
三级分类优化-2 缓存优化

缓存分类 本地缓存 把缓存数据存储在内存中(Map<String Object>) 分布式缓存



/** * 根据父编号 获取对应的子菜单信息 * @param list * @param parentCid * @return */ private List<CategoryEntity> queryByParentCid(List<CategoryEntity> list,Long parentCid){ List<CategoryEntity> collect = list.stream().filter(item -> { return item.getParentCid().equals(parentCid); }).collect(Collectors.toList()); return collect; } //本地缓存 private Map<String,Map<String,List<Catalog2VO>>> cache=new HashMap<>(); /** * 查询出所有的2级和三级分类 数据 并封装为json对象 * @return */ @Override public Map<String, List<Catalog2VO>> getCatelog2JSON() { if(cache.containsKey("getCatelog2JSON")){ //直接从缓存中获取 return cache.get("getCatelog2JSON"); } //获取所有数据 List<CategoryEntity> list=baseMapper.selectList(new QueryWrapper<CategoryEntity>()); // 获取所有的一级分类的数据 List<CategoryEntity> leve1Category = this.queryByParentCid(list, 0L); // 把一级分类的数据转换为Map容器 key就是一级分类的编号, value就是一级分类对应的二级分类的数据 Map<String, List<Catalog2VO>> map = leve1Category.stream().collect(Collectors.toMap( key -> key.getCatId().toString() , value -> { // 根据一级分类的编号,查询出对应的二级分类的数据 List<CategoryEntity> l2Catalogs = this.queryByParentCid(list, value.getCatId());//以一级分类的cat_id 为二级分类的parentid List<Catalog2VO> Catalog2VOs =null; if(l2Catalogs != null){ Catalog2VOs = l2Catalogs.stream().map(l2 -> { // 需要把查询出来的二级分类的数据填充到对应的Catelog2VO中 Catalog2VO catalog2VO = new Catalog2VO(l2.getParentCid().toString(), null, l2.getCatId().toString(), l2.getName()); // 根据二级分类的数据找到对应的三级分类的信息 List<CategoryEntity> l3Catelogs = this.queryByParentCid(list, l2.getCatId()); if(l3Catelogs != null){ // 获取到的二级分类对应的三级分类的数据 List<Catalog2VO.Catalog3VO> catalog3VOS = l3Catelogs.stream().map(l3 -> { Catalog2VO.Catalog3VO catalog3VO = new Catalog2VO.Catalog3VO(l3.getParentCid().toString(), l3.getCatId().toString(), l3.getName()); return catalog3VO; }).collect(Collectors.toList()); // 三级分类关联二级分类 catalog2VO.setCatalog3List(catalog3VOS); } return catalog2VO; }).collect(Collectors.toList()); } return Catalog2VOs; } )); //从数据库获取到了对应信息 然后再缓存中存储一份 cache.put("getCatelog2JSON", map); return map; }
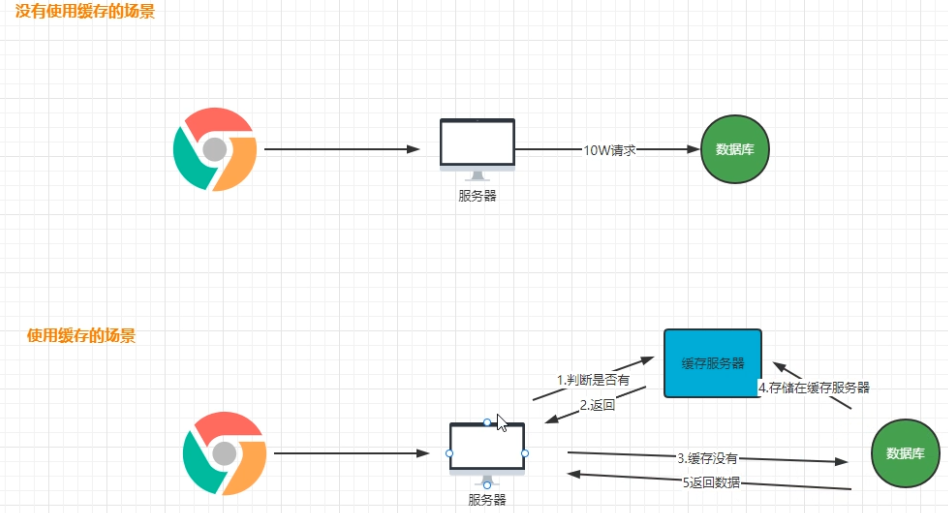
但是在分布式环境下 使用本地缓存
在前面nginx打过来的请求分配到相同服务的不同服务器上,那么会有多于的数据冗余,缓存的利用率不高
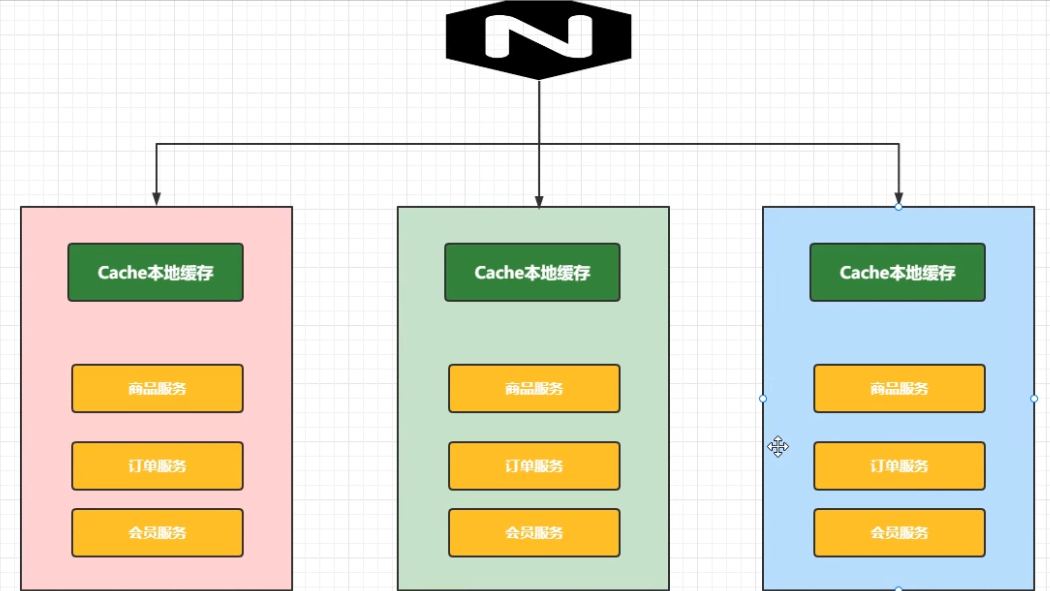
那么我么就可以使用分布式缓存
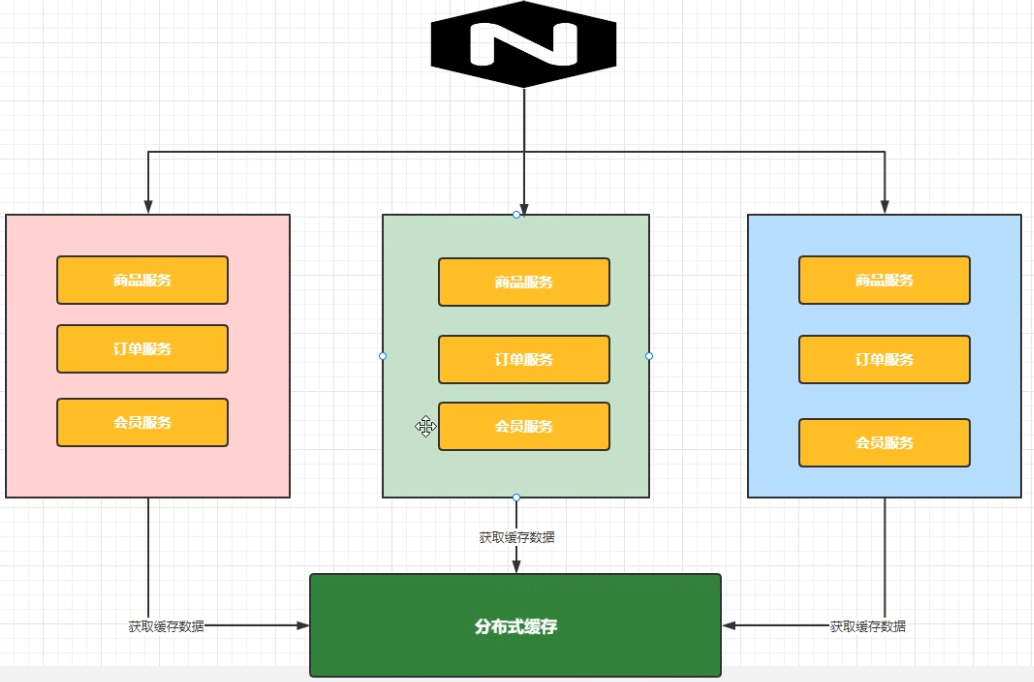
如果数据量比较多 缓存服务器可以做集群 分片 主从
当其中节点更改缓存中数据后 其他节点能及时获取到最新的更新信息 保证数据的一致性
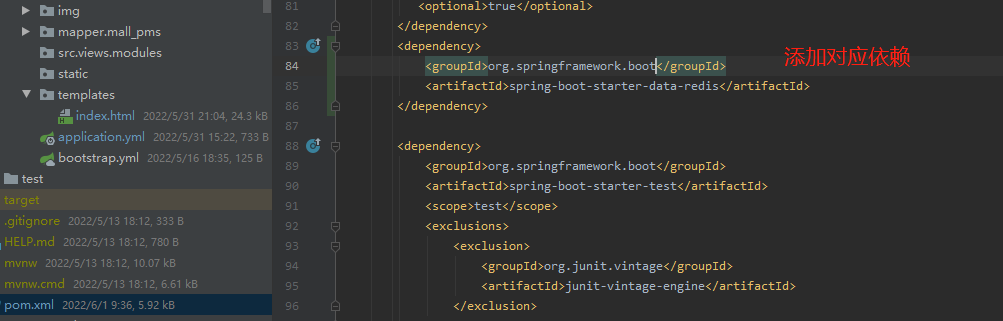
整合Redis
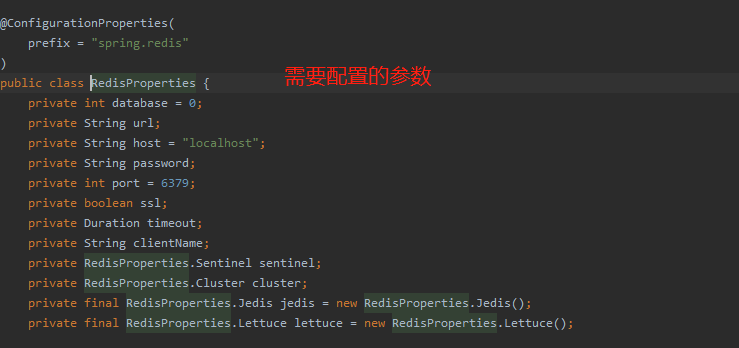
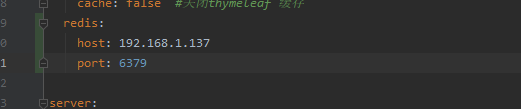
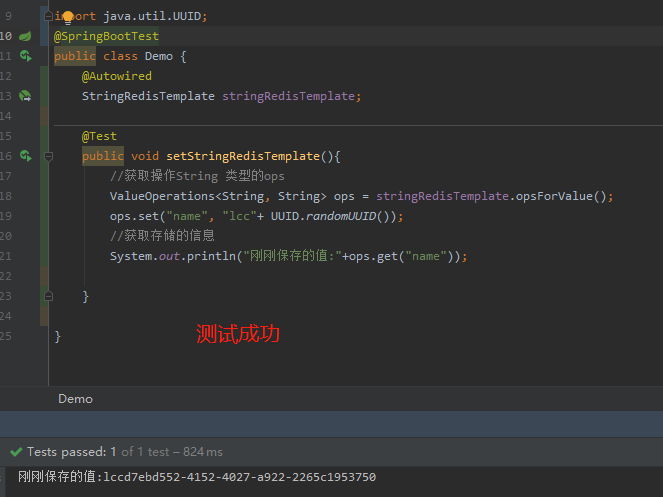
测试redis 数据
进入docker 中的redis
docker exec -it cf0 /bin/bash

验证存储成功到redis
这里 我们就可以开始优化三级分类
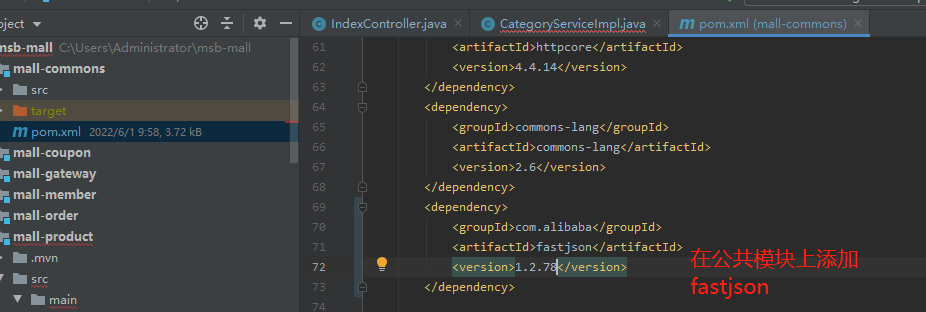
/** * 根据父编号 获取对应的子菜单信息 * @param list * @param parentCid * @return */ private List<CategoryEntity> queryByParentCid(List<CategoryEntity> list,Long parentCid){ List<CategoryEntity> collect = list.stream().filter(item -> { return item.getParentCid().equals(parentCid); }).collect(Collectors.toList()); return collect; } //本地缓存 private Map<String,Map<String,List<Catalog2VO>>> cache=new HashMap<>(); @Override public Map<String, List<Catalog2VO>> getCatelog2JSON(){ String catelogJSON = stringRedisTemplate.opsForValue().get("catelogJSON"); if(StringUtils.isEmpty(catelogJSON)){ //如果缓存中没有数据 那么就调用数据库去查询 Map<String, List<Catalog2VO>> catelog2JSONForDb = getCatelog2JSONForDb(); //从数据库中查询到的数据我们也需要给缓存存储一份 String json = JSON.toJSONString(catelog2JSONForDb);//将上面的对象转换成json数据 stringRedisTemplate.opsForValue().set("catelogJSON", json); return catelog2JSONForDb; } //表示缓存命中了数据 那么从缓存中获取信息 然后将json数据转换为对象返回 Map<String, List<Catalog2VO>> stringListMap = JSON.parseObject(catelogJSON, new TypeReference<Map<String, List<Catalog2VO>>>() { }); return stringListMap; } /** * 从数据库查询的结果 * 查询出所有的2级和三级分类 数据 并封装为json对象 * @return */ public Map<String, List<Catalog2VO>> getCatelog2JSONForDb() { if(cache.containsKey("getCatelog2JSON")){ //直接从缓存中获取 return cache.get("getCatelog2JSON"); } //获取所有数据 List<CategoryEntity> list=baseMapper.selectList(new QueryWrapper<CategoryEntity>()); // 获取所有的一级分类的数据 List<CategoryEntity> leve1Category = this.queryByParentCid(list, 0L); // 把一级分类的数据转换为Map容器 key就是一级分类的编号, value就是一级分类对应的二级分类的数据 Map<String, List<Catalog2VO>> map = leve1Category.stream().collect(Collectors.toMap( key -> key.getCatId().toString() , value -> { // 根据一级分类的编号,查询出对应的二级分类的数据 List<CategoryEntity> l2Catalogs = this.queryByParentCid(list, value.getCatId());//以一级分类的cat_id 为二级分类的parentid List<Catalog2VO> Catalog2VOs =null; if(l2Catalogs != null){ Catalog2VOs = l2Catalogs.stream().map(l2 -> { // 需要把查询出来的二级分类的数据填充到对应的Catelog2VO中 Catalog2VO catalog2VO = new Catalog2VO(l2.getParentCid().toString(), null, l2.getCatId().toString(), l2.getName()); // 根据二级分类的数据找到对应的三级分类的信息 List<CategoryEntity> l3Catelogs = this.queryByParentCid(list, l2.getCatId()); if(l3Catelogs != null){ // 获取到的二级分类对应的三级分类的数据 List<Catalog2VO.Catalog3VO> catalog3VOS = l3Catelogs.stream().map(l3 -> { Catalog2VO.Catalog3VO catalog3VO = new Catalog2VO.Catalog3VO(l3.getParentCid().toString(), l3.getCatId().toString(), l3.getName()); return catalog3VO; }).collect(Collectors.toList()); // 三级分类关联二级分类 catalog2VO.setCatalog3List(catalog3VOS); } return catalog2VO; }).collect(Collectors.toList()); } return Catalog2VOs; } )); //从数据库获取到了对应信息 然后再缓存中存储一份 cache.put("getCatelog2JSON", map); return map; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号