Python高级之迭代器与生成器
迭代器与生成器
【一】迭代器
- 在 Python 中,迭代是一种访问容器对象(例如列表、元组、字典等)元素的方式。迭代允许我们逐个访问序列中的元素,而不需要显式地使用索引。这种遍历序列的过程通常通过使用
for循环来实现。 - 在迭代中,被遍历的对象被称为可迭代对象(Iterable),而用于遍历的变量被称为迭代器(Iterator)。
【1】可迭代对象(Iterable):
- 可迭代对象是具有
__iter__()方法的对象,或者具有实现__getitem__()方法并能够在索引从 0 开始递增的范围内访问元素的对象。常见的可迭代对象包括列表、元组、字典、集合等。
from collections.abc import Iterable
my_list = [1, 2, 3, 4, 5]
# 判断一个对象是否是可迭代对象
print(isinstance(my_list, Iterable)) # 输出 True
- 常见的数据类型
'''可迭代类型'''
name_str = 'user' # <method-wrapper '__iter__' of str object at 0x0000025B8FE907B0>
num_list = [1, 2, 3] # <method-wrapper '__iter__' of list object at 0x000001672DF44F80>
num_tup = (1, 2, 3) # <method-wrapper '__iter__' of tuple object at 0x00000222BA26B540>
num_dict = {'a': 1, 'b': 2} # <method-wrapper '__iter__' of dict object at 0x0000021A3C1B1BC0>
num_set = {1, 2, 3} # <method-wrapper '__iter__' of set object at 0x000001D44AF02CE0>
'''不可迭代类型'''
is_bool = True # 'bool' object has no attribute '__iter__'.
num1 = 2 # 'int' object has no attribute '__iter__'
float1 = 1.0 # 'float' object has no attribute '__iter__'
【2】迭代器(Iterator):
- 迭代器是实现了迭代协议的对象,它必须包含
__iter__()方法和__next__()方法。__iter__()返回迭代器对象本身,而__next__()返回下一个元素。当没有更多元素时,__next__()应该引发StopIteration异常。
from collections.abc import Iterator
my_list = [1, 2, 3, 4, 5]
my_iterator = iter(my_list)
# 判断一个对象是否是迭代器
print(isinstance(my_iterator, Iterator)) # 输出 True
【3】迭代器对象
-
调用
obj.__iter__()方法返回的结果就是一个迭代器对象(Iterator)。 -
迭代器对象是内置有
iter和next方法的对象,打开的文件本身就是一个迭代器对象
- 执行
迭代器对象.iter()方法得到的仍然是迭代器本身 - 而执行
迭代器.next()方法就会计算出迭代器中的下一个值。
- 执行
-
迭代器是Python提供的一种统一的、不依赖于索引的迭代取值方式,只要存在多个“值”,无论序列类型还是非序列类型都可以按照迭代器的方式取值
【4】迭代过程:
- 通常,我们使用
for循环来进行迭代。for循环会调用可迭代对象的__iter__()方法获取迭代器对象,然后调用迭代器对象的__next__()方法逐个获取元素,直到遇到StopIteration异常。
my_list = [1, 2]
iterator = my_list.__iter__()
print(iterator) # <list_iterator object at 0x000002448198A6B0>
print(iterator.__next__()) # 1
print(iterator.__next__()) # 2
print(iterator.__next__()) # StopIteration
my_list = [1, 2, 3, 4, 5]
for element in my_list:
print(element)
# for循环内部其实相当于做了一个try except异常捕获的操作,帮助我们遍历可迭代对象
# 如下面的whil循环语句
- 或者我们可以手动使用迭代器进行迭代:
my_list = [1, 2, 3, 4, 5]
my_iterator = iter(my_list) # 通过iter()方法将my_list转为迭代器
print(type(my_iterator)) # <class 'list_iterator'>
while True:
try:
element = next(my_iterator)
print(element)
except StopIteration:
break
# 1 2 3 4 5
【二】生成器
【1】什么是生成器(Generator)
- 生成器是一种特殊的迭代器,它通过函数中的
yield语句来生成值。与普通函数不同,生成器函数在执行时并不一次性生成所有的值,而是在每次调用next()时生成一个值,并在暂停时保存当前状态。这种方式更加节省内存并支持懒加载。 - 通过生成器,可以逐个生成序列中的元素,而无需一次性生成整个序列。
- 生成器在处理大数据集时,具有节省内存、提高效率的特点。
| 懒加载(Lazy Loading),也被称为延迟加载,是一种软件设计模式,其主要思想是推迟某个操作或对象的创建、计算或加载直到真正需要的时候。这可以帮助减少系统启动时间、减轻资源压力,并提高程序的性能。 在懒加载中,不会在初始化阶段立即加载对象或执行操作,而是在需要的时候才进行加载。这种方式通常用于处理资源密集型或者耗时较长的操作,以避免不必要的开销。 |
|---|
# 创建一个简单的生成器
def my_generator():
yield 1
yield 2
yield 3
yield 4
yield 5
# 使用生成器逐个访问元素
gen = my_generator()
print(next(gen)) # 输出 1
print(next(gen)) # 输出 2
# ...
生成器的好处在于它们在运行时生成值,而不是一次性生成所有值。这对于处理大量数据或需要按需生成值的情况非常有用。
【2】生成器的两种创建方式
【2.1】通过推导式进行生成(i for i in range(3))
# 并没有真正的元组推导式,()小括号构成的是生成器
tup1 = (i for i in range(3))
print(tup1, type(tup1))
# <generator object <genexpr> at 0x000001F1A1AC8350> <class 'generator'>
print(next(tup1)) # 0
print(next(tup1)) # 1
print(next(tup1)) # 2
print(next(tup1)) # StopIteration
【2.2】通过yield关键字
def my_generator():
yield 1
yield 2
yield 3
print(type(my_generator)) # <class 'function'>
# 函数未加()调用前,my_generator的内存地址类型是函数
# 当函数被调用时,函数将转为生成器
print(type(my_generator())) # <class 'generator'>
g = my_generator()
print(type(g)) # <class 'generator'>
print(next(g)) # 输出:1
print(next(g)) # 输出:2
print(next(g)) # 输出:3
- 在 Python 中,函数是一等公民,它是对象。函数对象的类型是
function。当你不加括号调用函数时,你得到的是函数对象本身,而不是函数的执行结果。因此,此时的类型是function。 - 当你加上括号调用函数时,Python 解释器会执行函数体内的代码,并返回函数的执行结果。如果函数内部包含有
yield关键字,这个函数就是一个生成器函数,调用时返回的是生成器对象。此时,函数对象的类型变为generator。
让我们通过示例来说明:
def my_function():
print("This is a function.")
def my_generator():
yield 1
yield 2
yield 3
# 不加括号获取函数对象
func_object = my_function
print(type(func_object)) # 输出 <class 'function'>
# 加括号调用函数获取执行结果
func_result = my_function()
print(type(func_result)) # 输出 This is a function. <class 'NoneType'>,因为该函数没有返回值
# 不加括号获取生成器函数对象
gen_func_object = my_generator
print(type(gen_func_object)) # 输出 <class 'function'>
# 加括号调用生成器函数获取生成器对象
gen_object = my_generator()
print(type(gen_object)) # 输出 <class 'generator'>
【3】生成器的调用
【3.1】通过yield+send进行使用
def index():
count = 0
while True:
# yield "进入while了".center(30,'-')
# print("进入while了".center(30,'-'))
food = yield
print(f"现在的food是{food}")
count += 1
print(f"现在是第{count}次yield".center(30, '-'))
genetator = index()
print(genetator, type(genetator)) # <generator object index at 0x000001C9D7CFEB20> <class 'generator'>
next(genetator) # 需要先使用一次next(),将函数暂停在yield的位置
genetator.send("西红柿炒蛋")
# 向yield 传值,并向下运行
genetator.send("土豆丝")
# 因为是个循环语句,向下执行完毕就会返回到yield语句开始的位置,所以可以继续传参
genetator.send("土豆牛腩")
# 输出的结果
'''
现在的food是西红柿炒蛋
---------现在是第1次yield----------
现在的food是土豆丝
---------现在是第2次yield----------
现在的food是土豆牛腩
---------现在是第3次yield----------
'''
# 有一些怪情况 目前来看 是生成器的问题
# 当生成器内容执行完毕后 会自动抛出StopIteration异常
'''end给生成器发送数据11--->函数tt()里面执行完毕--->找下一个yield语句--->又回到send那里,因为这里它找下一个yield语句找不到,所以就会报StopIteration异常。'''
# 这个的解决办法就是在函数结尾添加一个占位的yield
# 但这样就需要每次传多次时多添加一层跳过
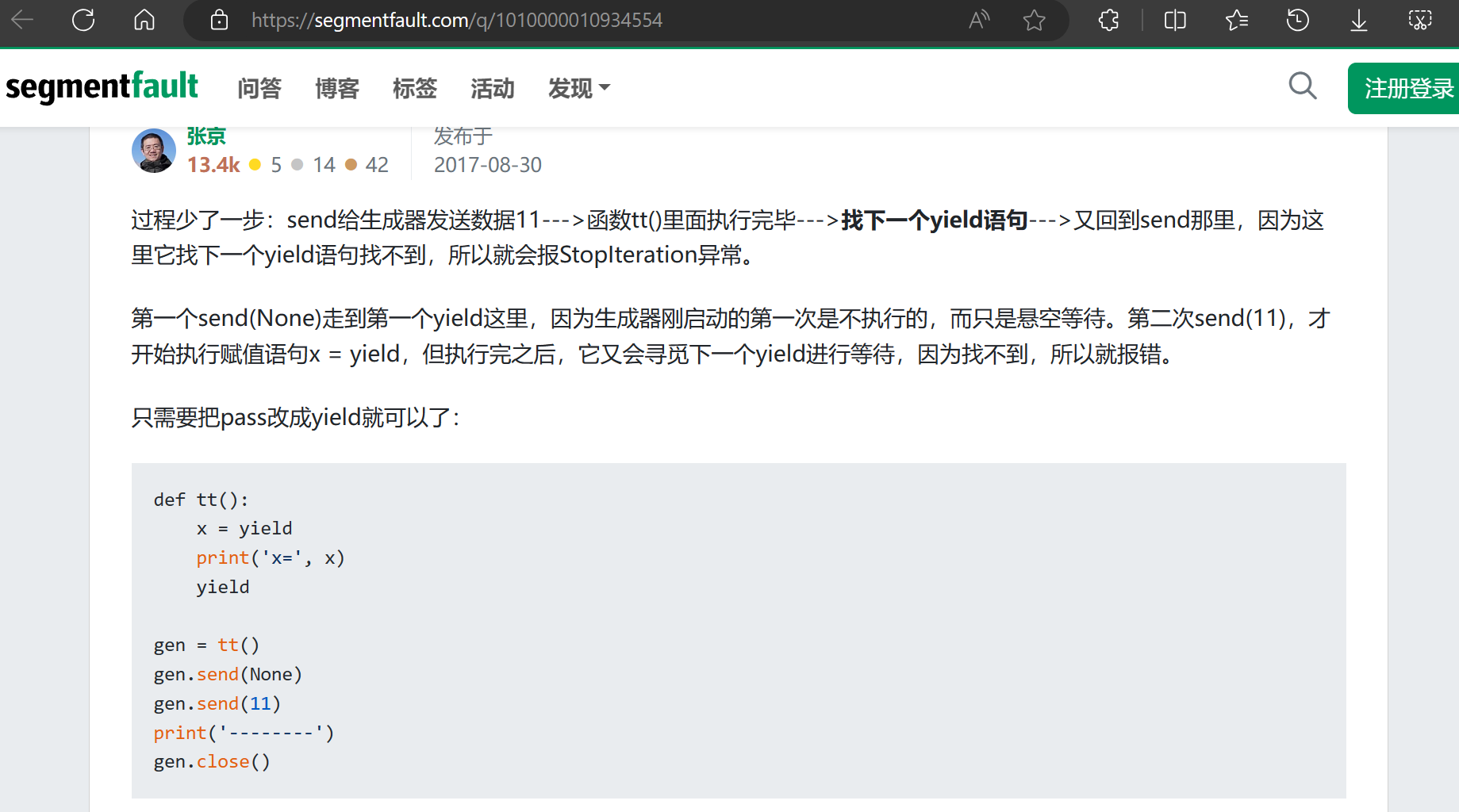
# 会报错的情况
def index():
count = 0
while count < 3:
# yield f"yield进入while了".center(30,'-')
food = yield
print(f"food是{food}".center(30, ' '))
count += 1
genetator1 = index()
genetator1.send(None)
genetator1.send("西红柿炒蛋")
print("这是测试用的,yield函数是否会连带着执行这行代码")
genetator1.send("土豆丝")
print("这是第二次测试用的,yield函数是否会连带着执行这行代码")
genetator1.send("土豆牛腩")
print("这是第三次测试用的,yield函数是否会连带着执行这行代码")
'''
food是西红柿炒蛋
这是测试用的,yield函数是否会连带着执行这行代码
food是土豆丝
这是第二次测试用的,yield函数是否会连带着执行这行代码
food是土豆牛腩
Traceback (most recent call last):
File "****** line 16, in <module>
genetator1.send("土豆牛腩")
StopIteration
'''
# 补充了一个yield参数
def index():
count = 1
while count <= 3:
# yield f"yield进入while了".center(30,'-')
food = yield
print(f"food是{food}".center(30, ' '))
count += 1
yield
genetator1 = index()
genetator1.send(None)
genetator1.send("西红柿炒蛋")
print("这是测试用的,yield函数是否会连带着执行这行代码")
genetator1.send(None)
genetator1.send("土豆丝")
print("这是第二次测试用的,yield函数是否会连带着执行这行代码")
genetator1.send(None)
genetator1.send("土豆牛腩")
print("这是第三次测试用的,yield函数是否会连带着执行这行代码")
'''
food是西红柿炒蛋
这是测试用的,yield函数是否会连带着执行这行代码
food是土豆丝
这是第二次测试用的,yield函数是否会连带着执行这行代码
food是土豆牛腩
这是第三次测试用的,yield函数是否会连带着执行这行代码
'''
【3.2】单独的yield 和 变量名赋值变量名 = yield
-
单独的
yield: 在生成器函数中,单独的yield语句用于产生值,并在产生值后暂停执行,将生成器的状态保存下来,等待下一次调用。示例:def my_generator(): yield 1 yield 2 yield 3 gen = my_generator() print(next(gen)) # 输出 1 print(next(gen)) # 输出 2 print(next(gen)) # 输出 3 -
变量名赋值
yield: 变量名赋值yield允许外部代码将值传递给生成器。这样,生成器可以从外部接收值,并在内部使用。示例:def my_generator(): value = yield print(value) gen = my_generator() next(gen) # 执行到第一个 yield 之前 gen.send(42) # 将 42 传递给生成器,并在内部打印输出
【4】生成器的特点
-
使用函数定义生成器: 生成器是通过函数中的
yield语句定义的。当函数被调用时,它并不立即执行,而是返回一个生成器对象。def my_generator(): yield 1 yield 2 yield 3 gen = my_generator() -
迭代生成器: 生成器可以用于
for循环,也可以使用next()函数逐个获取值。for value in my_generator(): print(value)或者手动使用
next():gen = my_generator() print(next(gen)) # 输出 1 print(next(gen)) # 输出 2 print(next(gen)) # 输出 3 -
惰性计算: 生成器只在需要时才生成值,可以大大减少内存消耗。这对于处理大量数据或无限序列非常有用。
-
状态保存: 生成器在每次执行
yield语句时会保存当前状态,下次调用next()时从上一次暂停的地方继续执行。def my_generator(): yield 1 print("After yielding 1") yield 2 print("After yielding 2") yield 3 gen = my_generator() print(next(gen)) # 输出 1,打印 "After yielding 1" print(next(gen)) # 输出 2,打印 "After yielding 2" -
方便的表达式: 生成器可以使用推导式来简洁地创建。
gen = (x for x in range(5)) -
无限序列: 生成器允许创建无限序列,因为它们是按需生成的。
def infinite_sequence(): num = 0 while True: yield num num += 1 gen = infinite_sequence() print(next(gen)) # 输出 0 print(next(gen)) # 输出 1 ... # 可以无限next
【三】生成器与迭代器的关系
- 生成器是迭代器的一种实现: 生成器是一种特殊的迭代器,它们都可以用于迭代操作,但生成器是通过生成器函数动态生成值,而迭代器则是通过定义
__iter__()和__next__()方法手动实现迭代器接口。 - 生成器提供了一种更简洁的迭代器实现方式: 生成器函数定义了一种简洁的语法来生成迭代器,不需要显式地实现迭代器接口,而是使用
yield关键字来逐个生成值,使得代码更加简洁易读。 - 生成器和迭代器都具有惰性求值的特性: 生成器对象是按需生成值的,它们在每次调用
next()函数时才会生成下一个值,因此可以有效地节省内存和提高性能,特别是在处理大数据集时。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号