

BUAA_OO_Unit3 总结
一、社交图网络架构分析
(一)第九次作业
1 需求分析
-
Person是组成社交图网络的基本原子,具有一定的属性,且可以通过“熟人”关系和别的Person进行连接;
-
Group是一个群组,可以容纳多个Person,并对在Group中所有的Person进行某些属性上的统计。此处要注意的是,群组并不是“连通子块”,即群内的人并不一定相识(可以类比于现实当中的微信群,你也不是有微信群所有人好友的吧);
-
Network是完整的社交图网络,其中包含多个Group和多个Person,在社交网络中,可以对某个群组或个人的属性进行查询,也可以对人与人之间的连通情况进行查询。
此外,每个层次都由官方包的接口提供了待实现的方法与相关的JML描述,我们要完成的任务就是理解整体架构并实现JML的描述。
2 整体架构
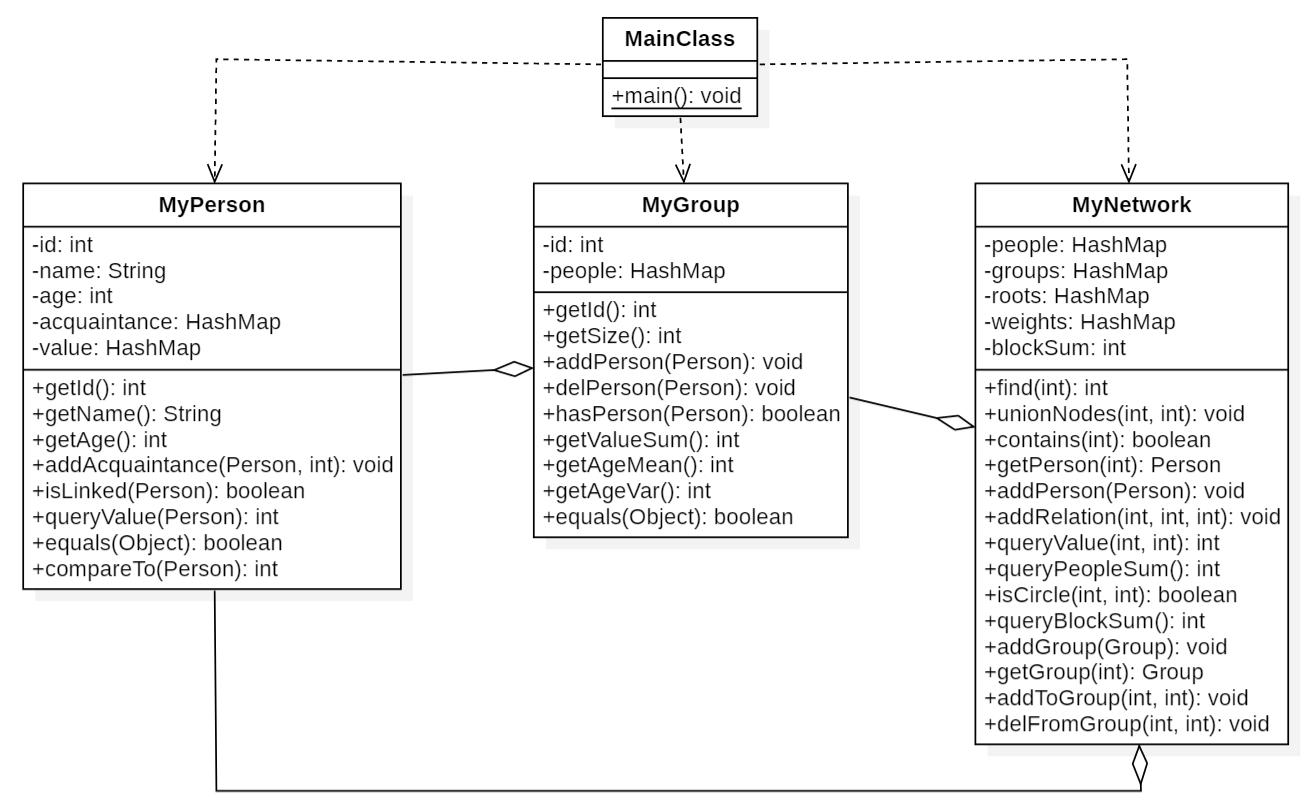
3 设计分析
由于社交图网络的层次化结构,我们整体的设计用聚合关系构建:Person聚合为Group,Person聚合为Network,同时Group聚合为Network。由于具体方法都由JML规格给出,整体实现难度是比较低的,唯一要注意的是JML规格只给出设计要求,对于实现的性能是不做规定的,为此我们从两个方面提高性能:
-
选择适当容器。在JML描述中不对集合的容器做出规定,但得益于规格中表示每个层次主体都包含一个独一无二的id,我们可以利用HashMap进行存储,从而达到O(1)级别的访问。
-
连通算法。在Network层次中包含
isCircle与queryBlockSum指令,前者要求传入两个Person,判断二者是否通过间接的熟人关系进行连通;后者则要求出Network中包含多少连通子块。对于该连通情况的查询,本次作业采取并查集算法,并将该算法内嵌到Network类中实现。具体实现见下文图算法部分。
(二)第十次作业
1 需求分析
本次作业在上次作业的基础上增加了如下需求:
-
实现Message接口,并在Person与Network层次扩展相关的存储容器和方法,从而进行消息的收发;
-
官方测试指令扩展。尤其注意的是在上次作业已经实现的
queryGroupValueSum在这次作业中要做出测试,故要注意实现的性能问题; -
新指令的扩展。尤其注意的是指令
queryLeastConnection,本质上是对连通子块的最小生成树进行查询。
2 整体架构

3 迭代分析
对于三个需求增量,本次作业做出的处理如下
-
对于新增的Message接口,我们严格依照JML描述实现即可;而对于Person与Network中存储消息的容器,由于在Person的具体功能中要求Message是有序的,故使用ArrayList进行存储,在Network中可以继续使用HashMap提高访问性能;而新增的传递消息的功能,我们也按照JML直接实现即可(因为实现上没有性能问题)。
-
由于官方测试指令的扩展,本次需要对一些指令的性能做出改进,改进的主要方式是缓存机制。例如指令
queryGroupValueSum,可以通过在Group层次维护一个valueSum变量,在加人、删人和加关系三个操作时动态更新该变量即可;这样在每次访问该变量时可以做到O(1)的操作。 -
对于新增指令
queryLeastConnection,采用朴素的贪心算法。为此在设计上做出如下调整:-
抽象出Relation类,对于人的关系进行存储,相当于连通子块的带权边;
-
抽象出Block层次,存储连通子块的所有人和关系,并在类内查询最短路;
-
抽象出BlockSum层次,是Network的另一种存储方式,对所有连通子块Block进行管理;
-
将并查集算法UnionFind单独抽象为类,以便在不同地方使用。
设计上做出调整后,算法的实现就只是细节问题了,具体见后面的图算法部分。
-
(三)第十一次作业
1 需求分析
本次作业在上次作业的基础上增加了如下需求:
-
扩展Message类,增加三个子类,以丰富消息的内涵;
-
对于三个新增的消息类扩展功能;
-
新增指令
sendIndirectMessage,对于直接不可达的消息进行转发,并求出最短的转发路径。本质上是考察最短路算法。
2 整体架构
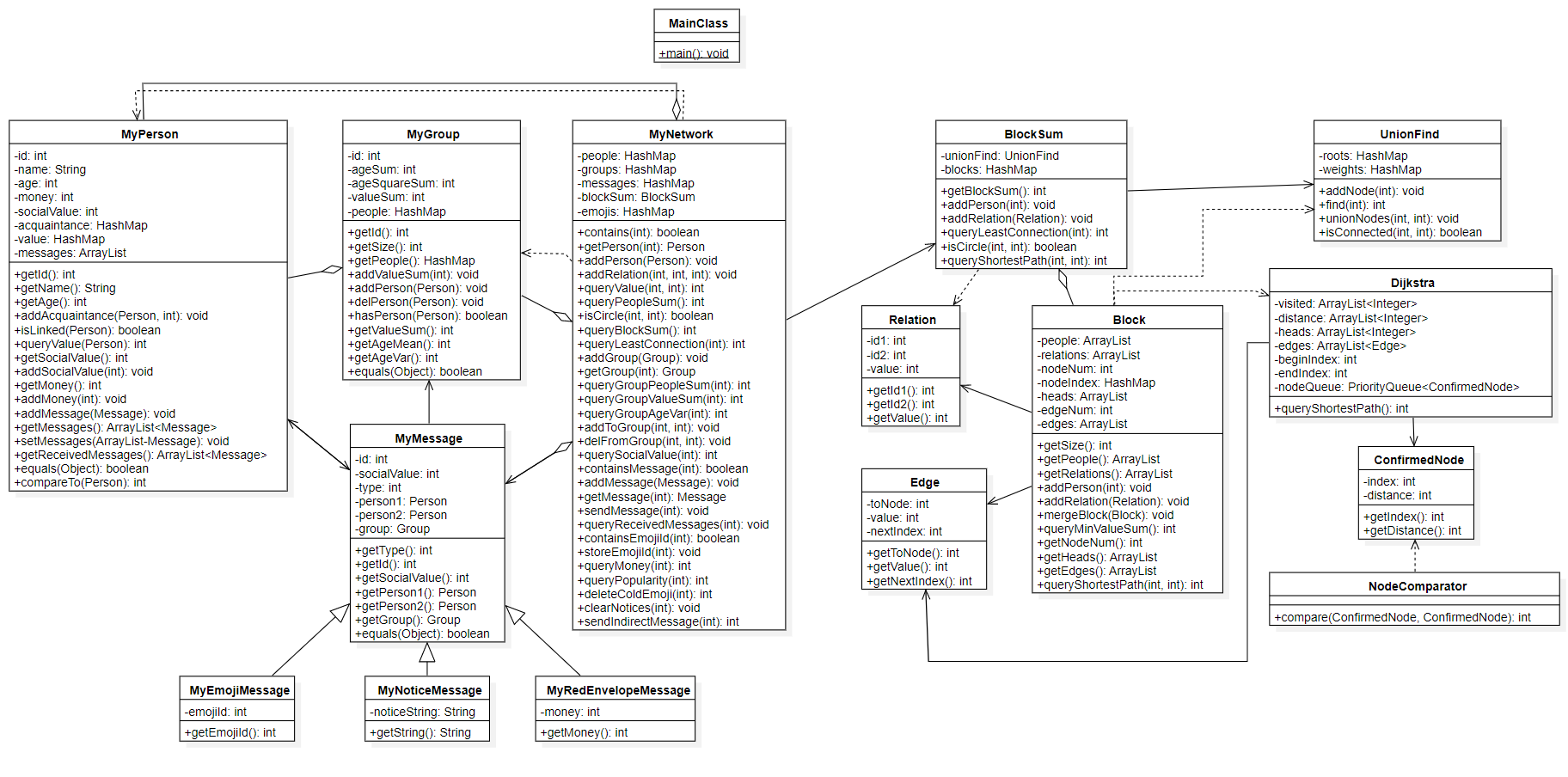
3 迭代分析
对于三个需求增量,本次作业做出的处理如下
-
对于新增的Message类,严格按照JML描述处理即可;
-
对于新增的消息功能严格按照JML描述处理即可。当然要注意集合增删处理的细节,这里的问题会在测试部分做出描述;
-
对于新增的最短路算法需求,本次做出的架构扩展如下:
-
新增ConfirmedNode类和Edge类,代表最短路算法中的已确认节点与边,其中Edge相对于Relation增加了支持链式前向星设计的改进,是Relation的另一种表示形式。二者都是是最短路算法的原子类;
-
新增Dijkstra类,是求解最短路的迪杰斯特拉算法的算法类。
-
由于两次作业迭代形成的类已经有些繁多,再加上整体设计还算层次化,我在本次作业将相互关联的类都放在一个package中,从而形成更清楚的逻辑结构,具体设计如下:
-
networkstruct:包含MyPerson、MyGroup、MyNetwork类。是社交图网络的具象结构。
-
messages:包含MyMessage、MyEmojiMessage、MyNoticeMessage、MyRedEnvelopeMessage类。是社交网络中传递的消息。
-
abstractstruct:包含Relation、Edge、Block、BlockSum类。表示出社交网络的基于连通块的抽象图结构。
-
algorithm:包含ConfirmedNode、NodeComparator、UnionFind、Dijkstra类。是涉及的图算法类集合。
具体的结构在UML类图的排布上也可见一斑。
二、性能分析与算法实现
(一)性能需求解析
JML描述只对实现的结果做出规约,而不关心具体的性能与设计问题,所以在JML规格描述中会出现多层循环嵌套的结构。若不对这些描述的实现进行化简,容易造成性能较低的后果。在本单元作业中,性能优化可以分为两个方面进行。
1 基于缓存的性能
以Group类中的getValueSum方法为例。其JML描述如下:
/*@ ensures \result == (\sum int i; 0 <= i && i < people.length;
@ (\sum int j; 0 <= j && j < people.length &&
@ people[i].isLinked(people[j]); people[i].queryValue(people[j])));
@*/
public /*@ pure @*/ int getValueSum();
这个指令单条时间复杂度就达到了O(n2),若叠加n条指令,总复杂度可以达到O(n3),这种复杂度是不可忍受的。为此,我们可以在Group类中维护valueSum属性,在每次增人、删人、增关系时动态更新这个变量,就可以做到查询时O(1)的复杂度。
2 基于图算法的性能
社交网络本身是一个巨大的含有多个连通分支的图,所以在本单元的作业中也涉及了相关的图论问题,其高性能的实现需要依赖一定的图算法。具体的对应关系如下:
-
连通性的查询——并查集算法
-
最小生成树——Kruskal算法
-
最短路径查询——Dijkstra算法
其具体的实现见下面一个部分。由于不是算法课程,我仅对算法的思路做出理解性的阐述。
(二)图算法
1 按秩合并+并查集的连通查询
并查集,在《啊哈!算法》一书中有个简短而精妙的描述“擒贼先擒王”。大致来说可以理解为:在增加两个点之间边/关系的时候,若两个点先前没有连通,则确定一个“老大”节点,只要每次都确定了节点的序关系,就可以构建一个类似于黑社会的网络。而判断两个节点是否连通可以通过比较两个节点的“王”节点是否相同实现。
当然,对于这样一个树形结构,影响性能的关键就是树的高度。为了尽量缩减树的高度,我们有两个优化点:按秩合并和路径压缩。
所谓按秩合并,解决了这样一个问题:两个点之间谁做“老大”节点呢?很明显,为了减小树的高度,我们要使自己所在的树高度更高的节点作为老大。但是在实现过程中我们会发现高度这一变量难以维护,于是退而求其次,我们通过比较两棵树含有的节点数(重量/秩)来作为判断标准,其原理是重量大的高度大概率更大。
而路径压缩则发生在并查集的find函数中。大致来说,就是每次在寻找祖先的路径上,将路径上的所有点压缩,即修改路径上所有点的直接父亲为当前树的根节点。这样一来,这条路径上树的高度就变为了2,可以大大提高索引效率。
2 Kruskal算法求解最小生成树
所谓Kruskal算法,就是按边排序的贪心算法:每次寻找权值最小的边,若这条边可以将两个本来不连通的点连接起来,则选定这条边,直到选中n-1(n为节点数)条边为止。而判断两个点是否连通,可以利用上一点中的并查集实现。(这也是我将并查集作为单独的类实现的原因之一——因为在多处使用到)。
3 链式前向星+Dijkstra的最短路查询
参考资料:
所谓Dijkstra算法,本质也是贪心算法,它维护了两个节点集:确定最短路的节点集P和未确定最短路的节点集Q,其核心过程可以用递归表示为:
-
在Q中寻找最短可达的节点q,加入集合P中;
-
遍历q到Q中其他节点的边,看看是否可以更新还在Q中节点的最短距离。
其中遍历边的操作可以进一步优化,用链式前向星存储具体的边的结构。所谓的链式前向星,就是一个存储一个起点对应多个边的邻接表。通过这个表访问边甚至可以达到比HashMap更高的效率。
最短路算法的核心实现逻辑如下:
public int queryShortestPath() {
distance.set(beginIndex, 0);
nodeQueue.add(new ConfirmedNode(beginIndex, 0));
while (visited.get(endIndex) == 0) {
ConfirmedNode cfNode = nodeQueue.poll();
int cfIndex = cfNode.getIndex();
visited.set(cfIndex, 1);
for (int i = heads.get(cfIndex); i != -1; i = edges.get(i).getNextIndex()) {
int toIndex = edges.get(i).getToNode();
int value = edges.get(i).getValue();
if (visited.get(toIndex) == 0 &&
distance.get(toIndex) > distance.get(cfIndex) + value) {
distance.set(toIndex, distance.get(cfIndex) + value);
nodeQueue.add(new ConfirmedNode(toIndex, distance.get(toIndex)));
}
}
}
return distance.get(endIndex);
}
三、基于规格的测试
(一)基于规格的全面测试
由于这次作业是基于JML描述进行开发的,而JML对各个输入限制都做了严格分类,我们要进行全面测试也可以基于规格进行数据的构造。由于本人并没有搭建自动评测机,只对评测数据的生成思路做出简单描述。
首先是常规测试。在数据生成初期只生成ap、ar、ag、atg指令的生成,且尽量保证不抛出异常,从而构建一个比较大的且完整的社交图网络;之后保证图网络的不变,随机生成各种查询指令且尽量保证指令合法,从而对功能进行覆盖性的测试。
其次是异常测试。对于各种异常即抛出顺序,JML规格都做出了严格规定。为此,我们只需要在常规测试下加大数据生成的随机性,既可以产生较为大量的异常数据。此外也可以通过压力测试加大异常概率。
最后是基于规格细节和性能的测试。这两部分的数据在随机数据生成中不易产生,需要手动构造,具体看后面两点的介绍。
(二)基于规格细节的测试
JML描述条分缕析地分类出各种输入行为下的输出情况,由于规格的需求,这种分类往往是细致甚至繁琐的,有些规格的细节没有被注意,容易造成实现的错误,对此可以构造基于规格细节的测试数据。
例如在addToGroup方法的描述中有这样一条:
/*
@ also
@ public normal_behavior
@ requires (\exists int i; 0 <= i && i < groups.length; groups[i].getId() == id2) &&
@ (\exists int i; 0 <= i && i < people.length; people[i].getId() == id1) &&
@ getGroup(id2).hasPerson(getPerson(id1)) == false &&
@ getGroup(id2).people.length >= 1111;
@ assignable \nothing;
*/
规格要求在组内人数≥1111时不能向组内增加人数。为此可以构造数据:向组内添加1110个人,添加第1111个人时选择之前添加过的id,若不抛出异常则实现正确。
(三)基于性能的测试
在上文中我们提到过,JML只对最终结果做出契约,而对设计的过程不做过多规定,所以其描述总是“简朴”的——从另一方面来说,是不保证性能的。例如上文出现的在Group类中的getValueSum方法,其描述中采用的是两层for循环,自身的复杂度达到了O(n2),再叠加n条这样的指令,最终复杂度可以达到O(n3),时间开销是恐怖的。为此我们可以构造数据(总2000条指令):创建666个人并添加进组,之后查询组内valueSum666次,可以达到最大的时间复杂度,从而进行卡性能的测试。
与此类似的可以卡性能的指令还有queryBlockSum,具体构造不再赘述。(总的来说,单条指令的复杂度达到O(n2)的都可以进行尝试)。
(四)基于语言特性的测试
在第十次作业的过程中,我的程序在高工大佬的测试下出现了一个bug,这个bug之神奇,以致于官方包都没有考虑周全。(所以本人也不幸hack到了官方包,导致一刀七事件的发生,在此向被hack的同学做出诚挚的道歉)
简单来说,这个bug触碰到了一个Java ArrayList中remove方法的底层逻辑。一言以蔽之,remove方法的逻辑如下所述:
remove()方法删除的元素为:按照列表索引值从小到大遍历,equals方法判断相等的第一个元素。而所谓的equals方法判断相等,在不重写equals方法的前提下,为内存位置相同的同一元素;而在重写equals方法后,一定要注意判断相等的逻辑,避免误删情况的发生。
由于这样的特性,我们可以构造如下数据:
ap 1 A 12
ap 2 B 13
ar 1 2 3
anm 3 mindYourNoticeRemove 0 1 2
sm 3
am 3 12 0 1 2
sm 3
cn 2
qrm 2
在这组数据中,我们首先向一个人发送id为3的notice消息,由于此时社交网络中已经不包含id为3的消息,所以可以再加入一个id为3的普通消息并发送。此时这个人获取了两个id为3的消息,且普通消息被插入消息列表头部。之后调用cn(clear notice)指令。对于如下实现:
ArrayList<Message> delMessages = new ArrayList<>();
for (Message message : getPerson(personId).getMessages()) {
if (message instanceof NoticeMessage) {
delMessages.add(message);
}
}
MyPerson person = (MyPerson) getPerson(personId);
for (Message message : delMessages) {
person.delMessage(message);
}
其中delMessage方法调用的正是remove方法,由于传入的是message元素,而不是具体索引位置,所以判断删除调用了equals方法,不巧的是,我们的equals方法判断的正是id,所以导致删除的是第一个出现的普通消息,而非应该删除的notice消息。
当然,在修改官方程序后,这样的数据直接被认定为非法了。但是其体现的内核——实现过程中要时刻注意Java语言的特性,是令我受益匪浅的。
四、社交图网络的扩展
(一)题目要求
假设出现了几种不同的Person
-
Advertiser:持续向外发送产品广告
-
Producer:产品生产商,通过Advertiser来销售产品
-
Customer:消费者,会关注广告并选择和自己偏好匹配的产品来购买
所谓购买,就是直接通过Advertiser给相应Producer发一个购买消息
-
Person:吃瓜群众,不发广告,不买东西,不卖东西
扩展Network,使之可以支持市场营销,并能查询某种商品的销售额和销售路径等。
(二)初步设计
思考社交网络中产品产生的逻辑:人们首先有一个需求,商家根据这个需求生产产品,再由经销商进行推销。推销到消费者后,消费者根据生产的具体商品的信息判断是否买该商品:若买商品,则发送购买消息给经销商;否则直接删除推销消息。
为此,我们需要三个方面的扩展:
1 产品扩展
产品是扩展为市场营销的新主体,需要单独设计一个接口Product。在设计具体的接口属性时,我们需要思考所谓的“消费者需求”这个逻辑。为什么消费者会有购物需求?一方面,这个产品的种类恰巧是ta需要的种类,另一方面,这个产品的价格不超出消费者预算。所以我们为此要额外扩展一个类。具体设计如下。
-
Type枚举类:表示商品的类别,是匹配商品是不是消费者偏好的抽象类型。(具体的字段可以如食物、饮品等)。 -
Product接口:表示具体的产品。具有属性id,指代具体的产品;type,指代产品的种类;price,指代产品的价格。
2 消息扩展
要进行营销应该设计两类消息:推销消息与购买消息,两个消息都可以通过继承Message接口实现。具体设计如下。
-
AdvertisementMessage:推销消息。包含ProducerId,AdvertiserId和Product,指代生产者、经销商和具体商品(的信息)。 -
PurchaseMessage:购买消息。包含CostomerId,AdvertiserId,Product和Number,指代生产者、经销商和具体商品(的信息)和购买数量。
3 人的扩展
涉及的三类人可以通过继承Person接口实现。具体设计如下。
-
Advertiser:经销商。需要存储联系的producers[]与costomers[],并负责收发推销消息与购买消息; -
Producer:产品商。需要存储自己生产的products[]和对应产量outputs[],从而提供产品。 -
Costomer:消费者。需要存储自己的需求types[]和需求量demands[],已经拥有的产品products[]和持有量holds[],从而对推销消息做出响应,并支持销售量的查询。
(三)JML规格
这里仅对消费者和查询产品销量的相关操作做出设计。
-
判断消费者是否有需求
/*
@ public normal_behavior
@ assignable \nothing;
@ ensures \result == ((\exists int i; 0 <= i && i <= types.length;
@ adMessage.getProduct.getType.equals(types[i])) &&
@ (adMessage.getProduct.getPrice *
@ getDemand(adMessage.getProduct.getType) < money));
*/
public boolean hasDemand(AdvertisementMessage adMessage); -
判断消费者某件商品购买量
/*
@ public normal_behavior
@ requires containsProduct(product);
@ assignable \nothing;
@ ensures \result == ((\exists int i; 0 <= i && i <= products.length;
@ product == products[i]) holds[i]);
@ also
@ public normal_behavior
@ requires !containsProduct(product);
@ assignable \nothing;
@ ensures \result == 0;
*/
public int queryAmount(Product product); -
判断消费者是否含有某消息
/*
@ public normal_behavior
@ assignable \nothing;
@ ensures \result == (\exists int i; 0 <= i && i <= messages.length;
@ messages[i].getMessageId == messageId);
*/
public boolean containsMessage(int messageId); -
Costomer处理广告消息/*
@ public normal_behavior
@ requires containsMessage(adMessage.getId) && hasDemand(adMessage);
@ assignable messages[], money;
@ ensures messages.length == (\old(messages.length) - 1);
@ ensures (\forall int i; 0 <= i && i < \old(messages.length);
@ (\exists int j; 0 <= j && j < messages.length;
@ messages[j].equals(\old(messages[i]))));
@ ensures (\forall int i; 0 <= i && i < messages.length;
@ !messages[i].equals(adMessage));
@ ensures money == (\old(money) - adMessage.getProduct.getPrice *
@ getDemand(adMessage.getProduct.getType));
@ also
@ public normal_behavior
@ requires containsMessage(adMessage.getId) && !hasDemand(adMessage);
@ assignable messages[];
@ ensures messages.length == (\old(messages.length) - 1);
@ ensures (\forall int i; 0 <= i && i < \old(messages.length);
@ (\exists int j; 0 <= j && j < messages.length;
@ messages[j].equals(\old(messages[i]))));
@ ensures (\forall int i; 0 <= i && i < messages.length;
@ !messages[i].equals(adMessage));
@ also
@ public exceptional_behavior
@ requires !containsMessage(adMessage.getId);
@ signals (MessageNotFoundException e) !containsMessage(adMessage.getId);
*/
public void dealAdvertisement(AdvertisementMessage adMessage) throws MessageNotFoundException; -
求商品销量
/*
@ public normal_behavior
@ requires existProduct(product);
@ ensures \result == (product.getPrice * (\sum int i; 0 <= i && i <= people.length;
@ isCostomer(people[i]) ? people[i].queryAmount(product) : 0))
@ also
@ public exceptional_behavior
@ requires !existProduct(product);
@ signals (ProductNotFoundException e) !existProduct(product);
*/
public int querySales(Product product) throws ProductNotFoundException;
五、本单元学习体会
(一)契约式编程
本单元接触学习的JML规格描述语言,其本质上是契约式编程的一个表现。而所谓的契约式编程,又是建立在防御式编程背景之下的,所以先对防御式编程做出定义。
所谓的防御式编程,其本质思想是“人类都是不安全、不值得信任的,所有的人,都会犯错误,而你写的代码,应该考虑到所有可能发生的错误,让你的程序不会因为他人的错误而发生错误”,一言以概之,就是你要对设计过程的细节“大包大揽”。而如何保证这种实现的错误能够提醒他人呢?在C++中提供了断言机制,在Java中提供了捕获与抛出异常机制,均可以实现对各种情况错误的提醒。
而契约式编程则更简单:由需求者提供程序实现的契约,再由实现者依照契约完成。这样程序员就不用哭天抢地地思考各个实现的细节——相反,契约之外的错误,都是架构师设计不完善导致的,与我无关(●'◡'●)。而要完整地进行规约,一般可以将契约分为前置条件-后置条件-不变式条件三个,不得不说这对规格设计者是一个不小的挑战。而且在我看来,设计规格和实现规格相比,设计规格说不定更加暗含了面向对象的设计思想(也许这就是让我们在博客中涉及规格的初衷?)。
(二)设计模式原则初探
在本单元的作业过程中,我还尝试将设计模式的具体原则融入到设计中。具体体现如下:
1 开闭原则
开闭原则的描述如下:
Software entities should be open for extension,but closed for modification.
也就是说软件的迭代设计,应该保证对扩展开放,对修改关闭。具体到本次作业中,在第十一次作业时我新增了Edge类,其表示的其实也是社交网络的边而已,只不过为了链式前向星的设计增加了一些设计需求。对此,我没有在原有的Relation类中进行修改,而是直接扩展一个单独的类,其目的就是为了保证扩展不会对原有功能造成影响,应该体现了开闭原则的要求。
2 单一职责原则
单一职责原则的描述如下:
There should never be more than one reason for a class to change.
也就是说在类的设计中,需要发现不同职责并将其分离,从而封装到不同的类或模块中。具体到本次作业,我在第九次到第十次作业的迭代开发过程中,将原本在MyNetwork类中实现的并查集算法单独封装成了一个UnionFind类,这就是细化每个类职责的过程。
此外,在总结课上,对于父子类之间JML前置条件、后置条件等的设计需求,也让我深入体会了第三个设计原则。
3 里氏替换原则
里氏替换原则的描述如下:
Inheritance should ensure that any property proved about super-type objects also holds for sub-type objects
这个原则初看有些难以理解,但是其本质就是子类可以扩展父类的功能,但不能改变父类原有的功能。具体到前置条件和后置条件的设计上,父子类应该满足如下关系:
-
当子类的方法重载父类的方法时,方法的前置条件(即方法的输入参数)要比父类的方法更宽松
-
当子类的方法实现父类的方法时(重写/重载或实现抽象方法),方法的后置条件(即方法的的输出/返回值)要比父类的方法更严格或相等
当然,设计模式的原则远不止这三条,其每一条的内涵也远不止上文所提及的如此肤浅。希望我能够在未来软件设计的征程中逐步体会,不断深入学习。
(三)其他

