Spring 事务扩展及分布式事务可见性问题
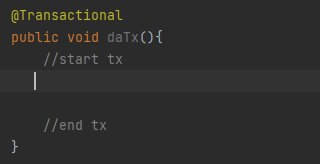
大家注意点,这个@Transactional其实在两种情况下会失效的:
第一种就是:
在方法内调用的时候,因为它没有经过Bean的代理,所以它没办法依赖Spring 的AOP增强去进行事务的控制
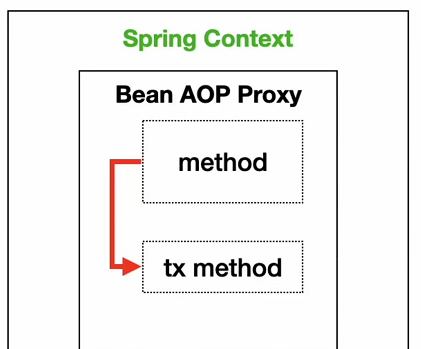
第二种就是:
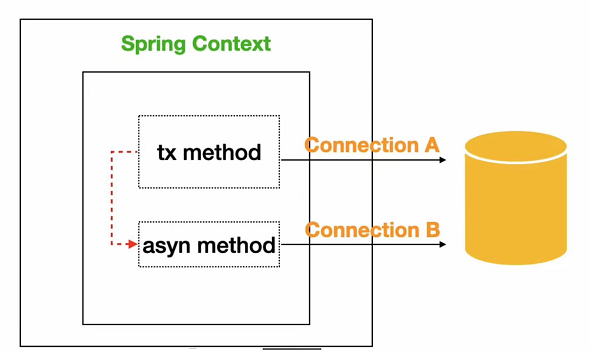
你在这个方面里面起了个异步线程,如果里面有事务处理,这种东西没办法用事务去保证的,异步线程拿到了连接和主线程,它拿到了连接肯定不是同一个,所以只有当一个数据库同一个连接,你才能去做事务控制。这种异步线程的情况,在Spring里面的事务是不支持的
第二个我想强调一点,关于分布式事务的
就是我们在很多场景下,可能有分布式事务问题,但是由于各种历史原因或者引入的成本太高或者这个场景本身对一致性的要求并不是特别高,我们是尽量去办证做的一致,并没有去引入这种本地消息表,事务消息,这种比较重的分布式事务实现,我相信这一点大家也是可以理解的
第三点
我们平时尽量要保证事务尽量小,开启关闭事务,这个是有资源消耗成本的,另外就是数据库的链接池,它也是有效的,如果有大事务,那你会一直持有这个连接不释放,那对于整个线程池的吞吐量,这个是有影响的,
所以我们在写代码的时候,要避免大事务,比如说:能批量的就尽量批量,不要用循环,也尽量不要在事务里面做一些RPC,这种比较耗时的操作。
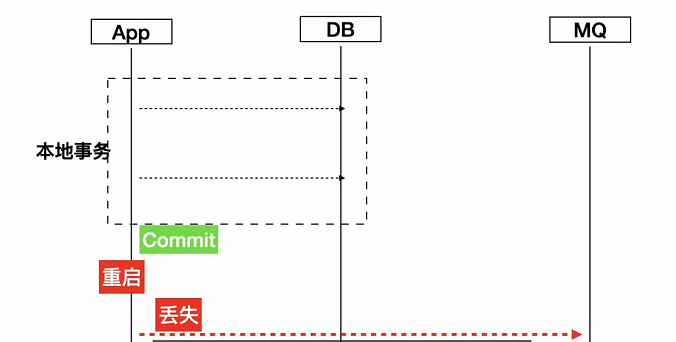
明确了这三点之后,我看了一下之前团队的代码,会出现有些,在事务里面去调用MQ的情况,而且在业务上,其实是本地事务提交成功了,才希望去发这个MQ,所以这个代码明显是有问题的
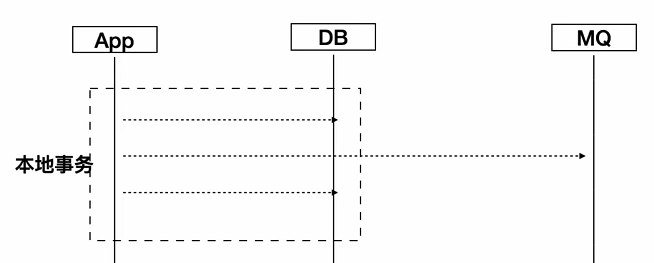
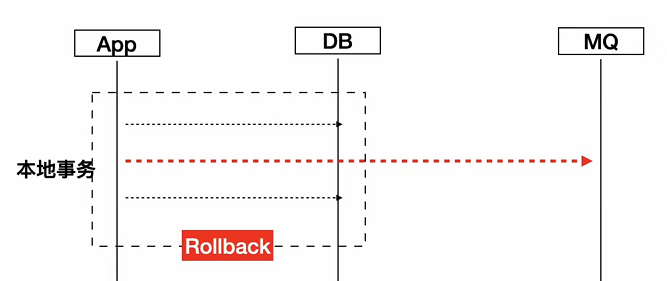
比如说我本地事务回滚了,但是中间消息已经发出去了,那你这个消息是没办法撤回的,那这里发生消息跟本地事务就没有保证原子性。
这个处理其实也很简单,就是把发送MQ消息放在本地事务执行之后。
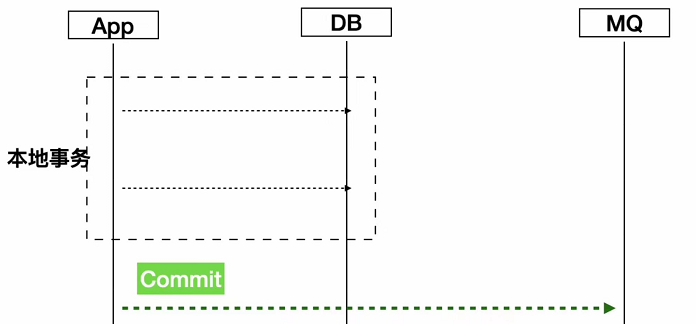
这个并不是分布式事务的解决方案,因为在极端情况下,你本地事务提交了之后,你还没有去发消息,这个时候机器重启了或者挂掉了,这里理论上来说也是有种风险的,所以这个方案并不是一种分布式事务的解决方案,这里更多的侧重点是优化我们的代码结构。
但是基于我们刚才所提到了Spring的代理,我们必须要把发送MQ消息移动到方法外,并且是从上层方法去进行一个调用,没办法再方法内去实现这个方法,这样才能基于Spring去做代理,所以现在已有的这些代码,如果你要去做变更的话,你挪动的代码就会比较多。
我认为代码一方面,你要告诉计算机怎么去执行,另外一方面,你也要让别人看得懂,易于理解,所以很多时候,确实在你这个事务里面去发消息,更容易得到人的理解。我的意思就是,我们能不能就在这个声明式事务里面去完成这个代码的编写,能不能通过某种方式,
在我本地事务执行成功之后,我再去做我这么一个回调的操作。答案是肯定的。Spring 它是提供这个扩展的。
这个类就是Spring的事务这个包下面,它提供了一个接口扩展TransactionSynchronization。这是一个事务同步回调的接口,基于这个是事务管理器,而且这个接口也有order的能力,就是你多个回调接口,它可以控制它回调的顺序,并且它这里提供了事务执行状态的几个常量,
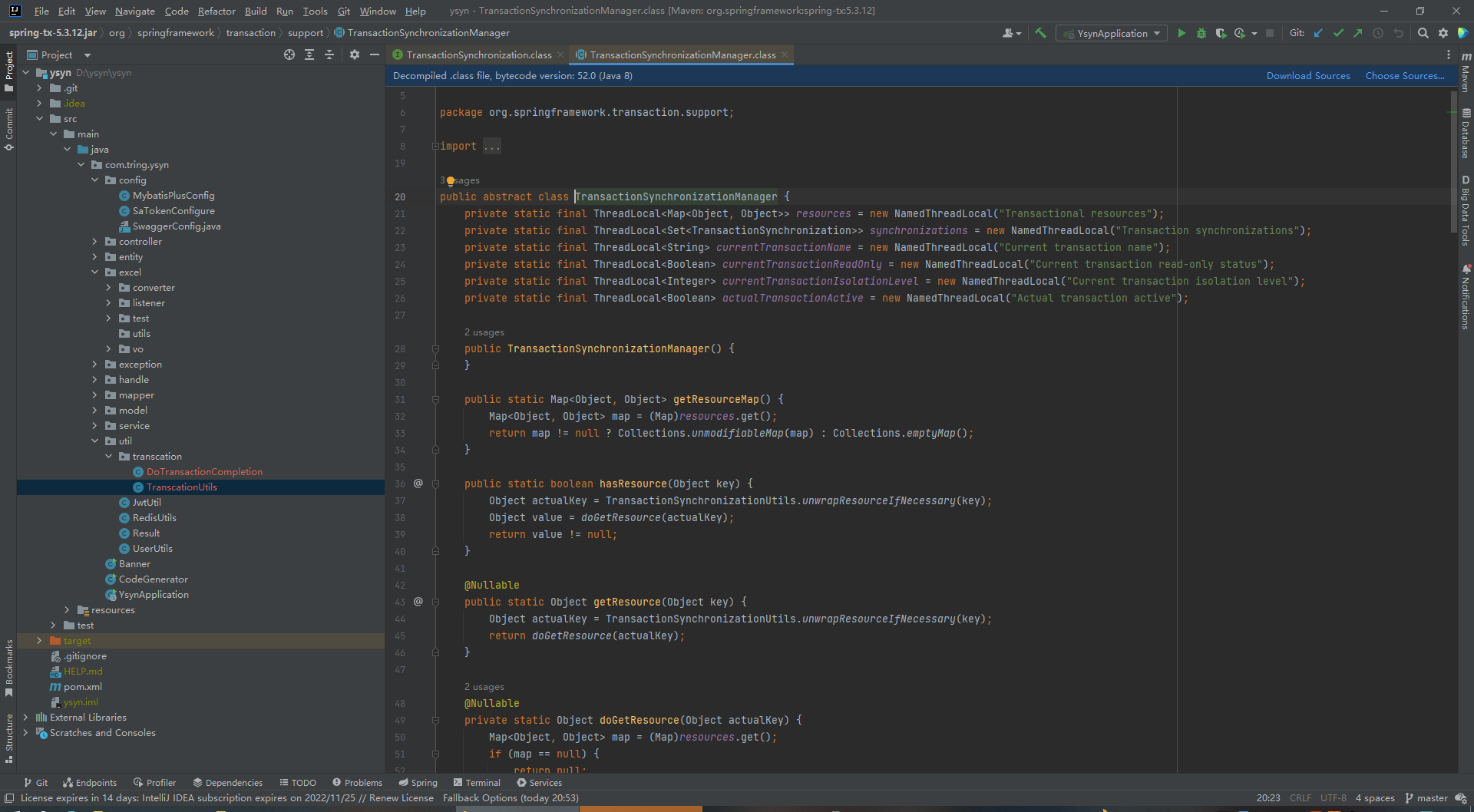
另外的一个问题,就是我们要判断当前上下文里面有没有事务,有事务的话我们才去做这么一个回调,没有的话就不去做处理。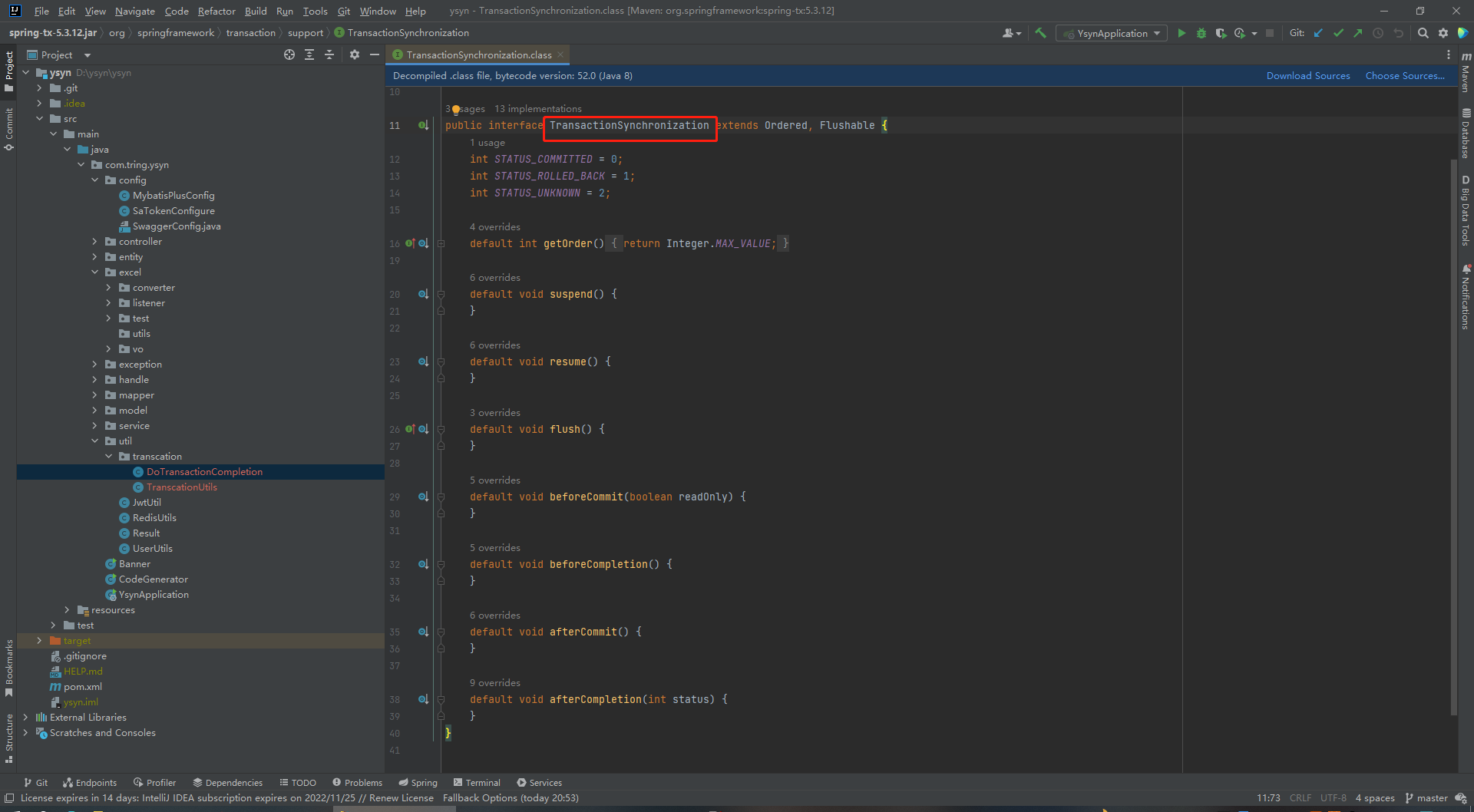
Spring 它同样提供了这样的能力,就是TransactionSynchronizationManager,这个方法里面它有静态方法,就能判断当前有没有事务它被激活,我们可以看它的文档。
接下来我就给大家演示一下
首先就定义一个扩展点的实现,就是我们要在事务之后去做什么事情。
package com.tring.ysyn.util.transcation; import org.springframework.transaction.support.TransactionSynchronization; /** * @author Tring * date 2022-11-11 */ public class DoTransactionCompletion implements TransactionSynchronization { private Runnable runnable; public DoTransactionCompletion(Runnable runnable) { this.runnable = runnable; } @Override public void afterCompletion(int status) { //只有当我事务成功提交的时候,才去做处理 if(status == TransactionSynchronization.STATUS_COMMITTED){ this.runnable.run(); } } }
我们再来写个静态的工具包
package com.tring.ysyn.util.transcation; import org.springframework.transaction.annotation.Transactional; import org.springframework.transaction.support.TransactionSynchronizationManager; /** * @author Tring * date 2022-11-11 */ public class TranscationUtils { public static void doAfterTransact(Runnable runnable){ //判断下我们上下文有没有事务激活,如果有就就把DoTransactionCompletion注册进去 if (TransactionSynchronizationManager.isActualTransactionActive()){ TransactionSynchronizationManager.registerSynchronization(new DoTransactionCompletion(runnable)); } } }
最后写写测试代码,随便写个控制器,调用我们工具类的方法就可以了,至于具体操作什么我就不写了。
/** *测试 */ @Transactional public void daTx(){ //start tx TranscationUtils.doAfterTransact(()->{ //semg MQ }); //end tx }
另外,我们来谈谈分布式事务可见性问题问题吧。
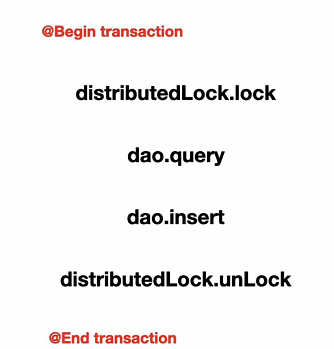
第一步就是先开启事务
第二步就是加分布式锁
第三步就是做一个查询
第四步如果查询没有查到就去做一个insert,然后就去释放锁提交事务
大家有没有发现,这就是非常典型的接口幂等性的设计,就是要避免重复去insert这行数据,所以加了这么一个分布式锁去防并发。
但是大家想一下,这个步骤真的能防住并发吗?我给大家两点提示。
1、解锁之后到事务提交之前,它可能中间会一些耗时的操作,这里其实是有一个间隙的。
2、事务默认的隔离级别是可重复读
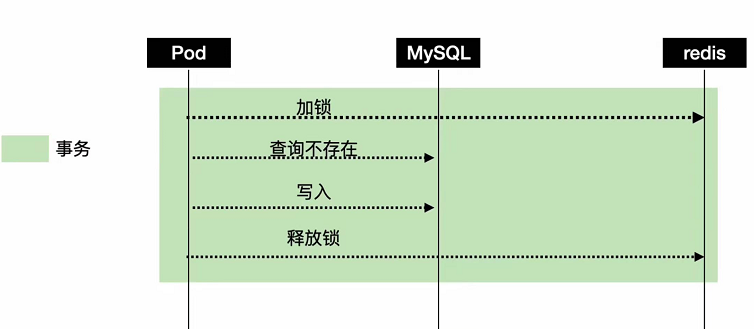
大家思考一下,如果说在你这个释放分布式锁之后,这个间隙里面来了一个并发的线程,会出现什么问题,
我们可以来逐行分析下这个伪代码。
第一步开启事务,第二步加锁,
因为第一个线程它已经释放掉锁了,所以说这里假锁肯定是会成功的,
然后这里去做查询
因为第一个线程,他的事务其实还没有提交的,所以根据事务的隔离级别,它是不会读到这个数据的,
查不到数据呢,那然后又会去insert,那这里就重复插入了,所以这个分布式锁,并没有起到它本该起的作用
大家能理清楚这个问题产生的原因吗?
所以这个问题要怎么去解决呢?
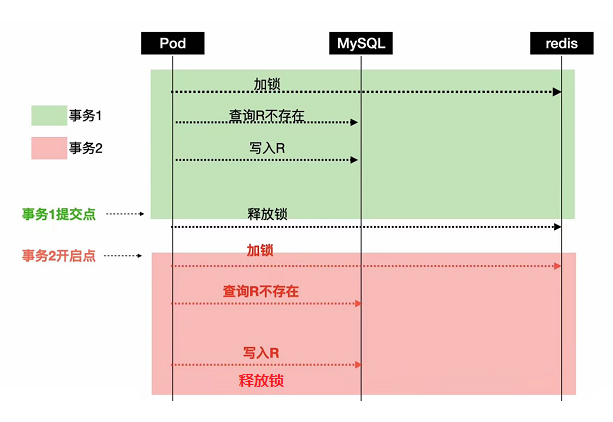
其实我们只要在事务提交之后,去进行分布式锁的释放,这个问题其实就能解决,因为前面的代码,它释放分布式锁是在事务里面,
那现在的话是在事务外面释放分布式锁,你发现它锁的范围变大了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号