NLP_1 —— 什么是embedding
NLP_1 —— 什么是embedding
Bag of Words (BoW)
BoW 是一种将句子拆解成每个词出现次数的方法,例如我将以下两个句子拆解:
I like apple.
{"I": 1, "like": 1, "apple": 1}
I like mango.
{"I": 1, "like": 1, "mango": 1}
这方法乍看之下分析出了句子的组成,但是却忽略掉了很重要的次序关係,会使得以下两句的结果完全相同。
I like apple, but I don't like mango.
I like mango, but I don't like apple.
Word Embedding
Word Embedding 的概念是建立字词向量(Word Vector),例如我定义一个向量的每个维度对应到什么字,并且将句子中每个字转换为向量,最后结合起来变成矩阵。
["I", "like", "apple", "mango"]
I => [1, 0, 0, 0]
like => [0, 1, 0, 0]
apple => [0, 0, 1, 0]
mango => [0, 0, 0, 1]
"I like apple" =>
[[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0]]
"I like mango" =>
[[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 0, 1]]
如此一来不仅可以保留句子中字词的顺序,使 BoW 范例中两个语意相反的句子有不同的呈现,且改变为适合电脑运算的矩阵形式,但产生了新的问题是“当字词过多时每个字的向量会太长,句子转换的矩阵亦会更加庞大,且这矩阵中有大量的栏位皆为 0”。 这么一来使得电脑多了许多额外的运算及储存成本,而且整体的效率十分低,后来有了更好的方法。
Word2vec
Word2vec,就是词嵌入( word embedding) 的一种。
我在前作『都是套路: 从上帝视角看透时间序列和数据挖掘』提到,大部分的有监督机器学习模型,都可以归结为:
\[f(x) \rightarrow y \]在 NLP 中,把 x 看做一个句子里的一个词语,y 是这个词语的上下文词语,那么这里的 f,便是 NLP 中经常出现的『语言模型』(language model),这个模型的目的,就是判断 (x,y) 这个样本,是否符合自然语言的法则,更通俗点说就是:词语x和词语y放在一起,是不是人话。
Word2vec 正是来源于这个思想,但它的最终目的,不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量(这里看不懂没关系,下一节我们详细剖析)。
我们来看个例子,如何用 Word2vec 寻找相似词:
- 对于一句话:『她们 夸 吴彦祖 帅 到 没朋友』,如果输入 x 是『吴彦祖』,那么 y 可以是『她们』、『夸』、『帅』、『没朋友』这些词
- 现有另一句话:『她们 夸 我 帅 到 没朋友』,如果输入 x 是『我』,那么不难发现,这里的上下文 y 跟上面一句话一样
- 从而 f(吴彦祖) = f(我) = y,所以大数据告诉我们:我 = 吴彦祖(完美的结论)
Skip-gram 和 CBOW 模型
上面我们提到了语言模型
- 如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型』
- 而如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』
CBOW 模型的全称为:continuous bag-of-words。
现在,我们只需要理解Skip-gram和CBOW的一种简单情况就可以接触到 word2vec 的本质,
上面说到, y 是 x 的上下文,所以 y 只取上下文里一个词语的时候,语言模型就变成:
用当前词 x 预测它的下一个词 y
但如上面所说,一般的数学模型只接受数值型输入,那么我们需要一种方法将文字以数学的形式输入。显然不能用 Word2vec,因为这是我们训练完模型的产物,现在我们想要的是 x 的一个原始输入形式。
答案是:one-hot encoder
所谓 one-hot encoder,其思想跟特征工程里处理类别变量的 one-hot 一样。本质上是用一个只含一个 1、其他都是 0 的向量来唯一表示词语。也就是前文中 word embedding 部分的解释。通过向量来独特的表示每个元素。
接下来就可以看看 Skip-gram 的网络结构了,x 就是上面提到的 one-hot encoder 形式的输入,y 是在这 V 个词上输出的概率,我们希望跟真实的 y 的 one-hot encoder 一样。
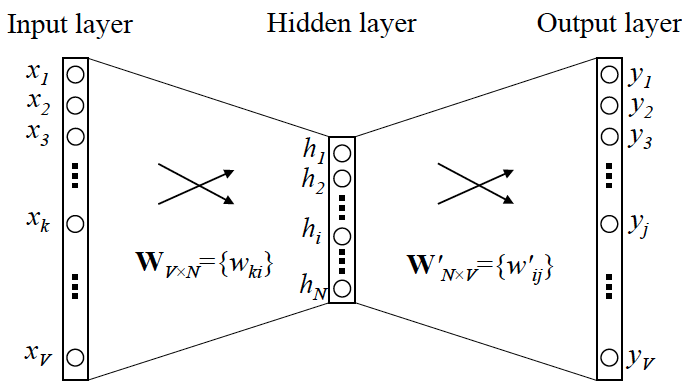
首先说明一点:隐层的激活函数其实是线性的,相当于没做任何处理(这也是 Word2vec 简化之前语言模型的独到之处),我们要训练这个神经网络,用反向传播算法,本质上是链式求导,在此不展开说明了,
当模型训练完后,最后得到的其实是神经网络的权重,比如现在输入一个 x 的 one-hot encoder: [1,0,0,…,0],对应刚说的那个词语『吴彦祖』,则在输入层到隐含层的权重里,只有对应 1 这个位置的权重被激活,这些权重的个数,跟隐含层节点数是一致的,从而这些权重组成一个向量 vx 来表示x,而因为每个词语的 one-hot encoder 里面 1 的位置是不同的,所以,这个向量 vx 就可以用来唯一表示 x。
注意:上面这段话说的就是 Word2vec 的精髓!! 相当于用 hidden layer 学习后的中间参数来用更少的空间表示词。
此外,我们刚说了,输出 y 也是用 V 个节点表示的,对应V个词语,所以其实,我们把输出节点置成 [1,0,0,…,0],它也能表示『吴彦祖』这个单词,但是激活的是隐含层到输出层的权重,这些权重的个数,跟隐含层一样,也可以组成一个向量 vy,跟上面提到的 vx 维度一样,并且可以看做是词语『吴彦祖』的另一种词向量。而这两种词向量 vx 和 vy,正是 Mikolov 在论文里所提到的,『输入向量』和『输出向量』,一般我们用『输入向量』。
需要提到一点的是,这个词向量的维度(与隐含层节点数一致)一般情况下要远远小于词语总数 V 的大小,所以 Word2vec 本质上是一种降维操作——把词语从 one-hot encoder 形式的表示降维到 Word2vec 形式的表示。
依照 stanfordnlp/GloVe 预先训练好的 word vector 中,可以用 300 维的向量来表示两百二十万个字词,可以有效解决上述的维度爆炸问题,节省了大量的运算及储存成本。
