
Shader性能优化
Shader通用优化规则
如果顶点上的计算需要在模型本地空间下进行,则需要开启,因为合批后所有模型合在一起,shader所拿到的模型本地空间会变
有两种写法GrabPass{"_GrabTex"}sample2D _GrabTex;或GrabPass{}sample2D _GrabTexture;
后者_GrabTexture是默认的写法,前者是指定贴图名称
单帧中:后者会在每个GrabPass调用时生成一个新的_GrabTexture,若没有这样需求,请使用特定命名的写法,这样一帧只会生成一帧
变体优化
变体会占用很大的内存,所以减少不需要的变体是很好的性能优化方案
变体怎么来的
为了让某shader出现不同的分支而设置的,一类分支就会拥有若干个变体
举个例子
#pragma multi_compile X Y Z
此时就会有X Y Z三个变体

倘若再加一类 #pragma multi_compile A B C

此时就会有3*3个变体

很恐怖兄弟,你再来一类就是3*3*3,指数级增加
引用官方变体
例如#pragma multi_compile_fog
此时就会有四个变体,如果不用其中的EXP2变体
可以通过#pragma skip_variants FOG_EXP2来剔除
shader_feature
这个会根据该材质球去开关变体,不会全出现变体,适用场景是特效制作时,只对某一特效开关某些变体时使用。
而multi_compile是必定全打包成变体,适用场景是游戏运行中不得不进行变体切换时才用。
因此尽量少用multi_compile
变体收集器
作用:
Shader如果去动态加载变体,会卡顿那么一下
因此需要在游戏开始时统一把所有变体都加载好,即 用空间换时间
创建:
右键-Shader-最下方
需要提供目标shader
ProjectSettings-Graphics:
可以去掉延迟渲染Pass,延迟反射渲染Pass等等
可以调整Unity内置变体
ShaderModel
Shader会用到很多GPU的指令,但不同厂家去设计时,底层指令究竟怎么设计一直没有一个统一的标准
因此微软提出ShaderModel这一概念,要求显卡厂商按SM级别提供对应的功能和指令支持
不同的SM包含不同的指令集和Shader规范
高版本的SM是低版本的超合集
微软官方有详细的SM
使用方法
#pragma target 2.5
这样,该Pass就只会使用2.5版本的指令集
详情:

如果想单独使用某一指令集也是可以的

然后在shader中,我们也是可以区分target的
SHADER_TARGET

如果版本小于等于2.0,就返回0,否则返回1
编译平台
#pragma only_renderers XXX,默认一个平台都不编译,仅编译跟在后面的
#pragma exclude_renderers XXX,默认全平台编译,不编译跟在后面的

可以通过Compile按钮查看编译后的代码
仅编译某几个平台时,体量会小很多,性能会高很多
GPU逻辑管线
深入GPU硬件架构及运行机制 - 0向往0 - 博客园 (cnblogs.com)
不愿意看的话
就是少用if判断,不用循环
一半计算单元算True的部分,一半计算单元算False的部分
因此最大可能会降低一半的性能
各种寄存器,缓存,计算单元
顶点做完光栅化,然后片段,最后帧缓存
还有Early-z技术
指令优化
主要是针对编译后的代码进行优化
阅读编译后的代码,对运算次数进行优化
举个简单例子,下方就是一个简单的贴图采样
源Shader
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
//#pragma only_renderers XXX
//#pragma exclude_renderers XXX
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
};
sampler2D _MainTex;
float4 _MainTex_ST;
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
// sample the texture
fixed4 col = tex2D(_MainTex, i.uv);
return col;
}
ENDCG编译后的就不展示了

顶点着色器部分有9个计算,使用了两个寄存器
这里的寄存器会自动分配至少两个
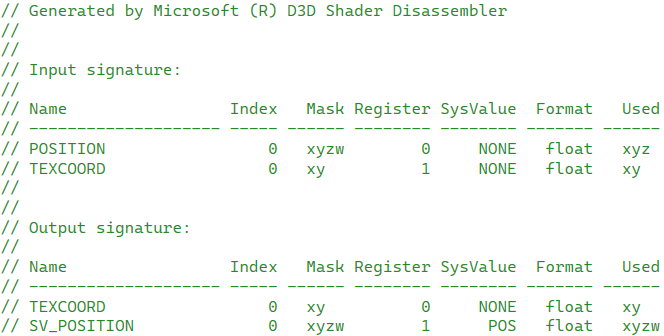
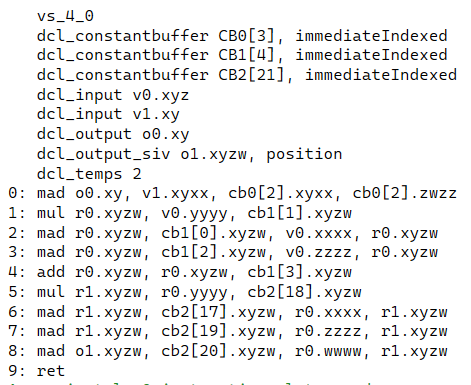
这是编译后出现的,是告诉开发者我顶点着色器的输入输出是什么,当然也有详细的计算
片段着色器0个计算,且引用了一张贴图
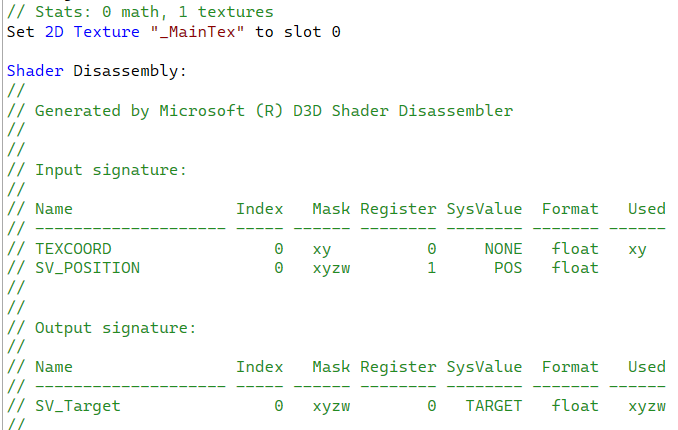
dcl_output就是最终输出颜色,这里使用sample进行了赋值
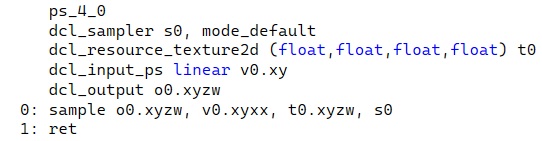
因此,优化方向就是优化编译后的代码
1.优化计算
而优化内容就是下面,优化计算步骤,要勤用 乘加 dset = A * B + C

例子:res=(a+b)*(a-b)
编译后就是三条指令
add r.x a b
add r.y a -b
mul res r.x r.y
优化成:res=a*a+(-b*b)
mul r.x b b
mad res a a r.x
看,用到的寄存器少了,用到了的指令也少了,换算成像素就是优化了1920*1080次计算+1920*1080/4个寄存器内存大小
2.优化判断
可以写if else 但不要在分支中写太多东西,类似step这样的只有一条计算的会更好
3.优化for循环
别用
4.normalize(a)
rsqrt(dot(a,a))*a
rsqrt是倒数平方根1/a*a
5.abs
如果abs是作为输入修饰符的话,那么就是免费的,如果是作为输出修饰符的话,就是收费的
例子:res=abs(a*b)
编译后就是两条指令
mul r.x a b
mov res |r.x|
优化成:res=abs(a)*abs(b)
编译后就是一条指令
mul res |a| |b|
寄存器少了,指令也少了
6.负号
和abs一样,输入免费,输出收费
因此要尽量写在数字前
res = -dot(a,b)
=>
res = dot(a,-b)
6.多维度相乘
尽量把同一纬度的进行运算
三维*一维*一维*三维*一维*一维
会有9条指令
优化成
a=三维*三维
b=一维*一维*一维*一维
会有3条指令
7.反三角函数别用asin/acos/atan
开销巨大
优化的前提是功能正确
合批Batching
动态合批
规则:
材质相同,材质实例无法合批
支持不同网格的合批
单个网格最多300个顶点,900个顶点属性
如果Shader中用到了Position、Normal、uv的话,则最多300个顶点
如果Shader中用到了Position、Normal、uv0、uv1、tangent的话,则最多180个顶点
Scale有镜像时无法合批,例如(-1,1,1)、(-1,-1,-1)可以合批
静态合批
通常和Lightmap一起使用
规则:
材质相同
倘若需要同材质球,不同贴图,则需要用到图集
物体Static中,勾选BatchingStatic
网格顶点数上限为2^16个,运行了自动变成一个网格
缺点:
包体会增大,解决办法就是在fbx导出时就进行合并
内存会增大,暂无解决办法
GPU实例化
适用场景:大量生成同一个网格时使用,例如树、草地,使他们的批次减少
简略版:

规则:
硬件支持:OpenGL-ES 3.0、GPU
美术支持:Shader、网格
脚本支持:让每个对象都有不同的呈现
Shader
第一步 数据准备
需要启用变体 #pragma multi_compile_instancing
需要在顶点数据和片段数据中加 UNITY_VERTEX_INPUT_INSTANCE_ID
来源:

而DEFAULT_UNITY_VERTEX_INPUT_INSTANCE_ID来源于对UNITY_INSTANCING_ENABLED的判断
倘若开启了GPUInstance or PROCEDURAL or STEREO变体,就去定义DEFAULT_UNITY_VERTEX_INPUT_INSTANCE_ID
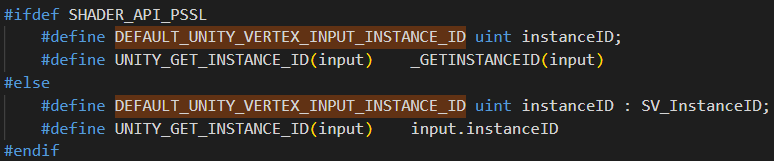
否则就定义为空
而UNITY_INSTANCING_ENABLED的定义来自于平台的判断


所以大费周章就是进行了平台的判断
最后定义为uint instanceID : SV_InstanceID;
uint:无符号整数 0~2^32
第二步 根据数据计算最终值
在顶点和片段中使用函数UNITY_SETUP_INSTANCE_ID(struct value)
value必须包含instanceID
原理:
在GameObject.Instantiate()阶段,就会创建一个unity_InstanceID,并存储该ID物体的矩阵等数据,后续可根据ID直接拿到矩阵等数据
然后就是显示阶段,通过各种平台分支、方式分支,拿到该物体的unity_InstanceID


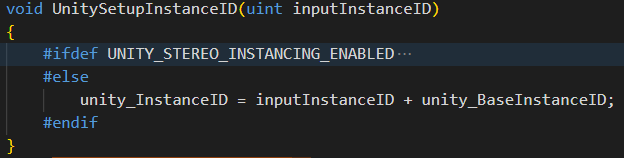
扩展:
目标:我能否将每个物体染上不同的颜色,并保持他们还是同一批次呢
理论:既然unity能根据unity_InstanceID存储不同的unity_MatrixVP,那是不是可以根据不同的unity_InstanceID存储不同的color
实践:
1.和上面一样,准备数据
2.计算值,并赋值,在前面,我们比并没有使用到片段着色器中的UNITY_SETUP_INSTANCE_ID(i),但现在我们需要了
3.创建寄存器
4.使用寄存器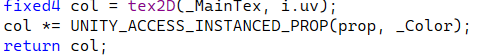
5.为寄存器赋值,需要用程序,用MeshRenderer.material或是.sharedMaterial都是不行的,前者是new一个材质,后者是只针对单个材质
因此需要特殊的MaterialPropertyBlock
查看代码
void Start()
{
Vector3 pos = new Vector3();
GameObject go;
for (int i = 0; i < count; i++)
{
pos.x = i / 10;
pos.z = i % 10;
go = GameObject.Instantiate<GameObject>(instance, pos, Quaternion.identity);
Color color = new Color(Random.value, Random.value, Random.value, 1);
MaterialPropertyBlock block = new MaterialPropertyBlock();
block.SetColor("_Color", color);
go.GetComponent<MeshRenderer>().SetPropertyBlock(block);
}
}6.Shader的具体代码,属性中需要_Color
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float2 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
sampler2D _MainTex;
float4 _MainTex_ST;
UNITY_INSTANCING_BUFFER_START(prop)
UNITY_DEFINE_INSTANCED_PROP(fixed4, _Color)
UNITY_INSTANCING_BUFFER_END(prop)
v2f vert (appdata v)
{
UNITY_SETUP_INSTANCE_ID(v);
v2f o;
UNITY_TRANSFER_INSTANCE_ID(v, o);
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
UNITY_SETUP_INSTANCE_ID(i);
// sample the texture
fixed4 col = tex2D(_MainTex, i.uv);
col *= UNITY_ACCESS_INSTANCED_PROP(prop, _Color);
return col;
}
ENDCG
}
启用变体Enable GPU Instancing 结果:
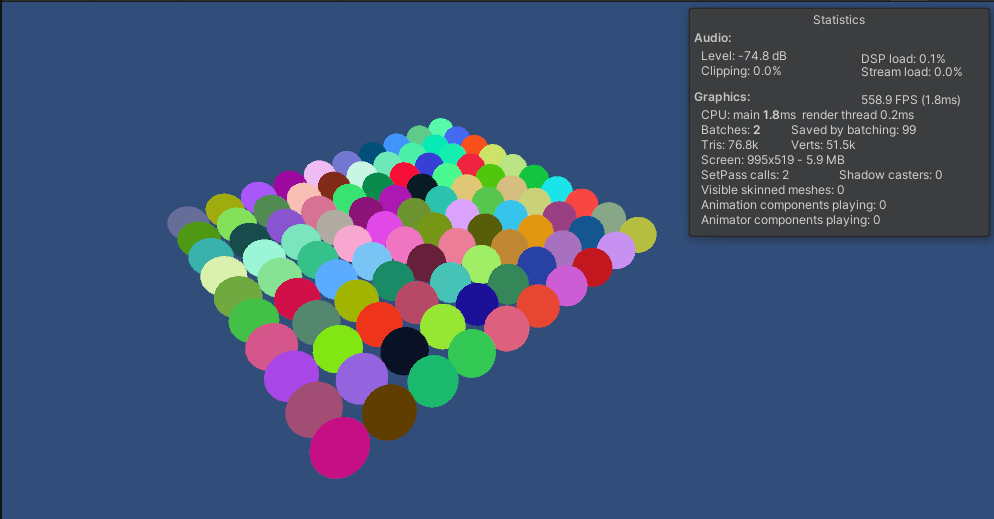
逻辑:
1.生成物体,存储数据
Start中生成物体,同时显存中记录Map<unity_InstanceID,unity_Matrix>(),也可能是表
使用MaterialPropertyBlock赋予颜色,同时将颜色存起来,存储方式为:
生成一个叫UnityInstancing_XXX的表,键是自动累加的unity_InstanceID,值是颜色数据
第一个会申请寄存器,取名为UnityInstancing_XXX,并生成当前unity_InstanceID表
第二个会读取UnityInstancing_XXX寄存器,并生成当前unity_InstanceID表
此时矩阵存在于显存A区域,颜色数据存在于显存B区域
2.渲染物体,读取数据
然后来到顶点数据准备区域,UNITY_VERTEX_INPUT_INSTANCE_ID=>uint instanceID : SV_InstanceID;
SV_InstanceID就是由系统提供的InstanceID,当他加上unity_BaseInstanceID就是unity_InstanceID了
顶点着色时,由于开启了GPUInstance,所有物体读取的都是同一个变换矩阵
因此需要在渲染时,根据当前的InstanceID去读取变换矩阵
使用UNITY_SETUP_INSTANCE_ID(v);去修改当前unity_InstanceID,因此在读取矩阵时就是目标矩阵了
然后我们再通过UNITY_TRANSFER_INSTANCE_ID(v, o);将instanceID传递给片段着色器(因为片段着色器的instanceID不是来自于系统,而是来自于顶点着色器)
片段着色时,由于材质的默认性质,所有的物体都会去读取同一个颜色
因此需要在渲染时,根据当前的instanceID去读取颜色
使用UNITY_SETUP_INSTANCE_ID(i);去修改当前的全局unity_InstanceID(不写这个就是颜色会变同一个,但位置是正确的)
使用UNITY_ACCESS_INSTANCED_PROP(prop, _Color);去读取目标颜色
3.结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号