Python高级之模块与包
模块与包
模块(Module)
【一】概要:
-
定义: 在Python中,模块是一个包含 Python 代码的文件。这些文件以
.py为扩展名,可以包含变量、函数和类等,文件名为xxx.py,模块名则是xxx,导入模块可以引用模块中已经写好的功能。 -
作用: 模块提供了一种组织代码的方式,将相关的功能组织在一个文件中,使得代码更加清晰和可维护。
-
创建和使用: 创建一个模块非常简单,只需编写 Python 代码并保存为
.py文件。其他 Python 文件可以通过import语句导入模块,并使用其中定义的变量、函数和类。# 例子:创建一个名为 mymodule.py 的模块 # mymodule.py def greet(name): return f"Hello, {name}!" # 在其他文件中使用该模块 # main.py import mymodule result = mymodule.greet("user") print(result) # 输出 "Hello, user!"
【二】模块的来源
- 在 Python 中,模块的来源可以分为两类:内建模块(Built-in Modules)和外部模块(External Modules)。
-
内建模块(Built-in Modules): Python 提供了一些内建模块,这些模块是 Python 安装的一部分,无需额外安装。一些常用的内建模块包括
math、random、sys、os等。这些模块提供了许多常用的功能,可以直接在 Python 程序中使用。import math result = math.sqrt(25) # 取平方根 print(result) # 输出 5.0 -
外部模块(External Modules): 外部模块是由第三方开发者编写的,不是 Python 标准库的一部分。这些模块通常提供了各种功能和工具,可以通过 pip(Python 包管理工具)等方式进行安装。一些常用的外部模块包括
requests、numpy、pandas等。# 通过 pip 安装外部模块 pip install requestsimport requests # 爬虫中的模块 response = requests.get("https://www.example.com") print(response.status_code) -
本地模块:本地模块就是你自己根据需求搭建出来的模块,可以自行编辑,创建
# test.py def index(x, y): return x + y # main.py from test import index print(index(1, 2)) # 3
【三】导入模块(import)
- 在 Python 中,
import语句用于导入模块,从而可以使用该模块中定义的变量、函数、类等内容。import有多种使用方式,以下是一些常见的形式:
# test.py
x = 'test'
def get():
print(x)
def change():
global x
x = 'test_change'
print(x)
class Foo:
def func(self):
print("hello from class Foo 下的func()")
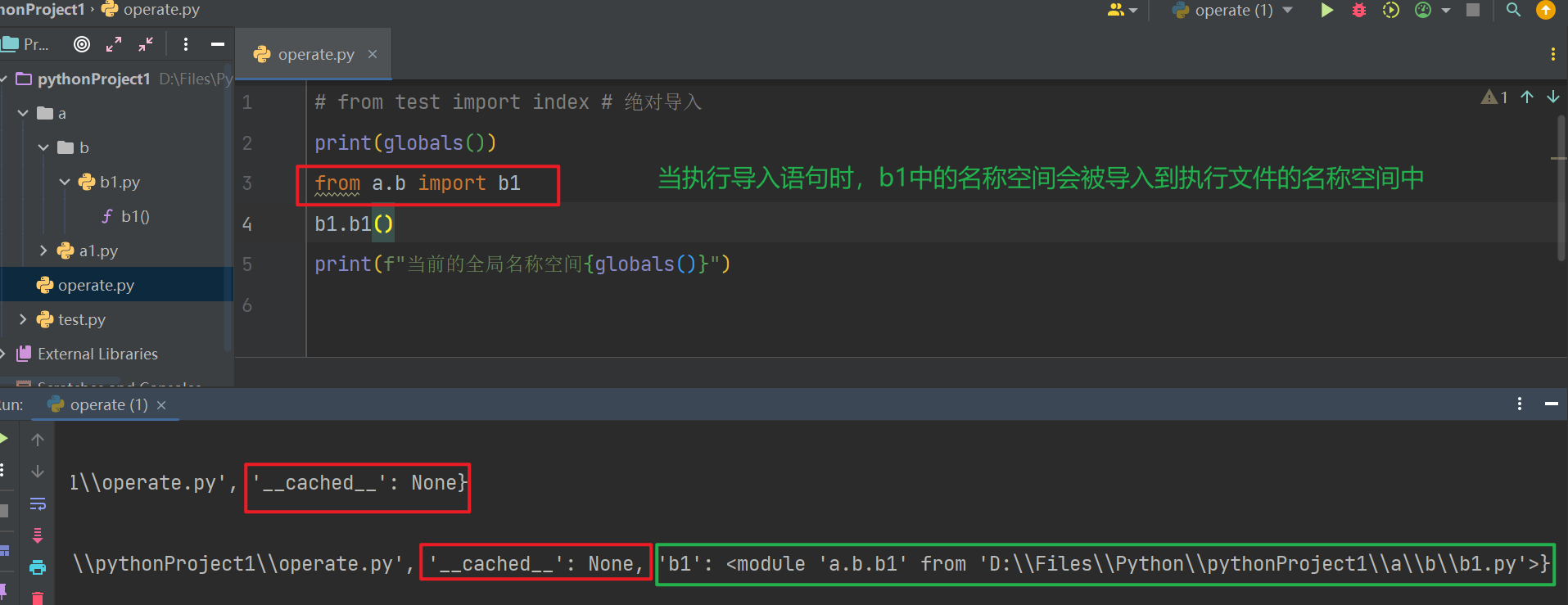
import test # 导入模块foo
a = test.x
# 引用模块foo中变量x的值赋值给当前名称空间中的名字a
print(a) # 输出 test
test.get() # 调用模块foo的get函数
# 这是test.py中get函数中的test
test.change() # 调用模块foo中的change函数
# 这是test.py中test_change中改变x值的test_change
obj = test.Foo() # 使用模块foo的类Foo来实例化,进一步可以执行obj.func()
obj.func() # hello from class Foo 下的func()
1、导入整个模块:(import)
import md # 导入模块的时候,只写模块名字,不要写后缀名字
"""
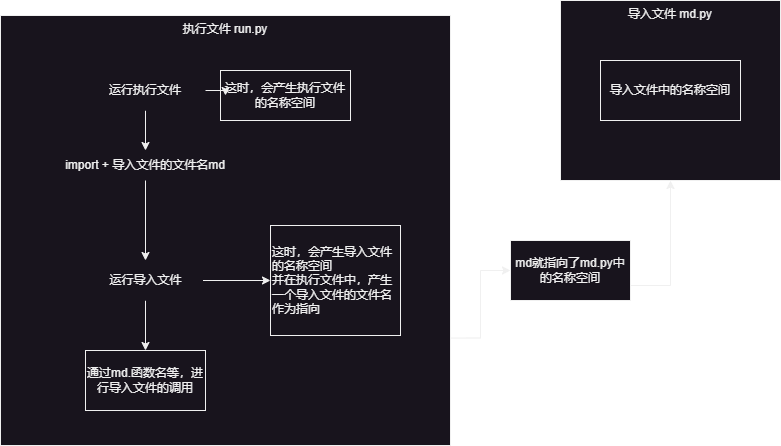
学习模块的时候一定要弄清楚:谁是执行文件,谁是导入文件?
运行当前文件,会导入md文件到此文件中,并且会执行导入文件
导入文件多次,那么,也只会执行一次导入文件中得代码,只需要导入一次即可
导入文件的时候发生了什么事儿?
1. 首先会运行执行文件,产生执行文件的全局名称空间
2. 运行导入文件
3. 会产生导入文件的全局名称空间,把导入文件中的名字都丢到全局名称空间中
4. 会在执行文件中产生一个名字md指向导入文件的名称空间
"""
- 执行文件名称空间中的变量与导入文件名称空间中的变量,哪怕重名也不会产生影响
- 当你在执行文件中直接打印变量名,就是打印执行文件名称空间中的该变量名
- 在执行文件中通过md.变量名打印该变量名,就是执行导入文件名称空间中的该变量名
2、给导入的模块指定别名:(import as )
- 当模块名特别长时,可以通过取别名来进行调用
import module_name as alias
# from 模块位置 import 模块名 as 自定义名字
这样可以为导入的模块指定一个别名,方便在代码中使用。例如:
import moudle_name as name
name.function() # 通过name也可以调用到moudle_name中的函数或其他名称空间中的内容
3、导入模块中的特定内容:(from import)
from module_name import name1, name2, ...
"""
from...import...句式
导入模块也会执行导入文件,多次导入也只会执行一次,跟import句式一样
导入文件的时候发生了什么事儿?
1. 首先会运行执行文件,产生执行文件的全局名称空间
2. 运行导入文件md
3. 会产生导入文件的全局名称空间,把导入文件中的名字都丢到全局名称空间中
4. 会在执行文件中产生一个名字name1指向导入文件的名称空间中的name1
如果使用from...import...句式的情况,在执行文件中会出现名字冲突的情况(在执行文件中出现了和导入的名字一样的时候)
出现冲突的时候离谁近用谁的
所有的导入语句都应当写在文件的开头
# 写在其他位置也不报错 ,但最好写在文件开头,清晰明了
"""
这种形式允许从模块中导入指定的变量、函数、类等,而不必使用模块名前缀。例如:
from module_name import name1, name2
print(name1)
print(name2)
- 此时,需要注意,此时,如果执行文件中同样出现了变量名为name1的,那么就是就近原则,旧的会被替换掉
- 与import语句有所不同
4、导入模块中的所有内容(不推荐):(from mport * )
from module_name import *
-
这种形式导入模块中的所有内容,但通常不推荐使用,因为可能引起命名冲突。最好的做法是只导入需要的内容。
-
只能在模块最顶层使用
*的方式导入,在函数内则非法
1.__all__
- 模块的编写者可以在自己的文件中定义
__all__变量用来控制*代表的意思
# foo.py
# 该列表中所有的元素必须是字符串类型,每个元素对应foo.py中的一个名字
__all__=['x','get']
x=1
def get():
print(x)
def change():
global x
x=0
class Foo:
def func(self):
print('from the func')
- 这样我们在另外一个文件中使用
*导入时,就只能导入__all__定义的名字了
# 此时的*只代表x和get
from foo import *
x #可用
get() #可用
change() #不可用
Foo() #不可用
5.判断文件类型(执行文件或导入文件)
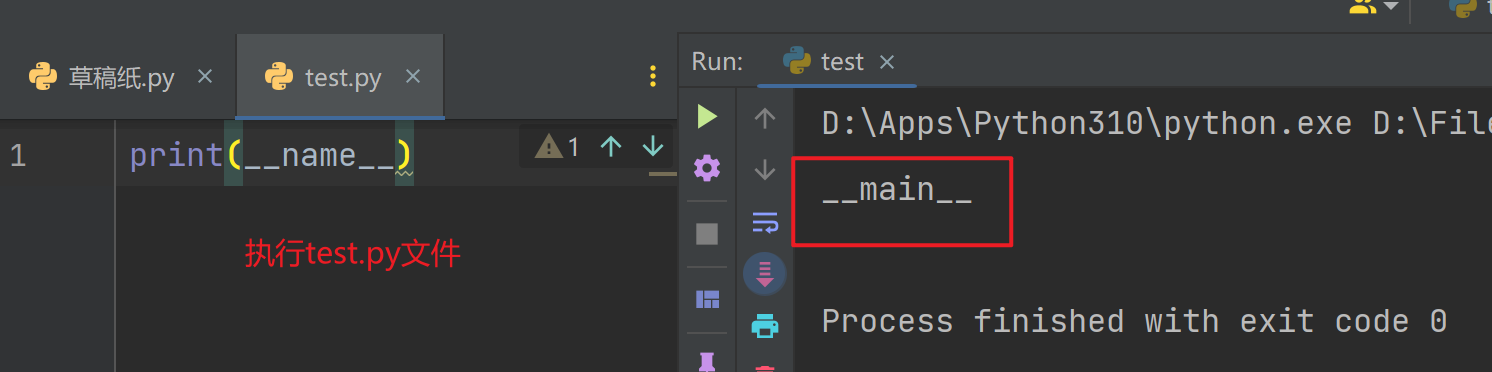
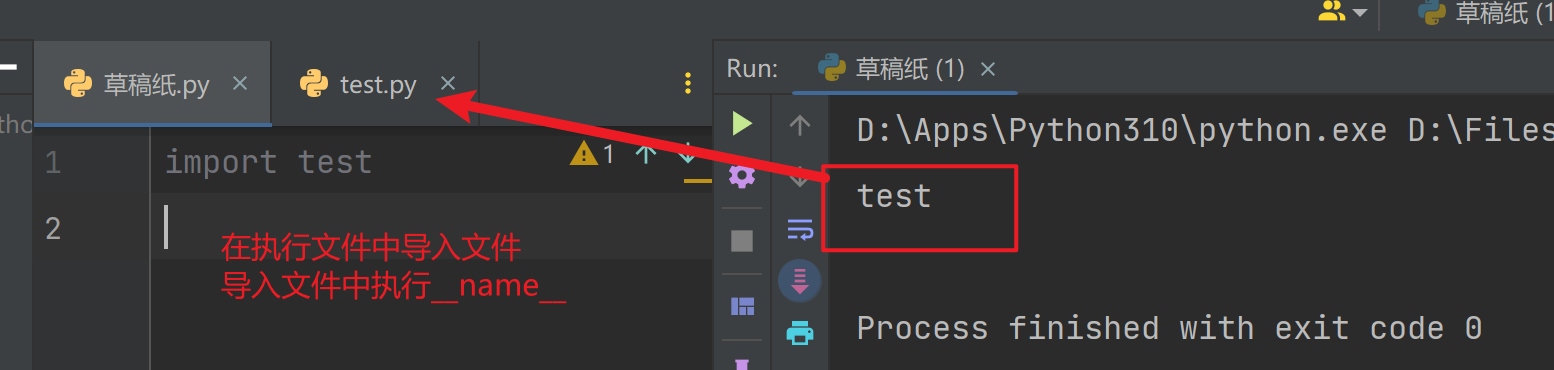
- 通过
__name__的结果来查看
# 如果当前文件是执行文件,那么,__name__的结果就是__main__
# 如果当前文件时导入文件,那么,__name__的结果就是模块名
# md.py 导入文件中
print(__name__)
# main.py 执行文件中
import md
print(__name__)
- 可以通过设置if语句,来进行程序的运行,当导入文件为执行文件时才执行
if __name__ == '__main__': # test
read2()
if __name__ == '__main__':
'''在这个判断里面写的代码,只有是以执行文件运行的时候,才会被执行,
当被当成导入文件的时候,不会被运行'''
read2()
【四】循环导入的问题与解决方案(circular import)
- 在编码过程中,循环导入时不可以出现的!如果出现了循环导入,说明代码设计不合理,需要及时更正
- 以下是循环导入的引发
# main.py
from test import index # 【1】从test模块名中导入index函数
def add():
index() # 【2】执行index函数 # 【6】再一次执行index函数,形成了循环导入circular import
# test.py
from main import add # 【3】从main模块名中导入add函数
def index(): # 【4】执行index函数
print(add())# 【5】执行add函数
# ImportError: cannot import name 'add' from partially initialized module 'main' (most likely due to a circular import)
【1】解决方案介绍
循环导入是指两个或多个模块相互导入,导致无法正确加载模块的情况。这可能会导致一系列问题,例如在导入过程中产生未定义的名称错误。
- 常用的解决思路是调整导入模块语句的位置,在你需要模块时再去延迟使用
以下是一些解决循环导入问题的常见方法:
-
重构代码结构: 重新组织代码,将导致循环导入的模块拆分成更小的模块或者合并它们,以减少相互依赖性。
-
延迟导入: 使用在需要的时候再导入的方式,可以使用
importlib模块的import_module函数。这样可以避免在模块级别的导入语句中形成循环依赖。# 模块 A from importlib import import_module def func(): B = import_module('module_B') B.some_function() -
将导入语句移到模块的末尾: 将导致循环导入的导入语句移到模块末尾,这样可以推迟导入的时机,直到整个模块加载完成。
在 Python 中,当一个模块被导入后,它的代码会在第一次导入时被执行,并且模块的名称空间(namespace)会被缓存起来。当再次导入同一个模块时,Python 解释器会直接使用缓存中的模块对象,而不会重新执行模块代码。 这个特性是为了提高性能和避免重复执行模块代码。由于模块代码只在第一次导入时执行,因此在导入语句位置之后的代码执行过程中,即使存在相互导入的情况,已经导入的模块的代码也不会再次执行。 当我们将导入语句放在模块的最后时,确保了整个模块的代码都执行完毕后才进行导入,这意味着在执行导入语句之前,相互导入的模块已经在第一次导入时完成了执行。因此,即使存在相互导入,由于 Python 解释器对模块的名称空间进行了缓存,不会重新执行模块代码,从而避免了循环导入问题。 这种机制使得 Python 可以高效地处理相互导入的情况,前提是在导入语句的位置合理,避免循环依赖导致的无限循环。 -
使用函数或方法级别的导入: 在需要的时候通过函数或方法级别的导入来避免模块级别的导入。
# 模块 A def func(): from module_B import some_function some_function() -
使用
__import__函数: 这是 Python 的内置函数,允许你在运行时动态导入模块,可以用于解决一些特殊的循环导入问题。# 模块 A B = __import__('module_B') -
引入局部导入: 通过在函数或方法内进行导入,将导入限制在局部作用域,避免了全局导入造成的循环依赖。
# 模块 A def func(): import module_B module_B.some_function()
【五】搜索模块的路径与优先级
【1】模块的分类
- 模块其实分为四个通用类别,分别是:
- 1、使用纯Python代码编写的py文件
- 2、包含一系列模块的包
- 3、使用C编写并链接到Python解释器中的内置模块
- 4、使用C或C++编译的扩展模块
- 在导入一个模块时
- 如果该模块已加载到内存中,则直接引用
- 否则会优先查找内置模块
- 然后按照从左到右的顺序依次检索
sys.path中定义的路径
- 然后按照从左到右的顺序依次检索
- 直到找模块对应的文件为止
- 否则抛出异常。
【补】从内存中导入
- 当模块已经被导入时,原文件哪怕被删除,还是可以执行文件,说明当模块存在于内存中时,也是可以导入的
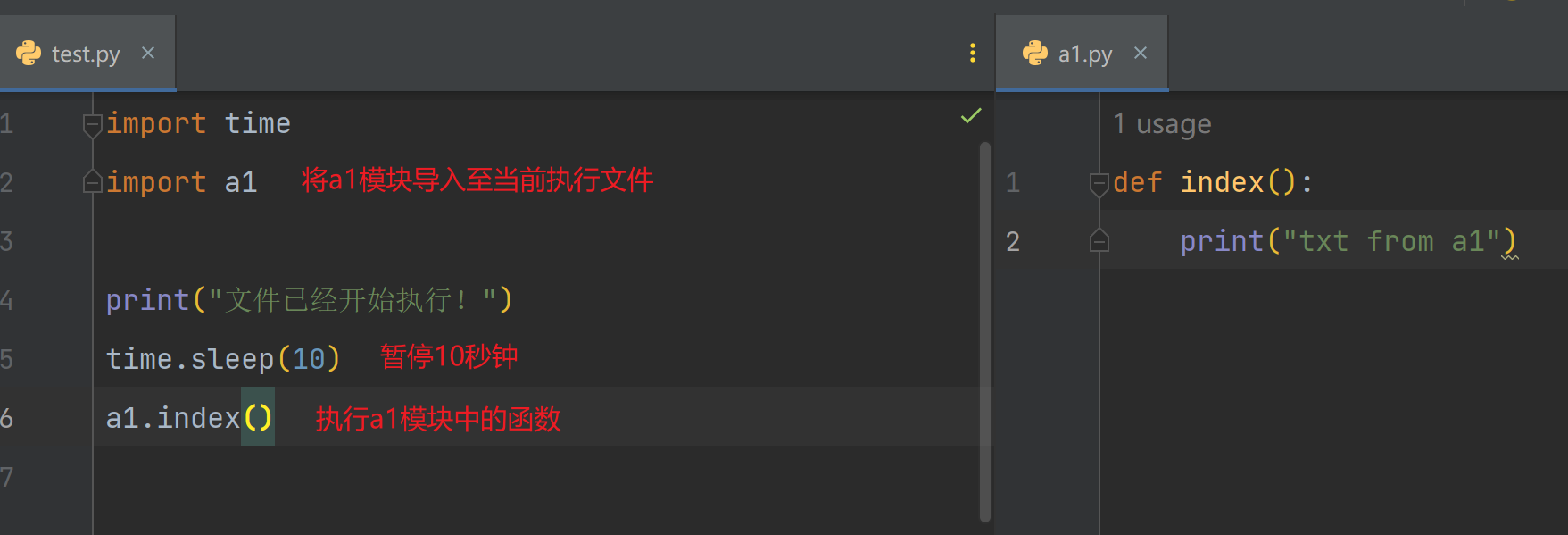
- 此时,哪怕我将a1.py文件删除,代码依旧可以执行完成
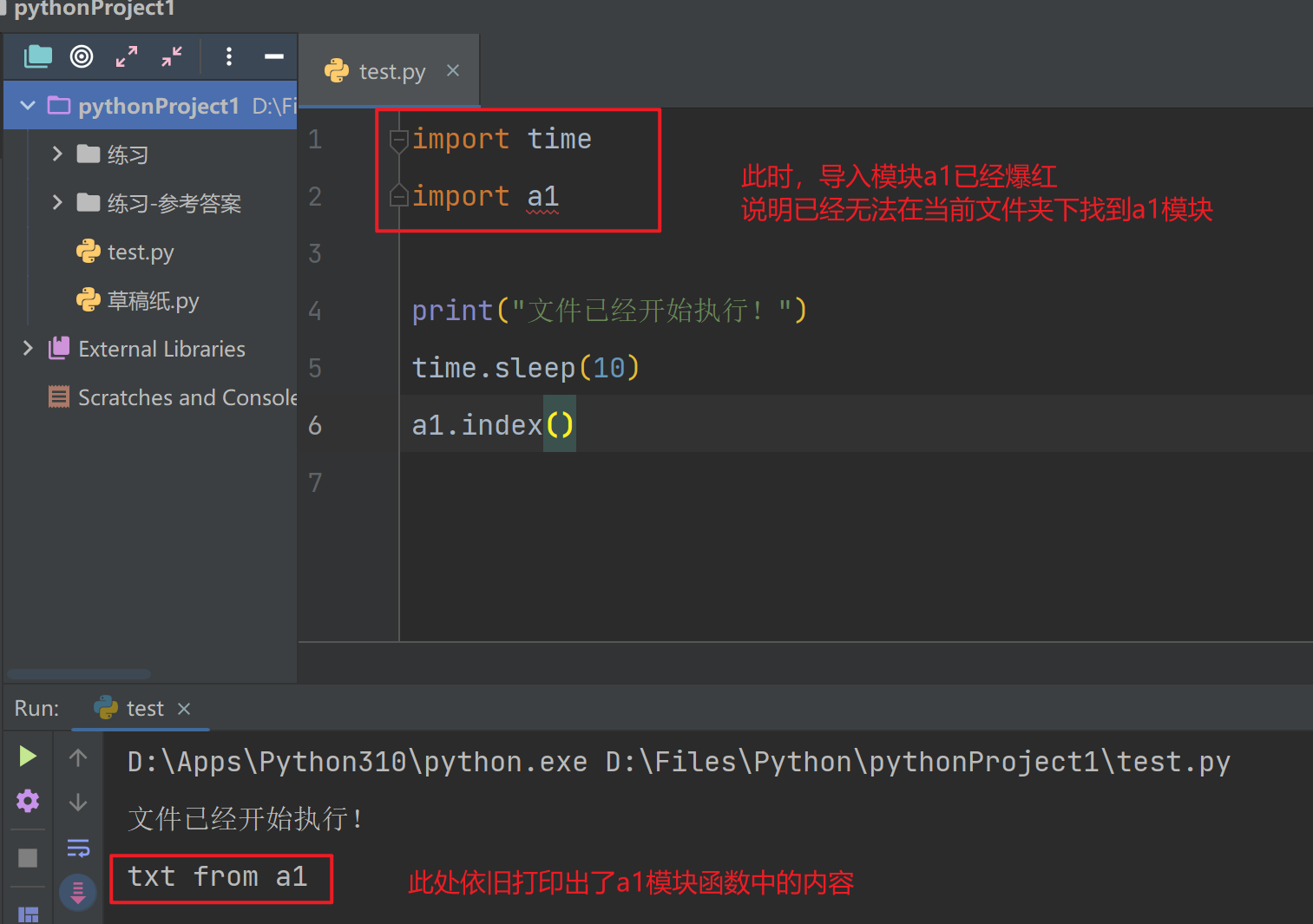
- 当执行导入的行为时,模块中的内容已经加载至内存中
【2】查看模块的搜索路径
sys.path也被称为模块的搜索路径,它是一个列表类型
import sys
print(sys.path)
'''
['D:\\Files\\Python\\pythonProject1', 'D:\\Files\\Python\\pythonProject1',
'D:\\Apps\\pycharm\\PyCharm 2023.2.1\\plugins\\python\\helpers\\pycharm_display', 'D:\\Apps\\Python310\\python310.zip', 'D:\\Apps\\Python310\\DLLs',
'D:\\Apps\\Python310\\lib', 'D:\\Apps\\Python310',
'D:\\Apps\\Python310\\lib\\site-packages',
'D:\\Apps\\pycharm\\PyCharm 2023.2.1\\plugins\\python\\helpers\\pycharm_matplotlib_backend']
'''
-
列表中的每个元素其实都可以当作一个目录来看:
- 在列表中会发现有.zip或.egg结尾的文件
- 二者是不同形式的压缩文件
- 在列表中会发现有.zip或.egg结尾的文件
-
事实上Python确实支持从一个压缩文件中导入模块
- 我们也只需要把它们都当成目录去看即可。
-
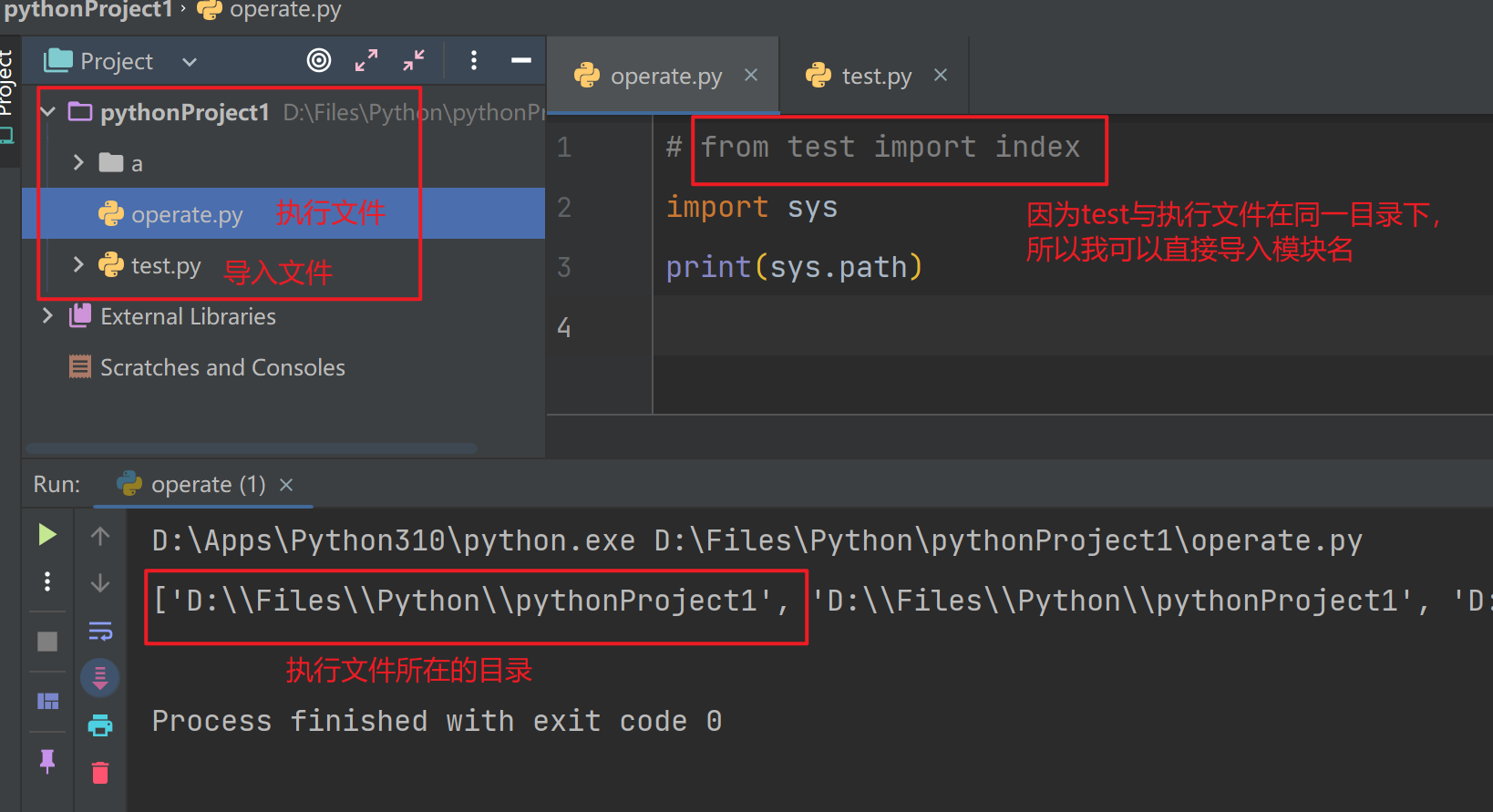
sys.path中的第一个路径通常为空,代表执行文件所在的路径,所以在被导入模块与执行文件在同一目录下时肯定是可以正常导入的 -
而针对被导入的模块与执行文件在不同路径下的情况
- 为了确保模块对应的源文件仍可以被找到
- 需要将源文件
foo.py所在的路径添加到sys.path中 - 假设
foo.py所在的路径为/pythoner/projects/
import sys # 也可以使用sys.path.insert(……) sys.path.append(r'/pythoner/projects/') # 无论foo.py在何处,我们都可以导入它了 import foo- 作为模块foo.py的开发者
- 可以在文件末尾基于
__name__在不同应用场景下值的不同来控制文件执行不同的逻辑
- 可以在文件末尾基于
# foo.py ... if __name__ == '__main__': # 被当做脚本执行时运行的代码 foo.py else: # 被当做模块导入时运行的代码 foo.py通常我们会在if的子代码块中编写针对模块功能的测试代码
这样foo.py在被当做脚本运行时,就会执行测试代码
而被当做模块导入时则不用执行测试代码。
【六】相对路径与绝对路径
【1】相对路径(Relative Path):
相对路径是相对于当前工作目录或当前脚本所在目录的路径。它描述如何从一个位置到达另一个位置。相对路径不包括根目录,直接从当前位置出发。
在相对路径中,常见的表示方法包括:
.:表示当前目录。..:表示父级目录。- 具体的目录或文件名:相对于当前位置的目录或文件名。
./subdirectory/file.txt # 表示当前目录下的 subdirectory 文件夹中的 file.txt 文件
../parentdirectory/file.txt # 表示父级目录下的 parentdirectory 文件夹中的 file.txt 文件
【2】绝对路径(Absolute Path)
-
绝对路径是从文件系统的根目录开始指定文件或目录的路径。它提供了完整的路径信息,不依赖于当前工作目录。
在绝对路径中,通常包括文件系统的根目录(如
/或C:\)和一系列目录名。
# 例如,绝对路径可能是:
absolute_path = 'C:/Users/username/projects/data/file.txt'
# /home/user/documents/file.txt # Linux 或 macOS 下的绝对路径
# C:\Users\User\Documents\file.txt # Windows 下的绝对路径
【3】导入模块中的绝对导入和相对导入
- 在导入模块的时候,模块的查找始终以执行文件所在的路径为准
绝对导入
- 它始终是以执行文件所在的sys.path路径为基准查找
- 当使用绝对导入导入模块时,Python 解释器会以执行文件所在的目录(即执行文件路径)作为起点,然后在
sys.path中的路径列表中查找相应的模块。这确保了绝对导入的路径是相对于执行文件的位置进行查找的。
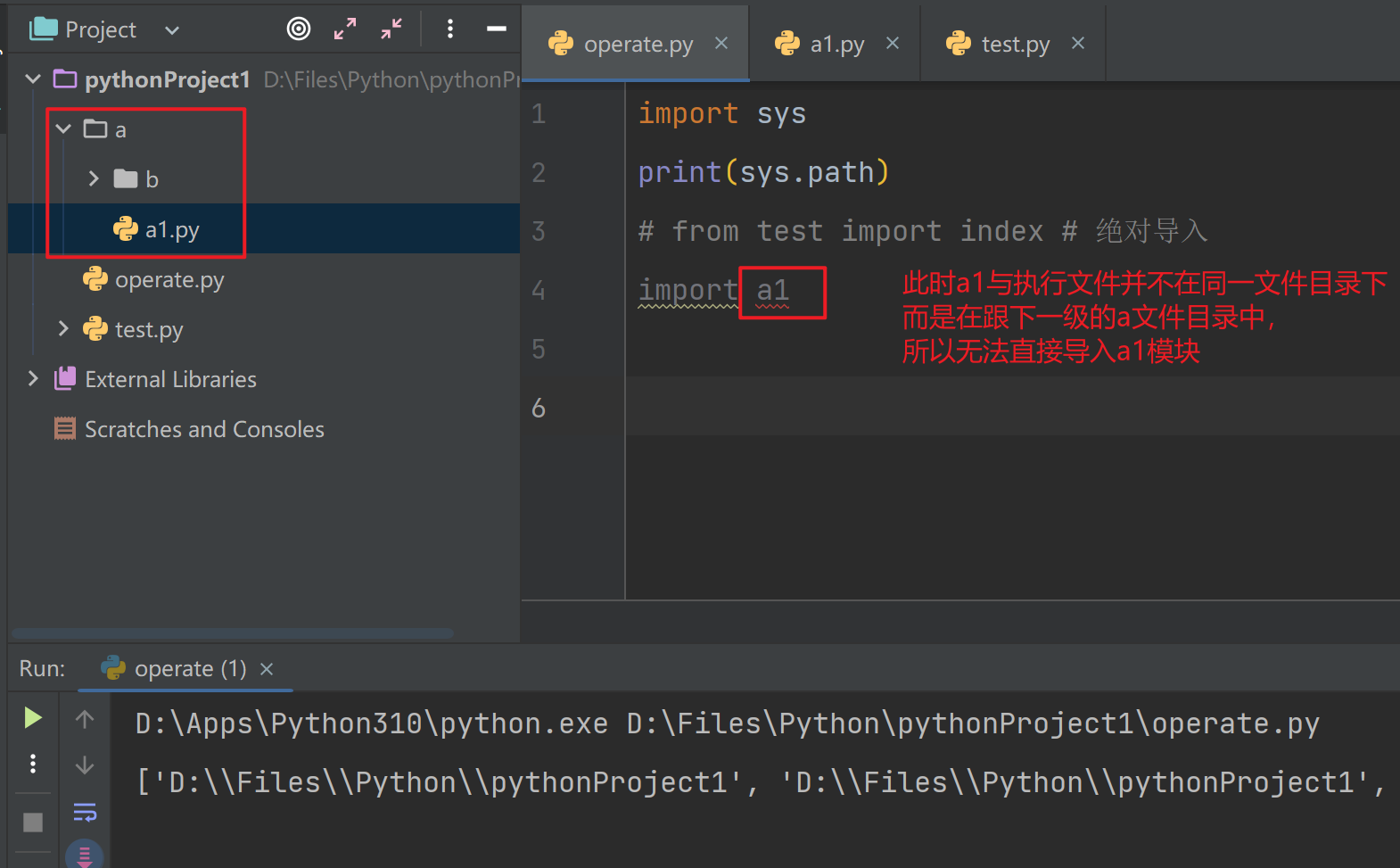
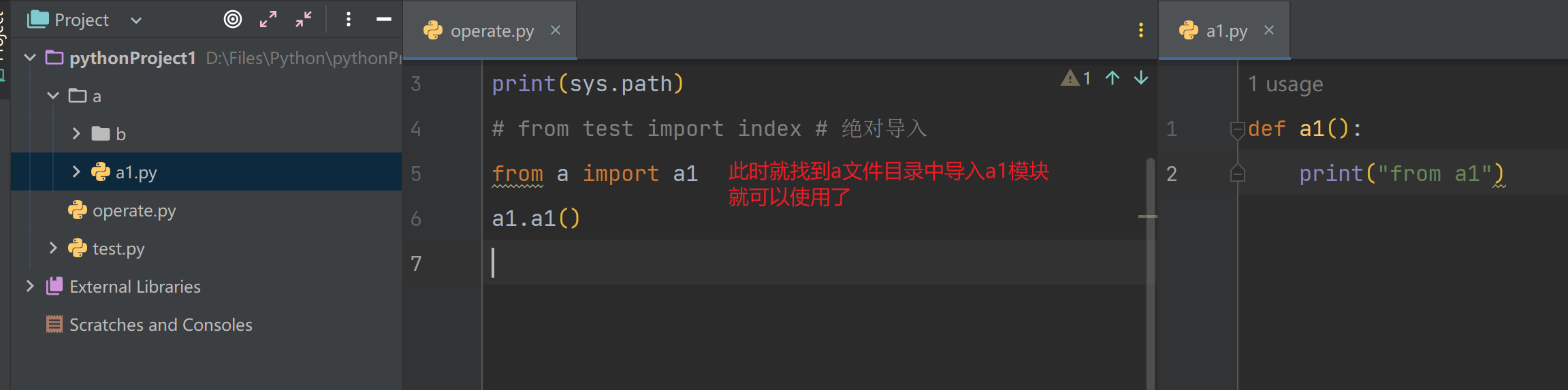
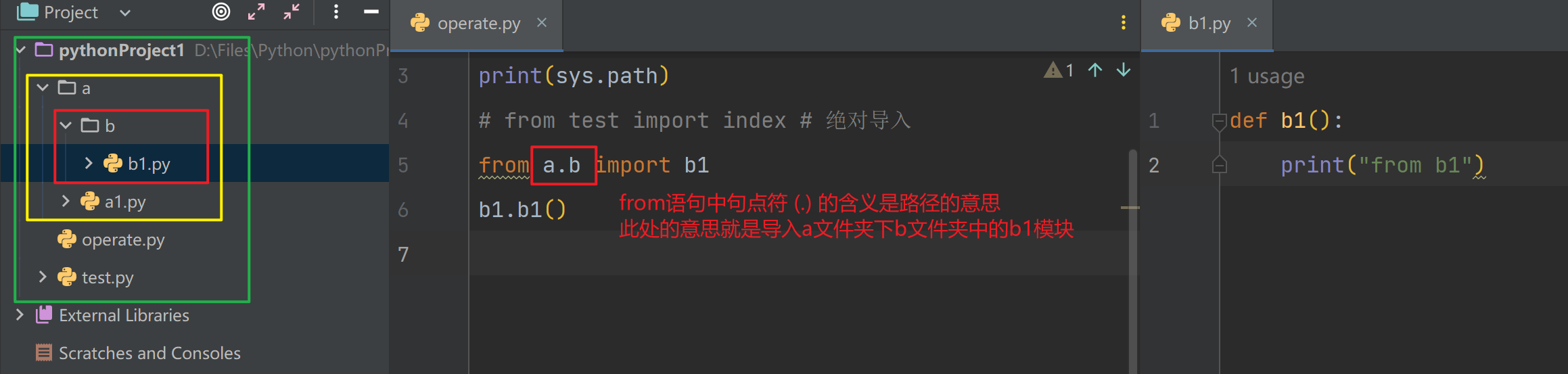
相对导入
.句点符- 相对导入可以打破始终以执行文件及准的查找顺序
- 只要py文件中出现了相对导入语句(.开头的语句),那么,这个文件就不能当成执行文件了,只能被导入
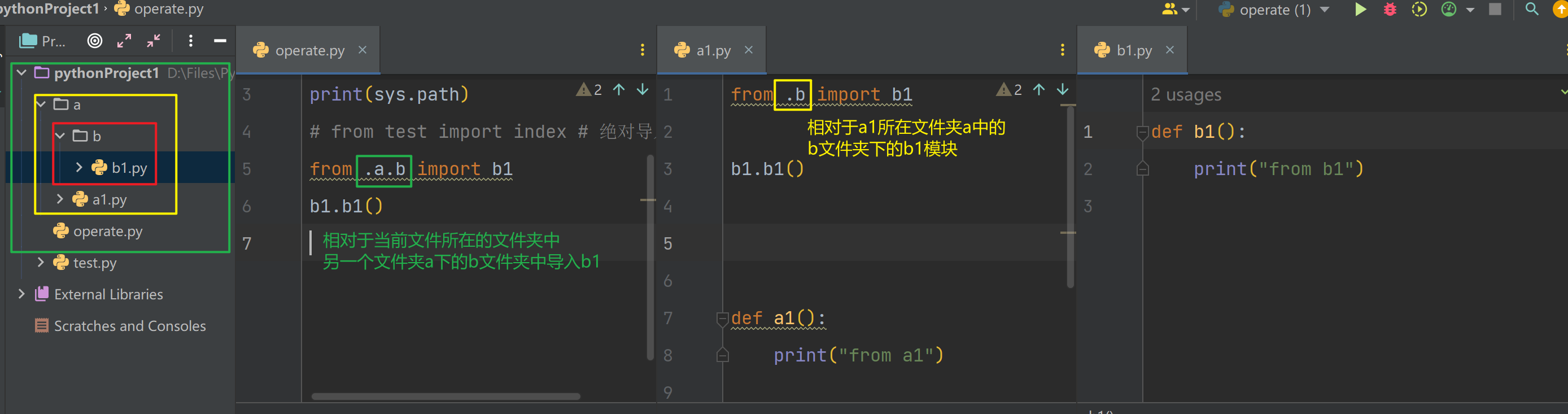
- 其中a1.py就不可以作为执行文件了,因为它出现了相对导入的语句
# 报错信息
# ImportError: attempted relative import with no known parent package

包(Package)
【一】概要:
-
定义: 包是一种将模块组织在一起的方式,它是一个包含特殊文件
__init__.py的目录。这个目录可以包含子目录和模块文件。 -
作用: 包用于将相关的模块组织在一个命名空间下,避免命名冲突,并提供更好的代码结构。
-
创建和使用: 创建一个包也很简单,只需在目录中添加
__init__.py文件。可以在包内创建子目录和模块,并通过import语句导入其中的内容。# 只要文件夹中有__init__.py并在__init__文件中为文件夹中的模块进行了注册就可以称为包 mypackage/ ├── __init__.py # 第一层包 ├── module1.py ├── module2.py └── subpackage/ ├── __init__.py # 第二层包1 └── module3.py └── subpackage/ └── __init__.py # 第二层包2 └── module4.py
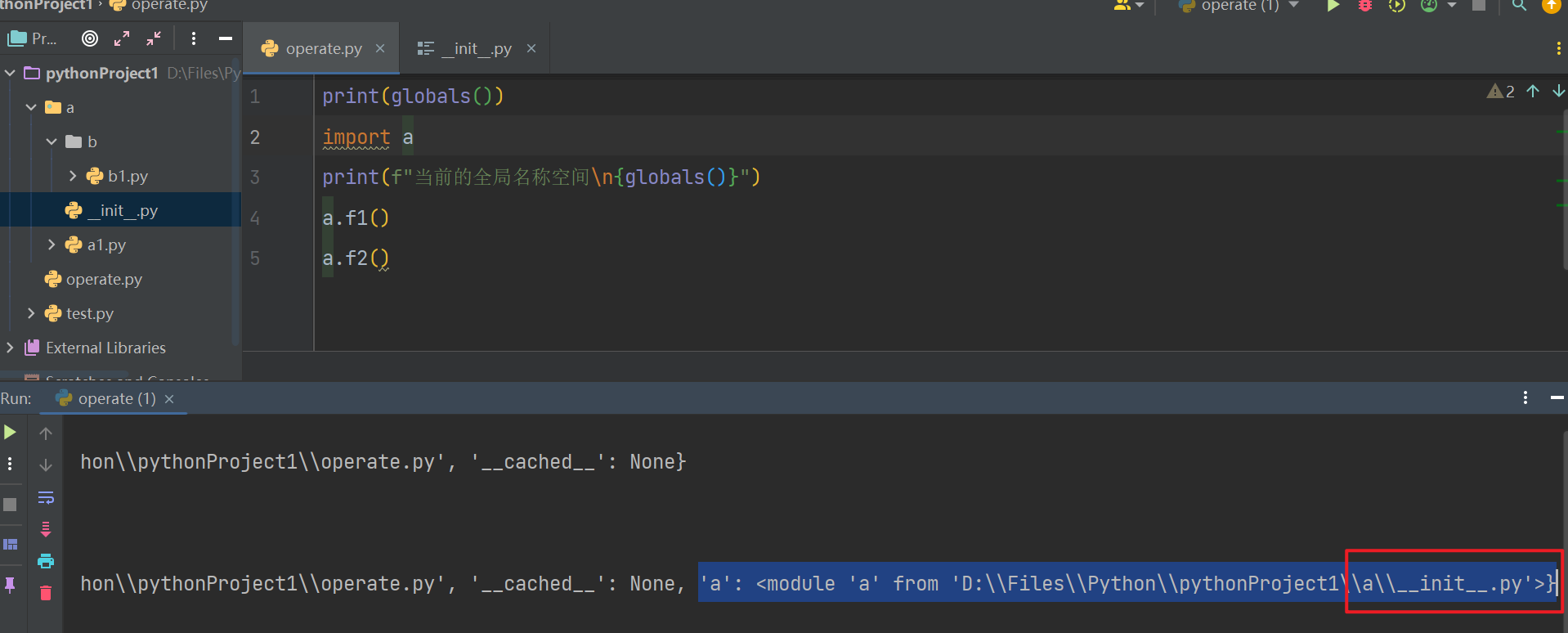
【二】包的使用
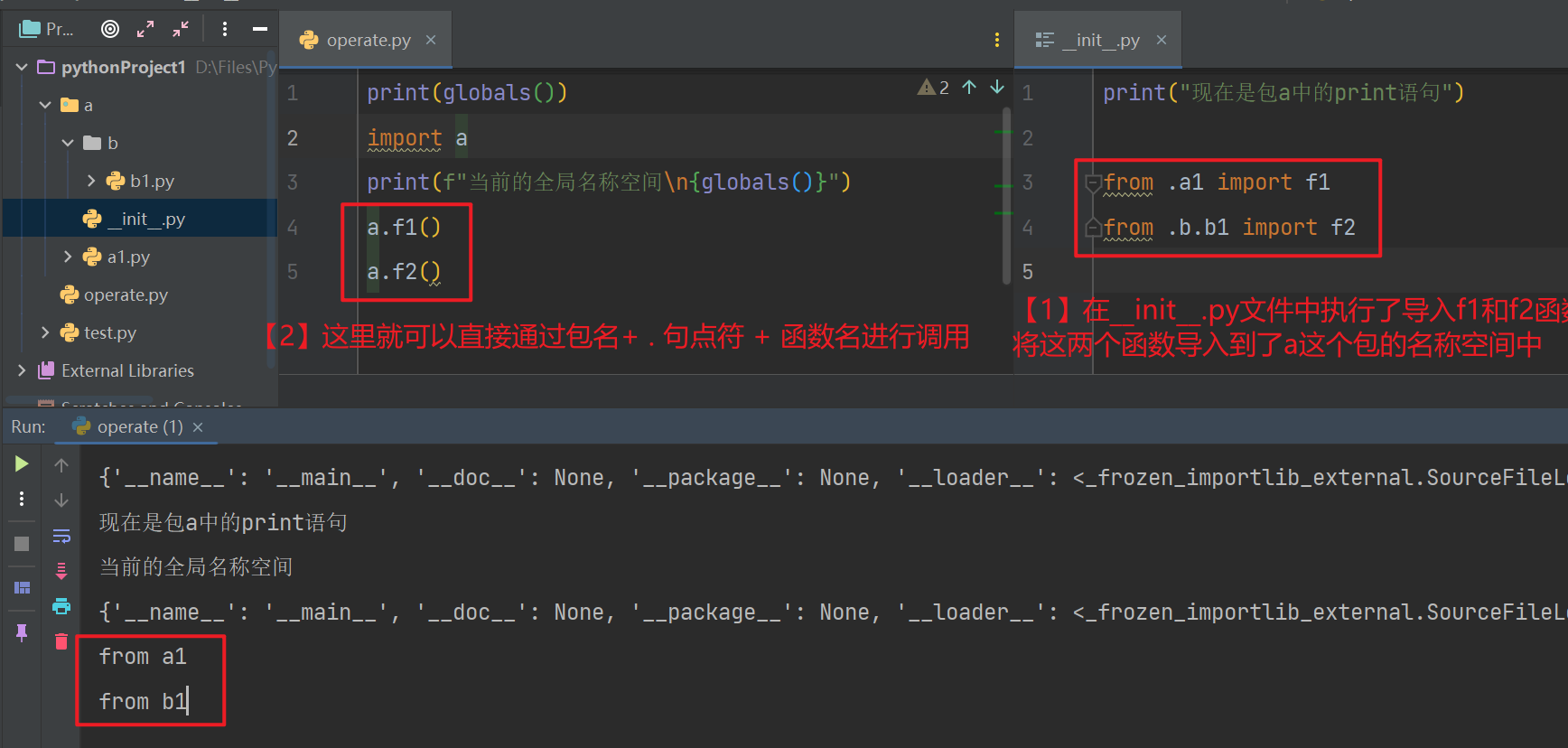
import 包的名字
# 导包其实就是在导入包文件目录下的__init__.py文件的!
"""
导包发生了什么事儿?
1. 首先是运行执行文件,产生执行文件的名称空间
2. 运行__init__.py文件,产生__init__.py(包的名称空间)文件的名称空间,会把该文件的所有名字都丢到该名称空间中
3. 在执行文件中产生一个包名指向包的名称空间
"""


 浙公网安备 33010602011771号
浙公网安备 33010602011771号