
Python中文文件处理中涉及的字符编码及字符集
在现在的互联网,字符编码是互联网信息交互的一个重要基础,各种语言都有支持信息编码的机制,Python也不例外。Python除了字符编码之外,对于字节码和字符串两种类型有严格区分,字符串是本地可以读取的信息,字节码既可以来源是本身是字节码的内容,也可以是字符串直接转换生成。
在中文环境下,主要用的编码有GBK、UTF-8、GB2312等,在Python中,主要使用encode将字符串转换成字节码,使用decode将字节码转换成字符串。使用什么字符集方式编码就需要使用什么字符集解码,否则解码会存在问题。
Python支撑的字符集编码及其含义如下:
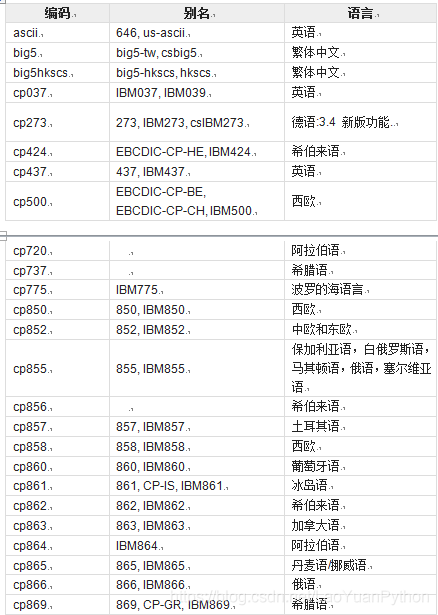
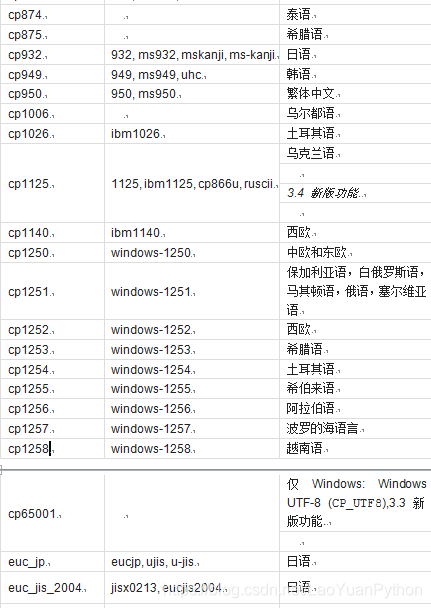
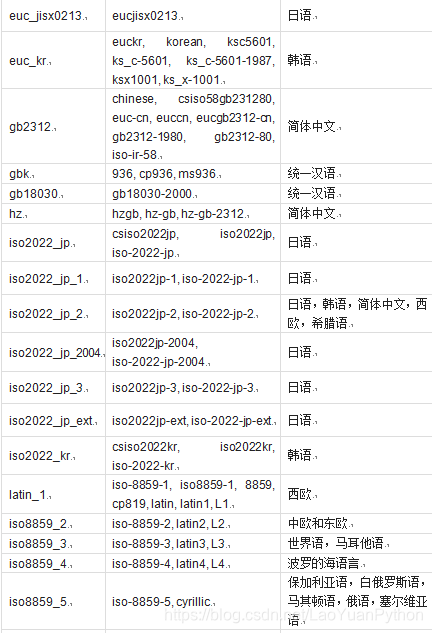
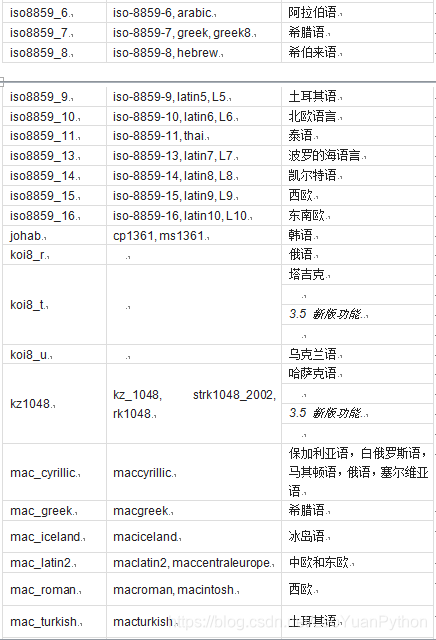
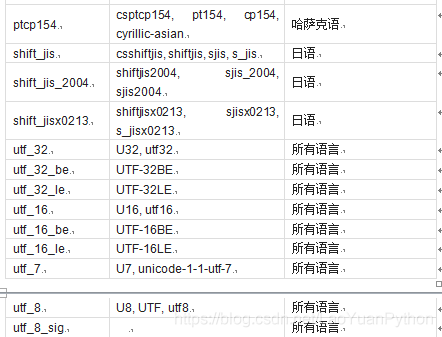
以上编码串大小写都可以,下面是从中文文本中读入的字节码解码例子:
>>> fp = open(r"c:\temp\test.txt","rb")
>>> line = fp.readline()
>>> line
b'\xb3\xfc\xd6\xdd\xce\xf7\xbd\xa7\r\n'
>>> line.decode('gbk')
'滁州西涧\r\n'
>>> line.decode('GBK')
'滁州西涧\r\n'
>>> line.decode('GBk')
'滁州西涧\r\n'
>>>
老猿Python,跟老猿学Python!
博客地址:https://blog.csdn.net/LaoYuanPython
请大家多多支持,点赞、评论和加关注!谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号