跳表(SkipList)原理篇
1、什么是跳表?
维基百科:跳表是一种数据结构。它使得包含n个元素的有序序列的查找和插入操作的平均时间复杂度都是 O(logn),优于数组的 O(n)复杂度。快速的查询效果是通过维护一个多层次的链表实现的,且与前一层(下面一层)链表元素的数量相比,每一层链表中的元素的数量更少。
- 优于数组的插入操作时间复杂度
简单理解跳表是基于链表实现的有序列表,跳表通过维护一个多层级的链表实现了快速查询效果将平均时间复杂度降到了O($log^n$),这是一个典型的异空间换时间数据结构。
2、为什么需要跳表?
在实际开发中经常遇到需要在数据集中查找一个指定数据的场景,而常用的支持高效查找算法的实现方式有以下几种:
-
有序数组。插入时可以先对数据排序,查询时可以采用二分查找算法降低查找操作的复杂度。缺点是插入和删除数据时,为了保持元素的有序性,需要进行大量数据的移动操作。
-
二叉查找树。既支持高效的二分查找算法,又能快速的进行插入和删除操作的数据结构,理想的时间复杂度为 O($log^n$),但是在某些极端情况下,二叉查找树有可能变成一个线性链表,即退化成链表结构。
-
平衡二叉树。基于二叉查找树的优点,对其缺点进行了优化改进,引入了平衡的概念。为了维持二叉树的平衡衍生出了多种平衡算法,根据平衡算法的不同具体实现有AVL树 /B树(B-Tree)/ B+树(B+Tree)/红黑树 等等。但是平衡算法的实现大多数比较复杂且较难理解。
针对大体量、海量数据集中查找指定数据有更好的解决方案,我们得评估时间、空间的成本和收益。
跳表同样支持对数据进行高效的查找,插入和删除数据操作时间复杂度能与平衡二叉树媲美,最重要的是跳表的实现比平衡二叉树简单几个级别。缺点就是“以空间换时间”方式存在一定数据冗余。
如果存储的数据是大对象,跳表冗余的只是指向数据的指针,几乎可以不计使用的内存空间。
3、跳表的实现原理
添加、删除操作都需要先查询出操作数据的位置,所以理解了跳表的查询原理后,剩下的只是对链表的操作。
3.1、查询数据
例设原始链表上的有序数据为【9,11,14,19,20,24,27】,如果我要查找的数据是20,只能从头结点沿着链表依次比较查找,如图所示:

链表不能像数组那样通过索引快速访问数据,只能沿着指针方向依次访问,所以不能使用二分查找算法快速进行数据查询。但是可以借鉴创建索引的这种思路,就像图书的目录一样,如果我要查看第六章的内容,直接翻到通过目录查询到的第六章对应页码处就行。
这里的目录就相当于创建的索引,该索引能够缩小我们查询数据的范围减少查询次数。在原始链表的基础上,我们增加一层索引链表,假如原始链表的每两个结点就有一个结点也在索引链表当中,如图所示:
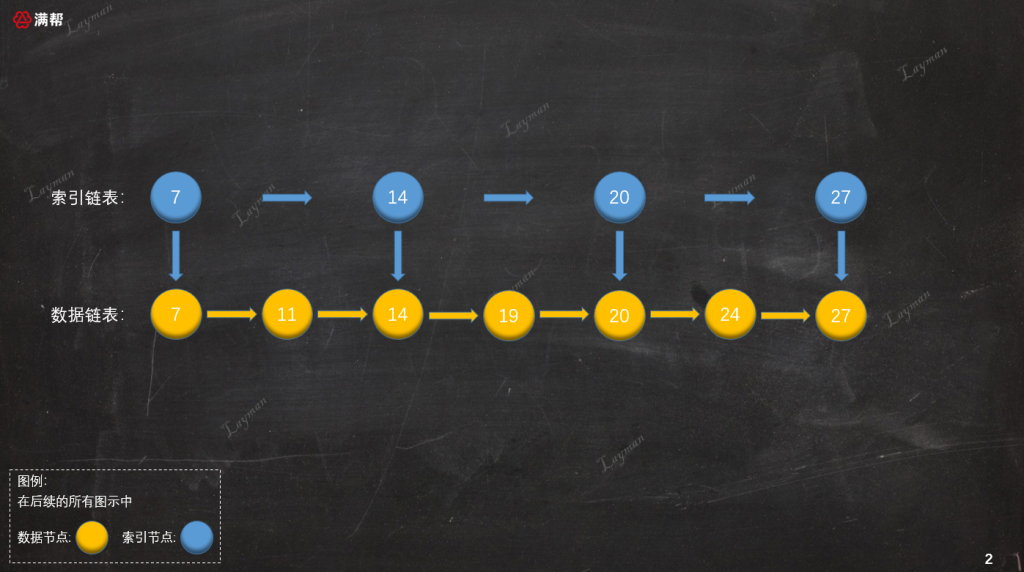
当建立了索引后检索数据的方式就发生了变化,当我们想要定位到DataNode-20,我们不需要在原始链表中一个一个结点访问,而是首先访问索引链表:
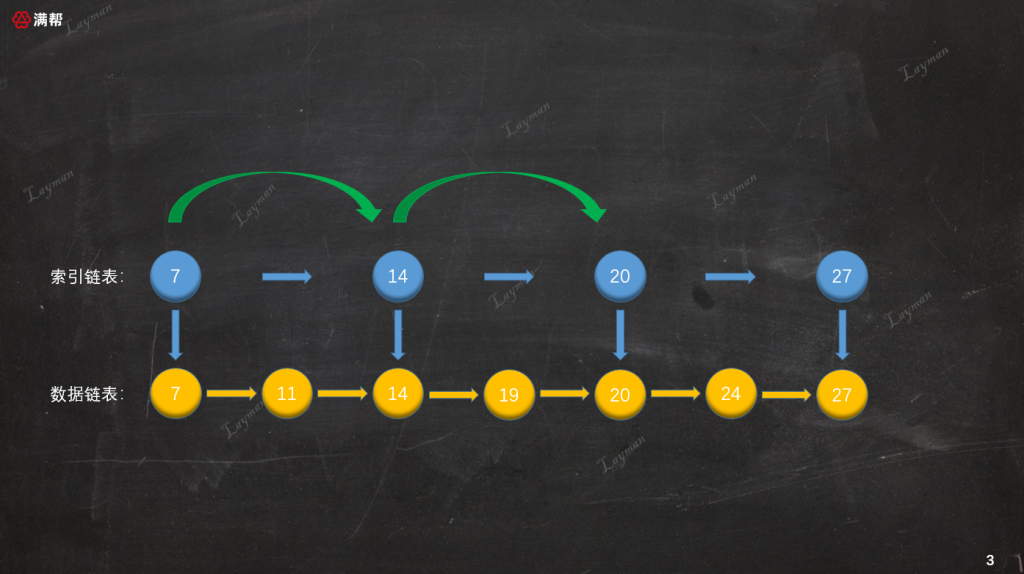
由于索引链表的结点个数是原始链表的一半,查找结点所需的访问次数也就相应减少了一半,经过两次查询我们便找到DataNode-20。
正如图书的目录不止按照“章节”划分,还可以按照“第几部分”、“第几小节”进行划分,链表的索引也一样。我们可以继续为链表创建更多层索引,每层索引节点为前一层索引(对应图例的下一层)的一半,在数据量比较大时能够大大的提升我们的查询效率。
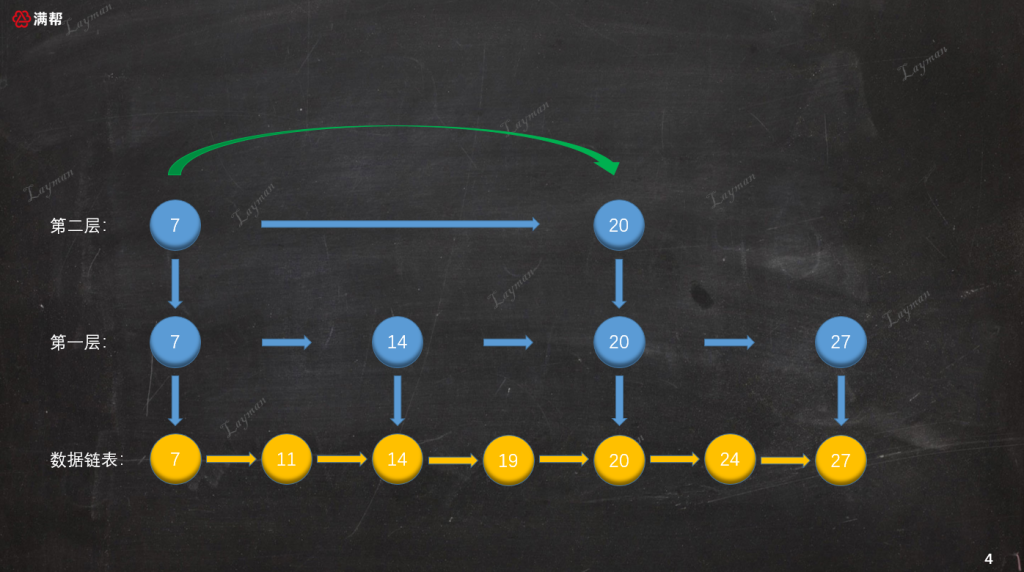
如图所示,我们基于原始链表的第1层索引,抽出了第2层更为稀疏的索引,结点数量是第1层索引的一半。这样的多层索引可以进一步提升查询效率,那么它是如何进行查询的呢?假如这次要查找DataNode-27,让我们来演示一下检索过程:
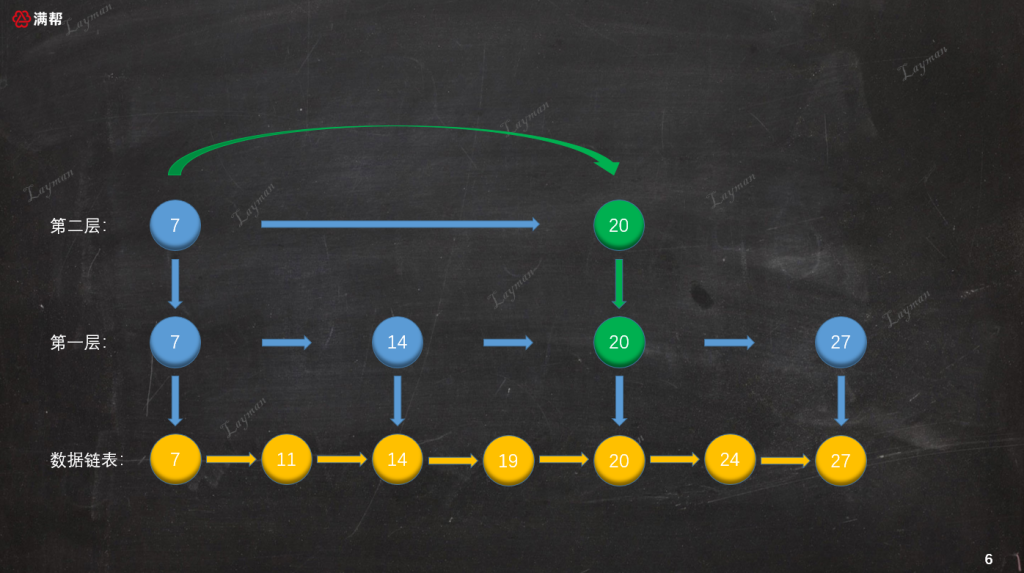
- 首先,我们从最上层(第二层)的
HeadIndex-7开始查找,HeadIndex-7指向DataNode-7比DataNode-27小,所以继续向右查询找到第二个索引节点IndexNode-20。
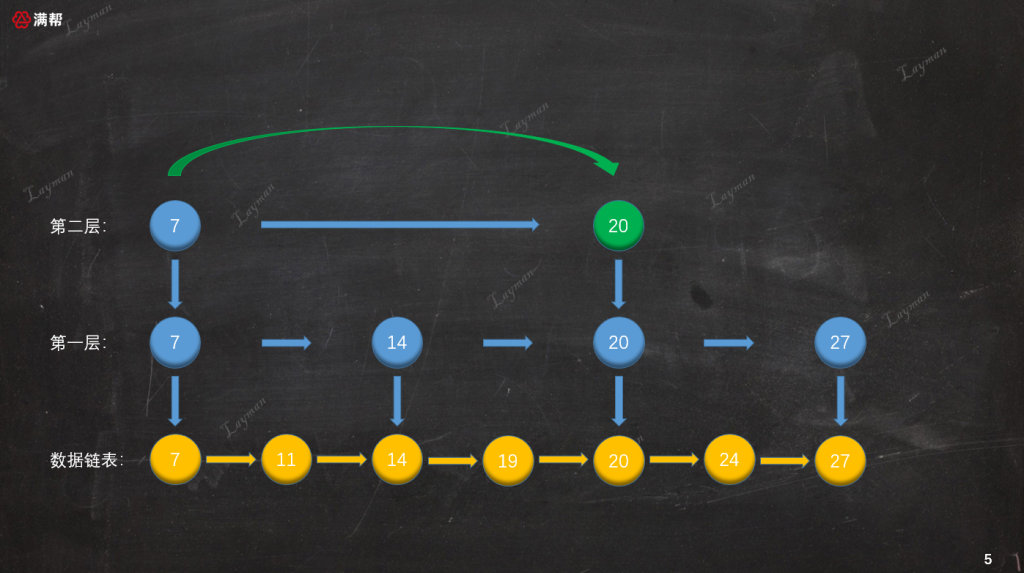
IndexNode-20指向DataNode-20也比DataNode-27小,但是此时第二层已经没有后续的索引节点,所以我们需要顺着IndexNode-20访问下一层索引,即第一层的IndexNode-20。
从索引节点访问方式可知,索引节点保存着“数据节点”、“下层索引节点”的指针。
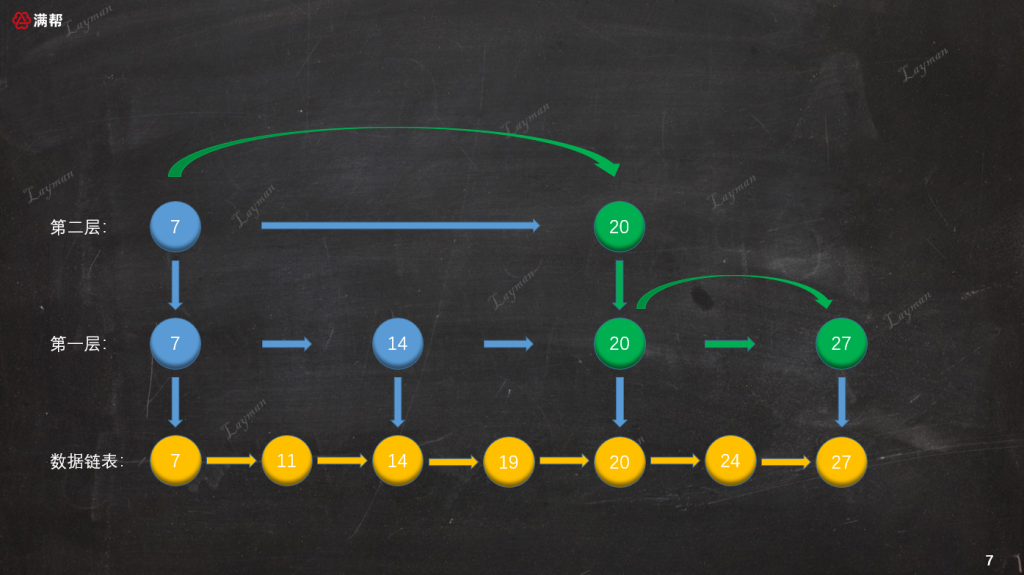
- 通过第一层的
IndexNode-20继续向右检索找到IndexNode-27便检索到了DataNode-27。
总结:
维基百科:
跳跃列表是按层建造的。底层是一个普通的有序链表。每个更高层都充当下面列表的“快速通道”,这里在第 i 层中的元素按某个固定的概率 $p$(通常为 $\frac 12$ 或 $\frac 14$ 出现在第 i + 1 层中。每个元素平均出现在 ${1\over 1-p}$ 个列表中,而最高层的元素(通常是在跳跃列表前端的一个特殊的头元素)在 $log_{1/p}^n$个列表中出现。在查找目标元素时,从顶层列表、头元素起步。算法沿着每层链表搜索,直至找到一个大于或等于目标的元素,或者到达当前层列表末尾。如果该元素等于目标元素,则表明该元素已被找到;如果该元素大于目标元素或已到达链表末尾,则退回到当前层的上一个元素,然后转入下一层进行搜索。每层链表中预期的查找步数最多为$\frac 1p$,而层数为 -${log_p^n}\over{p}$,由于 $p$ 是常数,查找操作总体的时间复杂度为 O($log^n$)。而通过选择不同 $p$ 值,就可以在查找代价和存储代价之间获取平衡。
上面的查询例子中索引节点已经是创建好的,那么原始链表哪些数据节点需要创建索引节点、什么时候创建?这些问题的答案都要回归到往原始链表添加数据时。
3.2、插入数据
从上面的总结不难理解在向原始链表中插入数据时,当前插入的数据按照某个固定的概率$p$($\frac 12$ 或 $\frac 14$)在每层索引链表中创建索引节点。假设现在插入DataNode-18,我们来看看是如何插入和创建索引节点的:
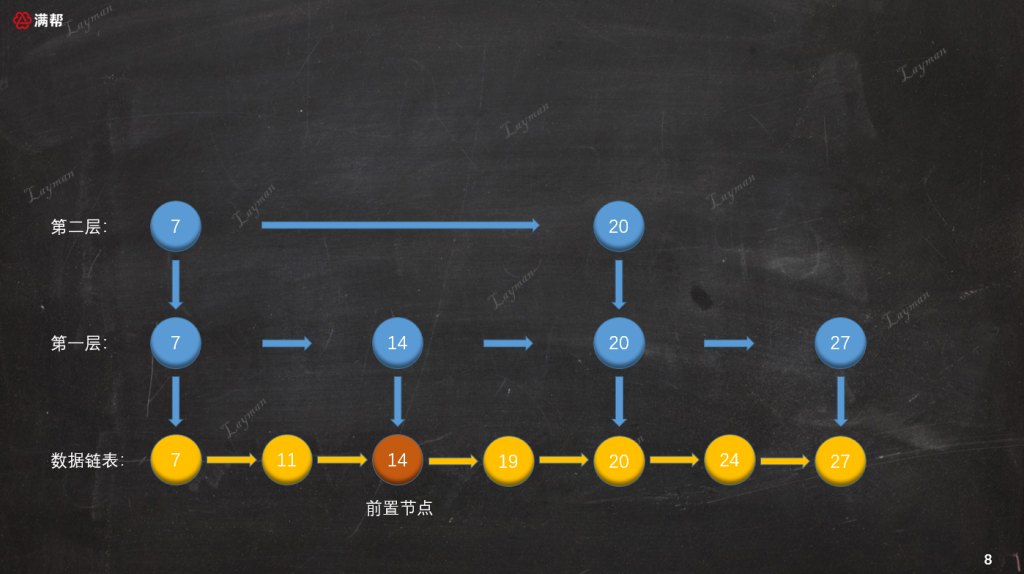
3.2.1、找到插入数据的前置节点
首先我们按照跳表查找结点的方法,找到待插入结点的前置结点(仅小于待插入结点):
3.2.2、插入原始链表
接下来按照一般链表的插入方式,把DataNode-18插入到结点DataNode-14的后续位置:
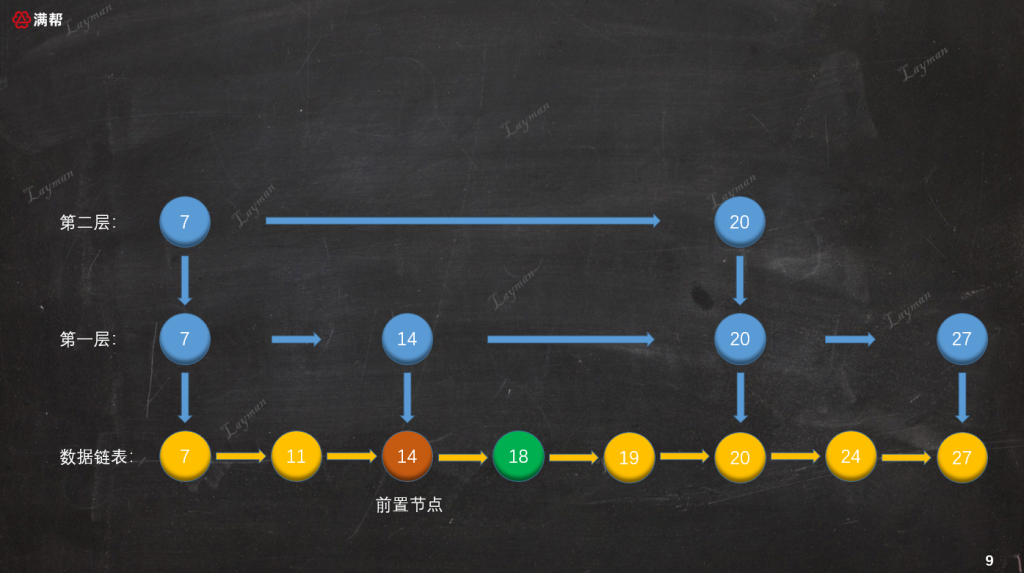
这样数据就插入到了原始链表中,但是我们的插入操作并没有结束。按照定义我们需要让新插入的结点随机(抛硬币的方式)“晋升”,也就是为DataNode-18创建索引节点,正是采取这种简单的随机方式,跳表也被称为一种随机化的数据结构。
3.2.3、创建索引节点
假设第一、第二次随机的结果都是晋升成功,那么我们需要为DataNode-18创建索引节点,插入到第一层和第二层索引的对应位置,并且向下指向原始链表的DataNode-18。
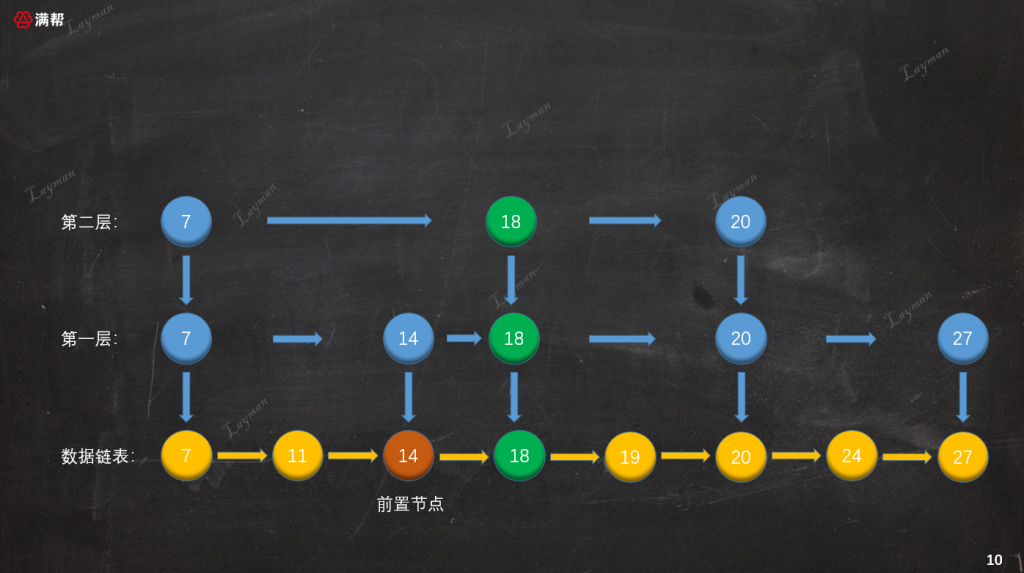
在索引链表中插入新创建的索引节点时需要注意几点:
- 找到待插入索引节点的前置索引节点指向新索引节点,新索引节点指向前置节点之前指向的索引节点。(也就是链表的插入操作)
- 随机的结果是“晋升成功”就可以继续向上一层创建索引,直到假设随机的结果是“晋升失败”或者“新增索引层”。
- 每层是否创建索引节点可以一次性抛几次硬币,而不是添加一层索引后再进行投币。(这样做的目的是为了更好的用代码实现)。
新建的索引节点何如衔接到前置索引节点以及如何用代码实现,这个我们在下篇文章“SkipList 代码实现”去解析。
3.2.4、添加索引层
如果在第二层(目前索引最大层级)创建索引节点后,下一次随机的结果仍然是晋升成功,这时候该怎么办呢?这个时候我们就需要添加一层索引层:
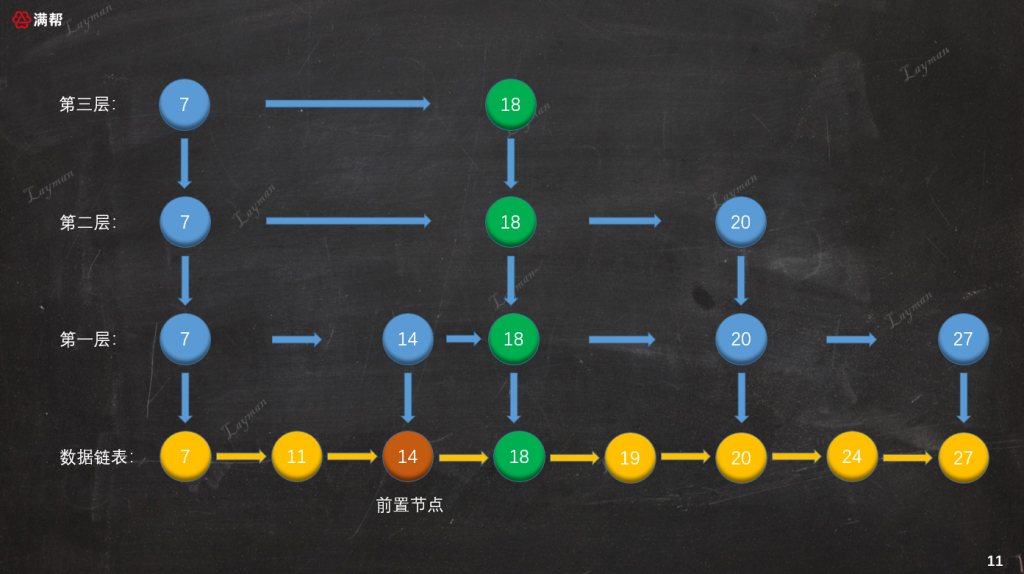
可以看到此时第三层只有HeadIndex-7和IndexNode-18,此时不会继续向上层创建索引,因为就算继续创建仍只有HeadIndex-7和IndexNode-18,这显得毫无意义。至此跳表的插入操作包括索引的创建过程已经解析完,跳表的删除过程正好和插入是相反的思路。
3.3、删除数据
3.3.1、查找待删除节点
假设我们要删除刚才插入的DataNode-18,首先我们要按照跳表查找结点的方法找到待删除的DataNode-18,当然如果没有找到对应的数据直接返回进行。
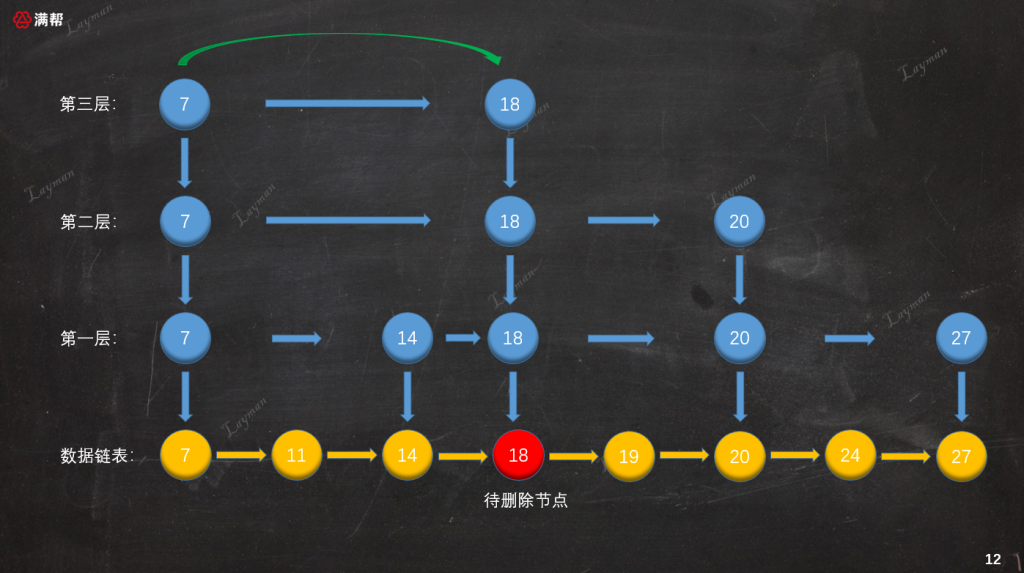
3.3.2、删除原始链表节点
接下来按照链表的删除方式,把DataNode-18从原始链表当中删除
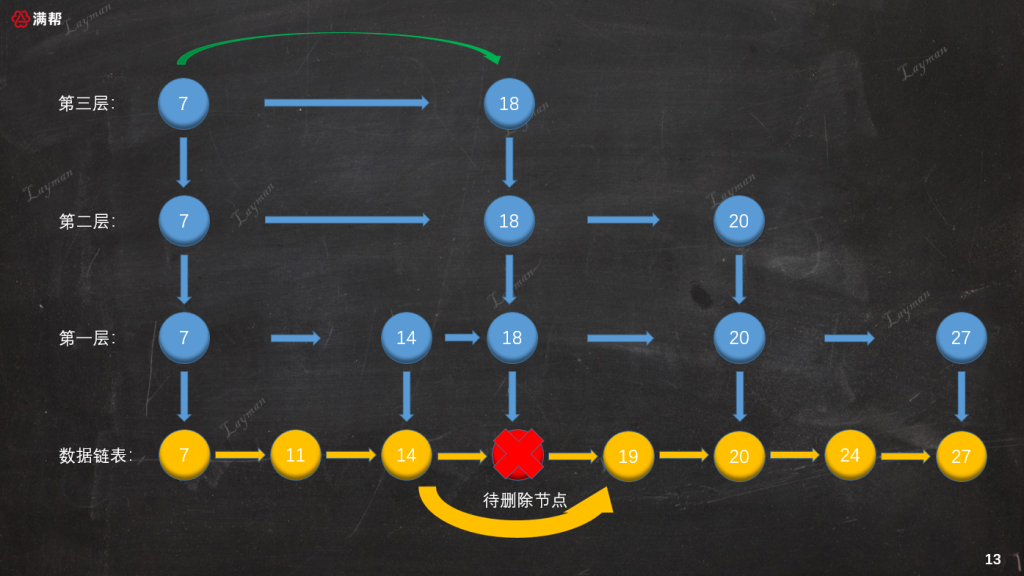
3.3.3、删除索引节点
同插入数据一样,删除工作并没有就此完成,我们需要将DataNode-18在索引层对应的IndexNode-18也一 一删除:
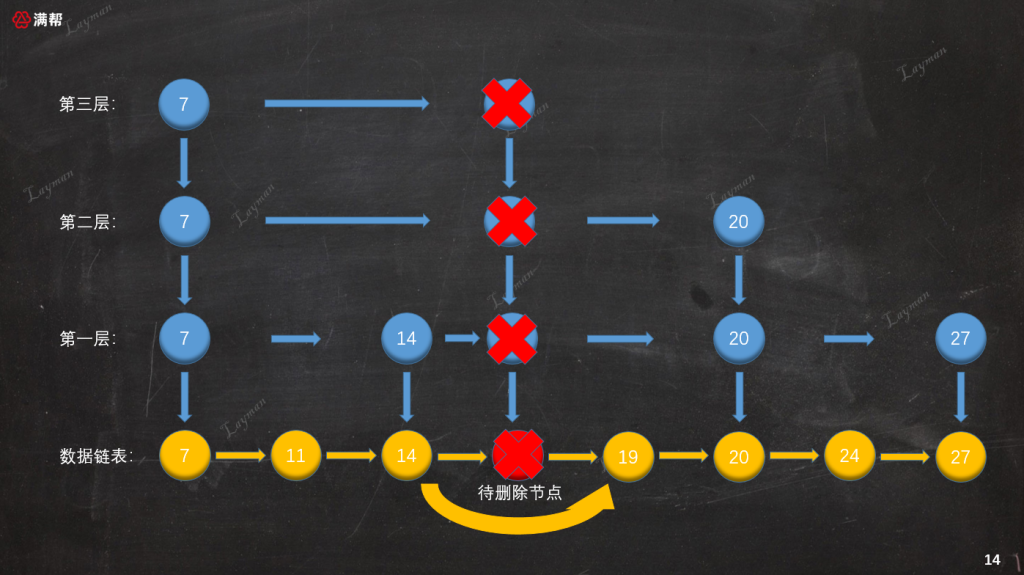
3.3.4、删除索引层
同插入索引节点一样,删除索引节点时也需要维护前置节点的指向关系。这里需要特别注意最上层索引(第三层),当删除IndexNode-18后该层只剩下HeadIndex-7,这个时候需要将该索引层也一同删除。
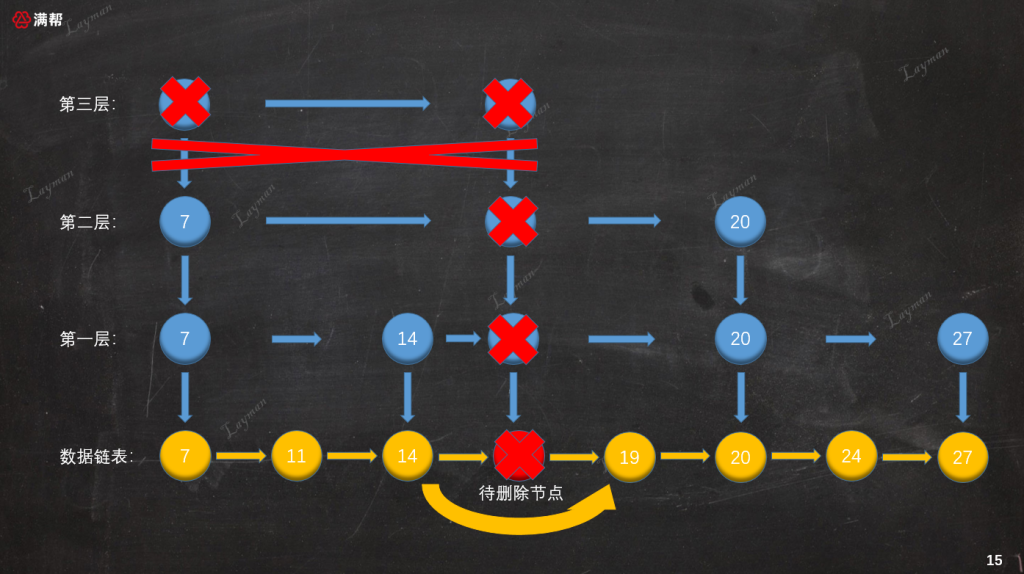
至此整个删除操作就算完成了,此时跳表的结构就和我们之前插入之前保持一致了:
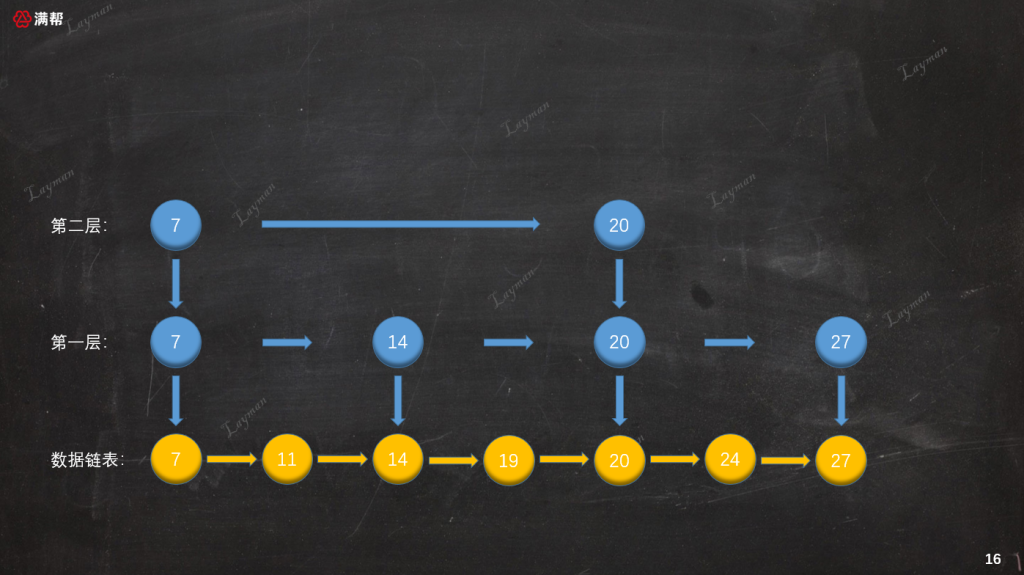
总结
- 简单对比了跳表和其他几种高效查找算法的优缺点。
- 跳表是基于链表实现的,是一种“以空间换时间”的“随机化”数据结构。
- 跳表引入了索引层的概念,有了它才有了时间复杂度为O($logn$)的查询效率,从而实现了增删操作的时间复杂度也是O($logn$)。
- 跳表拥有平衡二叉树相同的查询效率,但是跳表对于树平衡的实现是基于一种随机化的算法的,相对于AVL树/B树(B-Tree)/B+树(B+Tree)/红黑树的实现简单得多。
跳表的检索、插入、删除的原理篇就解析到这里,下篇将分析SkipList数据结构的代码实现,to be expected !!!
可耻的贴个个人Git地址:SkipList原理篇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号