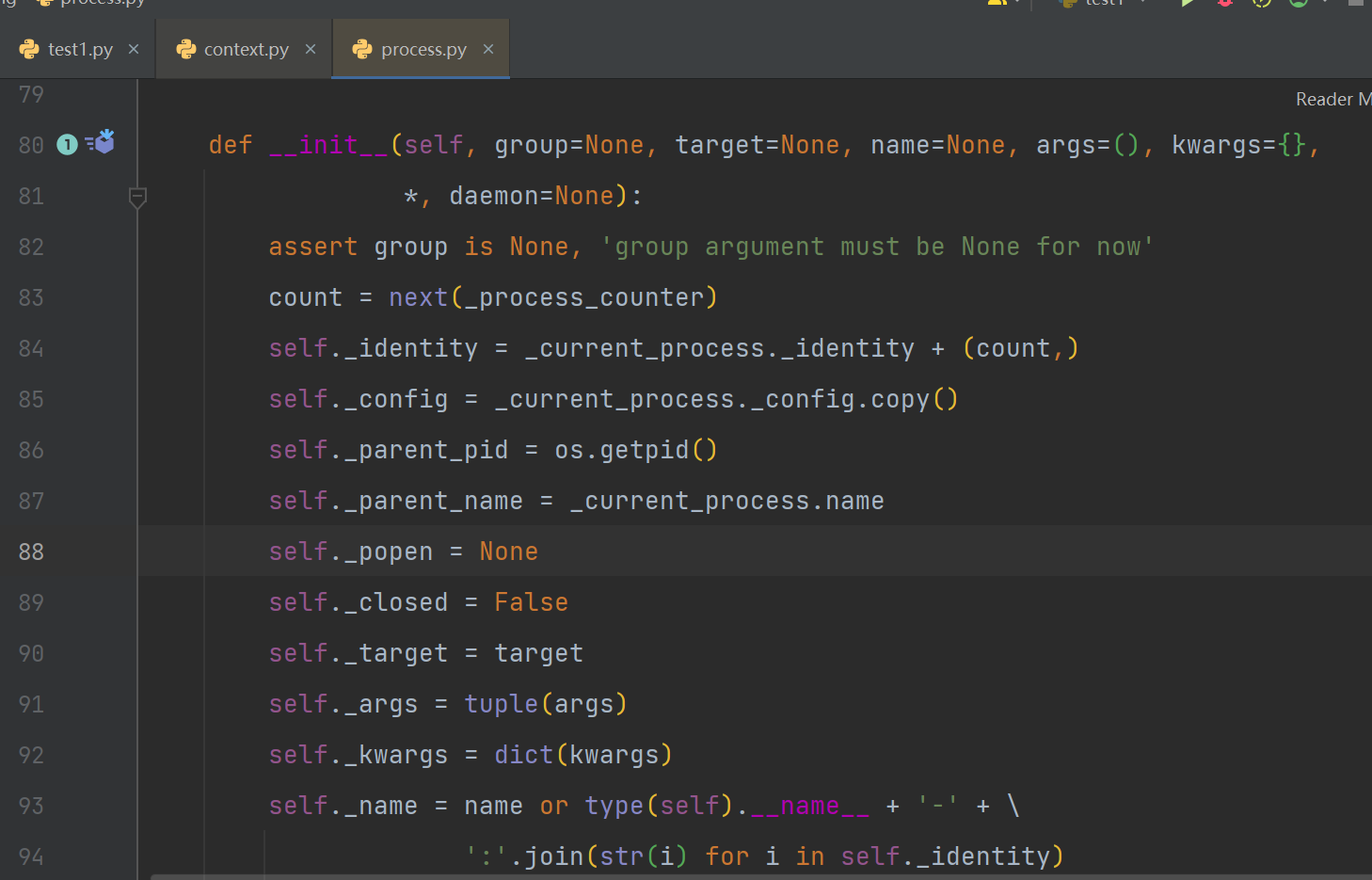
【1.3】参数详解
【1.3.1】初始化进程对象
- 通过追代码,可以看到process类的
__init__方法中的参数就是我们需要在创建进程对象时所需要填写的
-
都是有默认参数的,所有可以创建一个空的进程对象,但这样就没有意义了
-
group:断言assert group is None, 'group argument must be None for now',所有不需要填写数值-
group参数表示进程所属的进程组。这个参数通常用于在创建一组相关的进程时,将它们放入同一个组中,以便更方便地进行集中管理。但需要注意的是,
Group类并非在所有情况下都被广泛使用,而且在Python 3.6及之后的版本中,group参数的使用已经不被推荐,因为在实际应用中并没有提供太多实际的好处。
-
-
target: 表示要在新进程中运行的函数 -
args:表示传递给目标函数的位置参数,以元组的形式提供。 -
kwargs:表示传递给目标函数的关键字参数,以字典的形式提供。 -
daemon:用于设置进程是否为守护进程。守护进程是一种在主程序运行时后台执行的进程,当主程序退出时,守护进程会随之结束,而不会等待它完成。详细请查看【守护进程】
【1.3.2】方法介绍
-
p.start():- 启动进程,并调用该子进程中的p.run()
-
p.run():- 进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
-
p.terminate():- 强制终止进程p,不会进行任何清理操作
- 如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。
- 如果p还保存了一个锁那么也将不会被释放,进而导致死锁
-
p.is_alive():- 如果p仍然运行,返回True
-
p.join([timeout]):-
主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。
-
timeout是可选的超时时间
-
需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
-
【1.3.2】属性介绍
-
p.daemon:- 默认值为False
- 如果设为True,代表p为后台运行的守护进程
- 当p的父进程终止时,p也随之终止
- 并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
-
p.name: -
进程的名称
-
p.pid:- 进程的pid
-
p.exitcode:- 进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
-
p.authkey:- 进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。
- 这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
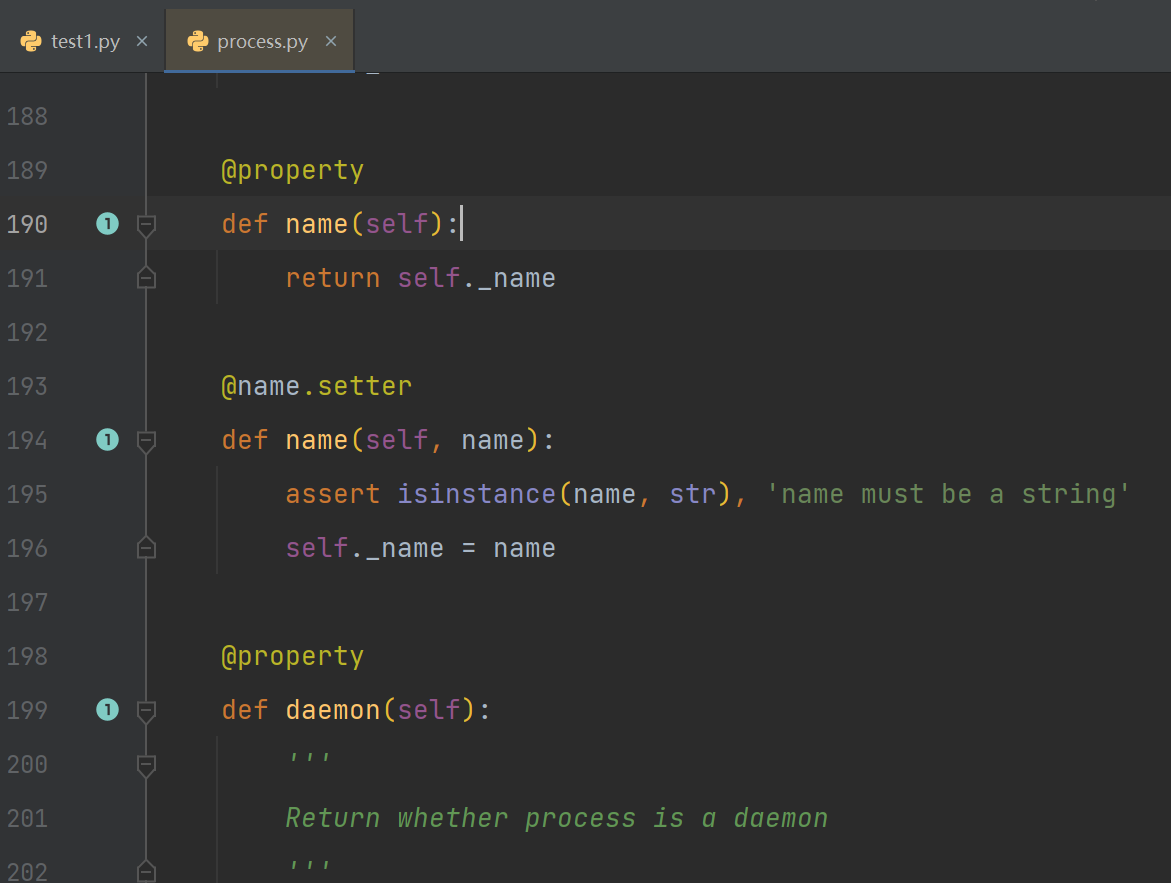
- 通过追代码可以看到,属性其实就是封装起来的函数,所以可以动态的变化
【1.4】创建并开启子进程的两种方式
【1.4.1】直接使用Process方法
import multiprocessing
import os
def run_task(i):
print(f"{i}子进程{os.getpid()}正在运行!")
if __name__ == '__main__':
p_list = []
for i in range(1, 5):
'''name参数可以指定任务名,不指定将默认为Process-1'''
p = multiprocessing.Process(name=f"task_{i}",target=run_task, args=(i,))
print(p.name)
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("主进程已结束")
【1.4.2】通过继承Process类并重写run函数
-
Process中的
start()本质就是调用类中的run()方法-
在 Python 中,
multiprocessing.Process类的start方法实际上是调用了操作系统底层的创建进程的接口,并在新的进程中执行一个函数(通常是用户指定的目标函数)。这个目标函数会在新的进程中作为入口点执行,从而实现了多进程并发执行。在
multiprocessing.Process类中,实际的执行逻辑是通过run方法来定义的。默认情况下,run方法被设置为执行用户通过target参数指定的目标函数。因此,当调用start方法启动进程时,实际上是在新的进程中执行了run方法。
-
import os
# 通过from导入,可以偷懒,因为太长了
from multiprocessing import Process
'''通过继承Process类'''
class MyProcess(Process):
# 将需要用到的参数在实例化时传入
def __init__(self, i):
# super一下原对象的__init__方法
super().__init__()
# 将参数添加到名称空间
self.i = i
# 需要执行的任务
def run(self) -> None:
print(f"{self.i}子进程{os.getpid()} 正在执行!")
if __name__ == '__main__':
p_lst = [MyProcess(i=i) for i in range(1, 5)]
'''显摆一下列表生成式'''
[p.start() for p in p_lst]
[p.join() for p in p_lst]
# 2子进程5716 正在执行!
# 4子进程13788 正在执行!
# 1子进程30216 正在执行!
# 3子进程22532 正在执行!
【1.5】进程间的独立性
'''创建对象不太明显,可以看下面的数字'''
from multiprocessing import Process
class Foo(object):
def __init__(self, name):
self.name = name
def run_task(name):
f = Foo(name=name)
print(f.__dict__)
if __name__ == '__main__':
p_list = []
for i in ['user001', 'user002', 'user003']:
p = Process(target=run_task, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("主函数结束啦~")
# {'name': 'user002'}
# {'name': 'user003'}
# {'name': 'user001'}
# 主函数结束啦~
'''修改数字'''
from multiprocessing import Process
num = 100
def run_task(name):
# 声明全局变量
global num
# 修改全局变量
num += 1
print(f"{name} 进程中的 num值为{num}")
if __name__ == '__main__':
p_list = []
for i in ['user001', 'user002', 'user003']:
p = Process(target=run_task, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("主函数结束啦~")
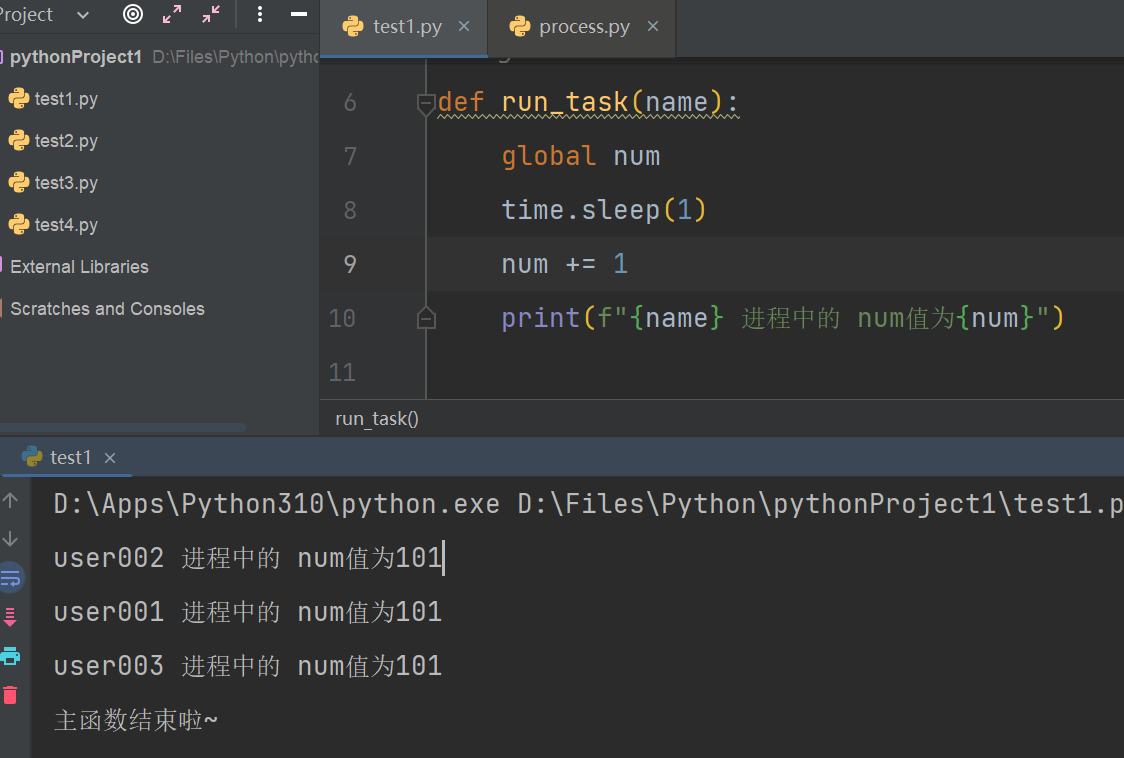
'''num的值并不会变成103,而是每一个进程拿到的num值都为100'''
# user001 进程中的 num值为101
# user002 进程中的 num值为101
# user003 进程中的 num值为101
# 主函数结束啦~
- 就算进行了堵塞,也还是一致的
【1.6】p.join()方法介绍
-
在多进程编程中,当一个进程启动后,主进程通常需要等待子进程执行完成后再继续执行下面的代码。
join()方法就是用来实现这个等待的。 -
具体来说,
process.join()会阻塞主进程,直到调用该方法的进程(这里是process)执行完毕。如果不使用join(),主进程可能会在子进程还没有执行完毕就继续往下执行,这可能导致程序的执行顺序混乱。 -
错误的情况-未使用join方法
import os
from multiprocessing import Process
def run_task(i):
print(f"{i} 进程{os.getpid()}正在 运行")
if __name__ == '__main__':
print("-----主进程开始-----")
for i in range(1, 5):
p = Process(target=run_task, args=(i,))
p.start()
print("-----主进程结束-----")
'''错乱的情况'''
# -----主进程开始-----
# -----主进程结束-----
# 2 进程8896正在 运行
# 3 进程9024正在 运行
# 4 进程19652正在 运行
# 1 进程13536正在 运行
- 错误的情况-未正确使用join
- 当不适用join的时候,创建多进程是异步非阻塞,速度非常快
- 当正确使用join的时候,创建多进程就变味了异步阻塞
- 而当你创建进程对象时也使用join时,创建多进程就变为了同步阻塞,巨慢无比
import os
import time
from multiprocessing import Process
def run_task(i):
print(f"{i} 进程{os.getpid()}正在 运行")
'''将join方法放置在创建对象后'''
if __name__ == '__main__':
start_time = time.time()
p_list = []
print("-----主进程开始-----")
for i in range(1, 5):
p = Process(target=run_task, args=(i,))
p.start()
p_list.append(p)
p.join()
print("-----主进程结束-----")
print(f"耗时{time.time()-start_time}s") # 耗时0.603428840637207s
'''正确做法'''
if __name__ == '__main__':
start_time = time.time()
p_list = []
print("-----主进程开始-----")
for i in range(1, 5):
p = Process(target=run_task, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("-----主进程结束-----")
print(f"耗时{time.time()-start_time}s") # 耗时0.1525125503540039s
- 正确的情况-正确使用join方法
import os
from multiprocessing import Process
def run_task(i):
print(f"{i} 进程{os.getpid()}正在 运行")
if __name__ == '__main__':
p_list = []
print("-----主进程开始-----")
for i in range(1, 5):
p = Process(target=run_task, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("-----主进程结束-----")
'''正确的情况'''
# -----主进程开始-----
# 2 进程26980正在 运行
# 1 进程28212正在 运行
# 3 进程20596正在 运行
# 4 进程24860正在 运行
# -----主进程结束-----
- 正确的情况-通过time.sleep创建阻塞
import os
import time
from multiprocessing import Process
def run_task(i):
print(f"{i} 进程{os.getpid()}正在 运行")
if __name__ == '__main__':
p_list = []
print("-----主进程开始-----")
for i in range(1, 5):
p = Process(target=run_task, args=(i,))
p.start()
p_list.append(p)
# for p in p_list:
# p.join()
'''因为目的就是阻塞,所以通过time.sleep设置阻塞也能达到同样的效果'''
time.sleep(1)
print("-----主进程结束-----")
# -----主进程开始-----
# 2 进程26980正在 运行
# 1 进程28212正在 运行
# 3 进程20596正在 运行
# 4 进程24860正在 运行
# -----主进程结束-----
【1.7】查看进程号
-
终端运行
- win
tasklist:查看所有进程tasklist |findstr PID:查看指定PID的进程
- mac
ps aux:查看所有进程ps aux|grep PID:查看指定PID的进程
- win
-
代码使用
multiprocessing.current_process().pid:当前进程的进程号os.getpid():当前进程的进程号os.getppid():查看父进程的PID
【1.8】报错信息
- 未将创建新进程的操作放在主程序的
if __name__ == '__main__':语句下执行
'''错误源码'''
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
'''中文翻译'''
尝试在当前进程完成引导阶段之前启动新进程。
这可能意味着您没有使用fork来启动子进程,而且您在主模块中忘记使用正确的惯用法:
if __name__ == '__main__':
freeze_support()
...
如果程序不打算被冻结以生成可执行文件,则可以省略"freeze_support()"行。
'''报错理由'''
# 这样做的原因涉及到操作系统在启动新进程时的一些细节,确保主程序模块在启动新进程时不会再次执行整个脚本。
【1.9】基于TCP协议的高并发程序
- 服务端
from socket import *
from multiprocessing import Process
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
def talk(conn, client_addr):
while True:
try:
msg = conn.recv(1024)
if not msg: break
decode_msg = msg.decode('utf8')
if decode_msg == 'q':
print(f"【{client_addr}】断开连接!")
conn.send(b'q')
break
print(f"来自【{client_addr}】的消息【{decode_msg}】")
conn.send(msg.upper())
except Exception as e:
print(f"出现了错误:{e}")
break
if __name__ == '__main__': # windows下start进程一定要写到这下面
while True:
conn, client_addr = server.accept()
p = Process(target=talk, args=(conn, client_addr))
p.start()
- 客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
send_msg = input("请输入转为大写的字母:").strip()
if not send_msg.isalpha():
print("请输入字母!")
continue
send_msg = send_msg.encode('utf8')
client.send(send_msg)
recv_msg = client.recv(1024)
if recv_msg == b'q':
print("已断开与服务器的连接")
break
print(recv_msg.decode('utf8'))
【补】setsockopt(__level: int, __optname: int, __value: int | bytes)参数
-
__level: 表示套接字选项的级别。SOL_SOCKET表示通用套接字选项,适用于所有套接字类型。 -
__optname: int: 表示具体的套接字选项。在这个例子中,SO_REUSEADDR是地址重用选项。启用这个选项后,允许在关闭服务器后立即重新使用服务器绑定的地址和端口。 -
__value:表示选项的值。在大多数情况下,当你希望启用一个选项时,将值设置为1,表示启用该选项。
【2】多线程
【2.1】多线程特点
- 共享内存空间: 所有线程共享相同的内存空间,因此它们可以直接访问共享数据。
- 资源共享: 线程之间共享相同的资源,但需要注意线程同步以避免数据竞争。
- 适用于 I/O 密集型任务: 适用于需要进行大量 I/O 操作的任务,因为在 I/O 操作中,线程可以释放 GIL。
- 创建线程的开销相对较小: 相对于进程,创建新线程的开销较小,因为它们共享相同的地址空间。
- 在Python中,可以使用
threading模块来实现多线程编程。
【2.2】基本模板
import threading
import os
def run_task(i):
'''os模块中有getpid方法,可以获取当前进程的pid'''
# 同一个进程下的子线程PID一致
print(f"{i}子线程{os.getpid()}正在运行!")
'''windows中开启进程必须在该语句下,否则将会报错'''
if __name__ == '__main__':
p_list = []
for i in range(1, 5):
'''与进程参数一致'''
p = threading.Thread(target=run_task, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("主进程已结束")
'''
1子线程27700正在运行!
2子线程27700正在运行!
3子线程27700正在运行!
4子线程27700正在运行!
主进程已结束
'''
- 多线程开启后,只有一个主进程而没有线程的显示,因为开启多线程并不会重新申请资源
【2.3】参数详解
-
基本参数与进程基本一致,只提出一些与进程不一致的
-
方法
threading.Thread: 线程对象的基本类。threading.current_thread:获取当前线程的名字threading.active_count:统计当前活跃的线程数
-
属性
name: 线程的名称。ident: 线程的标识符。
【2.4】创建并开启多线程
-
与多进程一致,只是改个类名
-
通过Thread类
-
通过继承Thread类并重写run方法
【2.5】线程间的资源共享
- 修改数字
import threading
import os
num = 100
def run_task(i):
# 声明变量
global num
# 每一个线程进入,拿到的都是上一个线程修改后的数据
num += 1
print(f"{i}子线程{os.getpid()}的num值为【{num}】!")
'''windows中开启进程必须在该语句下,否则将会报错'''
if __name__ == '__main__':
p_list = []
for i in range(1, 5):
p = threading.Thread(target=run_task, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("主进程已结束")
'''
1子线程24524的num值为【101】!
2子线程24524的num值为【102】!
3子线程24524的num值为【103】!
4子线程24524的num值为【104】!
主进程已结束
'''
- 当出现阻塞时,与多进程刚好相反,多线程最终拿到的值都为最终结果
import threading
import os
import time
num = 100
def run_task(i):
# 声明变量
global num
num += 1
time.sleep(1) # 当出现阻塞,与多进程相反,拿到的值都为最终的结果
print(f"{i}子线程{os.getpid()}的num值为【{num}】!")
if __name__ == '__main__':
p_list = []
for i in range(1, 5):
p = threading.Thread(target=run_task, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("主进程已结束")
'''
2子线程14132的num值为【104】!
1子线程14132的num值为【104】!
3子线程14132的num值为【104】!
4子线程14132的num值为【104】!
主进程已结束
'''
【3】多进程与多线程的区别与各自的使用场景
区别:
- 资源独立性:
- 多进程: 进程是操作系统中的一个独立执行单位,拥有独立的内存空间,因此进程间的资源是相互独立的。一个进程的错误通常不会影响其他进程。
- 多线程: 线程是进程中的一个执行单元,共享进程的内存空间,因此线程之间共享资源。一个线程的错误可能会影响整个进程。
- 创建和销毁开销:
- 多进程: 创建和销毁进程的开销相对较大,因为需要分配和释放独立的内存空间。
- 多线程: 创建和销毁线程的开销相对较小,因为线程共享相同的内存空间,无需分配额外的内存。
- 通信机制:
- 多进程: 进程间通信通常需要使用 IPC(Inter-Process Communication)机制,如管道、消息队列、共享内存等。
- 多线程: 线程间通信可以直接通过共享内存来进行,但需要考虑同步和互斥问题。
- 并行性:
- 多进程: 进程在多核系统上可以实现真正的并行执行,因为每个进程都有独立的执行环境。
- 多线程: 线程在多核系统上也可以实现并行执行,但由于线程共享进程的内存空间,可能存在线程间的竞争条件,需要使用锁等机制来解决。
使用场景:
- 多进程适用场景:
- 计算密集型任务: 当任务需要大量的 CPU 计算时,多进程能够充分利用多核系统,提高计算速度。
- 可独立运行的任务: 需要隔离的任务,互不影响的独立模块,适合使用多进程。
- 多线程适用场景:
- IO密集型任务: 当任务需要大量的 IO 操作时,多线程可以更好地利用等待 IO 的空闲时间,提高效率。
- 共享数据的任务: 当任务需要共享数据时,多线程由于共享内存,更方便实现数据共享。
- 混合使用场景:
- 有些任务可以同时利用多进程和多线程,根据任务的性质进行混合使用。
【3.1】多进程与多线程的运行速度对比
【3.1.1】计算密集型
from multiprocessing import Process
from threading import Thread
import time
# 创建计时器
def timer(func):
def inner(*args, **kwargs):
start_time = time.time()
res = func(*args, **kwargs)
print(f"{func.__name__}总耗时:{time.time() - start_time}s")
return res
return inner
def task_count():
count = 0
while 1:
count += 1
if count == 99999999:
break
@timer
def main_process():
p_list = [Process(target=task_count) for i in range(5)]
[p.start() for p in p_list]
[p.join() for p in p_list]
@timer
def main_thread():
p_list = [Thread(target=task_count) for i in range(5)]
[p.start() for p in p_list]
[p.join() for p in p_list]
if __name__ == '__main__':
main_process() # main_process总耗时:4.492878437042236s
main_thread() # main_thread总耗时:11.69202446937561s
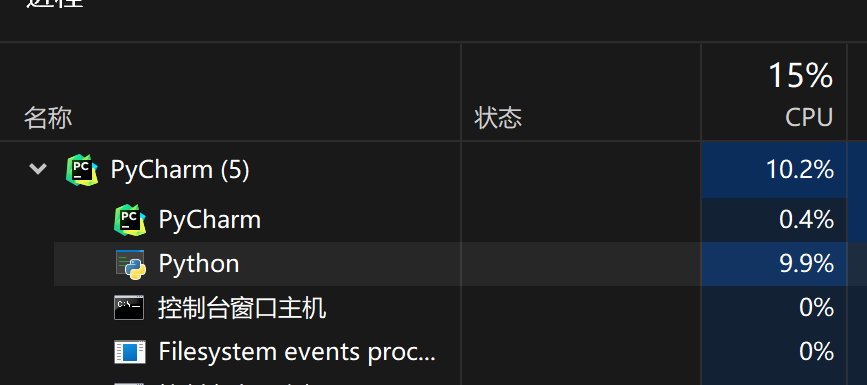
- 资源使用
- 多线程对于CPU的占用只有15%
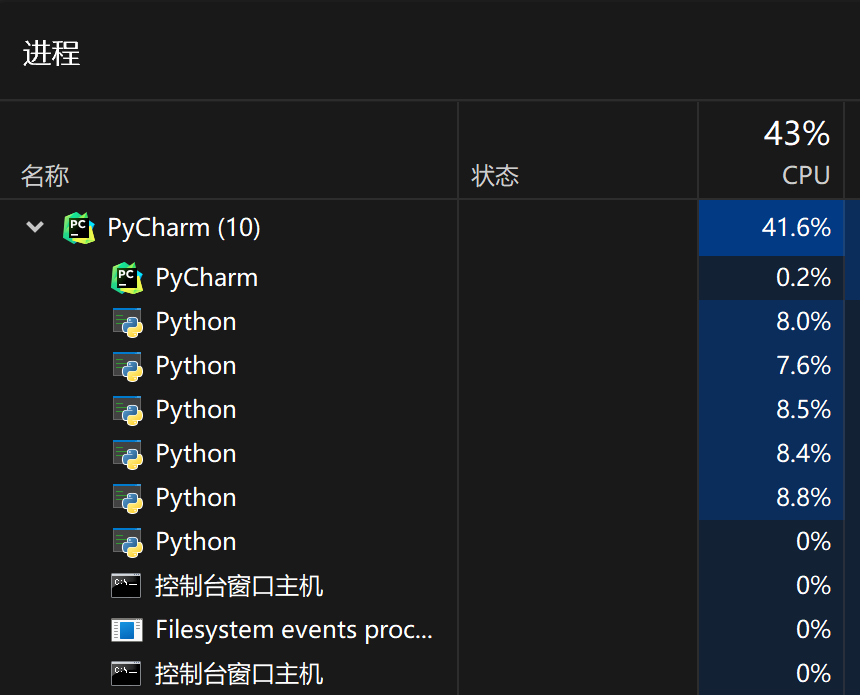
- 而多进程的CPU占用率高达43%
【3.1.2】IO密集型
from multiprocessing import Process
from threading import Thread
import time
# 创建计时器
def timer(func):
def inner(*args, **kwargs):
start_time = time.time()
res = func(*args, **kwargs)
print(f"{func.__name__}总耗时:{time.time() - start_time}s")
return res
return inner
def task_count():
# 通过sleep模拟IO
time.sleep(3)
@timer
def main_process():
p_list = [Process(target=task_count) for i in range(5)]
[p.start() for p in p_list]
[p.join() for p in p_list]
@timer
def main_thread():
p_list = [Thread(target=task_count) for i in range(5)]
[p.start() for p in p_list]
[p.join() for p in p_list]
if __name__ == '__main__':
print("主进程开始")
'''差距没有想象中的大对吧,是因为GIL锁,详细请看【锁】'''
'''不过还是可以看到多线程速度比多线程还是要快一些'''
main_process() # main_process总耗时:3.250441312789917s
main_thread() # main_thread总耗时:3.0127272605895996s
print("主进程结束")
【4】僵尸进程和孤儿进程
- Windows没有僵尸进程的概念导致进程ID不能真正区别出一个进程,比如说一个ID100的进程关闭了,然后一个新的进程启动后ID为100,并且父子进程之间的联系比Linux下要弱的多。
【4.1】进程的生命周期
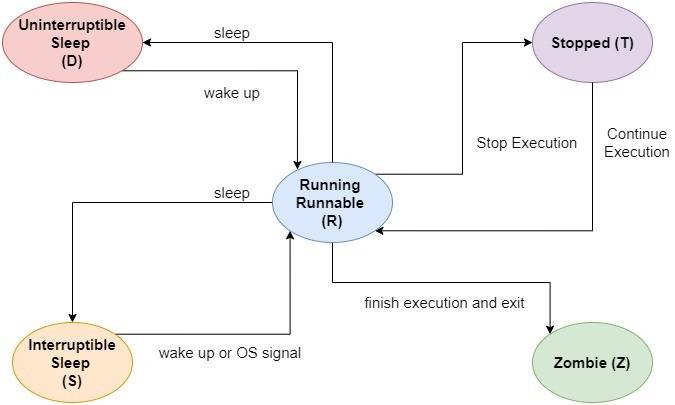
- uninterruptible:不间断的
- interruptible:可中断的
- stopped:停止的
【4.2】僵尸进程
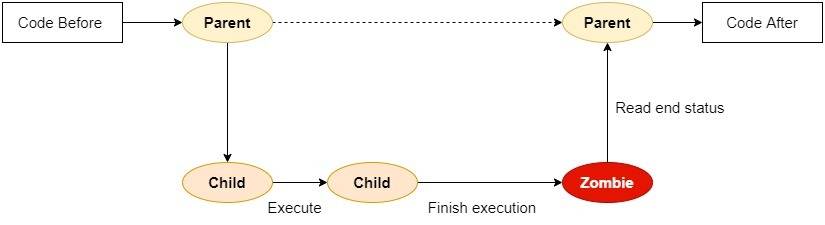
-
个人理解为,所有进程在执行结束后都称为僵尸进程,父进程会及时查看子进程的结果和状态,会将僵尸进程回收并释放
-
而当父进程出现繁忙的情况,未能及时回收僵尸进程,僵尸进程就将一直存在占用资源
-
解释:
-
僵尸进程(Zombie Process)是指在一个系统中,一个子进程在结束执行后,其父进程并没有正常地等待(通过调用
wait或类似的系统调用)获取子进程的终止状态信息,导致子进程的进程控制块仍然保留在系统中,但该进程已经不再执行任何代码。 -
主要特点和原因:
- 已终止但未被回收: 僵尸进程已经执行完毕,但其进程描述符仍然存在于系统进程表中,占用了系统资源。
- 父进程未调用
wait等待子进程: 僵尸进程的产生通常是由于父进程没有调用合适的系统调用来等待子进程的终止状态。
-
产生僵尸进程的常见原因:
-
父进程没有适当处理子进程的终止状态,即未调用
wait或类似的系统调用。 -
父进程被阻塞或忙碌,未及时处理子进程的终止状态。
-
-
【4.3】孤儿进程
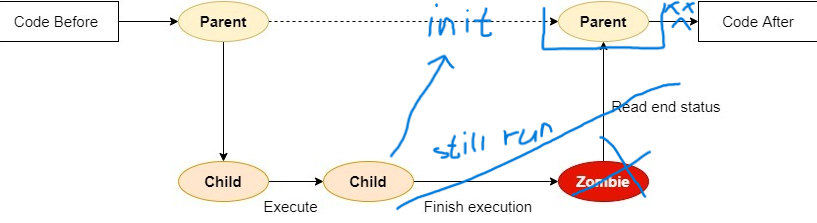
- 在操作系统中,孤儿进程是指其父进程提前终止或者意外终止,而导致子进程成为由系统 init 进程(或类似的进程)接管的情况。init 进程通常会成为孤儿进程的新父进程,负责收养和处理孤儿进程。
- 一个孤儿进程的特点是其父进程先于子进程终止,子进程成为由 init 进程接管的孤儿进程。
- 在 Unix/Linux 系统中,当一个进程创建子进程后,如果父进程先于子进程终止,子进程将成为孤儿进程。这是因为 Unix 系统中的 init 进程(通常是 PID 为 1 的进程)会接管孤儿进程,确保它们不会变成僵尸进程,同时为它们提供一个父进程。
'''大概的一种演示,因为我也不确定这个是不是孤儿进程'''
import multiprocessing
import time
def sleep():
time.sleep(3)
print("子进程结束了")
def create_process():
# 创建一个子进程
process = multiprocessing.Process(target=sleep)
process.start()
return process
if __name__ == "__main__":
process = create_process()
# 父进程结束
print("主进程结束")
print(f"Child process status: {process.is_alive()}")
'''当主进程结束以后,子进程依旧在运行,处在存活状态,但会结束,是因为init进程接收了该子进程,当子进程结束后,释放了进程'''
# 主进程结束
# Child process status: True
# 子进程结束了
【4.4】解决办法
-
windows系统下没有办法明显的看出来区别,所以也只能是理论
-
为了防止出现孤儿进程或僵尸进程
【4.4.1】对开启的子进程使用join
- 当添加join以后,主进程将会等待添加了join方法的子进程结束以后结束
'''从上述p.join拷贝出来的,具体可以看p.join()方法'''
import os
from multiprocessing import Process
def run_task(i):
print(f"{i} 进程{os.getpid()}正在 运行")
if __name__ == '__main__':
p_list = []
print("-----主进程开始-----")
for i in range(1, 5):
p = Process(target=run_task, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("-----主进程结束-----")
'''正确的情况'''
# -----主进程开始-----
# 2 进程26980正在 运行
# 1 进程28212正在 运行
# 3 进程20596正在 运行
# 4 进程24860正在 运行
# -----主进程结束-----
- 其余方法在windows系统中我无法实现,无法示例
- Zombie Processes and their Prevention - GeeksforGeeks
- signal(SIGCHLD, SIG_IGN)_signal(sigchld, sig_ign);-CSDN博客
【5】守护进程/守护线程
【5.1】守护进程
- 守护进程 (daemon) 是在计算机系统启动时就已经运行,并且一直在后台运行的一类特殊进程。
- 它们通常不与用户直接交互,也不接受标准输入和输出,而是在后台执行某种任务或提供某种服务。
- 守护进程往往是由系统管理员手动启动的,它们可以在系统启动时自动启动,一直运行在后台,直到系统关闭或被停止。
- 常见的守护进程包括网络服务 (如 web 服务器、邮件服务器、 ftp 服务器等)、日志记录系统 (如系统日志服务、应用程序日志服务等) 等。
- 守护进程通常在后台运行,不需要用户交互,并且有较高的权限,因此编写守护进程需要特别注意安全性和稳定性。
【5.1.1】守护进程的用法
- 当进程对象设置守护进程后,该进程将会随着主进程的结束而结束,哪怕他还有任务未完成
通过【.】语法更改属性值
import multiprocessing
import time
def sleep():
time.sleep(3)
print("子进程结束了")
def create_process():
# 创建一个子进程
process = multiprocessing.Process(target=sleep)
process.daemon = True
process.start()
return process
if __name__ == "__main__":
process = create_process()
# 父进程结束
print("主进程结束")
print(f"Child process status: {process.is_alive()}")
# time.sleep(4)
# print(f"Child process status: {process.is_alive()}")
'''未加time.sleep的结果如下'''
'''当主进程结束,子进程立即结束,哪怕它未完成任务,处于存活状态'''
'''将不会执行【子进程结束】这句话'''
# 主进程结束
# Child process status: True
'''添加time.sleep的结果如下'''
'''等待的时间将会由子进程继续执行'''
# 主进程结束
# Child process status: True
# 子进程结束了
# Child process status: False
通过Process对象的属性
'''除创建进程的函数有所变化,其余与上述一致,效果也是一样的,不做过多繁琐的复制粘贴'''
def create_process():
'''与点语法效果一致'''
process = multiprocessing.Process(target=sleep,daemon=True)
# process.daemon = True
process.start()
return process
【5.1.2】守护进程注意事项
- 通过【.】点语法更改守护进程属性值时,需要在start之前,否则将会报错
AssertionError: process has already started
【5.2】守护线程
- 与守护进程用法一致,只是从Process对象变为Thread对象
import threading
import time
def sleep():
time.sleep(3)
print("子进程结束了")
def create_thread():
'''与点语法效果一致'''
thread = threading.Thread(target=sleep,daemon=True)
# process.daemon = True
thread.start()
return thread
if __name__ == "__main__":
thread = create_thread()
# 父进程结束
print("主进程结束")
print(f"Child process status: {thread.is_alive()}")
# time.sleep(4)
# print(f"Child process status: {process.is_alive()}")
'''未加time.sleep的结果如下'''
'''当主进程结束,子进程立即结束,哪怕它未完成任务,处于存活状态'''
'''将不会执行【子进程结束】这句话'''
# 主进程结束
# Child process status: True
'''添加time.sleep的结果如下'''
'''等待的时间将会由子进程继续执行'''
# 主进程结束
# Child process status: True
# 子进程结束了
# Child process status: False
【5.3】守护进程和守护线程的应用场景
守护进程和守护线程通常用于在后台执行任务,而不阻塞主程序或主线程。它们的应用场景有一些相似之处,但也有一些差异。以下是它们常见的应用场景:
守护进程的应用场景:
- 服务进程: 守护进程常用于作为服务运行,例如 Web 服务器、数据库服务器等。它们在后台监听并处理请求。
- 定时任务: 守护进程可以周期性地执行一些任务,例如定时备份、日志清理等。
- 系统初始化: 在系统启动时,守护进程可以执行一些初始化任务,准备系统环境。
- 监控任务: 守护进程可以用于监控系统状态,例如资源使用情况、日志文件的变化等。
- 消息队列处理: 处理消息队列中的消息,例如异步任务处理。
守护线程的应用场景:
- 定时任务: 守护线程可以用于周期性地执行一些后台任务,类似于守护进程。
- 异步任务: 处理异步任务,例如异步请求的处理、定时任务等。
- 数据更新: 守护线程可以用于后台更新数据,确保数据的实时性。
- 事件监听: 守护线程可以监听某些事件,例如监测文件变化、网络状态变化等。
- 资源管理: 在后台管理资源,例如定期释放一些资源。
共同的应用场景:
- 日志处理: 守护进程和守护线程都常用于日志的后台处理,确保日志记录不会阻塞主程序或主线程。
- 后台任务执行: 在需要在后台执行任务而不影响主程序的场景下,都可以考虑使用守护进程或守护线程。
需要注意的是,在使用守护进程或守护线程时,要特别小心资源的释放,避免因为进程或线程的突然终止导致资源泄漏。另外,守护进程或守护线程可能在任何时候被终止,因此对于一些关键任务,可能需要使用其他机制来保证其完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号